前言:
这是最好的时代,也是最坏的时代;是充满挑战的时代,也是充满机遇的时代。是科技飞速的时代,也是无限可能的时代。
近年来,人工智能(AI)技术的飞速发展已经席卷了全球,不断突破着技术边界,为各行各业带来前所未有的变革。作为引领未来的核心技术之一,AI正在深刻地改变着我们的生活方式和工作模式。前几天OpenAI发布了邻人叹止Sora大模型,专门用于生成视频。这一模型在人工智能领域引起了广泛的关注和讨论,因为它在视频生成技术上实现了重大的突破。实现了对现实世界的理解和模拟两层能力。这意味着Sora不仅能理解你的文字描述,还能将其转化为真实、生动的视频画面。这将对很多行业形成冲击,也在不断地推动着行业的进步。让我们一起走进这个充满创新和变革的时代,共同迎接挑战,寻求机遇。
我们还是闲话少叙,切入正题。
序:
档案,它们是历史的碎片,是知识的宝藏,也是我们回望过去的窗口。然而,管理这些浩如烟海的资料,却常常让人头疼不已。在信息技术飞速发展的今天,传统的档案管理方式正面临着前所未有的挑战与机遇。好在,科技的魔法棒为我们指明了方向——机器人和三维可视化技术的融合应用,档案管理正逐步迈向智能化、自动化的新时代,正携手为我们打开档案管理的新篇章。
“工欲善其事,必先利其器。”古人的智慧,深刻揭示了技术创新对工作效率提升的重要性。如今,机器人已经能够胜任许多繁琐、重复性的工作,而三维可视化技术则为我们提供了一个全新的视角,让我们能够更直观、更全面地了解档案室的每一个角落。通过构建档案室的三维模型,我们可以更直观地理解各个环节的空间布局和操作逻辑,为实际操作提供有力的参考。此外,三维可视化还能帮助我们模拟和预测不同场景下的运行效果,从而指导我们做出更合理的决策。
下面我们探讨并如何利用三维可视化技术,模拟和优化档案室中机器人取档、盘点、人工查档以及巡检等关键环节的运作流程。这些环节共同构成了档案室管理的完整流程,每个环节都有其独特的作用和价值,共同确保档案室的高效、准确和安全运行。
一、机器人取档
1.1、效果展示
- 机器人定位前往档案架

2、机器人取档案

3、机器人交付档案

1.2、解决方案
3D密集架库房机器人取档是一种利用机器人技术实现档案拿取功能的无人值守库房管理方式。这种库房管理方式采用了数字孪生技术、三维建模等技术,构建了技防与人防相结合、软硬件同步发展的档案实体安全管理体系。在3D密集架库房中,机器人通过智能系统控制,可以精确地定位到需要拿取的档案位置,并通过智能机械臂等设备将档案取出。同时,库房还配备了实时定位感应系统、导轨式跟踪摄像系统、智能温湿度控制系统等先进配套设备,确保档案的精密存储和展呈。通过机器人实现档案拿取功能,可以大大提高库房管理的效率和准确性,减少人为因素造成的误差和损失。同时,无人值守库房也可以有效减少人力成本和安全风险,提高库房的安全性和可靠性。
- 构建档案室的三维模型,包括密集架、通道、机器人等。
- 为机器人设计三维模型,并添加导航系统、机械臂和抓取工具。
- 编写机器人的取档逻辑,包括路径规划、物体识别和抓取动作。
- 在虚拟环境中模拟机器人的取档过程,通过可视化界面展示机器人的运动轨迹和取档结果。
- 定义:机器人取档是指利用机器人技术从档案室中自动取出特定档案的过程。
- 过程:机器人根据输入的档案编号或关键词,通过导航系统移动到相应的密集架前,使用机械臂或其他工具从指定位置取出档案。
- 优势:提高取档效率,减少人力成本,降低人为错误,适用于大规模和高密度的档案存储。
1.3、代码实现
由于代码篇幅过长,此处给出实现逻辑的伪代码结构
1、统一机器人动作方法
我们把机器人的每一步动作都当作一次执行动画,根据不同动作名称,来实现不懂动作
functiondoRouteRunStep(index, data) {
/* 处理资源回收
doGC();
*/var currentroute =data[index];if(currentroute) {var cameraPosition =currentroute.position;var cameraTarget =currentroute.target;var runTime =currentroute.timeLong;var additionsTimeLong = 0;if(currentroute.additions) {
additionsTimeLong=currentroute.additionsTimeLong;
}if (additionsTimeLong == 0) {if (runTime != 0) {
