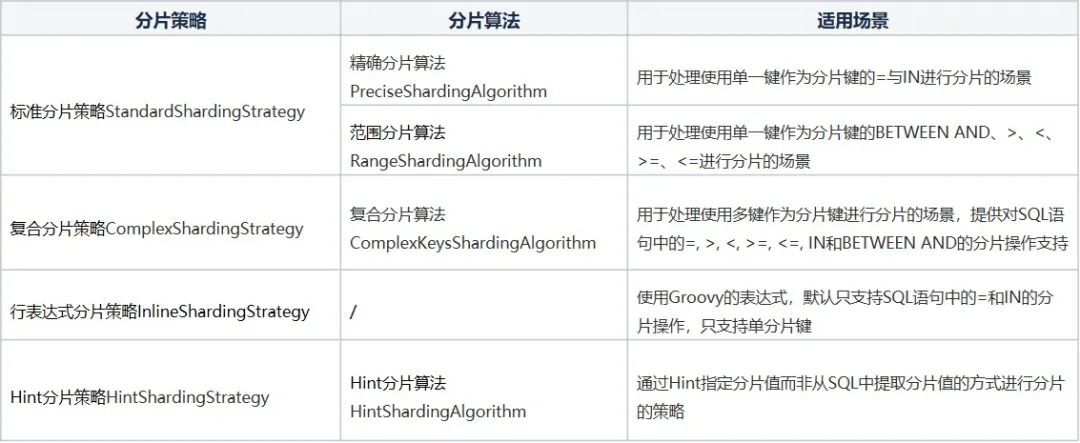
排查 dotNET Core 程序内存暴涨的问题
0. 问题
新版本上线之后,发现内存猛涨,入站流量猛增,不清楚具体原因,部分接口提示 OOM 异常,随后 Pod 直接崩溃无限重启。
1. 准备
Pod 已经接入了 NewRelic 和 Graylog,但是仍然没有办法找到真正的罪魁祸手,此时只能进入 Pod 容器当中抓取内存 Dump 信息。我们容器的基础镜像是基于 Apline-3.18 的,进入容器之后执行了以下命令开始安装相应的工具。
# 我们的镜像是基于 runtime 的,因此需要手动安装一下 SDK,以便后续操作。
# 这里还安装了 bash,后续会使用 bash 进行交互操作,自带的 sh 不好用。
apk add dotnet6-sdk bash
# 安装 Dump 工具
dotnet tool install --global dotnet-dump
因为容器的
ENTRYPOINT
就是直接运行的 dotNET 程序,一般来说其 PID 都是 1,如果你不清楚具体的进程 ID,可以执行
尝试运行
dotnet-dump collect -p 1
收集 Dump 信息,但是得到了以下错误:
/build# dotnet-dump collect -p 1
Writing full to /build/core_20240307_090401
Write dump failed - HRESULT: 0x00000000.
搜索一番之后,得知这是 Pod 没有足够的权限去执行 Dump 操作,因此修改了 Rollouts(或者 Deplotment) 的 YAML 定义,添加对应的
securityContext
应用即可,随后便能够正确地获取 Dump 文件。
securityContext:
capabilities:
add:
- SYS_PTRACE
- SYS_ADMIN
seccompProfile:
type: RuntimeDefault
再次执行
dotnet-dump collect -p 1
获取到了对应的 Dump 文件,将文件拷贝到挂载的 NFS 卷当中,随即下载到本地以便进行调试排查问题。
2. 调查
得到 Dump 文件之后,我们可以使用多种工具来分析 Dump 文件,这里我使用的是
dotnet-dump
命令。因为我是 macOS 的机器,使用
dotnet-dump
我可以直接开始进行分析,你也可以使用 Visual Studio 、dotnetMemory、WinDBG 来打开 Dump 的文件,具体看你的喜好了。
使用
dotnet dump analyze <dump file path>
进入交互式页面:
Loading core dump: D:\dotNET_Dumps\\core_20240307_142201 ...
Ready to process analysis commands. Type 'help' to list available commands or 'help [command]' to get detailed help on a command.
Type 'quit' or 'exit' to exit the session.
