Next.js 开发指南 初始篇 | Next.js CLI
前言
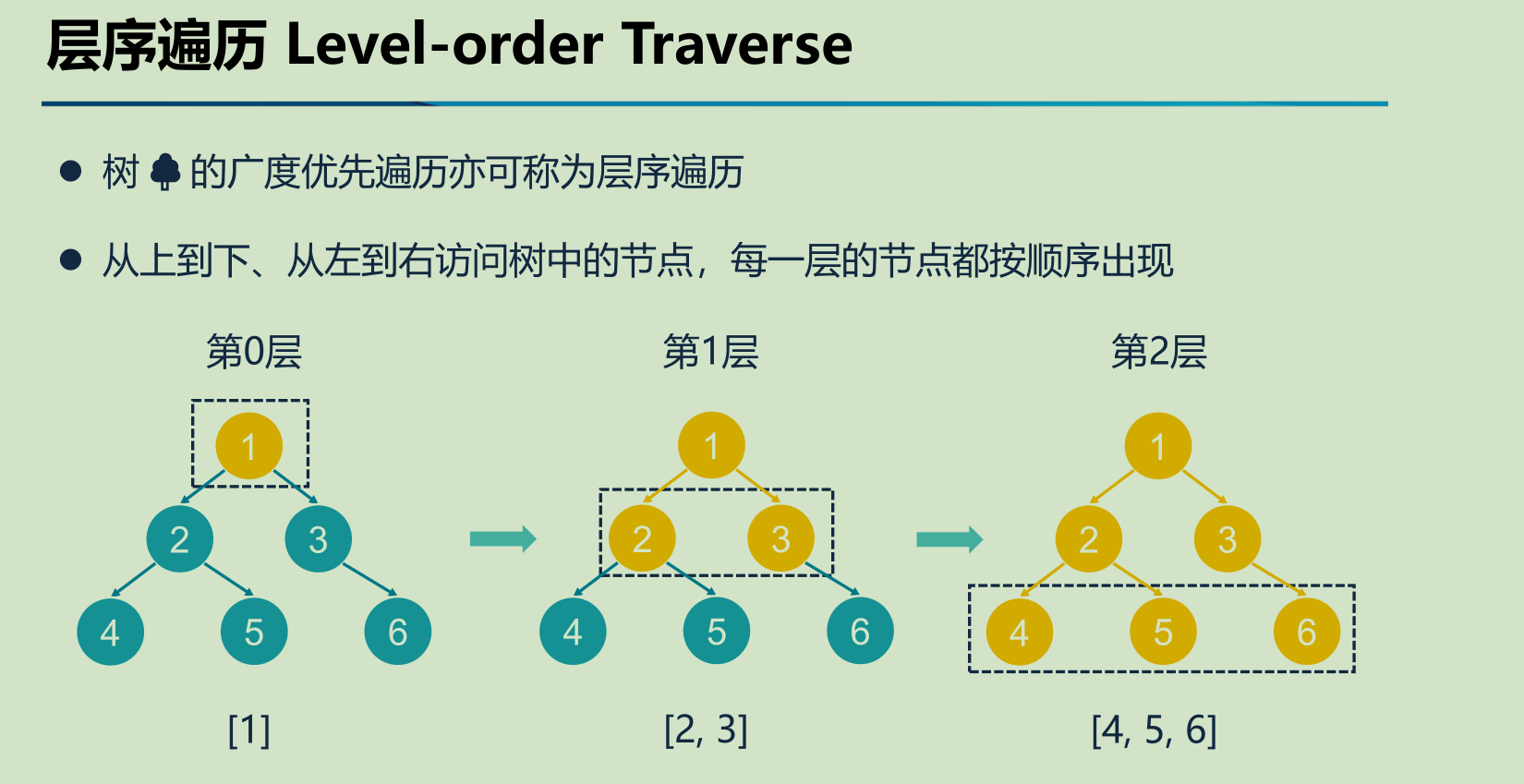
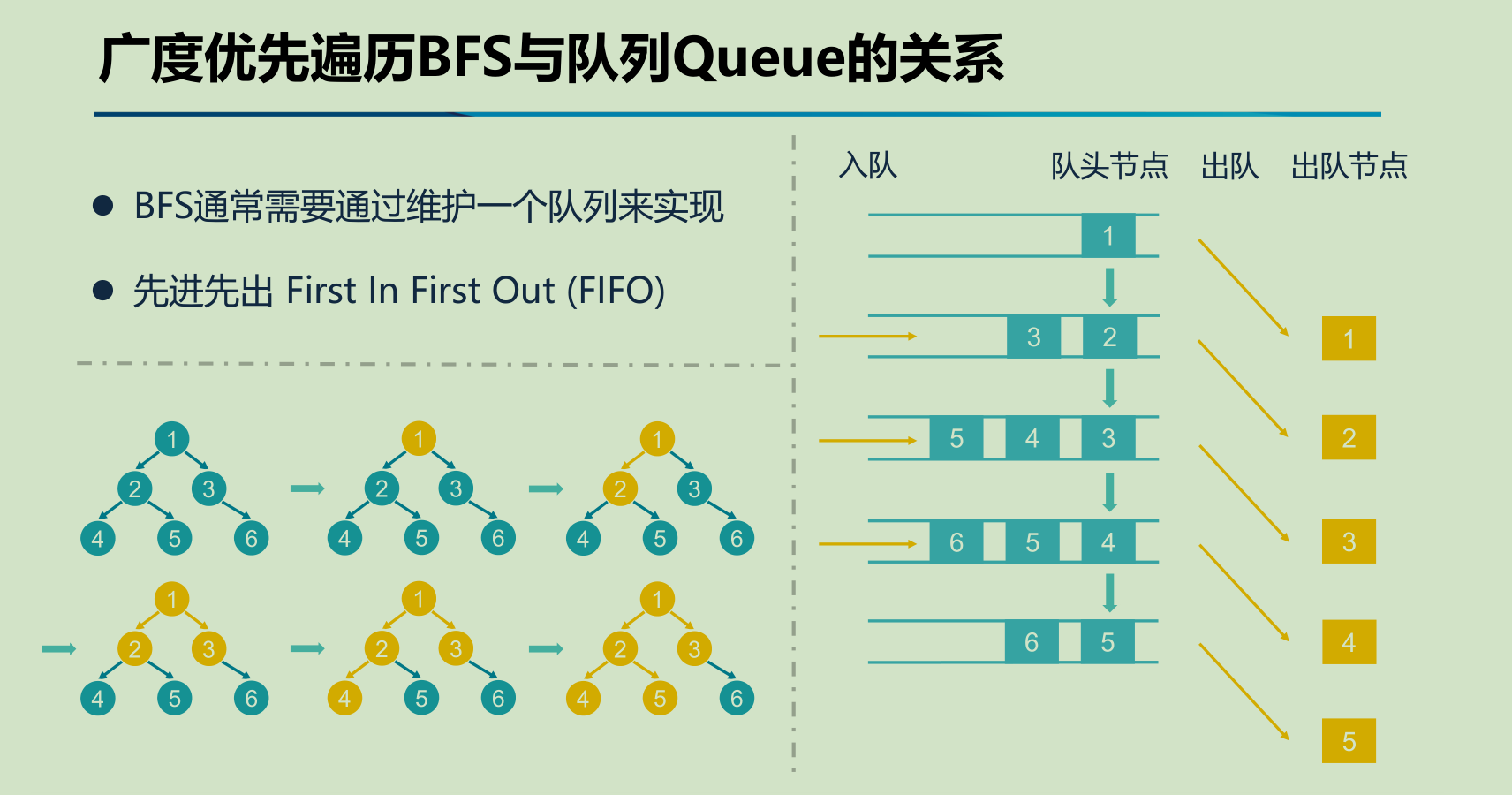
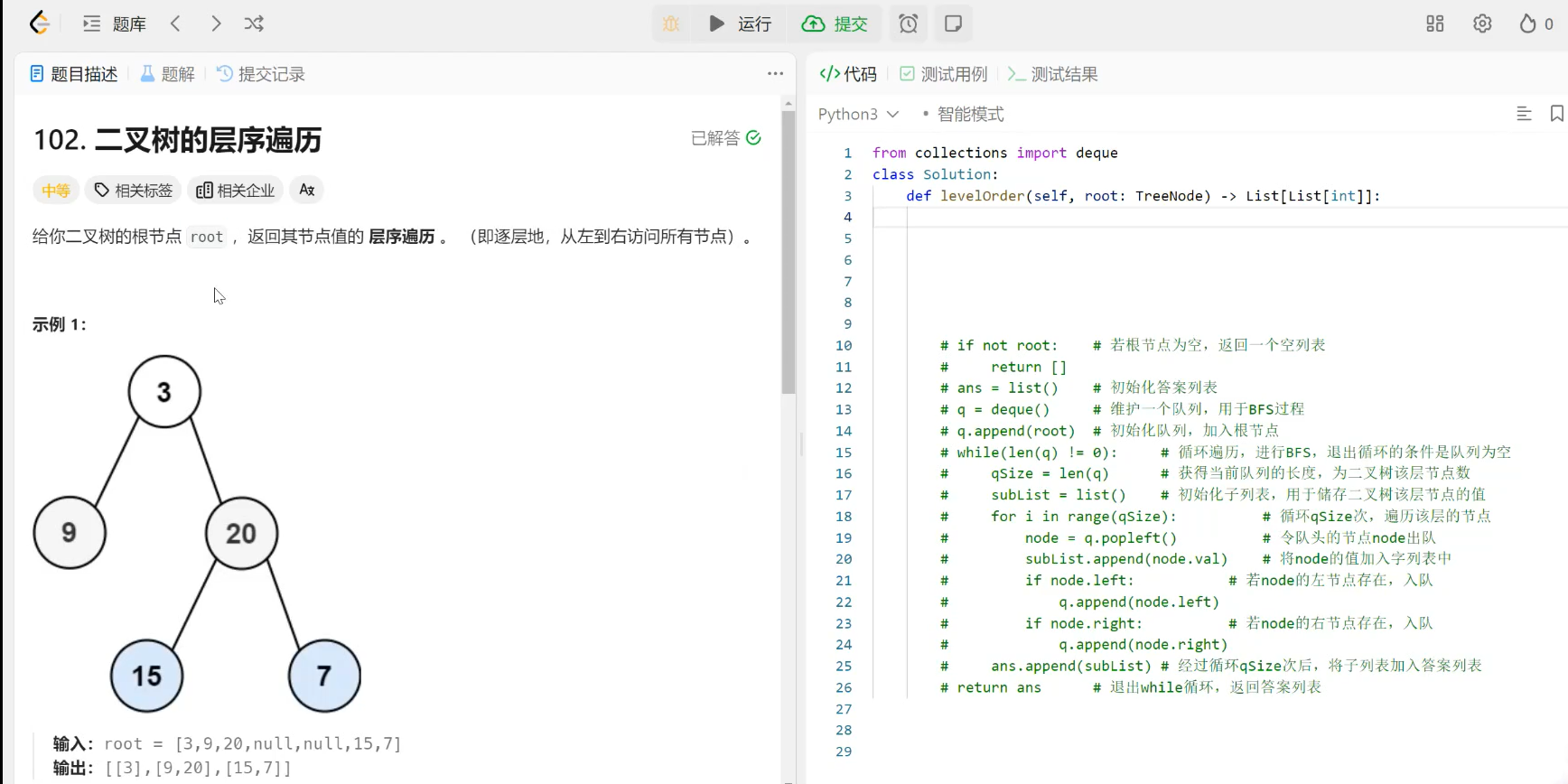
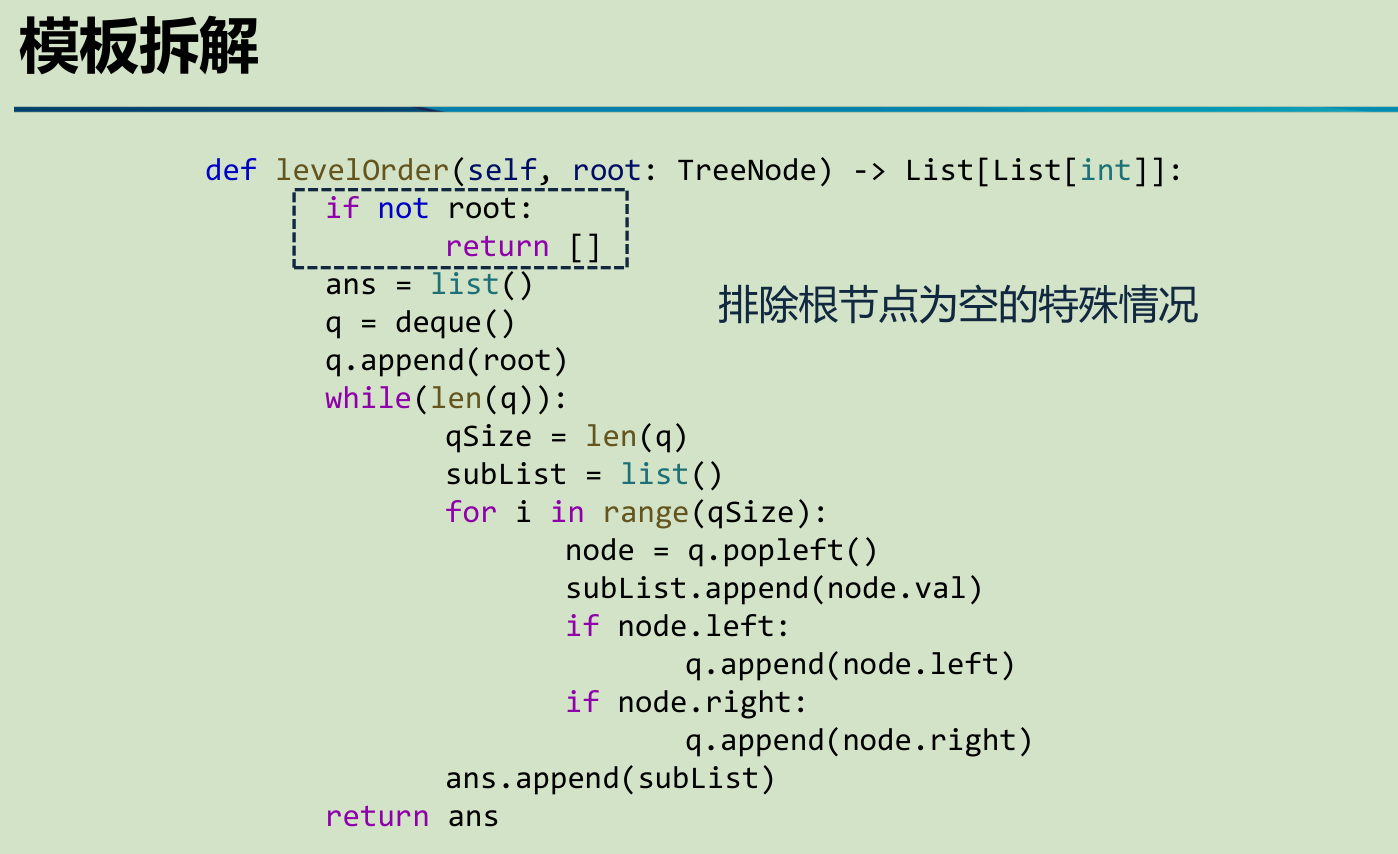
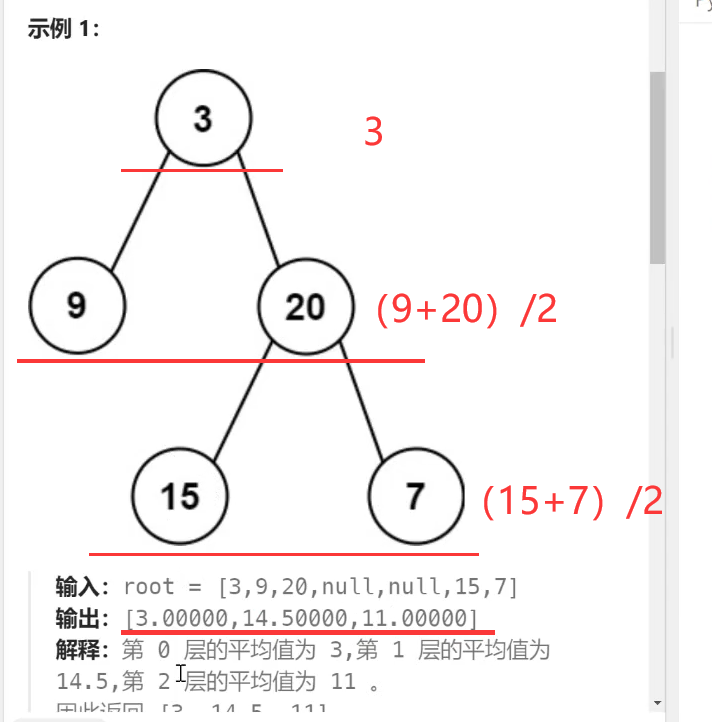
欢迎学习 Next.js!在学习具体的知识点之前,我们先来创建一个 Next.js 项目。创建了可运行的项目,才能在学习的时候边调试边理解,从而达到事半功倍的效果。
幸运的是,Next.js 提供了开箱即用的
create-next-app
脚手架,内置支持 TypeScript、ESLint 等功能,零配置即可实现自动编译和打包。
