Java语言在Spark3.2.4集群中使用Spark MLlib库完成朴素贝叶斯分类器
一、贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率,生活中,我们可能很容易知道P(A|B),但是我需要求解P(B|A),学习了贝叶斯定理,就可以解决这类问题,计算公式如下:
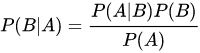
- P(A)是A的先验概率
- P(B)是B的先验概率
- P(A|B)是A的后验概率(已经知道B发生过了)
- P(B|A)是B的后验概率(已经知道A发生过了)
二、朴素贝叶斯分类
朴素贝叶斯的思想是,对于给出的待分类项,求解在此项出现的条件下,各个类别出现的概率,哪个最大,那么就是那个分类。
是一个待分类的数据,有m个特征
是类别,计算每个类别出现的先验概率
- 在各个类别下,每个特征属性的条件概率计算
- 计算每个分类器的概率
- 概率最大的分类器就是样本
的分类
三、java样例代码开发步骤
首先,需要在pom.xml文件中添加以下依赖项:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.12</artifactId> <version>3.2.0</version> </dependency>
然后,在Java代码中,可以执行以下步骤来实现朴素贝叶斯算法:
1、创建一个SparkSession对象,如下所示:
importorg.apache.spark.sql.SparkSession;
SparkSession spark=SparkSession.builder()
.appName("NaiveBayesExample")
.master("local[*]")
.getOrCreate();
2、加载训练数据和测试数据:
importorg.apache.spark.ml.feature.LabeledPoint;importorg.apache.spark.ml.linalg.Vectors;importorg.apache.spark.sql.Dataset;importorg.apache.spark.sql.Row;importorg.apache.spark.sql.types.DataTypes;import static org.apache.spark.sql.functions.*;//读取训练数据 Dataset<Row> trainingData =spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/training_data.csv");//将训练数据转换为LabeledPoint格式 Dataset<LabeledPoint> trainingLP =trainingData
.select(col("label"), col("features"))
.map(row-> newLabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class));//读取测试数据 Dataset<Row> testData =spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/test_data.csv");//将测试数据转换为LabeledPoint格式 Dataset<LabeledPoint> testLP =testData
.select(col("label"), col("features"))
.map(row-> newLabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class));
请确保训练数据和测试数据均包含
"label"
和
"features"
两列,其中
"label"
是标签列,
"features"
是特征列。
3、创建一个朴素贝叶斯分类器:
importorg.apache.spark.ml.classification.NaiveBayes;importorg.apache.spark.ml.classification.NaiveBayesModel;
NaiveBayes nb= newNaiveBayes()
.setSmoothing(1.0) //设置平滑参数 .setModelType("multinomial"); //设置模型类型 NaiveBayesModel model= nb.fit(trainingLP); //拟合模型
在这里,我们创建了一个NaiveBayes对象,并设置了平滑参数和模型类型。然后,我们使用
fit()
方法将模型拟合到训练数据上。
4、使用模型进行预测:
Dataset<Row> predictions =model.transform(testLP);//查看前10条预测结果 predictions.show(10);
在这里,我们使用
transform()
方法对测试数据进行预测,并将结果存储在一个DataFrame中。可以通过调用
show()
方法查看前10条预测结果。
5、关闭SparkSession:
spark.close();
以下是完整代码的示例。请注意,需要替换数据文件的路径以匹配您的实际文件路径:
importorg.apache.spark.ml.classification.NaiveBayes;importorg.apache.spark.ml.classification.NaiveBayesModel;importorg.apache.spark.ml.feature.LabeledPoint;importorg.apache.spark.ml.linalg.Vectors;importorg.apache.spark.sql.Dataset;importorg.apache.spark.sql.Row;importorg.apache.spark.sql.SparkSession;importorg.apache.spark.sql.Encoders;import static org.apache.spark.sql.functions.*;public classNaiveBayesExample {public static voidmain(String[] args) {//创建SparkSession对象 SparkSession spark =SparkSession.builder()
.appName("NaiveBayesExample")
.master("local[*]")
.getOrCreate();try{//读取很抱歉,我刚才的回答被意外截断了。以下是完整的Java代码示例: ```javaimportorg.apache.spark.ml.classification.NaiveBayes;importorg.apache.spark.ml.classification.NaiveBayesModel;importorg.apache.spark.ml.feature.LabeledPoint;importorg.apache.spark.ml.linalg.Vectors;importorg.apache.spark.sql.Dataset;importorg.apache.spark.sql.Row;importorg.apache.spark.sql.SparkSession;importorg.apache.spark.sql.Encoders;import static org.apache.spark.sql.functions.*;public classNaiveBayesExample {public static voidmain(String[] args) {//创建SparkSession对象 SparkSession spark =SparkSession.builder()
.appName("NaiveBayesExample")
.master("local[*]")
.getOrCreate();try{//读取训练数据 Dataset<Row> trainingData =spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/training_data.csv");//将训练数据转换为LabeledPoint格式 Dataset<LabeledPoint> trainingLP =trainingData
.select(col("label"), col("features"))
.map(row-> newLabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class));//读取测试数据 Dataset<Row> testData =spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/test_data.csv");//将测试数据转换为LabeledPoint格式 Dataset<LabeledPoint> testLP =testData
.select(col("label"), col("features"))
.map(row-> newLabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class));//创建朴素贝叶斯分类器 NaiveBayes nb = newNaiveBayes()
.setSmoothing(1.0)
.setModelType("multinomial");//拟合模型 NaiveBayesModel model =nb.fit(trainingLP);//进行预测 Dataset<Row> predictions =model.transform(testLP);//查看前10条预测结果 predictions.show(10);
}finally{//关闭SparkSession spark.close();
}
}
}