前言
这不是高支模项目需要嘛,他们用传统算法切那个横杆竖杆流程复杂耗时很长,所以想能不能用机器学习完成这些工作,所以我就来整这个工作了。
工欲善其事,必先利其器,在正式开始之前,我们先要搞懂如何切分数据集。
本系列文章所用的核心骨干网络代码主要来自
点云处理:实现PointNet点云分割
使用的数据集类型主要为SharpNet,这篇文章里主要是讲如何使用CC切出指定的对象,并将其转换成我们想要的SharpNet数据集。
之后可能写一个番外,简单说说如何使用semantic-segmentation-editor工具进行简单的点云分割和解析吧,最近也摸了一下,但是发现这个工具貌似没有CC好用。
如果有人问起再写吧,有点折腾,不过也还好。
什么是SharpNet数据集?
我们可以在
LARGE-SCALE 3D SHAPE RECONSTRUCTION AND SEGMENTATION
FROM SHAPENET CORE55
网站上下载到SharpNet的数据集和标签,我们下载下来解压看看里面的结构

以下是训练集点云文件组
以下是训练集点云的标签组
也就是说实际上是一个pts文件对应一个.seg文件。
其中pts文件好理解,就是一个个的明文点云,内容如下:
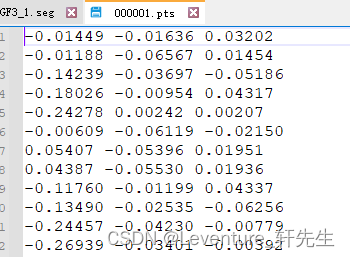
打开seg文件,里面行数和同名的pts文件行数相同,
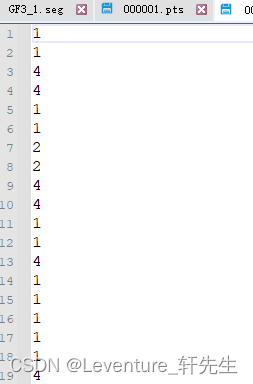
