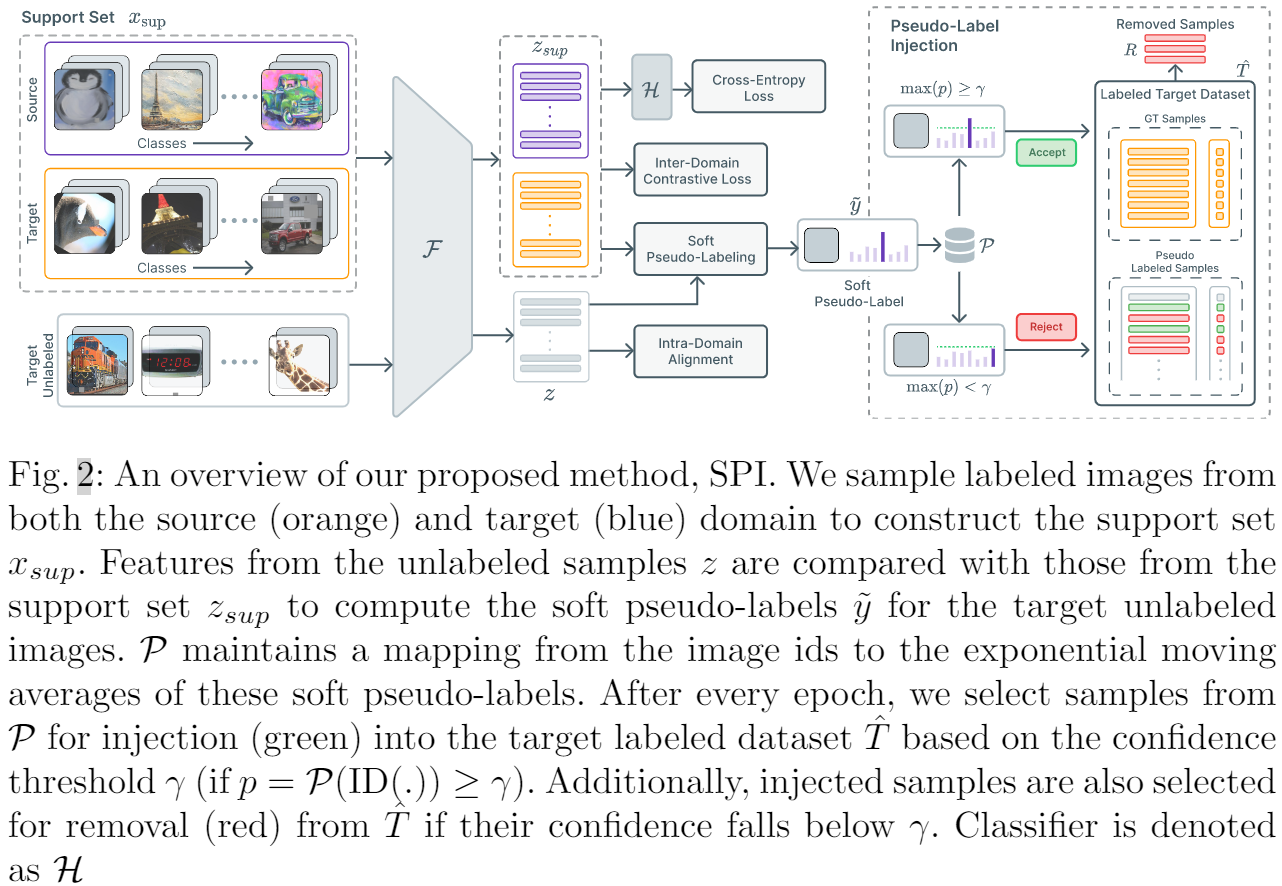
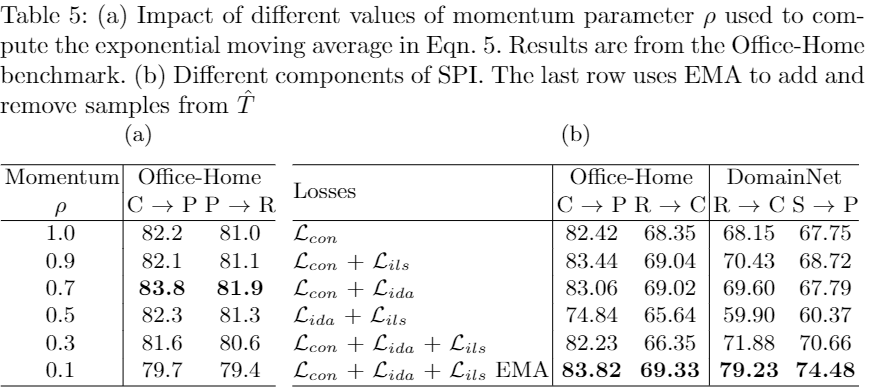
Android HAL机制的深入理解及在Linux上移植和运行的一个好玩的HAL小例子
PS:要转载请注明出处,本人版权所有。
PS: 这个只是基于《我自己》的理解,
如果和你的原则及想法相冲突,请谅解,勿喷。
环境说明
Ubuntu 18.04.x
前言
近一年来,虽然还是做的是AIOT相关的事情,但是某些事情却发生了一些变化。随着个人的阅历提升,现在的AI在边缘端部署已经不局限于传统的linux这样的形态,这一年来,我已经逐渐接触到android的边缘端盒子这样的概念了。
对于Android来说,我之前有所了解,但是停留的非常表面,只知道其是一个Linux内核+Android Runtime+app的这样的形态。但是如果我们将Android Runtime和App看作普通的Linux app,那么我们会发现Android和传统Linux的差别没有那么大,我们甚至可以将Android当成一个Linux发行版来使用。但是实际在使用过程中,最大的差异在于Android引入了许多的Android特有的内容,例如binder,log,adb等等,其次和linux下面编程的最大区别还是在于他们的基础c库不一样,一个是bonic c,一个的glibc,这一点可以说是贯穿我在使用Android的整个过程中。
在使用Android的过程中,我们会听见一个HAL的词,整个HAL可以说是Android能够成功商业化的一个重要因素,因为其可以保护各个厂商的利益,然后反过来,正是由于各个厂家的支持,导致了Android的生态是非常丰富的。那么我们来看看这个HAL到底是干嘛的。
由于网上有许多介绍HAL的文章了,本文不会重复一些基础的内容,因此本文后续的阅读需要读者至少对Linux和Android HAL有一个基础的了解后,才建议阅读本文。
HAL 深入分析
首先Android HAL分为大概分为两个版本,一个新的和旧的,本文重点分析新版HAL原理。其中两种版本架构大概简介如下:
- 旧的HAL架构(libhardware_legacy.so)每个app都会加载模块,有重入问题,由于每个app直接加载对应的so,也导致app和模块接口耦合较大,非常不方便维护。
- 新的HAL架构module/stub,app访问对应硬件对应的服务,然后对应硬件服务通过抽象api,module id,设备id,代理后访问硬件。
上面对新的架构说的还是有些表面了,下面我们深入分析其中的重要的几个结构(在hardware.h中),然后最后通过一个实际例子来深入理解它。
struct hw_module_t
它的实际源码定义如下:
/**
* Every hardware module must have a data structure named HAL_MODULE_INFO_SYM
* and the fields of this data structure must begin with hw_module_t
* followed by module specific information.
*/
typedef struct hw_module_t {
/** tag must be initialized to HARDWARE_MODULE_TAG */
uint32_t tag;
/**
* The API version of the implemented module. The module owner is
* responsible for updating the version when a module interface has
* changed.
*
* The derived modules such as gralloc and audio own and manage this field.
* The module user must interpret the version field to decide whether or
* not to inter-operate with the supplied module implementation.
* For example, SurfaceFlinger is responsible for making sure that
* it knows how to manage different versions of the gralloc-module API,
* and AudioFlinger must know how to do the same for audio-module API.
*
* The module API version should include a major and a minor component.
* For example, version 1.0 could be represented as 0x0100. This format
* implies that versions 0x0100-0x01ff are all API-compatible.
*
* In the future, libhardware will expose a hw_get_module_version()
* (or equivalent) function that will take minimum/maximum supported
* versions as arguments and would be able to reject modules with
* versions outside of the supplied range.
*/
uint16_t module_api_version;
#define version_major module_api_version
/**
* version_major/version_minor defines are supplied here for temporary
* source code compatibility. They will be removed in the next version.
* ALL clients must convert to the new version format.