modelbusiness.changeCameraPositionObj= msj3DObj.commonFunc.changeCameraPosition(cameraPosition, cameraTarget, runTime, function() {if (modelbusiness.runState == 0) {
}
});
}if(currentroute.additions) {
additionsTimeLong=runTime;
$.each(currentroute.additions,function(_index, _obj) {if(_obj) {if (_obj.changeParam == "function") {
modelbusiness[_obj.function](_obj.addtion_name, _obj.paramvalue)
}else{var cobj =msj3DObj.commonFunc.findObject(_obj.addtion_name);if (_obj.changeParam == "position"){if (_obj.addtion_name == "people" || _obj.addtion_name == "jiqiren") {
cobj.lookAt(newTHREE.Vector3(
_obj[_obj.changeParam].x,
cobj.position.y,
_obj[_obj.changeParam].z));
}if (_obj.addtion_name == "people") {
cobj.mixer.clipAction(cobj.oldGLTFObj.animations[1]).play()
cobj.mixer.clipAction(cobj.oldGLTFObj.animations[0]).stop();
console.log("run");
}
}var _tween = new TWEEN.Tween(cobj[_obj.changeParam]).to(_obj[_obj.changeParam], additionsTimeLong).onUpdate(function() {if (modelbusiness.runState == 0) {
_tween.stop();
}
}).onComplete(function() {if (_obj.addtion_name == "people" && _obj.changeParam == "position") {
cobj.mixer.clipAction(cobj.oldGLTFObj.animations[1]).stop();
cobj.mixer.clipAction(cobj.oldGLTFObj.animations[0]).play();
console.log("stop");
}
}).start();
modelbusiness.currentTween=_tween;
}
}
});
}
modelbusiness.currentSetTimeOut= setTimeout(function() {if (data[index + 1]) {
modelbusiness.doRouteRunStep(index+ 1, data);
}
}, runTime+100)
}}else{if (data[index + 1]) {
modelbusiness.doRouteRunStep(index+ 1, data);
}
}
}
2、统一调用,配置动画步骤
functionjiqirenDD
(area, nub, Face, pandianRow, pandianCol) { $("#pandianDataDetail").html("");var cabforename = "cabinet2_";var positionZ = [ -350];if (area == 1) { cabforename= "cabinet_"; positionZ= [ 360]; }var rundata =[];for (var i = nub; i <= nub; i++) {var cabobj = msj3DObj.commonFunc.findObject(cabforename +i);var step1 ={"timeLong": (i == nub ? nub * 700 : 1200), "position": (i == nub ?