他凌晨1:30给我开源的游戏加了UI|模拟龙生,挂机冒险
一、前言
新年就要到了,祝大家新的一年:
新年就要到了,祝大家新的一年:
by emanjusaka from
https://www.emanjusaka.top/2024/01/linux-base-command
彼岸花开可奈何
本文欢迎分享与聚合,全文转载请留下原文地址。
分类总结了 Linux 中的基础命令,可以收藏本文以后如果忘记了某些基础命令或者对某些命令不知道怎么用时,拿出本文快速查看各种命令的用法及作用。希望这个速查手册可以帮助到大家。
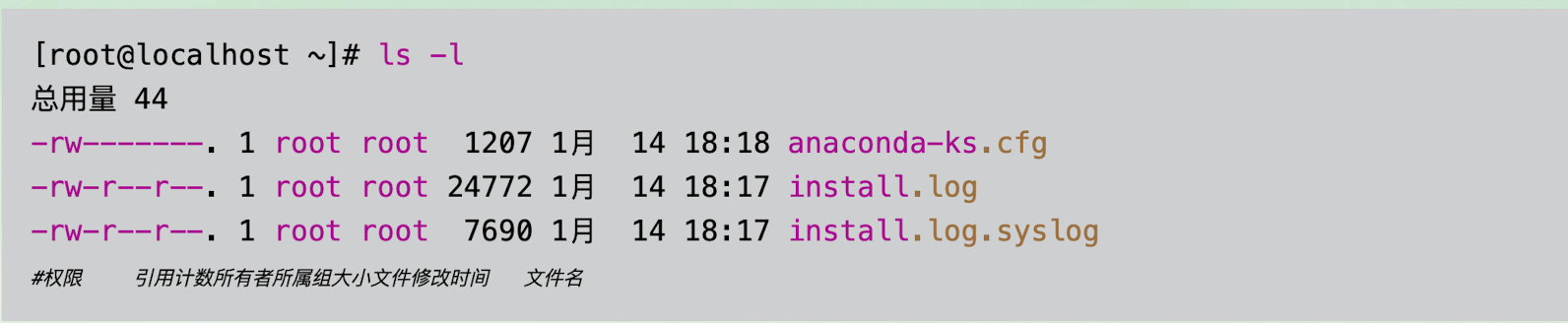
显示当前目录下的文件名
ls [选项] [文件名或目录名]
-a:显示所有文件
--color=when:支持颜色输出,when 的值默认是 always(总显示颜色),也可以是 never(从不显示颜色)和 auto(自动)
-d:显示目录信息,而不是目录下的文件
-h:人性化显示,按照我们习惯的单位显示文件大小
-i:显示文件的 i 节点号
-l:长格式显示
切换所在目录的命令。
cd 目录名称
cd命令的特殊符号:
创建目录的命令
mkdir [选项] 目录名
-p:递归建立所需目录
删除目录的命令
rmdir [选项] 目录名
-p:递归删除目录
只能删除空目录,不太常用。
以树形结构显示目录下的文件
tree 目录名称
如果文件不存在,则会建立空文件;如果文件已经存在,则会修改文件的时间戳。
touch [选项] 文件名或目录名
-a: 只修改文件的访问时间(Access Time)
-c:如果文件不存在,则不建立新文件
-d:把文件的时间改为指定的时间
-m:只修改文件的数据修改时间(Modify Time)
查看文件详细信息的命令
stat [选项] 文件名或目录名
-f:查看文件所在的文件系统信息,而不是查看文件的信息
用来查看文件内容
cat [选项] 文件名
-A:相当于-vET 选项的整合,用于列出所有隐藏符号
-E:列出每行结尾的回车符$
-n:显示行号
-T:把 Tab键用^I显示出来
-v:列出特殊字符
分屏显示文件的命令
more 文件名
交互命令:
- 空格键:向下翻页
- b:向上翻页
- 回车键:向下滚动一行
- /字符串:搜索指定的字符串
- q:退出
分行显示命令
less 文件名
显示文件开头的命令
head [选项] 文件名
-n 行数:从文件头开始,显示指定行数
-v:显示文件名
默认显示文件的开头 10 行内容
显示文件结尾的命令
tail [选项] 文件名
-n 行数:从文件结尾开始,显示指定行数
-f:监听文件的新增内容
默认显示文件的后 10 行
在文件之间建立链接
ln [选项] 源文件 目标文件
-s:建立软链接文件。如果不加“-s”选项,则建立硬链接文件
-f:强制。如果目标文件已经存在,则删除目标文件后再建立链接文件
软链接文件的源文件必须写成绝对路径
删除文件或目录
rm [选项] 文件或目录
-f:强制删除(force)
-i:交互删除,在删除之前会询问用户
-r:递归删除,可以删除目录(recursive)
复制文件和目录
cp [选项] 源文件 目标文件
-a:相当于-dpr 选项的集合
-d:如果源文件为软链接(对硬链接无效),则复制出的目标文件也为软链接
-i:询问,如果目标文件已经存在,则会询问是否覆盖
-l:把目标文件建立为源文件的硬链接文件,而不是复制源文件
-s:把目标文件建立为源文件的软链接文件,而不是复制源文件
-p:复制后目标文件保留源文件的属性(包括所有者、所属组、权限和时间)
-r:递归复制,用于复制目录
移动文件或改名
mv [选项] 源文件 目标文件
-f:强制覆盖,如果目标文件已经存在,则不询问,直接强制覆盖
-i:交互移动,如果目标文件已经存在,则询问用户是否覆盖(默认选项)
-n:如果目标文件已经存在,则不会覆盖移动,而且不询问用户
-v:显示详细信息
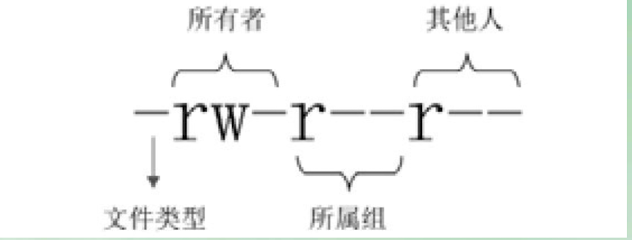
权限位的含义:
第一位代表文件类型
- - 普通文件
- b 块设备文件。这是一种特殊设备文件,存储设备都是这种文件,如分区文件/dev/sda1就是这种文件
- c 字符设备文件。这也是特殊设备文件,输入设备一般都是这种文件,如鼠标、键盘等
- d 目录文件。Linux 中一切皆文件,所以目录也是文件的一种。
- l 软链接文件。
- p 管道符文件。这是一种非常少见的特殊设备文件。
- s 套接字文件。这也是一种特殊设备文件,一些服务支持 Socket 访问,就会产生这样的文件。
第 2~4 位代表文件所有者的权限
- r 代表 read,是读取权限。
- w 代表 write,是写权限。
- x 代表 execute,是执行权限。
如果有字母,则代表拥有对应的权限;如果是”-“,则代表没有对应的权限。
第 5~7 位代表文件所属组的权限,同样拥有”rwx“权限。
第 8~10 位代表其他人的权限,同样拥有”rwx“ 权限。
如果在文件的权限位中含有. 则表示这个文件受 SELinux 的安全规则管理。
修改文件的权限模式
chmod [选项] 权限模式 文件名
-R:递归设置权限,也就是给子目录中的所有文件设定权限
权限模式:
- -u:代表所有者(user)
- -g:代表所属组(group)
- -o:代表其他人(other)
- -a:代表全部身份(all)
赋予方式:
- -+:加入权限
- --:减去权限
- -=:设置权限
权限:
- -r:读取权限
- -w:写权限
- -x:执行权限
数字权限:
- 4:代表“r”权限
- 2:代表“w”权限
- 1:代表“x”权限
修改文件和目录的所有者和所属组
chown [选项] 所有者:所属组 文件或目录
-R:递归设置权限,也就是给子目录中的所有文件设置权限
修改文件和目录的所属组的命令
chgrp 所属组 文件或目录
显示联机帮助手册
man [选项] 命令
-f:查看命令拥有哪个级别的帮助
-k:查看和命令相关的所有帮助
获取命令的帮助
显示 Shell 内置命令的帮助
help 内置命令
查找二进制命令、源文件和帮助文档的命令
whereis [选项] 命令
-b:只查找二进制命令
-m:只查找帮助文档
列出命令的所在路径
which 命令
按照文件名搜索文件
locate [选项] 文件名
-i:忽略大小写
在目录中搜索文件
find 搜索路径 [选项] 搜索内容
按照文件名搜索:
-name:按照文件名搜索
-iname:按照文件名搜索,不区分文件名大小写
-inum:按照 inode 号搜索
按照文件大小搜索:
-size [+-]大小:按照指定大小搜索文件
按照修改时间搜索:
-atime [+-]时间:按照文件访问时间搜索
-mtime [+-]时间:按照文件数据修改时间搜索
-ctime [+-]时间:按照文件状态修改时间搜索
按照权限搜索:
-perm 权限模式:查找文件权限刚好等于“权限模式”的文件
-perm -权限模式:查找文件权限全部包含“权限模式”的文件
-perm +权限模式:查找文件权限包含“权限模式”的任意一个权限的文件
按照所有者和所属组搜索:
-uid 用户 ID:按照用户 ID 查找所有者是指定 ID 的文件
-gid 组 ID:按照用户组 ID 查找所属组是指定 ID 的文件
-user 用户名:按照用户名查找所有者是指定用户的文件
-group 组名:按照组名查找所属组是指定用户组的文件
-nouser:查找没有所有者的文件
按照文件类型搜索:
-type d:查找目录
-type f:查找普通文件
-type l:查找软链接文件
逻辑运算符:
-a:and 逻辑与
-o:or 逻辑或
-not:not 逻辑非
压缩文件或目录
zip [选项] 压缩包名 源文件或源目录
-r:压缩目录
列表、测试和提取压缩文件中的文件
unzip [选项] 压缩包名
-d:指定解压缩位置
压缩文件或目录
gzip [选项] 源文件
-c:将压缩数据输出到标准输出中,可以用于保留源文件
-d:解压缩
-r:压缩目录
-v:显示压缩文件的信息
-数字:用于指定压缩等级,-1 压缩等级最低,压缩比最差;-9 压缩比最高。默认压缩比是-6
解压缩文件或目录
.bz2格式的压缩命令
bzip2 [选项] 源文件
-d:解压缩
-k:压缩时,保留源文件
-v:显示压缩的详细信息
-数字:这个参数和 gzip 命令的作用一样,用于指定压缩等级,-1 压缩等级最低,压缩比最差;-9 压缩比最高
注意,gzip 只是不会打包目录,但是如果使用“-r”选项,则可以分别压缩目录下的每个文件;而 bzip2 命令则根本不支持压缩目录,也没有“-r”选项。
.bz2格式的解压缩命令
bunzip2 [选项] 源文件
-k:解压缩时,保留源文件
打包与解打包命令
打包:
tar [选项] [-f 压缩包名] 源文件或目录
-c:打包
-f:指定压缩包的文件名。压缩包的扩展名是用来给管理员识别格式的,所以一定要正确指定扩展名
-v:显示打包文件过程
“-cvf” 一般是打包习惯用法
解打包:
tar [选项] 压缩包
-x:解打包
-f:指定压缩包的文件名
-v:显示打包文件过程
-t:测试,就是不解打包,只是查看包中有哪些文件
-C:指定解打包位置
“-xcf” 一般是解打包习惯用法
tar [选项] 压缩包 源文件或目录
-z:压缩和解压缩“.tar.gz”格式
-j:压缩和解压缩".tar.bz2"格式
.tar.gz
压缩
tar -zcvf tmp.tar.gz /tmp/
解压缩
tar -zxvf tmp.tar.gz
.tar.bz2
压缩
tar -jcvf tmp.tar.bz2 /tmp/
解压缩
tar -jxvf tmp.tar.bz2
刷新文件系统缓冲区
在关机或重启之前多执行几次 sync 命令。
关机和重启
shutdown [选项] 时间 [警告信息]
-c:取消已经执行的 shutdown 命令
-h:关机
-r:重启
重启
关机
init 0 #关机
init 6 # 重启
setup 是一个简化命令,是 Red Hat 系列专有的命令,其他的 Linux 系列不一定有此命令。
Linux 中查看和临时修改 IP 地址的命令
ifconfig
临时配置 IP 地址
ifconfig eth0192.168.3.1 #使用标准子网掩码
ifconfig eth0192.168.3.1 netmask 255.255.255.0