*/
/**
* The API version of the HAL module interface. This is meant to
* version the hw_module_t, hw_module_methods_t, and hw_device_t
* structures and definitions.
*
* The HAL interface owns this field. Module users/implementations
* must NOT rely on this value for version information.
*
* Presently, 0 is the only valid value.
*/
uint16_t hal_api_version;
#define version_minor hal_api_version
/** Identifier of module */
const char *id;
/** Name of this module */
const char *name;
/** Author/owner/implementor of the module */
const char *author;
/** Modules methods */
struct hw_module_methods_t* methods;
/** module's dso */
void* dso;
#ifdef __LP64__
uint64_t reserved[32-7];
#else
/** padding to 128 bytes, reserved for future use */
uint32_t reserved[32-7];
#endif
} hw_module_t;
一个hw_module_t代表一个硬件模块,但是一个硬件模块可能包含了很多的硬件设备,所以我们要操作一个实际的硬件设备,按照这套框架,第一件事获取模块,第二件事就是打开设备,第三操作设备,第四关闭设备。
其实这里的注释说的很清楚,使用它,有两个注意事项,一是必须要在实际模块中定义一个HAL_MODULE_INFO_SYM的结构体变量,且此结构体必须是struct hw_module_t 作为第一个成员变量。这里的根本原因是因为c的结构体内存布局和暴露这个结构体的名字,后面会详细说这个事情。
struct hw_module_methods_t
它的实际源码定义如下:
typedef struct hw_module_methods_t {
/** Open a specific device */
int (*open)(const struct hw_module_t* module, const char* id,
struct hw_device_t** device);
} hw_module_methods_t;
此结构体没啥可说的,就是通过实际的模块,然后传入一个硬件设备的id,然后打开实际的硬件设备。因此在每个实际的hw_module_t中,都包含了一个hw_module_methods_t,然后有打开设备的操作。这里也体现出来了一个模块可以有多个设备的这种概念。
struct hw_device_t
它的实际源码定义如下:
/**
* Every device data structure must begin with hw_device_t
* followed by module specific public methods and attributes.
*/
typedef struct hw_device_t {
/** tag must be initialized to HARDWARE_DEVICE_TAG */
uint32_t tag;
/**
* Version of the module-specific device API. This value is used by
* the derived-module user to manage different device implementations.
*
* The module user is responsible for checking the module_api_version
* and device version fields to ensure that the user is capable of
* communicating with the specific module implementation.
*
* One module can support multiple devices with different versions. This
* can be useful when a device interface changes in an incompatible way
* but it is still necessary to support older implementations at the same
* time. One such example is the Camera 2.0 API.
*
* This field is interpreted by the module user and is ignored by the
* HAL interface itself.
*/
uint32_t version;
/** reference to the module this device belongs to */
struct hw_module_t* module;
/** padding reserved for future use */
#ifdef __LP64__
uint64_t reserved[12];
#else
uint32_t reserved[12];
#endif
/** Close this device */
int (*close)(struct hw_device_t* device);
} hw_device_t;
此结构体就是上文我们说的实际打开的设备结构体,一般情况我们会将此结构体暴露到对应hal的头文件中,因为这个包含了实际操作硬件的一些接口信息。注意这个hw_device_t包含了一个close接口,是每个设备的关闭接口。
注意,我们这个时候没有去说hardware.c所做的事情,也就是如下两个接口到底做了什么,这个问题的解答,我们留到下一小节例子中去深入认识他。
/**
* Get the module info associated with a module by id.
*
* @return: 0 == success, <0 == error and *module == NULL
*/
int hw_get_module(const char *id, const struct hw_module_t **module);
/**
* Get the module info associated with a module instance by class 'class_id'
* and instance 'inst'.
