Sharding-JDBC源码解析与vivo的定制开发
作者:vivo IT 平台团队 - Xiong Huanxin
Sharding-JDBC是在JDBC层提供服务的数据库中间件,在分库分表场景具有广泛应用。本文对Sharding-JDBC的解析、路由、改写、执行、归并五大核心引擎进行了源码解析,并结合业务实践经验,总结了使用Sharding-JDBC的一些痛点问题并分享了对应的定制开发与改造方案。
本文源码基于Sharding-JDBC 4.1.1版本。
一、业务背景
随着业务并发请求和数据规模的不断扩大,单节点库表压力往往会成为系统的性能瓶颈。公司IT内部
营销库存、交易订单、财经台账、考勤记录
等多领域的业务场景的日增数据量巨大,存在着
数据库节点压力过大、连接过多、查询速度变慢
等情况,根据数据来源、时间、工号等信息来将
没有联系的数据
尽量均分到不同的库表中,从而在不影响业务需求的前提下,减轻数据库节点压力,提升查询效率和系统稳定性

二、技术选型
我们对比了几款比较常见的支持分库分表和读写分离的中间件。
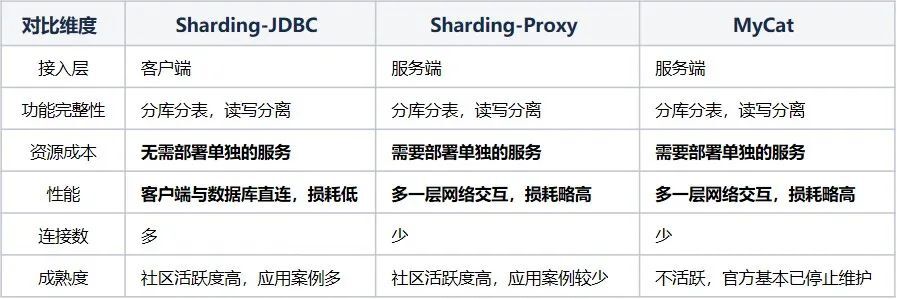
Sharding-JDBC作为轻量化的增强版的JDBC框架,相较其他中间件性能更好,接入难度更低,其数据分片、读写分离功能也覆盖了我们的业务诉求,因此我们在业务中广泛使用了Sharding-JDBC。但在使用Sharding-JDBC的过程中,我们也发现了诸多问题,为了业务更便捷的使用Sharding-JDBC,我们对源码做了针对性的定制开发和组件封装来满足业务需求。
三、源码解析
3.1 引言
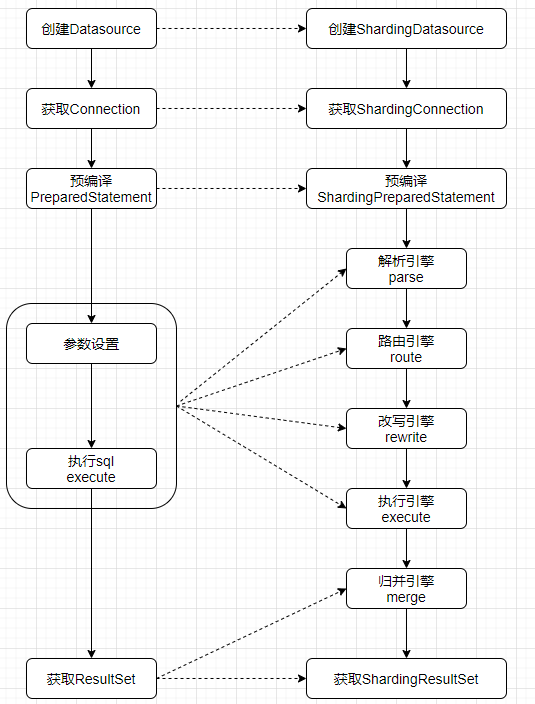
Sharding-JDBC作为基于JDBC的数据库中间件,实现了JDBC的标准api,Sharding-JDBC与原生JDBC的执行对比流程如下图所示:
相关执行流程的代码样例如下:
JDBC执行样例
//获取数据库连接
try (Connection conn = DriverManager.getConnection("mysqlUrl", "userName", "password")) {
String sql = "SELECT * FROM t_user WHERE name = ?";
//预编译SQL
try (PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
//参数设置与执行
preparedStatement.setString(1, "vivo");
preparedStatement.execute(sql);
//获取结果集
try (ResultSet resultSet = preparedStatement.getResultSet()) {
while (resultSet.next()) {
//处理结果
}
}
}
}Sharding-JDBC 源码
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement#execute
public boolean execute() throws SQLException {
try {从对比的执行流程图可见:
【JDBC】:执行的主要流程是通过Datasource获取Connection,再注入SQL语句生成PreparedStatement对象,PreparedStatement设置占位符参数执行后得到结果集ResultSet。
【Sharding-JDBC】:主要流程基本一致,但Sharding基于PreparedStatement进行了实现与扩展,具体实现类
ShardingPreparedStatement中会抽象出解析、路由、重写、归并等引擎,从而实现分库分表、读写分离
等能力,每个引擎的作用说明如下表所示:
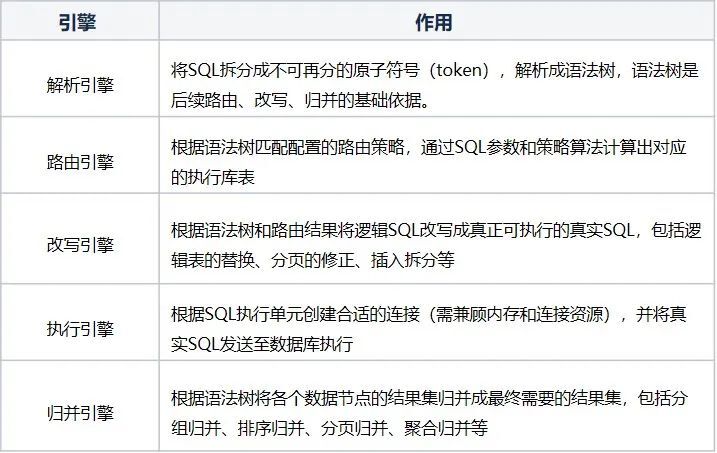
//*相关引擎的源码解析在下文会作更深入的阐述
3.2 解析引擎
3.2.1 引擎解析
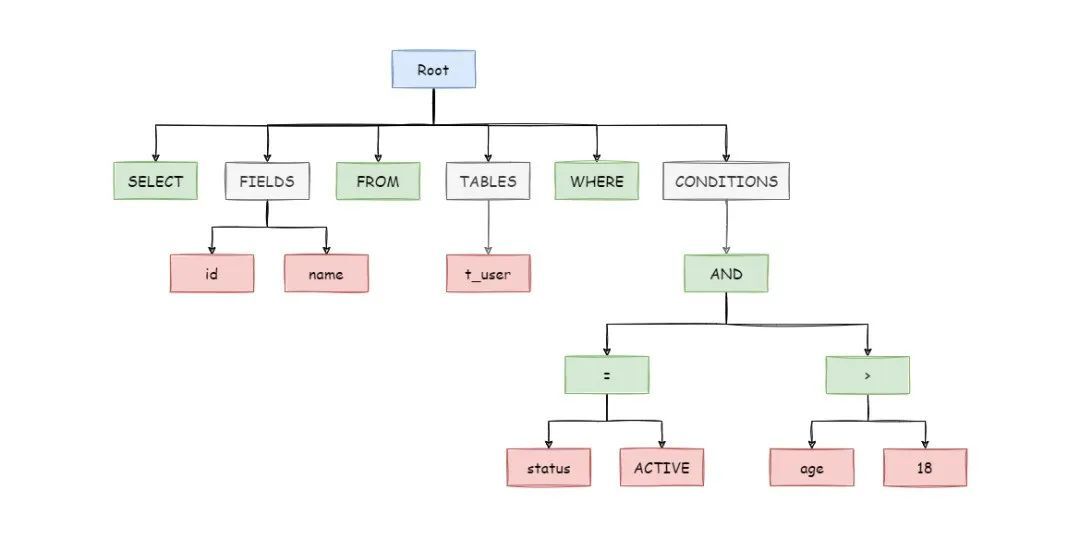
解析引擎是Sharding-JDBC进行分库分表逻辑的基础,其作用是将SQL拆解为不可再分的原子符号(称为token),再根据数据库类型将这些token分类成关键字、表达式、操作符、字面量等不同类型,进而生成抽象语法树,而语法树是后续进行路由、改写操作的前提(这也正是语法树的存在使得Sharding-JDBC存在各式各样的语法限制的原因之一)。
▲图片来源:
ShardingSphere 官方文档
4.x的版本采用ANTLR(ANother Tool for Language Recognition)作为解析引擎,在ShardingSphere-sql-parser-dialect模块中定义了适用于不同数据库语法的解析规则(.g4文件),idea中也可以下载ANTLR v4的插件,输入SQL查看解析后的语法树结果。
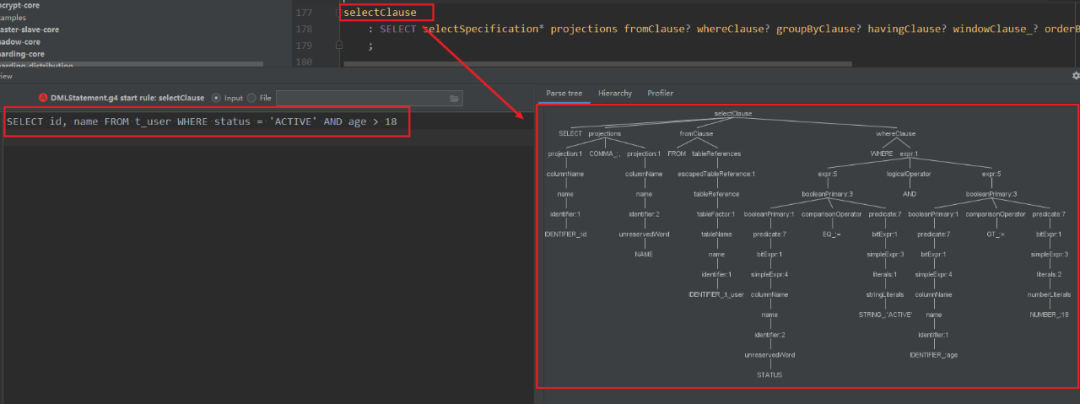
解析方法的入口在DataNodeRouter的createRouteContext方法中,解析引擎根据数据库类型和SQL创建SQLParserExecutor执行得到解析树,再通过ParseTreeVisitor()的visit方法,对解析树进行处理得到SQLStatement。ANTLR支持listener和visitor两种模式的接口,visitor方式可以更灵活的控制解析树的遍历过程,更适用于SQL解析的场景。
解析引擎核心代码
org.apache.shardingsphere.underlying.route.DataNodeRouter#createRouteContext#96
private RouteContext createRouteContext(final String sql, final List<Object> parameters, final boolean useCache) {
//解析引擎解析SQL
SQLStatement sqlStatement = parserEngine.parse(sql, useCache);
try {
SQLStatementContext sqlStatementContext = SQLStatementContextFactory.newInstance(metaData.getSchema(), sql, parameters, sqlStatement);
return new RouteContext(sqlStatementContext, parameters, new RouteResult());
// TODO should pass parameters for master-slave
} catch (final IndexOutOfBoundsException ex) {
return new RouteContext(new CommonSQLStatementContext(sqlStatement), parameters, new RouteResult());
}
}
org.apache.shardingsphere.sql.parser.SQLParserEngine#parse0#72
private SQLStatement parse0(final String sql, final boolean useCache) {
//缓存
if (useCache) {
Optional<SQLStatement> cachedSQLStatement = cache.getSQLStatement(sql);
if (cachedSQLStatement.isPresent()) {
return cachedSQLStatement.get();
}
}
//根据数据库类型和sql生成解析树
ParseTree parseTree = new SQLParserExecutor(databaseTypeName, sql).execute().getRootNode();
//ParseTreeVisitor的visit方法对解析树进行处理得到SQLStatement
SQLStatement result = (SQLStatement) ParseTreeVisitorFactory.newInstance(databaseTypeName, VisitorRule.valueOf(parseTree.getClass())).visit(parseTree);
if (useCache) {
cache.put(sql, result);
}
return result;
}SQLStatement实际上是一个接口,其实现对应着不同的SQL类型,如SelectStatement 类中就包括查询的字段、表名、where条件、分组、排序、分页、lock等变量,可以看到这里并没有对having这种字段做定义,相当于Sharding-JDBC无法识别到SQL中的having,这使得Sharding-JDBC对having语法有一定的限制。
SelectStatement
public final class SelectStatement extends DMLStatement {
// 字段
private ProjectionsSegment projections;
// 表
private final Collection<TableReferenceSegment> tableReferences = new LinkedList<>();
// where
private WhereSegment where;
// groupBy
private GroupBySegment groupBy;
// orderBy
private OrderBySegment orderBy;
// limit
private LimitSegment limit;
// 父statement
private SelectStatement parentStatement;
// lock
private LockSegment lock;
}SQLStatement还会被进一步转换成SQLStatementContext,如SelectStatement 会被转换成SelectStatementContext ,其结构与SelectStatement 类似不再多说,值得注意的是虽然这里定义了containsSubquery来判断是否包含子查询,但4.1.1源码永远是返回的false,与having类似,这意味着Sharding-JDBC不会对子查询语句做特殊处理。
SelectStatementContext
public final class SelectStatementContext extends CommonSQLStatementContext<SelectStatement> implements TableAvailable, WhereAvailable {
private final TablesContext tablesContext;
private final ProjectionsContext projectionsContext;
private final GroupByContext groupByContext;
private final OrderByContext orderByContext;
private final PaginationContext paginationContext;
private final boolean containsSubquery;
}
private boolean containsSubquery() {
// FIXME process subquery
// Collection<SubqueryPredicateSegment> subqueryPredicateSegments = getSqlStatement().findSQLSegments(SubqueryPredicateSegment.class);
// for (SubqueryPredicateSegment each : subqueryPredicateSegments) {
// if (!each.getAndPredicates().isEmpty()) {
// return true;
// }
// }
return false;
}3.2.2 引擎总结
解析引擎是进行路由改写的前提基础,其作用就是将SQL按照定义的语法规则拆分成原子符号(token),生成语法树,根据不同的SQL类型生成对应的SQLStatement,SQLStatement由各自的Segment组成,所有的Segment都包含startIndex和endIndex来定位token在SQL中所属的位置,但解析语法难以涵盖所有的SQL场景,使得部分SQL无法按照预期的结果路由执行。
3.3 路由引擎
3.3.1 引擎解析
路由引擎是Sharding-JDBC的核心步骤,作用是根据定义的分库分表规则将解析引擎生成的SQL上下文生成对应的路由结果,RouteResult 包括DataNode和RouteUnit,DataNode是实际的数据源节点,包括数据源名称和实际的物理表名,RouteUnit则记录了逻辑表/库与物理表/库的映射关系,后面的改写引擎也是根据这个映射关系来决定如何替换SQL中的逻辑表(
实际上RouteResult 就是维护了一条SQL需要往哪些库哪些表执行的关系
)。
RouteResult
public final class RouteResult {
private final Collection<Collection<DataNode>> originalDataNodes = new LinkedList<>();
private final Collection<RouteUnit> routeUnits = new LinkedHashSet<>();
}
public final class DataNode {
private static final String DELIMITER = ".";
private final String dataSourceName;
private final String tableName;
}
public final class RouteUnit {
private final RouteMapper dataSourceMapper;
private final Collection<RouteMapper> tableMappers;
}
public final class RouteMapper {
private final String logicName;
private final String actualName;
}其中,路由有分为
分片路由
和
主从路由
,两者可以单独使用,也可以组合使用。
分片路由
ShardingRouteDecorator的decorate方法是路由引擎的核心逻辑,经过SQL校验->生成分片条件->合并分片值后得到路由结果。
分片路由decorate方法
org.apache.shardingsphere.sharding.route.engine.ShardingRouteDecorator#decorate#57
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final ShardingRule shardingRule, final ConfigurationProperties properties) {
SQLStatementContext sqlStatementContext = routeContext.getSqlStatementContext();