本篇我们会讲解创建项目的两种方式:自动创建项目和手动创建项目,以及开发项目时常用的脚本命令。同时我们会对脚本背后的
next
命令进行详解,帮助大家了解每个命令实现的功能以及可选参数。
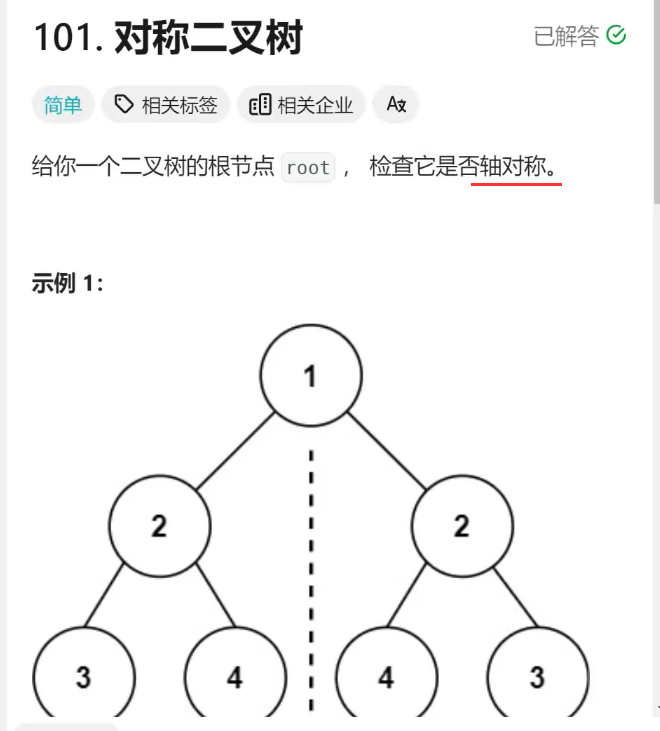
1. 自动创建项目
1.1. 环境要求
此本小册基于的是目前最新版本的 v14 版本,需要
Node.js 18.17
及以后版本,支持 macOS、Windows、Linux 系统。
1.2. 创建项目
最快捷的创建 Next.js 项目的方式是使用
create-next-app
脚手架,你只需要执行:
npx create-next-app@latest接下来会有一系列的操作提示,比如设置项目名称、是否使用 TypeScript、是否开启 ESLint、是否使用 Tailwind CSS 等,根据自己的实际情况进行选择即可。