首先我们可以看一下目前 GC 堆的信息:
> eeheap -gc
========================================
Number of GC Heaps: 3
----------------------------------------
Heap 0 (00007faa2a73b6b0)
generation 0 starts at 7fa2495932e8
generation 1 starts at 7fa2458279f0
generation 2 starts at 7fa232703000
ephemeral segment allocation context: none
Small object heap
segment begin allocated committed allocated size committed size
7fa232702000 7fa232703000 7fa249be4020 7fa252174000 0x174e1020 (390991904) 0x1fa72000 (531046400)
Large object heap starts at 7fa3b2703000
segment begin allocated committed allocated size committed size
7fa3b2702000 7fa3b2703000 7fa3e3dfc348 7fa3e3dfd000 0x316f9348 (829395784) 0x316fb000 (829403136)
Pinned object heap starts at 7fa6b2703000
segment begin allocated committed allocated size committed size
7fa6b2702000 7fa6b2703000 7fa6b27d4bb8 7fa6b27d5000 0xd1bb8 (859064) 0xd3000 (864256)
------------------------------
Heap 1 (00007faa2a68b6e0)
generation 0 starts at 7fa2c75ae080
generation 1 starts at 7fa2c40eec00
generation 2 starts at 7fa2b2703000
ephemeral segment allocation context: none
Small object heap
segment begin allocated committed allocated size committed size
7fa2b2702000 7fa2b2703000 7fa2c9b1ebb0 7fa2d00b8000 0x1741bbb0 (390183856) 0x1d9b6000 (496721920)
Large object heap starts at 7fa4b2703000
segment begin allocated committed allocated size committed size
7fa4b2702000 7fa4b2703000 7fa4e3f804f0 7fa4e3f81000 0x3187d4f0 (830985456) 0x3187f000 (830992384)
Pinned object heap starts at 7fa7b2703000
segment begin allocated committed allocated size committed size
7fa7b2702000 7fa7b2703000 7fa7b2703018 7fa7b2704000 0x18 (24) 0x2000 (8192)
------------------------------
Heap 2 (00007faa2a5db720)
generation 0 starts at 7fa3466d0298
generation 1 starts at 7fa343173ee0
generation 2 starts at 7fa332703000
ephemeral segment allocation context: none
Small object heap
segment begin allocated committed allocated size committed size
7fa332702000 7fa332703000 7fa348631878 7fa34f736000 0x15f2e878 (368240760) 0x1d034000 (486752256)
Large object heap starts at 7fa5b2703000
segment begin allocated committed allocated size committed size
7fa5b2702000 7fa5b2703000 7fa5e519c3b0 7fa5e519d000 0x32a993b0 (849974192) 0x32a9b000 (849981440)
Pinned object heap starts at 7fa8b2703000
segment begin allocated committed allocated size committed size
7fa8b2702000 7fa8b2703000 7fa8b270c0f0 7fa8b2714000 0x90f0 (37104) 0x12000 (73728)
------------------------------
GC Allocated Heap Size: Size: 0xda315cf0 (3660668144) bytes.
GC Committed Heap Size: Size: 0xeff58000 (4025843712) bytes.
可以看到有 3 个 GC 堆,并且大部分内存占用都在 LOH 上,我们使用
dumpheap -stat -min 85000
搜索一下大小大于 85000 字节的对象有多少?
> dumpheap -stat -min 85000
Statistics:
MT Count TotalSize Class Name
7fa9b9be29c0 1 85,112 Serilog.Events.LogEventPropertyValue[]
7fa9ba87d710 1 117,464 Microsoft.AspNetCore.Routing.Matching.DfaState[]
7fa9b327b110 2 261,648 System.Object[]
7fa9b3348080 2 849,380 System.Int32[]
7fa9bb1e29f8 5 1,441,912 ***.Core.***.*************[]
7fa9b334d2e0 6 1,939,370 System.String
7fa9bb3589a0 1 2,097,176 ***.Core.***.***.***[]
7fa9b5200528 9 2,228,440 ***.Core.***.***[]
7fa9b5206200 20 3,670,496 ***.Core.***.***[]
7fa9bb3625e8 1 4,506,048 System.Collections.Generic.Dictionary<System.String, ***.***.***.***.***>+Entry[]
7fa9b338edd0 20 9,716,748 System.Char[]
7faa2cb14350 76 13,295,160 Free
7fa9b3d60c98 1,100 2,464,160,840 System.Byte[]
Total 1,244 objects, 2,504,369,794 bytes
可以看到这里面有 1100 个对象的大小都超过了 85000 字节,总共加起来快 2.3GB 了,所以问题出在这里。随后使用
dumpheap -type System.Byte[]
查看这些具体的对象列表,以便得到具体对象的地址:
7fa5d5175480 7fa9b3d60c98 18,749,311
7fa5d6356c20 7fa9b3d60c98 6,734,857
7fa5d69c3050 7fa9b3d60c98 878,704
7fa5d6a998e0 7fa9b3d60c98 174,565
7fa5d6ad21c0 7fa9b3d60c98 18,749,311
