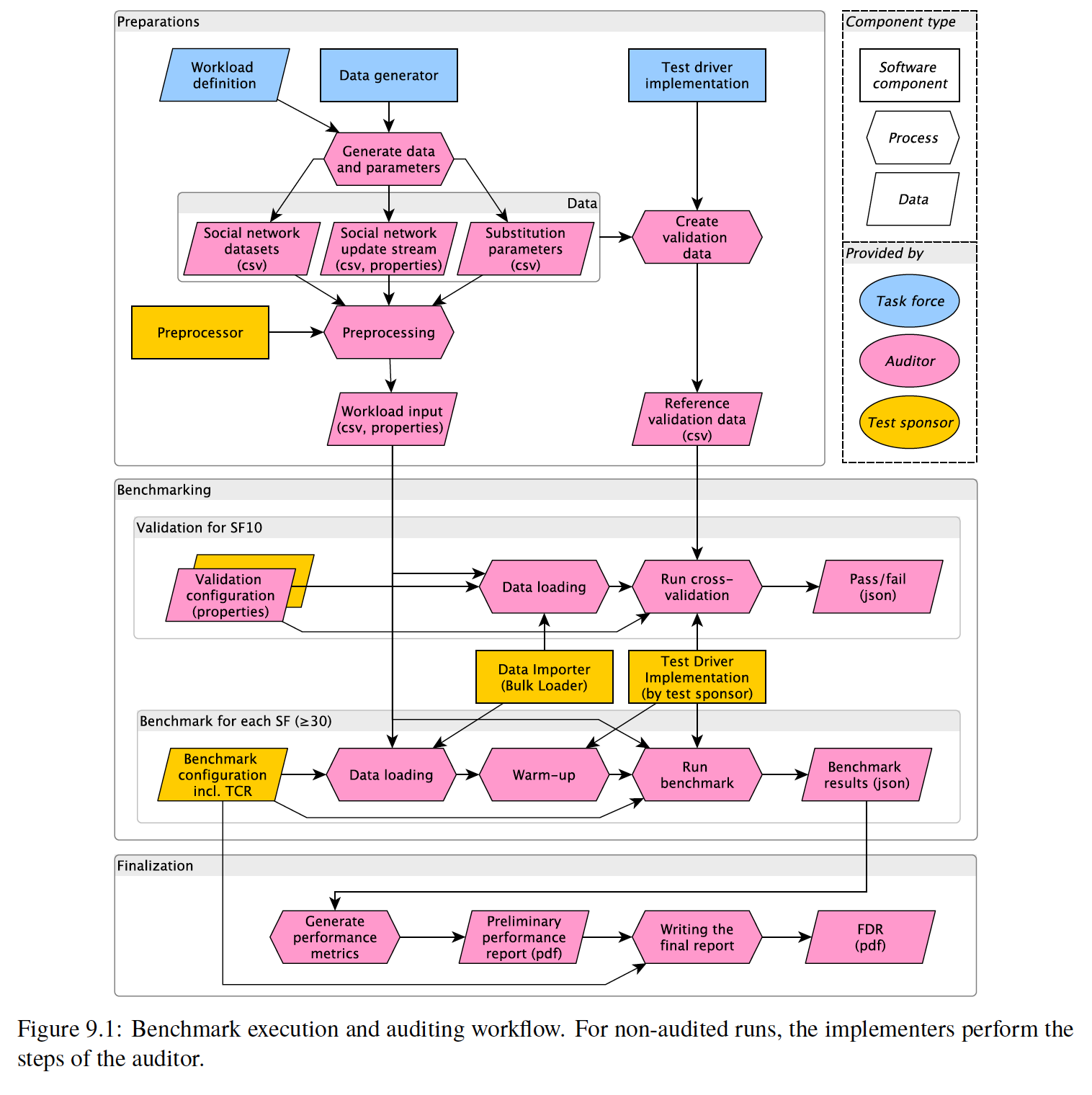
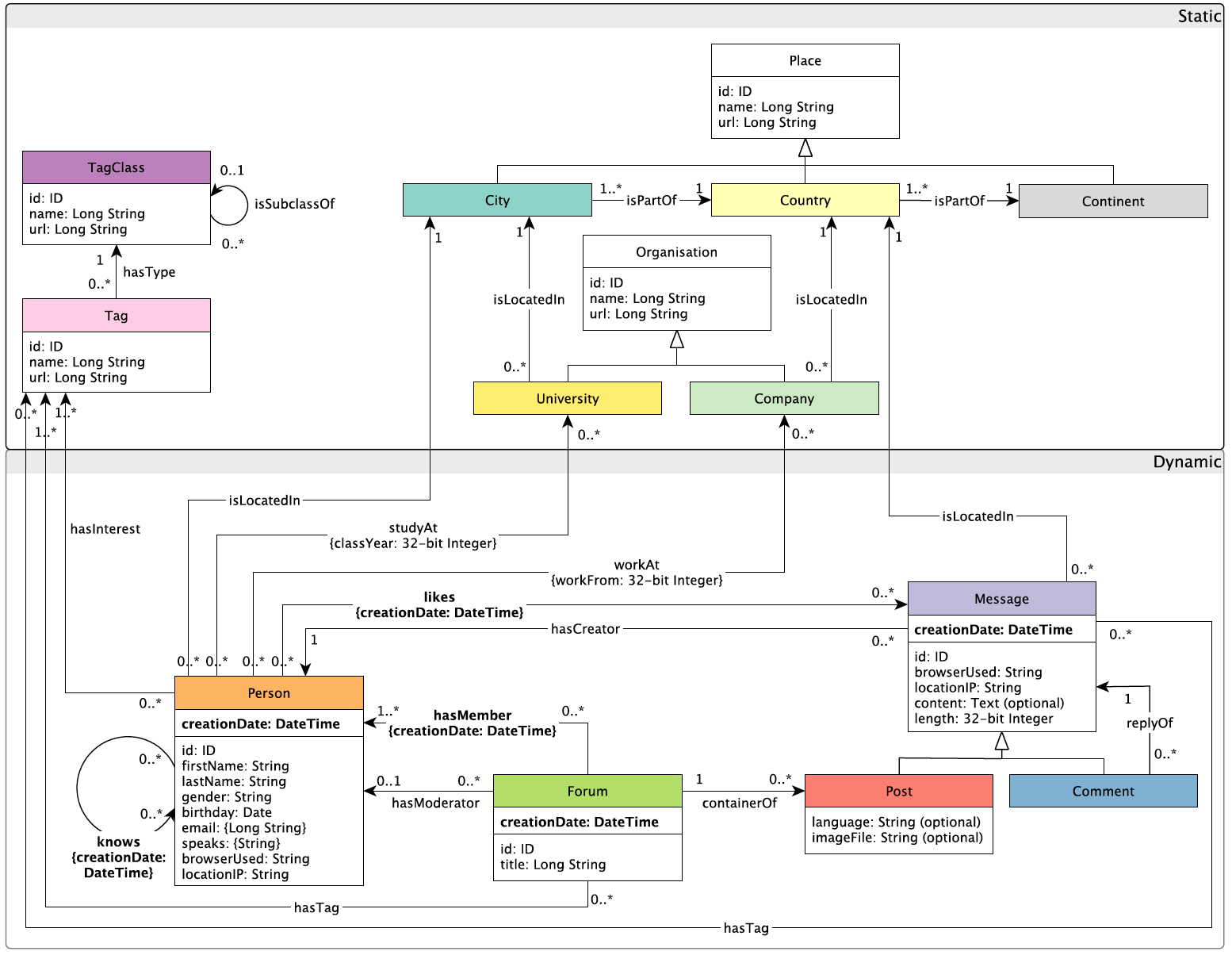
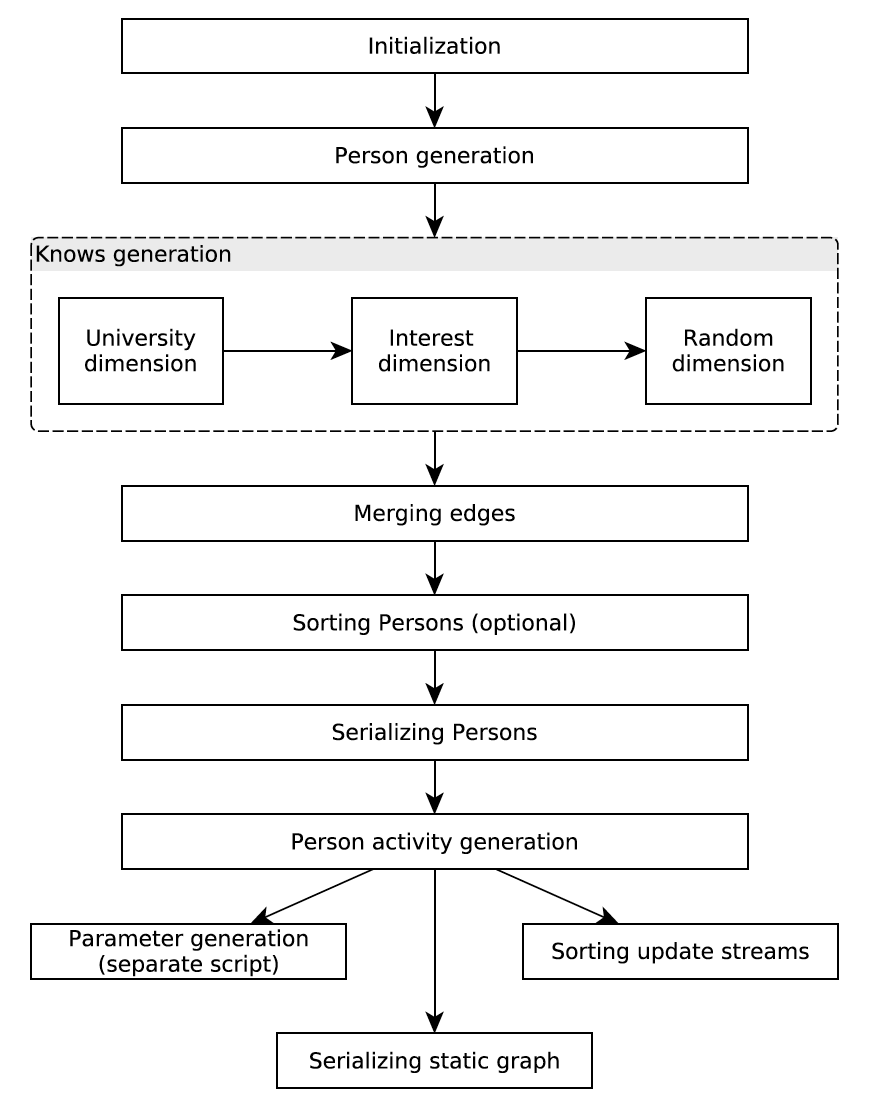
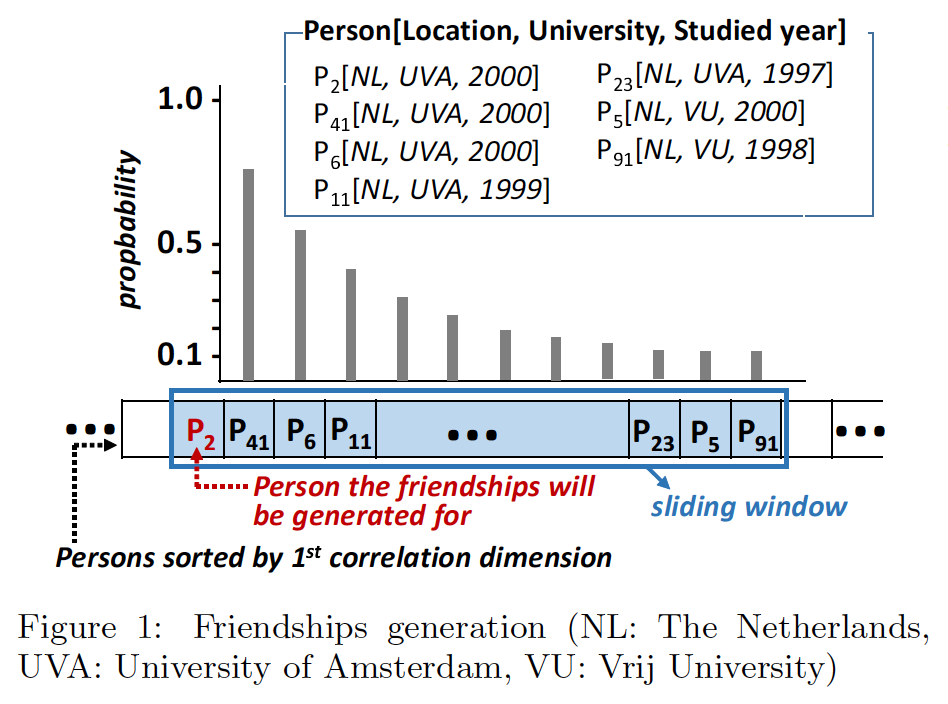
building-a-simple-redis-server-with-python
前几天我想到,写一个简单的东西会很整洁
雷迪斯
-像数据库服务器。虽然我有很多 WSGI应用程序的经验,数据库服务器展示了一种新颖 挑战,并被证明是学习如何工作的不错的实际方法 Python中的套接字。在这篇文章中,我将分享我在此过程中学到的知识。
我项目的目的是
编写一个简单的服务器
我可以用 我的任务队列项目称为
Huey
。 Huey使用Redis作为默认存储引擎来跟踪被引用的工作, 完成的工作和其他结果。就本职位而言, 我进一步缩小了原始项目的范围,以免造成混乱 使用代码的水域,您可以很容易地自己写,但是如果您 很好奇,你可以看看
最终结果 这里
(
文件
)。
我们将要构建的服务器将能够响应以下命令:
- GET
<key>
- SET
<key>
<value>
- DELETE
<key>
- FLUSH
- MGET
<key1>
...
<keyn>
- MSET
<key1>
<value1>
...
<keyn>
<valuen>
我们还将支持以下数据类型:
- Strings
and
Binary Data
