全球 IPv4 耗尽,下个月开始收费!
哈喽大家好,我是咸鱼
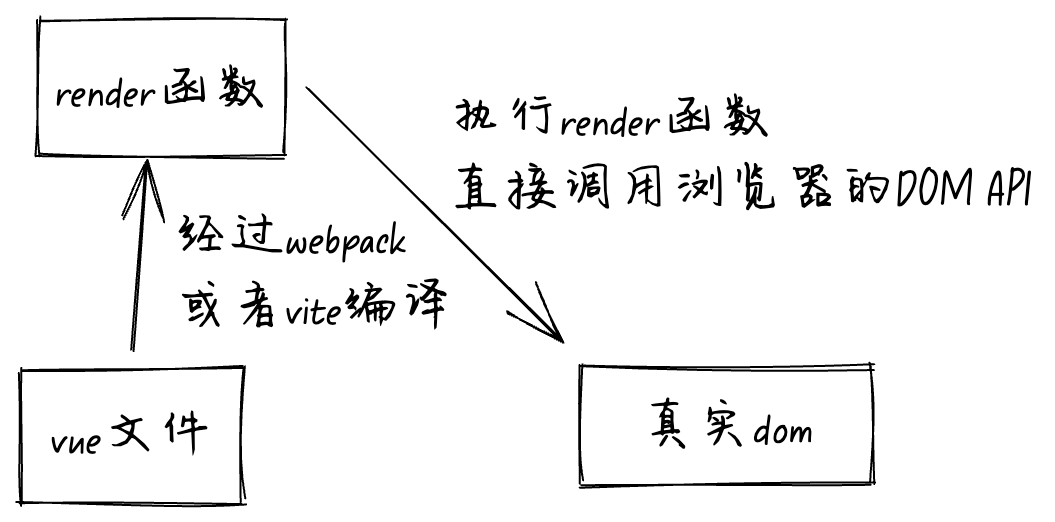
IPv4(Internet Protocol version 4)是互联网上使用最广泛的网络层协议之一,于1981年在 RFC 791 中发布,它定义了 32 位的IP地址结构和基本的协议操作。
由于 IPv4 使用 32 位的地址,因此只有四十亿(4,294,967,296,2^32)个地址。
这就导致随着地址不断被分配,IPv4 地址开始面临枯竭问题:
- 2011 年,互联网分配与分配机构(IANA)正式宣布IPv4地址用尽
- 由于 IPv4 地址短缺,一些机构开始收费分配IPv4地址,推动更多组织采用 IPv6
IPv 4 枯竭,升级 IPv6 任重道远。
今天我们来看一篇文章,看看向 IPv6 迁移会遇到什么样的挑战以及各个企业会拿出什么样的策略。
原文链接:
https://medium.com/stackademic/global-ipv4-depletion-charges-begin-next-month-011c914c5737
IPv4 即将迎来支付时代:
- 去年 7 月,亚马逊云科技宣布,从 2024 年 2 月 1 日起,所有公有 IPv4 地址将按每小时 0.005 美元(约每月 4 美元)的费率收费,无论它们是否与服务绑定。
- 基于容器的部署平台 Fly.io 最近也更新了其社区公告,表示 2 月 1 日之后,将对每个专用 IPv4 每月收取约 2 美元的费用。
- 开源数据处理服务平台 Supabase 计划推出 IPv4 的付费附加服务,月费为 4 美元。
随着时间流逝,围绕 "IPv4 收费,迁移到 IPv6" 的讨论越来越激烈。最近,开源数据处理服务平台 Supabase 的首席执行官兼联合创始人 Paul Copplestone 呼吁大家:“做好准备,IPv6 即将到来。”
然而,由于 IPv4 和 IPv6 报文头之间的显著差异,这两个协议不能互操作。升级到 IPv6 的道路也面临着多重挑战。
一些开发人员已经尝试使用 IPv6,但得出的结论是:IPv6 是一个“灾难”。虽然我们可能在未来会解决这些困难,但目前的准备仍然不够。
全球 IPv4 地址耗尽,IPv6 升级成为焦点
据负责英国、欧洲、中东和中亚部分地区互联网资源分配的 Réseaux IP Européens Network Coordination Centre (RIPE NCC)宣布:随着互联网规模的不断扩大,设备数量的快速增加导致最后一个 IPv4 地址空间储备池于 2019年11月25日15:35 耗尽,全球 42 亿个 IPv4 地址已经分配完毕。
公网 IPv4 地址耗尽后,我们使用的公网 IPv4 地址主要靠回收和释放未被用的地址范围来获取。这些地址有的可能是来自解散的公司,有的可能是那些搬迁到 IPv6 后不再需要的。
获取日益紧缺的 IPv4 地址橙味一个复杂的过程,这导致了成本自然增加。亚马逊(AWS)此前透露,过去五年来,由于获取难度增加,单个公网 IPv4 地址的获取成本增加了300%以上。
所以大公司不得不采取收费政策,希望大家更有效地利用公 共IPv4 地址,同时促进 IPv6 在行业内的采用。
Paul Copplestone 表示:“虽然 AWS 每月收费约 4 美元,对个人来说不算昂贵,但 AWS 是许多基础设施公司的基础设施层,比如 Supabase。我们需要为每个 Postgres 数据库提供完整的 EC2 实例,这将使我们的 AWS 账单增加数百万美元。”
一些分析人士认为,对于规模较大的 AWS 客户来说,这些费用可以完全忽略,可能在他们的账单上不值一提。然而,对于很多中小企业和初创公司来说,这些费用很容易就占到他们账单的 10-30%。
三个选择
当涉及到处理这些成本时,公司有哪些选择来最小化成本呢 ?