List<Object> parameters = routeContext.getParameters();
//SQL校验 校验INSERT INTO .... ON DUPLICATE KEY UPDATE 和UPDATE语句中是否存在分片键
ShardingStatementValidatorFactory.newInstance(
sqlStatementContext.getSqlStatement()).ifPresent(validator -> validator.validate(shardingRule, sqlStatementContext.getSqlStatement(), parameters));
//生成分片条件
ShardingConditions shardingConditions = getShardingConditions(parameters, sqlStatementContext, metaData.getSchema(), shardingRule);
//合并分片值
boolean needMergeShardingValues = isNeedMergeShardingValues(sqlStatementContext, shardingRule);
if (sqlStatementContext.getSqlStatement() instanceof DMLStatement && needMergeShardingValues) {
checkSubqueryShardingValues(sqlStatementContext, shardingRule, shardingConditions);
mergeShardingConditions(shardingConditions);
}
ShardingRouteEngine shardingRouteEngine = ShardingRouteEngineFactory.newInstance(shardingRule, metaData, sqlStatementContext, shardingConditions, properties);
//得到路由结果
RouteResult routeResult = shardingRouteEngine.route(shardingRule);
if (needMergeShardingValues) {
Preconditions.checkState(1 == routeResult.getRouteUnits().size(), "Must have one sharding with subquery.");
}
return new RouteContext(sqlStatementContext, parameters, routeResult);
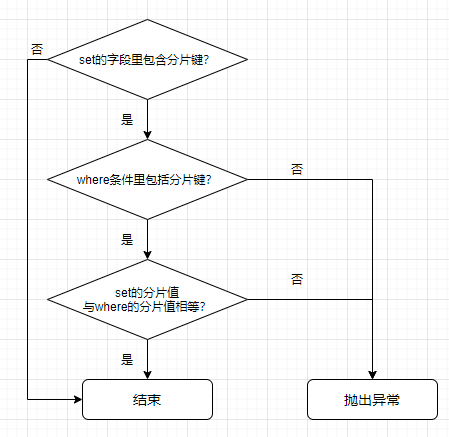
}ShardingStatementValidator有ShardingInsertStatementValidator和ShardingUpdateStatementValidator两种实现,INSERT INTO .... ON DUPLICATE KEY UPDATE和UPDATE语法都会涉及到字段值的更新,Sharding-JDBC是不允许更新分片值的,毕竟修改分片值还需要将数据迁移至新分片值对应的库表中,才能保证数据分片规则一致。两者的校验细节也有所不同:
INSERT INTO .... ON DUPLICATE KEY UPDATE仅仅是对UPDATE字段的校验, ON DUPLICATE KEY UPDATE中包含分片键就会报错;
而UPDATE语句则会额外校验WHERE条件中分片键的原始值和SET的值是否一样,不一样则会抛出异常。
ShardingCondition中只有一个变量routeValues,RouteValue是一个接口,有ListRouteValue和RangeRouteValue两种实现,前者记录了分片键的in或=条件的分片值,后者则记录了范围查询的分片值,两者被封装为ShardingValue对象后,将会透传至分片算法中计算得到分片结果集。
ShardingCondition
public final class ShardingConditions {
private final List<ShardingCondition> conditions;
}
public class ShardingCondition {
private final List<RouteValue> routeValues = new LinkedList<>();
}
public final class ListRouteValue<T extends Comparable<?>> implements RouteValue {
private final String columnName;
private final String tableName;
//in或=条件对应的值
private final Collection<T> values;
@Override
public String toString() {
return tableName + "." + columnName + (1 == values.size() ? " = " + new ArrayList<>(values).get(0) : " in (" + Joiner.on(",").join(values) + ")");
}
}
public final class RangeRouteValue<T extends Comparable<?>> implements RouteValue {
private final String columnName;
private final String tableName;
//between and 大于小于等范围值的上下限
private final Range<T> valueRange;
}生成分片条件后还会合并分片条件,但是前文提过在SelectStatementContext中的containsSubquery永远是false,所以这段逻辑永远返回false,即不会合并分片条件。
判断是否需要合并分片条件
org.apache.shardingsphere.sharding.route.engine.ShardingRouteDecorator#isNeedMergeShardingValues#87
private boolean isNeedMergeShardingValues(final SQLStatementContext sqlStatementContext, final ShardingRule shardingRule) {
return sqlStatementContext instanceof SelectStatementContext && ((SelectStatementContext) sqlStatementContext).isContainsSubquery()
&& !shardingRule.getShardingLogicTableNames(sqlStatementContext.getTablesContext().getTableNames()).isEmpty();
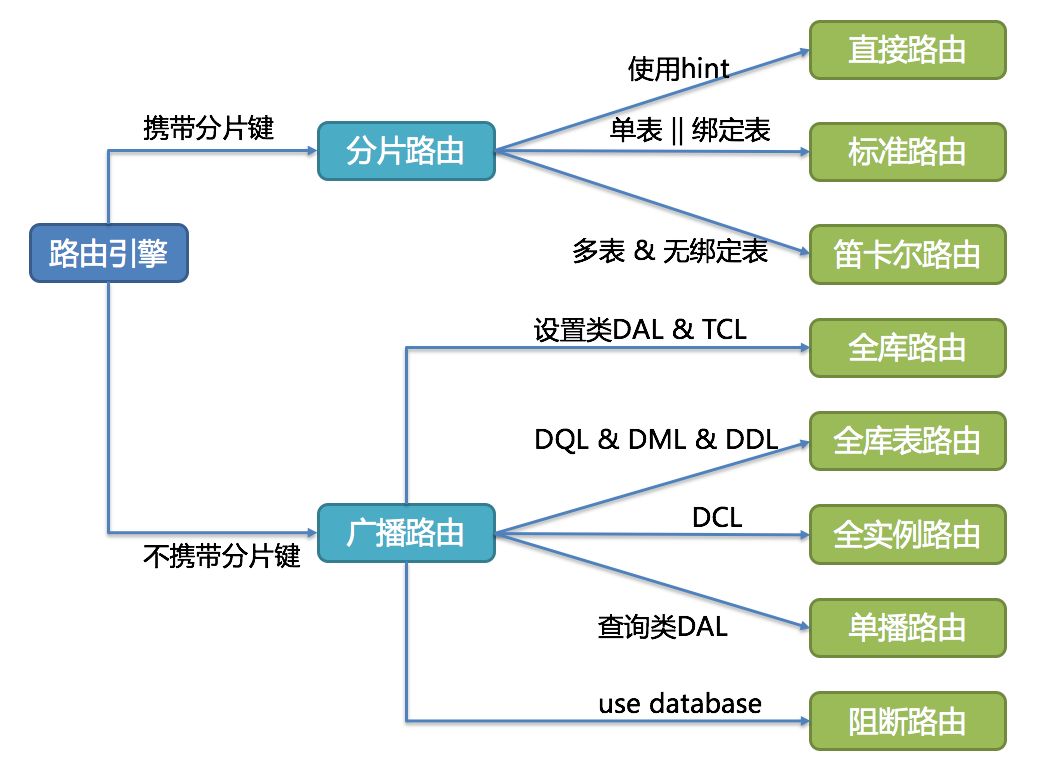
}然后就是通过分片路由引擎调用分片算法计算路由结果了,ShardingRouteEngine实现较多,介绍起来篇幅较多,这里就不展开说明了,可以
参考官方文档来了解路由引擎的选择规则
。
▲图片来源:
ShardingSphere 官方文档
Sharding-JDBC定义了多种分片策略和算法接口,主要的分配策略与算法说明如下表所示:
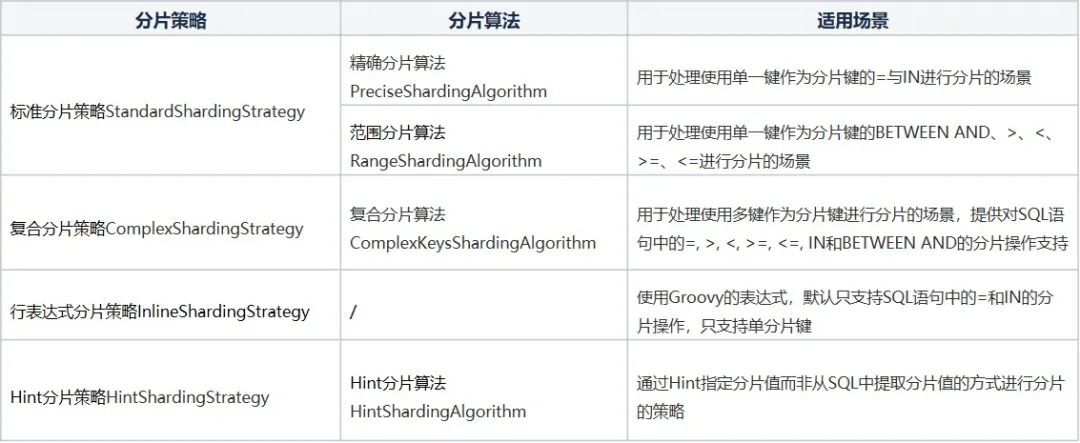
补充两个细节:
(1)当ALLOW_RANGE_QUERY_WITH_INLINE_SHARDING配置设置true时,InlineShardingStrategy支持范围查询,但是并不是根据分片值计算范围,而是
直接全路由至配置的数据节点,会存在性能隐患。
InlineShardingStrategy.doSharding
org.apache.shardingsphere.core.strategy.route.inline.InlineShardingStrategy#doSharding
public Collection<String> doSharding(final Collection<String> availableTargetNames, final Collection<RouteValue> shardingValues, final ConfigurationProperties properties) {
RouteValue shardingValue = shardingValues.iterator().next();
//ALLOW_RANGE_QUERY_WITH_INLINE_SHARDING设置为true,直接返回availableTargetNames,而不是根据RangeRouteValue计算
if (properties.<Boolean>getValue(ConfigurationPropertyKey.ALLOW_RANGE_QUERY_WITH_INLINE_SHARDING) && shardingValue instanceof RangeRouteValue) {
return availableTargetNames;
}
Preconditions.checkState(shardingValue instanceof ListRouteValue, "Inline strategy cannot support this type sharding:" + shardingValue.toString());
Collection<String> shardingResult = doSharding((ListRouteValue) shardingValue);
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
for (String each : shardingResult) {
if (availableTargetNames.contains(each)) {
result.add(each);
}
}
return result;
}(2)4.1.1的
官方文档虽然说Hint可以跳过解析和改写
,但在我们上面解析引擎的源码解析中,我们并没有看到有对Hint策略的额外跳过。事实上,即使使用了Hint分片SQL也同样需要解析重写,也同样受Sharding-JDBC的语法限制,这在
官方的issue
中也曾经被提及。

▲图片来源:
ShardingSphere 官方文档
主从路由
主从路由的核心逻辑就是通过MasterSlaveDataSourceRouter的route方法进行判定SQL走主库还是从库。主从情况下,配置的数据源实际是一组主从,而不是单个的实例,所以需要通过masterSlaveRule获取到具体的主库或者从库名字。
主从路由decorate
org.apache.shardingsphere.masterslave.route.engine.MasterSlaveRouteDecorator#decorate
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final MasterSlaveRule masterSlaveRule, final ConfigurationProperties properties) {
//为空证明没有经过分片路由
if (routeContext.getRouteResult().getRouteUnits().isEmpty()) {
//根据SQL判断选择走主库还是从库
String dataSourceName = new MasterSlaveDataSourceRouter(masterSlaveRule).route(routeContext.getSqlStatementContext().getSqlStatement());
RouteResult routeResult = new RouteResult();
//根据具体的主库/从库名创建路由单元
routeResult.getRouteUnits().add(new RouteUnit(new RouteMapper(dataSourceName, dataSourceName), Collections.emptyList()));
return new RouteContext(routeContext.getSqlStatementContext(), Collections.emptyList(), routeResult);
}
Collection<RouteUnit> toBeRemoved = new LinkedList<>();
Collection<RouteUnit> toBeAdded = new LinkedList<>();
//不为空证明已经被分片路由处理了
for (RouteUnit each : routeContext.getRouteResult().getRouteUnits()) {
if (masterSlaveRule.getName().equalsIgnoreCase(each.getDataSourceMapper().getActualName())) {
//先标记移除 因为这里是一组主从的名字而不是实际的库
toBeRemoved.add(each);
//根据SQL判断选择走主库还是从库
String actualDataSourceName = new MasterSlaveDataSourceRouter(masterSlaveRule).route(routeContext.getSqlStatementContext().getSqlStatement());
//根据具体的主库/从库名创建路由单元
toBeAdded.add(new RouteUnit(new RouteMapper(each.getDataSourceMapper().getLogicName(), actualDataSourceName), each.getTableMappers()));
}
}
routeContext.getRouteResult().getRouteUnits().removeAll(toBeRemoved);
routeContext.getRouteResult().getRouteUnits().addAll(toBeAdded);
return routeContext;
}MasterSlaveDataSourceRouter中isMasterRoute方法会判断SQL是否需要走主库,当出现以下情况时走主库:
select语句包含锁,如for update语句
不是select语句
MasterVisitedManager.isMasterVisited()设置为true
HintManager.isMasterRouteOnly()设置为true
不走主库则通过负载算法选择从库,Sharding-JDBC提供了
轮询和随机
两种算法。
MasterSlaveDataSourceRouter
public final class MasterSlaveDataSourceRouter {
private final MasterSlaveRule masterSlaveRule;
/**
* Route.
*
* @param sqlStatement SQL statement
* @return data source name
*/
public String route(final SQLStatement sqlStatement) {
if (isMasterRoute(sqlStatement)) {
MasterVisitedManager.setMasterVisited();
return masterSlaveRule.getMasterDataSourceName();
}
return masterSlaveRule.getLoadBalanceAlgorithm().getDataSource(
masterSlaveRule.getName(), masterSlaveRule.getMasterDataSourceName(), new ArrayList<>(masterSlaveRule.getSlaveDataSourceNames()));
}
private boolean isMasterRoute(final SQLStatement sqlStatement) {
return containsLockSegment(sqlStatement) || !(sqlStatement instanceof SelectStatement) || MasterVisitedManager.isMasterVisited() || HintManager.isMasterRouteOnly();
}
private boolean containsLockSegment(final SQLStatement sqlStatement) {
return sqlStatement instanceof SelectStatement && ((SelectStatement) sqlStatement).getLock().isPresent();
}
}是否走主库的信息存在MasterVisitedManager中,MasterVisitedManager是通过ThreadLocal实现的,但这种实现会有一个问题,
当我们使用事务先查询再更新/插入时,第一条查询SQL并不会走主库,而是走从库
,如果业务需要事务的第一条查询也走主库,事务查询前需要手动调用一次MasterVisitedManager.setMasterVisited()。
MasterVisitedManager
public final class MasterVisitedManager {
private static final ThreadLocal<Boolean> MASTER_VISITED = ThreadLocal.withInitial(() -> false);
/**
* Judge master data source visited in current thread.
*
* @return master data source visited or not in current thread
*/
public static boolean isMasterVisited() {
return MASTER_VISITED.get();
}
/**
* Set master data source visited in current thread.
*/
public static void setMasterVisited() {
MASTER_VISITED.set(true);
}
/**
* Clear master data source visited.
*/
public static void clear() {
MASTER_VISITED.remove();
}
}3.3.2 引擎总结
路由引擎的作用是将SQL根据参数通过实现的策略算法计算出实际该在哪些库的哪些表执行,也就是路由结果。路由引擎有两种实现,分别是分片路由和主从路由,两者都提供了标准化的策略接口来让业务实现自己的路由策略,分片路由需要注意自身SQL场景和策略算法相匹配,主从路由中同一线程且同一数据库连接内,有写入操作后,之后的读操作会从主库读取,写入操作前的读操作不会走主库。
3.4 改写引擎
3.4.1 引擎解析
经过解析路由后虽然确定了执行的实际库表,但SQL中表名依旧是逻辑表,不能执行,改写引擎可以将逻辑表替换为物理表。同时,路由至多库表的SQL也需要拆分为多条SQL执行。
改写的入口仍旧在BasePrepareEngine中,创建重写上下文createSQLRewriteContext,再根据上下文进行改写rewrite,最终返回执行单元ExecutionUnit。
改写逻辑入口
org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#executeRewrite
private Collection<ExecutionUnit> executeRewrite(final String sql, final List<Object> parameters, final RouteContext routeContext) {
//注册重写装饰器
registerRewriteDecorator();
//创建 SQLRewriteContext
SQLRewriteContext sqlRewriteContext = rewriter.createSQLRewriteContext(sql, parameters, routeContext.getSqlStatementContext(), routeContext);
//重写
return routeContext.getRouteResult().getRouteUnits().isEmpty() ? rewrite(sqlRewriteContext) : rewrite(routeContext, sqlRewriteContext);
}执行单元包含了数据源名称,改写后的SQL,以及对应的参数,SQL一样的两个SQLUnit会被视为相等。
ExecutionUnit
@RequiredArgsConstructor
@Getter
@EqualsAndHashCode
@ToString
public final class ExecutionUnit {
private final String dataSourceName;
private final SQLUnit sqlUnit;
}
@AllArgsConstructor
@RequiredArgsConstructor
@Getter
@Setter
//根据sql判断是否相等
@EqualsAndHashCode(of = { "sql" })
@ToString
public final class SQLUnit {
private String sql;
private final List<Object> parameters;
}createSQLRewriteContext完成了两件事,一个是对SQL参数进行了重写,一个是生成了SQLToken。
createSQLRewriteContext
org.apache.shardingsphere.underlying.rewrite.SQLRewriteEntry#createSQLRewriteContext
public SQLRewriteContext createSQLRewriteContext(final String sql, final List<Object> parameters, final SQLStatementContext sqlStatementContext, final RouteContext routeContext) {
SQLRewriteContext result = new SQLRewriteContext(schemaMetaData, sqlStatementContext, sql, parameters);
//sql参数重写
decorate(decorators, result, routeContext);
//生成SQLToken
result.generateSQLTokens();
return result;
}
org.apache.shardingsphere.sharding.rewrite.context.ShardingSQLRewriteContextDecorator#decorate
public void decorate(final ShardingRule shardingRule, final ConfigurationProperties properties, final SQLRewriteContext sqlRewriteContext) {
for (ParameterRewriter each : new ShardingParameterRewriterBuilder(shardingRule, routeContext).getParameterRewriters(sqlRewriteContext.getSchemaMetaData())) {
if (!sqlRewriteContext.getParameters().isEmpty() && each.isNeedRewrite(sqlRewriteContext.getSqlStatementContext())) {
//参数重写
each.rewrite(sqlRewriteContext.getParameterBuilder(), sqlRewriteContext.getSqlStatementContext(), sqlRewriteContext.getParameters());
}
}
//sqlTokenGenerators
sqlRewriteContext.addSQLTokenGenerators(new ShardingTokenGenerateBuilder(shardingRule, routeContext).getSQLTokenGenerators());
}
org.apache.shardingsphere.underlying.rewrite.context.SQLRewriteContext#generateSQLTokens
public void generateSQLTokens() {
sqlTokens.addAll(sqlTokenGenerators.generateSQLTokens(sqlStatementContext, parameters, schemaMetaData));
}ParameterRewriter中与分片相关的实现有两种。

//*详细的例子可以参考 官方文档中分页修正和补列部分 。
SQLToken记录了SQL中每个token(解析引擎中提过的不可再分的原子符号)的起始位置,从而方便改写引擎知道哪些位置需要改写。
SQLToken
@RequiredArgsConstructor
@Getter
public abstract class SQLToken implements Comparable<SQLToken> {
private final int startIndex;
@Override
public final int compareTo(final SQLToken sqlToken) {
return startIndex - sqlToken.getStartIndex();
}
}创建完SQLRewriteContext后就对整条SQL进行重写和组装参数,可以看出每个RouteUnit都会重写SQL并获取自己对应的参数。
SQLRouteRewriteEngine.rewrite
org.apache.shardingsphere.underlying.rewrite.engine.SQLRouteRewriteEngine#rewrite
public Map<RouteUnit, SQLRewriteResult> rewrite(final SQLRewriteContext sqlRewriteContext, final RouteResult routeResult) {
Map<RouteUnit, SQLRewriteResult> result = new LinkedHashMap<>(routeResult.getRouteUnits().size(), 1);
for (RouteUnit each : routeResult.getRouteUnits()) {
//重写SQL+组装参数
result.put(each, new SQLRewriteResult(new RouteSQLBuilder(sqlRewriteContext, each).toSQL(), getParameters(sqlRewriteContext.getParameterBuilder(), routeResult, each)));
}
return result;
}toSQL核心就是根据SQLToken将SQL拆分改写再拼装,比如select * from t_order where created_by = '123' 就会被拆分为select * from | t_order | where created_by = '123'三部分进行改写拼装。
toSQL
org.apache.shardingsphere.underlying.rewrite.sql.impl.AbstractSQLBuilder#toSQL
public final String toSQL() {
if (context.getSqlTokens().isEmpty()) {
return context.getSql();
}
Collections.sort(context.getSqlTokens());
StringBuilder result = new StringBuilder();
//截取第一个SQLToken之前的内容 select * from
result.append(context.getSql().substring(0, context.getSqlTokens().get(0).getStartIndex()));
for (SQLToken each : context.getSqlTokens()) {
//重写拼接每个SQLToken对应的内容 t_order ->t_order_0
result.append(getSQLTokenText(each));
//拼接SQLToken中间不变的内容 where created_by = '123'
result.append(getConjunctionText(each));
}
return result.toString();
}ParameterBuilder有StandardParameterBuilder和GroupedParameterBuilder两个实现。
StandardParameterBuilder:
适用于非insert语句,getParameters无需分组处理直接返回即可GroupedParameterBuilder:
适用于insert语句,需要根据路由情况对参数进行分组。
原因和样例可以参考
官方文档批量拆分部分
。
getParameters
org.apache.shardingsphere.underlying.rewrite.engine.SQLRouteRewriteEngine#getParameters
private List<Object> getParameters(final ParameterBuilder parameterBuilder, final RouteResult routeResult, final RouteUnit routeUnit) {
if (parameterBuilder instanceof StandardParameterBuilder || routeResult.getOriginalDataNodes().isEmpty() || parameterBuilder.getParameters().isEmpty()) {
//非插入语句直接返回
return parameterBuilder.getParameters();
}
List<Object> result = new LinkedList<>();
int count = 0;
for (Collection<DataNode> each : routeResult.getOriginalDataNodes()) {
if (isInSameDataNode(each, routeUnit)) {
//插入语句参数分组构造
result.addAll(((GroupedParameterBuilder) parameterBuilder).getParameters(count));
}
count++;
}
return result;
}3.4.2 引擎总结
改写引擎的作用是将逻辑SQL转换为实际可执行的SQL,这其中既有逻辑表名的替换,也有多路由的SQL拆分,还有为了后续归并操作而进行的分页、分组、排序等改写,select语句不会对参数进行重组,而insert语句为了避免插入多余数据,会通过路由单元对参数进行重组。
3.5 执行引擎
3.5.1 引擎解析
改写完成后的SQL就可以执行了,执行引擎需要平衡好资源和效率,如果为每条真实SQL都创建一个数据库连接显然会造成资源的滥用,但如果单线程串行也必然会影响执行效率。
执行引擎会先将执行单元中需要执行的SQLUnit根据数据源分组,同一个数据源下的SQLUnit会放入一个list,然后会根据maxConnectionsSizePerQuery对同一个数据源的SQLUnit继续分组,创建连接并绑定SQLUnit 。
执行组创建
org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSynchronizedExecuteUnitGroups
private Collection<InputGroup<StatementExecuteUnit>> getSynchronizedExecuteUnitGroups(
final Collection<ExecutionUnit> executionUnits, final SQLExecutePrepareCallback callback) throws SQLException {
