vivo 短视频体验与成本优化实践
作者:来自 vivo 互联网短视频研发团队
本文根据蔡创业、马运杰老师在“2023 vivo开发者大会"现场演讲内容整理而成。
在线点播场景,播放体验提升与成本优化是同等重要的两件事,并在部分场景体验优化与成本优化存在一定的互斥关系。vivo短视频深入分析播放链路的每个环节、并结合大数据统计,探索出了多种的体验优化策略;同时针对成本优化,上线了转码、PCDN、共享闲时带宽等多种策略用于降低带宽成本。基于技术优化和业务发展的要求,vivo短视频还上线了系统性的监控体系,对播放体验、带宽成本进行了多维度的监控。
一、业务介绍
vivo短视频项目的业务架构,从链路上来说,主要包括:
内容生产,主要包括拍摄、导入、剪辑以及作品上传
视频处理,包括画质增强、转码、压缩等
分发
消费,包括预加载、视频播放
除此之外,我们还设计了若干个子系统,其中比较重要的有:
日志收集,主要用于收集用户主动反馈问题。
监控统计,主要用于监控线上核心指标,为后续优化提供方向。
AB测试,主要用于新功能验证。
技术架构的最终目的是为了给用户呈现一个有着良好体验的产品,同时又兼顾到开发、运营成本。通过我们产品内置的意见反馈、大数据统计以及用户调研,我们发现/用户对vivo短视频的反馈主要集中在播放卡顿、不流畅、画质不清晰上面,从成本方面,我们的主要压力来自于CDN。
这些也就是本文的主题,即:如何做到既要播放体验好,又要业务成本低。接下来,将分别介绍一些在播放流畅度以及成本优化相关的探索和实践。

二、体验优化
2.1 播放链路拆解
对于在线点播场景来说,影响用户体验的环节主要在视频开播以及播放过程。首先,在起播阶段,应尽力做到首帧零耗时,当用户观看视频时应直接展示视频画面而不是出现等待过程。
我们对开播过程做了拆解和监控,在无任何优化策略的场景下,网络连接环节耗时占比30%,下载环节占比15%, 解封装、解复用环节占比15%。
其次,在视频播放过程中,应做到流畅播放不卡顿,这就需要合理的预加载策略、码率控制以及下载策略。
通过以上的分析,确定了我们4个重点
优化方向
:
建连优化,通过连接复用、保活等方式减少在连接环节的耗时
分片下载,通过优化下载架构提升下载速度以及成功率
预渲染,把耗时的解封装、解复用、解码等环节前置
数据预加载,通过预加载减少在下载环节的耗时
在此基础上,我们上线了数据监控体系,对开播性能、优化策略、视频基础信息、画质、带宽利用率等方面进行了详细的监控。

2.2 建连优化
通过以下4个策略来降低建连环节的耗时:
在应用冷启动以及视频播放时,通过连接复用,减少了DNS解析、SSL以及TCP连接环节的耗时。
在视频播放过程中,用户可能因为某些原因暂停视频,比如把应用切到后台,几分钟后再打开 应用,这种情况下可能出现连接被断开,当恢复播放时需要重新建连,从而导致播放卡顿的问题。通过连接保活,可确保再次播放时视频快速下载、快速 开播。
传统的local dns可能会出现解析DNS劫持、解析缓慢等问题,通过http dns,可有效应对DNS劫持以及解析缓慢的问题,为了应对复杂多变的网络环境,我们还通过在线配置的方式,支持多种dns解析以及降级策略。
当DNS解析失败时,通过服务端下发的IP实现直连,从而提升连接成功率。
以上就是我们在网络连接环节的一些优化策略,下面介绍我们在视频下载环节的优化。

