openGauss Datakit安装部署
一、问题描述:目前找不到任何关于opengauuss Datakit安装部署的文档,自己来尝试踩坑。
DataKit是一个以资源(物理机,数据库)为底座的开发运维工具,将上层的开发运维工具插件化,各插件之间相互独立,方便用户按需引入。各插件围绕DataKit的资源中心进行扩展开,完成数据库的运维,监控,迁移,开发,建模等复杂的操作。
Datakit安装部署在服务器上,是一个自动化运维的平台。可以部署不同类型的插件来实现不同的功能,是跟随opengauss5.0发布的新软件,也可以用来监控小于5.0的opengauss版本
二、环境准备:
Datakit官方文档:https://docs.opengauss.org/zh/docs/5.0.0/docs/ToolandCommandReference/DataKit.html
DataKit使用文档和开发文档:
https://gitee.com/opengauss/openGauss-workbench/tree/master/openGauss-visualtool/doc
openGauss-workbench下载链接:https://gitee.com/opengauss/openGauss-workbench.git
Datakit下载链接:https://opengauss.org/zh/download/
JDK下载链接:https://www.oracle.com/in/java/technologies/javase/jdk11-archive-downloads.html#license-lightbox
linux操作系统的jdk版本要与datakit打的jar包jdk版本保持一致,要不然通过不了
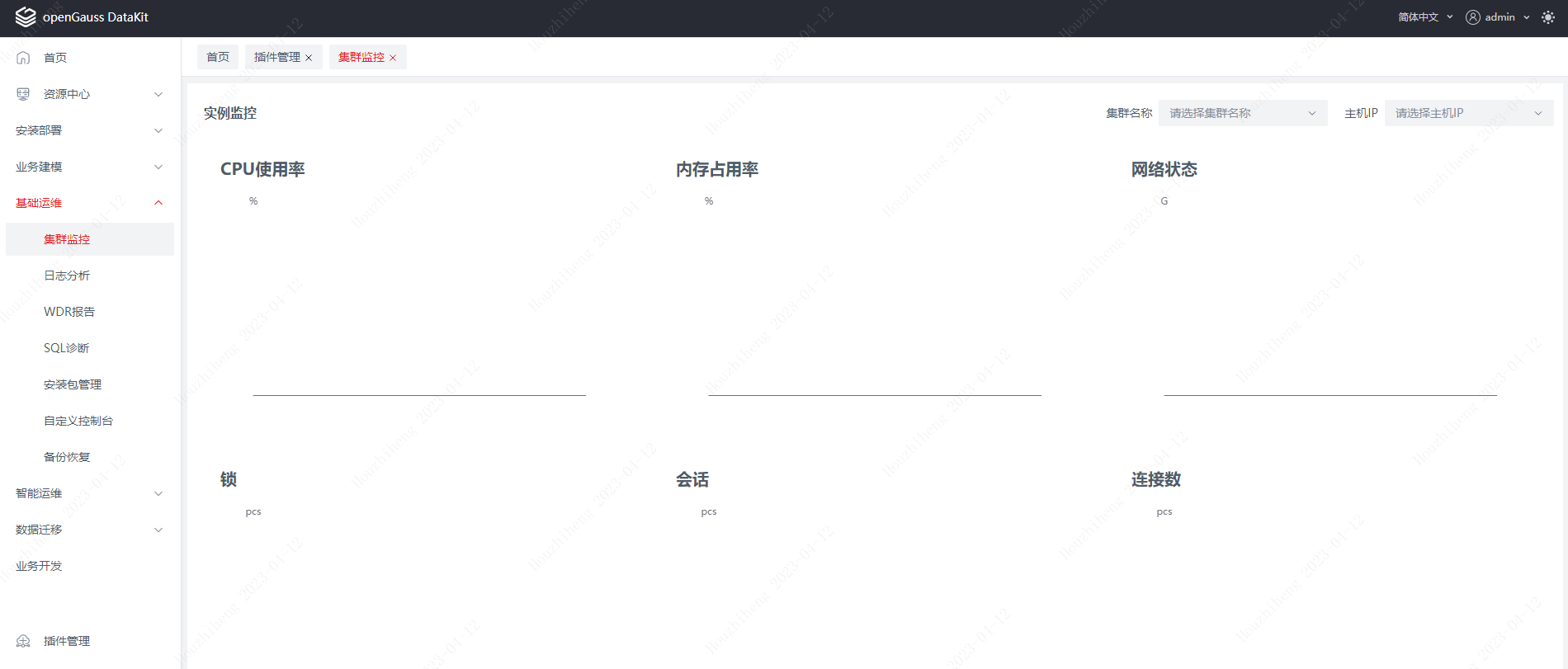
三、安装部署
部署环境:redhat7,opengauss3.0.3,Datakit5.0
1.上传压缩包
# 此时如果没有/ops/server/openGauss-visualtool目录,可以临时手动创建,也可以把这一步在初始化环境中进行解压
[root@test01 tmp]# tar -xvf Datakit-5.0.0.tar.gz -C /ops/server/openGauss-visualtool
jdk手动安装
workbench-master有启动和初始化的脚本可以拿来用
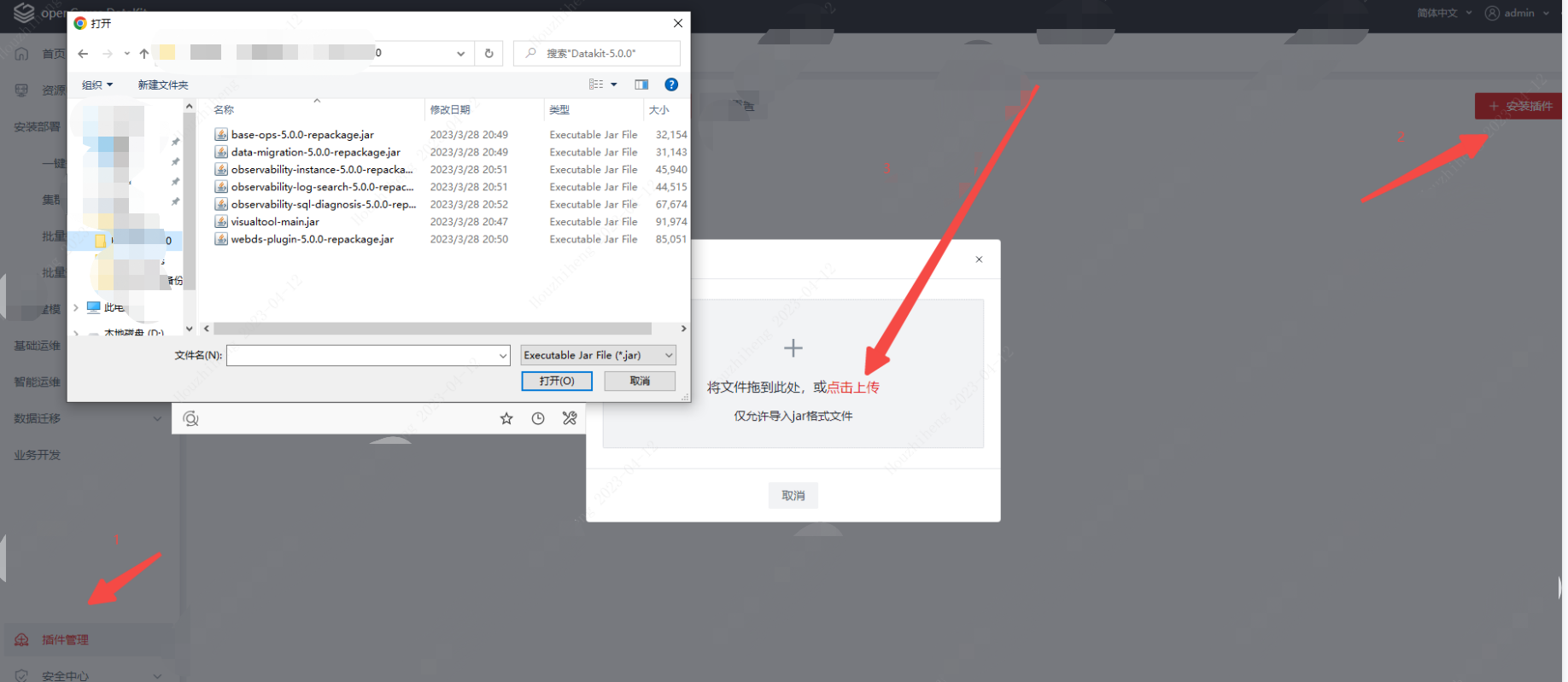
datakit除了visualtool-main.jar 放在/ops/server/openGauss-visualtool目录中,其余几个打包好的插件需要放在/ops/server/openGauss-visualtool/visualtool-plugin/ 目录中
2.更新jdk版本,如果需要
# 检查
rpm -qa |grep java
rpm-qa |grep jdk
# 卸载
rpm-qa | grep java | xargs rpm -e --nodeps
rpm-qa | grep jdk | xargs rpm -e --nodeps
# 安装
rpm -ivh jdk-11.0.17_linux-x64_bin.rpm
# 验证
[root@test01 tmp]# java -version
java version "11.0.17" 2022-10-18 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.17+10-LTS-269)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.17+10-LTS-269, mixed mode)
3.创建远程用户
# 创建用户
openGauss=# CREATE USER jack WITH MONADMIN password "xxxxxxxx";
openGauss=# alter user jack sysadmin;
# 写入pg_hba.conf文件
[omm@test01 ~]$ gs_guc set -N all -I all -h "host all jack 192.168.1.0/24 sha256"
4.编辑安装和启动脚本
安装脚本在\openGauss-workbench-master\openGauss-workbench-master\openGauss-visualtool中
使用安装脚本初始化环境,或者使用https://docs.opengauss.org/zh/docs/5.0.0/docs/ToolandCommandReference/DataKit.html文档中初始化环境,安装脚本需要修改一下。如果脚本执行不顺畅,也可以手动跑脚本中的内容,保障目录正常,以及加密文件生成