//根据数据源将SQLUnit分组 key=dataSourceName
Map<String, List<SQLUnit>> sqlUnitGroups = getSQLUnitGroups(executionUnits);
Collection<InputGroup<StatementExecuteUnit>> result = new LinkedList<>();
//创建sql执行组
for (Entry<String, List<SQLUnit>> entry : sqlUnitGroups.entrySet()) {
result.addAll(getSQLExecuteGroups(entry.getKey(), entry.getValue(), callback));
}
return result;
}
org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSQLExecuteGroups
private List<InputGroup<StatementExecuteUnit>> getSQLExecuteGroups(final String dataSourceName,
final List<SQLUnit> sqlUnits, final SQLExecutePrepareCallback callback) throws SQLException {
List<InputGroup<StatementExecuteUnit>> result = new LinkedList<>();
//每个连接需要执行的最大sql数量
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1, 1);
//分组,每组对应一条数据库连接
List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);
//选择连接模式 连接限制/内存限制
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
//创建连接
List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());
int count = 0;
for (List<SQLUnit> each : sqlUnitPartitions) {
//绑定连接和SQLUnit 创建StatementExecuteUnit
result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
return result;
}SQLUnit分组和连接模式选择没有任何关系,
连接模式的选择只取决于maxConnectionsSizePerQuery和SQLUnit数量的大小关系
,maxConnectionsSizePerQuery代表了一个数据源一次查询允许的最大连接数。
当maxConnectionsSizePerQuery<sqlunit数量时,意味着无法做到每个sqlunit独享一个连接,需要直接查询出结果集至内存中;< li="">
当maxConnectionsSizePerQuery>=SQLUnit数量时,意味着可以支持每个SQLUnit独享一个连接,可以通过ResultSet游标下移的方式查询结果集。
不过maxConnectionsSizePerQuery默认值为1,所以当一条SQL需要路由至多张表时(即有多个SQLUnit)会采用连接限制,当路由至单表时是内存限制模式。

为了避免产生数据库连接死锁问题,
在内存限制模式时,Sharding-JDBC通过锁住数据源对象一次性创建出本条SQL需要的所有数据库连接
。连接限制模式下,各连接一次性查出各自的结果,不会出现多连接相互等待的情况,因此不会发生死锁,而内存限制模式通过游标读取结果集,需要多条连接去查询不同的表做合并,如果不一次性拿到所有需要的连接,则可能存在连接相互等待的情况造成死锁。可以参照
官方文档中执行引擎相关例子
。
不同连接模式创建连接
private List<Connection> createConnections(final String dataSourceName, final ConnectionMode connectionMode, final DataSource dataSource, final int connectionSize) throws SQLException {
if (1 == connectionSize) {
Connection connection = createConnection(dataSourceName, dataSource);
replayMethodsInvocation(connection);
return Collections.singletonList(connection);
}
if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) {
return createConnections(dataSourceName, dataSource, connectionSize);
}
//内存限制模式加锁 一次性获取所有的连接
synchronized (dataSource) {
return createConnections(dataSourceName, dataSource, connectionSize);
}
}此外,结果集的内存合并和流式合并只在调用JDBC的executeQuery的情况下生效,
如果使用execute方式进行查询,都是统一使用流式方式的查询。
查询结果归并对比
org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#executeQuery#101
org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#getQueryResult
private QueryResult getQueryResult(final Statement statement, final ConnectionMode connectionMode) throws SQLException {
PreparedStatement preparedStatement = (PreparedStatement) statement;
ResultSet resultSet = preparedStatement.executeQuery();
getResultSets().add(resultSet);
//executeQuery 中根据连接模式选择流式/内存
return ConnectionMode.MEMORY_STRICTLY == connectionMode ? new StreamQueryResult(resultSet) : new MemoryQueryResult(resultSet);
}
//execute 单独调用getResultSet中只会使用流式合并
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#getResultSet#158
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#getQueryResults
private List<QueryResult> getQueryResults(final List<ResultSet> resultSets) throws SQLException {
List<QueryResult> result = new ArrayList<>(resultSets.size());
for (ResultSet each : resultSets) {
if (null != each) {
result.add(new StreamQueryResult(each));
}
}
return result;
}多条连接的执行方式分为串行和并行,在本地事务和XA事务中是串行的方式,其余情况是并行,具体的执行逻辑这里就不再展开了。
isHoldTransaction
public boolean isHoldTransaction() {
return (TransactionType.LOCAL == transactionType && !getAutoCommit()) || (TransactionType.XA == transactionType && isInShardingTransaction());
}3.5.2 引擎总结
执行引擎通过maxConnectionsSizePerQuery和同数据源的SQLUnit的数量大小确定连接模式,maxConnectionsSizePerQuery=SQLUnit数量使用内存限制模式,当使用内存限制模式时会通过对数据源对象加锁来保证一次性获取本条SQL需要的连接而避免死锁。在使用executeQuery查询时,处理结果集时会根据连接模式选择流式或者内存合并,但使用execute方法查询,处理结果集只会使用流式合并。
3.6 归并引擎
3.6.1 引擎解析
查询出的结果集需要经过归并引擎归并后才是最终的结果,归并的核心入口在MergeEntry的process方法中,优先处理分片场景的合并,再进行脱敏,只有读写分离的情况下则直接返回TransparentMergedResult,TransparentMergedResult实际上没做合并的额外处理,其内部实现都是完全调用queryResult的实现。
- 归并逻辑入口
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#mergeQuery#190
org.apache.shardingsphere.underlying.pluggble.merge.MergeEngine#merge#61
org.apache.shardingsphere.underlying.merge.MergeEntry#process
public MergedResult process(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext) throws SQLException {
//分片合并
Optional<MergedResult> mergedResult = merge(queryResults, sqlStatementContext);
//脱敏处理
Optional<MergedResult> result = mergedResult.isPresent() ? Optional.of(decorate(mergedResult.get(), sqlStatementContext)) : decorate(queryResults.get(0), sqlStatementContext);
//只有读写分离的情况下,orElseGet会不存在,TransparentMergedResult
return result.orElseGet(() -> new TransparentMergedResult(queryResults.get(0)));
}TransparentMergedResult
@RequiredArgsConstructor
public final class TransparentMergedResult implements MergedResult {
private final QueryResult queryResult;
@Override
public boolean next() throws SQLException {
return queryResult.next();
}
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
return queryResult.getValue(columnIndex, type);
}
@Override
public Object getCalendarValue(final int columnIndex, final Class<?> type, final Calendar calendar) throws SQLException {
return queryResult.getCalendarValue(columnIndex, type, calendar);
}
@Override
public InputStream getInputStream(final int columnIndex, final String type) throws SQLException {
return queryResult.getInputStream(columnIndex, type);
}
@Override
public boolean wasNull() throws SQLException {
return queryResult.wasNull();
}
}我们只看分片相关的操作,ResultMergerEngine只有一个实现类ShardingResultMergerEngine,所以只有存在分片情况的时候,上文的第一个merge才会有结果。根据SQL类型的不同选择ResultMerger实现,查询类的合并是最常用也是最复杂的合并。
MergeEntry.merge
org.apache.shardingsphere.underlying.merge.MergeEntry#merge
private Optional<MergedResult> merge(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext) throws SQLException {
for (Entry<BaseRule, ResultProcessEngine> entry : engines.entrySet()) {
if (entry.getValue() instanceof ResultMergerEngine) {
//选择不同类型的 resultMerger
ResultMerger resultMerger = ((ResultMergerEngine) entry.getValue()).newInstance(databaseType, entry.getKey(), properties, sqlStatementContext);
//归并
return Optional.of(resultMerger.merge(queryResults, sqlStatementContext, schemaMetaData));
}
}
return Optional.empty();
}
org.apache.shardingsphere.sharding.merge.ShardingResultMergerEngine#newInstance
public ResultMerger newInstance(final DatabaseType databaseType, final ShardingRule shardingRule, final ConfigurationProperties properties, final SQLStatementContext sqlStatementContext) {
if (sqlStatementContext instanceof SelectStatementContext) {
return new ShardingDQLResultMerger(databaseType);
}
if (sqlStatementContext.getSqlStatement() instanceof DALStatement) {
return new ShardingDALResultMerger(shardingRule);
}
return new TransparentResultMerger();
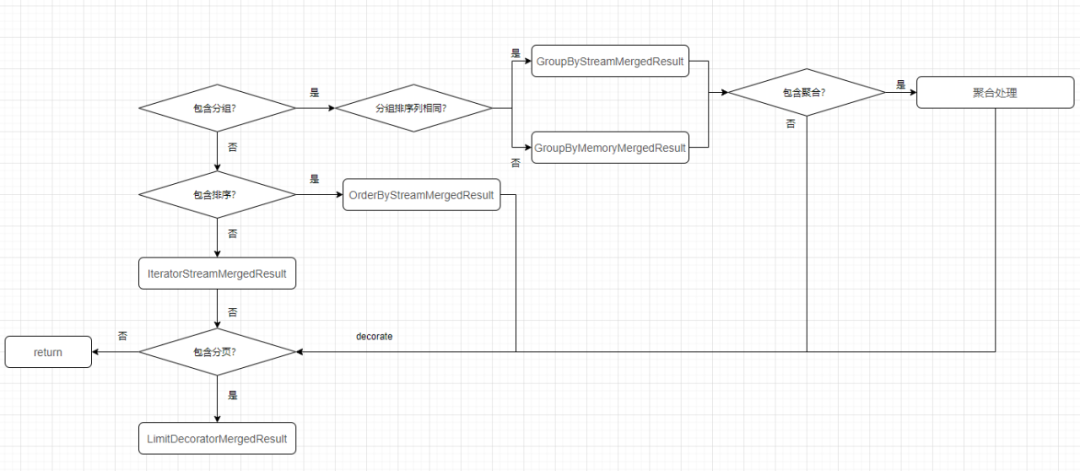
}ShardingDQLResultMerger的merge方法就是根据SQL解析结果中包含的token选择合适的归并方式(分组聚合、排序、遍历),归并后的mergedResult统一经过decorate方法进行判断是否需要分页归并,整体处理流程图可以概括如下。
归并方式选择
org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#merge
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext, final SchemaMetaData schemaMetaData) throws SQLException {
if (1 == queryResults.size()) {
return new IteratorStreamMergedResult(queryResults);
}
Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0));
SelectStatementContext selectStatementContext = (SelectStatementContext) sqlStatementContext;
selectStatementContext.setIndexes(columnLabelIndexMap);
//分组聚合,排序,遍历
MergedResult mergedResult = build(queryResults, selectStatementContext, columnLabelIndexMap, schemaMetaData);
//分页归并
return decorate(queryResults, selectStatementContext, mergedResult);
}
org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#build
private MergedResult build(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext,
