带你掌握如何查看并读懂昇腾平台的应用日志
摘要:
本文介绍了昇腾平台日志分类、日志级别设置、日志内容格式,以及如何获取日志文件的方法。
本文分享自华为云社区《
如何查看并读懂昇腾平台的应用日志
》,作者:昇腾CANN。
当您完成训练/推理工程开发后,将工程放到昇腾平台运行,以调试工程是否正常运行,此时,可能会出现各种各样、五花八门的异常状况。
当问题发生时,我们的第一反应是不是查看日志,看看哪里报错了。昇腾平台有哪些日志呢?日志文件又在哪呢?本期带您了解如何使用昇腾平台的日志功能。
01 了解日志分类
根据工程运行过程中日志产生的场景不同,日志通常被分为以下4类:
- 调试日志(debug):记录调试级别的相关信息,一般用于跟踪运行路径,如记录函数的进入和退出等,大部分为代码级的信息输出,调试日志用于开发人员定位复杂问题。
- 操作日志(operation):记录设备操作维护人员下发或通过设置相关的自动化任务下发的操作和操作结果。
- 安全日志(security):记录系统用户登录、注销和鉴权,增加、删除用户,用户的锁定和解锁,角色权限变更,系统相关安全配置(如安全日志内容配置)变更等活动。
- 运行日志(run):记录系统的运行状况或执行流程中的一些关键信息,包括异常的状态、动作,关键的事件等。
02 如何获取日志文件
我们现在知道了昇腾AI处理器有4类日志,那我们需要到哪里查看这些日志呢?本节来揭秘。
昇腾AI处理器具有EP和RC两种形态,针对不同的硬件形态,日志文件存放位置不同,需根据实际硬件形态获取。
EP场景日志获取
- 应用类日志
用户应用进程在Host侧和Device侧产生的日志。例如,一个推理/训练任务下发后,通常与本次推理/训练直接相关的日志都存放在应用类日志中。
这类日志默认存放在“$HOME/ascend/log”路径下,格式如下:
├── debug
│ ├── device-0│ │ └── device-pid_*.log //Device侧产生的日志 │ └── plog
│ └── plog-pid_*.log //Host侧产生的日志 ├── operation
│ ├── device-0│ │ └── device-pid_*.log
│ └── plog
│ └── plog-pid_*.log
├── run
│ ├── device-0│ │ └── device-pid_*.log
│ └── plog
│ └── plog-pid_*.log
└── security
├── device-0│ └── device-pid_*.log
└── plog
└── plog-pid_*.log
- 系统类日志
非用户应用进程在Device侧产生的日志,即Device侧常驻进程运行产生的日志通常都在存放在系统类日志中。
这类日志生成时默认存放在Device侧/var/log/npu/slog路径下,需要在Host侧通过msnpureport工具将其导出到Host侧再进行查看。
命令举例:
$Driver_HOME/driver/tools/msnpureport -a
通过msnpureport工具导出到Host侧后,系统类日志按Device侧文件夹存放,格式如下:
├── debug
│ ├── device-os
│ └── device-os_*.log
├── operation
│ ├── device-os
│ └── device-os_*.log
├── run
│ ├── device-os
│ └── device-os_*.log
├──security
│ ├── device-os
│ └── device-os_*.log
└── slog
└── slogdlog
RC形态日志获取
RC形态日志获取比较简单,不管是应用类日志还是系统类日志,均存放在/var/log/npu/slog路径下。存放格式与EP场景类似:
├── debug
│ ├── device-app-pid
│ │ └── device-app-pid_*.log
│ └── device-os
│ └── device-os_*.log
├── operation
│ ├── device-app-pid
│ │ └── device-app-pid_*.log
│ └── device-os
│ └── device-os_*.log
├── run
│ ├── device-app-pid
│ │ └── device-app-pid_*.log
│ └── device-os
│ └── device-os_*.log
├── security
│ ├── device-app-pid
│ │ └── device-app-pid_*.log
│ └── device-os
│ └── device-os_*.log
└── device-id
└──device-id_*.log
03 如何读懂日志内容
日志内容严格按照日志规范打印,每条日志格式一致、字段含义明确,便于阅读。日志格式、字段含义如下:
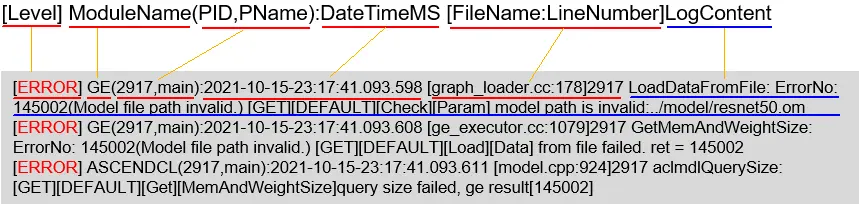
日志内容可以通过cat、grep等命令查看。
04 如何设置日志级别
日志级别定义
不同日志级别打印的日志内容详细程度不同,因此,问题定位时可以使用最详细日志(DEBUG)打印,而验证性能时使用最简日志(ERROR)打印即可。日志功能提供了5种级别供大家选择使用:
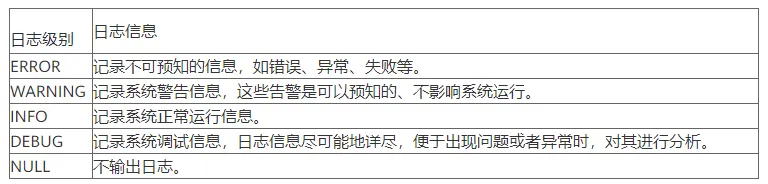
说明:各级别日志详细程度:DEBUG > INFO > WARNING > ERROR
设置日志级别
通过上面日志级别介绍,我们了解到可以根据自己需求设置不同的日志级别、打印不同详细程度的日志。那应该如何设置呢?
- 应用类日志级别设置,通过在Host侧设置ASCEND_GLOBAL_LOG_LEVEL环境变量实现,例如设置INFO级别:
export ASCEND_GLOBAL_LOG_LEVEL=1- 系统类日志级别设置,针对EP和RC形态提供了不同的方法。
RC形态通过修改/var/log/npu/conf/slog/slog.conf配置文件、重启日志进程生效。
#note, 0:debug, 1:info, 2:warning, 3:error, 4:null(no output log), default(1)
global_level=1# Event Type Log Flag,0:disable, 1:enable, default(1)
enableEvent=1# note,0:debug, 1:info, 2:warning, 3:error, 4:null(no output log), 5:invalid(follow global_level)
SLOG=5# Slog
IDEDD=5# ascend debug device agent
DVPP=5# DVPP
CCE=5 # CCE
EP形态通过msnpureport工具设置系统类日志级别。例如:
$Driver_HOME/driver/tools/msnpureport –g info
05 更多介绍
关于昇腾平台日志更多介绍,请登录
昇腾文档中心
查阅。