2.3 分片下载
为了实现预加载,即在视频播放之前把在线视频提前下载到本地,我们在播放器和CDN直接增加了一个本地代理的服务,播放的网络请求都由本地代理服务响应,本地代理服务再向CDN发起请求。在弱网下测试,我们发现
卡顿情况比较严重,
主要是存在不必要的网速竞争,并且常规单线程下载效率低于多线程并发下载。为此,我们通过分析协议以及多次实验,最终确定了全新的下载方式,即首个视频起播时使用单线程,后续的视频下载以及预加载都通过多线程分片请求完成。
同时,把播放器 与本地代理之间的socket通信方式修改为直连,避免了socket中不必要的读写缓冲区浪费。通过这样的调整,首帧耗时降低3.8%,播放失败率下降9%;并且还具备了播放过程中实时切换cdn的能力,即在首次开播时使用性能较好的标准cdn,在缓存较充足时切换为低成本的cdn。

2.4 预渲染
通过以下优化策略提升预渲染效果:
应用冷起后,首个视频的开播体验对用户的后续消费有着非常重要的影响,为了提升该的播放体验,在应用启动时预创建H265以及H264对应的codec实例,在开播环节直接使用预创建的解码器,开播耗时可降低50ms左右。
播放器的创建环节涉及到较多的流程,比较耗时;另外,常规的每次播放视频都创建一个播放器对象的方式,容易出现因播放器对象泄漏导致的OOM、ANR甚至播放失败。基于这两个问题,我们创建了全局复用的播放资源池,每次视频播放时都从资源池中直接获取已经创建好的播放器对象,通过该策略,可有效的降低播放器创建耗时,并且彻底解决了播放器实例泄漏问题,对系统稳定性以及播放成功率都有明显的改善。
前面我们介绍了预加载策略,即在视频播放之前提前下载部分数据到本地,视频播放时直接播放本地准备好的缓存,开播速度较优化前有明显的提升;但本地视频开播仍需要嗅探、解封装、解码这些环节,开播耗时仍存在优化空间。因此,我们基于播放器资源池,使用另一个空闲的播放器对象来提前完成下一个即将播放的视频的嗅探、解封装、解码过程,通过这个策略,首帧耗时可降低到50ms以内。

2.5 预加载策略
首先介绍的是固定大小的预加载策略:视频播放时,把后续5个视频添加到缓存待下载队列,每个视频使用固定的预加载大小,当前视频的缓存处于高水位时,开始下载缓存队列中视频,当前视频缓存处于低水位即有可能即将发生卡顿时,停止下载缓存队列中的视频。
这个方案整体实现比较简单,但存在两个
问题
:
预加载大小是固定的,未能与视频码率、时长关联,当视频码率、时长发生变化时,可能会出现缓存不足或者缓存浪费。
对于一条用户会重度消费的视频,应提升预加载大小,从而提升用户在播放过程中的流畅度。
为了解决以上两个问题,我们上线了动态预加载策略。

动态预加载就是在固定预加载的基础上,做了如下调整:
缓存分级,把固定预加载策略中的单一缓存调整为3个不同优先级的缓存,优先级高的缓存较小,优先下载,优先级较低的缓存较大,下载优先级较低;一级缓存下载结束后开始下载二级缓存,二级缓存下载完成后再下载三级缓存。
缓存大小不再固定,修改为根据视频时长和预加载时长动态计算当用户快速滑动时,一般情况下会命中一级缓存,确保视频可以顺利开播;当用户在列表中重度消费时,后续的视频将有充足的时间完成三级缓存的下载。
动态预加载策略上线后,首帧耗时降低了2.3%,卡顿率降低了19.5%,当然,这个策略也存在的明显的问题,即体验提升了,但带宽成本也提升了。我们需要思考,如何在不增加成本的前提下提升体验。

我们来看一个示例:在一个视频列表中,有些视频用户喜欢观看,完播率较高,有些视频用户不感兴趣,会快速滑过。
也就是说,只有深度消费的视频,才真正的需要二级和三级缓存,快滑的视频能快速开播即可。基于这样的一个普遍性的案例,我们结合视频的观看时长调整了预加载策略。
现在介绍的是智能预加载策略,整体流程如下:
首先,在云端基于视频基础特征比如码率、时长、清晰度,网络以及时段、历史行为等特征,使用深度神经网络创建、训练模型,用于预测一个视频用户会深度消费还是快速滑过。
其次,模型导出、转换之后,部署在客户端,在视频开播之前预测消费深度。
最后,播放器仍保留之前的一级缓存,并作为最高优先级进行下载;所有的一级缓存都下载完成后,根据预测的消费深度调整二级缓存的大小,如果该条视频会重度消费,则开启二级缓存,否则放弃二级缓存。
这个方案目前还在实验中,后续我们也将持续探索机器学习在播放上的其他应用。