final Map<String, Integer> columnLabelIndexMap, final SchemaMetaData schemaMetaData) throws SQLException {
if (isNeedProcessGroupBy(selectStatementContext)) {
//分组聚合归并
return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schemaMetaData);
}
if (isNeedProcessDistinctRow(selectStatementContext)) {
setGroupByForDistinctRow(selectStatementContext);
//分组聚合归并
return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schemaMetaData);
}
if (isNeedProcessOrderBy(selectStatementContext)) {
//排序归并
return new OrderByStreamMergedResult(queryResults, selectStatementContext, schemaMetaData);
}
//遍历归并
return new IteratorStreamMergedResult(queryResults);
}
org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#decorate
private MergedResult decorate(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final MergedResult mergedResult) throws SQLException {
PaginationContext paginationContext = selectStatementContext.getPaginationContext();
if (!paginationContext.isHasPagination() || 1 == queryResults.size()) {
return mergedResult;
}
String trunkDatabaseName = DatabaseTypes.getTrunkDatabaseType(databaseType.getName()).getName();
//根据数据库类型分页归并
if ("MySQL".equals(trunkDatabaseName) || "PostgreSQL".equals(trunkDatabaseName)) {
return new LimitDecoratorMergedResult(mergedResult, paginationContext);
}
if ("Oracle".equals(trunkDatabaseName)) {
return new RowNumberDecoratorMergedResult(mergedResult, paginationContext);
}
if ("SQLServer".equals(trunkDatabaseName)) {
return new TopAndRowNumberDecoratorMergedResult(mergedResult, paginationContext);
}
return mergedResult;
}每种归并方式的作用在
官方文档有比较详细的案例
,这里就不再重复介绍了。
3.6.2 引擎总结
归并引擎是Sharding-JDBC执行SQL的最后一步,其作用是将多个数节点的结果集组合为一个正确的结果集返回,查询类的归并有
分组归并、聚合归并、排序归并、遍历归并、分页归并
五种,这五种归并方式并不是互斥的,而是相互组合的。
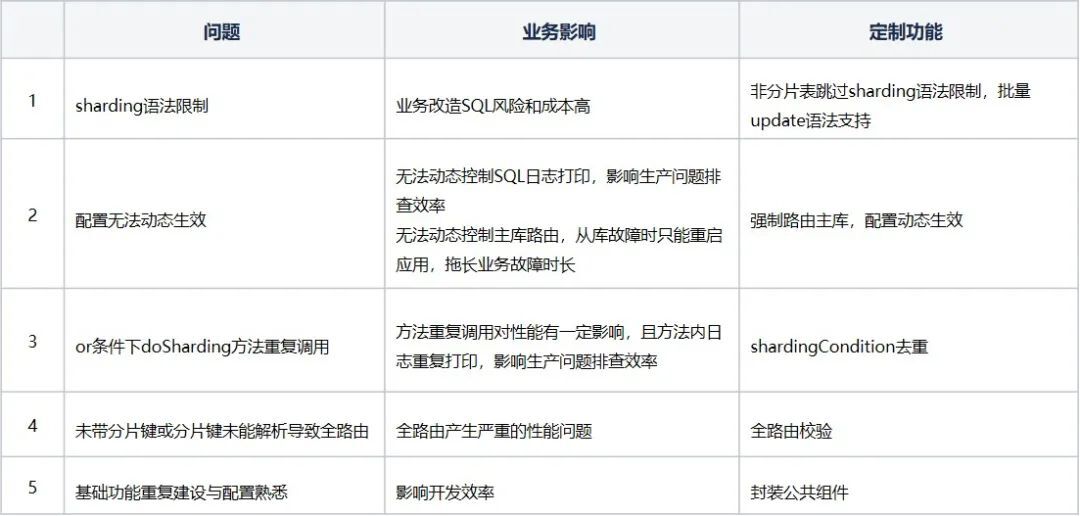
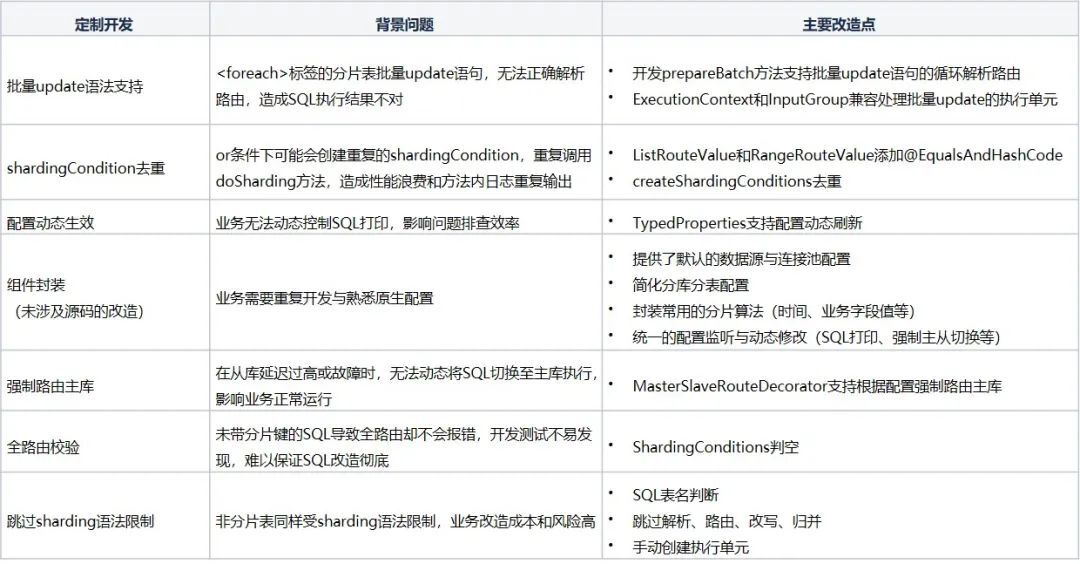
四、定制开发
在使用Sharding-JDBC过程中,我们发现了一些问题可以改进,比如存量系统数据量到达一定规模而需要分库分表引入Sharding-JDBC时,就会
存在两大问题
。
一个是存量数据的迁移
,这个问题我们可以通过分片算法兼容,前文已经提过分片键的值是不允许更改的,而且SQL如果不包含分片键,如果这个分片键对应的值是递增的(如id,时间等),我们可以设置一个阈值,在分片算法的doSharding中判断分片值与阈值的大小决定将数据路由至旧表或新表,避免数据迁移的麻烦。如果是根据用户id取模分表,而新增的数据无法只通过用户id判断,这时可以考虑采用复合分片算法,将用户id与订单id或者时间等递增的字段同时设置为分片键,根据订单id或时间判断是否是新数据,再根据用户id取模得到路由结果即可。
另一个是
Sharding-JDBC
语法限制会使得存量SQL面对巨大的改造压力,而实际上业务更关心的是需要分片的表,非分片的表不应该发生改动和影响。实际上,非分片表理论上无需通过解析、路由、重写、合并,为此我们在源码层面对这段逻辑进行了优化,支持跳过部分解析,完全跳过分片路由、重写和合并,尽可能减少Sharding-JDBC对非分片表的语法限制,来减少业务系统的改造压力与风险。
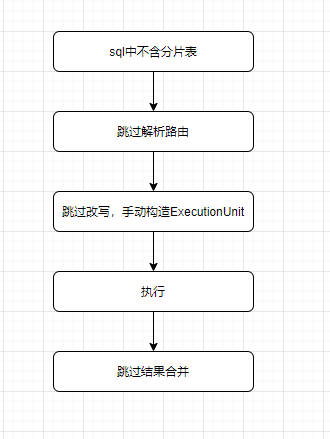
4.1 跳过Sharding语法限制
Sharding-JDBC执行解析路由重写的逻辑都是在BasePrepareEngine中,最终构造ExecutionContext交由执行引擎执行,ExecutionContext中包含sqlStatementContext和executionUnits,非分片表不涉及路由改写,所以其ExecutionUnit我们非常容易手动构造,而查看SQLStatementContext的使用情况,我们发现SQLStatementContext只会影响结果集的合并而不会影响实际的执行,而不分片表也无需进行结果集的合并,整体实现思路如图。
ExecutionContext相关对象
public class ExecutionContext {
private final SQLStatementContext sqlStatementContext;
private final Collection<ExecutionUnit> executionUnits = new LinkedHashSet<>();
}
public final class ExecutionUnit {
private final String dataSourceName;
private final SQLUnit sqlUnit;
}
public final class SQLUnit {
private String sql;
private final List<Object> parameters;
}(1)校验SQL中是否包含分片表:
我们是通过正则将SQL中的各个单词分隔成Set,然后再遍历BaseRule判断是否存在分片表。大家可能会奇怪明明解析引擎可以帮我们解析出SQL中的表名,为什么还要自己来解析。因为我们测试的过程中发现,
存量业务上的SQL很多在解析阶段就会报错,只能提前判断
,当然这种判断方式并不严谨,比如 SELECT order_id FROM t_order_record WHERE order_id=1 AND remarks=' t_order xxx';,配置的分片表t_order时就会存在误判,但这种场景在我们的业务中没有,所以暂时并没有处理。由于这个信息需要在多个对象方法中使用,为了避免修改大量的对象变量和方法入参,而又能方便的透传这个信息,判断的结果我们选择放在ThreadLocal里。
RuleContextManager
public final class RuleContextManager {
private static final ThreadLocal<RuleContextManager> SKIP_CONTEXT_HOLDER = ThreadLocal.withInitial(RuleContextManager::new);
/**
* 是否跳过sharding
*/
private boolean skipSharding;
/**
* 是否路由至主库
*/
private boolean masterRoute;
public static boolean isSkipSharding() {
return SKIP_CONTEXT_HOLDER.get().skipSharding;
}
public static void setSkipSharding(boolean skipSharding) {
SKIP_CONTEXT_HOLDER.get().skipSharding = skipSharding;
}
public static boolean isMasterRoute() {
return SKIP_CONTEXT_HOLDER.get().masterRoute;
}
public static void setMasterRoute(boolean masterRoute) {
SKIP_CONTEXT_HOLDER.get().masterRoute = masterRoute;
}
public static void clear(){
SKIP_CONTEXT_HOLDER.remove();
}
}判断SQL是否包含分片表
org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#buildSkipContext
// 判断是否可以跳过sharding,构造RuleContextManager的值
private void buildSkipContext(final String sql){
Set<String> sqlTokenSet = new HashSet<>(Arrays.asList(sql.split("[\\s]")));
if (CollectionUtils.isNotEmpty(rules)) {
for (BaseRule baseRule : rules) {
//定制方法,ShardingRule实现,判断sqlTokenSet是否包含逻辑表即可
if(baseRule.hasContainShardingTable(sqlTokenSet)){
RuleContextManager.setSkipSharding(false);
break;
}else {
RuleContextManager.setSkipSharding(true);
}
}
}
}
org.apache.shardingsphere.core.rule.ShardingRule#hasContainShardingTable
public Boolean hasContainShardingTable(Set<String> sqlTokenSet) {
//logicTableNameList通过遍历TableRule可以得到
for (String logicTable : logicTableNameList) {
if (sqlTokenSet.contains(logicTable)) {
return true;
}
}
return false;
}(2)跳过解析路由:
通过RuleContextManager中的skipSharding判断是否需要跳过Sharding解析路由,但为了兼容读写分离的场景,我们还需要知道这条SQL应该走主库还是从库,走主库的场景在后面强制路由主库部分有说明,SQL走主库实际上只有两种情况,一种是非SELECT语句,另一种就是SELECT语句带锁,如SELECT...FOR UPDATE,因此整体实现的步骤如下:
如果标记了跳过Sharding且不为select语句,直接返回SkipShardingStatement,单独构造一个SkipShardingStatement的目的是为了能利用解析引擎中的缓存,缓存中不能放入null值。
如果是select语句需要继续解析,判断是否有锁后直接返回,避免后续解析造成语法不兼容,这里也曾尝试用反射获取lockClause来判断是否包含锁,但最终没有成功。
ShardingRouteDecorator根据RuleContextManager.isSkipSharding判断是否跳过路由。
跳过解析路由
public class SkipShardingStatement implements SQLStatement{
@Override
public int getParameterCount() {
return 0;
}
}
org.apache.shardingsphere.sql.parser.SQLParserEngine#parse0
private SQLStatement parse0(final String sql, final boolean useCache) {
if (useCache) {
Optional<SQLStatement> cachedSQLStatement = cache.getSQLStatement(sql);
if (cachedSQLStatement.isPresent()) {
return cachedSQLStatement.get();
}
}
ParseTree parseTree = new SQLParserExecutor(databaseTypeName, sql).execute().getRootNode();
/**
* 跳过sharding 需要判断是否需要路由至主库 如果不是select语句直接跳过
* 是select语句则需要通过继续解析判断是否有锁
*/
SQLStatement result ;
if(RuleContextManager.isSkipSharding()&&!VisitorRule.SELECT.equals(VisitorRule.valueOf(parseTree.getClass()))){
RuleContextManager.setMasterRoute(true);
result = new SkipShardingStatement();
}else {
result = (SQLStatement) ParseTreeVisitorFactory.newInstance(databaseTypeName, VisitorRule.valueOf(parseTree.getClass())).visit(parseTree);
}
if (useCache) {
cache.put(sql, result);
}
return result;
}
org.apache.shardingsphere.sql.parser.mysql.visitor.impl.MySQLDMLVisitor#visitSelectClause
public ASTNode visitSelectClause(final SelectClauseContext ctx) {
SelectStatement result = new SelectStatement();
// 跳过sharding 只需要判断是否有锁来决定是否路由至主库即可
if(RuleContextManager.isSkipSharding()){
if (null != ctx.lockClause()) {
result.setLock((LockSegment) visit(ctx.lockClause()));
RuleContextManager.setMasterRoute(true);
}
return result;
}
//...后续解析
}
org.apache.shardingsphere.underlying.route.DataNodeRouter#createRouteContext
private RouteContext createRouteContext(final String sql, final List<Object> parameters, final boolean useCache) {
SQLStatement sqlStatement = parserEngine.parse(sql, useCache);
//如果需要跳过sharding 不进行后续的解析直接返回
if (RuleContextManager.isSkipSharding()) {
return new RouteContext(sqlStatement, parameters, new RouteResult());
}
//...解析
}
org.apache.shardingsphere.sharding.route.engine.ShardingRouteDecorator#decorate
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final ShardingRule shardingRule, final ConfigurationProperties properties) {
// 跳过sharding路由
if(RuleContextManager.isSkipSharding()){
return routeContext;
}
//...路由
}(3)手动构造ExecutionUnit:
ExecutionUnit中我们需要确定的内容就是datasourceName,这里我们认为跳过Sharding的SQL最终执行的库一定只有一个。如果只是跳过Sharding的情况,直接从元数据中获取数据源名称即可,如果存在读写分离的情况,主从路由的结果也一定是唯一的。创建完ExecutionUnit直接放入ExecutionContext返回即可,从而跳过后续的改写逻辑。
手动构造ExecutionUnit
public ExecutionContext prepare(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
// 判断是否可以跳过sharding,构造RuleContextManager的值
buildSkipContext(sql);