如果刚开始你不知道如何选择,遵循默认选择即可,这些选择的作用我们会随着小册的学习逐渐了解。
注:为了减少展示的代码量,此本小册的示例代码并未使用 TypeScript。(想学习 TypeScript 的同学可以看我
整理的最新的 TypeScript 官方文档
)
完成选择之后,
create-next-app
会自动创建项目文件并安装依赖,创建安装完的项目目录和文件如下:
如果你不使用
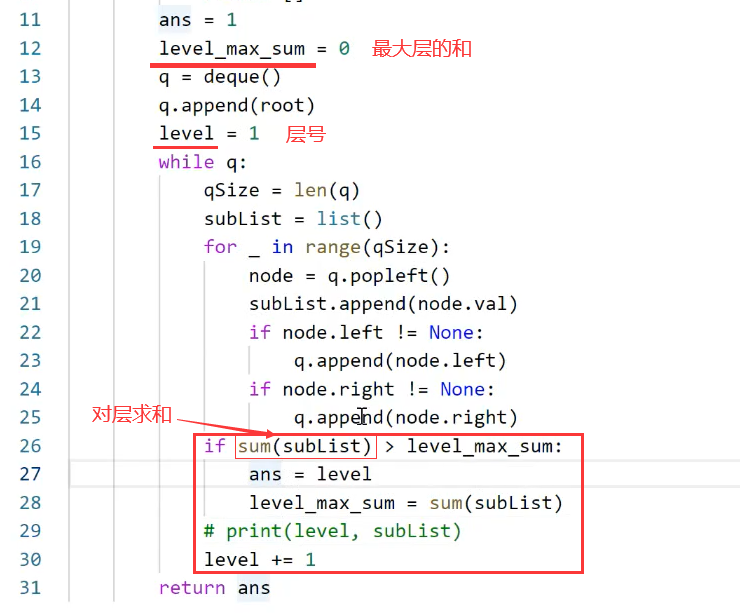
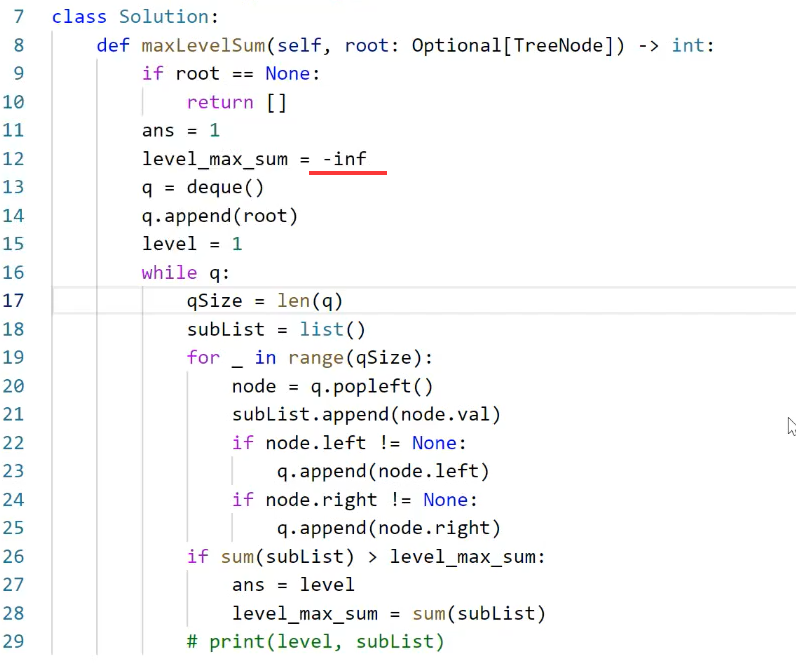
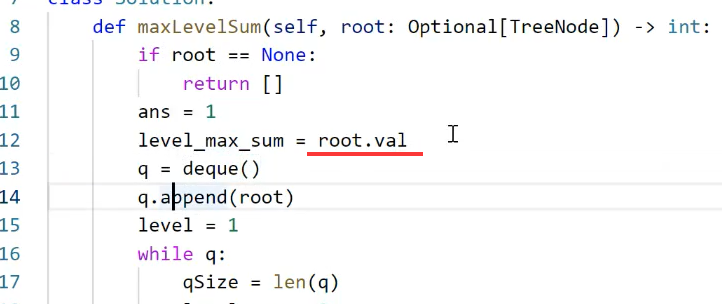
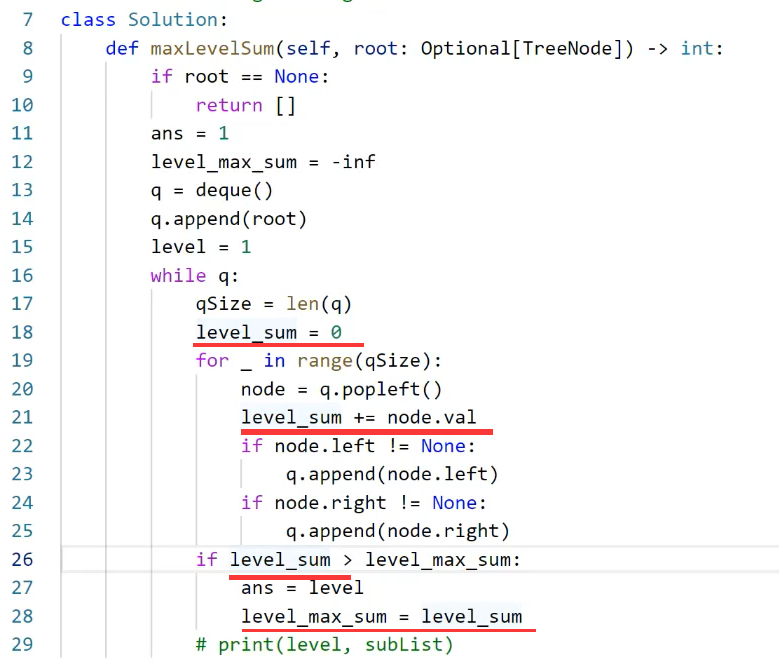
npx
,也支持使用
yarn
、
pnpm
、
bunx
:
yarn create next-apppnpm create next-appbunx create-next-app1.3. 运行项目
查看项目根目录
package.json
文件的代码:
// package.json
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},我们可以看到执行命令有
dev
、
build
、
start
、
lint
,分别对应开发、构建、运行、代码检查。
开发的时候使用
npm run dev
。部署的时候先使用
npm run build
构建生产代码,再执行
npm run start
运行生产项目。运行
npm run lint
则会执行 ESLint 语法检查。
现在我们执行
npm run dev
运行项目吧!