体验优化的效果需要被准确、客观的衡量,并且能准确反映用户的真实体验。
在起播环节,我们设计了两个P0指标,即首帧耗时和失败率,同时,我们也设计了若干个p1指标,包括缓存大小、缓存命中率、预渲染命中率,下载速度等,这些指标的波动直接会影响到P0指标。
在视频播放环节,我们设计了卡顿率、卡顿时长以及seek卡顿等P0指标,同时,设计了百秒卡顿时长、百秒卡顿次数、缓存利用率等p1指标作为对P0指标的补充。
基于以上指标以及视频基础信息、预加载预渲染策略信息,我们设计并上线了分层监控系统,自上往下共分为
4个层级
:
P0指标
:包括开播耗时、卡顿率等,这些是我们最为关注的核心指标P1指标
:作为对P0指标拆解和补充策略指标
:包括预加载开启率、命中率、预渲染开启率、命中率,这两个策略对播放体验的影响比较明显最后一层是
视频基础信息
,包括码率、时长、画质分等,这些指标也会影响到核心性能指标

三、成本优化
前面介绍了我们短视频在播放体验方面所做的一些努力,经过前述的这些优化,目前我们短视频的播放流畅度已经达到行业内的一流水平。而随着业务的不断发展,播放的成本也随之水涨船高,成为业务必须要应对处理的首要问题,接下来将和大家分享下我们在播放成本优化方面的一些思考及实践方案。
3.1 成本拆解
首先,我们先了解下播放成本包含了哪些成本。它主要是由CDN成本、存储成本以及进行转码压缩等所需要的计算成本组成,而这里面CDN成本占了总成本的80%左右,是最大的一个成本来源,所以,接下来我们的分享主要是围绕如何降低CDN成本展开。
要知道怎么进行CDN成本的降低,就需要了解哪些是影响CDN成本的重要因素。如下图所示:

第一层拆解,CDN成本 = 单价x用量,这个相信大家都能很好理解。
第二层的拆解,正常情况下,用量=用户实际播放的视频时长乘以视频的码率,而前面我们也介绍过,为了提升视频播放的起播速度,降低播放过程中的卡顿率,我们会对视频进行预加载及预缓冲,那这部分量可能最后用户并没有产生播放行为,也就造成了流量的浪费。因此我们引出了流量利用率的概念,在后续还会详细介绍。这里我们需要知道的是CDN实际计费的用量=用户播放的时长x码率除以流量利用率。
那现在有4个最基础的因素会影响成本,分别是单价、时长、码率、流量利用率,其中时长是业务追求的增长目标,无法用以降本,因此其他三个因素就成了我们重点
优化的方向
,它们分别是。
寻找方案降低单价
对视频码率进行极致压缩
对利用率进行治理提升流量利用率
在正式介绍我们的降本方案之前,我们还需要先思考一个问题:成本的降低往往带来的是服务质量的降低,我们需要如何才能在保证播放体验的同时,降低播放成本,也就是大家经常讨论的,如何做到体验与成本的非零和博弈。
3.2 单价降低
本小节将为大家介绍我们的第一个降本方向,CDN单价的降低。
3.2.1 引入PCDN
我们的第一个方案是引入单价更低的PCDN技术,PCDN是目前一种新兴的内容分发网络,其主要是利用路由器、小盒子等廉价的边缘设备代替标准CDN的边缘节点,由于接入设备及接入网络更加廉价,故而成本相对于标准CDN,要低很多。
其网络架构如下图所示,APP通过SDK访问PCDN的边缘节点,如果内容热度值低,PCDN节点中没有该视频的缓存,则返回302状态码给到客户端,客户端再去访问标准CDN获取资源,当视频热度达到一定阈值时,PCDN会去标准CDN上回源获取对应的视频资源向客户端提供服务。