这个.seg文件中代表的意思就是对应行数的点所对应的label标签,通常以一个数字来表示,比如1是背景,2,3,4代表各种各样的对象,具体每个数字对应的对象是什么。
如何标注点云文件
上文中简单说了下SharpNet的规则,那么本章就简单说说如何标注点云文件
主要可以参考这篇文章,我这里仅展示简单的流程:
如何利用CloudCompare软件进行点云数据标注
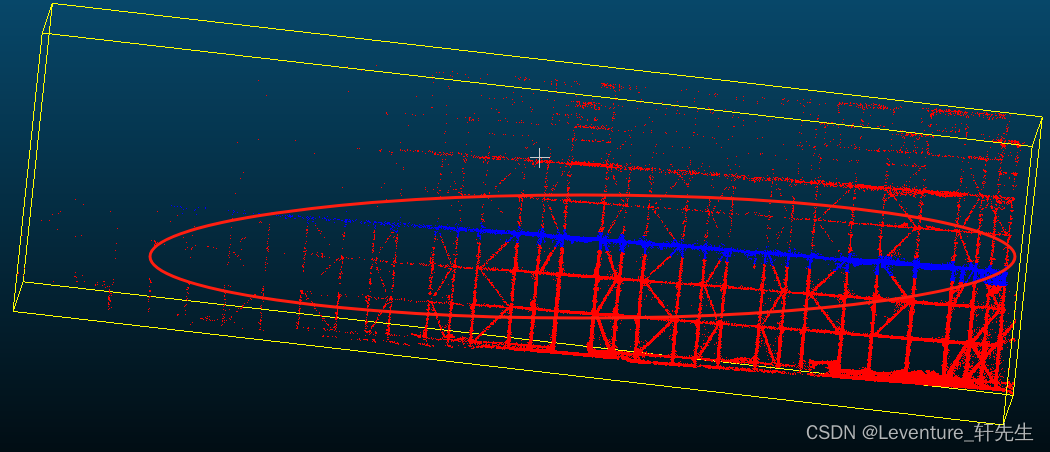
比如我现在有一个这样的高支模点云,如果我想要做一个横杆的检测,那么我们就需要把横杆全部截出来
1.切割
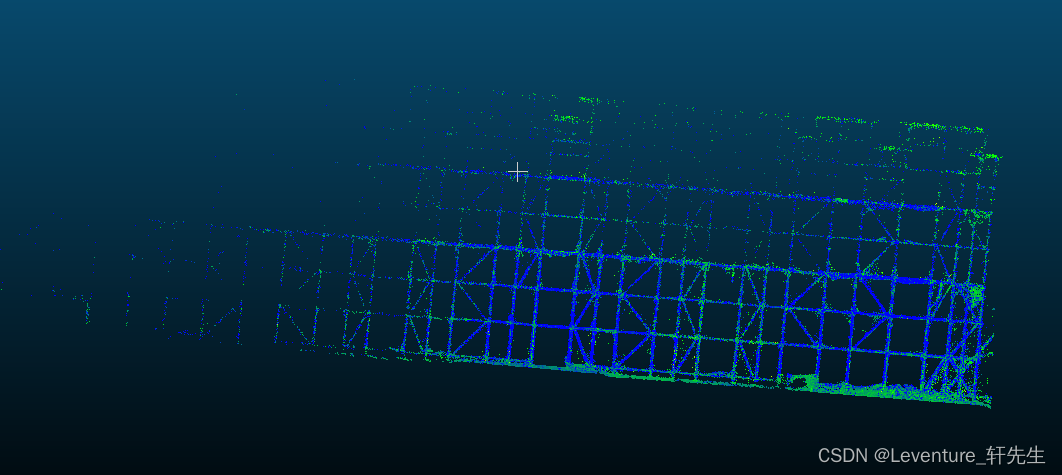
先点击需要切片的点云文件,然后点这个剪刀进入剪切模式
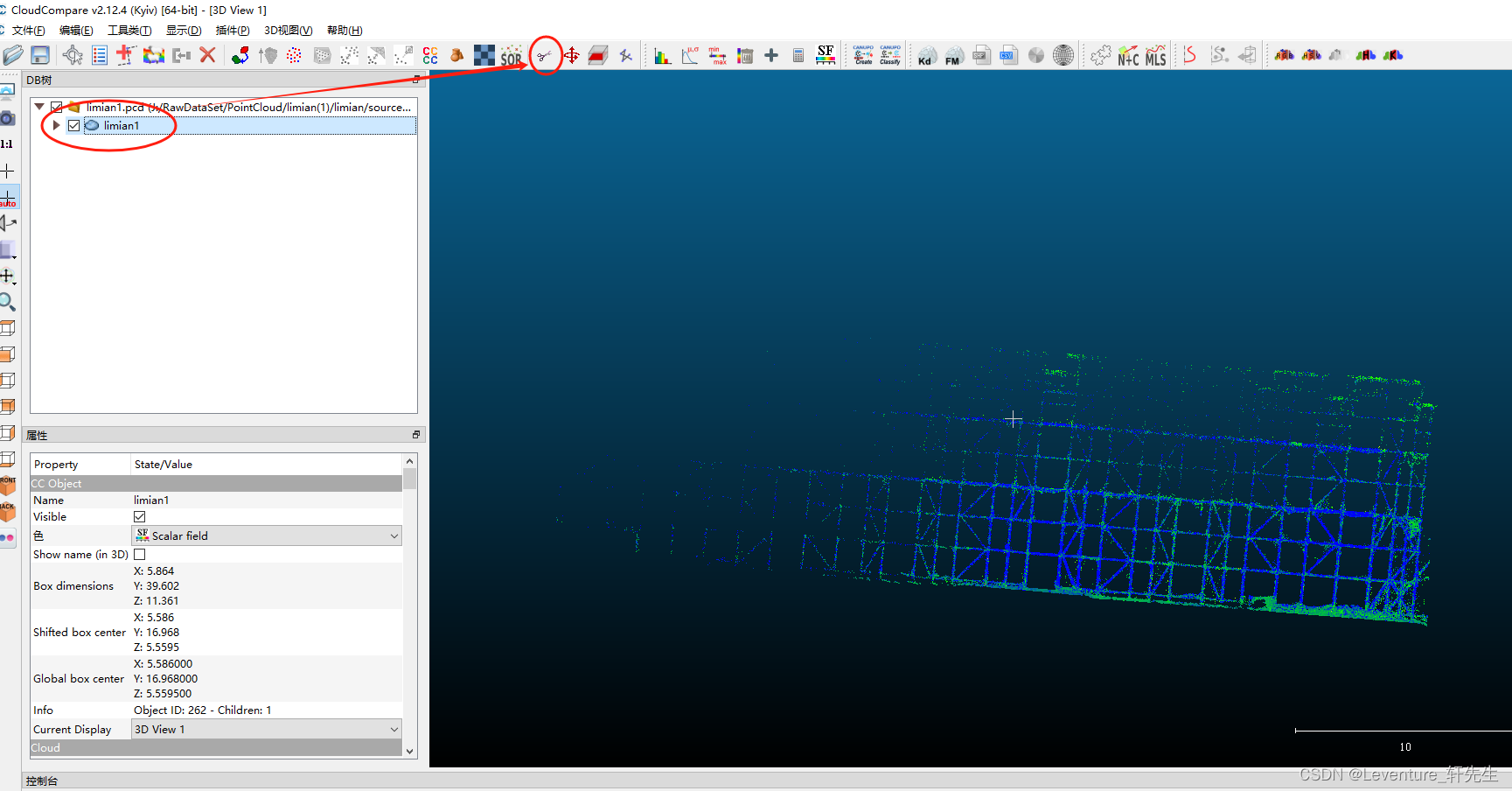
先用左键划线工具框选住一个横杆,选完了之后单击右键确定选框,这个时候点击这个红色的多边形(选中框选内容)完成切割,再点击右边的这个绿色勾
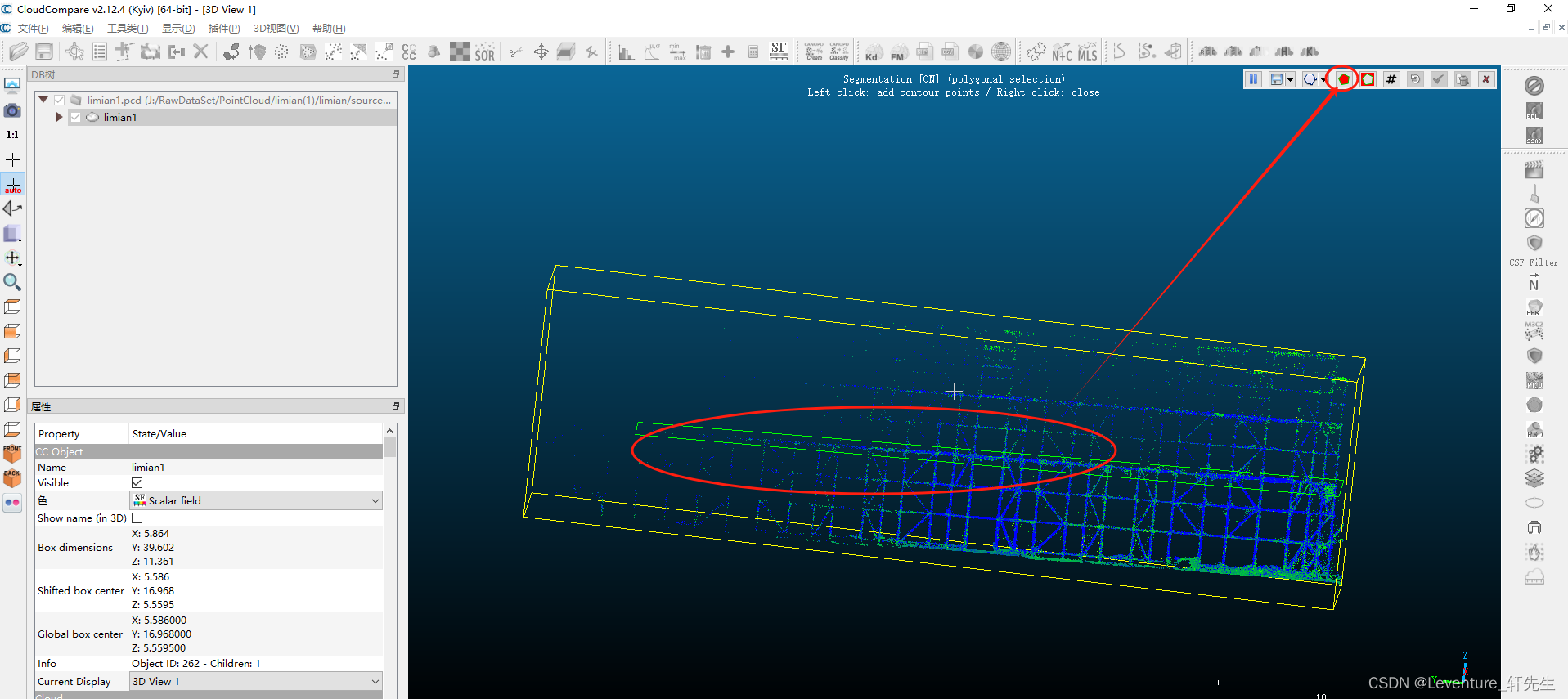
这个时候切片就切出来了,可以看看效果


2. 分类
完成了切割工作之后,要给这个切出来的片加上一个名字,就点上面这个加号,然后给定一个对象的名称,再给定一个值
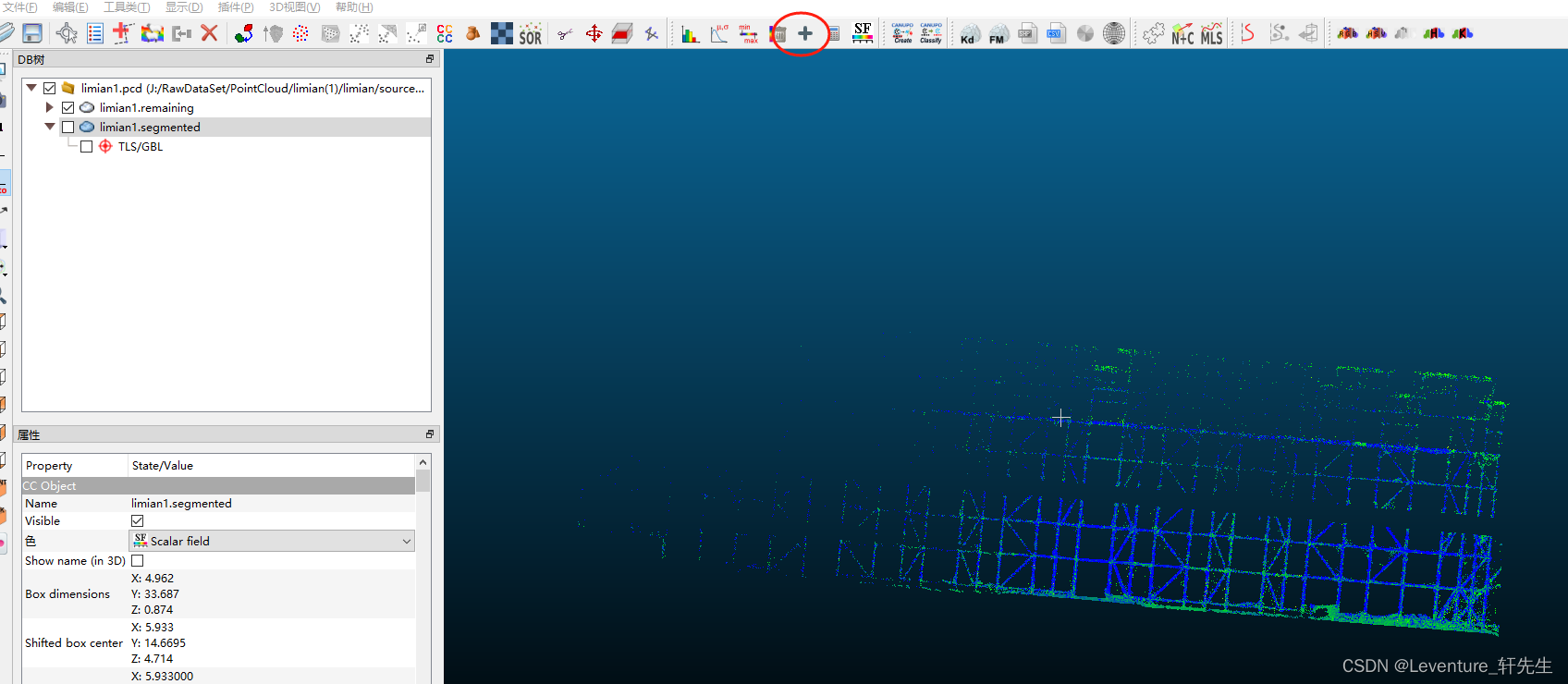
我们切分的是水平支撑,那么就给它起个名字叫Support