命令行会提示运行在
3000
端口,我们在浏览器打开页面
http://localhost:3000/
,看到如下内容即表示项目成功运行:
注:学习的时候为了避免浏览器插件带来的影响,建议在无痕模式下测试。
1.4. 示例代码
Next.js 提供了丰富的示例代码,比如
with-redux
、
api-routes-cors
、
with-electron
、
with-jest
、
with-markdown
、
with-material-ui
、
with-mobx
,从这些名字中也可以看出,这些示例代码演示了 Next.js 的各种使用场景,比如
with-redux
就演示了 Next.js 如何与 redux 搭配使用。
你可以访问
github.com/vercel/next…
来查看有哪些示例代码。如果你想直接使用某个示例代码,就比如
with-redux
,无须手动 clone 代码,在创建项目的时候使用
--example
参数即可直接创建:
npx create-next-app --example with-redux your-app-name注:使用示例代码的时候,并不会像执行
npx create-next-app
时提示是否使用 TypeScript、ESLint 等,而是会直接进入项目创建和依赖安装。
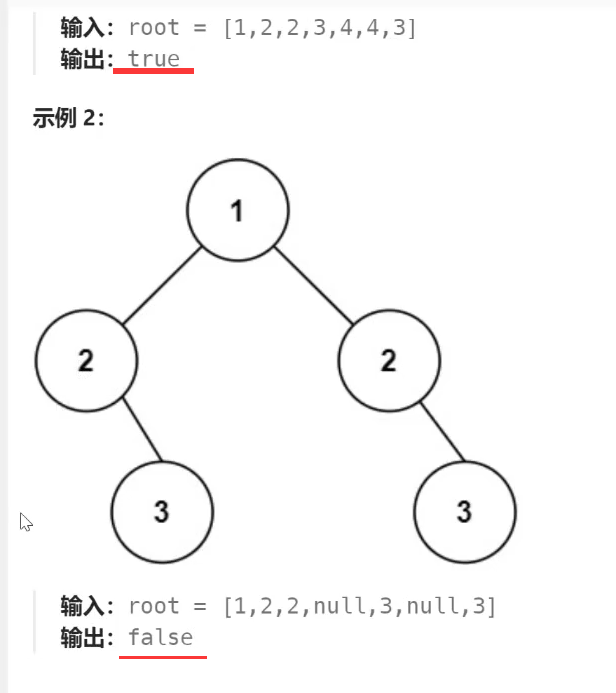
2. 手动创建项目
大部分时候我们并不需要手动创建 Next.js 项目,但了解这个过程有助于我们认识到一个最基础的 Next.js 项目依赖哪些东西。
2.1. 创建文件夹并安装依赖
现在,创建一个文件夹,假设名为
next-app-manual
,
cd
进入该目录,安装依赖:
npm install next@latest react@latest react-dom@latestnpm 会自动创建
package.json
并安装依赖项。
2.2. 添加 scripts
打开
package.json
,添加以下内容:
{
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
}
}2.3. 创建目录
在
next-app-manual
下创建一个
layout.js
和
page.js
文件:
// app/layout.js
export default function RootLayout({ children }) {
return (
<html lang="en">
<body>{children}</body>
</html>
)
}// app/page.js
export default function Page() {
return <h1>Hello, Next.js!</h1>
}2.4. 运行项目
现在运行
npm run dev
,正常渲染则表示运行成功:
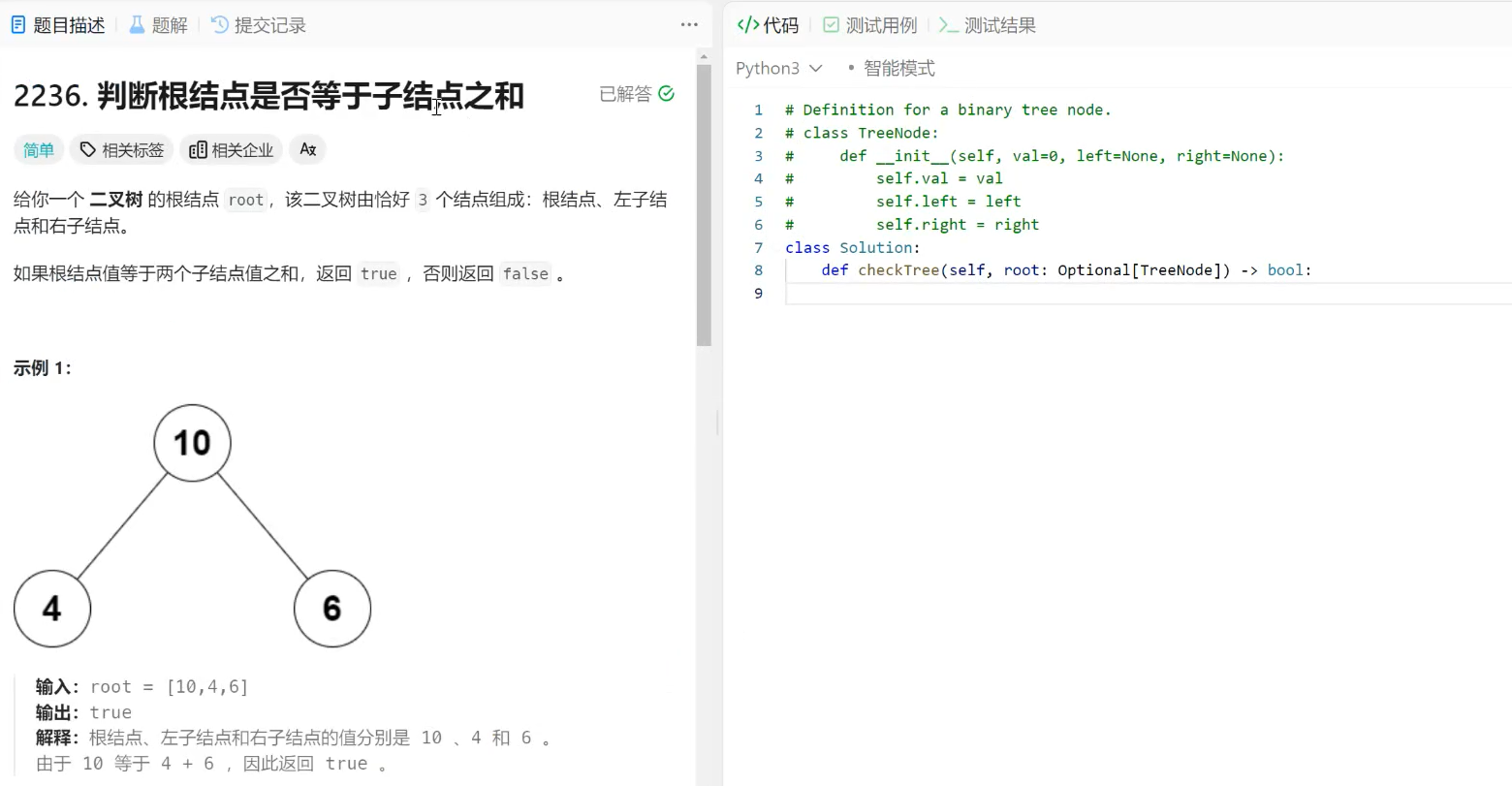
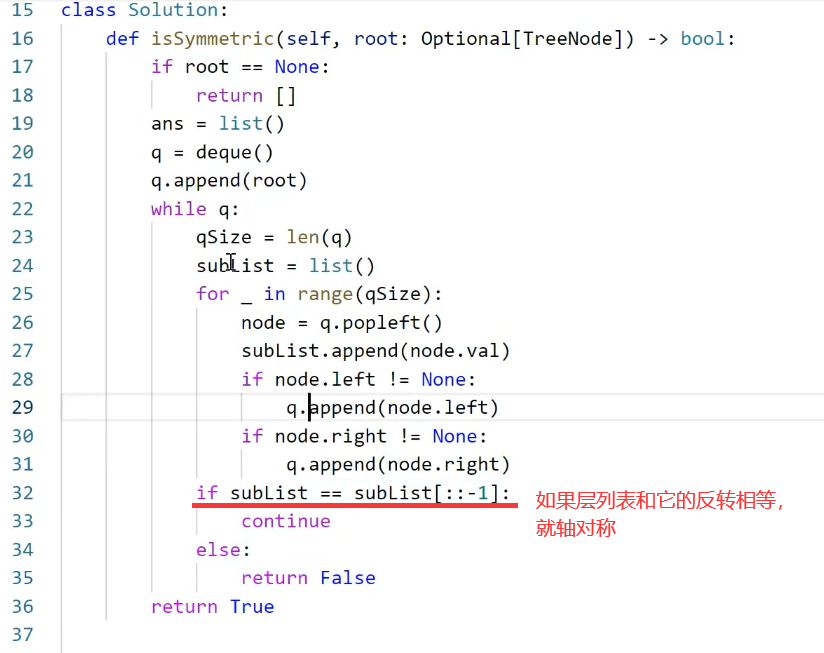
3. Next.js CLI
通过
package.json
中的代码我们知道:当我们运行
npm run dev
的时候,其实执行的是
next dev
。
next
命令就是来自于 Next.js CLI。Next.js CLI 可以帮助你启动、构建和导出项目。
完整的 CLI 命令,你可以执行
npx next -h
查看(
-h
是
--help
的简写)。
从上图可以看到,
next
可以执行的命令有多个,我们介绍下最常用的一些。
注:因为我们是使用
npx
创建的项目,这种方式下避免了全局安装