7fa5d7cb3960 7fa9b3d60c98 6,734,857
7fa5d831fd90 7fa9b3d60c98 10,670,254
7fa5d8d4ce60 7fa9b3d60c98 10,670,254
7fa5d9779f30 7fa9b3d60c98 18,749,311
7fa5da95b6d0 7fa9b3d60c98 18,749,311
7fa5dbb3ce70 7fa9b3d60c98 1,931,776
7fa5dbd6b8e0 7fa9b3d60c98 6,842,488
7fa5dc3f2178 7fa9b3d60c98 7,773,830
7fa5dcb5c020 7fa9b3d60c98 7,773,830
7fa5dd2c5ec8 7fa9b3d60c98 7,773,830
7fa5dda2fd70 7fa9b3d60c98 12,585,235
7fa5de6306a8 7fa9b3d60c98 1,889,260
7fa5de7fdab8 7fa9b3d60c98 1,172,106
7fa5de91bd68 7fa9b3d60c98 134,508
7fa5de94dff8 7fa9b3d60c98 8,857,584
7fa5df1c0808 7fa9b3d60c98 6,842,488
7fa5df8470a0 7fa9b3d60c98 6,842,488
7fa5dfecd938 7fa9b3d60c98 6,842,488
7fa5e05541d0 7fa9b3d60c98 8,857,584
7fa5e0dc69e0 7fa9b3d60c98 7,773,449
7fa5e1530710 7fa9b3d60c98 7,773,449
7fa5e1c9a440 7fa9b3d60c98 980,321
7fa5e1d899c8 7fa9b3d60c98 1,052,316
7fa5e1e8a888 7fa9b3d60c98 1,052,316
7fa5e1f8b748 7fa9b3d60c98 7,373,509
7fa5e2693a30 7fa9b3d60c98 7,373,509
7fa5e2d9bd18 7fa9b3d60c98 2,660,027
7fa5e30253f8 7fa9b3d60c98 2,660,027
7fa5e32aead8 7fa9b3d60c98 2,783,326
7fa5e3556358 7fa9b3d60c98 2,783,326
7fa5e37fdbd8 7fa9b3d60c98 2,783,326
7fa5e3aa5458 7fa9b3d60c98 6,840,270
7fa5e412b448 7fa9b3d60c98 17,239,905
7fa6b27706c8 7fa9b3d60c98 4,120
7fa6b27716e0 7fa9b3d60c98 4,120
7fa6b27726f8 7fa9b3d60c98 4,120
7fa6b2773710 7fa9b3d60c98 4,120
7fa6b2774728 7fa9b3d60c98 4,120
7fa6b2775740 7fa9b3d60c98 4,120
7fa6b2776758 7fa9b3d60c98 4,120
7fa6b2777770 7fa9b3d60c98 4,120
7fa6b2778788 7fa9b3d60c98 4,120
7fa6b27797a0 7fa9b3d60c98 4,120
7fa6b277a7b8 7fa9b3d60c98 4,120
7fa6b277b7d0 7fa9b3d60c98 4,120
7fa6b277c7e8 7fa9b3d60c98 4,120
7fa6b277d800 7fa9b3d60c98 4,120
7fa6b277e818 7fa9b3d60c98 4,120
7fa6b277f830 7fa9b3d60c98 4,120
7fa6b2790860 7fa9b3d60c98 4,120
7fa6b2791878 7fa9b3d60c98 4,120
7fa6b2792890 7fa9b3d60c98 4,120
7fa6b27938a8 7fa9b3d60c98 4,120
7fa6b27948c0 7fa9b3d60c98 4,120
7fa6b27958d8 7fa9b3d60c98 4,120
7fa6b27968f0 7fa9b3d60c98 4,120
7fa6b2797908 7fa9b3d60c98 4,120
7fa6b2798920 7fa9b3d60c98 4,120
7fa6b2799938 7fa9b3d60c98 4,120
7fa6b279a950 7fa9b3d60c98 4,120
7fa6b279b968 7fa9b3d60c98 4,120
7fa6b279c980 7fa9b3d60c98 4,120
7fa6b279d998 7fa9b3d60c98 4,120
7fa6b279e9b0 7fa9b3d60c98 4,120
7fa6b279f9c8 7fa9b3d60c98 4,120
7fa6b27a09e0 7fa9b3d60c98 4,120
7fa6b27a19f8 7fa9b3d60c98 4,120
7fa6b27a2a10 7fa9b3d60c98 4,120
7fa6b27a3a28 7fa9b3d60c98 4,120
7fa6b27a4a40 7fa9b3d60c98 4,120
7fa6b27a5a58 7fa9b3d60c98 4,120
7fa6b27a6a70 7fa9b3d60c98 4,120
7fa6b27a7a88 7fa9b3d60c98 4,120
7fa6b27a8aa0 7fa9b3d60c98 4,120
7fa6b27a9ab8 7fa9b3d60c98 4,120
7fa6b27aaad0 7fa9b3d60c98 4,120
7fa6b27abae8 7fa9b3d60c98 4,120
7fa6b27acb00 7fa9b3d60c98 4,120
7fa6b27adb18 7fa9b3d60c98 4,120
7fa6b27aeb30 7fa9b3d60c98 4,120
7fa6b27afb48 7fa9b3d60c98 4,120
7fa6b27b0b60 7fa9b3d60c98 4,120
7fa6b27b1b78 7fa9b3d60c98 4,120
7fa6b27b2b90 7fa9b3d60c98 4,120
7fa6b27b3ba8 7fa9b3d60c98 4,120
7fa8b2703018 7fa9b3d60c98 4,120
7fa8b2704030 7fa9b3d60c98 4,120
7fa8b2705048 7fa9b3d60c98 4,120
7fa8b2706060 7fa9b3d60c98 4,120
7fa8b2707078 7fa9b3d60c98 4,120
7fa8b2708090 7fa9b3d60c98 4,120
7fa8b27090a8 7fa9b3d60c98 4,120
7fa8b270a0c0 7fa9b3d60c98 4,120
7fa8b270b0d8 7fa9b3d60c98 4,120
Statistics:
MT Count TotalSize Class Name
7fa9b4c13148 1 24 AutoMapper.Configuration.MemberConfigurationExpression<***.Core.***.***, ***.***.***.***.***, System.Byte[]>+<>c__DisplayClass21_0
7fa9b4c13070 1 32 System.Linq.Expressions.Expression1<System.Func<***.***.***.***, System.Byte[]>>
7fa9bb162720 1 32 System.Collections.Generic.List<System.Byte[]>
7fa9b4c12a38 1 48 AutoMapper.Configuration.MemberConfigurationExpression<***.***.***.***, ***.***.***.***.***, System.Byte[]>
7fa9baa24648 1 64 System.Func<Microsoft.Win32.SafeHandles.SafeX509Handle, System.Byte[]>
