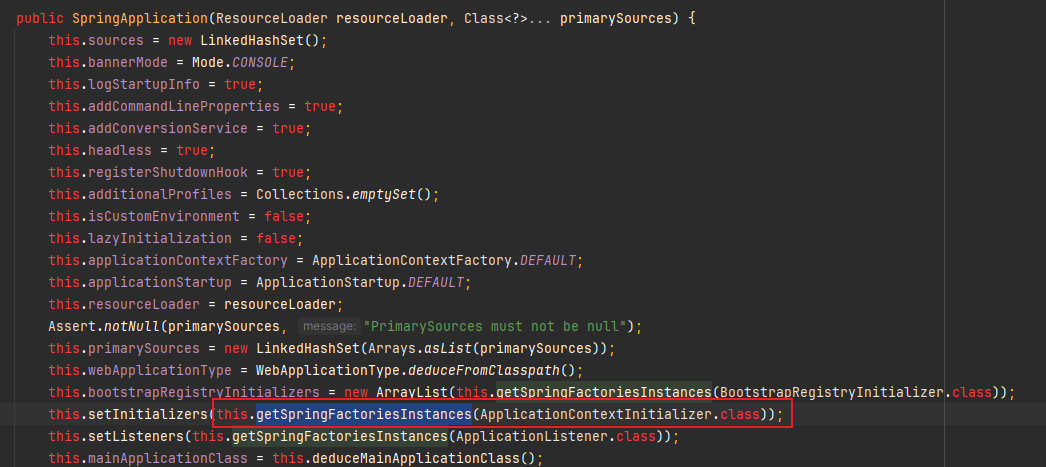
毫秒时间位数,时而1位,时而2位,时而3位,搞得我好乱呐!
开心一刻
今天我突然顿悟了,然后跟我妈聊天
我:妈,我发现一个饿不死的办法
妈:什么办法
我:我先养个狗,再养个鸡
妈:然后了
我:我拉的狗吃,狗拉的鸡吃,鸡下的蛋我吃,如此反复,我们三都饿不死
妈:你整那么多中间商干啥,你就自己拉的自己吃得了,还省事
我又顿悟了,回到:也是啊

说句很重要的心里话:祝大家在2024年,身体健康,万事如意!
场景重温
为了让大家更好的明白问题,先做下相关准备工作
环境准备
数据库:
MySQL
8.0
.
30
,表:
tbl_order


DROP TABLE IF EXISTS`tbl_order`;CREATE TABLE`tbl_order` (
`id`bigint(0) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`order_no`varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '业务名',
`created_at`datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`updated_at`datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '最终修改时间',PRIMARY KEY(`id`) USING BTREE
) ENGINE= InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '订单' ROW_FORMAT =Dynamic;--------------------------------Records of tbl_order------------------------------ INSERT INTO `tbl_order` VALUES (1, '123456', '2023-04-20 07:37:34.000', '2023-04-20 07:37:34.720');INSERT INTO `tbl_order` VALUES (2, '654321', '2023-04-20 07:37:34.020', '2023-04-20 07:37:34.727');
View Code
基于
JDK1.8
、
druid 1.1.12
、
mysql-connector-java 8.0.21
、
Spring 5.2.3.RELEASE
完整代码:
druid-timeout
毫秒位数捉摸不透
直接运行
com.qsl.DruidTimeoutTest#main
,会看到如下结果

数据库表中的值:
2023-04-20 07:37:34.000
运行出来后是
2023-04-20 07:37:34.0
,
2023-04-20 07:37:34.720
对应
2023-04-20 07:37:34.72
2023-04-20 07:37:34.020
对应
2023-04-20 07:37:34.02
,
2023-04-20 07:37:34.727
对应
2023-04-20 07:37:34.727
毫秒位数时而1位,时而2位,时而3位,搞的我好乱呐