*
* Some modules types necessitate multiple instances. For example audio supports
* multiple concurrent interfaces and thus 'audio' is the module class
* and 'primary' or 'a2dp' are module interfaces. This implies that the files
* providing these modules would be named audio.primary.<variant>.so and
* audio.a2dp.<variant>.so
*
* @return: 0 == success, <0 == error and *module == NULL
*/
int hw_get_module_by_class(const char *class_id, const char *inst,
const struct hw_module_t **module);
一个MY_HW的硬件模块的HAL例子
如上,我们已经介绍了hal里面的重要的3个结构体,但是如果就到此的话,其实我们对hal还是一知半解,这个时候,我们可以尝试自己虚拟一个硬件出来,然后设计HAL接口。这样可以实际体会HAL的工作原理。
首先,我们定义我们的模块叫做MY_HW。
下面是自定义的hal模块源码
my_hw_hal.h 源码
#ifndef __MY_HW_HAL_H__
#define __MY_HW_HAL_H__
#include "hardware.h"
#define MY_HW_MODULE_ID "MY_HW"
struct my_hw_device_t{
struct hw_device_t base;
int (*set_my_hw_op)(struct my_hw_device_t * dev, int op_type);
};
#endif //__MY_HW_HAL_H__
my_hw_hal.c 源码
#include "my_hw_hal.h"
#include <stdio.h>
#include <string.h>
int my_hw_open(const struct hw_module_t* module, const char* id,
struct hw_device_t** device);
int set_my_hw_op_device_0 (struct my_hw_device_t * dev, int op_type);
int my_hw_close_device_0(struct hw_device_t* device);
//For hw_moudle_methods_t
static struct hw_module_methods_t my_hw_methods = {
.open = my_hw_open,
};
//For hw_module_t
struct my_hw_module_t {
struct hw_module_t base;
};
__attribute__((visibility("default"))) struct my_hw_module_t HAL_MODULE_INFO_SYM = {
.base = {
.tag = HARDWARE_MODULE_TAG,
.module_api_version = 0,
.hal_api_version = 0,
.id = MY_HW_MODULE_ID,
.name = "MY HW MODULE",
.author = "Sky",
.methods = &my_hw_methods
}
};
//For hw_device_t
static struct my_hw_device_t my_hw_device_0 = {
.base = {
.tag = HARDWARE_DEVICE_TAG,
.version = 0,
.module = (hw_module_t*)&HAL_MODULE_INFO_SYM,
.close = my_hw_close_device_0
},
.set_my_hw_op = set_my_hw_op_device_0
};
//For hw_device_t
int set_my_hw_op_device_0 (struct my_hw_device_t * dev, int op_type)
{
printf("set_my_hw_op_device_0() op_type = %d\n", op_type);
return 0;
}
int my_hw_close_device_0(struct hw_device_t* device)
{
printf("my_hw_close_device_0()\n");
return 0;
}
//For hw_moudle_methods_t
int my_hw_open(const struct hw_module_t* module, const char* id,
struct hw_device_t** device)
{
printf("my_hw_open() device id %s\n", id);
if (strcmp(id, "0") != 0){
printf("my_hw_open() failed\n");
return -1;
}
*device = (struct hw_device_t*)&my_hw_device_0;
return 0;
}
从这里我们可以看出,新模块的实现就是对3个结构体的继承和实现。同时对一些成员变量进行赋值。
MY_HW模块源码的分析
__attribute__((visibility("default"))) struct my_hw_module_t HAL_MODULE_INFO_SYM = {
.base = {
.tag = HARDWARE_MODULE_TAG,
.module_api_version = 0,
.hal_api_version = 0,
.id = MY_HW_MODULE_ID,
.name = "MY HW MODULE",
.author = "Sky",
.methods = &my_hw_methods
}
};
my_hw_module_t 的定义,就是定义一个HAL_MODULE_INFO_SYM(它是一个宏定义)变量,注意此宏定义会被替换为一个HMI的名字,此名字是所有HAL模块必须暴露的一个符号。且必须叫做这个名字,因为这是libhardware.so中读取它的约定。