7fa9b4199a80 1 64 System.Action<AutoMapper.IMemberConfigurationExpression<***.***.***.***, ***.***.***.***.***, System.Byte[]>>
7fa9ba918cf8 1 64 System.Func<System.String, System.Threading.CancellationToken, System.Byte[]>
7fa9bb7434d0 1 64 System.Buffers.SpanAction<System.Char, System.ValueTuple<System.Byte[], System.Int32, System.Int32>>
7fa9ba21c2f8 1 64 System.Func<System.Byte[], System.Security.Cryptography.HashAlgorithm>
7fa9ba3fb308 1 64 System.Action<System.IntPtr, System.Byte[], System.Int32, System.Net.Sockets.SocketError>
7fa9b98b3e90 67 4,288 System.Action<System.Int32, System.Byte[], System.Int32, System.Net.Sockets.SocketFlags, System.Net.Sockets.SocketError>
7fa9b6ad65e8 55 50,376 System.Byte[][]
7fa9b3d60c98 68,716 3,046,115,321 System.Byte[]
Total 68,848 objects, 3,046,170,505 byte
到这一步,你就需要多看看这些对象是什么东西,你可以使用
dumpobj [address]
查看某个对象的具体信息,这里我优先考虑那些比较大的对象,这里我选择了
7fa5d6ad21c0
看看里面有什么东西。
> dumpobj 7fa5d6ad21c0
Name: System.Byte[]
MethodTable: 00007fa9b3d60c98
EEClass: 00007fa9b3d60c28
Tracked Type: false
Size: 18749311(0x11e177f) bytes
Array: Rank 1, Number of elements 18749287, Type Byte
Content: ... ftypisom....isomiso2avc1mp41....free...}mdat..........E....H..,. .#..x264 - core 155 r2917 0a84d98 - H.264/MPEG-4 AVC codec
Fields:
None
从内容可以看到,这似乎是一个视频文件被加载到了一个字节数组,那么我们需要看看谁在持有它,这里我们可以使用
gcroot [address]
来查看它的引用情况。
> gcroot 7fa5d6ad21c0
Caching GC roots, this may take a while.
Subsequent runs of this command will be faster.
Thread da:
7fa21caae740 7fa9ba5849b9 Serilog.Capturing.PropertyValueConverter.TryConvertEnumerable(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
r12:
-> 7fa236bd11a8 System.Collections.Generic.List<***.***.***.CompanyManager>
-> 7fa5b420b040 ***.***.***.CompanyManager[]
-> 7fa236bd1c90 ***.***.***.CompanyManager
-> 7fa33f3b91e0 ***.***.***.CompanyTypeManager
-> 7fa33fa34ee8 System.Collections.Generic.List<***.***.***.ManualManager>
-> 7fa33fa375f0 ***.***.***.ManualManager[]
-> 7fa33fa37058 ***.***.***.ManualManager
-> 7fa5d6ad21c0 System.Byte[]
... Other Information
7fa21caaf680 7fa9b93b3c34 Serilog.Core.Logger.ForContext(System.String, System.Object, Boolean)
r15:
-> 7fa2b6278930 ***.***.***.Services.BaseResponse
-> 7fa2b627dc18 ***.***.***.ServiceLogItemManager
-> 7fa2b627d998 ***.***.***.ServiceLogManager
-> 7fa236bcac90 ***.***.***.UserManager
-> 7fa236bccbb0 ***.***.***.UserGroupManager
-> 7fa236bcd558 ***.***.***.CompanyManager
-> 7fa236bcdfb8 ***.***.***.CompanyTypeManager
-> 7fa236bd11a8 System.Collections.Generic.List<***.***.***.CompanyManager>
-> 7fa5b420b040 ***.***.***.CompanyManager[]
-> 7fa236bd1c90 ***.***.***.CompanyManager
-> 7fa33f3b91e0 ***.***.***.CompanyTypeManager
-> 7fa33fa34ee8 System.Collections.Generic.List<***.***.***.ManualManager>
-> 7fa33fa375f0 ***.***.***.ManualManager[]
-> 7fa33fa37058 ***.***.***.ManualManager
-> 7fa5d6ad21c0 System.Byte[]
7fa21caaf710 7fa9bb62a3a2 ***.***.***.***.SendNewOrderIntegrationBeforeCommit(***.***.***.***, System.Collections.Generic.List`1<***.***.***.***Manager>)
rbp-d0: 00007fa21caaf850
-> 7fa2b6278930 ***.***.***.***.BaseResponse
-> 7fa2b627dc18 ***.***.***.ServiceLogItemManager
-> 7fa2b627d998 ***.***.***.ServiceLogManager
-> 7fa236bcac90 ***.***.***.UserManager
-> 7fa236bccbb0 ***.***.***.UserGroupManager
-> 7fa236bcd558 ***.***.***.CompanyManager
-> 7fa236bcdfb8 ***.***.***.CompanyTypeManager
-> 7fa236bd11a8 System.Collections.Generic.List<***.***.***.CompanyManager>
-> 7fa5b420b040 ***.***.***.CompanyManager[]
-> 7fa236bd1c90 ***.***.***.CompanyManager
-> 7fa33f3b91e0 ***.***.***.CompanyTypeManager
-> 7fa33fa34ee8 System.Collections.Generic.List<***.***.***.ManualManager>
-> 7fa33fa375f0 ***.***.***.ManualManager[]
-> 7fa33fa37058 ***.***.***.ManualManager
-> 7fa5d6ad21c0 System.Byte[]
Found 32 unique roots.
