迁移学习(SPI)《Semi-Supervised Domain Adaptation by Similarity based Pseudo-label Injection》
论文信息
论文标题:Semi-Supervised Domain Adaptation by Similarity based Pseudo-label Injection
论文作者:
Abhay Rawat
,
Isha Dua
,
Saurav Gupta
,
Rahul Tallamraju
论文来源:Published in ECCV Workshops 5 September 2022
论文地址:
download
论文代码:
download
视屏讲解:click
1 摘要
挑战:半监督域适应 (SSDA) 的主要挑战之一是标记的源样本和目标样本数量之间的比例偏差,导致模型偏向源域;
问题:SSDA 最近的工作表明,仅将标记的目标样本与源样本对齐可能会导致目标域与源域的域对齐不完整;
2 介绍
无监督域适应的基本假设是,学习到域不可知特征空间的映射,以及在源域上表现足够好的分类器,可以泛化到目标域。 然而,最近的研究 [20,42,46,7] 表明,这些条件不足以实现成功的域适应,
甚至可能由于两个域的边缘标签分布之间的差异而损害泛化
。
半监督学习 (SSL) [1,36,3,45] 已被证明在每个注释的性能方面非常高效,因此提供了一种更经济的方式来训练深度学习模型。 然而,一般来说,UDA 方法在半监督环境中表现不佳,在半监督环境中我们可以访问目标域中的一些标记样本 [31]。 半监督域适应 (SSDA) [35,21,19],利用目标域中的少量标记样本来帮助学习目标域上具有低错误率的模型。 然而,如 [19] 所示,简单地将标记的目标样本与标记的源样本对齐会导致目标域中的域内差异。 在训练期间,标记的目标样本被拉向相应的源样本簇。然而,未标记的样本与标记目标样本的较小相关性被抛在后面。这是因为标记源样本的数量支配标记目标样本的数量,导致标签分布偏斜。 这导致在目标域的同一类中进行子分布。 为了减轻来自源域和目标域的标记样本之间的这种偏差比率,最近的方法 [17,40] 将伪标签分配给未标记的数据。 但是,这些伪标签可能存在噪声,可能导致对目标域的泛化效果不佳。