从这里我们可以看到,PCDN的节点性能相比标准CDN更差,而访问时会有一定几率进行302跳转,增加了链路的耗时,所以必然会对视频播放时的起播速度和卡顿率造成较大的影响。
对此,我们制定了多个优化措施,来降低播放体验的受损情况,在成本和体验之间进行平衡。
(1)播放器策略优化

第一个优化点是通过播放缓冲水位去控制是否走PCDN,在视频起播时使用高性能的标准CDN进行分片下载,而只有当前视频的缓冲数据达到阈值后,才使用PCDN进行下载,利用缓冲视频的时长,可以有效抵消PCDN的链路耗时增加。
第二个优化点是,在视频起播阶段发送1字节的探测包到PCDN节点,以此来确定PCDN节点上是否存在对应的视频内容,不存在时则后续分片都从标准CDN拉取,存在的话后续再走PCDN,这样可以大大减少302跳转发生的概率。
经过以上两个优化后,引入PCDN对我们的播放体验已基本不会产生负面影响了。以此,我们达到了保证播放体验的同时,降低了CDN成本的目的。
(2)业务策略优化
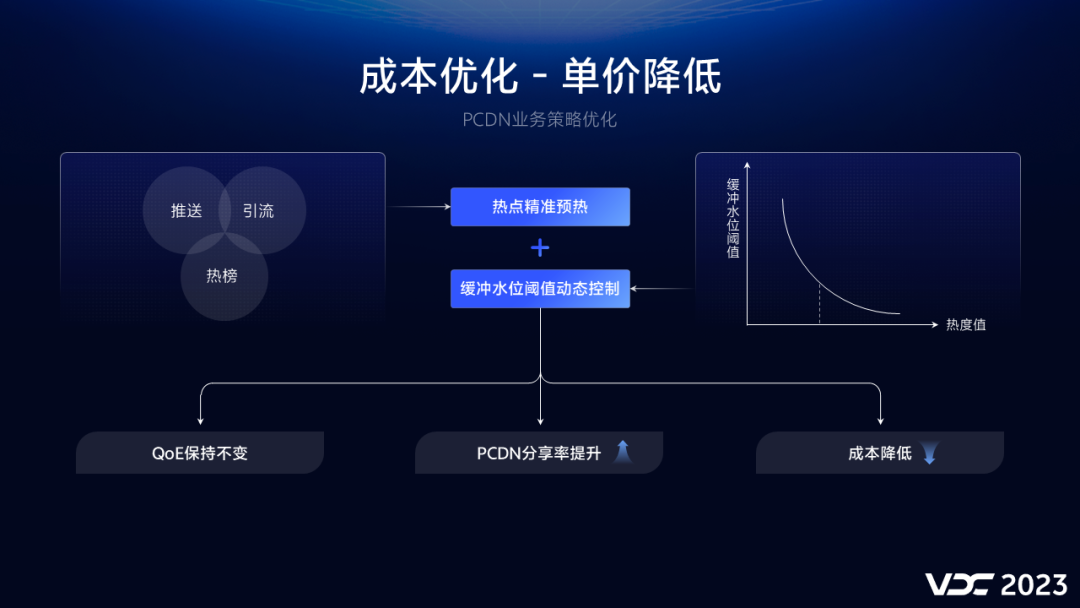
由于PCDN节点服务的主要是热点视频,因此我们对热点分发的场景进行了梳理,对这些场景用到的视频提前预热到边缘节点。由于做了预热,PCDN节点提前缓存了相关视频,出现302跳转的概率进一步减少,因此我们可以适当降低缓冲水位的阈值,提前请求到PCDN节点。基于此方案,我们做了相关的A/B实验,实验的结果是,我们在保证QoE不变的情况下,提升了PCDN的分享率,即,会有更多的流量走到PCDN节点上,进一步降低了CDN成本。
当前我们PCDN分享率在46%左右,在探测成功后,只有1%以内的流量会出现302跳转,基本可以忽略不计。通过线上长期实验组的观测,卡顿率和起播耗时上下波动,无显著负向。
以上是我们进行单价降低的第一个方案,接入PCDN,接下来我们看下
另外一个方案
。
3.2.2 共享闲时带宽
行业内CDN计费的方式有多种,包括流量计费,峰值带宽计费等,对于峰值带宽计费,是以每天的带宽最高点作为计费值的,这种计费方式,对于持续稳定的流量会更加合适。而我们短视频是一个用户实时消费视频的应用,访问热度会有明显的波峰和波谷,比如中午大家休息的时候以及下班的时候会有更多的时间去看视频,而夜里睡觉时,业务的流量则相对较低。正常情况下我们CDN的带宽波形如下图所示,可以看到闲时我们的带宽是很低的,造成了很大的浪费。

