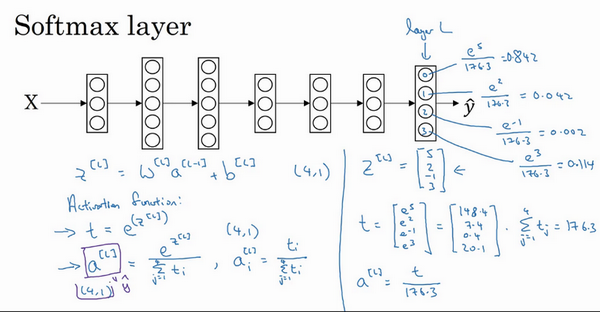
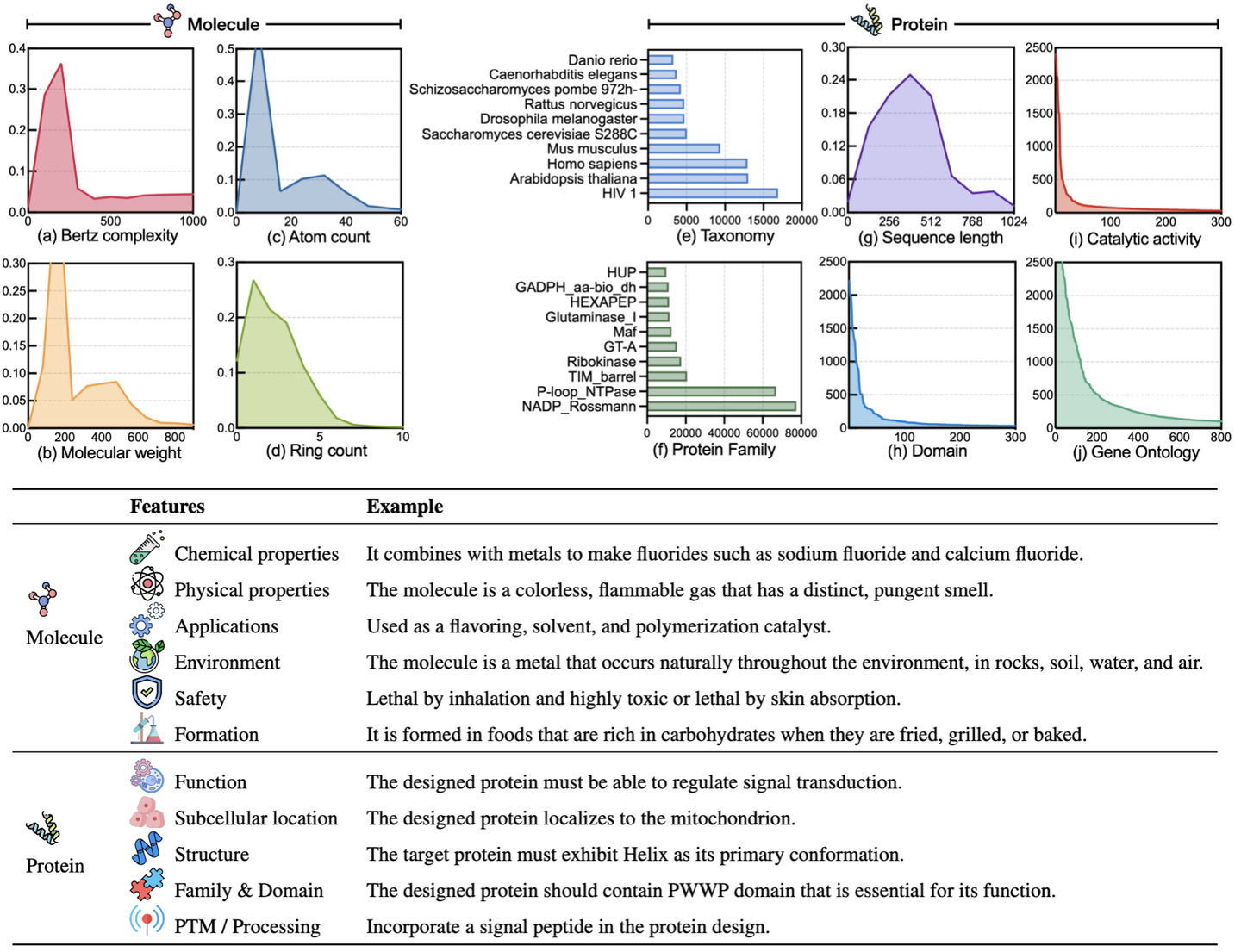
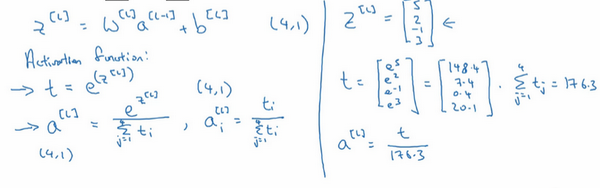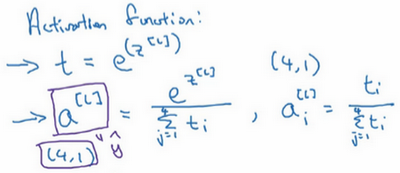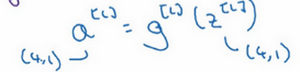本文介绍基于
C++
语言
GDAL
库,
批量读取
大量栅格遥感影像文件,并生成
各像元数值的时间序列
数组的方法。
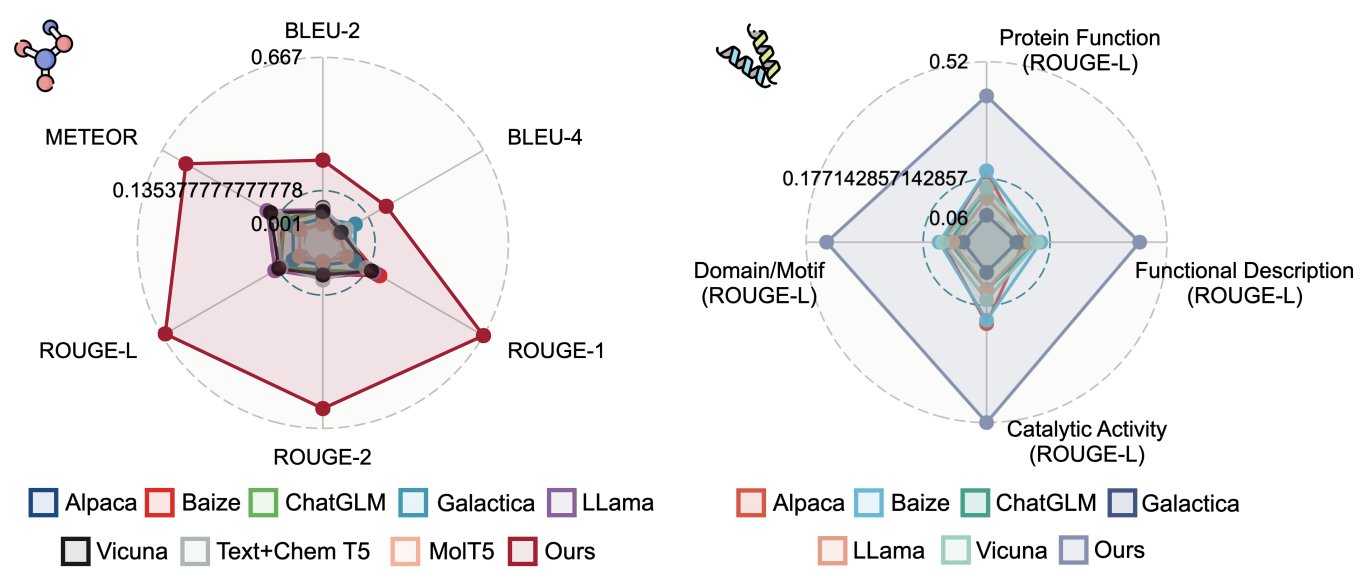
首先,我们来明确一下本文所需实现的需求。现在有一个文件夹,其中包含了很多不同格式的文件,如下图所示。

其中,我们首先需要遍历这一文件夹,遴选出其中所有类型为
.bmp
格式的栅格遥感影像文件(一共有
6
个),并分别读取文件(已知这些遥感影像的行数、列数都是一致的);随后,将
不同遥感影像
的
同一个位置的像素
的数值进行分别读取,并存储在一个数组中。例如,最终我们生成的第一个数组,其中共有
6
个元素,分别就是上图所示文件夹中
6
景遥感影像各自
(0,0)
位置的像元数值;生成的第二个数组,其中也是
6
个元素,分别就是
6
景遥感影像各自
(1,0)
位置的像元数值,以此类推。其中,显然我们得到的
数组个数
,就是遥感影像
像元的个数
。此外,这里
6
景遥感影像的
排序
,是按照
文件名称的升序
来进行的。
明确了具体需求,接下来就可以开始代码的实践。其中,本文分为两部分,第一部分为代码的分段讲解,第二部分为完整代码。
此外,本文是基于
GDAL
库来实现栅格数据读取的;具体
GDAL
库的配置方法大家可以参考文章
在Visual Studio中部署GDAL库的C++版本(包括SQLite、PROJ等依赖)
。
1 代码分段介绍
1.1 代码准备
这一部分主要是代码的
头文件
、
命名空间
与我们自行撰写的
自定义函数
get_need_file()
的声明;具体代码如下所示。
#include <iostream>
#include <vector>
#include <io.h>
#include "gdal_priv.h"
using namespace std;
void get_need_file(string path, vector<string>& file, string ext);
其中,由于我们在接下来的代码中需要用到容器
vector
这一数据类型,因此首先需要添加
#include <vector>
;同时,我们在接下来的代码中需要用到头文件
io.h
中的部分函数(主要都是一些与计算机系统、文件管理相关的函数),因此需要添加
#include <io.h>
;此外,我们是基于