对此,Paul Copplestone 分享了 AWS 基础设施公司的三种选择:
- 将成本转移给客户:类似于 AWS 和 Fly.io 那样,在租用或购买 IPv4 地址时,制定新的定价政策,让客户为此付费。对于单个 IPv4 地址,AWS 的新费用为每年 43.80 美元(0.05 * 24 小时 * 365 天)
- 提供替代解决方案(如代理):企业可以为客户提供 IPv4 代理服务,通过代理将 IPv6 流量映射到 IPv4 流量。这种方法允许 IPv6 设备访问 IPv4 资源,同时减少对 IPv4 地址的直接需求;或者通过 NAT 技术来优化 IPv4 地址的利用率:共享一个IPv4地址,使用不同的端口来区分不同的业务或用户。
- 只提供 IPv6:希望大家能跟上它。
ipv6 面临的挑战
长期来看,第三种选择 ——“只提供 IPv6” 是最经济有效的解决方案。作为 IPv4 的继任者,IPv6 对移动设备的支持更好,地址分配更灵活,报头结构更简化,安全性更高。
IPv6 的地址空间非常大,大约有 3.4 x 10^38 个地址,能够满足未来互联网连接设备不断增长的需求。。可以说 “IPv6 为每一粒沙子提供了一个唯一的地址”。

IPv6 的出现无疑是一件好事,然而根据谷歌的统计,截至 2024年1月15日,IPv6 引入十多年来,互联网用户使用 IPv6 的占比还没有达到 50%,仅仅是 41.23%。

关于这背后的原因,Paul Copplestone 认为有两点:
- 互联网服务提供商 (ISP) 支持不足
- 缺乏相关工具支持
ISP 支持不足
问题来了:你的互联网服务提供商(ISP)是否支持 IPv6?
Paul Copplestone认为,全球 IPv6 面临的最大挑战在于 ISP 的支持。简单来说,当输入网站的域名时,它会被转换为 IPv4 地址:
example.com → 93.184.216.34
如果采用 IPV6,这些域名最终将被解析成:
example.com → 2607:f8b0:4006:819::200e
一旦 ISP 收到此地址,它就负责将所有流量路由到正确的目的地。
不幸的是,许多 ISP 没有为域名解析成 IPv6 地址做好充分的准备。它们需要更新的交换机、更新的软件以及与 IPv4 的互操作性——这些都会产生成本,而在过去十年中,这些成本似乎并不合理。
如果你的 ISP 不支持 IPv6,则当域名/服务器开始解析为 IPv6 而不是 IPv4 地址时,可能会遇到以下问题:
- 如果在 AWS 中设置了 Web 服务器,则无法通过 SSH 连接到该服务器。
- 如果直接从本地计算机连接到 Supabase 数据库,则需要使用连接池,该连接池将解析为 IPv4(提供商需要为这些 IPv4 地址付费)
- 如果通过 Vercel 连接到任何 AWS 服务器,并且没有为服务器设置 IPv4 地址,则会连接失败。
缺乏工具支持
除了上面 ISP 支持不足的原因之外,许多开发工具还没有针对 IPv6 进行配置兼容。Paul Copplestone 以他的开源 Firebase 替代品 Supabase 为例解释说,为了让他们的数据团队的工具与 IPv6 兼容,他们需要进行以下更改:
- 向 VPC 网络添加 IPv6 支持。
- 向 Airflow VM 添加 IPv6 支持。
- 向 Docker 和 Compose 添加 IPv6 支持。
虽然这些步骤看起来很简单,但实现它们实际上是相当具有挑战性的。
以配置 Docker 的步骤为例:
1、更新
/etc/docker/daemon.json
"ipv6": true,
"fixed-cidr-v6": "fd00:ffff::/80",
"ip6tables": true,
"experimental": true
2、重启 Docker 服务
systemctl restart docker
3、创建临时 IPv6 网络并测试
docker network create --ipv6 --subnet fd00:ffff::/80 ip6net
docker run --rm -it --network ip6net busybox ping6 google.com -c3
4、检查 IPv6 iptables 配置
ip6tables -L
5、将 IPv6 网络配置添加到
Docker Compose
文件
# enable IPv6 to default network
networks:
default:
enable_ipv6: true
ipam:
config:
- subnet: fd00:c16a:601e::/80
gateway: fd00:c16a:601e::1
6、检查是否正常运行
docker exec -it "airflow_airflow-worker_1" bash