在本文中,我们提出了一种简单而有效的方法来缓解 SSDA 面临的上述挑战。 为了对齐来自两个域的监督样本,我们利用对比损失来学习语义有意义和域不变的特征空间。 为了解决域内差异问题,我们通过将未标记目标样本的特征表示与标记样本的特征表示进行比较来计算未标记目标样本的软伪标签。 然而,与标记样本相关性较低的样本可能会有噪声和不正确的伪标签。 因此,我们根据模型对各个伪标签的置信度,在整个训练过程中逐渐将伪标记样本注入(或从)标记目标数据集中(或从中移除)。
3 方法
整体框架:
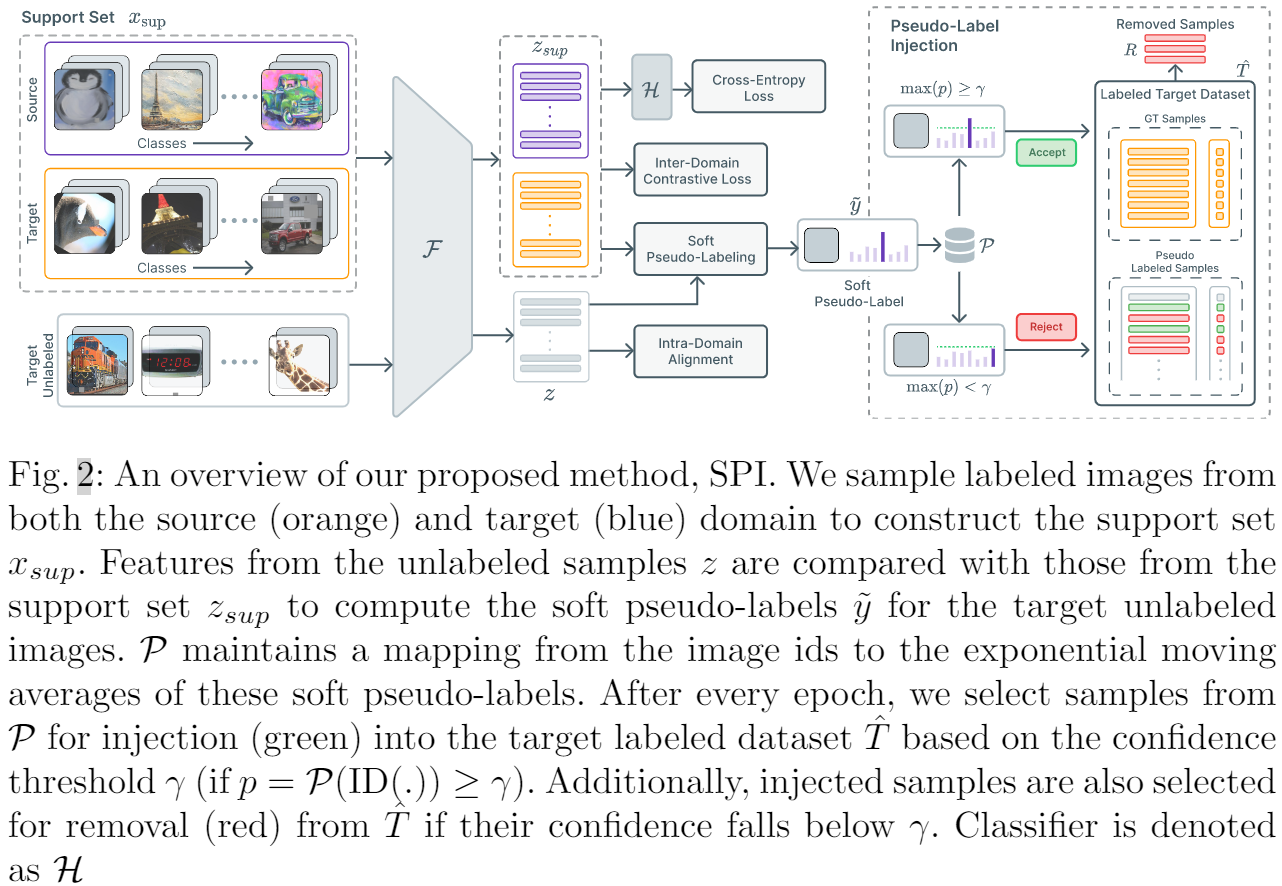
Support set:
基于小批量,源域、目标域标记样本每个类包含 $\eta_{\text {sup }}$ 个样本,所以支持集包含来自两个域的 $\eta_{\text {sup }} C$ 个样本,总共 2 个 $\eta_{\text {sup }} C$ 个样本。
3.1 域间特征对齐
直接地利用对比损失,通过明确地将相同类别的样本视为正样本,而不管领域如何。 然后训练特征提取器通过最大化同一类特征之间的相似性来最小化 $\mathcal{L}_{\text {con }}$。
$\mathcal{L}_{\text {con }}=\sum_{i \in A} \frac{-1}{\left|P_{i}\right|} \sum_{p \in P_{i}} \log \frac{\exp \left(z_{i} \cdot z_{p} / \tau\right)}{\sum_{a \in A \backslash i} \exp \left(z_{a} \cdot z_{p} / \tau\right)} \quad\quad\quad(1)$
Note
:支撑集之间;
3.2 伪标签注入
然而,正如 [19] 中指出的那样,对齐来自源域和目标域的标记样本可能会导致目标域中的子分布。 即,与目标域中标记样本相关性较低的未标记样本不会受到对比损失的影响。 这会导致域内差异,从而导致性能不佳。 为缓解这个问题,本文考虑将未标记的样本注入标记的目标数据集 ^ T,从而有效地增加目标域中标记样本的支持。 我们将更详细地讨论这种方法。 3.2.