原因分析
大家注意看这个代码

获取列值,
sqlRowSet.getObject(i)
返回的类型是
Object
,我们调整下输出:
System.out.println(obj.getClass().getName() + " " + obj);
此时输出结果如下
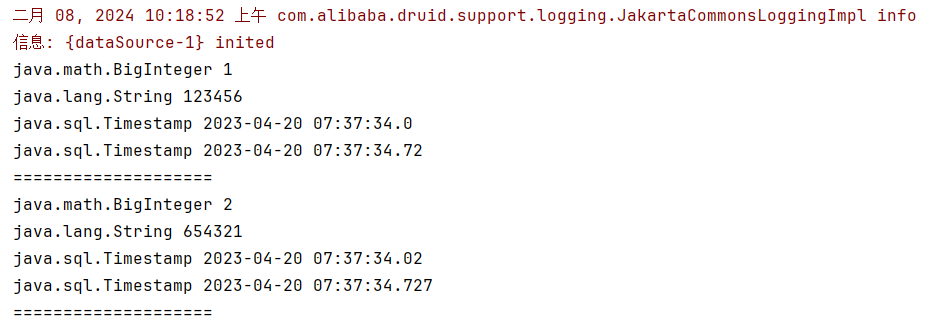
可以看到,
java
程序中,此时的时间类型是
java.sql.Timestamp
有了这个依托点,原因就很好分析了
Timestamp的toString
我们知道,
java
中直接输出对象,会调用对象的
toString
方法,如果自身没有重写
toString
则会沿用
Object
的
toString
方法
我们先来看一下
Object
的
toString
方法

粗略看一下,返回值明显不是
2023-04-20 07:37:34.0
这种时间字符串格式
那说明什么?
说明
Timestamp
肯定重写了
toString
方法嘛
java.sql.Timestamp#toString
内容如下
/*** Formats a timestamp in JDBC timestamp escape format.
* <code>yyyy-mm-dd hh:mm:ss.fffffffff</code>,
* where <code>ffffffffff</code> indicates nanoseconds.
* <P>
*@returna <code>String</code> object in
* <code>yyyy-mm-dd hh:mm:ss.fffffffff</code> format*/@SuppressWarnings("deprecation")publicString toString () {int year = super.getYear() + 1900;int month = super.getMonth() + 1;int day = super.getDate();int hour = super.getHours();int minute = super.getMinutes();int second = super.getSeconds();
String yearString;
String monthString;
String dayString;
String hourString;
String minuteString;
String secondString;
String nanosString;
String zeros= "000000000";
String yearZeros= "0000";
StringBuffer timestampBuf;if (year < 1000) {//Add leading zeros yearString = "" +year;
yearString= yearZeros.substring(0, (4-yearString.length())) +yearString;
}else{
yearString= "" +year;
}if (month < 10) {
monthString= "0" +month;
}else{
monthString=Integer.toString(month);
}if (day < 10) {
dayString= "0" +day;
}else{
dayString=Integer.toString(day);
}if (hour < 10) {
hourString= "0" +hour;
}else{
hourString=Integer.toString(hour);
}if (minute < 10) {
minuteString= "0" +minute;
}else{
minuteString=Integer.toString(minute);
}if (second < 10) {
secondString= "0" +second;
}else{
secondString=Integer.toString(second);
}if (nanos == 0) {
nanosString= "0";
}else{
nanosString=Integer.toString(nanos);//Add leading zeros nanosString = zeros.substring(0, (9-nanosString.length())) +nanosString;//Truncate trailing zeros char[] nanosChar = new char[nanosString.length()];
nanosString.getChars(0, nanosString.length(), nanosChar, 0);int truncIndex = 8;while (nanosChar[truncIndex] == '0') {
truncIndex--;
}
nanosString= new String(nanosChar, 0, truncIndex + 1);
}//do a string buffer here instead. timestampBuf = new StringBuffer(20+nanosString.length());
timestampBuf.append(yearString);
timestampBuf.append("-");
timestampBuf.append(monthString);
timestampBuf.append("-");
timestampBuf.append(dayString);
timestampBuf.append(" ");
timestampBuf.append(hourString);
timestampBuf.append(":");
timestampBuf.append(minuteString);
timestampBuf.append(":");
timestampBuf.append(secondString);
timestampBuf.append(".");
timestampBuf.append(nanosString);return(timestampBuf.toString());
}
View Code
注意看注释:
yyyy-mm-dd hh:mm:ss.fffffffff
,说明精度是到纳秒级别,不只是到毫秒哦!
该方法很长,我们只需要关注
fffffffff
的处理,也就是如下代码