针对此种情况,我们和公司内其他业务进行合作,引入了他们的流量进行填谷,共享了我们的闲时带宽。可以看到填谷后,蓝色区域的比重明显增加了很多,其他业务会针对这部分流量进行成本分担,因此相当于降低了我们的成本单价。通过上述的PCDN及共享闲时带宽,CDN的单价得到了大幅的降低,从而有效节省了CDN成本,是我们进行降本的重要手段。
3.3 极致压缩
接下来,是我们降本的第二个方向,对视频进行极致的压缩从而降低视频的码率。
我们当下遇到的
问题
是:一个视频的清晰度是和码率强相关的,而为了达到相同的清晰度,不同内容场景的视频所需的码率是不一样的。
先前,为了保证用户的播放体验,减少低质视频的出现,我们设置的码率标准较高,导致很多视频没有得到有效的压缩。
在解决这些问题时,我们面临着这样几个
困难
:
第一是内容库中有千万量级的视频内容,内容量非常大;
第二是这些视频场景非常复杂,千变万化;
第三则是这些原始视频的质量也是参差不齐的。
为了能够在这样的情况下进行成本优化,我们需要根据视频的内容特征,自适应调整编码参数,在保证视频清晰度的前提下,对视频进行极致压缩。
接下来,来看下我们是如何做的。
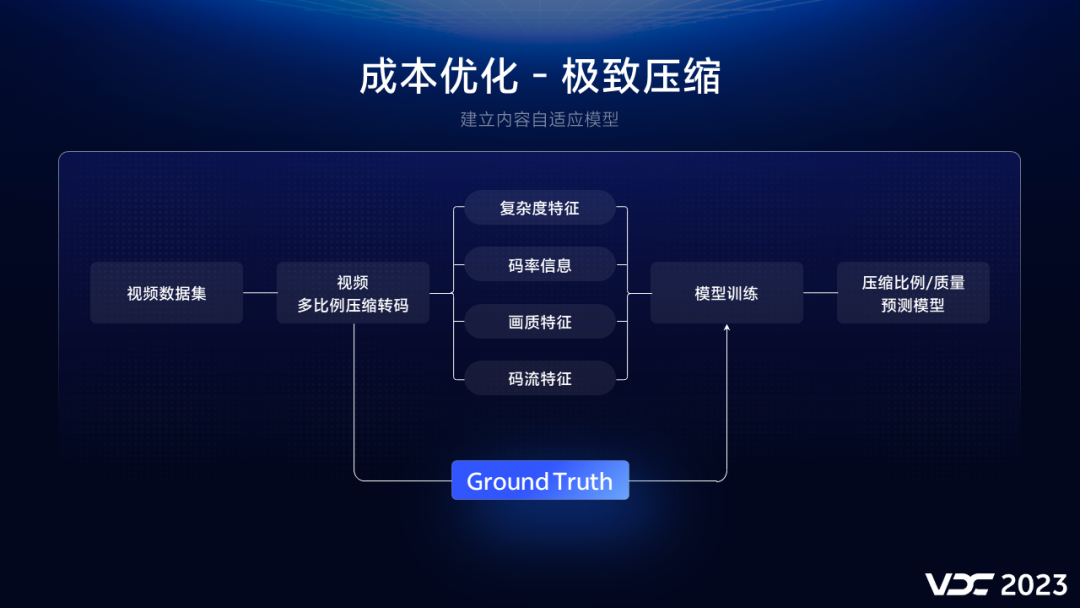
首先我们基于神经网络,自研了一套内容自适应编码算法。算法模型的训练过程如下:首先第一步我们会根据内容库中的场景标签,从内容库中收集足够大视频数据集作为模型的训练数据。
然后对训练集中的视频进行不同比例的压缩转码作为Ground Truth,再对压缩后的视频提取特征,这些特征包括视频的复杂度特征、码率信息、画质特征、码流特征等;最后利用上述特征,进行神经网络拟合训练,得到视频质量与压缩率的关系模型,该模型可以预测压缩比例和视频压缩质量之间的对应关系曲线。
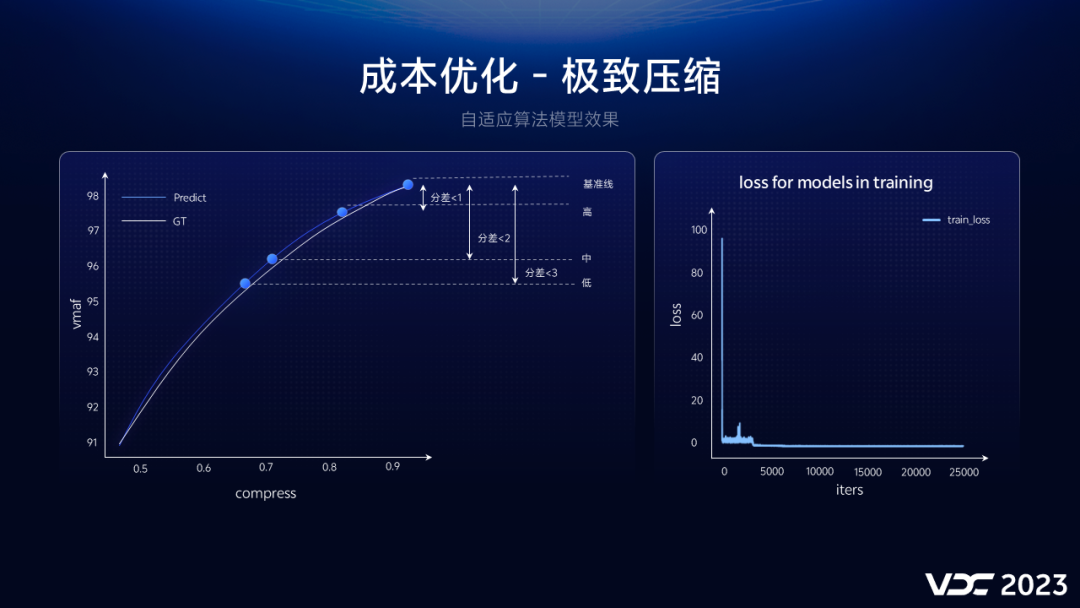
上图展示的是我们模型的预测效果,白色弧线是视频在经过不同比例压缩后得到的VMAF曲线,是实际的Ground Truth,而蓝色曲线则是我们模型的预测曲线,可以看到预测曲线和Ground Truth非常接近。于是,我们便可以通过预测曲线,在保证清晰度一致的情况下,确定不同视频需要的编码参数,达到内容自适应编码的目的。
最后再来看下我们极致压缩的
完整流程
:

首先第一步是对视频进行前置增强处理,这一步处理的目的是提升原始视频的画质,从而可以抵消一部分视频编码带来的损伤,另外去除噪声等退化也有利于压缩过程中降低视频的码率。
在经过增强修复后,需要对视频进行场景划分,一个视频可能包含多个场景,这些场景所需要的编码参数也不一样,通常我们称之为Per-title分场景编码,更细粒度的选择不同的编码参数对视频进行压缩。
第三步就是对每一个场景的视频提取视频特征,通过我们的自适应模型决策出最佳的编码参数,进行编码合成,最后得到输出视频。
通过这几步的处理,我们的压缩率相比之前有了大幅度的降低,通过线上的数据统计,我们的平均压缩率从60%降低到了40%,可以看到这个优化效果非常明显,以上就是我们极致压缩的方案,通过进一步压缩码率,降低我们的CDN成本。
3.4 利用率治理
我们的最后一个优化方向是
利用率治理
。
先解释下什么是流量利用率:在播放过程中,为了提升播放的流畅度,需要提前去缓存当前视频以及预加载后面的视频,同时网络层也会有socket的buffer,用户如果使用不到这些流量,那就会产生流量浪费,这些浪费的流量与用户实际播放的流量相加,就是CDN实际产生的流量,流量利用率就等于实际播放的流量除以CDN实际产生的流量。
由此可见,在整个播放链路上,都存在流量的浪费,而我们希望通过利用率的治理,控制并减少这些浪费的产生。