RouteContext routeContext = executeRoute(sql, clonedParameters);
ExecutionContext result = new ExecutionContext(routeContext.getSqlStatementContext());
// 跳过sharding的sql最后的路由结果一定只有一个库
if(RuleContextManager.isSkipSharding()){
log.debug("可以跳过sharding的场景 {}", sql);
if(!Objects.isNull(routeContext.getRouteResult())){
Collection<String> allInstanceDataSourceNames = this.metaData.getDataSources().getAllInstanceDataSourceNames();
int routeUnitsSize = routeContext.getRouteResult().getRouteUnits().size();
/*
* 1. 没有读写分离的情况下 跳过sharding路由会导致routeUnitsSize为0 此时需要判断数据源数量是否为1
* 2. 读写分离情况下 只会路由至具体的主库或从库 routeUnitsSize数量应该为1
*/
if(!(routeUnitsSize == 0 && allInstanceDataSourceNames.size()==1)|| routeUnitsSize>1){
throw new ShardingSphereException("可以跳过sharding,但是路由结果不唯一,SQL= %s ,routeUnits= %s ",sql, routeContext.getRouteResult().getRouteUnits());
}
Collection<String> actualDataSourceNames = routeContext.getRouteResult().getActualDataSourceNames();
// 手动创建执行单元
String datasourceName = CollectionUtils.isEmpty(actualDataSourceNames)? allInstanceDataSourceNames.iterator().next():actualDataSourceNames.iterator().next();
ExecutionUnit executionUnit = new ExecutionUnit(datasourceName, new SQLUnit(sql, clonedParameters));
result.getExecutionUnits().add(executionUnit);
//标记该结果需要跳过
result.setSkipShardingScenarioFlag(true);
}
}else {
result.getExecutionUnits().addAll(executeRewrite(sql, clonedParameters, routeContext));
}
if (properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
SQLLogger.logSQL(sql, properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE), result.getSqlStatementContext(), result.getExecutionUnits());
}
return result;
}(4)跳过合并:
跳过查询结果的合并和影响行数计算的合并,注意ShardingPreparedStatement和ShardingStatement都需要跳过
跳过合并
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#executeQuery
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
List<QueryResult> queryResults = preparedStatementExecutor.executeQuery();
List<ResultSet> resultSets = preparedStatementExecutor.getResultSets();
// 定制开发,不分片跳过合并
if(executionContext.isSkipShardingScenarioFlag()){
return CollectionUtils.isNotEmpty(resultSets) ? resultSets.get(0) : null;
}
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingResultSet(resultSets, mergedResult, this, executionContext);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#getResultSet
public ResultSet getResultSet() throws SQLException {
if (null != currentResultSet) {
return currentResultSet;
}
List<ResultSet> resultSets = getResultSets();
// 定制开发,不分片跳过合并
if(executionContext.isSkipShardingScenarioFlag()){
return CollectionUtils.isNotEmpty(resultSets) ? resultSets.get(0) : null;
}
if (executionContext.getSqlStatementContext() instanceof SelectStatementContext || executionContext.getSqlStatementContext().getSqlStatement() instanceof DALStatement) {
MergedResult mergedResult = mergeQuery(getQueryResults(resultSets));
currentResultSet = new ShardingResultSet(resultSets, mergedResult, this, executionContext);
}
return currentResultSet;
}
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#isAccumulate
public boolean isAccumulate() {
//定制开发,不分片跳过计算
if(executionContext.isSkipShardingScenarioFlag()){
return false;
}
return !connection.getRuntimeContext().getRule().isAllBroadcastTables(executionContext.getSqlStatementContext().getTablesContext().getTableNames());
}(5)清空RuleContextManager:
查看一下Sharding-JDBC其他ThreadLocal的清空位置,对应的清空RuleContextManager就好。
清空ThreadLocal
org.apache.shardingsphere.shardingjdbc.jdbc.adapter.AbstractConnectionAdapter#close
public final void close() throws SQLException {
closed = true;
MasterVisitedManager.clear();
TransactionTypeHolder.clear();
RuleContextManager.clear();
int connectionSize = cachedConnections.size();
try {
forceExecuteTemplateForClose.execute(cachedConnections.entries(), cachedConnections -> cachedConnections.getValue().close());
} finally {
cachedConnections.clear();
rootInvokeHook.finish(connectionSize);
}
}举个例子,比如Sharding-JDBC本身是不支持INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? 这种语法的,会报空指针异常。
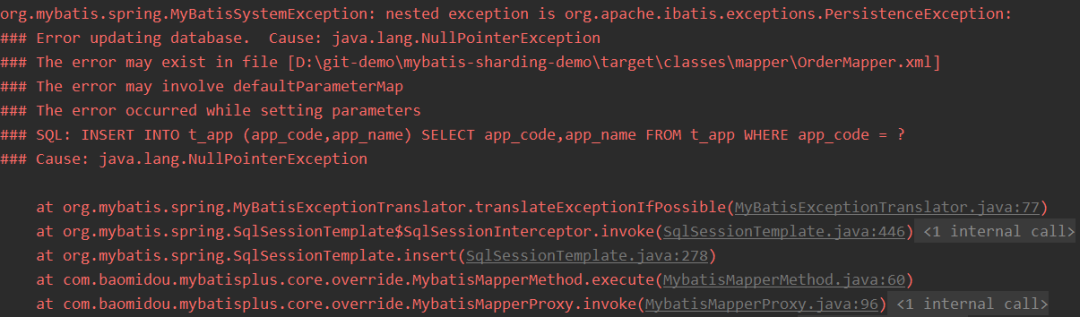
经过我们上述改造验证后,非分片表是可以跳过语法限制执行如下的SQL的。
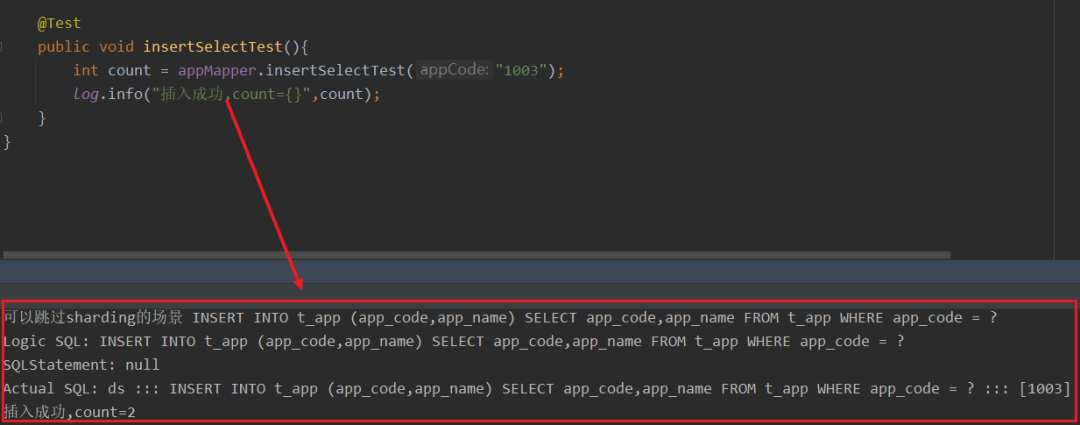
通过该功能的实现,业务可以更关注与分片表的SQL改造,而无需担心引入Sharding-JDBC造成所有SQL的验证改造,大幅减少改造成本和风险。
4.2 强制路由主库
Sharding-JDBC可以通过配置主从库数据源方便的实现读写分离的功能,但使用读写分离就必须面对主从延迟和从库失联的痛点,针对这一问题,我们实现了强制路由主库的动态配置,当主从延迟过大或从库失联时,通过修改配置来实现SQL语句强制走主库的不停机路由切换。
后面会说明了配置的动态生效的实现方式,这里只说明强制路由主库的实现,我们直接使用前文的RuleContextManager即可,在主从路由引擎里判断下是否开启了强制主库路由。
MasterSlaveRouteDecorator.decorate改造
org.apache.shardingsphere.masterslave.route.engine.MasterSlaveRouteDecorator#decorate
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final MasterSlaveRule masterSlaveRule, final ConfigurationProperties properties) {
/**
* 如果配置了强制主库 MasterVisitedManager设置为true
* 后续isMasterRoute中会保证路由至主库
*/
if(properties.<Boolean>getValue(ConfigurationPropertyKey.MASTER_ROUTE_ONLY)){
MasterVisitedManager.setMasterVisited();
}
//...路由逻辑
return routeContext;
}为了兼容之前跳过Sharding的功能,我们需要同步修改下isMasterRoute方法,如果是跳过了Sharding路由需要通过RuleContextManager来判断是否走主库。
isMasterRoute改造
org.apache.shardingsphere.masterslave.route.engine.impl.MasterSlaveDataSourceRouter#isMasterRoute
private boolean isMasterRoute(final SQLStatement sqlStatement) {
if(sqlStatement instanceof SkipShardingStatement){
// 优先以MasterVisitedManager中的值为准
return MasterVisitedManager.isMasterVisited()|| RuleContextManager.isMasterRoute();
}
return containsLockSegment(sqlStatement) || !(sqlStatement instanceof SelectStatement) || MasterVisitedManager.isMasterVisited() || HintManager.isMasterRouteOnly();
}当然,更理想的状况是通过监控主从同步延迟和数据库拨测,当超过阈值时或从库失联时直接自动修改配置中心的库,实现自动切换主库,减少业务故障时间和运维压力。
4.3 配置动态生效
Sharding-JDBC中的ConfigurationPropertyKey中提供了许多配置属性,而Sharding-JDBCB并没有为这些配置提供在线修改的方法,而在实际的应用场景中,像SQL_SHOW这样控制SQL打印的开关配置,我们更希望能够在线修改配置值来控制SQL日志的打印,而不是修改完配置再重启服务。
以SQL打印为例,BasePrepareEngine中存在ConfigurationProperties对象,通过调用getValue方法来获取SQL_SHOW的值。
SQL 打印
org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#prepare
/**
* Prepare to execute.
*
* @param sql SQL
* @param parameters SQL parameters
* @return execution context
*/
public ExecutionContext prepare(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
RouteContext routeContext = executeRoute(sql, clonedParameters);
ExecutionContext result = new ExecutionContext(routeContext.getSqlStatementContext());
result.getExecutionUnits().addAll(executeRewrite(sql, clonedParameters, routeContext));
//sql打印
if (properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
SQLLogger.logSQL(sql, properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE), result.getSqlStatementContext(), result.getExecutionUnits());
}
return result;
}ConfigurationProperties继承了抽象类TypedProperties,其getValue方法就是根据key获取对应的配置值,因此我们直接在TypedProperties中实现刷新缓存中的配置值的方法。
TypedProperties刷新配置
public abstract class TypedProperties<E extends Enum & TypedPropertyKey> {
private static final String LINE_SEPARATOR = System.getProperty("line.separator");
@Getter
private final Properties props;
private final Map<E, TypedPropertyValue> cache;
public TypedProperties(final Class<E> keyClass, final Properties props) {
this.props = props;
cache = preload(keyClass);
}
private Map<E, TypedPropertyValue> preload(final Class<E> keyClass) {
E[] enumConstants = keyClass.getEnumConstants();
Map<E, TypedPropertyValue> result = new HashMap<>(enumConstants.length, 1);
Collection<String> errorMessages = new LinkedList<>();
for (E each : enumConstants) {
TypedPropertyValue value = null;
try {
value = new TypedPropertyValue(each, props.getOrDefault(each.getKey(), each.getDefaultValue()).toString());
} catch (final TypedPropertyValueException ex) {
errorMessages.add(ex.getMessage());
}
result.put(each, value);
}
if (!errorMessages.isEmpty()) {
throw new ShardingSphereConfigurationException(Joiner.on(LINE_SEPARATOR).join(errorMessages));
}
return result;
}
/**
* Get property value.
*
* @param key property key
* @param <T> class type of return value
* @return property value
*/
@SuppressWarnings("unchecked")
public <T> T getValue(final E key) {
return (T) cache.get(key).getValue();
}
/**
* vivo定制改造方法 refresh property value.