nanos
类型是
int
:
private
int
nanos;
,用来存储秒后面的那部分值
数据库表中的值:
2023-04-20 07:37:34.000
对应的
nanos
的值是 0,
2023-04-20 07:37:34.720
对应的
nanos
的值是多少了?
不是、不是、不是
720
,因为它的格式是
fffffffff
,所以应该是
720000000
那
2023-04-20 07:37:34.020
对应的
nanos
的值又是多少?
不是、不是、不是
200000000
,而是
20000000
,因为
nanos
是
int
类型,不能以0开头
再回到上述代码,当
nanos
等于 0 时,
nanosString
即为字符串0,所以
2023-04-20 07:37:34.000
对应
2023-04-20 07:37:34.0
当
nanos
不等于 0 时
1、先将
nanos
转换成字符串
nanosString
,
nanosString
的位数与
nanos
一致
2、
nanosString
前补0,
nanos
的位数与 9 差多少就前补多少个0
例如
2023-04-20 07:37:34.020
对应的
nanos
是
20000000
,只有8位,前补1个0,则
nanosString
的值是
020000000
3、去掉末尾的0
020000000
去掉末尾的0,得到
02
原因是不是找到了?
总结下就是:
java.sql.Timestamp#toString
会格式化掉
nanosString
末尾的0!(注意:
nanos
的值是没有变的)
是不是很精辟

但是问题又来了:为什么要格式化末尾的0?
说实话,我没有找到一个确切的、准确的说明
只是自己给自己编造了一个勉强的理由:简洁化,提高可读性
去掉
nanosString
末尾的 0,并没有影响时间值的准确性,但是可以简化整个字符串,末尾跟着一串0,可读性会降低
如果非要保留末尾的0,可以自定义格式化方法,想保留几个0就保留几个0
类型对应
MySQL
类型和
JAVA
类型是如何对应的,是不是很想知道这个问题?
那就安排起来,如何寻找了?
别慌,我有葵花宝典:
杂谈篇之我是怎么读源码的,授人以渔
为了节约时间,我就不带你们一步一步
debug
了,直接带你们来到关键点
com.mysql.cj.protocol.a.ColumnDefinitionReader#read
里面有如下关键代码

为了方便你们跟源码,我把此刻的堆栈信息贴一下

我们继续跟进
unpackField
,会发现里面有这样一行代码

恭喜你,只差临门一脚了
按住
ctrl
键,鼠标左击
MysqlType
,欢迎来到
类型对应
世界:
com.mysql.cj.MysqlType
其构造方法
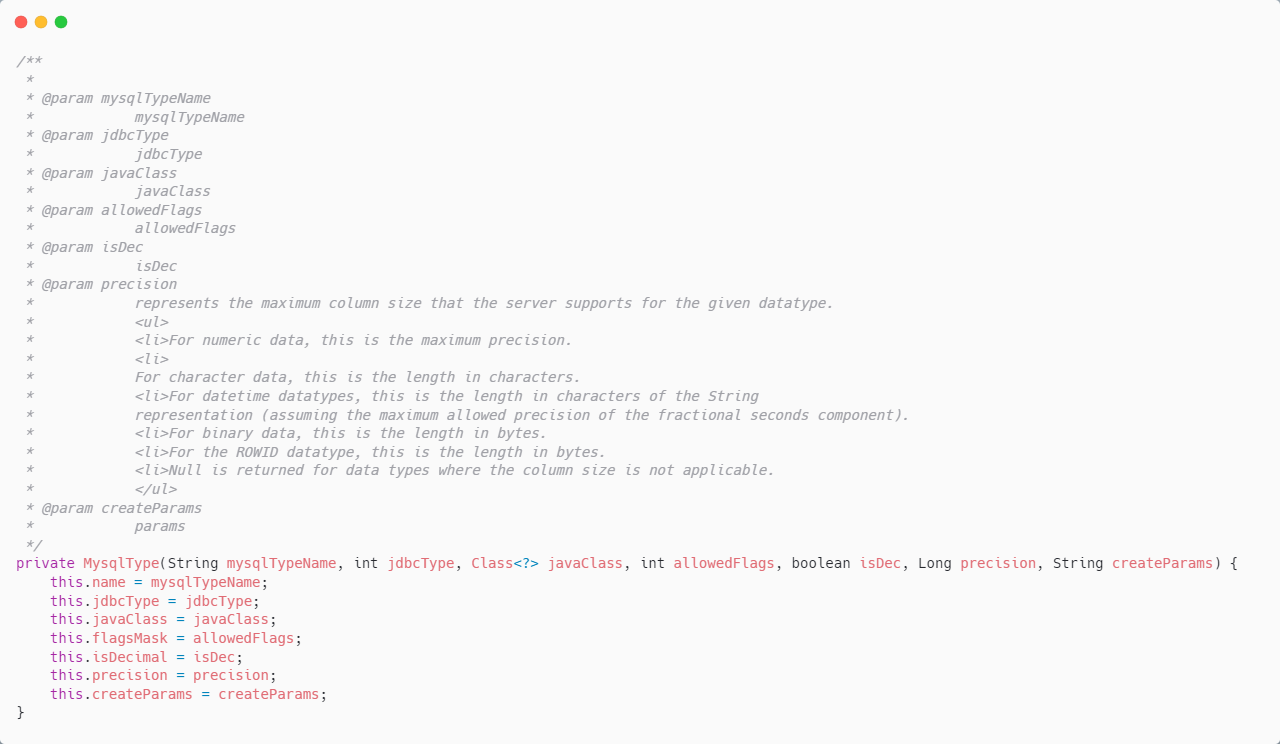
我们暂时只需要关注:
mysqlTypeName
、
jdbcType
和
javaClass
接下来我们找到
MySQL
的
DATETIME