# 创建ops用户
useradd-m opsvim install.sh
#!/usr/bin/env bash
echo"begin install..."#sh ./uninstall.sh
read-p "Do you want to automatically install dependencies (JDK, maven, node) ? (Press y|Y for Yes, any other key for No)."install_depencyif [ "$install_depency" = "Y" -o "$install_depency" = "y"]; thensh ./install-depency.sh elseecho"Please install the dependencies required by the system by yourself, including openjdk (11), maven (3), and node (16.15.1)."exit1fi
read-p "Please enter the host of openGauss, Please ensure that the current host IP is in the whitelist of openGauss:"hostif [ ! -n "$host"]; then
echo"Host cannot be empty."exit1fi
read-p "Please enter the port of openGauss.:"portif [ ! -n "$port"]; then
echo"Port cannot be empty."exit1fi
read-p "Please enter the database of openGauss.:"databaseif [ ! -n "$database"]; then
echo"Database cannot be empty."exit1fi
read-p "Please enter the username of openGauss.:"usernameif [ ! -n "$username"]; then
echo"Username cannot be empty."exit1fi
stty-echo
read-p "Please enter the password of openGauss.:"passwordif [ ! -n "$password"]; then
echo"Password cannot be empty."exit1fi
stty echo
echo"host: $host, port: $port username: $username database: $database"cp config/application-temp.yml config/application-cus.yml
sed-i "23s/ip:port/$host:$port/" config/application-cus.yml
sed-i "23s/database/$database/" config/application-cus.yml
sed-i "24s/dbuser/$username/" config/application-cus.yml
sed-i "25s/dbpassword/$password/" config/application-cus.yml
#mvn clean install-P prod -Dmaven.test.skip=truemkdir-p /ops/server/openGauss-visualtool/mkdir-p /ops/files/mkdir-p /ops/server/openGauss-visualtool/logs/mkdir-p /ops/server/openGauss-visualtool/config/mkdir-p /ops/ssl/ if [ ! -f "/ops/ssl/keystore.p12"];then
keytool-genkey -noprompt \-dname "CN=opengauss, OU=opengauss, O=opengauss, L=Beijing, S=Beijing, C=CN"\-alias opengauss\-storetype PKCS12 \-keyalg RSA \-keysize 2048\-keystore /ops/ssl/keystore.p12 \-validity 3650\-storepass 123456fi