看起来这里的
Byte[]
最后是被某个
BaseResponse
所持有的,并且被
7fa21caaf680 7fa9b93b3c34 Serilog.Core.Logger.ForContext(System.String, System.Object, Boolean)
调用,其实到这一步我也猜到大概是什么原因了,如果想要获取更加详细的信息,可以切换到对应线程执行
clrstack
查看调用堆栈。
这里 Thread Number 是
da
,使用
threads
指令查看所有线程:
> threads
*0 0x0001 (1)
1 0x0007 (7)
2 0x0008 (8)
3 0x0009 (9)
4 0x000A (10)
5 0x000B (11)
6 0x000C (12)
7 0x000D (13)
8 0x000E (14)
9 0x000F (15)
10 0x0010 (16)
11 0x0011 (17)
12 0x0013 (19)
13 0x0017 (23)
14 0x0018 (24)
15 0x0019 (25)
16 0x001B (27)
17 0x001D (29)
18 0x001E (30)
19 0x001F (31)
20 0x0020 (32)
21 0x0024 (36)
22 0x0025 (37)
23 0x0026 (38)
24 0x002A (42)
25 0x004A (74)
26 0x00BB (187)
27 0x00BC (188)
28 0x00BD (189)
29 0x00CE (206)
30 0x00D1 (209)
31 0x00D2 (210)
32 0x00D4 (212)
33 0x00D5 (213)
34 0x00D6 (214)
35 0x00DA (218)
36 0x00DB (219)
发现
0x00DA
对应的是 35 号线程,使用命令
setthread 35
切换到对应线程,执行
clrstack
指令查看调用堆栈。
> setthread 35
> clrstack
OS Thread Id: 0xda (35)
Child SP IP Call Site
00007FA21CAACE00 00007faa2ce99f63 [InlinedCallFrame: 00007fa21caace00] Interop+Sys.ReceiveMessage(System.Runtime.InteropServices.SafeHandle, MessageHeader*, System.Net.Sockets.SocketFlags, Int64*)
00007FA21CAACE00 00007fa9ba5ddc38 [InlinedCallFrame: 00007fa21caace00] Interop+Sys.ReceiveMessage(System.Runtime.InteropServices.SafeHandle, MessageHeader*, System.Net.Sockets.SocketFlags, Int64*)
00007FA21CAACDF0 00007FA9BA5DDC38 ILStubClass.IL_STUB_PInvoke(System.Runtime.InteropServices.SafeHandle, MessageHeader*, System.Net.Sockets.SocketFlags, Int64*)
00007FA21CAACE90 00007FA9BA5DDAE9 System.Net.Sockets.SocketPal.SysReceive(System.Net.Sockets.SafeSocketHandle, System.Net.Sockets.SocketFlags, System.Span`1<Byte>, Byte[], Int32 ByRef, System.Net.Sockets.SocketFlags ByRef, Error ByRef) [/_/src/libraries/System.Net.Sockets/src/System/Net/Sockets/SocketPal.Unix.cs @ 158]
00007FA21CAACF30 00007FA9BA5DD671 System.Net.Sockets.SocketPal.TryCompleteReceiveFrom(System.Net.Sockets.SafeSocketHandle, System.Span`1<Byte>, System.Collections.Generic.IList`1<System.ArraySegment`1<Byte>>, System.Net.Sockets.SocketFlags, Byte[], Int32 ByRef, Int32 ByRef, System.Net.Sockets.SocketFlags ByRef, System.Net.Sockets.SocketError ByRef) [/_/src/libraries/System.Net.Sockets/src/System/Net/Sockets/SocketPal.Unix.cs @ 834]
00007FA21CAACFA0 00007FA9BAD28C59 System.Net.Sockets.SocketAsyncContext.ReceiveFrom(System.Memory`1<Byte>, System.Net.Sockets.SocketFlags ByRef, Byte[], Int32 ByRef, Int32, Int32 ByRef) [/_/src/libraries/System.Net.Sockets/src/System/Net/Sockets/SocketAsyncContext.Unix.cs @ 1540]
00007FA21CAAD030 00007FA9BAD28ABB System.Net.Sockets.SocketPal.Receive(System.Net.Sockets.SafeSocketHandle, Byte[], Int32, Int32, System.Net.Sockets.SocketFlags, Int32 ByRef)
00007FA21CAAD0B0 00007FA9BAD28857 System.Net.Sockets.Socket.Receive(Byte[], Int32, Int32, System.Net.Sockets.SocketFlags, System.Net.Sockets.SocketError ByRef)
00007FA21CAAD130 00007FA9BAD28549 System.Net.Sockets.NetworkStream.Read(Byte[], Int32, Int32) [/_/src/libraries/System.Net.Sockets/src/System/Net/Sockets/NetworkStream.cs @ 231]
00007FA21CAAD180 00007FA9BAD2DD75 System.IO.Stream.Read(System.Span`1<Byte>) [/_/src/libraries/System.Private.CoreLib/src/System/IO/Stream.cs @ 667]
00007FA21CAAD1D0 00007FA9BA5DC52B System.Net.Sockets.NetworkStream.Read(System.Span`1<Byte>) [/_/src/libraries/System.Net.Sockets/src/System/Net/Sockets/NetworkStream.cs @ 246]
00007FA21CAAD220 00007FA9BAD2DB78 Microsoft.Data.SqlClient.SNI.SslOverTdsStream.Read(System.Span`1<Byte>) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/SNI/SslOverTdsStream.NetCoreApp.cs @ 32]
00007FA21CAAD290 00007FA9BAD39691 System.Net.Security.SslStream+<EnsureFullTlsFrameAsync>d__186`1[[System.Net.Security.SyncReadWriteAdapter, System.Net.Security]].MoveNext()
00007FA21CAAD310 00007FA9BAD39477 System.Runtime.CompilerServices.AsyncMethodBuilderCore.Start[[System.Net.Security.SslStream+<EnsureFullTlsFrameAsync>d__186`1[[System.Net.Security.SyncReadWriteAdapter, System.Net.Security]], System.Net.Security]](<EnsureFullTlsFrameAsync>d__186`1<System.Net.Security.SyncReadWriteAdapter> ByRef) [/_/src/libraries/System.Private.CoreLib/src/System/Runtime/CompilerServices/AsyncMethodBuilderCore.cs @ 38]
00007FA21CAAD350 00007FA9BAD393D7 System.Net.Security.SslStream.EnsureFullTlsFrameAsync[[System.Net.Security.SyncReadWriteAdapter, System.Net.Security]](System.Net.Security.SyncReadWriteAdapter)
00007FA21CAAD3C0 00007FA9BAD38A39 System.Net.Security.SslStream+<ReadAsyncInternal>d__188`1[[System.Net.Security.SyncReadWriteAdapter, System.Net.Security]].MoveNext() [/_/src/libraries/System.Net.Security/src/System/Net/Security/SslStream.Implementation.cs @ 963]
00007FA21CAAD520 00007FA9BAD385D7 System.Runtime.CompilerServices.AsyncMethodBuilderCore.Start[[System.Net.Security.SslStream+<ReadAsyncInternal>d__188`1[[System.Net.Security.SyncReadWriteAdapter, System.Net.Security]], System.Net.Security]](<ReadAsyncInternal>d__188`1<System.Net.Security.SyncReadWriteAdapter> ByRef) [/_/src/libraries/System.Private.CoreLib/src/System/Runtime/CompilerServices/AsyncMethodBuilderCore.cs @ 38]
00007FA21CAAD560 00007FA9BAD3847B System.Net.Security.SslStream.Read(Byte[], Int32, Int32) [/_/src/libraries/System.Net.Security/src/System/Net/Security/SslStream.cs @ 767]
00007FA21CAAD620 00007FA9BAD27C43 Microsoft.Data.SqlClient.SNI.SNITCPHandle.Receive(Microsoft.Data.SqlClient.SNI.SNIPacket ByRef, Int32) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/SNI/SNITcpHandle.cs @ 799]
00007FA21CAAD780 00007FA9BAD279FA Microsoft.Data.SqlClient.SNI.TdsParserStateObjectManaged.ReadSyncOverAsync(Int32, UInt32 ByRef) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParserStateObjectManaged.cs @ 219]
00007FA21CAAD7D0 00007FA9BAD276EF Microsoft.Data.SqlClient.TdsParserStateObject.ReadSniSyncOverAsync() [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParserStateObject.cs @ 1223]
00007FA21CAAD820 00007FA9BAD2760C Microsoft.Data.SqlClient.TdsParserStateObject.TryReadNetworkPacket() [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParserStateObject.cs @ 1181]
00007FA21CAAD840 00007FA9BAD37E54 Microsoft.Data.SqlClient.TdsParserStateObject.TryPrepareBuffer() [/_/src/Microsoft.Data.SqlClient/src/Microsoft/Data/SqlClient/TdsParserStateObject.cs @ 901]
00007FA21CAAD860 00007FA9BAD3C748 Microsoft.Data.SqlClient.TdsParserStateObject.TryReadUInt32(UInt32 ByRef) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParserStateObject.cs @ 632]
00007FA21CAAD890 00007FA9BAD7C73C Microsoft.Data.SqlClient.TdsParserStateObject.TryReadPlpLength(Boolean, UInt64 ByRef) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParserStateObject.cs @ 908]
00007FA21CAAD8D0 00007FA9BAD7CA11 Microsoft.Data.SqlClient.TdsParserStateObject.TryReadPlpBytes(Byte[] ByRef, Int32, Int32, Int32 ByRef) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParserStateObject.cs @ 1054]
00007FA21CAAD930 00007FA9BAD6D9A8 Microsoft.Data.SqlClient.TdsParser.TryReadSqlValue(Microsoft.Data.SqlClient.SqlBuffer, Microsoft.Data.SqlClient.SqlMetaDataPriv, Int32, Microsoft.Data.SqlClient.TdsParserStateObject, Microsoft.Data.SqlClient.SqlCommandColumnEncryptionSetting, System.String, Microsoft.Data.SqlClient.SqlCommand) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/TdsParser.cs @ 6054]
00007FA21CAAD9B0 00007FA9BAD6CF76 Microsoft.Data.SqlClient.SqlDataReader.TryReadColumnInternal(Int32, Boolean, Boolean) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/SqlDataReader.cs @ 3915]
00007FA21CAADA40 00007FA9BAD6C92A Microsoft.Data.SqlClient.SqlDataReader.GetValueInternal(Int32) [/_/src/Microsoft.Data.SqlClient/netcore/src/Microsoft/Data/SqlClient/SqlDataReader.cs @ 2719]
00007FA21CAADA60 00007FA9BAD6C864 Microsoft.Data.SqlClient.SqlDataReader.GetValue(Int32)
00007FA21CAADAA0 00007FA9BAD6C26A ***.DataAccess.NeoBaseDAL`1[[System.__Canon, System.Private.CoreLib]].LoadObject(System.Data.IDataReader)
