python序列类型及操作
!序列类型定义:
~序列是一维元素向量,元素类型可以不一样。
!序列处理函数及方法
操作符及应用 |
描述 |
A in B |
返回bool值,如果A在B中,返回True |
A not in B |
返回bool值,如果A不在B中,返回true |
a+b |
连接两个序列a和b |
a*b 或a*b |
将序列a复制b次 |
a[i] |
返回a中的第i个元素 |
a[i:j]或a[i:j:k] |
返回a中第i到j以k为步长的元素子序列 |
Len(a) |
返回序列a中的元素个数 |
Min(a) |
返回序列a中的最小元素 |
Max(a) |
返回序列a中的最大元素 |
a.Count(b) |
返回序列a中出现b的总次数 |
a.Index(b)或a.index(b,i,j) |
返回序列a从i到j位置中第一次出现元素b的位置 |
案例:
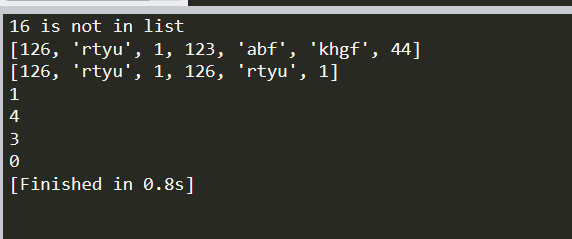
list=[123,"abf","khgf",44];
if 16 in list:
print("16 in list")
else:
print("16 is not in list")
pass
list2=[126,"rtyu",1]
list3=list2+list
print(list3)
print(list2*2)
print(list3[2])
print(len(list))
print(list.index(44))
print(list.count("f"))
!元组类型及操作
~元组是一种序列类型,一旦创建就不能被修改,用()和tuple()创建。
A="my","she","he",13
B=("dog","pen",16)
C=(12,A,B)
print(C[2][1])
print(C[2][3])
结果:

这表明了一个问题,就是元组类它不会自动赋值为null
!列表类型及操作
~列表是一种序列类型,创建后可以随意被修改,用[]和set()创建
操作有:
函数或方法 |
描述 |
Ls[i]=x |
替换列表ls第i元素为x |
Ls[i:j:k]=lt |
用列表lt替换ls切片后所对应元素子列表 |
Del ls[i] |
删除列表ls中第i元素 |
Del ls[i:j:k] |
删除列表ls中第i到第j以k为步长的元素 |
Ls+=lt |
更新列表ls,将列表lt元素增加到列表ls中 |
Ls*=n |
更新列表ls,其元素重复n次 |
Ls.append(x) |
在列表ls最后增加一个元素x |
Ls.clear() |
删除列表ls中所有的元素 |
Ls.copy() |
生成一个新的列表,复制ls中所有的元素 |
Ls.insert(I,x) |
在列表ls的第i位置增加元素x |
Ls.pop(i) |
将列表ls中第i位元素去除并删除该元素 |
Ls.remove(x) |
将列表中出现的第一个元素x删除 |
Ls.reverse() |
将列表ls中的元素反转 |
案例操作:
lt=["tom","car","cat",1420,"mother"]#定义列表 lt+=["henry","sorry","fox",145,65]#向列表中加入5个元素 print(lt) lt[2]=14#修改列表中的第二个元素,这里我们要指出索引为第二个元素,而不是下标 print(lt) lt.insert(2,"ffg")#向元素第二个位置增加一个元素 print(lt) print(lt.pop(0))#显示列表中第一个元素并删除 del lt[1:4]#删除列表中第1-3位置元素 print(lt) print(0 in lt)#判断lt中是否包含数字0 print(lt.append(0))#向lt中新增数字0 print(lt.index((0)))#返回数字0在lt中的索引 print(len(lt))#列表的长度 print(max(lt))#列表中的最大元素 lt.clear()#清空列表
操作结果:




