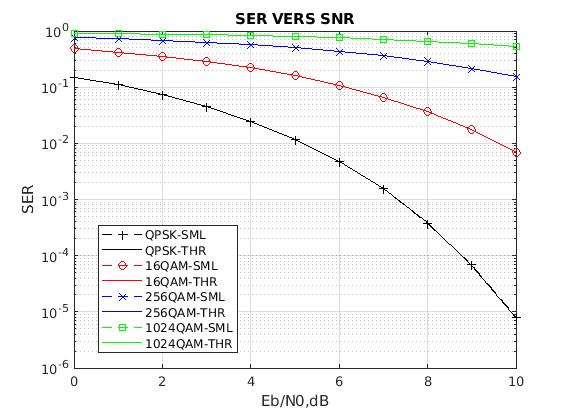
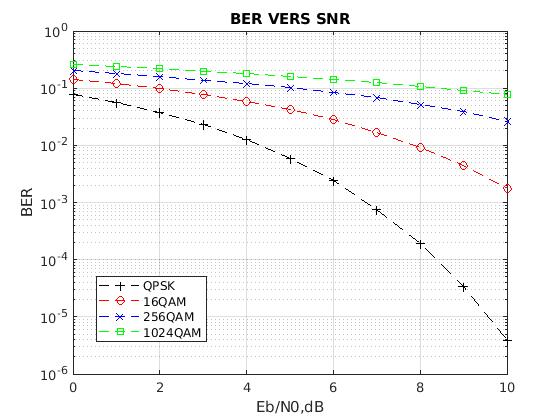
1、环境设置:
此环节将加载实现笔记本无缝功能的基本模块,包括NumPy、Pandas和TensorFlow等库。此外,它还建立了关键的环境常数,如图像尺寸和学习率,这对后续分析和模型训练至关重要。
# General
import os
import keras
import numpy as np
import pandas as pd
import tensorflow as tf
# Data
import plotly.express as px
import matplotlib.pyplot as plt
# Data Preprocessing
import tensorflow.data as tfds
from sklearn.model_selection import train_test_split
# Model
from keras.applications import VGG16
from keras.applications import Xception, InceptionV3
from keras.applications import ResNet50V2, ResNet152V2
from keras.applications import MobileNetV3Small, MobileNetV3Large
# Model training
from keras import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten, GlobalAveragePooling2D
from keras.layers import InputLayer
# Model Callbacks
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
# Setting constants for reproducibility
np.random.seed(42)
tf.random.set_seed(42)
# Constants
BATCH_SIZE = 32
IMAGE_SIZE = 224
2、加载和处理UTKFace数据集
在Kaggle上发现的UTKFace数据集是一个全面的面部图像集合,专门用于年龄和性别识别任务。它包括2万多张人脸图像,并附有年龄、性别和种族的注释。这些图像是多样化的,代表了不同的种族、年龄和性别,使其成为机器学习和计算机视觉研究的广泛而有价值的资源。
UTKFace数据集中的每张图像都标有人的年龄,范围从0到116岁,以及他们的性别,分类为男性或女性。
此外,数据集还包括有关个人种族的信息,允许进行更细致的分析和应用。
研究人员和开发人员经常利用该数据集来训练和测试面部识别技术中年龄估计、性别分类和其他相关任务的算法。它的大尺寸和多样化的面部特征表示使其成为探索和开发计算机视觉领域模型的热门选择。
# Initialize the directory path
dir_path = "/kaggle/input/utkface-new/UTKFace/"
image_paths = os.listdir(dir_path)
# Initialize a Gender Mapping
gender_mapping = ["Male", "Female"]
# Choose and load an image randomly
rand_image_path = np.random.choice(image_paths)
rand_image = plt.imread(dir_path + rand_image_path)/255.
sample_age, sample_gender, *_ = rand_image_path.split("_")
print(f"Total number of images : {len(image_paths)}")
print(f"Sample Image path : {rand_image_path}")
print(f"Sample Age : {sample_age}")
print(f"Sample Gender : {gender_mapping[int(sample_gender)]}\n")
# Show the image
plt.figure(figsize = (5,5))
plt.title("Sample Image")
plt.imshow(rand_image)
plt.axis("off")
plt.show()
结果:
Total number of images : 23708
Sample Image path : 1_0_3_20161220222642427.jpg.chip.jpg
Sample Age : 1
Sample Gender : Male
处理23,708张图像需要使用诸如批处理或使用图像生成器之类的内存高效策略来避免压倒性的内存限制。此外,描绘年龄和性别的图像路径结构(第一部分表示年龄,第二部分表示性别(0表示男性,1表示女性))为后续分析和分类提供了重要信息。
仔细管理这些路径将有助于根据年龄和性别属性进行有针对性的数据处理。
# Initialize a male counter variable
male_count = 0
# Initialize variable to store all the ages.
ages = []
# Loop over the paths and check for male images.
for path in image_paths:
path_split = path.split("_")
if "0" == path_split[1]:
male_count += 1
ages.append(int(path_split[0]))
# Computee total female counts
female_count = len(image_paths) - male_count
# Visualizing The Class Imbalance
pie_chart = px.pie(
names = gender_mapping,
values = [male_count, female_count],
hole = 0.4,
title = "Gender Distribution (Donut Chart)",
height = 500
)
pie_chart.show()
bar_graph = px.bar(
y = gender_mapping,
x = [male_count, female_count],
title = "Gender Distribution (Bar Graph)",
color = gender_mapping,
height = 500
)
bar_graph.update_layout(
yaxis_title = "Gender",
xaxis_title = "Frequency Count"
)
bar_graph.show()


我们的数据集似乎显示出轻微的类别不平衡,男性图像的数量高于女性图像——大约52%的男性和48%的女性代表。虽然这种不平衡不足以显著影响模型的准确性,但值得注意的是,要全面了解数据集对男性图像的偏见。管理这种轻微的偏差可以提高模型的稳健性和预测的公平性,尽管它目前对准确性的影响可能有限。
# Histogram
fig = px.histogram(sorted(ages), title = "Age Distribution")
fig.update_layout(
xaxis_title = "Age",
yaxis_title = "Value Counts"
)
fig.show()
# Violin Plot
fig = px.violin(x = sorted(ages), title = "Age Distribution")
fig.update_layout(
xaxis_title = "Age",
yaxis_title = "Distribution"
)
fig.show()
# Box Plot
fig = px.box(x = sorted(ages), notched=True, title = "Age Distribution")
fig.update_layout(
xaxis_title = "Age",
)
fig.show()


直方图分析在我们的数据集分布中显示了两个突出的峰值。第一个簇包含年龄从0到12岁左右的人,而第二个簇包含16到45岁左右的人。
有趣的是,这些峰值表现出不同的强度,后一个峰值明显更强。具体来说,我们在1岁左右观察到大约1123张图像的峰值,而在26岁时观察到大约2197张图像的峰值。
值得注意的是,虽然我们的数据集确实包含了一些80岁以上的老年人的图像,但这些事件构成了较小的峰值。总的来说,这种分布表明了对年轻群体的潜在偏见,强调了数据集强调的是描绘早期和成年期个体的图像,而不是老年。
从小提琴图和箱形图中获得的见解证实了我们从直方图中得出的初步观察结果。数据明显分为两个子集:一个是非常小的孩子的图像,证实了直方图在1岁左右的峰值,另一个是26到45岁之间的成年人的大量集中。小提琴的情节特别强调这种双峰分布。
在仔细检查箱形图后,向左侧的明显挤压与我们在直方图中观察到的相呼应。这种压缩源于较年长年龄范围内的数值分布拉长和相对稀疏。它重申了我们的理解,即数据集显示出对年轻人的轻微倾斜。
这种固有的偏见可能确实会影响我们模型的准确性,因为它倾向于更有效地从大量的年轻人口统计数据中学习和概括,而可能忽略了老年群体中普遍存在的模式或细微差别。解决这一问题对于确保我们的模式在不同年龄段的公平和全面的学习至关重要。
# SHuffling the Images
np.random.shuffle(image_paths)
# Split data into training, testing and validation set
train_images, test_images = train_test_split(
image_paths,
train_size = 0.9,
test_size = 0.1
)
train_images, valid_images = train_test_split(
image_paths,
train_size = 0.9,
test_size = 0.1
)
print(f"Training Size : {len(train_images)}")
print(f"Testing Size : {len(test_images)}")
# Extract age and gender
train_ages = [int(path.split("_")[0]) for path in train_images]
train_genders = [int(path.split("_")[1]) for path in train_images]
valid_ages = [int(path.split("_")[0]) for path in valid_images]
valid_genders = [int(path.split("_")[1]) for path in valid_images]
test_ages = [int(path.split("_")[0]) for path in test_images]
test_genders = [int(path.split("_")[1]) for path in test_images]
Training Size : 21337
Testing Size : 2371
由于我们有大量的图像,因此使用Tensorflow数据集进行高效处理会更好。
def show_image(image, show=False):
"""
Displays the provided image without axis.
Args:
- image (array-like): The image data to be displayed.
- show (bool): If True, displays the image immediately. Defaults to False.
Returns:
- None
"""
plt.imshow(image)
plt.axis("off")
if show:
plt.show()
def preprocess_age_data(image_path, age, gender, dir_path=dir_path, IMAGE_SIZE = IMAGE_SIZE):
"""
Preprocesses an image for analysis by extracting age and gender from the image path,
loading and decoding the image, resizing it to (IMAGE_SIZE,IMAGE_SIZE), normalizing pixel values,
and returning the preprocessed image along with age and gender labels.
Args:
- image_path (str): The path to the image file.
- dir_path (str): The directory path where the image is located. Defaults to `dir_path`.
Returns:
- tuple: A tuple containing the preprocessed image as a TensorFlow tensor,
the age (int), and the gender (int) extracted from the image path.
"""
# Load the Image
image = tf.io.read_file(dir_path + image_path)
image = tf.io.decode_jpeg(image)
# Resize and Normalize the Image
image = tf.image.resize(image, (IMAGE_SIZE, IMAGE_SIZE))
image = image / 255.
image = tf.cast(image, tf.float32)
return image, age
def preprocess_gender_data(image_path, age, gender, dir_path=dir_path, IMAGE_SIZE = IMAGE_SIZE):
"""
Preprocesses an image for analysis by extracting age and gender from the image path,
loading and decoding the image, resizing it to (IMAGE_SIZE,IMAGE_SIZE), normalizing pixel values,
and returning the preprocessed image along with age and gender labels.
Args:
- image_path (str): The path to the image file.
- dir_path (str): The directory path where the image is located. Defaults to `dir_path`.
Returns:
- tuple: A tuple containing the preprocessed image as a TensorFlow tensor,
the age (int), and the gender (int) extracted from the image path.
"""
# Load the Image
image = tf.io.read_file(dir_path + image_path)
image = tf.io.decode_jpeg(image)
# Resize and Normalize the Image
image = tf.image.resize(image, (IMAGE_SIZE, IMAGE_SIZE))
image = image / 255.
image = tf.cast(image, tf.float32)
return image, gender
# Obtain training, testing and validation datasets
train_ds = tfds.Dataset.from_tensor_slices((train_images, train_ages, train_genders)).shuffle(2000)
train_age_ds = train_ds.map(preprocess_age_data, num_parallel_calls=BATCH_SIZE).batch(BATCH_SIZE).prefetch(tfds.AUTOTUNE)
train_gender_ds = train_ds.map(preprocess_gender_data, num_parallel_calls=BATCH_SIZE).batch(BATCH_SIZE).prefetch(tfds.AUTOTUNE)
valid_ds = tfds.Dataset.from_tensor_slices((valid_images, valid_ages, valid_genders)).shuffle(2000)
valid_age_ds = valid_ds.map(preprocess_age_data, num_parallel_calls=BATCH_SIZE).batch(BATCH_SIZE).prefetch(tfds.AUTOTUNE)
valid_gender_ds = valid_ds.map(preprocess_gender_data, num_parallel_calls=BATCH_SIZE).batch(BATCH_SIZE).prefetch(tfds.AUTOTUNE)
test_ds = tfds.Dataset.from_tensor_slices((test_images, test_ages, test_genders)).shuffle(500)
test_age_ds = test_ds.map(preprocess_age_data, num_parallel_calls=BATCH_SIZE).batch(BATCH_SIZE).prefetch(tfds.AUTOTUNE)
test_gender_ds = test_ds.map(preprocess_gender_data, num_parallel_calls=BATCH_SIZE).batch(BATCH_SIZE).prefetch(tfds.AUTOTUNE)
plt.figure(figsize=(15, 10))
for images, ages, genders in train_ds.batch(BATCH_SIZE).take(1):
for index in range(len(images)):
image = tf.io.read_file(dir_path + images[index])
image = tf.io.decode_jpeg(image)
plt.subplot(4, 8, index + 1)
plt.imshow(image)
plt.title(f"Age: {ages[index]}\nGender: {gender_mapping[genders[index]]}")
plt.axis("off")
plt.tight_layout()
plt.show()

3、骨干架构比较
当我们的目标是为最终模型建立一个最优的架构时,我们正在探索各种候选模型来作为基础架构。这个过程包括评估多个主干,以全面衡量它们的性能。
通过进行比较分析,我们试图辨别每个骨干架构的优点和缺点。我们的目标是确定最合适的骨干体系结构,它将作为我们最终模型的健壮基础。随后,将采用微调对选定的骨干进行细化和定制,确保开发出优化有效的模型。
# Initializing all the Backbones
backbones = [
(
"VGG16",
VGG16(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
(
"ResNet50V2",
ResNet50V2(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
(
"ResNet152V2",
ResNet152V2(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
(
"Xception",
Xception(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
(
"InceptionV3",
InceptionV3(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
(
"MobileNetV3Small",
MobileNetV3Small(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
(
"MobileNetV3Large",
MobileNetV3Large(
input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3),
weights = "imagenet",
include_top = False
)
),
为了找到最好的骨干架构,我们首先需要训练一个相当小的网络进行几次迭代,然后我们将看到哪个骨干架构将更快更好地带来鲁棒性能。
请注意
在进行了几次实验之后,很明显,为年龄和性别预测建立一个单一的模型并不能产生最佳结果。尽管在预测年龄方面取得了显著的成绩,但性别预测的准确性并不理想。因此,更有效的方法是采用两种不同的模型来预测年龄和性别。
在这个修改后的策略中,模型的主干保持不变。然而,重点是在年龄预测的基础上确定表现最好的骨干。由于准确的年龄预测涉及到回归,这是一个更复杂的任务,因此预期在年龄预测中表现出色的骨干在性别预测中也会表现良好。
通过采用不同的年龄和性别预测模型,我们可以根据每个任务提出的独特挑战来定制架构和训练策略。这种专门的方法允许对每个模型进行独立的优化,从而提高整体性能。这种任务的解耦承认了年龄和性别预测的微妙本质,并允许对模型进行微调,以解决与每种预测类型相关的具体挑战。
BACKBONE_HISTORIES = {}
for (name, backbone) in backbones:
print(f"Testing : {name}")
# Freeze the Model weights
backbone.trainable = False
# Creating a base model
model = keras.Sequential([
InputLayer((IMAGE_SIZE, IMAGE_SIZE, 3), name = "InputLayer"),
backbone,
Dropout(0.2, name = "SlightDropout"),
Flatten(name = "FlattenEmbeddings"),
Dense(1, name = "Age")
])
# Train the model for few iterations
model.compile(
loss = ["mae"],
optimizer = "adam",
weighted_metrics=[]
)
history = model.fit(
train_age_ds,
validation_data = valid_age_ds,
epochs = 5,
batch_size = BATCH_SIZE
)
BACKBONE_HISTORIES[name] = pd.DataFrame(history.history)
cls()
print("\n")
metric = "loss"
plt.figure(figsize=(15, 5))
for i, sub in enumerate(['Train', 'Val']):
plt.subplot(1, 2, i+1)
plt.title(f"{sub} {metric} Plot")
for name, history in BACKBONE_HISTORIES.items():
plt.plot(history[metric] if sub=="Train" else history[f"val_{metric}"], label = name)
plt.xlabel("Epochs")
plt.ylabel(metric.title())
plt.legend()
plt.grid()
plt.tight_layout()
plt.show()

在仔细检查年龄模型学习曲线后,可以明确排除某些骨干,特别是与MobileNet相关的骨干。他们一贯的糟糕表现使他们不适合做候选人。
VGG16是最有希望的主干,在训练和验证损失方面都表现出稳定的下降,收敛在平均绝对误差8.0左右。这种一致性表明了鲁棒性,使VGG16成为一个有利的选择。
虽然其他一些模型,如Inception和exception,产生较低的训练损失,但它们在训练和验证曲线之间的相当大的差距表明潜在的不稳定性。考虑到速度和健壮性之间的权衡,盗梦空间作为一个值得称赞的选择脱颖而出。
其平滑的增长轨迹和相对的可预测性使其成为一个合适的折衷方案,特别是与异常的更不稳定的性能相比时。这种细致入微的评估指导了选择过程,确保选择的主干与所需的模型特征保持一致。
BACKBONE_HISTORIES = {}
for (name, backbone) in backbones:
print(f"Testing : {name}")
# Freeze the Model weights
backbone.trainable = False
# Creating a base model
model = keras.Sequential([
InputLayer((IMAGE_SIZE, IMAGE_SIZE, 3), name = "InputLayer"),
backbone,
Dropout(0.2, name = "SlightDropout"),
Flatten(name = "FlattenEmbeddings"),
Dense(1, activation="sigmoid", name = "Age")
])
# Train the model for few iterations
model.compile(
loss = ["binary_crossentropy"],
optimizer = "adam",
metrics = ['accuracy'],
weighted_metrics=[]
)
history = model.fit(
train_gender_ds,
validation_data = valid_gender_ds,
epochs = 5,
batch_size = BATCH_SIZE
)
BACKBONE_HISTORIES[name] = pd.DataFrame(history.history)
cls()
print("\n")
metric = "accuracy"
plt.figure(figsize=(15, 5))
for i, sub in enumerate(['Train', 'Val']):
plt.subplot(1, 2, i+1)
plt.title(f"{sub} {metric} Plot")
for name, history in BACKBONE_HISTORIES.items():
plt.plot(history[metric] if sub=="Train" else history[f"val_{metric}"], label = name)
plt.xlabel("Epochs")
plt.ylabel(metric.title())
plt.legend()
plt.grid()
plt.tight_layout()
plt.show()

在评估性别预测准确性的模型时,一个值得注意的消除包括MobileNet模型,它一直表现出较差的性能。
深入研究训练和验证精度曲线揭示了一个杰出的表演者:ResNet152V2模型,由独特的绿色曲线表示。该模型达到了最高的训练精度和验证精度,将其定位为一个引人注目的选择。
然而,必须解决所有模型的训练和验证精度之间的巨大差异。这强调了在最终模型创建期间需要更复杂的基线模型,合并多个层以更好地处理这些差异。
尽管考虑到这一点,ResNet152V2仍然保持着突出的地位,拥有出色的训练和验证性能。值得注意的是,ResNet50V2在训练性能上与ResNet152V2非常接近,尽管在验证精度上有所欠缺。
4、VGG16 Age Network