{"x": cabobj.position.x + 180, "y": 8, "z": 23.203} : {"x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }), "target": (i == nub ? { "x": cabobj.position.x + 15, "y": 10, z: 0.876428765845767 } : { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }), "additionsTimeLong": 0,"additions": [ {"changeParam": "position", "position": { x: cabobj.position.x+ 15, z:23.203, },"addtion_name": "jiqiren"} ] };var step2 ={"timeLong": 300, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767} };//转动面向架子 var step3 ={"timeLong": 300, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 100,"additions": [ {"changeParam": "position", "position": { x: cabobj.position.x+ 15, z:23.203 + (area == 1 ? 1 : -1), },"addtion_name": "jiqiren"} ] };//开架 var step3_1 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 1000,"additions": [ {"changeParam": "function", "function": "openCabnitByName", "paramvalue": "打开架子", "addtion_name": cabforename +i } ] }; rundata=rundata.concat([step1, step2, step3, step3_1]);for (var pj = 0; pj < positionZ.length; pj++) {//进入 位置一 var step4 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 3000,"additions": [ {"changeParam": "position", "position": { x: cabobj.position.x+ 15, z: positionZ[pj], },"addtion_name": "jiqiren"} ] };//转动面向架子 var step5 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 100,"additions": [ {"changeParam": "position", "position": { x: cabobj.position.x+ (area == 1 ? 16 : 14), z: positionZ[pj], },"addtion_name": "jiqiren"} ] };//停留 var step6 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 3000,"additions": [ {"changeParam": "function", "function": "jiqirenQuShu", "paramvalue": "取档案", "addtion_name": "jiqiren"} ] }; rundata=rundata.concat([step4, step5, step6]); }//转动角度 var step7 ={"timeLong": 300, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 0};//回退 var step8 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 5000,"additions": [ {"changeParam": "position", "position": { x: cabobj.position.x+ 