用于开启和关闭网卡
ifup eth0 #开启网卡
ifdown eth0 #关闭网卡
向网络主机发送 ICMP 请求
ping [选项] IP
-b:后面加入广播地址,用于对整个网段进行探测
-c 次数:用于指定 ping 的次数
-s 字节:指定探测包的大小
输出网络连接、路由表、接口统计、伪装连接和组播成员
netstat [选项]
-a:列出所有网络状态,包括 Socket 程序
-c 秒数:指定每隔几秒刷新一次网络状态
-n:使用 IP 地址和端口号显示,不使用域名与服务名
-p:显示 PID 和程序名
-t:显示使用 TCP 协议端口的连接状况
-u:显示使用 UDP 协议端口的连接状况
-l:仅显示监听状态的连接
-r:显示路由表
向其他用户发送信息
write 用户名 [终端号]
用于给所有登录用户发送信息,包括自己
wall 发送的信息
发送和接收电子邮件
本文原创,才疏学浅,如有纰漏,欢迎指正。如果本文对您有所帮助,欢迎点赞,并期待您的反馈交流,共同成长。
原文地址:
https://www.emanjusaka.top/2024/01/linux-base-command
微信公众号:emanjusaka的编程栈
感知机(Perceptron)是一个二类分类的线性分类模型,属于监督式学习算法。
最终目的:
将不同的样本分类
感知机饮食了多个权重参数,输入的特征向量先是和对应的权重相乘,再加得到的积相加,然后将加权后的特征值送入激活函数,最后得到输出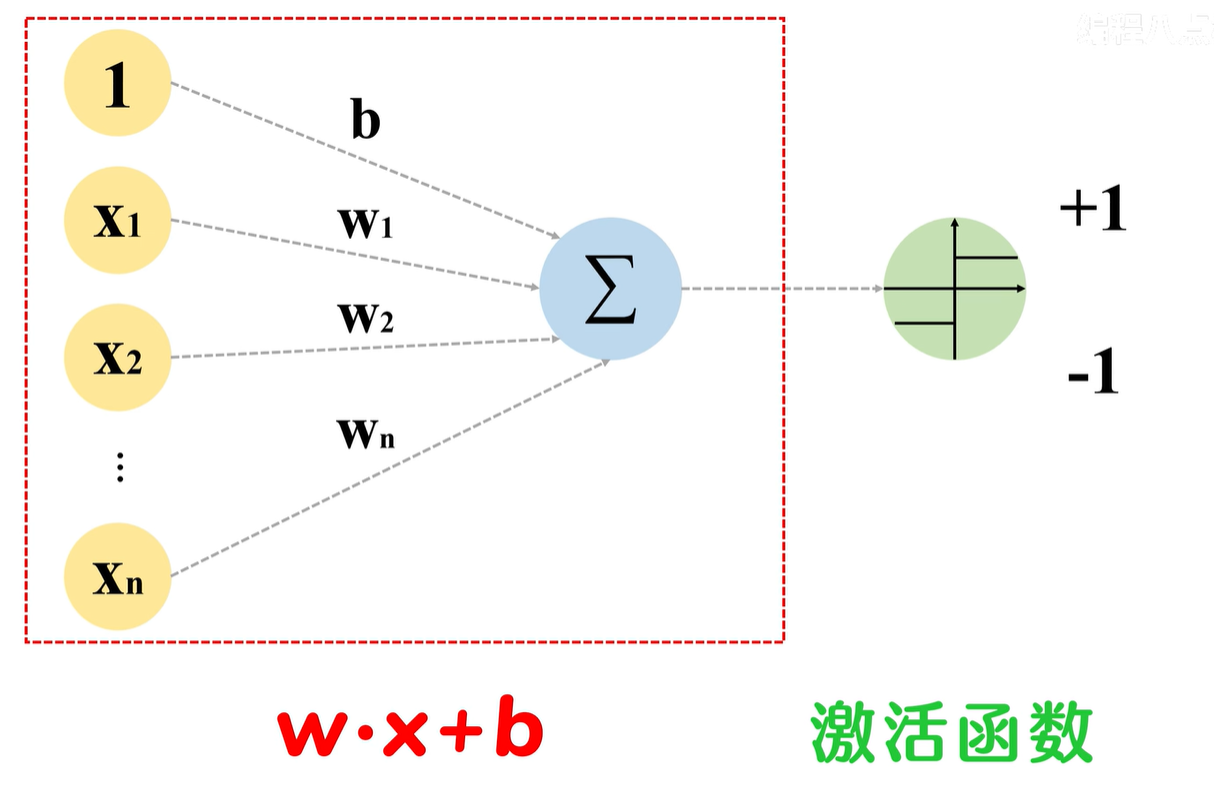
激活函数的前面部分,是线性方程
wx+b
线性方程输出的是连续的值,但对于分类来说,最终需要的类别信息是离散的值,这时候,激活函数就派上用场了,激活函数的存在,是将连续回归值,转变成1 -1 这样的离散值,从而实现类别划分
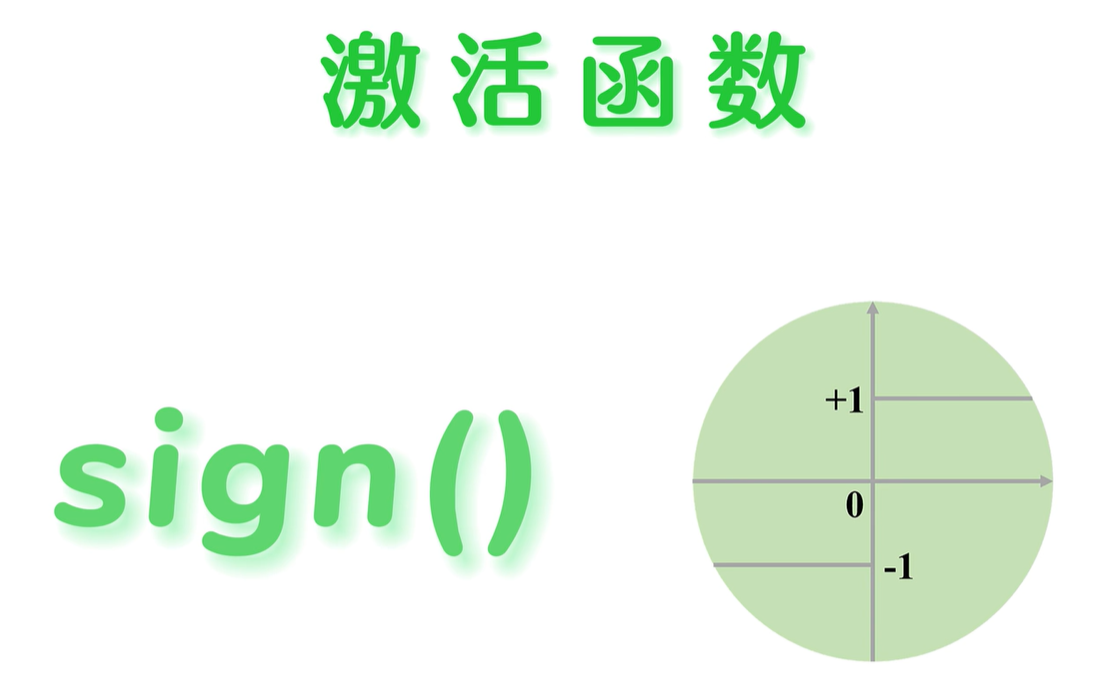
激活函数有很多种,在深度学习中,有着非常重要的作用,在感知机中使用的激活函数是
sin()
,
假如输入到模型中的是一个二维的特征向量(x1,x2),则整个过程可以表示为如下: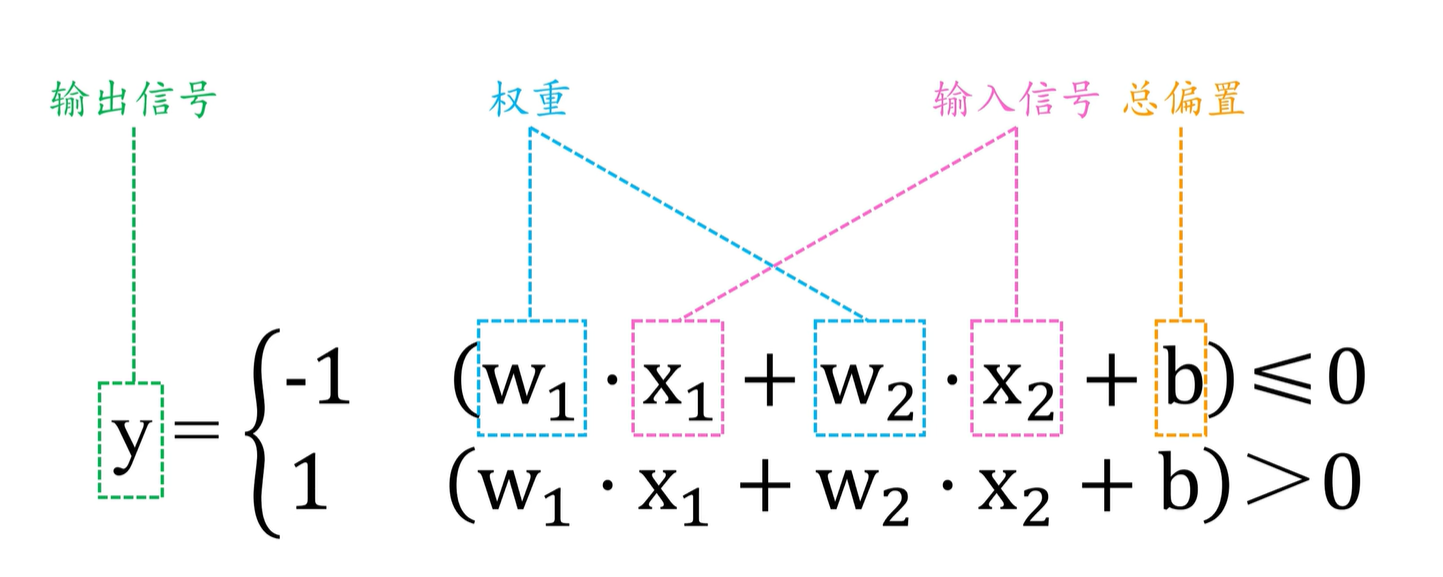
输入的特征向量(x1,x2)先分别和权重(w1,w2)相乘,再将两者相加,最后加上偏置 b ,最终得到的值,和阈值 0 做比较,如果值大于0 则输出1,否则则输出 -1
这样一来,就会划分到了线性方程 wx+b=0 两侧的样本,就分成了正、负两类,用感知机进行二分类,需要先找到能够将正、负样本完全区分开的决策函数
wx+b=0
,如下图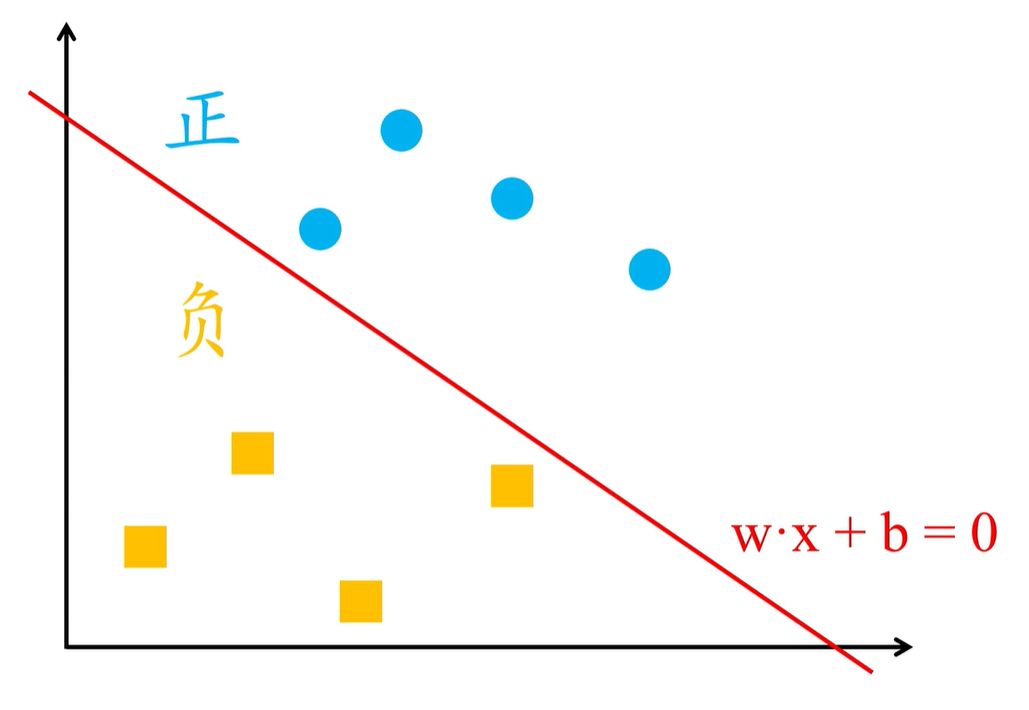
因此就需要确定一个学习策略,也就是定义一个
损失函数
,再通过训练样本,通过减小损失值,不断迭代模型参数,最终找到最优参数 w 和 b ,
损失函数的作用:
用来衡量模型的输出结果,和真实结果之间的偏差,然后根据偏差,修正模型,
回归任务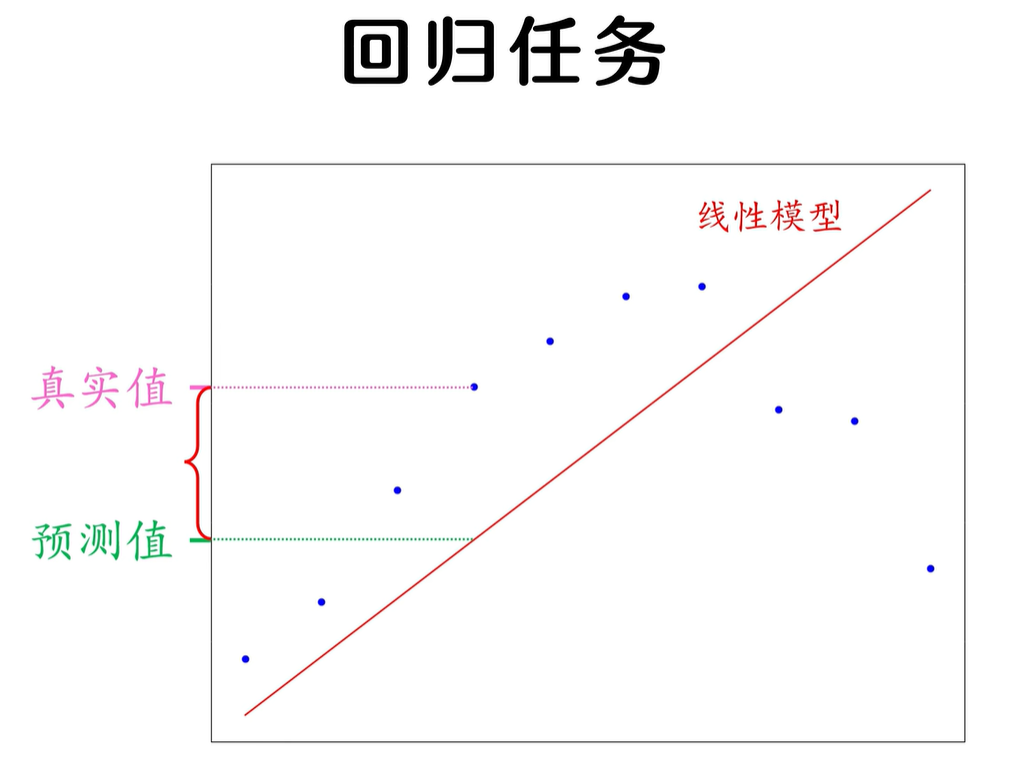
在回归任务中,标签和模型输出都是连续的数值,很容易就能衡量出二者之间的差异。
可对于感知机的分类问题来说,我们又该如何衡量差异呢?一个直观的想法,就是去统计误分类样本的个数作为损失值,误分类的样本个数越多,说明这个该样本空间下的表现越差,但是这样的函数是非连续的,对 w 和 b 不可导,所以我们无法使用这样的损失函数来更新 w 和 b.
为了得到连续可导的损失函数,感知机选择用误分类样本到决策函数的距离,来衡量偏差
这里是单个样本点到决策函数的距离公式
\(\frac {1}{||w||} |w*x_0+b|\)
其中
\(x_0\)
表示样本点的输入
\(||w||\)
等于权重向量
\(w\)
的模长
\(||w|| = \sqrt{(w_1^2 + w_2^2 + ... + w_n^2)}\)
对于感知机分类问题来说,可以用
\(-y_0(w*x_0+b)\)
来代替
\(|w*x_0+b|\)
\(y_0\)
表示样本点
\(x_0\)
对应的标签值。
为什么可以这样代替呢?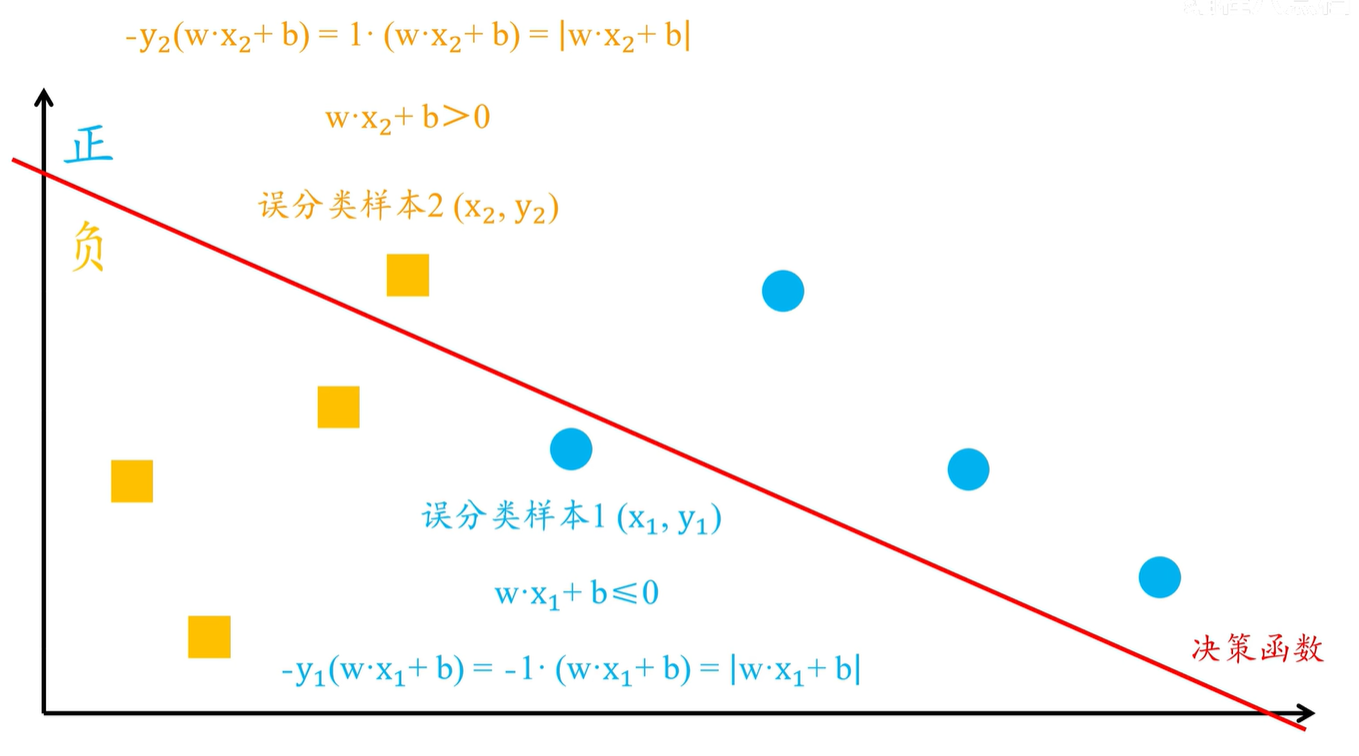
假设有两个误分类样本
样本1
\((x_1,y_1)\)
样本2 $(x_2,y_2)
\(,
样本1 的真实类别为正样本,即:\)
y_1 = 1$,但是在模型中,样本1 却被误分类为了负样本,也就是计算得到的
\(wx1+b \leq 0\)
,那么
\(-y_1(w*x_1+b)=-1(w*x_1+b)\)
最终的结果变成了正值,大小等于
\(|w*x_1+b|\)
样本2 的真实类别为负样本,
\(y_2=-1\)
即在模型中被误分类为了正样本。也就是计算得到的
\(w*x_2+b > 0\)
,那么
\(-y_2(w*x_2+b)\)
就等于
\(1(w*x_2+b)\)
,结果仍为正值,大小等于
\(|w*x_2+b|\)
因此:所有误分类的样本到决策函数的距离和就可以表示为如下
感知机所关心的,是怎么能将两类样本正确地区分开,对样本点到决策函数距离的大小并不关心,如下图,红线和绿线都能将两类样本正确地区分开,所以对感知机来说,这两条线的分类效果是一样的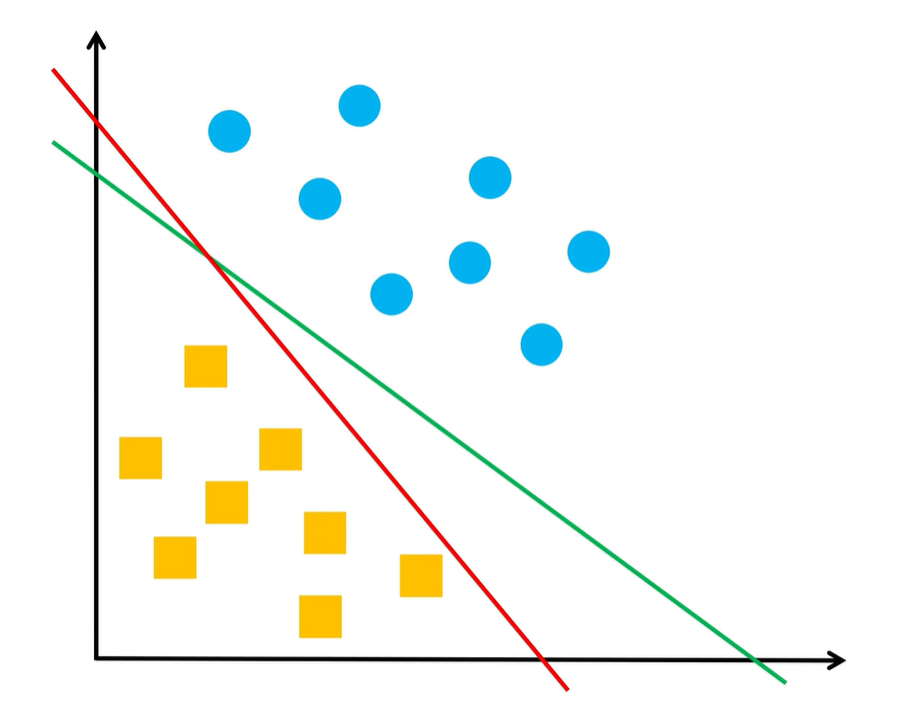
因此,可以把
\(\frac {1}{||w||}\)
去掉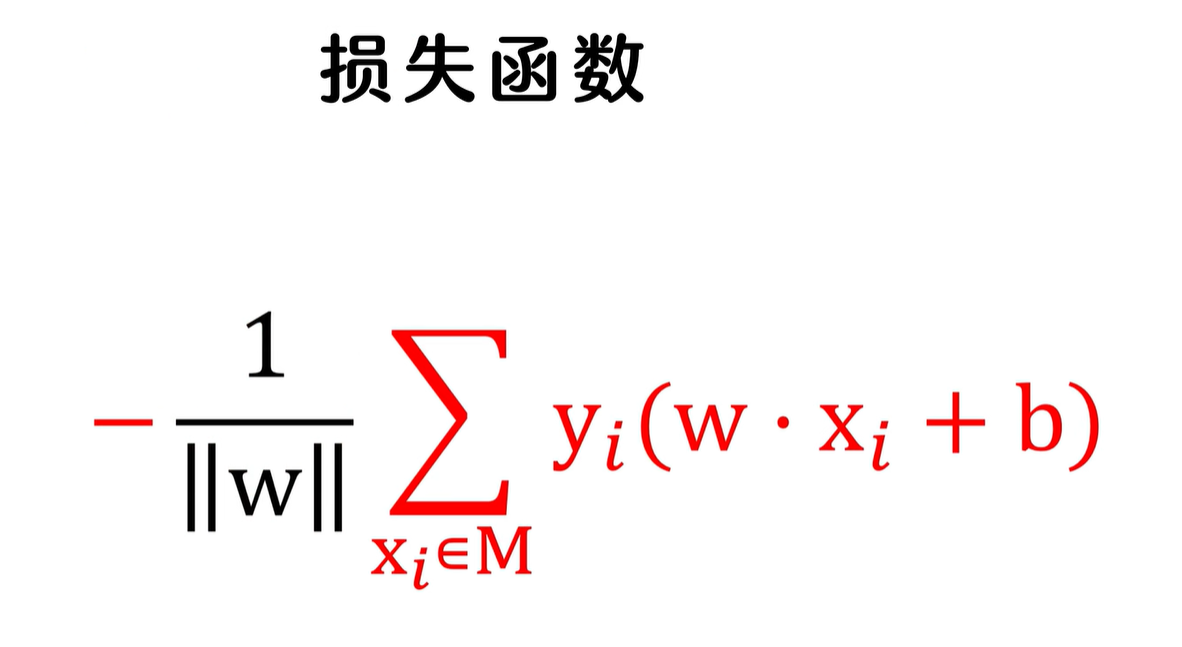
最终,感知机的函数就是 $$ L(w,b) = - \sum_{x_i{\in}M}y_i(w*x_i+b) $$
感知机适用于样本特征简单,且线性可分的二分类问题,因为运算简单,所以计算效率高。
不过在复杂的场景中,感知机往往不能胜任,所以我们在感知机的基础上,又诞生了多层感知机和神经网络
MLA 即 Memory Leak Analyzer,是一个排查内存泄漏的分析器
实现机制是在malloc时记录分配位置信息,在free时记录释放位置信息,通过两者计数作差可得是否存在泄漏
你可以使用提供的脚本
do.sh
来快速使用本代码库
可以使用
./do.sh help
命令
-*- help -*-
usage: ./do.sh [generate] [make] [exec] [clean] [help]
[generate]: -g -G generate
Example usage of the MLA mechanism
$ ./do.sh -g MLA
$ ./do.sh make
Self-validation of MLA mechanisms
$ ./do.sh -g SV
$ ./do.sh make
LOG mechanism implementation analysis
$ ./do.sh -g LOG
$ ./do.sh make
Execute the program to view the results
$ ./do.sh exec
Remove unnecessary code
$ ./do.sh clean
你只需两步就可以开始使用了
1、适配
mla.h
文件中的两个接口malloc和free
/* MLA内部使用的内存管理接口 */
#define MLA_MALLOC(size) malloc(size)
#define MLA_FREE(addr) free(addr)
/* 对外提供使用的内存泄漏检查的分配释放接口 */
#define PORT_MALLOC(size) MlaMalloc(size, __FILENAME__, __func__, __LINE__)
#define PORT_FREE(addr) MlaFree(addr, __FILENAME__, __func__, __LINE__)
2、在你的代码初始化部分加入接口
MlaInit
,在查看内存泄漏信息的地方调用接口
MlaOutput
即可
通过自证清白来演示MLA的用法
$ ./do.sh -g SV
Generate a example version of the MLA file.