此处的
Timestamp.
class
就是
java.sql.Timestamp
其他的对应关系,大家也可以看看,比如
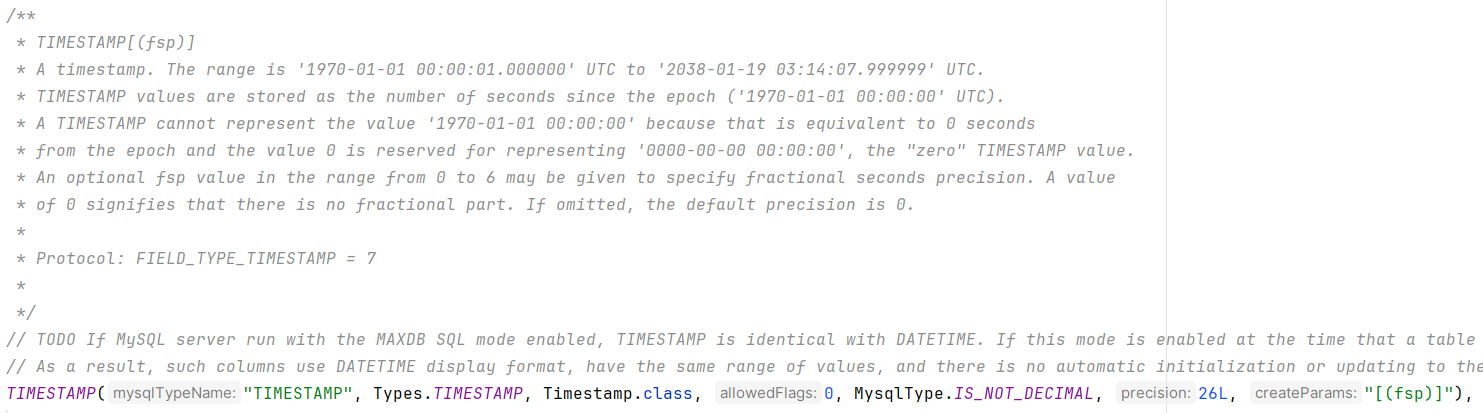
额外拓展
TIMESTAMP范围
回答这个问题的时候,一定要说明前提条件
MySQL8
,范围是
'1970-01-01 00:00:01' UTC to '2038-01-19 03:14:07' UTC

JDK8
,
Timestamp
构造方法

入参是
long
类型,其最大值是
9223372036854775807
,1 年是
365*24*60*60*1000=31536000000
毫秒
也就是
long
最大可以记录
6269161692
年,所以范围是
1970 ~ (1970 + 6269161692)
,不会有
2038年问题
MySQL
的
TIMESTAMP
和
JAVA
的
Timestamp
是对应关系,并不是对等关系,大家别搞混了
关于不允许使用java.sql.Timestamp
阿里巴巴的开发手册中明确指出不能用:
java.sql.Timestamp