15, z:23.203, },"addtion_name": "jiqiren"} ] }; rundata=rundata.concat([step7, step8]); }this.pandianDD = this.pandianDD.concat(rundata);//回去档案给人 this.pandianDD.push({"timeLong": 8000, "position": { x: 1795.3290848770343, y: 216.90756778187463, z: 148.3450456666665639 }, "target": { x: 1912.5600353289337, y: -11.238253288388648, z: 166.20100949665147 }, "additionsTimeLong": 0,"additions": [ {"changeParam": "position", "position": { "x": 1900, "y": -93, "z": 150 }, "addtion_name": "jiqiren"} ] });this.pandianDD.push({"timeLong": 0, "position": { x: 1795.3290848770343, y: 216.90756778187463, z: 148.3450456666665639 }, "target": { x: 1912.5600353289337, y: -11.238253288388648, z: 166.20100949665147 }, "additionsTimeLong": 4000,"additions": [ {"changeParam": "function", "function": "jiqirenGeiShu", "paramvalue": "给档案", "addtion_name": "jiqiren"} ] });this.pandianDD.push({"timeLong": 0, "position": { "x": 1496.961677226794, "y": 6.048526864006573, "z": -396.50227110708374 }, "target": { "x": 1482.9322600214946, "y": -4.512061245433281, "z": -165.11374369473938 }, "additionsTimeLong": 1000,"additions": [ {"changeParam": "function", "function": "stopDD", "paramvalue": "停止调档", "addtion_name": ""} ] });this.doRouteRun(0, this.pandianDD); }二、机器人盘点
2.1、效果展示
机器人盘点扫描

2.2、解决方案
密集架库房机器人盘点解决方案是一种利用机器人技术实现对密集架库房中档案进行高效、准确盘点的方案。该方案结合了导航定位、图像识别、数据分析等多种技术,旨在解决传统盘点方式中存在的效率低下、误差率高、安全风险大等问题。
3D密集架库房机器人盘点是指利用机器人技术自动对密集架库房中的档案进行清点和核查的过程。这种技术结合了3D建模、导航定位、图像识别等多种先进技术,能够实现对库房内档案的高效、准确盘点。
在3D密集架库房中,机器人首先通过3D建模技术获取库房的三维布局和档案存放信息。然后,机器人利用导航定位系统自主导航到各个密集架前,并通过图像识别技术对档案进行识别和清点。
在盘点过程中,机器人会逐个扫描密集架上的档案,并与库房管理系统中的档案信息进行比对。如果发现差异或错误,机器人会立即进行记录和报告,以便工作人员及时处理。
通过3D密集架库房机器人盘点,可以大大提高盘点的效率和准确性,减少人为因素导致的误差和遗漏。同时,机器人盘点还可以实现无人值守,减少人力成本和安全风险,提高库房的管理水平和安全性。
具体来说,密集架库房机器人盘点解决方案包括以下几个部分:
- 机器人及导航定位系统:选用具有自主导航功能的机器人,通过激光导航、视觉导航等技术实现精确定位和自主移动。机器人能够自主遍历库房中的各个密集架区域,进行档案的盘点工作。
- 图像识别系统:机器人配备高清摄像头和图像识别算法,能够对密集架上的档案进行精确识别。通过图像识别技术,机器人可以读取档案的标签、条形码等信息,并与库房管理系统中的数据进行比对。