* @param key property key
* @param value property value
* @return 更新配置是否成功
*/
public boolean refreshValue(String key, String value){
//获取配置类支持的配置项
E[] enumConstants = targetKeyClass.getEnumConstants();
for (E each : enumConstants) {
//遍历新的值
if(each.getKey().equals(key)){
try {
//空白value认为无效,取默认值
if(!StringUtils.isBlank(value)){
value = each.getDefaultValue();
}
//构造新属性
TypedPropertyValue typedPropertyValue = new TypedPropertyValue(each, value);
//替换缓存
cache.put(each, typedPropertyValue);
//原始属性也替换下,有可能会通过RuntimeContext直接获取Properties
props.put(key,value);
return true;
} catch (final TypedPropertyValueException ex) {
log.error("refreshValue error. key={} , value={}", key, value, ex);
}
}
}
return false;
}
}实现了刷新方法后,我们还需要将该方法一步步暴露至一个外部可以调用的类中,以便在服务监听配置的方法中,能够调用这个刷新方法。ConfigurationProperties直接在BasePrepareEngine的构造函数中传入,我们通过构造函数逐步反推最外层的这一对象调用来源,最终可以定位到在AbstractDataSourceAdapter中的getRuntimeContext()方法中可以获取到这个配置,而这个就是Sharding-JDBC实现的JDBC中Datasource接口的抽象类,我们直接在这个类中调用刚刚实现的refreshValue方法,剩下的就是监听配置,通过自己实现的AbstractDataSourceAdapter来调用这个方法就好了。
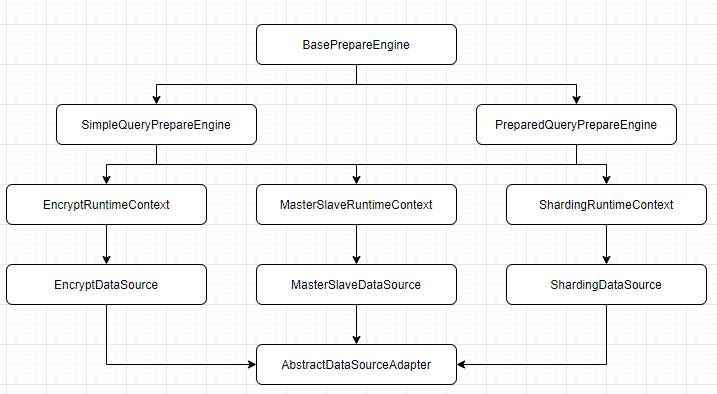
通过这一功能,我们可以方便的控制一些开关属性的在线修改,如SQL打印、强制路由主库等,业务无需重启服务即可做到配置的动态生效。
4.4 批量update语法支持
业务中存在使用foreach标签来批量update的语句,这种SQL在Sharding-JDBC中无法被正确路由,只会路由第一组参数,后面的无法被路由改写,原因是解析引擎无法将语句拆分解析。
批量update样例
<update id="batchUpdate">
<foreach collection="orderList" item="item">
update t_order set
status = 1,
updated_by = #{item.updatedBy}
WHERE created_by = #{item.createdBy};
</foreach>
</update>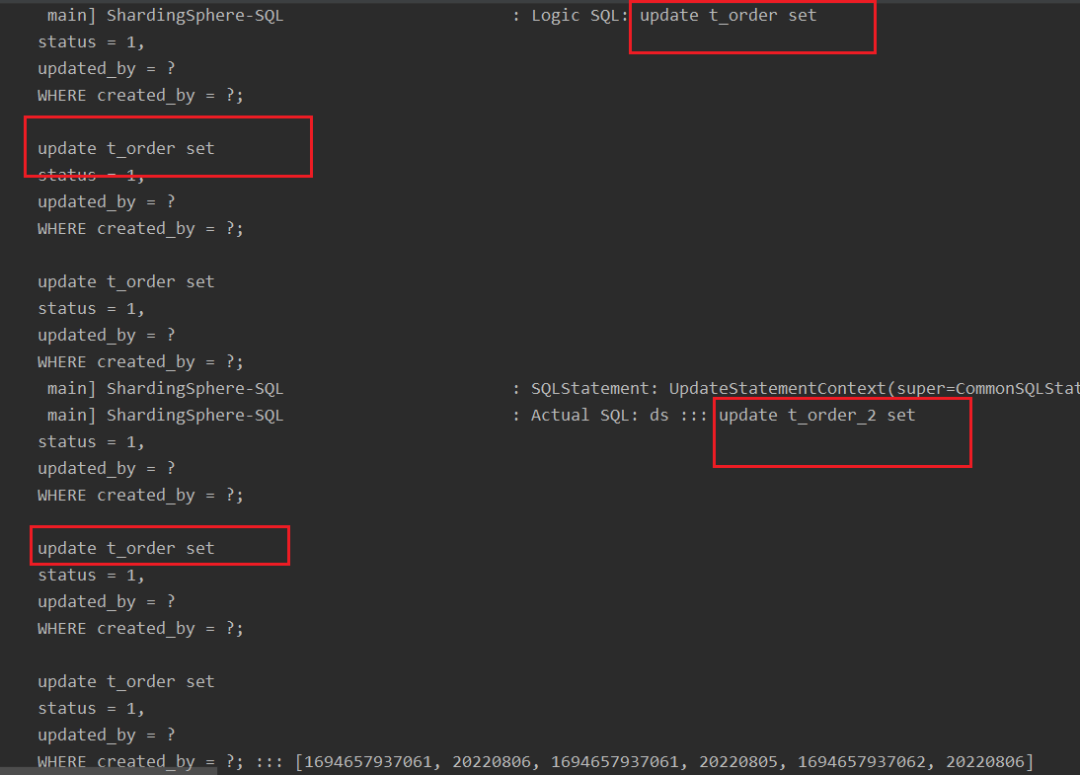
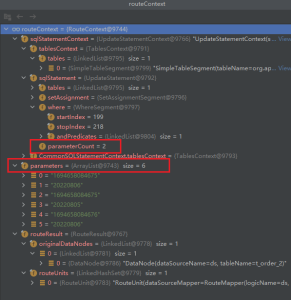
我们通过将批量update按照;拆分为多个语句,然后分别路由,最后手动汇总路有结果生成执行单元。
为了能正确重写SQL,批量update拆分后的语句需要完全一样,这样就不能使用动态拼接set条件,而是使用ifnull语法或者字段值不发生变化时也将原来的值放入set中,只不过set前后的值保持一致,整体思路与实现如下。
prepareBatch实现
org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#prepareBatch
private ExecutionContext prepareBatch(List<String> splitSqlList, final List<Object> allParameters) {
//SQL去重
List<String> sqlList = splitSqlList.stream().distinct().collect(Collectors.toList());
if (sqlList.size() > 1) {
throw new ShardingSphereException("不支持多条SQL,请检查SQL," + sqlList.toString());
}
//以第一条SQL为标准
String sql = sqlList.get(0);
//所有的执行单元
Collection<ExecutionUnit> globalExecutionUnitList = new ArrayList<>();
//初始化最后的执行结果
ExecutionContext executionContextResult = null;
//根据所有参数数量和SQL语句数量 计算每组参数的数量
int eachSqlParameterCount = allParameters.size() / splitSqlList.size();
//平均分配每条SQL的参数
List<List<Object>> eachSqlParameterListList = Lists.partition(allParameters, eachSqlParameterCount);
for (List<Object> eachSqlParameterList : eachSqlParameterListList) {
//每条SQL参数不同 需要根据参数路由不同的结果 实际的SqlStatementContext 是一致的
RouteContext routeContext = executeRoute(sql, eachSqlParameterList);
//由于SQL一样 实际的SqlStatementContext 是一致的 只需初始化一次
if (executionContextResult == null) {
executionContextResult = new ExecutionContext(routeContext.getSqlStatementContext());
}
globalExecutionUnitList.addAll(executeRewrite(sql, eachSqlParameterList, routeContext));
}
//排序打印日志
executionContextResult.getExtendMap().put(EXECUTION_UNIT_LIST, globalExecutionUnitList.stream().sorted(Comparator.comparing(ExecutionUnit::getDataSourceName)).collect(Collectors.toList()));
if (properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
SQLLogger.logSQL(sql, properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE),
executionContextResult.getSqlStatementContext(), (Collection<ExecutionUnit>) executionContextResult.getExtendMap().get(EXECUTION_UNIT_LIST));
}
return executionContextResult;
}这里我们在ExecutionContext单独构造了一个了ExtendMap来存放ExecutionUnit,原因是ExecutionContext中的executionUnits是HashSet,而判断ExecutionUnit中的SqlUnit只会根据SQL去重,批量update的SQL是一致的,但parameters不同,为了不影响原有的逻辑,单独使用了另外的变量来存放。
ExecutionContext改造
@RequiredArgsConstructor
@Getter
public class ExecutionContext {
private final SQLStatementContext sqlStatementContext;
private final Collection<ExecutionUnit> executionUnits = new LinkedHashSet<>();
/**
* 自定义扩展变量
*/
private final Map<ExtendEnum,Object> extendMap = new HashMap<>();
/**
* 定制扩展,是否可以跳过分片逻辑
*/
@Setter
private boolean skipShardingScenarioFlag = false;
}
@RequiredArgsConstructor
@Getter
@EqualsAndHashCode
@ToString
public final class ExecutionUnit {
private final String dataSourceName;
private final SQLUnit sqlUnit;
}
@AllArgsConstructor
@RequiredArgsConstructor
@Getter
@Setter
//根据SQL判断是否相等
@EqualsAndHashCode(of = { "sql" })
@ToString
public final class SQLUnit {
private String sql;
private final List<Object> parameters;
}我们还需要改造下执行方法,在初始化执行器的时候,判断下ExtendMap中存在我们自定义的EXECUTION_UNIT_LIST是否存在,存在则使用生成InputGroup,同一个数据源下的ExecutionUnit会被放入同一个InputGroup中。
InputGroup改造
org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#init
public void init(final ExecutionContext executionContext) throws SQLException {
setSqlStatementContext(executionContext.getSqlStatementContext());
//兼容批量update 分库分表后同一张表的情况 判断是否存在EXECUTION_UNIT_LIST 存在则使用未去重的List进行后续的操作
if (MapUtils.isNotEmpty(executionContext.getExtendMap())){
Collection<ExecutionUnit> executionUnitCollection = (Collection<ExecutionUnit>) executionContext.getExtendMap().get(EXECUTION_UNIT_LIST);
if(CollectionUtils.isNotEmpty(executionUnitCollection)){
getInputGroups().addAll(obtainExecuteGroups(executionUnitCollection));
}
}else {
getInputGroups().addAll(obtainExecuteGroups(executionContext.getExecutionUnits()));
}
cacheStatements();
}改造完成后,批量update中的每条SQL都可以被正确路由执行。
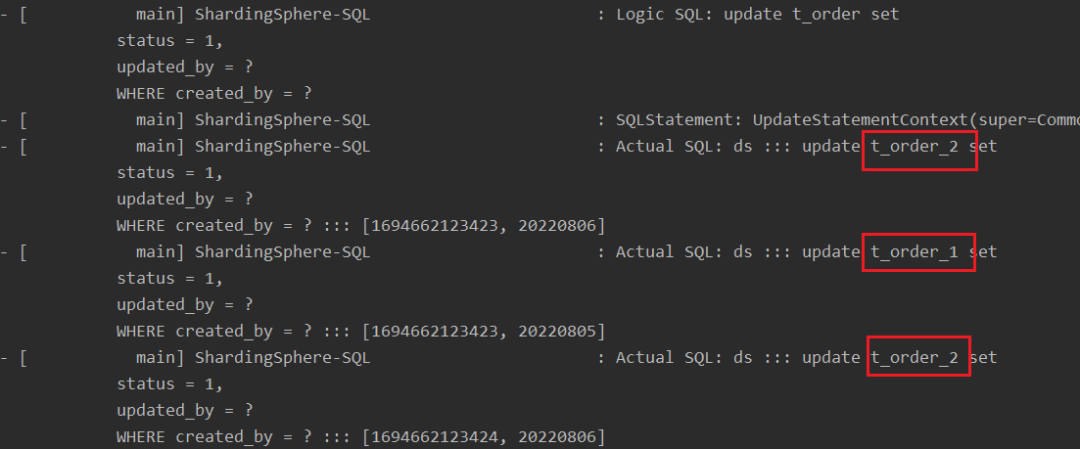
4.5 ShardingCondition去重
当where语句包括多个or条件时,而or条件不包含分片键时,会造成createShardingConditions方法生成重复的分片条件,导致重复调用doSharding方法。
如SELECT * FROM t_order WHERE created_by = ? and ( (status = ?) or (status = ?) or (status = ?) )这种SQL,存在三个or条件,分片键是created_by ,实际产生的shardingCondition会是三个一样的值,并会调用三次doSharding的方法。虽然实际执行还是只有一次(批量update那里说明过执行单元会去重),但为了减少方法的重复调用,我们还是对这里做了一次去重。
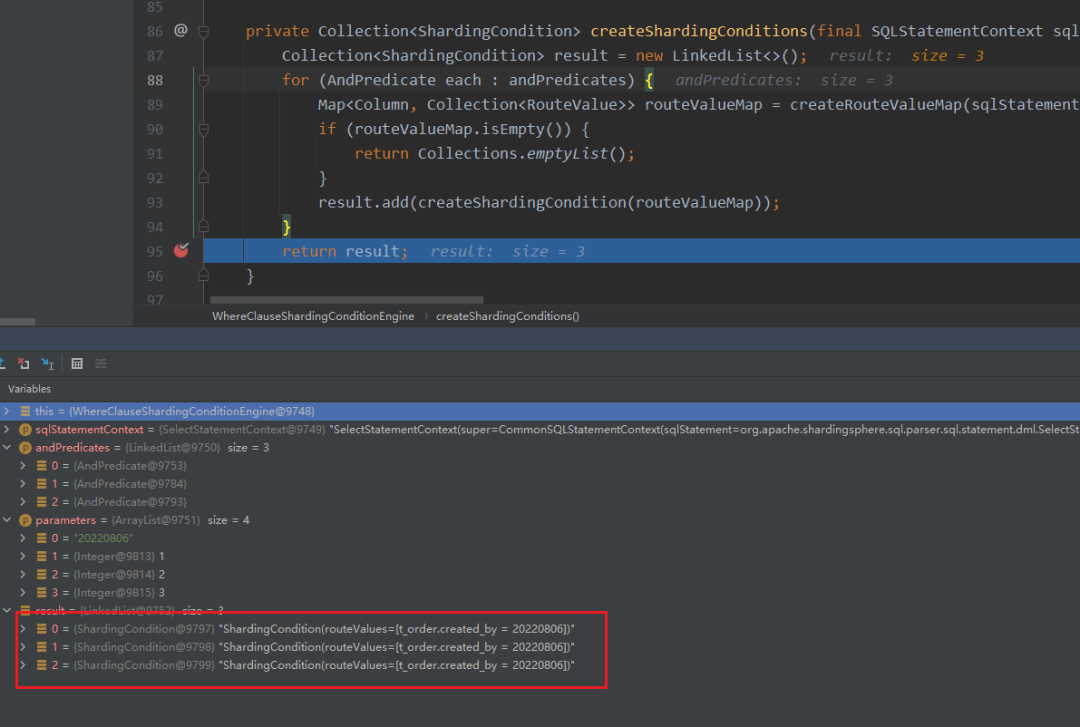
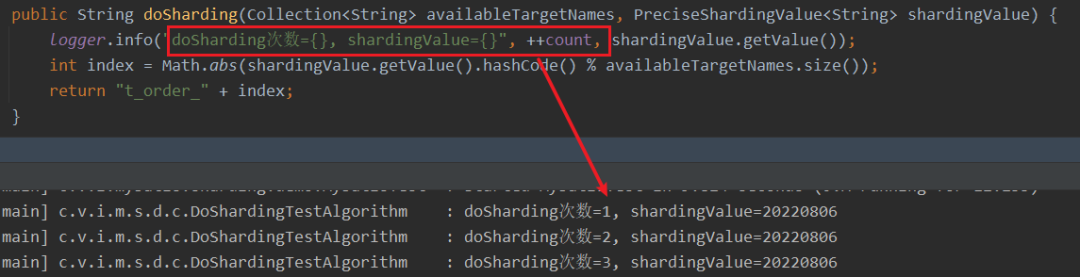
去重的方法也比较简单粗暴,我们对ListRouteValue和RangeRouteValue添加了@EqualsAndHashCode注解,然后在WhereClauseShardingConditionEngine的createShardingConditions方法返回最终结果前加一次去重,从而避免生成重复的shardingCondition造成doSharding方法的重复调用。