为了减少域内差异,我们建议将未标记目标数据集 $T$ 中的样本注入标记目标数据集 $\hat{T}$。 使用支持集,首先计算未标记样本的软伪标签。在整个训练过程中,我们为未标记的目标数据集 $T$ 中的每个样本保留锐化软伪标签的指数移动平均值。 这个移动平均值估计了我们的模型对每个未标记样本的预测的置信度。 使用这个估计,我们将高度置信的样本注入到标记的目标数据集 $\hat{T}$ 中,并且在每个时期之后将它们各自的标签设置为主导类。
为了计算来自目标域的未标记样本的软伪标签,我们从 PAWS [1] 中获得灵感,这是一项半监督学习的最新工作,并将其扩展到 SSDA 设置。 我们将支持集 $\mathcal{x}_{sup} $ 及其各自的标签表示为 $y_{sup}$。 设 $z_{sup}$ 是支持集 $\mathcal{x}_{sup} $ 中样本的归一化特征表示,$\hat{z}_{i}\left(=z_{i} /\left\|z_{i}\right\|\right)$ 表示未标记样本 $x_i$ 的归一化特征表示。 然后,可以使用以下方法计算第 $i$ 个未标记样本的软伪标签:
$\tilde{y}_{i}=\sigma_{\tau}\left(\hat{z}_{i} \cdot \hat{z}_{\text {sup }}^{\top}\right) y_{\text {sup }}$
其中,$\sigma_{\tau}(\cdot)$ 表示带温度参数 $\tau$ 的 $\text{softmax}$, 然后使用温度 $\tau>0$ 的锐化函数 $\pi$ 对这些软伪标签进行锐化,描述如下:
$\pi(\tilde{y})=\frac{\tilde{y}^{1 / \tau}}{\sum_{j=1}^{C} \tilde{y}_{j}^{1 / \tau}}$
锐化有助于从未标记和标记样本之间的相似性度量中产生自信的预测。
在整个训练过程中,我们保持未标记目标数据集 $T$ 中每个图像的锐化软伪标签的指数移动平均值 (EMA)。 更具体地说,我们维护一个映射 $\mathcal{P}: \mathbb{I} \rightarrow \mathbb{R}^{C}$ 从未标记样本的图像 ID 到它们各自锐化的软伪标签(类概率分布)的运行 EMA。 令 $ID(\cdot)$ 表示一个运算符,它返回与未标记目标数据集 $T$ 中的输入样本对应的图像 $ID$,$\mathcal{P}\left(\operatorname{ID}\left(x_{i}\right)\right)$ 是 $x_i$ 的锐化伪标签的 EMA。 然后,未标记数据集 $T$ 中样本 $x_i$ 的指数移动平均值更新如下:
$\mathcal{P}\left(\mathrm{ID}\left(x_{i}\right)\right) \leftarrow \rho \pi\left(\tilde{y}_{i}\right)+(1-\rho) \mathcal{P}\left(\operatorname{ID}\left(x_{i}\right)\right) \quad\quad(5)$
其中 $\rho$ 表示动量参数。 当在训练过程中第一次遇到一个样本时,$\mathcal{P}\left(\operatorname{ID}\left(x_{i}\right)\right)$ 被设置为 $\pi\left(\tilde{y}_{i}\right)$ 和 $\text{Eq.5}$ 之后使用。
在每个 epoch 之后,我们检查 $\mathcal{P}$ 中每个样本的 EMA(类概率分布)。如果某个特定样本对某个类的置信度超过某个阈值 $\gamma$,我们将该样本及其对应的预测类注入到标记的目标数据集 $\hat{T}$ 中。 我们将考虑用于注射 $I$ 的样本集定义为:
$I_{t} \triangleq\left\{\left(x_{i}, \arg \max \mathcal{P}\left(\operatorname{ID}\left(x_{i}\right)\right) \mid x_{i} \in T \wedge \max \mathcal{P}\left(\operatorname{ID}\left(x_{i}\right)\right) \geq \gamma\right\}\right.\quad\quad\quad(6)$
其中 $t$ 表示当前 $\text{epoch}$。
但是,这些样本可能存在噪音并可能阻碍训练过程; 因此,如果样本的置信度低于阈值 $\gamma$,我们也会从标记的数据集中删除样本。 要从标记目标数据集 $R$ 中删除的样本集定义为:
$R_{t} \triangleq\left\{\left(x_{i}, y_{i}\right) \mid x_{i} \in\left(\hat{T}_{t} \backslash \hat{T}_{0}\right) \wedge \max \mathcal{P}\left(\operatorname{ID}\left(x_{i}\right)\right)<\gamma\right\}$
其中 $y_{i}$ 表示先前分配给方程式中的样本 $x_i$ 的相应伪标签。 请注意,来自标记目标数据集 $\hat{T}_{0}$ 的原始样本永远不会从数据集中删除,因为 $I$ 和 $R$ 都仅包含来自未标记目标数据集 $T$ 的样本。
因此,在每个纪元 $t$ 之后,标记的目标数据集 $T$ 将更新为:
$\hat{T}_{t+1}=\left\{\begin{array}{ll}\left(\hat{T}_{t} \backslash R_{t}\right) \cup I_{t} & \text { if } t \geq W \\\hat{T}_{t} & \text { otherwise }\end{array}\right.$
其中 $W$ 表示标记的目标数据集 $\hat{T}$ 保持不变的预热阶段数。 这些预热时期允许源域和目标域的特征表示在样本被注入标签目标数据集之前在某种程度上对齐。 这可以防止假阳性样本进入 $\hat{T}$,否则会阻碍学习过程。
3.3 实例级相似度
我们现在介绍实例级相似性损失。 受 [1,5] 的启发,我们遵循多视图增强来生成未标记图像的 $ηg = 2$ 全局裁剪和 $ηl$ 局部裁剪。 这种增强方案背后的关键见解是通过明确地使这些不同视图的特征表示更接近来强制模型关注感兴趣的对象。 全局裁剪包含更多关于感兴趣对象的语义信息,而局部裁剪仅包含图像(或对象)的有限视图。 通过计算全局作物和支持集样本之间的特征级相似度,我们使用 $\text{Eq.3}$ 计算未标记样本的伪标签。
然后训练特征提取器以最小化使用一个全局视图生成的伪标签与使用另一个全局视图生成的锐化伪标签之间的交叉熵。 此外,使用局部视图生成的伪标签与来自全局视图的锐化伪标签的平均值之间的交叉熵被添加到损失中。
稍微滥用符号,给定样本 $x_{i}$,我们将 $\tilde{y}_{i}^{g_{1}}$ 和 $\tilde{y}_{i}^{g_{2}}$ 定义为两种全局作物的伪标签,并且 $\tilde{y}_{i}^{l_{j}}$ 表示第 $j$ 个局部作物的伪标签。 类似地,我们遵循相同的符号来为这些由 $\pi$ 表示的作物定义锐化的伪标签。 因此训练特征提取器以最小化以下损失:
$\mathcal{L}_{i l s}=-\sum\limits_{i=1}^{\left|B_{u}\right|}\left(\mathrm{H}\left(\tilde{y}_{i}^{g_{1}}, \pi_{i}^{g_{2}}\right)+\mathrm{H}\left(\tilde{y}_{i}^{g_{2}}, \pi_{i}^{g_{1}}\right)+\sum\limits _{j=1}^{\eta_{l}} \mathrm{H}\left(\tilde{y}_{i}^{l_{j}}, \pi_{i}^{g}\right)\right),$