- 数据分析系统:机器人盘点完成后,将收集到的数据上传至数据分析系统。系统对盘点数据进行处理和分析,生成盘点报告和异常情况预警,帮助管理人员快速了解库房的存储状态和潜在问题。
- 安全防护系统:为确保盘点过程的安全,解决方案中还包括安全防护系统。该系统能够监测库房内的温度、湿度等环境参数,确保档案的安全存储。同时,机器人还配备了碰撞检测、紧急停车等功能,以避免在盘点过程中发生意外。
- 在档案室的三维模型中,为每个密集架和档案分配唯一的标识符。
- 使用图像识别算法(如深度学习模型)训练机器人识别档案上的标签或条形码。
- 编写盘点逻辑,让机器人在虚拟环境中遍历各个密集架,并使用机械臂或扫描设备读取档案信息。
- 将读取的数据与库存数据进行比对,生成盘点报告,并通过可视化界面展示盘点结果。
- 定义:机器人盘点是指利用机器人技术对档案室中的档案进行自动清点和核查的过程。
- 过程:机器人按照预设的路线遍历档案室,利用图像识别、RFID等技术识别档案,并与库存数据进行比对,生成盘点报告。
- 优势:提高盘点的准确性和效率,减少人工盘点的时间和误差,实时更新库存数据,优化库存管理。
2.3、代码实现
functionjiqirenShaomiao (objname) {if (modelbusiness.runState == 1) {//$("#PanDianData").show();
modelbusiness.sendMessage(null,"盘点扫描");var jiqiren =msj3DObj.commonFunc.findObject(objname);
jiqiren.children[1].visible = true;new TWEEN.Tween(jiqiren.children[1].rotation).to({ x: 0.8 }, 750).onUpdate(function() {
modelbusiness.addPanDianData();
}).onComplete(function() {if (modelbusiness.runState == 1) {new TWEEN.Tween(jiqiren.children[1].rotation).to({ x: 2.4 }, 1500).onUpdate(function() {
modelbusiness.addPanDianData();
}).onComplete(function() {if (modelbusiness.runState == 1) {new TWEEN.Tween(jiqiren.children[1].rotation).to({ x: Math.PI / 2 }, 750).onUpdate(function() {
modelbusiness.addPanDianData();
}).onComplete(function() {
jiqiren.children[1].visible = false;
}).start();
}
}).start();
}
}).start();
}
}三、人工查档
3.1、效果展示


3.2、解决方案
在3D档案室中,为了提高查档取档的效率和准确性,通常会采用一些先进的技术手段,如智能货架、RFID标签、自动化搬运设备等。这些技术可以帮助快速定位档案位置、减少人工查找时间,并提高档案管理的整体效率。
此外,为了确保档案的安全性和完整性,3D档案室还会采取一系列安全措施,如监控摄像头、门禁系统、防火防盗设施等。这些措施可以有效防止档案被盗、丢失或损坏等情况的发生。
概述:创建一个三维可视化的档案室环境,模拟用户或管理员在档案室中手动查找和检索档案的过程。
实现:
- 使用3D建模软件构建档案室的三维模型,并提供交互式界面供用户浏览。
- 在模型中设置检索工具或目录系统,允许用户输入查询条件(如关键词、档案编号等)。
- 根据查询条件,高亮显示符合条件的档案位置,并提供导航指引帮助用户快速找到档案。
- 允许用户在虚拟环境中手动浏览档案架、抽屉等,查看档案的详细信息。
定义:人工查档是指档案管理员或用户通过手动方式在档案室中查找和检索档案的过程。
过程:用户或管理员在档案室的目录系统或检索工具中输入查询条件,然后手动浏览档案架、抽屉或密集架,找到符合条件的档案。
适用场景:适用于档案量不大、对查档速度要求不特别高或需要人工判断的情况。
在3D档案室中,人工查档取档的过程通常涉及以下步骤:
- 交互界面查询:用户首先通过2D面板(例如触摸屏或电脑界面)进行档案查询。可以输入关键词、档案编号或其他相关信息来检索所需的档案。
