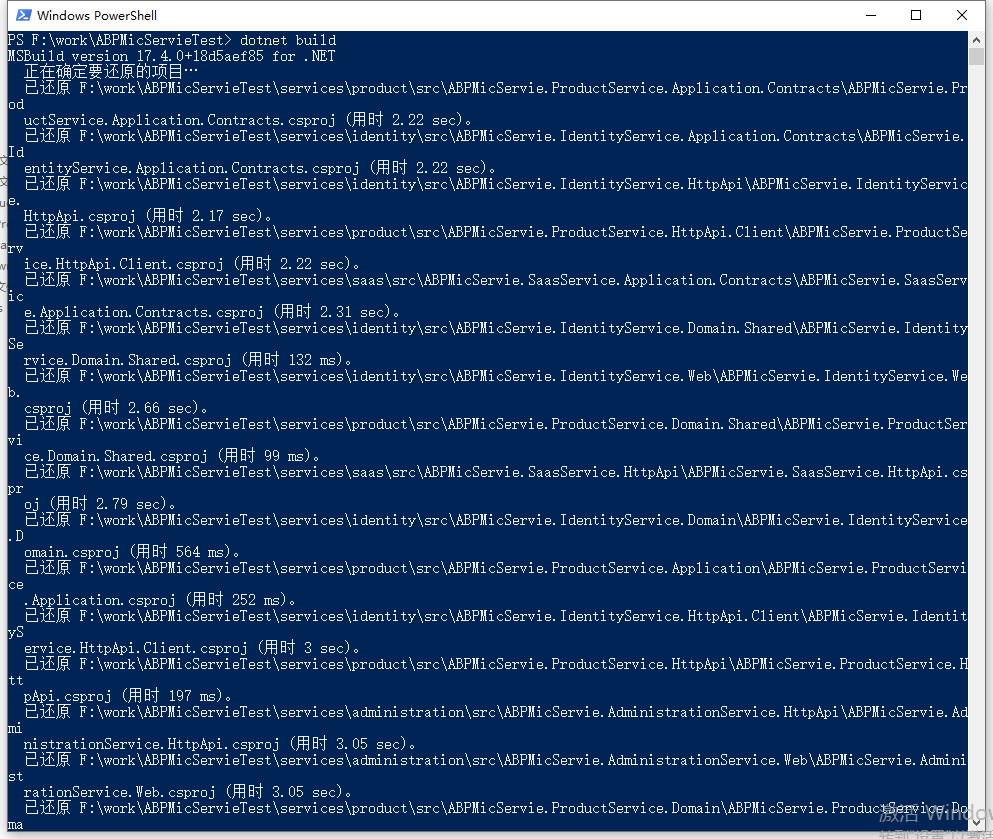
作者:京东零售 王鹏超
1.什么是参数解析器
@RequstBody、@RequstParam 这些注解是不是很熟悉?
我们在开发Controller接口时经常会用到此类参数注解,那这些注解的作用是什么?我们真的了解吗?
简单来说,这些注解就是帮我们将前端传递的参数直接解析成直接可以在代码逻辑中使用的javaBean,例如@RequstBody接收json参数,转换成java对象,如下所示:
|
前台传参
|
参数格式
|
|
application/json |
正常代码书写如下:
@RequestMapping(value = "/getUserInfo")
public String getUserInfo(@RequestBody UserInfo userInfo){
//***
return userInfo.getName();
}
但如果是服务接收参数的方式改变了,如下代码,参数就不能成功接收了,这个是为什么呢?