curl -6 https://ifconfig.co/ip
可以看到,这些配置还是很繁杂的,尤其是对于 docker 这样无处不在的工具。
向 IPv6 迈进,挑战重重
DevOps 工程师 Mathew Duggan 吐槽迁移到 IPv6 困难重重:“几乎没有什么是开箱操作的。主要依赖项会立即停止工作,并且解决方法不足以满足生产需求。我们团队的 IPv6 迁移过程相当艰难,主要是因为很少有人承担这项工作,我们已经很多年没有做这项工作了,现在正在付出代价。”
Mathew Duggan 尝试使用 CDN 将他的博客 (
https://matduggan.com/ipv6-is-a-disaster-and-its-our-fault/)
迁移到 IPv6 以管理 IPv4 流量。
他说:“实际的设置很简单。我配置了一个 Debian 设备并选择了 IPv6。然后我得到了第一个惊喜:设备没有获取到 IPv6 地址,但收到了一个 64 位地址(18,446,744,073,709,551,616)。我的小型 ARM 服务器可以通过扩展,在所有公共地址上运行我曾工作过的每家公司所有网络基础设施。
然而,当他试图像普通服务器一样设置它时,问题出现了。
- 无法 SSH 登录
因为他的工作或家庭的 ISP 不支持 IPV6,所以需要他手动设置,否则根本无法正常工作。因此,他必须先添加一个 IPv4 地址,通过 SSH 登录,然后设置 Cloudflared 来运行隧道(tunnel)。
但是 Cloudflare 系统本身不能处理转换。当他删除 IPv4 地址时,隧道意外崩溃了。因为 Cloudflared 默认使用 IPv4,如果想要支持 IPv6,要编辑 systemd 服务文件添加:
—-edge-ip-version 6
,这样隧道才能正常使用。
- 无法使用 GitHub
当 Mathew Duggan 的服务器开始运行时,他尝试去执行一个服务器设置脚本,这个脚本会去 GitHub 获取安装文件,但是报错了。
他感到困惑,GitHub 确定支持 IPv6 吗?最后他意外发现 GitHub 不支持 IPv6
最后他使用了 TransIP Github 代理服务器,运行良好。但随后 Python 遇到了
urllib.error.URLError
“好吧,我放弃了。我猜 Debian 中的 Python 3 版本不喜欢 IPv6,但我现在不想排查了,“ Mathew Duggan 说。
- 无法设置 Datadog
接下来,Mathew Duggan 想要设置 Datadog 来监控服务器,当他访问 Datadog、登录并开始工作时,系统立即崩溃。
他只是通过运行
curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh
进行设置,但是现在 S3 支持 IPv6,问题可能出在哪里?
经过故障排除后,他发现问题不在于 S3 或服务器,因为他可以使用 AWS 提供的 S3 连接测试而不会出现任何问题。后来,他通过
apt
手动修复了这个问题。
他开始意识到纯 IPv6 的使用没有未来。如果没有代理和技术补丁,那几乎没有什么东西能正常工作
后来,为了从 IPv6 访问 IPv4 资源,他选择了 NAT64 服务 (
https://nat64.net/)
作为支持。
不但如此,他还搜索了许多工具,发现其中大多数工具已经不能工作:如下面的 Dresel 链接无法工作;Trex 在测试中出现了问题;August Internet 彻底消失;大多数 Go5lab 测试设备离线;Tuxis 倒是可以工作,但在 2019 年推出之后似乎就没升级过。只有一个 Kasper Dupont 支持度还是可以的。
采用 IPv6 任重道远
虽然向 IPv6 过渡的时机已经到来,但大多数基础设施和软件仍然没有为这种变化做好准备。而且 IPv6 的培训和准备对数字专业人员来说将是一项重大挑战。
不但许多开发人员这么认为,来自 HN 上的网友也纷纷诉苦:
- 我仍然在诅咒 IPv6 的设计者,因为他们没有使 IPv6 向后兼容 IPv4。IPv6 的设计无疑是优越的,但由于缺乏向后兼容性,过渡到 IPv6 是一个绝对的挑战。我知道设计师们认为这种转变只需要几年的时间,但它已经持续了近 30 年……我们还在原地踏步。
- 除非 IPv6 地址成为一等公民,否则 IPv6 并不能真正解决地址耗尽的问题。只有当我们不再需要依赖 IPv4 地址时,才会发生这种情况。
如果不迁移到IPv6,继续使用IPv4,可能无法满足日益增长的需求,导致性能下降和业务不稳定。现在许多组织采用 NAT 技术来共享有限的 IPv4 地址,但是这会增加网络管理的复杂性,还可能使某些程序或服务的功能受限。
鉴于此,越来越多的组织开始加入到实施 IPv6 迁移的浪潮之中。