- 系统定位:档案管理系统根据用户输入的查询条件,快速定位到相应的档案位置。这通常涉及到对档案室中各个密集架、档案盒和具体档案的精确管理。
- 人工取档:一旦系统定位到目标档案的位置,用户(通常是档案管理员或工作人员)会前往相应的密集架或档案盒处,手动取出所需的档案。在这个过程中,可能需要使用梯子或其他工具来访问高处的档案。
- 档案核验:取出档案后,工作人员会进行核验,确保取出的档案与用户需求一致。
- 档案利用:核验无误后,档案会被提供给用户进行查阅或使用。在使用完毕后,档案需要按照规定进行归档和整理。
3.3、代码实现
var cabforename = "cabinet2_";var positionZ = [-350];if (area == 1) {
cabforename= "cabinet_";
positionZ= [320];
}var rundata =[];
{var cabobj = msj3DObj.commonFunc.findObject(cabforename +nub);var step1 ={"timeLong": nub * 500 , "position": { "x": cabobj.position.x + 180, "y": 8, "z": 23.203 }, "target": { "x": cabobj.position.x + 15, "y": -18.18775405235692, "z": 23.203 }, "additionsTimeLong": 0,"additions": [
{"changeParam": "position", "position": {
x: cabobj.position.x+ 15,
z:23.203,
},"addtion_name": "people"}
]
};//{ x: -1289.8040127242514, y: 216.26956010470187, z: -193.36005383255667 }
//msj3DObj.controls.target
//si { x: -1287.253404838314, y: 89.3259331925796, z: 0.876428765845767 }
var step2 ={"timeLong": 300, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0,"additions": [
{"changeParam": "function", "function": "sendMessage", "paramvalue": "面向档案架", "addtion_name": "people"}
]
};//转动面向架子
var step3 ={"timeLong": 300, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 100,"additions": [
{"changeParam": "position", "position": {
x: cabobj.position.x+ 15,
z:23.203 + (area == 1 ? 1 : -1),
},"addtion_name": "people"}
]
};//开架
var step3_1 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 1000,"additions": [
{"changeParam": "function", "function": "openCabnitByName", "paramvalue": "打开架子", "addtion_name": cabforename +nub },
{"changeParam": "function", "function": "sendMessage", "paramvalue": "打开架子", "addtion_name": "people"}
]
};
rundata=rundata.concat([step1, step2, step3, step3_1]);for (var pj = 0; pj < positionZ.length; pj++) {//进入 位置一
var step4 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 3000,"additions": [
{"changeParam": "position", "position": {
x: cabobj.position.x+ 15,