create-next-app
,所以我们本地全局并无
next
命令。如果你要执行
next
命令,可以在
next
前加一个
npx
,就比如这次用到的
npx next -h
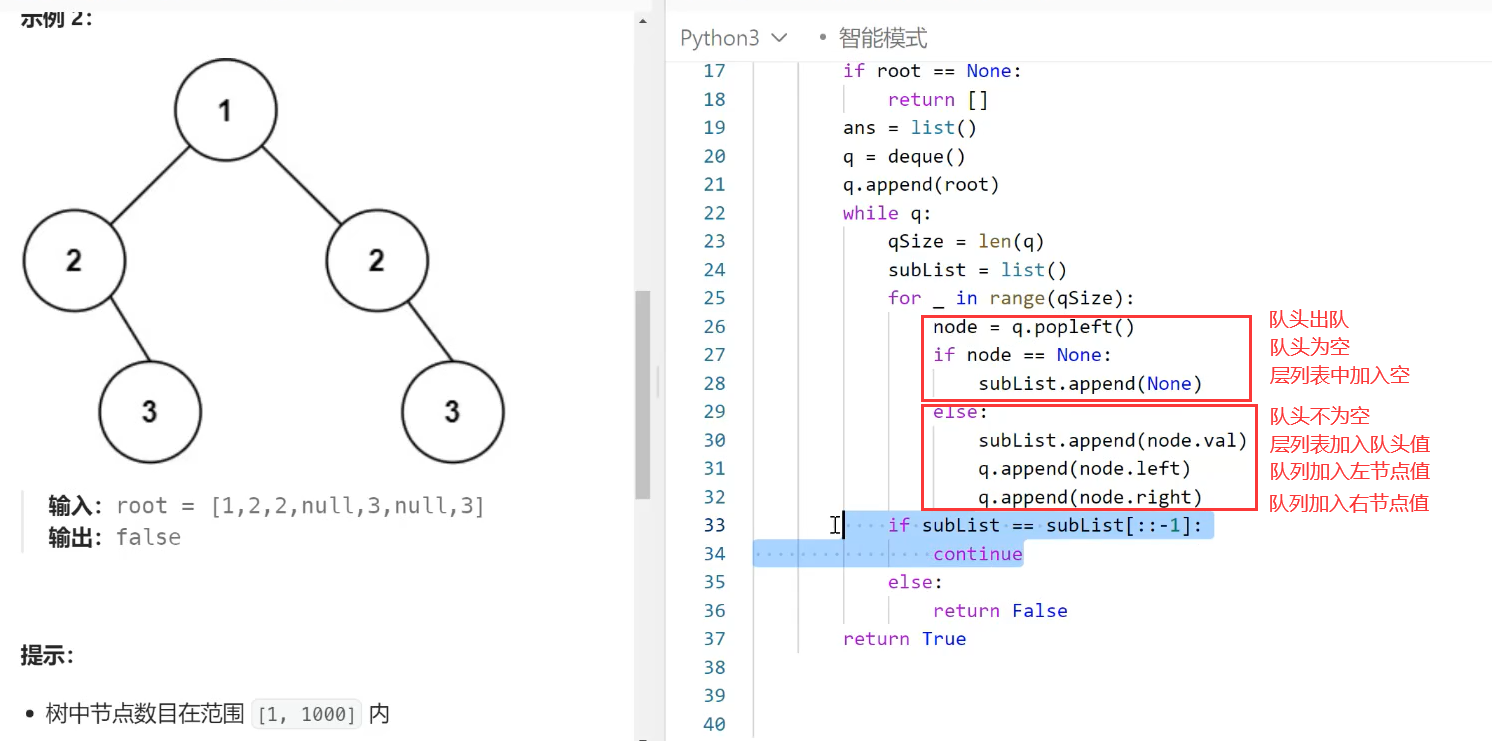
3.1. next build
执行
next build
将会创建项目的生产优化版本:
npx next build构建输出如下:
从上图可以看出,构建时会输出每条路由的信息,比如 Size 和 First Load JS。注意这些值指的都是 gzip 压缩后的大小。其中 First Load JS 会用绿色、黄色、红色表示,绿色表示高性能,黄色或红色表示需要优化。
这里要解释一下 Size 和 First Load JS 的含义。正常我们开发的 Next.js 项目,其页面表现类似于单页应用,即路由跳转(我们称之为“导航”)的时候,页面不会刷新,而会加载目标路由所需的资源然后展示。
加载目标路由一共所需的 JS 大小 = 每个路由都需要依赖的 JS 大小 + 目标路由单独依赖项 JS 大小其中:
- 加载目标路由一共所需的 JS 大小就是
First Load JS - 目标路由单独依赖项 JS 大小就是
Size - 每个路由都需要依赖的 JS 大小就是图中单独列出来的
First load JS shared by all
也就是说:
First Load JS = Size + First load JS shared by all以上图中的
/
路由地址为例,89 kB(First Load JS)= 5.16 kB(Size) + 83.9 kB(First load JS shared by all)
使用官方文档中的介绍:
Size
:导航到该路由时下载的资源大小,每个路由的大小只包括它自己的依赖项First Load JS
:加载该页面时下载的资源大小First load JS shared by all
:所有路由共享的 JS 大小会被单独列出来
现在我们访问生产版本的
http://localhost:3000/
:
上图中红色框住的 JS 是每个页面都要加载的 JS,根据命令行中的输出,总共大小为
83.9
kB,
413-dd2d1e77cac135ea.js
和
page-9a9638f75b922b0c.js
是这个页面单独的 JS,总共大小为
5.16
kB,所有JS 资源大小为
89 kB
。(注:跟图中的数字没有完全一致是因为没有开启 gzip 压缩)
next build --profile
该命令参数用于开启 React 的生产性能分析(需要 Next.js v9.5 以上)。
next build --profile然后你就可以像在开发环境中使用 React 的
profiler
功能。
如果你想测验这个功能,首先你的
浏览器要装有 React 插件
,然后你要对 React 的
Profiler API
有一定了解(其实就是测量组件渲染性能)。比如现在我们把
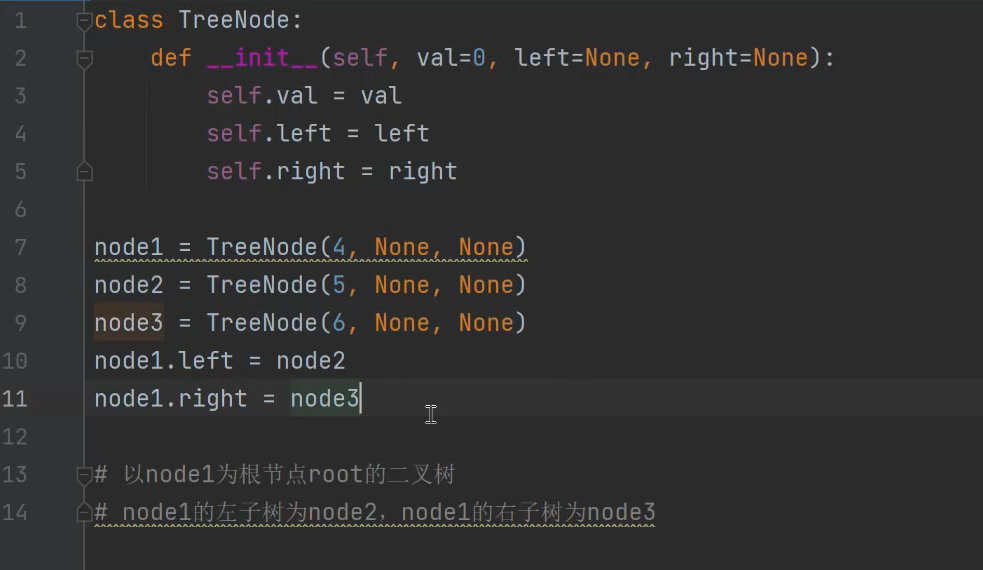
page.js
的代码改为:
// app/page.js
import React from 'react'
export default function Page() {
return (
<React.Profiler id="hello">
<p>hello app server</p>
</React.Profiler>
)
}执行
npm run dev
,你在控制台里可以看到:
通常执行
npm run build
和
npm run start