echo"SSL is enabled, you can replace the keystore file at /ops/ssl/ folder and config the ssl options at file /ops/server/openGauss-visualtool/config/application-cus.yml"touch/ops/server/openGauss-visualtool/logs/visualtool-main.outcp visualtool-api/target/visualtool-main.jar /ops/server/openGauss-visualtool/mv config/application-cus.yml /ops/server/openGauss-visualtool/config/chown-R ops:ops /ops
echo"end install"
编辑启动脚本
#!/usr/bin/env bash
SERVER_HOME=/ops/server/openGauss-visualtool
cd $SERVER_HOME
API_NAME=visualtool-main
JAR_NAME=$SERVER_HOME/$API_NAME\.jar
LOG=$SERVER_HOME/logs/$API_NAME\.outPID=$SERVER_HOME/$API_NAME\.pid
usage() {
echo"Usage: sh server.sh [start|stop|restart|status]"exit1}
is_exist(){
pid=`ps -ef|grep $JAR_NAME|grep -v grep|awk '{print $2}'`if [ -z "${pid}"]; thenreturn 1 else return 0fi
}
start(){
is_existif [ $? -eq "0"]; then
echo">>> ${JAR_NAME} is already running PID=${pid} <<<" elseecho'' >$LOG
nohupjava -Xms2048m -Xmx4096m -jar $JAR_NAME --spring.profiles.active=cus >$LOG 2>&1 &echo $! >$PID
echo">>> start $JAR_NAME successed PID=$! <<<"fi
}
stop(){
pidf=$(cat $PID)
echo">>> ${API_NAME} PID = $pidf begin kill $pidf <<<"kill $pidf
rm-rf $PID
sleep2is_existif [ $? -eq "0"]; then
echo">>> ${API_NAME} 2 PID = $pid begin kill -9 $pid <<<"kill-9$pid
sleep2echo">>> $JAR_NAME process stopped <<<" elseecho">>> ${JAR_NAME} is not running <<<"fi
}
status(){
is_existif [ $? -eq "0"]; then
echo">>> ${JAR_NAME} is running PID is ${pid} <<<" elseecho">>> ${JAR_NAME} is not running <<<"fi
}
restart(){
stop
start
}case "$1" in "start")
start
;;"stop")
stop
;;"status")
status
;;"restart")
restart
;;*)
usage
;;
esac
exit0}
5.初始化环境
[root@test01 openGauss-visualtool]# mv application-temp.yml ./config/[root@test01 openGauss-visualtool]# ./install.sh
begin install...
sh: ./uninstall.sh: No such file or directory
Do you want to automatically install dependencies (JDK, maven, node)? (Press y|Y for Yes, any other key forNo). Y
sh: ./install-depency.sh: No such file or directory
Please enter the host of openGauss, Please ensure that the current host IPis in the whitelist of openGauss: 10.83.239.211Please enter the port of openGauss.:26000Please enter the database of openGauss.: postgres