z: positionZ[pj],
},"addtion_name": "people"}
]
};//转动面向架子
var step5 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 100,"additions": [
{"changeParam": "position", "position": {
x: cabobj.position.x+ (area == 1 ? 16 : 14),
z: positionZ[pj],
},"addtion_name": "people"}
]
};//停留
var step6 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": 89.3259331925796, z: 0.876428765845767 }, "additionsTimeLong": 0, "additionsTimeLong": 17000,"additions": [
{"changeParam": "function", "function": "peopleGetBook", "paramvalue": "取书_" + area + "_" + nub, "addtion_name": "people"},
{"changeParam": "function", "function": "sendMessage", "paramvalue": "取档案", "addtion_name": "people"}
]
};
rundata=rundata.concat([step4, step5, step6]);
}//转动角度
var step7 ={"timeLong": 300, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": -18.18775405235692, "z": 23.203 }, "additionsTimeLong": 0, "additionsTimeLong": 0};//回退
var step8 ={"timeLong": 0, "position": { "x": cabobj.position.x + 15, "y": 212, "z": (area == 1 ? -193 : 197) }, "target": { "x": cabobj.position.x + 15, "y": -18.18775405235692, "z": 23.203 }, "additionsTimeLong": 5000,"additions": [
{"changeParam": "position", "position": {
x: cabobj.position.x+ 15,
z:23.203,
},"addtion_name": "people"}
]
};
rundata=rundata.concat([step7, step8]);
}this.peopleSearchData = this.peopleSearchData.concat(rundata);this.peopleSearchData.push({"timeLong": 0, "position": { "x": 1496.961677226794, "y": 6.048526864006573, "z": -396.50227110708374 }, "target": { "x": 1482.9322600214946, "y": -4.512061245433281, "z": -165.11374369473938 }, "additionsTimeLong": 1000,"additions": [
{"changeParam": "function", "function": "stopChaDang", "paramvalue": "停止查档", "addtion_name": ""}
]
});this.doRouteRun(0, this.peopleSearchData);四、设备巡检
4.1、效果展示

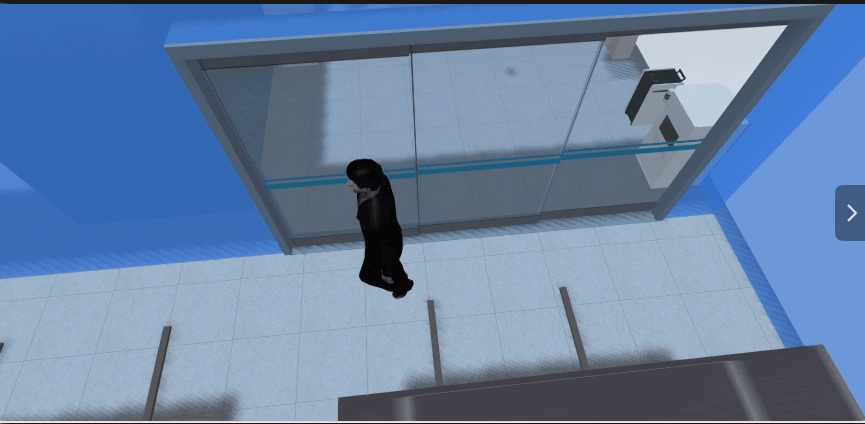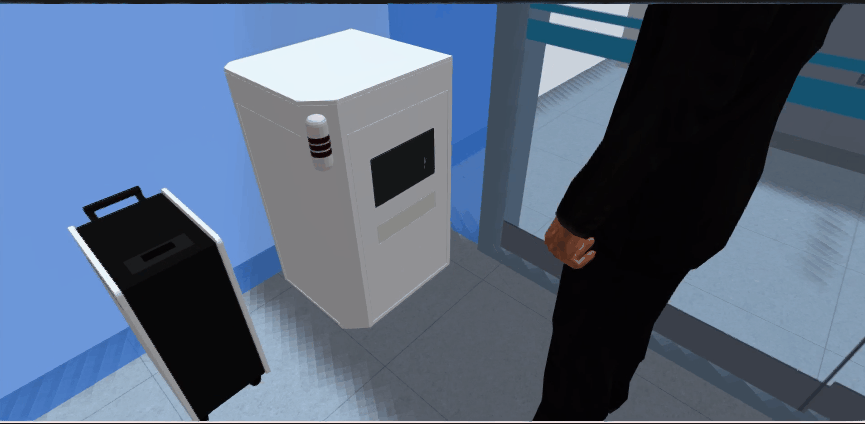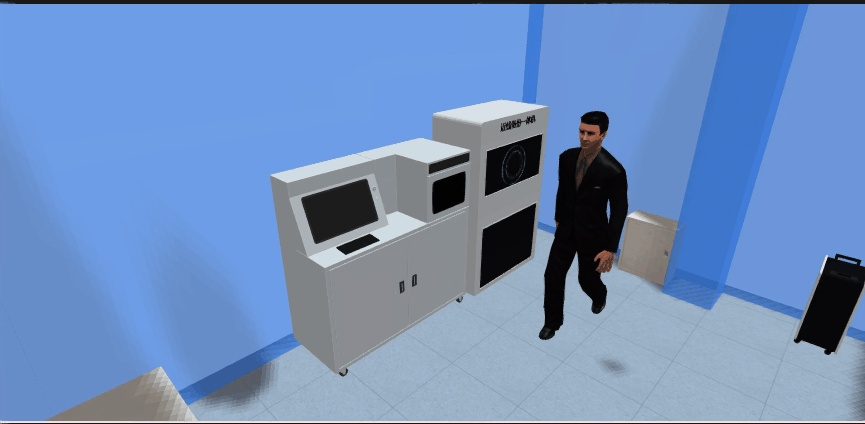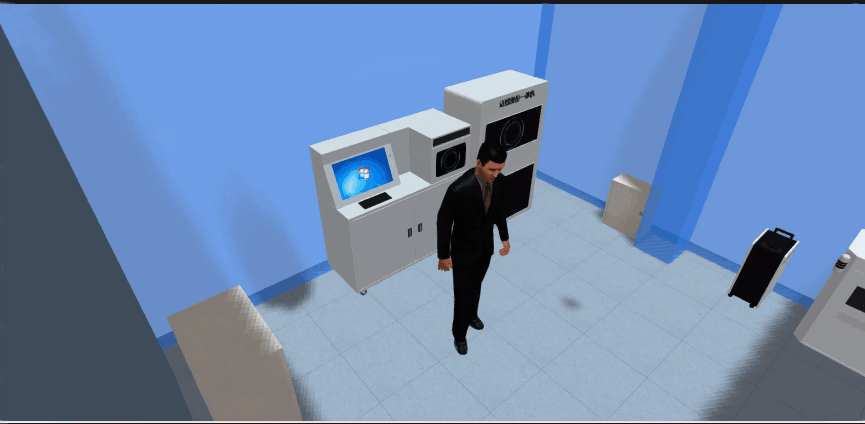
4.2、解决方案