GDAL
库来实现栅格数据读取的,因此需要添加
#include "gdal_priv.h"
。
接下来,这里声明了一个自定义函数
get_need_file()
,具体我们在本文
1.2
部分介绍。
1.2 栅格文件筛选
由于我这里几乎将全部的代码都放在了主函数中,因此这一部分就先介绍代码
main()
函数的第一部分,亦即栅格文件的遴选部分;具体代码如下所示。
int main() {
string file_path = R"(E:\02_Project\02_ChlorophyllProduce\01_Data\00_Test)";
vector<string> my_file;
string need_extension = ".bmp";
get_need_file(file_path, my_file, need_extension);
int file_size = my_file.size();
if (file_size == 0)
{
cout << "No file can be found!" << endl;
}
else
{
cout << "Find " << file_size << " file(s).\n" << endl;
}
这一部分主要就是做好调用自定义函数
get_need_file()
的变量准备,并调用
get_need_file()
函数,得到指定文件夹下的栅格文件;随后,将栅格文件的筛选结果进行输出。这一部分的具体代码介绍,大家查看文章
C++遴选出特定类型的文件或文件名符合要求的文件
即可,这里就不再赘述。
1.3 栅格文件读取
这一部分主要是基于
GDAL
库,循环读取前述文件夹中的每一个栅格遥感影像文件。
int nXSize, nYSize;
float** pafScanline = new float* [file_size];
int pic_index = 1;
for (auto x : my_file)
{
GDALDataset* poDataset;
GDALAllRegister();
CPLSetConfigOption("GDAL_FILENAME_IS_UTF8", "NO");
poDataset = (GDALDataset*)GDALOpen(x.c_str(), GA_ReadOnly);
if (poDataset == NULL)
{
cout << "Open File " << x << " Error!" << endl;
}
else
{
cout << "Open File " << x << " Success!" << endl;
}
GDALRasterBand* poBand;
poBand = poDataset->GetRasterBand(1);
nXSize = poBand->GetXSize();