@RequestMapping(value = "/getUserInfo")
public String getUserInfo(@RequestBody String userName, @RequestBody Integer userId){
//***
return userName;
}
如果上面的代码稍微改动一下注解的使用并且前台更改一下传参格式,就可以正常解析了。
|
前台传参
|
参数格式
|
| http://***?userName=Alex&userId=1 |
无 |
@RequestMapping(value = "/getUserInfo")
public String getUserInfo(@RequestParam String userName, @RequestParam Integer userId){
//***
return userName;
}
这些这里就不得不引出这些注解背后都对应的内容—Spring提供的参数解析器,这些参数解析器帮助我们解析前台传递过来的参数,绑定到我们定义的Controller入参上,不通类型格式的传递参数,需要不同的参数解析器,有时候一些特殊的参数格式,甚至需要我们自定义一个参数解析器。
不论是在SpringBoot还是在Spring MVC中,一个HTTP请求会被DispatcherServlet类接收(本质是一个Servlet,继承自HttpServlet)。Spring负责从HttpServlet中获取并解析请求,将请求uri匹配到Controller类方法,并解析参数并执行方法,最后处理返回值并渲染视图。
参数解析器的作用就是将http请求提交的参数转化为我们controller处理单元的入参
。原始的Servlet获取参数的方式如下,需要手动从HttpServletRequest中获取所需信息。
@WebServlet(urlPatterns="/getResource")
public class resourceServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) {
/**获取参数开始*/
String resourceId = req.getParameter("resourceId");
String resourceType = req.getHeader("resourceType");
/**获取参数结束*/
resp.setContentType("text/html;charset=utf-8");
PrintWriter out = resp.getWriter();
out.println("resourceId " + resourceId + " resourceType " + resourceType);
}
}
Spring为了帮助开发者解放生产力,提供了一些特定格式(header中content-type对应的类型)入参的参数解析器,我们在接口参数上只要加上特定的注解(当然不加注解也有默认解析器),就可以直接获取到想要的参数,不需要我们自己去HttpServletRequest中手动获取原始入参,如下所示:
@RestController
public class resourceController {
@RequestMapping("/resource")
public String getResource(@RequestParam("resourceId") String resourceId,
@RequestParam("resourceType") String resourceType,
@RequestHeader("token") String token) {
return "resourceId" + resourceId + " token " + token;
}
}
常用的注解类参数解析器使用方式以及与注解的对应关系对应关系如下:
|
注解命名
|
放置位置
|
用途
|
| @PathVariable |
放置在参数前 |
允许request的参数在url路径中 |
| @RequestParam |
放置在参数前 |
允许request的参数直接连接在url地址后面,也是Spring默认的参数解析器 |
| @RequestHeader |
放置在参数前 |
从请求header中获取参数 |
| @RequestBody |
放置在参数前 |
允许request的参数在参数体中,而不是直接连接在地址后面 |
|
注解命名
|
对应的解析器
|
content-type
|
| @PathVariable |
PathVariableMethodArgumentResolver |
无 |
| @RequestParam |
RequestParamMethodArgumentResolver |
无(get请求)和multipart/form-data |
| @RequestBody |
RequestResponseBodyMethodProcessor |
application/json |
| @RequestPart |
RequestPartMethodArgumentResolver |
multipart/form-data |
2.参数解析器原理
要了解参数解析器,首先要了解一下最原始的Spring MVC的执行过程。客户端用户发起一个Http请求后,请求会被提交到前端控制器(Dispatcher Servlet),由前端控制器请求处理器映射器(步骤1),处理器映射器会返回一个执行链(Handler Execution 步骤2),我们通常定义的拦截器就是在这个阶段执行的,之后前端控制器会将映射器返回的执行链中的Handler信息发送给适配器(Handler Adapter 步骤3),适配器会根据Handler找到并执行相应的Handler逻辑,也就是我们所定义的Controller控制单元(步骤4),Handler执行完毕会返回一个ModelAndView对象,后续再经过视图解析器解析和视图渲染就可以返回给客户端请求响应信息了。