Please enter the username of openGauss.: jack
Please enter the password of openGauss.: host:192.168.163.21, port: 26000username: jack database: postgres
SSLis enabled, you can replace the keystore file at /ops/ssl/ folder and config the ssl options at file /ops/server/openGauss-visualtool/config/application-cus.yml
cp: cannot stat ‘visualtool-api/target/visualtool-main.jar’: No such file or directory
mv: ‘config/application-cus.yml’ and ‘/ops/server/openGauss-visualtool/config/application-cus.yml’ are the same file
end install
[root@hktestmysqldb01 openGauss-visualtool]# ll config/total8 -rw------- 1 ops ops 873 Apr 11 16:42 application-cus.yml-rw-r--r-- 1 ops ops 865 Mar 28 20:47 application-temp.yml
[root@hktestmysqldb01 openGauss-visualtool]# pwd/ops/server/openGauss-visualtool
6. 启动服务
# 把模板移动到插件目录下。也可以后期启动好平台后手动补入插件
[ops@test01 openGauss-visualtool]$ mkdir -p /ops/server/openGauss-visualtool/visualtool-plugin
[ops@test01 openGauss-visualtool]$ mv base-ops-5.0.0-repackage.jar ./visualtool-plugin/[ops@test01 openGauss-visualtool]$ mv data-migration-5.0.0-repackage.jar ./visualtool-plugin/[ops@test01 openGauss-visualtool]$ mv observability-instance-5.0.0-repackage.jar ./visualtool-plugin/[ops@test01 openGauss-visualtool]$ mv observability-log-search-5.0.0-repackage.jar ./visualtool-plugin/[ops@test01 openGauss-visualtool]$ mv observability-sql-diagnosis-5.0.0-repackage.jar ./visualtool-plugin/[ops@test01 openGauss-visualtool]$ mv webds-plugin-5.0.0-repackage.jar ./visualtool-plugin/# ./server.sh start/stop/restart
[ops@test01 openGauss-visualtool]$ ./server.sh restart>>> visualtool-main PID = 45148 begin kill 45148 <<< >>> /ops/server/openGauss-visualtool/visualtool-main.jar is not running <<< >>> start /ops/server/openGauss-visualtool/visualtool-main.jar successed PID=46530 <<<
7.检查是否启动成功
/ops/server/openGauss-visualtool/logs/visualtool-main.out 会记录实时日志
[root@test01 ~]# netstat -ntpl | grep 9494tcp0 0 0.0.0.0:9494 0.0.0.0:* LISTEN 46530/java
前台访问链接:https://192.168.163.21:9494/
插件管理,如果没有做第6部在服务器上移动插件,也可以在前台手动导入一次