nYSize = poBand->GetYSize();
cout << nXSize << "," << nYSize << "\n" << endl;
pafScanline[pic_index - 1] = new float[nXSize * nYSize];
poBand->RasterIO(GF_Read, 0, 0, nXSize, nYSize, pafScanline[pic_index - 1], nXSize, nYSize, GDT_Float32, 0, 0);
pic_index ++;
}
其中,
nXSize
与
nYSize
分别表示栅格遥感影像的列数与行数,
pafScanline
是我们读取栅格遥感影像文件所需的变量,之后读取好的遥感影像数据就会存放在这里;由于我们有多个栅格文件需要读取,因此通过
for
循环来实现批量读取的操作,并通过
pic_index
这个变量作为每一次读取文件的计数。
在这里,
float** pafScanline = new float* [file_size];
这句代码表示我们将
pafScanline
作为一个
指向指针的指针
的数组;在后期读取遥感影像数据后,
pafScanline[0]
、
pafScanline[1]
一直到
pafScanline[5]
,这
6
个数值同样分别是指针,分别指向存储
6
景遥感影像数据的地址。这里我们通过
new
实现对
pafScanline
内存的动态分配,因为我们在获取栅格遥感影像的景数(也就是文件夹中栅格遥感影像文件的个数)之前,也不知道具体需要给
pafScanline
这一变量分配多少的内存。此外,在
for
循环中,我们还对
pafScanline[0]
、
pafScanline[1]
一直到
pafScanline[5]
同样进行了动态内存分配,因为我们在获取每一景栅格遥感影像的行数与列数之前,同样是不知道需要给
pafScanline[x]
这
6
个数组变量分配多少内存的。
随后,
for
循环中的其他部分,就是
GDAL
库读取遥感影像的基本代码。读取第一景遥感影像数据后,我们将数据保存至
pafScanline[0]
,并随后进行第二次循环,读取第二景遥感影像数据,并将其数据保存至
pafScanline[1]
中,随后再次循环;以此类推,直至读取
6
景遥感影像完毕。
如果大家只是需要实现
C++
批量读取栅格遥感影像数据,那么以上操作就已经实现了大家的需求。其中,显然
pafScanline[0]
就是第一景遥感影像数据,
pafScanline[1]
就是第二景遥感影像数据,
pafScanline[2]
就是第三景遥感影像数据,以此类推。
1.4 像元时间序列数组生成
这一部分则是基于以上获取的各景遥感影像数据读取结果,进行每一个