在容器初始化的时候,RequestMappingHandlerMapping 映射器会将 @RequestMapping 注解注释的方法存储到缓存,其中key是 RequestMappingInfo,value是HandlerMethod。HandlerMethod 是如何进行方法的参数解析和绑定,就要了解请求参数适配器**RequestMappingHandlerAdapter,**该适配器对应接下来的参数解析及绑定过程。源码路径如下:
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter
RequestMappingHandlerAdapter
大致的解析和绑定流程如下图所示,
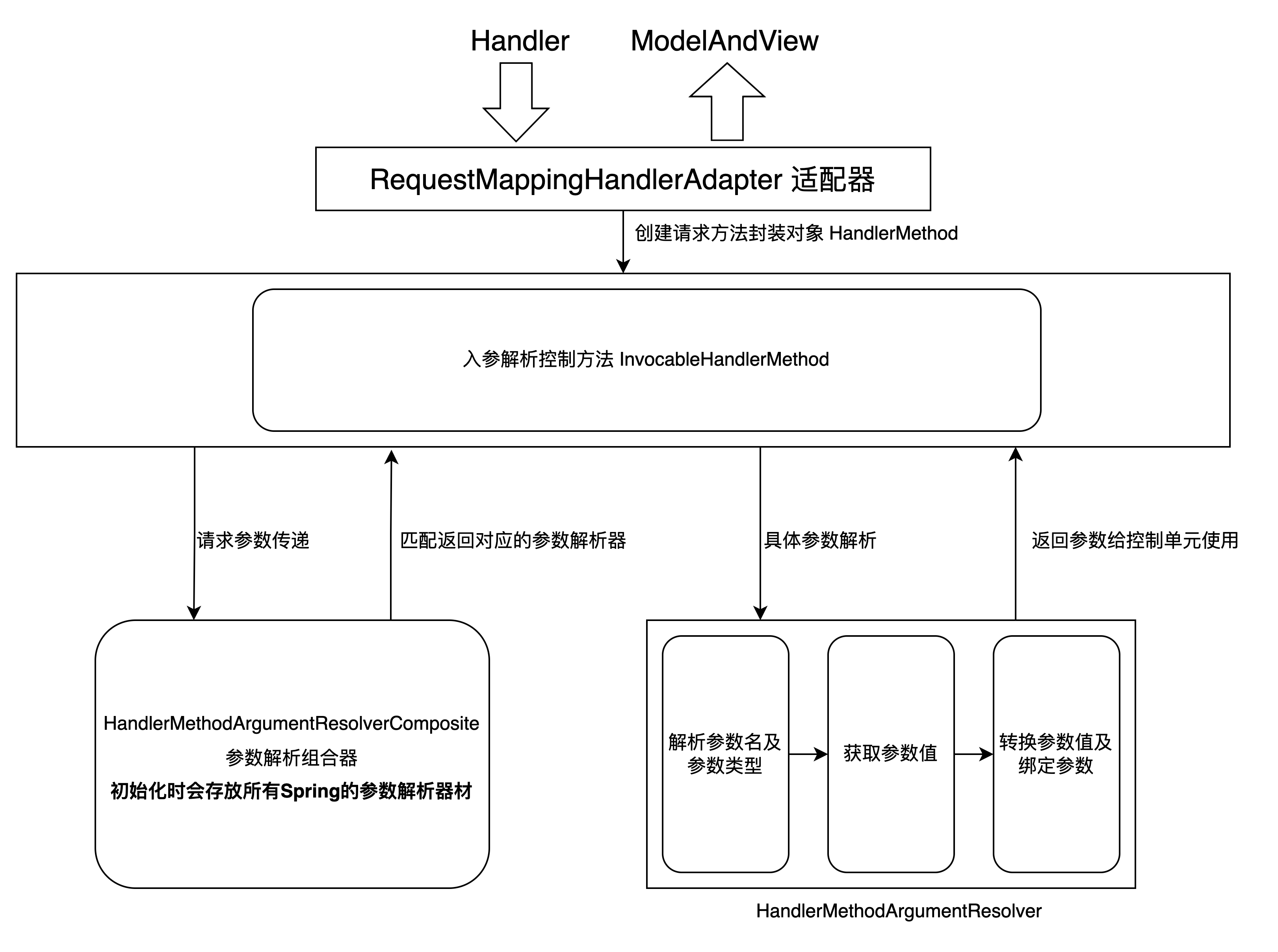
RequestMappingHandlerAdapter实现了接口InitializingBean,在Spring容器初始化Bean后,调用方法afterPropertiesSet( ),将默认参数解析器绑定HandlerMethodArgumentResolverComposite 适配器的参数 argumentResolvers上,其中HandlerMethodArgumentResolverComposite是接口HandlerMethodArgumentResolver的实现类。源码路径如下:
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter#afterPropertiesSet
@Override
public void afterPropertiesSet() {
// Do this first, it may add ResponseBody advice beans
initControllerAdviceCache();
if (this.argumentResolvers == null) {
/** */
List<HandlerMethodArgumentResolver> resolvers = getDefaultArgumentResolvers();
this.argumentResolvers = new HandlerMethodArgumentResolverComposite().addResolvers(resolvers);
}
if (this.initBinderArgumentResolvers == null) {
List<HandlerMethodArgumentResolver> resolvers = getDefaultInitBinderArgumentResolvers();
this.initBinderArgumentResolvers = new HandlerMethodArgumentResolverComposite().addResolvers(resolvers);
}
if (this.returnValueHandlers == null) {
List<HandlerMethodReturnValueHandler> handlers = getDefaultReturnValueHandlers();
this.returnValueHandlers = new HandlerMethodReturnValueHandlerComposite().addHandlers(handlers);
}
}
通过getDefaultArgumentResolvers( )方法,可以看到Spring为我们提供了哪些默认的参数解析器,这些解析器都是
HandlerMethodArgumentResolver
接口的实现类。
针对不同的参数类型,Spring提供了一些基础的参数解析器,其中有基于注解的解析器,也有基于特定类型的解析器,当然也有兜底默认的解析器,如果已有的解析器不能满足解析要求,Spring也提供了支持用户自定义解析器的扩展点,源码如下:
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter#getDefaultArgumentResolvers
private List<HandlerMethodArgumentResolver> getDefaultArgumentResolvers() {
List<HandlerMethodArgumentResolver> resolvers = new ArrayList<HandlerMethodArgumentResolver>();
// Annotation-based argument resolution 基于注解
/** @RequestPart 文件注入 */
resolvers.add(new RequestParamMethodArgumentResolver(getBeanFactory(), false));
/** @RequestParam 名称解析参数 */
resolvers.add(new RequestParamMapMethodArgumentResolver());
/** @PathVariable url路径参数 */
resolvers.add(new PathVariableMethodArgumentResolver());
/** @PathVariable url路径参数,返回一个map */
resolvers.add(new PathVariableMapMethodArgumentResolver());
/** @MatrixVariable url矩阵变量参数 */
resolvers.add(new MatrixVariableMethodArgumentResolver());
/** @MatrixVariable url矩阵变量参数 返回一个map*/
resolvers.add(new Matrix VariableMapMethodArgumentResolver());
/** 兜底处理@ModelAttribute注解和无注解 */