3.4.1 利用率漏斗建设
我们
需要治理的第一个问题是:在版本迭代的过程中,播放的策略也是在不断优化的
,比如我们可能为了体验着想,增加了预加载的数量,或者做了多级预加载。但是在做这些优化的时候,我们无法有效的衡量每个优化究竟对CDN成本带来了多大的变化,会不会增加流量的浪费。
对于这个问题,我们的
解决方案是,针对每个版本,建立了如下图所示利用率漏斗,并加入到了灰度报告中
,严格监控每个版本出现的流量浪费情况,防止播放策略优化导致CDN成本大幅增加。

3.4.2 利用率提升
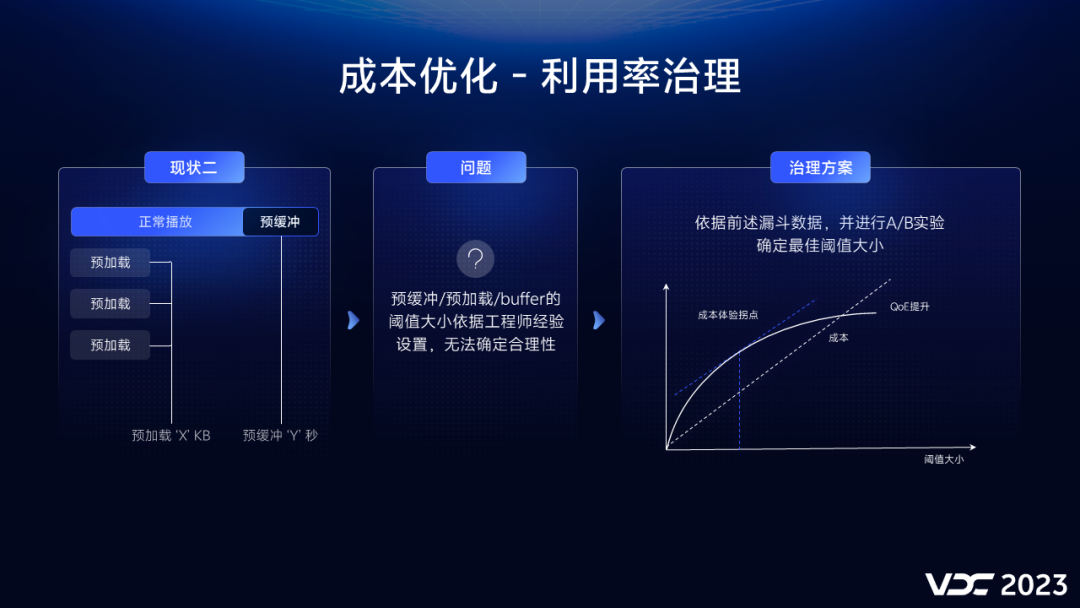
我们需要
治理的第二个问题是:对于预加载或者预缓冲等策略,我们都会设置一个上限阈值,保证体验的同时防止消耗过多流量
,但是这个阈值一直都是以我们工程师的经验设置的,无法确切的知道这个阈值是否合理。
针对这个问题,我们的
治理方案是,通过前述建立的漏斗数据,针对阈值进行线上A/B实验,通过收集不同阈值下体验和成本的变化数据,找到投产比拐点,从而确定最优阈值。
3.4.3 治理效果
这边展示了我们治理后的
效果
。
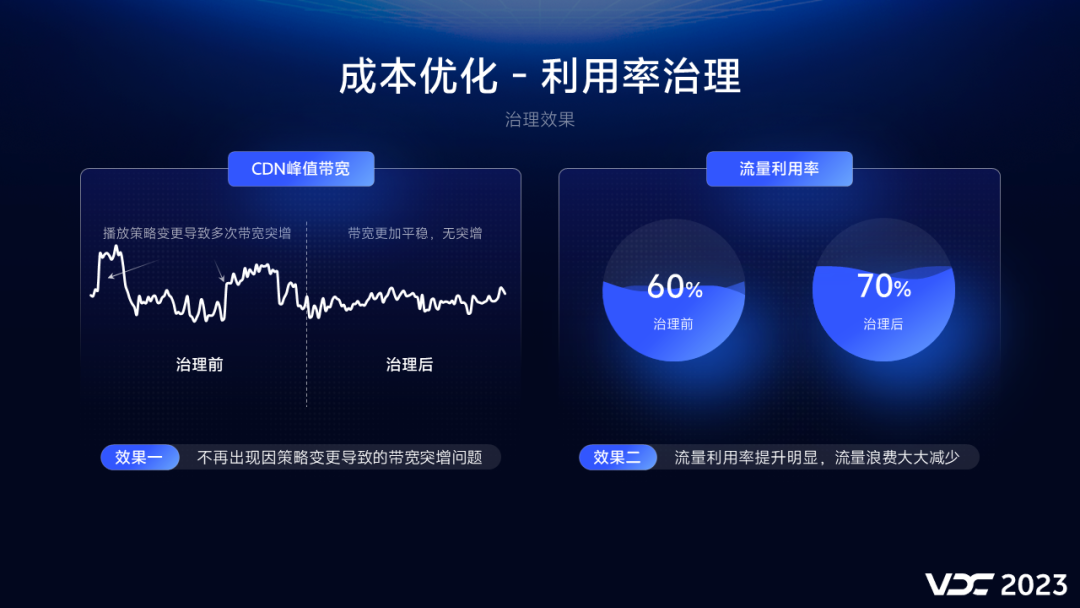
(1)首先在治理前,如下图左侧显示,有两个突刺点,这是因为某些版本优化时,没有识别到成本的增长量级,并且在灰度期间无法明显看出成本的变化,及时止损,最终导致我们的CDN带宽大幅增长。而