为什么
mysql-connector-java
还要用它?
可以从以下几点来分析
1、
java.sql.Timestamp
存在有存在的道理,它有它的优势
1.1 精度到了纳秒级别
1.2 被设计为与
SQL TIMESTAMP
类型兼容,这意味着在数据库交互中,使用
Timestamp
可以减少数据类型转换的问题,提高数据的一致性和准确性
1.3 时间方面的计算非常方便
2、在某些特定情况下才会触发
Timestamp
的
bug
,我们不能以此就完全否定
Timestamp
吧
况且
JDK9
也修复了
3、
MySQL
的
TIMESTAMP
如果不对应
java.sql.Timestamp
,那该对应
JAVA
的哪个类型?
MySQL的DATETIME为什么也对应java.sql.Timestamp
MySQL
的
TIMESTAMP
对应
java.sql.Timestamp
,对此我相信大家都没有疑问
为何
MySQL
的
DATETIME
也对应
java.sql.Timestamp
?
我反问一句,不对应
java.sql.Timestamp
对应哪个?
LocalDateTime
?试问
JDK8
之前有
LocalDateTime
吗?
不过
mysql-connector-java
还是做了调整,我们来看下
我把
mysql-connector-java
的源码
clone
下来了,更方便我们查看提交记录
找到
com.mysql.cj.MysqlType#DATETIME
,在其前面空白处右击
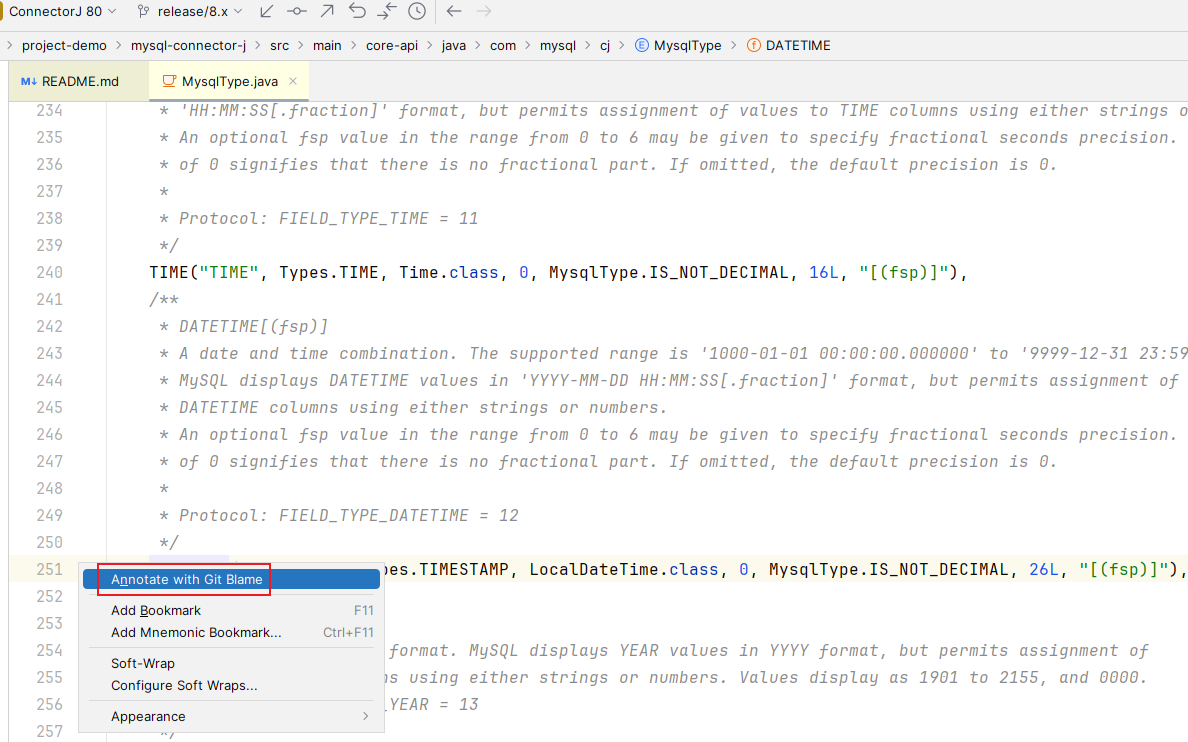
鼠标左击
Annotate with Git Blame
,会看到每一行的最新修改提交记录
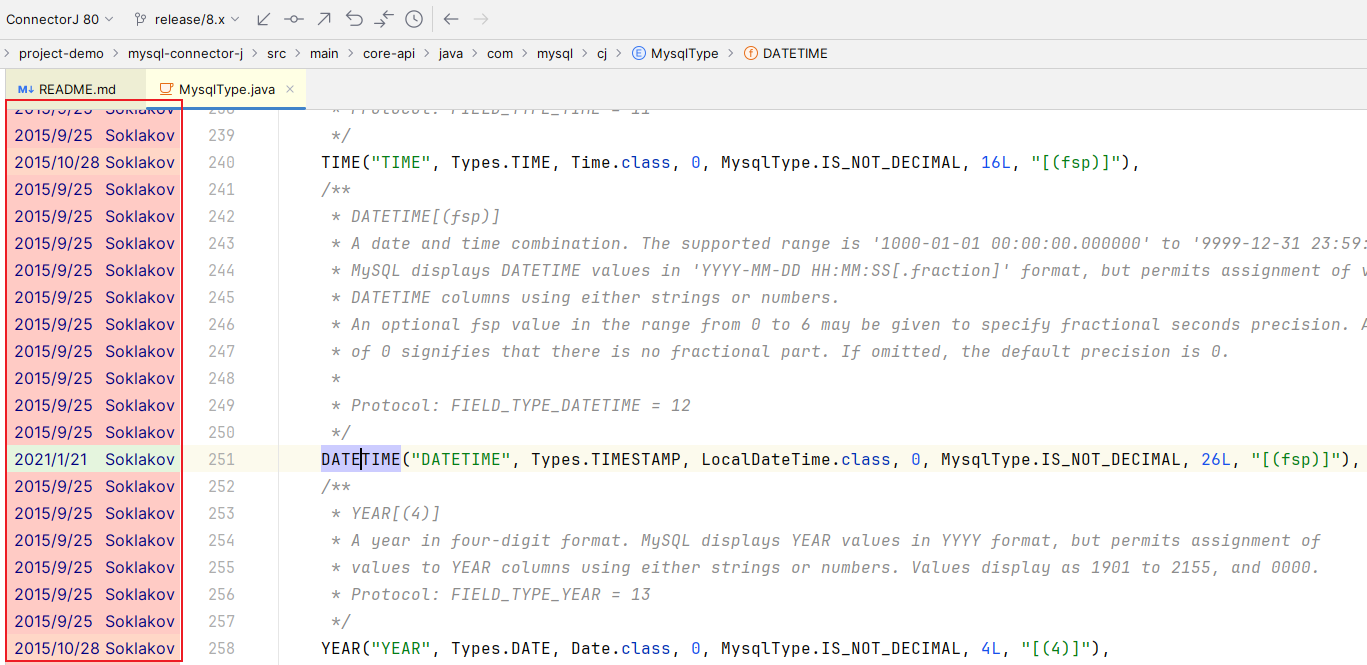
我们继续左击
DATETIME
的最新修改提交记录