3D模拟档案室设备巡检是一种利用3D建模和仿真技术来模拟和评估档案室设备巡检过程的方法。这种技术可以帮助档案管理员或设备维护人员在不进入实际档案室的情况下,对档案室设备进行全面、系统的检查和评估。以下是3D模拟档案室设备巡检的一般步骤:
建立3D档案室模型:首先,需要利用3D建模软件建立档案室的详细模型。模型应该包括档案室内的所有设备、设施以及空间布局。
设备数据集成:将档案室设备的实际运行数据集成到3D模型中。这些数据可以包括设备的运行状态、温度、噪音等参数,以便在模拟过程中进行实时监测和分析。
制定巡检计划:在3D模型中制定设备巡检计划,明确巡检的路线、时间以及需要检查的设备。
模拟巡检过程:通过仿真软件,模拟巡检人员按照巡检计划在档案室内进行设备巡检的过程。在模拟过程中,可以实时监测设备的运行状态和参数,并发现潜在的问题或隐患。
问题诊断与分析:根据模拟巡检的结果,对发现的问题或隐患进行诊断和分析。可以利用仿真软件提供的数据分析工具,对设备的运行状态、性能等指标进行深入挖掘,为后续的维护和管理提供决策支持。
结果展示与报告:将模拟巡检的结果以直观的方式进行展示,如生成巡检报告、数据分析图表等。这些结果可以作为改进档案室设备管理和维护的依据,帮助提高设备巡检的效率和准确性。
通过3D模拟档案室设备巡检,可以在不进入实际档案室的情况下,全面、系统地检查和评估档案室设备的运行状态和性能。这种技术可以帮助档案管理员或设备维护人员及时发现潜在问题或隐患,提高设备巡检的效率和准确性,为档案室的安全和稳定运行提供有力保障。
实现:
- 使用3D建模软件构建档案室的三维模型,并集成各种设备和传感器的模型。
- 编写巡检逻辑,模拟巡检人员按照预定的巡检计划和路线在虚拟环境中进行巡检。
- 使用传感器模拟技术,模拟巡检人员使用各种设备(如温度计、湿度计、摄像头等)对档案室环境进行监测和记录。
- 在巡检过程中,如果发现异常情况或问题,可以通过可视化界面进行标注和记录,以便后续处理和改进。
定义:巡检是指定期对档案室的设施、设备和环境进行检查和评估的过程,以确保档案室的安全和正常运行。
过程:巡检人员按照预定的巡检计划和路线,对档案室的空调、消防系统、安防设备、照明、温度湿度等环境参数进行检查,记录异常情况,并及时处理。
目的:预防潜在的安全隐患,及时发现和解决问题,确保档案的安全保存和档案的连续性。
由于篇幅原因,我们本节课先到这里,后面我们更新如何创建一个可编辑工具完成配置
技术交流 1203193731@qq.com
如果你有什么要交流的心得 可邮件我
其它相关文章:
如何使用webgl(three.js)实现煤矿隧道、井下人员定位、掘进面、纵采面可视化解决方案——第十九课(一)
如何使用webgl(three.js)实现3D消防、3D建筑消防大楼、消防数字孪生、消防可视化解决方案——第十八课(一)
webgl(three.js)3D光伏,3D太阳能能源,3D智慧光伏、光伏发电、清洁能源三维可视化解决方案——第十六课
如何用webgl(three.js)搭建一个3D库房,3D仓库3D码头,3D集装箱,车辆定位,叉车定位可视化孪生系统——第十五课
webgl(three.js)实现室内三维定位,3D定位,3D楼宇bim、实时定位三维可视化解决方案——第十四课(定位升级版)
使用three.js(webgl)搭建智慧楼宇、设备检测、数字孪生——第十三课
如何用three.js(webgl)搭建3D粮仓、3D仓库、3D物联网设备监控-第十二课
如何用webgl(three.js)搭建处理3D隧道、3D桥梁、3D物联网设备、3D高速公路、三维隧道桥梁设备监控-第十一课
如何用three.js实现数字孪生、3D工厂、3D工业园区、智慧制造、智慧工业、智慧工厂-第十课
使用webgl(three.js)创建3D机房,3D机房微模块详细介绍(升级版二)
如何用webgl(three.js)搭建一个3D库房-第一课
如何用webgl(three.js)搭建一个3D库房,3D密集架,3D档案室,-第二课
使用webgl(three.js)搭建一个3D建筑,3D消防模拟——第三课
使用webgl(three.js)搭建一个3D智慧园区、3D建筑,3D消防模拟,web版3D,bim管理系统——第四课
如何用webgl(three.js)搭建不规则建筑模型,客流量热力图模拟
使用webgl(three.js)搭建一个3D智慧园区、3D建筑,3D消防模拟,web版3D,bim管理系统——第四课(炫酷版一)
如何用webgl(three.js)搭建处理3D园区、3D楼层、3D机房管线问题(机房升级版)-第九课(一)