resolvers.add(new ServletModelAttributeMethodProcessor(false));
/** @RequestBody body体解析参数 */
resolvers.add(new RequestResponseBodyMethodProcessor(getMessageConverters(), this.requestResponseBodyAdvice));
/** @RequestPart 使用类似RequestParam */
resolvers.add(new RequestPartMethodArgumentResolver(getMessageConverters(), this.requestResponseBodyAdvice));
/** @RequestHeader 解析请求header */
resolvers.add(new RequestHeaderMethodArgumentResolver(getBeanFactory()));
/** @RequestHeader 解析请求header,返回map */
resolvers.add(new RequestHeaderMapMethodArgumentResolver());
/** Cookie中取值注入 */
resolvers.add(new ServletCookieValueMethodArgumentResolver(getBeanFactory()));
/** @Value */
resolvers.add(new ExpressionValueMethodArgumentResolver(getBeanFactory()));
/** @SessionAttribute */
resolvers.add(new SessionAttributeMethodArgumentResolver());
/** @RequestAttribute */
resolvers.add(new RequestAttributeMethodArgumentResolver());
// Type-based argument resolution 基于类型
/** Servlet api 对象 HttpServletRequest 对象绑定值 */
resolvers.add(new ServletRequestMethodArgumentResolver());
/** Servlet api 对象 HttpServletResponse 对象绑定值 */
resolvers.add(new ServletResponseMethodArgumentResolver());
/** http请求中 HttpEntity RequestEntity数据绑定 */
resolvers.add(new HttpEntityMethodProcessor(getMessageConverters(), this.requestResponseBodyAdvice));
/** 请求重定向 */
resolvers.add(new RedirectAttributesMethodArgumentResolver());
/** 返回Model对象 */
resolvers.add(new ModelMethodProcessor());
/** 处理入参,返回一个map */
resolvers.add(new MapMethodProcessor());
/** 处理错误方法参数,返回最后一个对象 */
resolvers.add(new ErrorsMethodArgumentResolver());
/** SessionStatus */
resolvers.add(new SessionStatusMethodArgumentResolver());
/** */
resolvers.add(new UriComponentsBuilderMethodArgumentResolver());
// Custom arguments 用户自定义
if (getCustomArgumentResolvers() != null) {
resolvers.addAll(getCustomArgumentResolvers());
}
// Catch-all 兜底默认
resolvers.add(new RequestParamMethodArgumentResolver(getBeanFactory(), true));
resolvers.add(new ServletModelAttributeMethodProcessor(true));
return resolvers;
}
HandlerMethodArgumentResolver
接口中只定义了两个方法,分别是解析器适用范围确定方法supportsParameter( )和参数解析方法resolveArgument(),不同用途的参数解析器的使用差异就体现在这两个方法上,这里就不具体展开参数的解析和绑定过程。
3.自定义参数解析器的设计
Spring的设计很好践行了开闭原则,不仅在封装整合了很多非常强大的能力,也为用户留好了自定义拓展的能力,参数解析器也是这样,Spring提供的参数解析器基本能满足常用的参数解析能力,但很多系统的参数传递并不规范,比如京东color网关传业务参数都是封装在body中,需要先从body中取出业务参数,然后再针对性解析,这时候Spring提供的解析器就帮不了我们了,需要我们扩展自定义适配参数解析器了。
Spring提供两种自定义参数解析器的方式,一种是实现适配器接口
HandlerMethodArgumentResolver
,另一种是继承已有的参数解析器(
HandlerMethodArgumentResolver
接口的现有实现类)例如
AbstractNamedValueMethodArgumentResolver
进行增强优化。如果是深度定制化的自定义参数解析器,建议实现自己实现接口进行开发,以实现接口适配器接口自定义开发解析器为例,介绍如何自定义一个参数解析器。