可以看到详细的提交信息
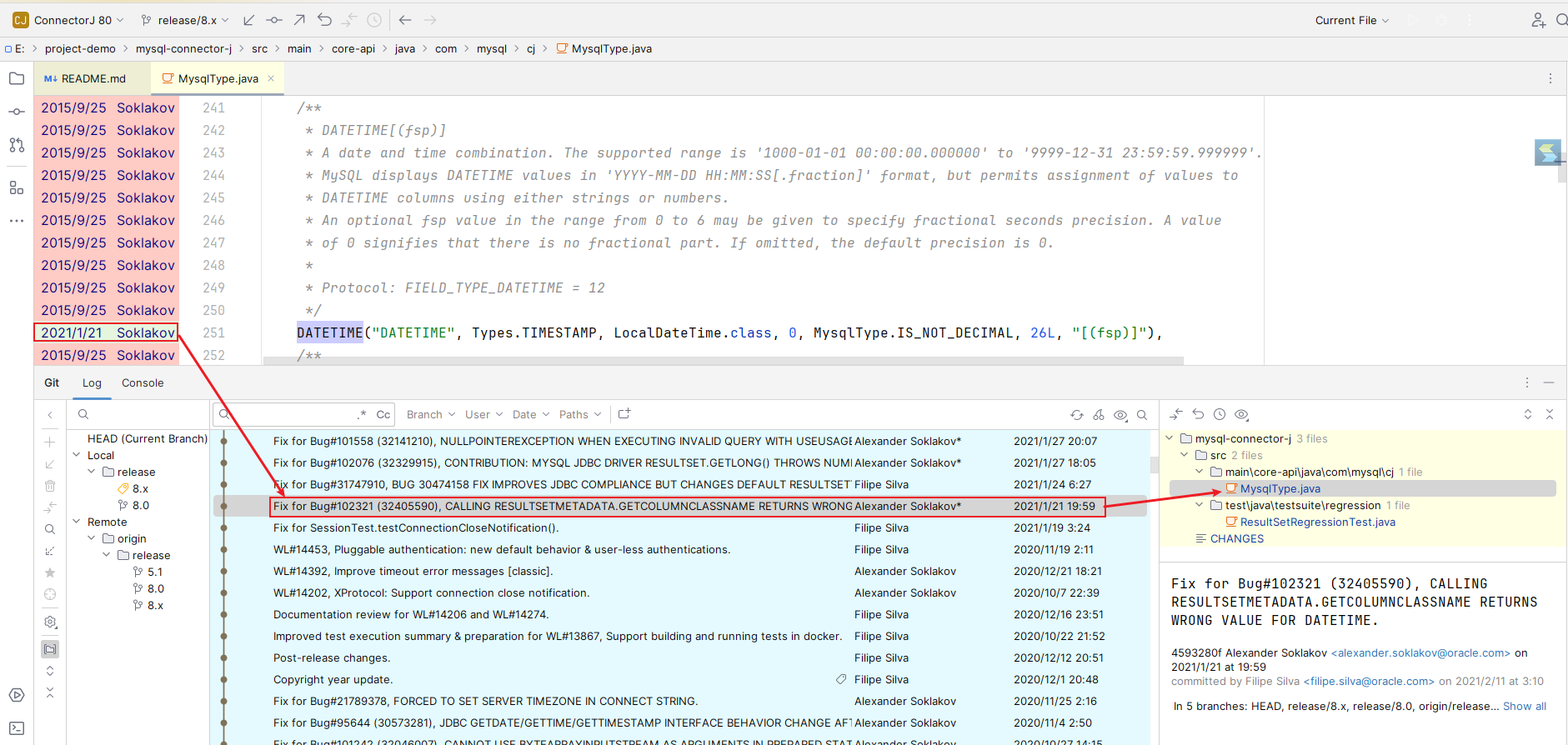
双击
MysqlType.java
,可以看到修改内容
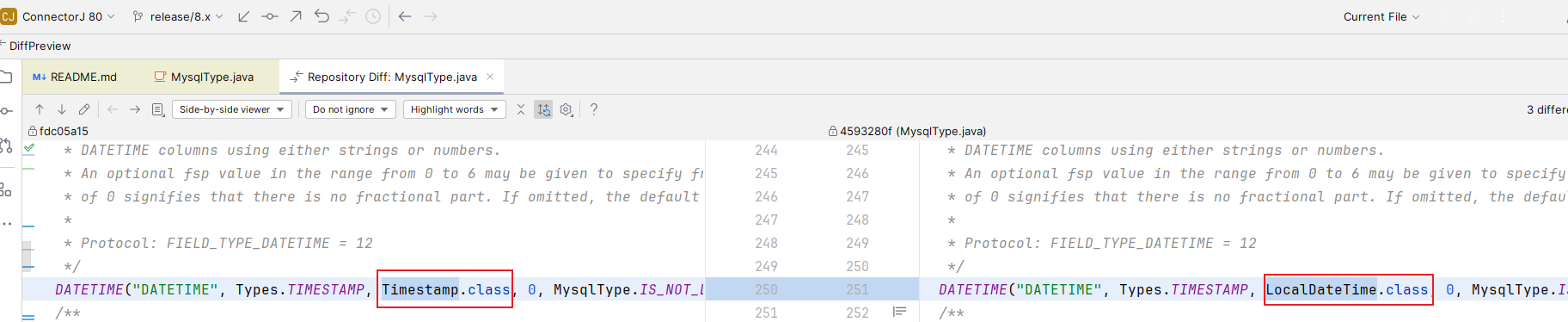
可以看到
MySQL
的
DATETIME
对应的
JAVA
类型从
java.sql.Timestamp
调整成了
java.time.LocalDateTime
那
mysql-connector-java
哪个版本开始生效的了?
它是开源的,那就直接在
github
上找
mysql-connector-java
的
issue
:
Bug#102321
但是你会发现搜不到