createShardingConditions去重
org.apache.shardingsphere.sharding.route.engine.condition.engine.WhereClauseShardingConditionEngine#createShardingConditions
private Collection<ShardingCondition> createShardingConditions(final SQLStatementContext sqlStatementContext, final Collection<AndPredicate> andPredicates, final List<Object> parameters) {
Collection<ShardingCondition> result = new LinkedList<>();
for (AndPredicate each : andPredicates) {
Map<Column, Collection<RouteValue>> routeValueMap = createRouteValueMap(sqlStatementContext, each, parameters);
if (routeValueMap.isEmpty()) {
return Collections.emptyList();
}
result.add(createShardingCondition(routeValueMap));
}
//去重
Collection<ShardingCondition> distinctResult = result.stream().distinct().collect(Collectors.toCollection(LinkedList::new));
return distinctResult;
}4.6 全路由校验
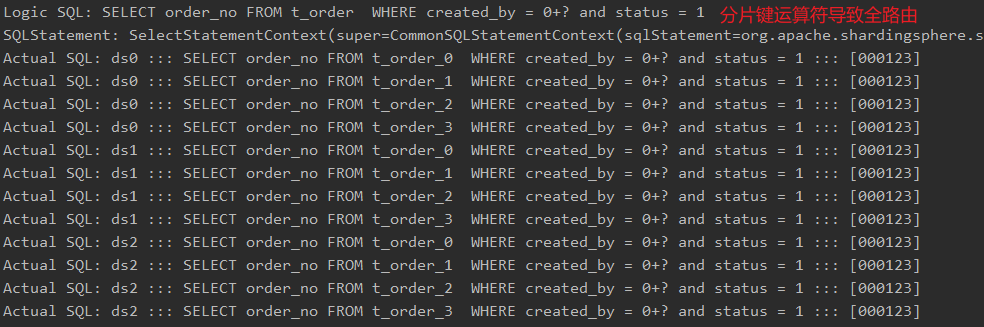
分片表的SQL中如果没有携带分片键(或者带上了分片键结果没有被正确解析)将会导致全路由,产生性能问题,而这种SQL并不会报错,这就导致在实际的业务改造中,开发和测试很难保证百分百改造彻底。为此,我们在源码层面对这种情况做了额外的校验,当产生全路由,也就是ShardingConditions为空时,主动抛出异常,从而方便开发和测试能够快速发现全路由SQL。
实现方式也比较简单,校验下ShardingConditions是否为空即可,只不过需要额外兼容下Hint策略ShardingConditions始终为空的特殊情况。
全路由校验
org.apache.shardingsphere.sharding.route.engine.ShardingRouteDecorator#decorate
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final ShardingRule shardingRule, final ConfigurationProperties properties) {
//省略...
//获取 ShardingConditions
ShardingConditions shardingConditions = getShardingConditions(parameters, sqlStatementContext, metaData.getSchema(), shardingRule);
boolean hintAlgorithm = isHintAlgorithm(sqlStatementContext, shardingRule);
//判断是否允许全路由
if (!properties.<Boolean>getValue(ConfigurationPropertyKey.ALLOW_EMPTY_SHARDING_CONDITIONS)) {
//如果不是Hint算法
if(!isHintAlgorithm(sqlStatementContext, shardingRule)){
/** 如果是DML语句 则可能有两种情况 这两种情况是根据getShardingConditions方法的内部逻辑而来的
* 一种是非插入语句 shardingConditions.getConditions()为空即可
* 一种是插入语句 插入语句shardingConditions.getConditions()不会为空 但是ShardingCondition的routeValues是空的
*/
if (sqlStatementContext.getSqlStatement() instanceof DMLStatement) {
if(shardingConditions.getConditions().isEmpty()) {
throw new ShardingSphereException("SQL不包含分库分表键,请检查SQL");
}else {
if (sqlStatementContext instanceof InsertStatementContext) {
List<ShardingCondition> routeValuesNotEmpty = shardingConditions.getConditions().stream().filter(r -> CollectionUtils.isNotEmpty(r.getRouteValues())).collect(Collectors.toList());
if(CollectionUtils.isEmpty(routeValuesNotEmpty)){
throw new ShardingSphereException("SQL不包含分库分表键,请检查SQL");
}
}
}
}
}
}
boolean needMergeShardingValues = isNeedMergeShardingValues(sqlStatementContext, shardingRule);
//省略...
return new RouteContext(sqlStatementContext, parameters, routeResult);
}
private boolean isHintAlgorithm(final SQLStatementContext sqlStatementContext, final ShardingRule shardingRule) {
// 场景a 全局默认策略是否使用强制路由策略
if(shardingRule.getDefaultDatabaseShardingStrategy() instanceof HintShardingStrategy
|| shardingRule.getDefaultTableShardingStrategy() instanceof HintShardingStrategy){
return true;
}
for (String each : sqlStatementContext.getTablesContext().getTableNames()) {
Optional<TableRule> tableRule = shardingRule.findTableRule(each);
//场景b 指定表是否使用强制路由策略
if (tableRule.isPresent() && (shardingRule.getDatabaseShardingStrategy(tableRule.get()) instanceof HintShardingStrategy
|| shardingRule.getTableShardingStrategy(tableRule.get()) instanceof HintShardingStrategy)) {
return true;
}
}
return false;
}当然这块功能也可以在完善些,比如对分片路由结果中的数据源数量进行校验,从而避免跨库操作,我们这边没有实现也就不再赘述了。
4.7 组件封装
业务接入Sharding-JDBC的步骤是一样的,都需要通过Java创建数据源和配置对象或者使用SpringBoot进行配置,存在一定的熟悉成本和重复开发的问题,为此我们也对定制开发版本的Sharding-JDBC封装了一个公共组件,从而简化业务配置,减少重复开发,提升业务的开发效率,具体功能可见下。这块没有涉及源码的改造,只是在定制版本上包装的一个公共组件。
提供了默认的数据源与连接池配置
简化分库分表配置,业务配置逻辑表名和后缀,组件拼装行表达式和actual-data-nodes
封装常用的分片算法(时间、业务字段值等),
统一的配置监听与动态修改(SQL打印、强制主从切换等)
开源Sharding-JDBC配置
//数据源名称
spring.shardingsphere.datasource.names=ds0,ds1
//ds0配置
spring.shardingsphere.datasource.ds0.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=
//ds1配置
spring.shardingsphere.datasource.ds1.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=
//分表规则
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
//默认分库规则
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}组件简化配置
//数据源名称
vivo.it.sharding.datasource.names = ds0,ds1
//ds0配置
vivo.it.sharding.datasource.ds0.url = jdbc:mysql://localhost:3306/ds1
vivo.it.sharding.datasource.ds0.username = root
vivo.it.sharding.datasource.ds0.password =
//ds1配置
vivo.it.sharding.datasource.ds1.url = jdbc:mysql://localhost:3306/ds1
vivo.it.sharding.datasource.ds1.username = root
vivo.it.sharding.datasource.ds1.password =
//分表规则
vivo.it.sharding.table.rule.config = [{"logicTable":"t_order,t_order_item","tableRange":"0..1","shardingColumn":"order_id ","algorithmExpression":"order_id %2"}]
//默认分库规则
vivo.it.sharding.default.db.rule.config = {"shardingColumn":"user_id","algorithmExpression":"user_id %2"}五、使用建议
结合官方文档和业务实践经验,我们也梳理了部分使用Sharding-JDBC的建议供大家参考,实际具体如何优化SQL写法(比如子查询、分页、分组排序等)还需要结合业务的实际场景来进行测试和调优。
(1)强制等级
建议①:涉及分片表的SQL必须携带分片键
原因:无分片键会导致全路由,存在严重的性能隐患
建议②:禁止一条SQL中的分片值路由至不同的库
原因:跨库操作存在严重的性能隐患,事务操作会升级为分布式事务,增加业务复杂度
建议③:禁止对分片键使用运算表达式或函数操作
原因:无法提前计算表达式和函数获取分片值,导致全路由
说明:
详见官方文档
- 建议④:禁止在子查询中使用分片表
原因:无法正常解析子查询中的分片表,导致业务错误
说明:虽然
官方文档中说有限支持子查询
,但在实际的使用中发现4.1.1并不支持子查询,可见官方
issue6164
|
issue 6228
。

- 建议⑤:包含CASE WHEN、HAVING、UNION (ALL)语法的分片SQL,不支持路由至多数据节点
说明:
详见官方文档
(2)建议等级
① 建议使用分布式id来保证分片表主键的全局唯一性
原因:方便判断数据的唯一性和后续的迁移扩容
② 建议跨多表的分组SQL的分组字段与排序字段保证一致
原因:分组和排序字段不一致只能通过内存合并,大数据量时存在性能隐患
说明:
详见官方文档③ 建议通过全局递增的分布式id来优化分页查询
原因:Sharding-JDBC的分页优化侧重于结果集的流式合并来避免内存爆涨,但深度分页自身的性能问题并不能解决
说明:
详见官方文档
六、总结
本文结合个人理解梳理了各个引擎的源码入口和关键逻辑,读者可以结合本文和官方文档更好的定位理解Sharding-JDBC的源码实现。
定制开发的目的是为了降低业务接入成本
,尽可能减少业务存量SQL的改造,部分改造思想其实与官方社区也存在差异,比如跳过语法解析,官方社区致力于通过优化解析引擎来适配各种语法,而不是跳过解析阶段,可参考官方
issue
。源码分析和定制改造只涉及了Sharding-JDBC的数据分片和读写分离功能,定制开发的功能也在生产环境经过了考验,如有不足和优化建议,也欢迎大家批评指正。