像元数值的时间序列数组
生成。
float** pixel_paf = new float* [nXSize * nYSize];
for (int pixel_num = 0; pixel_num < nXSize * nYSize; pixel_num++)
{
pixel_paf[pixel_num] = new float[file_size];
for (int time_num = 0; time_num < file_size; time_num++)
{
pixel_paf[pixel_num][time_num] = pafScanline[time_num][pixel_num];
}
}
这一部分的代码思路其实也非常简单,就是通过两个
for
循环,将原本
一共
6
个
的、每一个表示
每一景遥感影像中全部数据
的数组,转变为
一共
X
个
的(
X
表示每一景遥感影像的像元总个数)、每一个表示
每一个位置的像元在
6
景遥感影像中的各自数值
的数组。
在这里,由于同样的原因,我们对
pixel_paf
亦进行了内存的动态分配。
1.5 输出测试与代码收尾
这一部分主要是输出一个我们刚刚配置好的
像元数值时间序列数组
,从而检查代码运行结果是否符合我们的要求;此外,由于前面我们对很多变量进行了动态内存分配,因此需要将其
delete
掉;同时,这里还可以对前面我们定义的指向指针的指针赋值为
NULL
,这样子其就不能再指向任何地址了,即彻底将其废除。
for (int i = 0; i < file_size; i++)
{
cout << pixel_paf[0][i] << "," << endl;
}
delete[] pafScanline;
delete[] pixel_paf;
pafScanline = NULL;
pixel_paf = NULL;
return 0;
}
至此,代码的主函数部分结束。
1.6 自定义函数
这一部分是我们的自定义函数
get_need_file()
。
void get_need_file(string path, vector<string>& file, string ext)
{
intptr_t file_handle = 0;
struct _finddata_t file_info;
string temp;
if ((file_handle = _findfirst(temp.assign(path).append("/*" + ext).c_str(), &file_info)) != -1)
{
do
{
file.push_back(temp.assign(path).append("/").append(file_info.name));
} while (_findnext(file_handle, &file_info) == 0);