其中,$\mathrm{H}(\cdot, \cdot)$ 表示交叉熵,$\pi_{i}^{g}=\left(\pi_{i}^{g_{1}}+\pi_{i}^{g_{1}}\right) / 2$,$\left|B_{u}\right|$ 表示未标记样本的数量。
3.4 域内对齐
为了确保来自目标域中同一类的未标记样本在潜在空间中靠得更近,我们使用未标记样本之间的一致性损失。 由于这些样本没有标签,我们计算未标记样本之间的成对特征相似性,以估计它们是否可能属于同一类。 正如[13]所提出的,如果两个样本 $x_i$ 和 $x_j$ 的前 $k$ 个高度激活的特征维度的索引相同,则可以认为它们相似。 令 $top-k (z)$ 表示 $z$ 的前 $k$ 个高度激活的特征维度的索引集,然后,我们认为两个未标记的样本 $i$ 和 $j$ 相似,如果:
$\text { top-k }\left(z_{i}\right) \ominus \text { top- } \mathrm{k}\left(z_{j}\right)=\Phi$
其中,$z_{i}$ 和 $z_{j}$ 是各自的特征表示,$\ominus$ 是对称集差算子。
我们构造一个二元矩阵 $M \in\{0,1\}^{\left|B_{u}\right| \times\left|B_{u}\right|}$ ,$M_{i j}$ 表示未标记 Batch $B_{u}$ 中第 $i$ 个样本是否与第 $j$ 个样本相似。使用相似性矩阵 $M$ ,我们计算目标未标记样本的域内一致性损失 $\mathcal{L}_{i d a}$ 如下:
$\mathcal{L}_{i d a}=\frac{1}{\left|B_{u}\right|^{2}} \sum_{i=1}^{\left|B_{u}\right|} \sum_{j=1}^{\left|B_{u}\right|} M_{i j}\left\|z_{i}-z_{j}\right\|_{2}$
3.5 分类损失和整体框架
我们使用标签平滑交叉熵 [24] 损失来训练分类器层。 对于分类器训练,我们只使用来自标记的源数据集 $S$ 和标记的目标数据集 $\hat{T}$ 的样本,这些样本不断用新样本更新。
$\mathcal{L}_{c l s}=-\sum_{i=1}^{2 \eta_{\text {sup }} C} \mathrm{H}\left(h_{i}, \hat{y}_{i}\right)$
其中,$h_{i}$ 是预测的类别概率,$H$ 表示交叉熵损失,$\hat{y}_{i}=(1-\alpha) y_{i}+\alpha / C$ 是对应于 $xi$ 的平滑标签。 这里,$\alpha$ 是平滑参数,$y_{i}$ 是单热编码标签向量。
结合我们提出的方法 SPI、$\mathcal{L}_{\text {con }}$、$\mathcal{L}_{i l s}$ 和 $\mathcal{L}_{i d a$ 中使用的不同损失,产生一个单一的训练目标:
$\mathcal{L}_{S P I}=\lambda \mathcal{L}_{c o n}+\mathcal{L}_{i l s}+\mathcal{L}_{i d a}+\mathcal{L}_{c l s}$
4 实验
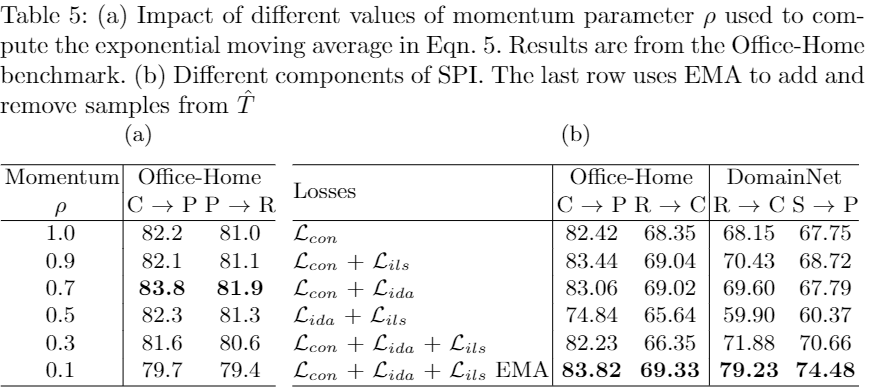
消融研究
5 总结
为了对齐两个域,使用两个域的监督样本利用对比损失来来学习语义上有意义和域不可知的特征空间;
为减轻标签比例偏斜带来的挑战,通过将未标记的目标样本的特征表示 与 来自源域和目标域的标记样本的特征表示进行比较来为未标记的目标样本打伪标记;
为增加对目标域的支持,潜在的噪声伪标签在训练过程中逐渐注入到标记的目标数据集中。 具体来说,使用温度标度余弦相似性度量来为未标记的目标样本分配软伪标签。 此外,为每个未标记的样本计算软伪标签的指数移动平均值。 这些伪标签基于置信度阈值逐渐注入(或移除)到(从)标记的目标数据集中,以补充源和目标分布的对齐。 最后,在标记和伪标记数据集上使用监督对比损失来对齐源和目标分布。