00007FA21CAADBE0 00007FA9BAD7E4C9 ***.DataAccess.NeoBaseDAL`1[[System.__Canon, System.Private.CoreLib]].LoadObjects(Microsoft.Data.SqlClient.SqlDataReader)
00007FA21CAADC20 00007FA9BAD7D6BB ***.DataAccess.NeoBaseDAL`1[[System.__Canon, System.Private.CoreLib]].GetData(System.__Canon, ***.Domain.FiltroPaginador)
00007FA21CAADCC0 00007FA9BAD7D12E ***.Domain.NeoBaseManager`1[[System.__Canon, System.Private.CoreLib]].GetData(System.__Canon)
00007FA21CAADD10 00007FA9BB66EAFD ***.***.***.***.get_ListManual()
00007FA21CAADFC0 00007faa2c663c13 [DebuggerU2MCatchHandlerFrame: 00007fa21caadfc0]
00007FA21CAAE0C8 00007faa2c663c13 [HelperMethodFrame_PROTECTOBJ: 00007fa21caae0c8] System.RuntimeMethodHandle.InvokeMethod(System.Object, System.Span`1<System.Object> ByRef, System.Signature, Boolean, Boolean)
00007FA21CAAE240 00007FA9B49E9B3C System.Reflection.RuntimeMethodInfo.Invoke(System.Object, System.Reflection.BindingFlags, System.Reflection.Binder, System.Object[], System.Globalization.CultureInfo) [/_/src/coreclr/System.Private.CoreLib/src/System/Reflection/RuntimeMethodInfo.cs @ 435]
00007FA21CAAE2C0 00007FA9BB644BB8 Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAE340 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAE3A0 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAE410 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAE460 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAE4D0 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAE550 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAE5B0 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAE620 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAE670 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAE6E0 00007FA9BB66EA50 Serilog.Capturing.PropertyValueConverter+DepthLimiter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring)
00007FA21CAAE740 00007FA9BA5849B9 Serilog.Capturing.PropertyValueConverter.TryConvertEnumerable(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAE7A0 00007FA9B93B403D Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAE810 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAE890 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAE8F0 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAE960 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAE9B0 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAEA20 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAEAA0 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAEB00 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAEB70 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAEBC0 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAEC30 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAECB0 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAED10 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAED80 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAEDD0 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAEE40 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAEEC0 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAEF20 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAEF90 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAEFE0 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAF050 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAF0D0 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAF130 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAF1A0 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAF1F0 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAF260 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAF2E0 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAF340 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAF3B0 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAF400 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAF470 00007FA9BB644CCD Serilog.Capturing.PropertyValueConverter+<GetProperties>d__22.MoveNext()