通过查看源码发现,参数解析适配器接口留给我扩展的方法有两个,分别是supportsParameter( )和resolveArgument( ),第一个方法是自定义参数解析器适用的场景,也就是如何命中参数解析器,第二个是具体解析参数的实现。
public interface HandlerMethodArgumentResolver {
/**
* 识别到哪些参数特征,才使用当前自定义解析器
*/
boolean supportsParameter(MethodParameter parameter);
/**
* 具体参数解析方法
*/
Object resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception;
}
现在开始具体实现一个基于注解的自定义参数解析器,这个是代码实际使用过程中用到的参数解析器,获取color网关的body业务参数,然后解析后给Controller方法直接使用。
public class ActMethodArgumentResolver implements HandlerMethodArgumentResolver {
private static final String DEFAULT_VALUE = "body";
@Override
public boolean supportsParameter(MethodParameter parameter) {
/** 只有指定注解注释的参数才会走当前自定义参数解析器 */
return parameter.hasParameterAnnotation(RequestJsonParam.class);
}
@Override
public Object resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer, NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception {
/** 获取参数注解 */
RequestJsonParam attribute = parameter.getParameterAnnotation(RequestJsonParam.class);
/** 获取参数名 */
String name = attribute.value();
/** 获取指定名字参数的值 */
String value = webRequest.getParameter(StringUtils.isEmpty(name) ? DEFAULT_VALUE : name);
/** 获取注解设定参数类型 */
Class<?> targetParamType = attribute.recordClass();
/** 获取实际参数类型 */
Class<?> webParamType = parameter.getParameterType()
/** 以自定义参数类型为准 */
Class<?> paramType = targetParamType != null ? targetParamType : parameter.getParameterType();
if (ObjectUtils.equals(paramType, String.class)
|| ObjectUtils.equals(paramType, Integer.class)
|| ObjectUtils.equals(paramType, Long.class)
|| ObjectUtils.equals(paramType, Boolean.class)) {
JSONObject object = JSON.parseObject(value);
log.error("ActMethodArgumentResolver resolveArgument,paramName:{}, object:{}", paramName, JSON.toJSONString(object));
if (object.get(paramName) instanceof Integer && ObjectUtils.equals(paramType, Long.class)) {
//入参:Integer 目标类型:Long
result = paramType.cast(((Integer) object.get(paramName)).longValue());
}else if (object.get(paramName) instanceof Integer && ObjectUtils.equals(paramType, String.class)) {
//入参:Integer 目标类型:String
result = String.valueOf(object.get(paramName));
}else if (object.get(paramName) instanceof Long && ObjectUtils.equals(paramType, Integer.class)) {
//入参:Long 目标类型:Integer(精度丢失)
result = paramType.cast(((Long) object.get(paramName)).intValue());
}else if (object.get(paramName) instanceof Long && ObjectUtils.equals(paramType, String.class)) {
//入参:Long 目标类型:String
result = String.valueOf(object.get(paramName));
}else if (object.get(paramName) instanceof String && ObjectUtils.equals(paramType, Long.class)) {
//入参:String 目标类型:Long
result = Long.valueOf((String) object.get(paramName));