在治理后,可以看到,我们的带宽变得平稳很多,不再出现突刺点,带宽突增问题得到了有效。
(2)其次,如下图右侧所示,在治理前,我们的流量利用率在60%左右,而在
治理后,我们在保证体验不受损的情况下,将利用率提升到了70%,从而节省了相应的CDN成本。
通过对流量利用率的监控和治理,我们可以清晰的掌控播放链路中每个节点可能产生的流量及带宽情况,找到成本优化点,降低我们的CDN成本。
四、总结&展望
如下图所示,可以看到我们的优化结合了大数据、A/B实验、AI技术等,通过对这些技术的应用,我们进行了播放体验和播放成本两个方面的优化。

首先是对播放体验优化,我们依次从网络层、播放层、应用层进行了相关的策略优化,这里面主要包括分片下载、预加载/预渲染、分级缓存等策略。
其次是播放成本的优化,我们分别从单价、码率、利用率等方向进行了降本,这里面主要包括PCDN、极致压缩、利用率治理等方案。
这些优化方案,是我们短视频团队长时间的实践积累,帮助我们在体验和成本之间做到了双赢。

最后是我们未来的一些展望,我们会持续聚焦音视频前沿技术,在压缩编码方面,我们会去研究引入H266技术,进一步压缩视频的码率,而在增强方面,我们会对端侧增强技术进行预研,通过端云协同增强,进一步做到降本增效。