_findclose(file_handle);
}
}
如前所述,这一部分的具体代码介绍,大家查看文章
C++遴选出特定类型的文件或文件名符合要求的文件
即可,这里就不再赘述。
2 完整代码
本文所需用到的完整代码如下所示。
#include <iostream>
#include <vector>
#include <io.h>
#include "gdal_priv.h"
using namespace std;
void get_need_file(string path, vector<string>& file, string ext);
int main() {
string file_path = R"(E:\02_Project\02_ChlorophyllProduce\01_Data\00_Test)";
vector<string> my_file;
string need_extension = ".bmp";
get_need_file(file_path, my_file, need_extension);
int file_size = my_file.size();
if (file_size == 0)
{
cout << "No file can be found!" << endl;
}
else
{
cout << "Find " << file_size << " file(s).\n" << endl;
}
int nXSize, nYSize;
float** pafScanline = new float* [file_size];
int pic_index = 1;
for (auto x : my_file)
{
GDALDataset* poDataset;
GDALAllRegister();
CPLSetConfigOption("GDAL_FILENAME_IS_UTF8", "NO");
poDataset = (GDALDataset*)GDALOpen(x.c_str(), GA_ReadOnly);
if (poDataset == NULL)
{
cout << "Open File " << x << " Error!" << endl;
}
else
{
cout << "Open File " << x << " Success!" << endl;
}
GDALRasterBand* poBand;
poBand = poDataset->GetRasterBand(1);
nXSize = poBand->GetXSize();
nYSize = poBand->GetYSize();
cout << nXSize << "," << nYSize << "\n" << endl;