这是因为
mysql-connector-java
调整成了
mysql-connector-j
,相关
issue
没有整合
那么我们就换个方式搜,就像这样
回车,结果如下
也没有搜到!!!
但你去点一下左侧的
Commits
,你会发现有结果!!!
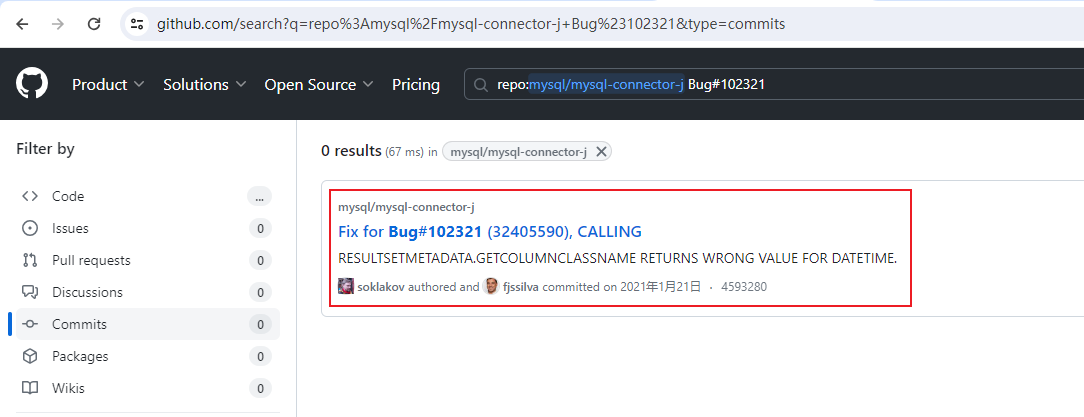
Commits
不是 0 吗,怎么有结果,谁来都懵呀

这绝对是
github
的
Bug
呀(这个我回头找下官方确认下,不深究!)