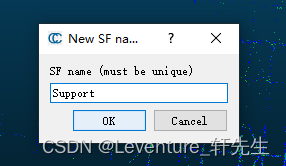
至于值的话随便声明就行,无所谓,这里声明的是1.00,这个和后面的处理有关,当然了你不懂也无所谓,如果你看懂了的话可以自己改这块的逻辑。
然后选中所有的点云,然后合并就行了
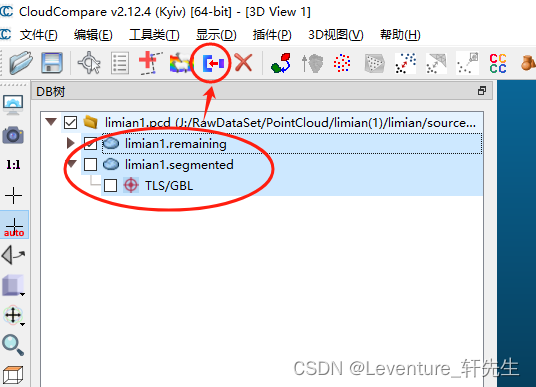
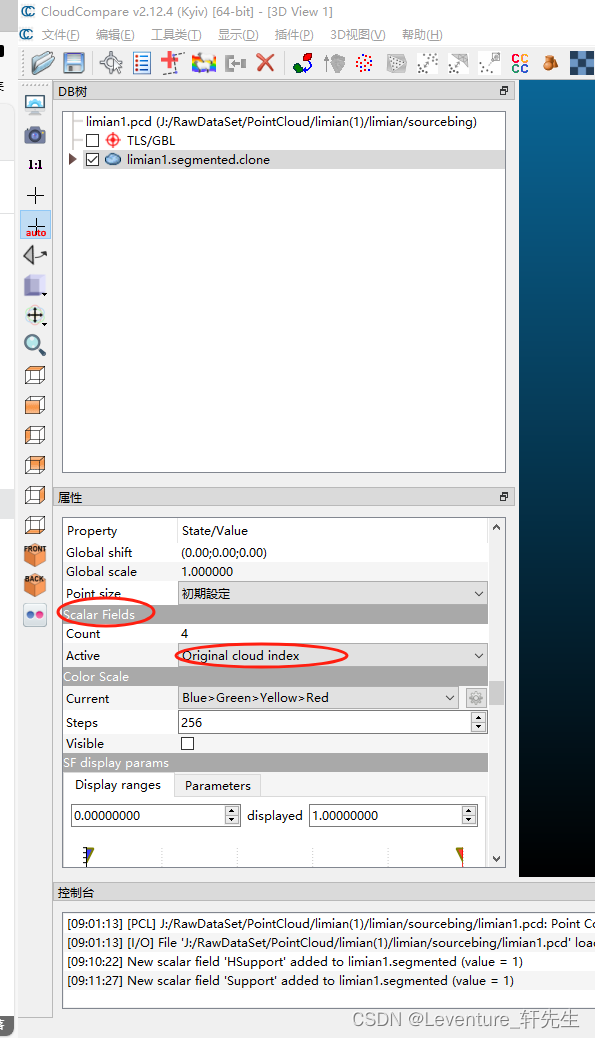
合并后可以看到被截取的这一块点云已经和原来的点云不一样了
在属性中找到Active可以找到被切分的点云分类
保存一下这个点云,保存成ASCII码的格式,以便我们对这个点云文件重新进行操作,以文本格式打开:
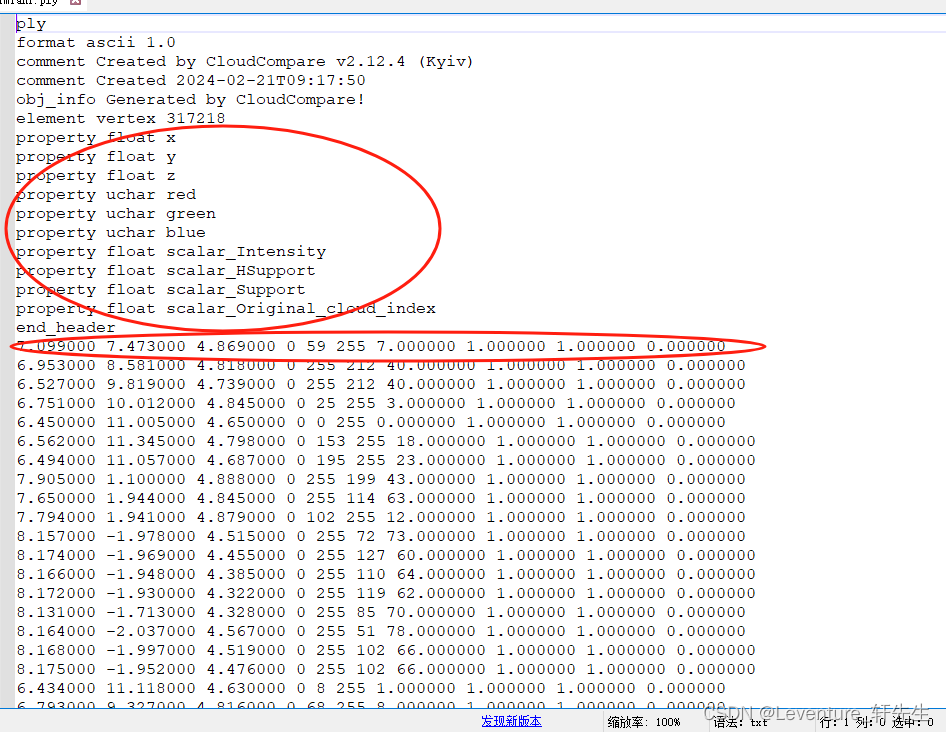
每个属性从上到下对应end_header后从左到右的一条条内容,比如第一行
7.099000 7.473000 4.869000 0 59 255 7.000000 1.000000 1.000000 0.000000
代表了一个点的
x坐标 y坐标 z坐标 r色 g色 b色 scalar_Intensity scalar_HSupport scalar_Support scalar_Original_cloud_index
我们在这里只需要判断Support的值就可以了,后面的几个scalar值就是标签的值,我们在这里只需要判断是不是Support对象,然后一行行地制作出.pts文件和.seg文件即可。