执行上述命令后会生成一些文件,这些是
MLA
自证的测试文件
$ ./do.sh make
$ ./do.sh exec
执行上述命令后会输出
MLA
的分析信息,借助
Diff
字段可以清晰看出有没有内存泄漏
在
MLA Verbose
部分可以看到详细的内存分配和释放信息,包括代码文件名、行数、函数以及分配大小、释放次数等信息
-- SV_MlaOutput:
* *
********************************************** Memory Leak Analyzer **********************************************
* *
* M L A N O N E *
-- MlaOutput: *
********************************************** Memory Leak Analyzer **********************************************
* *
Caller Hash Malloc Free Diff
sv_mla.c:316 SV_MlaMalloc 52f06d09 3 3 0
sv_mla.c:214 MlaMallocRecorder 1239e656 1 1 0
sv_mla.c:286 MlaFreeRecorder 49583dd0 2 2 0
*%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% MLA Verbose %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%*
>1
Caller Size Malloc Free Diff
sv_mla.c:316 SV_MlaMalloc 12 3 3 0
*----------------------------------------------------------------------------------------------------------------*
|Verbose: malloc free |
| 1. (12)B - [3] sv_mla.c:357 SV_MlaFree - [3] |
*----------------------------------------------------------------------------------------------------------------*
>2
Caller Size Malloc Free Diff
sv_mla.c:214 MlaMallocRecorder 104 1 1 0
*----------------------------------------------------------------------------------------------------------------*
|Verbose: malloc free |
| 1. (104)B - [1] sv_mla.c:201 MlaDelItem - [1] |
*----------------------------------------------------------------------------------------------------------------*
>3
Caller Size Malloc Free Diff
sv_mla.c:286 MlaFreeRecorder 88 2 2 0
*----------------------------------------------------------------------------------------------------------------*
|Verbose: malloc free |
| 1. (88)B - [2] sv_mla.c:153 MlaProcessFreeNode - [2] |
*----------------------------------------------------------------------------------------------------------------*
欢迎大家使用并
issue
反馈
本文将带领读者探索 Docker 桥接网络模型的内部机制,通过手动实现 veth pair、bridge、iptables 等关键技术,揭示网络背后的运作原理。
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【
探索云原生
】即可订阅

Docker 有多种网络模型,对于单机上运行的多个容器,可以使用缺省的
bridge 网络驱动
。
我们按照下图创建网络拓扑,让容器之间网络互通,从容器内部可以访问外部资源,同时,容器内可以暴露服务让外部访问。
桥接网络的一个拓扑结构如下:
![Docker Bridge 网络拓扑][docker bridge 网络拓扑]
上述网络拓扑实现了:让容器之间网络互通,从容器内部可以访问外部资源,同时,容器内可以暴露服务让外部访问。
根据网络拓扑图可以看到,容器内的数据通过 veth pair 设备传递到宿主机上的网桥上,最终通过宿主机的 eth0 网卡发送出去(或者再通过 veth pair 进入到另外的容器),而接收数据的流程则恰好相反。
这里对本文会用到的相关网络知识做一个简单介绍。
相关笔记:
veth-pair
Veth
是成对出现的两张虚拟网卡,从一端发送的数据包,总会在另一端接收到
。
利用
Veth
的特性,我们可以将一端的虚拟网卡"放入"容器内,另一端接入虚拟交换机。这样,接入同一个虚拟交换机的容器之间就实现了网络互通。
即:通过 veth 来突破 network namespace 的封锁
相关笔记:
Linux bridge
我们可以认为
Linux bridge
就是
虚拟交换机
,连接在同一个
bridge
上的容器组成局域网,不同的
bridge
之间网络是隔离的。
docker network create [NETWORK NAME]
实际上就是创建出虚拟交换机。
交换机是工作在数据链路层的网络设备,它转发的是二层网络包。最简单的转发策略是将到达交换机输入端口的报文,广播到所有的输出端口。当然更好的策略是在转发过程中进行学习,记录交换机端口和 MAC 地址的映射关系,这样在下次转发时就能够根据报文中的 MAC 地址,发送到对应的输出端口。
相关笔记:
iptables
NAT(Network Address Translation),是指网络地址转换。
因为容器中的 IP 和宿主机的 IP 是不一样的,为了保证发出去的数据包能正常回来,需要对 IP 层的源 IP/目的 IP 进行转换。
SNAT
Source Network Address Translation,源地址转换,用于修改数据包中的源地址。
比如上图中的 eth0 ip 是
183.69.215.18
,而容器 dockerA 的 IP 却是
172.187.0.2
。
因此容器中发出来的数据包,
源IP
肯定是
172.187.0.2
,如果就这样不处理直接发出去,那么接收方处理后发回来的响应数据包的
目的IP
自然就会填成
172.187.0.2
,那么我们肯定接收不到这个响应了。
因此在将容器中的数据包通过 eth0 网卡发送出去之前,需要进行 SNAT 把源 ip 改为 eth0 的 ip,也就是
183.69.215.18
。
这样接收方响应时将源 IP
183.69.215.18
作为目的 IP,这样我们才能收到返回的数据。
DNAT
Destination Network Address Translation:目的地址转换,用于修改数据包中的目的地址。
如果发出去做了 SNAT,源 IP 改成了宿主机的
183.69.215.18
,那么回来的响应数据包目的 IP 自然就是
183.69.215.18
,我们(宿主机)可以成功收到这个响应。
但是如果直接把源 IP 是
183.69.215.18
的数据包发到容器里面去,由于容器 IP 是
172.187.0.2
,那肯定不会处理这个包,所以宿主机收到响应包需要进行 DNAT,将目的 IP 地址从
183.69.215.18
改成容器中的
172.187.0.2
。
这样容器才能正常处理该数据。
实验环境 Ubuntu 20.04
首先需要创建对应的容器,veth pair 设备以及 bridge 设备 并分配对应 IP。
todo
从前面的背景知识了解到,容器的本质是
Namespace + Cgroups + rootfs
。因此本实验我们可以仅仅创建出
Namespace
网络隔离环境来模拟容器行为:
$ sudo ip netns add ns1
$ sudo ip netns add ns2
$ sudo ip netns show
ns2
ns1
sudo ip link add veth0 type veth peer name veth1
sudo ip link add veth2 type veth peer name veth3
查看一下:
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether fa:16:3e:9b:9b:33 brd ff:ff:ff:ff:ff:ff
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 9a:45:4c:f9:77:eb brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fe:5a:a1:3b:94:9b brd ff:ff:ff:ff:ff:ff
5: veth3@veth2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 96:d2:e4:ea:9a:1d brd ff:ff:ff:ff:ff:ff
6: veth2@veth3: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
将 Veth 的一端放入“容器”
将 veth 的一端移动到对应的
Namespace
就相当于把这张网卡加入到’容器‘里了。
sudo ip link set veth0 netns ns1
sudo ip link set veth2 netns ns2
查看宿主机上的网卡
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether fa:16:3e:9b:9b:33 brd ff:ff:ff:ff:ff:ff
3: veth1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 9a:45:4c:f9:77:eb brd ff:ff:ff:ff:ff:ff link-netns ns1
5: veth3@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 96:d2:e4:ea:9a:1d brd ff:ff:ff:ff:ff:ff link-netns ns2
发现少了两个,然后进入容器对应
Namespace
查看一下容器中的网卡:
$ sudo ip netns exec ns1 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fe:5a:a1:3b:94:9b brd ff:ff:ff:ff:ff:ff link-netnsid 0
$ sudo ip netns exec ns2 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: veth2@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8e:6a:e4:a0:50:ce brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到,
veth0
和
veth2
确实已经放到“容器”里去了。
一般使用
brctl
进行管理,不是自带的工具,需要先安装一下:
sudo apt-get install bridge-utils
创建 bridge
br0
:
sudo brctl addbr br0
sudo brctl addif br0 veth1
sudo brctl addif br0 veth3
查看接入效果:
$ sudo brctl show
bridge name bridge id STP enabled interfaces
br0 8000.361580fa3c8b no veth1
veth3
可以看到,两个网卡
veth1
和
veth3
已经“插”在
bridge
上。
至此,veth pair 已经一端在容器里,一端在宿主机网桥上了,大致拓扑结构完成。
sudo ip addr add 172.18.0.1/24 dev br0
sudo ip link set br0 up
docker0 容器:
sudo ip netns exec ns1 ip addr add 172.18.0.2/24 dev veth0
sudo ip netns exec ns1 ip link set veth0 up
docker1 容器:
sudo ip netns exec ns2 ip addr add 172.18.0.3/24 dev veth2
sudo ip netns exec ns2 ip link set veth2 up
sudo ip link set veth1 up
sudo ip link set veth3 up
至此,整个拓扑结构搭建完成,且所有设备都分配好 ip 并上线。
测试从容器
docker0
ping 容器
docker1
,测试之前先用 tcpdump 抓包,等会好分析:
sudo tcpdump -i br0 -n
在新窗口执行 ping 命令:
sudo ip netns exec ns1 ping -c 3 172.18.0.3
br0
上的抓包数据如下:
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on br0, link-type EN10MB (Ethernet), capture size 262144 bytes
12:35:18.285705 ARP, Request who-has 172.18.0.3 tell 172.18.0.2, length 28
12:35:18.285903 ARP, Reply 172.18.0.3 is-at e2:31:15:64:bd:39, length 28
12:35:18.285908 IP 172.18.0.2 > 172.18.0.3: ICMP echo request, id 13829, seq 1, length 64
12:35:18.286034 IP 172.18.0.3 > 172.18.0.2: ICMP echo reply, id 13829, seq 1, length 64
12:35:19.309392 IP 172.18.0.2 > 172.18.0.3: ICMP echo request, id 13829, seq 2, length 64
12:35:19.309589 IP 172.18.0.3 > 172.18.0.2: ICMP echo reply, id 13829, seq 2, length 64
12:35:20.349350 IP 172.18.0.2 > 172.18.0.3: ICMP echo request, id 13829, seq 3, length 64
12:35:20.349393 IP 172.18.0.3 > 172.18.0.2: ICMP echo reply, id 13829, seq 3, length 64
12:35:23.309404 ARP, Request who-has 172.18.0.2 tell 172.18.0.3, length 28
12:35:23.309517 ARP, Reply 172.18.0.2 is-at 2e:93:7e:33:b0:ed, length 28
可以看到,先是
172.18.0.2
发起的
ARP
请求,询问
172.18.0.3
的
MAC
地址,然后是
ICMP
的请求和响应,最后是
172.18.0.3
的 ARP 请求。
因为接在同一个 bridge
br0
上,所以是二层互通的局域网。
同样,从容器
docker1
ping
容器
docker0
也是通的:
sudo ip netns exec ns2 ping -c 3 172.18.0.2
在“容器”
docker0
内启动服务,监听 80 端口:
sudo ip netns exec ns1 nc -lp 80
在宿主机上执行 telnet,可以连接到
docker0
的 80 端口:
$ telnet 172.18.0.2 80
Trying 172.18.0.2...
Connected to 172.18.0.2.
Escape character is '^]'.
可以联通。
这部分稍微复杂一些,需要配置 NAT 规则。
1)配置容器内路由
需要配置容器内的路由,这样才能把网络包从容器内转发出来。
具体就是:
将 bridge 设置为“容器”的缺省网关
。让非
172.18.0.0/24
网段的数据包都路由给
bridge
,这样数据就从“容器”跑到宿主机上来了。
sudo ip netns exec ns1 ip route add default via 172.18.0.1 dev veth0
sudo ip netns exec ns2 ip route add default via 172.18.0.1 dev veth2
查看“容器”中的路由规则
$ sudo ip netns exec ns1 ip route
default via 172.18.0.1 dev veth0
172.18.0.0/24 dev veth0 proto kernel scope link src 172.18.0.2
可以看到,非 172.18.0.0 网段的数据都会走默认规则,也就是发送给网关 172.18.0.1。
2)宿主机开启转发功能并配置转发规则
在宿主机上配置内核参数,允许 IP forwarding,这样才能把网络包转发出去。
sudo sysctl net.ipv4.conf.all.forwarding=1
还有就是要配置 iptables FORWARD 规则
首先确认
iptables FORWARD
的缺省策略:
$ sudo iptables -t filter -L FORWARD
Chain FORWARD (policy ACCEPT)
target prot opt source destination
一般都是 ACCEPT,如果如果缺省策略是
DROP
,需要设置为
ACCEPT
:
sudo iptables -t filter -P FORWARD ACCEPT
3)宿主机配置 SNAT 规则
sudo iptables -t nat -A POSTROUTING -s 172.18.0.0/24 ! -o br0 -j MASQUERADE
上面的命令的含义是:在
nat
表的
POSTROUTING
链增加规则,当数据包的源地址为
172.18.0.0/24
网段,出口设备不是
br0
时,就执行
MASQUERADE
动作。
MASQUERADE
也是一种源地址转换动作,它会动态选择宿主机的一个 IP 做源地址转换,而
SNAT
动作必须在命令中指定固定的 IP 地址。
测试能否访问外网:
$ sudo ip netns exec ns1 ping -c 3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=80 time=21.1 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=89 time=19.5 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=86 time=19.2 ms
外部访问容器需要进行 DNAT,把目的 IP 地址从宿主机地址转换成容器地址。
sudo iptables -t nat -A PREROUTING ! -i br0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.18.0.2:80
上面命令的含义是:在
nat
表的
PREROUTING
链增加规则,当输入设备不是
br0
,目的端口为 80 时,做目的地址转换,将宿主机 IP 替换为容器 IP。
测试一下
在“容器”docker0 内启动服务:
sudo ip netns exec ns1 nc -lp 80
在
和宿主机同一个局域网的远程主机
访问宿主机 IP:80
telnet 192.168.2.110 80
确认可以访问到容器内启动的服务。
不过由于只在
PREROUTING
链上做了 DNAT,因此直接在宿主机上访问是不行,需要本机访问的话可以添加下面这个 iptables 规则,直接在 OUTPUT 链上增加 DNAT 规则:
这样其他节点来的流量和本机直接访问流量都可以正常 DNAT 了。
sudo iptables -t nat -A OUTPUT -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.18.0.2:80
添加后再本机直接测试:
telnet 192.168.2.110 80
这下可以成功连上了。
删除虚拟网络设备
sudo ip link set br0 down
sudo brctl delbr br0
sudo ip link del veth1
sudo ip link del veth3
iptablers
和
Namesapce
的配置在机器重启后被清除。
本文主要通过 Linux 提供的各种虚拟设备以及 iptables 模拟出了
docker bridge 网络模型
,并测试了几种场景的网络互通。实际上
docker network
就是使用了
veth
、
Linux bridge
、
iptables
等技术,帮我们创建和维护网络。
具体分析一下:
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【
探索云原生
】即可订阅