我们点击
Commits
的这个搜索结果,会来到如下界面
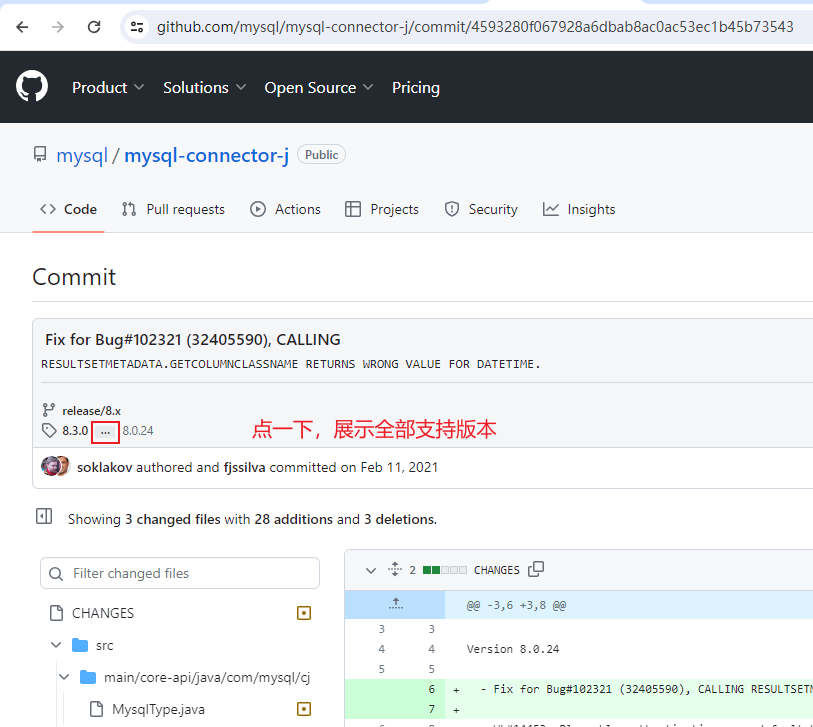
答案已经揭晓
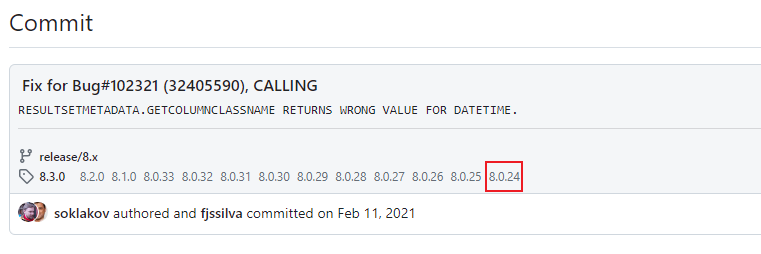
从
8.0.24
开始,
MySQL
的
DATETIME
对应的
JAVA
类型从
java.sql.Timestamp
调整成
java.time.LocalDateTime
总结
java.sql.Timestamp
1、设计初衷就是为了对应
SQL TIMESTAMP
,所以不管是
MySQL
还是其他数据库,其
TIMESTAMP
对应的
JAVA
类型都是
java.sql.Timestamp
2、
MySQL
的
TIMESTAMP
有
2038年
问题,是因为它的底层存储是 4 个字节,并且最高位是符号位,至于其他类型的数据库是否有该问题,得看具体实现
3、在清楚使用情况的前提下(不触发
JDK8 BUG
)是可以使用的,有些场景使用
java.sql.Timestamp
确实更方便
DATETIME对应类型
SQL DATETIME
对应的
JAVA
类型,没有统一标准,需要看具体数据库的
jdbc
版本
比如
mysql-connector-java
,
8.0.24
之前,
DATETIME
对应的
JAVA
类型是
java.sql.Timestamp
,而
8.0.24
及之后,对应的是
java.time.LocalDateTime
至于其他数据库的
jdbc
是如何对应的,就交给你们了,可以从最新版本着手去分析