这里给出一段示例代码,需要注意的是,这个代码并不是自适应的识别所有标签,所以需要自己根据业务和自己的需要调整
CCSeperator.h
#pragma once
#include <QtWidgets/QMainWindow>
#include "ui_CCSeperator.h"
#include "qpoint.h"
#include "qvector.h"
#include "qfile.h"
#include "qfileinfo.h"
#include "qtextstream.h"
#include "qdir.h"
#include "qdebug.h"
//CC数据清洗工具
enum class PointType {
None = 0,
Support = 1,
VSupport = 2
};
struct CCPoint {
float x = 0.00;
float y = 0.00;
float z = 0.00;
PointType type = PointType::None;
};
class CCSeperator
{
Q_OBJECT
public:
CCSeperator();
~CCSeperator();
/// <summary>
/// 读取指定点云文件并尝试解析到指定目录下
/// </summary>
void ReadFile(const QString& filePath, const QString& outputPath);
QVector<CCPoint> vec_points;
};
CCSeperator.cpp
#include "CCSeperator.h"
CCSeperator::CCSeperator()
{
this->ReadFile("J:\\output\\GF3_7.ply", "J:\\output");
}
CCSeperator::~CCSeperator()
{
}
void CCSeperator::ReadFile(const QString& filePath, const QString& outputPath)
{
//尝试读取指定目录下的文件
QFile file(filePath);
QString fileName = QFileInfo(file).baseName();
if (!file.exists()) {
qDebug() << " file not exist";
return;
}
this->vec_points.clear();
qDebug() << file.open(QIODevice::ReadWrite | QIODevice::Text);
QTextStream in(&file);
bool blnEndHead = false;
while (!in.atEnd()) {
QString line = in.readLine();
if (line.contains("end_header")) {