pafScanline[pic_index - 1] = new float[nXSize * nYSize];
poBand->RasterIO(GF_Read, 0, 0, nXSize, nYSize, pafScanline[pic_index - 1], nXSize, nYSize, GDT_Float32, 0, 0);
pic_index ++;
}
float** pixel_paf = new float* [nXSize * nYSize];
for (int pixel_num = 0; pixel_num < nXSize * nYSize; pixel_num++)
{
pixel_paf[pixel_num] = new float[file_size];
for (int time_num = 0; time_num < file_size; time_num++)
{
pixel_paf[pixel_num][time_num] = pafScanline[time_num][pixel_num];
}
}
for (int i = 0; i < file_size; i++)
{
cout << pixel_paf[0][i] << "," << endl;
}
delete[] pafScanline;
delete[] pixel_paf;
pafScanline = NULL;
pixel_paf = NULL;
return 0;
}
void get_need_file(string path, vector<string>& file, string ext)
{
intptr_t file_handle = 0;
struct _finddata_t file_info;
string temp;
if ((file_handle = _findfirst(temp.assign(path).append("/*" + ext).c_str(), &file_info)) != -1)
{
do
{
file.push_back(temp.assign(path).append("/").append(file_info.name));
} while (_findnext(file_handle, &file_info) == 0);
_findclose(file_handle);
}
}
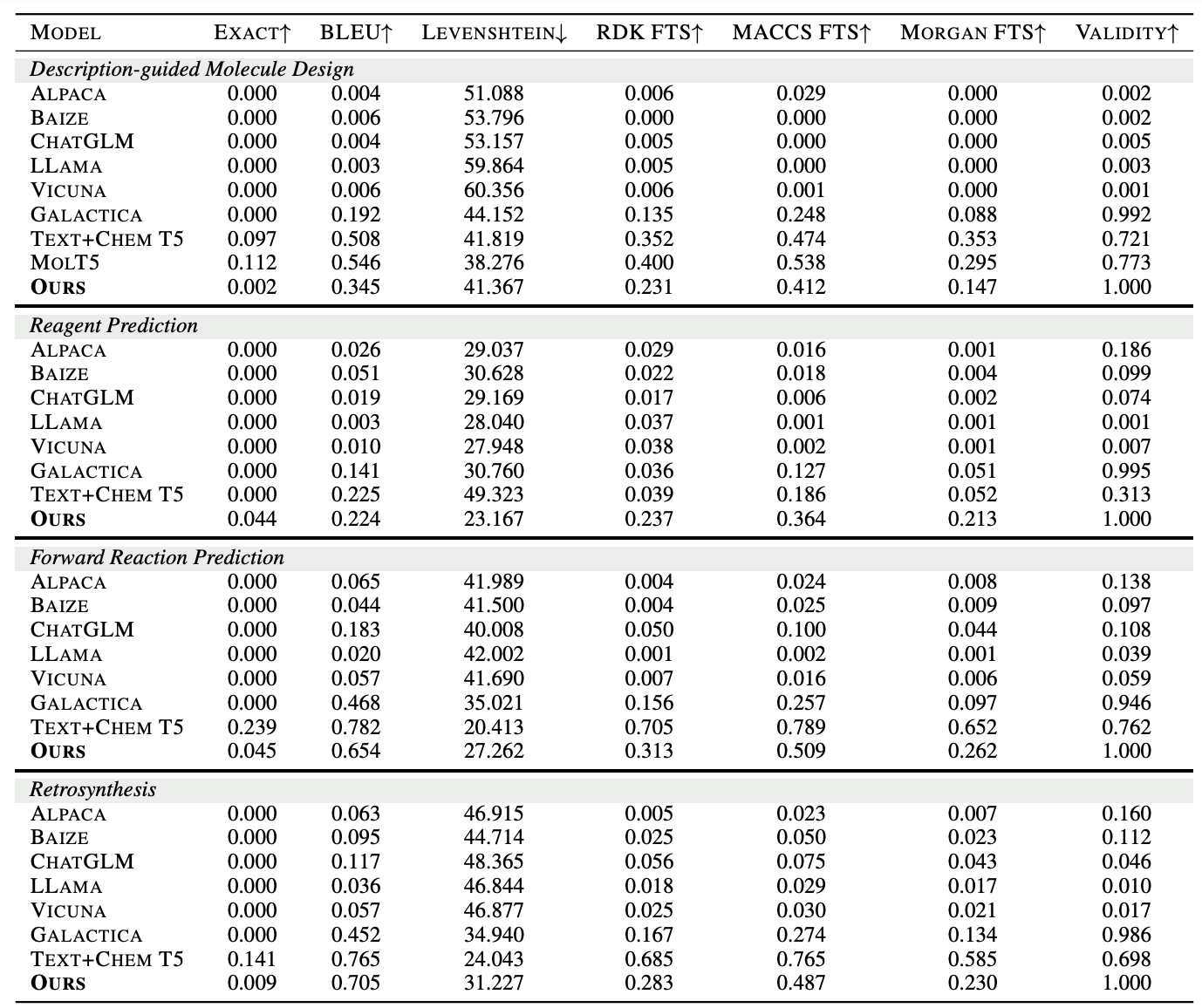
当我们运行上述代码后,将会出现如下所示的界面。

其中,会显示栅格遥感影像文件的筛选情况、具体文件名称及其各自的行号与列号;同时,最后一部分则是本文
1.5
部分提及的测试输出结果,其表示本文所用的
6
景遥感影像各自
(0,0)
位置处的像元数值。
至此,大功告成。
欢迎关注:疯狂学习GIS