00007FA21CAAF4F0 00007FA9B49A7C29 System.Collections.Generic.LargeArrayBuilder`1[[System.__Canon, System.Private.CoreLib]].AddRange(System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/LargeArrayBuilder.SpeedOpt.cs @ 116]
00007FA21CAAF550 00007FA9B40C0EA5 System.Collections.Generic.EnumerableHelpers.ToArray[[System.__Canon, System.Private.CoreLib]](System.Collections.Generic.IEnumerable`1<System.__Canon>) [/_/src/libraries/Common/src/System/Collections/Generic/EnumerableHelpers.Linq.cs @ 85]
00007FA21CAAF5C0 00007FA9BA584DD7 Serilog.Capturing.PropertyValueConverter.TryConvertCompilerGeneratedType(System.Object, System.Type, Serilog.Parsing.Destructuring, Serilog.Events.LogEventPropertyValue ByRef)
00007FA21CAAF610 00007FA9B93B4090 Serilog.Capturing.PropertyValueConverter.CreatePropertyValue(System.Object, Serilog.Parsing.Destructuring, Int32)
00007FA21CAAF680 00007FA9B93B3C34 Serilog.Core.Logger.ForContext(System.String, System.Object, Boolean)
00007FA21CAAF710 00007FA9BB62A3A2 ***.***.***.***.SendNewOrderIntegrationBeforeCommit(***.***.***.***, System.Collections.Generic.List`1<***.***.***.***>)
00007FA21CAAF930 00007FA9BB60EDAD ***.***.***.***.GenerateOrder(***.***.***.***, Boolean)
00007FA21CAAFD90 00007FA9BB60910F ***.***.***.***.GenerateOrderManuallyWithSelectedItems(***.***.***.***, ***.***.***.***)
00007FA21CAAFE20 00007FA9BB608F44 ***.***.***.***.GenerateOrder(***.***.***.***, Int64)
00007FA21CAAFE60 00007FA9BB605B29 ***.***.***.Controllers.OrderController.GenerateOrder(***.***.***.***.*********)
... 省略
00007FA21CAB11F0 00007FA9BA585082 NewRelic.Providers.Wrapper.AspNetCore.WrapPipelineMiddleware.Invoke(Microsoft.AspNetCore.Http.HttpContext)
00007FA21CAB1240 00007FA9BA56EDB1 Microsoft.AspNetCore.Server.Kestrel.Core.Internal.Http.HttpProtocol+<ProcessRequests>d__226`1[[System.__Canon, System.Private.CoreLib]].MoveNext()
00007FA21CAB13E0 00007FA9B70753AD System.Threading.ExecutionContext.RunFromThreadPoolDispatchLoop(System.Threading.Thread, System.Threading.ExecutionContext, System.Threading.ContextCallback, System.Object) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/ExecutionContext.cs @ 268]
00007FA21CAB1420 00007FA9BADE97EA System.Runtime.CompilerServices.AsyncTaskMethodBuilder`1+AsyncStateMachineBox`1[[System.Threading.Tasks.VoidTaskResult, System.Private.CoreLib],[Microsoft.AspNetCore.Server.Kestrel.Core.Internal.Http.HttpProtocol+<ProcessRequests>d__226`1[[System.__Canon, System.Private.CoreLib]], Microsoft.AspNetCore.Server.Kestrel.Core]].MoveNext(System.Threading.Thread) [/_/src/libraries/System.Private.CoreLib/src/System/Runtime/CompilerServices/AsyncTaskMethodBuilderT.cs @ 332]
00007FA21CAB1470 00007FA9B6FD2073 System.Threading.ThreadPoolWorkQueue.Dispatch() [/_/src/libraries/System.Private.CoreLib/src/System/Threading/ThreadPoolWorkQueue.cs @ 724]
00007FA21CAB14E0 00007FA9B6FD0230 System.Threading.PortableThreadPool+WorkerThread.WorkerThreadStart() [/_/src/libraries/System.Private.CoreLib/src/System/Threading/PortableThreadPool.WorkerThread.cs @ 107]
00007FA21CAB16F0 00007faa2c663c13 [DebuggerU2MCatchHandlerFrame: 00007fa21cab16f0]
找到对应方法
SendNewOrderIntegrationBeforeCommit
里面调用
Serilog.Core.Logger.ForContext
的地方,发现了以下代码:
result objBaseResponse = ***.***(***, ***.IdOrder);
Log..ForContext("{@Result}", objBaseResponse, true)
.Information("SendNewOrderIntegration end");
3. 结论
调查 objBaseResponse 得知,里面手搓了类似于导航属性的玩意儿,而且还有循环依赖,这样一旦走到这个打日志的地方,就会遍历对象的属性,与此同时还会触发从数据库获取数据的操作,也就是会导致入站流量飙升。
Create a logger that enriches log events with the specified property.
Params:
propertyName – The name of the property. Must be non-empty.
value – The property value.
destructureObjects – If true, the value will be serialized as a structured object if possible; if false, the object will be recorded as a scalar or simple array.
本来不指定
true
值可能都不会有问题,一旦指定了
true
值,序列化对象的时候就会完全遍历里面的子对象。