此外,hw_module_t必须在我定义的变量的开始位置,这样方便类型转换。
//For hw_moudle_methods_t
static struct hw_module_methods_t my_hw_methods = {
.open = my_hw_open,
};
hw_module_methods_t 的定义,实现一个真正的设备打开接口。
//For hw_device_t
static struct my_hw_device_t my_hw_device_0 = {
.base = {
.tag = HARDWARE_DEVICE_TAG,
.version = 0,
.module = (hw_module_t*)&HAL_MODULE_INFO_SYM,
.close = my_hw_close_device_0
},
.set_my_hw_op = set_my_hw_op_device_0
};
my_hw_device_t的定义,此设备就是我们这个模块定义的一个设备,此设备通过my_hw_module_t中的open接口打开,然后提供相关的接口给HAL相关的程序使用。
综合分析
这里我们简单设计一个服务程序来调用我们封装的hal模块,其流程就是调用hw_get_module获取实际module地址,然后通过module打开对应设备,然后操作设备,最后关闭设备。
#include "my_hw_hal.h"
int main(int argc, char * argv[])
{
hw_module_t * hwmodule = nullptr;
my_hw_device_t * my_hw_device = nullptr;
int _ret = hw_get_module(MY_HW_MODULE_ID, (const hw_module_t**)&hwmodule);
#define MY_HW_DEVICE_ID "0"
_ret = hwmodule->methods->open(hwmodule, MY_HW_DEVICE_ID, (hw_device_t**)&my_hw_device);
#define MY_HW_DEVICE_ID_0_OP_TYPE_0 0
my_hw_device->set_my_hw_op(my_hw_device, MY_HW_DEVICE_ID_0_OP_TYPE_0);
my_hw_device->base.close((hw_device_t*)my_hw_device);
return 0;
}
然后通过如下编译脚本生成两个so和一个应用程序。
#!/bin/bash
# for hardware so
gcc -fPIC -c hardware.c -I . -fvisibility=hidden
gcc -shared hardware.o -o libhardware.so -ldl -fvisibility=hidden
strip libhardware.so
# for MY_HW.sky-sdk.so
gcc -fPIC -c my_hw_hal.c -I . -fvisibility=hidden
gcc -shared my_hw_hal.o -o MY_HW.sky-sdk.so -fvisibility=hidden
strip MY_HW.sky-sdk.so
# for my hw service
g++ my_hw_service.cpp -o my_hw_service -L . -l hardware -I . -fvisibility=hidden
我们先来看看我们应用程序执行的结果如下:

我们可以看到,第一步通过hw_get_module获取到一个模块信息,这里其实在hardware.c里面定义的很清楚,直接通过dlopen/dlsym 一个HMI的符号得到了我们定义的my_hw_module_t的变量地址,由于c的内存布局的原因,本来这个地址存放的是my_hw_module_t变量,但是可以直接强转为hw_module_t变量。简单来说,这就是一种c里面实现类似c++继承的方法,由于内存布局是连续的,根据hw_module_t的大小,可以直接从my_hw_module_t前面部分转换为hw_module_t。这也是hw_module_t必须放在my_hw_module_t中开始的原因。
我们也可知道,在hardware.c中,hw_get_module是根据id来在特定目录中去搜索相关的模块so,然后通过dlopen打开它并进行后续的操作。如我修改的hardware.c部分节选:

同理,到了这里,我们不用猜测,一定在MY_HW.sky-sdk.so暴露了一个HMI的符号。如图:

注意hardware.c和hardware.h直接从android源码中拿出来,简单做修改即可在linux里面编译。这里我们简单看看libhardware.so的符号暴露信息:

这里其实就暴露了上面提到的两个接口,hw_get_module和hw_get_module_by_class。
后记
总的来说:
- hw_module_methods_t 可以用来标识模块的公用方法,当前具备了一个open方法,注意一个module对应多个设备功能。
- hw_get_module() 主要是使用传入的id,然后通过id和一些属性通过dlopen加载so。注意'HMI'这个符号,这个符号是存放的hw_module_t作为基类的地址。通过此地址可以打开这个模块中的特有设备,并提供特定操作。
- hw_module_t 可以用来标识一个模块,首先通过hw_get_module()获取当前hw_module_t,然后通过当前hw_module_t的hw_module_methods_t中的open方法打开设备。
- hw_device_t 可以用来标识模块下的一个设备,其中的close方法用来关闭本设备。
注意三个结构体之间的关系:hw_get_module()获取hw_module_t,hw_module_t通过hw_module_methods_t获取hw_device_t,hw_device_t中携带了当前设备的各种操作方法,其实HAL的另一个重要部分是在hw_device_t中定义当前设备的通用接口。
其实HAL的整个原理并不复杂,在Linux内核源码中,你会看到大量的类似的操作。归根到底,其实HAL的这种封装,就是一种应用技巧。
参考文献
- 无

PS: 请尊重原创,不喜勿喷。
PS: 要转载请注明出处,本人版权所有。
PS: 有问题请留言,看到后我会第一时间回复。