} else if (object.get(paramName) instanceof String && ObjectUtils.equals(paramType, Integer.class)) {
//入参:String 目标类型:Integer
result = Integer.valueOf((String) object.get(paramName));
} else {
result = paramType.cast(object.get(paramName));
}
}else if (paramType.isArray()) {
/** 入参是数组 */
result = JsonHelper.fromJson(value, paramType);
if (result != null) {
Object[] targets = (Object[]) result;
for (int i = 0; i < targets.length; i++) {
WebDataBinder binder = binderFactory.createBinder(webRequest, targets[i], name + "[" + i + "]");
validateIfApplicable(binder, parameter, annotations);
}
}
} else if (Collection.class.isAssignableFrom(paramType)) {
/** 这里要特别注意!!!,集合参数由于范型获取不到集合元素类型,所以指定类型就非常关键了 */
Class recordClass = attribute.recordClass() == null ? LinkedHashMap.class : attribute.recordClass();
result = JsonHelper.fromJsonArrayBy(value, recordClass, paramType);
if (result != null) {
Collection<Object> targets = (Collection<Object>) result;
int index = 0;
for (Object targetObj : targets) {
WebDataBinder binder = binderFactory.createBinder(webRequest, targetObj, name + "[" + (index++) + "]");
validateIfApplicable(binder, parameter, annotations);
}
}
} else{
result = JSON.parseObject(value, paramType);
}
if (result != null) {
/** 参数绑定 */
WebDataBinder binder = binderFactory.createBinder(webRequest, result, name);
result = binder.convertIfNecessary(result, paramType, parameter);
validateIfApplicable(binder, parameter, annotations);
mavContainer.addAttribute(name, result);
}
}
自定义参数解析器注解的定义如下,这里定义了一个比较特殊的属性recordClass,后续会讲到是解决什么问题。
/**
* 请求json参数处理注解
* @author wangpengchao01
* @date 2022-11-07 14:18
*/
@Target(ElementType.PARAMETER)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface RequestJsonParam {
/**
* 绑定的请求参数名
*/
String value() default "body";
/**
* 参数是否必须
*/
boolean required() default false;
/**
* 默认值
*/
String defaultValue() default ValueConstants.DEFAULT_NONE;
/**
* 集合json反序列化后记录的类型
*/
Class recordClass() default null;
}
通过配置类将自定义解析器注册到Spring容器中
@Configuration
public class WebConfig extends WebMvcConfigurerAdapter {
@Bean
public static ActMethodArgumentResolver actMethodArgumentResolverConfigurer() {
return new ActMethodArgumentResolver();
}
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
argumentResolvers.add(actMethodArgumentResolverConfigurer());
}
}
到此,一个完整的基于注解的自定义参数解析器就完成了。
4.总结
了解Spring的参数解析器原理有助于正确使用Spring的参数解析器,也让我们可以设计适用于自身系统的参数解析器,对于一些通用参数类型的解析减少重复代码的书写,但是这里有个前提是我们
项目中复杂类型的入参要统一
,
前端传递参数的格式也要统一
,不然设计自定义参数解析器就是个灾难,需要做各种复杂的兼容工作。参数解析器的设计尽量要放在项目开发开始阶段,历史复杂的系统如果接口开发没有统一规范也不建议自定义参数解析器设计。
该文章仅作为Spring参数解析器的介绍性解读,希望对大家有所帮助,欢迎有这类需求或者兴趣的同学沟通交流,批评指正,一起进步!