后,你再打开控制台,会发现在生产环境中不支持性能测量:
但如果你执行
npx next build --profile
再执行
npm run start
,尽管 React 插件会显示当前在生产环境,但 Profiler 是可以使用的:
这个功能可以帮助大家排查线上的性能问题。
next build --debug
该命令参数用于开启更详细的构建输出:
next build --debug开启后,将输出额外的构建输出信息如
rewrites
、
redirects
、
headers
。
举个例子,我们修改下
next.config.js
文件:
/** @type {import('next').NextConfig} */
const nextConfig = {
reactStrictMode: true,
async redirects() {
return [
{
source: '/index',
destination: '/',
permanent: true,
},
]
},
async rewrites() {
return [
{
source: '/about',
destination: '/',
},
]
}
}
module.exports = nextConfig再执行
npx next build --debug
,输出结果如下:
你可以看到相比之前的构建输出信息,多了
rewrites
、
redirects
等信息。
3.2. next dev
开发模式下,使用
next dev
运行程序,会自动具有热加载、错误报告等功能。默认情况下,程序将在
http://localhost:3000
开启。如果你想更改端口号:
npx next dev -p 4000如果你想更改主机名(hostname):(以便其他主机访问)
npx next dev -H 192.168.1.23.3. next start
生产模式下,使用
next start
运行程序。不过要先执行
next build
构建出生产代码。运行的时候,跟开发模式相同,程序默认开启在
http://localhost:3000
。如果你想更改端口号:
npx next start -p 40003.4. next lint
执行
next lint
会为
pages/
、
app/
、
components/
、
lib/
、
src/
目录下的所有文件执行 ESLint 语法检查。如果你没有安装 ESLint,该命令会提供一个安装指导。如果你想要指定检查的目录:
next lint --dir utils3.5. next info
next info
会打印当前系统相关的信息,可用于报告 Next.js 程序的 bug。在项目的根目录中执行:
next info打印信息类似于:
Operating System:
Platform: linux
Arch: x64
Version: #22-Ubuntu SMP Fri Nov 5 13:21:36 UTC 2021
Binaries:
Node: 16.13.0
npm: 8.1.0
Yarn: 1.22.17
pnpm: 6.24.2
Relevant packages:
next: 12.0.8
react: 17.0.2
react-dom: 17.0.2这些信息可以贴到 GitHub Issues 中方便 Next.js 官方人员排查问题。
小结
恭喜你,完成本篇内容的学习!
这一节我们讲解了
自动创建项目
和
手动创建项目
两种创建项目的方式,如果是全新的项目,推荐使用自动创建方式。如果是项目中引入 Next.js,可以参考手动创建项目的方式。
Next.js 项目常用的脚本有三个:
npm run dev
用于开发时使用、
npm run build
用于构建生产版本、
npm run start
用于运行生产版本。
从
package.json
中,我们得知这些脚本背后用的其实是 Next.js CLI 的
next
命令,然后我们对常用的
next
命令和相关参数进行了介绍。在必要的时候,可以使用这些命令和参数自定义 npm 脚本。
靡不有初,鲜克有终。恭喜你迈出第一步!接下来我们将进入路由篇,带大家了解 Next.js v13 带来颠覆式更新的的 App Route 功能。在学习的过程中,如果遇到有疑问的地方,一定要多写 demo 测试哦!
- 初始篇 | Next.js CLI
- 路由篇 | App Router
- 路由篇 | 动态路由、路由组、平行路由和拦截路由
- 路由篇 | 路由处理程序和中间件
- 路由篇 | 国际化
- 数据获取篇 | 数据获取、缓存与重新验证
- 数据获取篇 | Server Actions 与表单
- 渲染篇 | 从 CSR、SSR、SSG、ISR 开始说起
- 渲染篇 | 服务端组件和客户端组件
- 渲染篇 | Streaming 和 Edge Runtime
- 缓存篇 | Caching
- 样式篇 | Tailwind CSS、CSS-in-JS 与 Sass
- 组件篇 | Images
- 组件篇 | Font
- 组件篇 | Link 和 Script
- 优化篇 | 懒加载
- 配置篇 | TypeScript 和 ESLint
- 配置篇 | 环境变量、路径别名与 src 目录
- 配置篇 | MDX
- 配置篇 | 草稿模式和内容安全策略
- 配置篇 | 路由段配置项
- 部署篇 | 静态导出
- Metadata 篇 | 基于配置
- Metadata 篇 | 基于文件
- API 篇 | next.config.js(上)
- API 篇 | next.config.js(下)
- API 篇 | 请求相关的常用函数与方法
- API 篇 | 常用函数与方法
- 实战篇 | React Notes | 项目介绍与创建
- 实战篇 | React Notes | 侧边栏笔记列表
- 实战篇 | React Notes | 笔记预览界面
- 实战篇 | React Notes | 笔记编辑界面
- 实战篇 | React Notes | 笔记搜索
- 实战篇 | React Notes | 国际化
- 实战篇 | React Notes | Auth
- 实战篇 | React Notes | 文件上传
- 实战篇 | React Notes | 部署(一)
- 实战篇 | React Notes | 部署(二)
- 实战篇 | 博客 | 项目创建
- 实战篇 | 博客 | 博客后台
- 实战篇 | 博客 | MDX
- 实战篇 | 博客 | Server Actions
- 实战篇 | 博客 | 渲染原理
- 实战篇 | App | 需求分析
- 实战篇 | App | 数据库设计
- 实战篇 | App | 项目创建
- 实战篇 | App | 移动端处理
- 实战篇 | App | 接口开发
- 实战篇 | App | 数据请求
- 实战篇 | App | 构建部署
- 源码篇 | 源码架构
- 源码篇 | 调试代码
- 源码篇 | 路由实现
- 源码篇 | 渲染原理
- 源码篇 | 手写 SSR
- 源码篇 | mini-next
- 源码篇 | mini-next
- 源码篇 | mini-next
- 源码篇 | mini-next
- 面试篇 | 常见面试题及解析
- 面试篇 | 常见面试题及解析
- 面试篇 | 常见面试题及解析