blnEndHead = true;
continue;
}
if (!blnEndHead) continue;
QStringList list = line.split(" ");
CCPoint point;
point.x = list[0].toFloat();
point.y = list[1].toFloat();
point.z = list[2].toFloat();
//这个对应的是识别的列,这里是第七行
if (list[6].toFloat() == 1.0000) {
point.type = PointType::Support;
}
else {
point.type = PointType::None;
}
this->vec_points.append(point);
}
//注入点完成后,需要将其导出到指定目录下
QDir dir(outputPath);
if (!dir.exists()) {
dir.mkpath(dir.absolutePath());
}
QFile file_out_data(outputPath + QString("/Data/%1.pts").arg(fileName));
QTextStream out(&file_out_data);
QFile file_out_label(outputPath + QString("/Label/%1.seg").arg(fileName));
QTextStream out_label(&file_out_label);
file_out_data.open(QIODevice::WriteOnly | QIODevice::Text | QIODevice::Truncate);
file_out_label.open(QIODevice::WriteOnly | QIODevice::Text | QIODevice::Truncate);
for (auto item : this->vec_points) {
//将所有的点写入到指定目录下
//无论如何,正常的点都需要写入
QString fileContent = QString("%1 %2 %3").arg(item.x).arg(item.y).arg(item.z);
out << fileContent << endl;
QString label = QString("%1").arg(static_cast<qint32>(item.type));
out_label << label << endl;
}
file_out_data.close();
file_out_label.close();
}
这样洗出来的数据就是这样的:
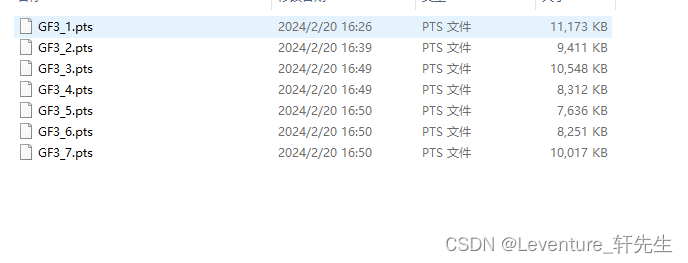
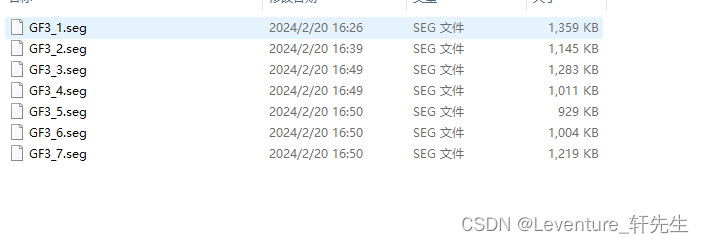
这样我们就完成了自制SharpNet数据集的过程