- Numbers
- NULL
- Arrays (which may be nested)
- Dictionaries (which may be nested)
- Error messages
为了异步处理多个客户端,我们将使用
gevent
, 但是您也可以使用标准库的
SocketServer
模块与 要么
ForkingMixin
或
ThreadingMixin
。
骨架
让我们为服务器设置一个框架。我们需要服务器本身,以及 新客户端连接时要执行的回调。另外,我们需要 某种逻辑来处理客户端请求并发送响应。
这是一个开始:
from gevent import socket
from gevent.pool import Pool
from gevent.server import StreamServer
from collections import namedtuple
from io import BytesIO
from socket import error as socket_error
# We'll use exceptions to notify the connection-handling loop of problems.
class CommandError(Exception): pass
class Disconnect(Exception): pass
Error = namedtuple('Error', ('message',))
class ProtocolHandler(object):
def handle_request(self, socket_file):
# Parse a request from the client into it's component parts.
pass
def write_response(self, socket_file, data):
# Serialize the response data and send it to the client.
pass
class Server(object):
def __init__(self, host='127.0.0.1', port=31337, max_clients=64):
self._pool = Pool(max_clients)
self._server = StreamServer(
(host, port),
self.connection_handler,
spawn=self._pool)
self._protocol = ProtocolHandler()
self._kv = {}
def connection_handler(self, conn, address):
# Convert "conn" (a socket object) into a file-like object.
socket_file = conn.makefile('rwb')
# Process client requests until client disconnects.
while True:
try:
data = self._protocol.handle_request(socket_file)
except Disconnect:
break
try:
resp = self.get_response(data)
except CommandError as exc:
resp = Error(exc.args[0])
self._protocol.write_response(socket_file, resp)
def get_response(self, data):
# Here we'll actually unpack the data sent by the client, execute the
# command they specified, and pass back the return value.
pass
def run(self):
self._server.serve_forever()
希望以上代码相当清楚。我们已经分开了担忧,以便 协议处理属于自己的类,有两种公共方法:
handle_request
和
write_response
。服务器本身使用协议 处理程序解压缩客户端请求并将服务器响应序列化回 客户。The
get_response()
该方法将用于执行命令 由客户发起。
仔细查看代码
connection_handler()
方法,你可以 看到我们在套接字对象周围获得了类似文件的包装纸。这个包装器 让我们抽象一些
怪癖
通常会遇到使用原始插座的情况。函数输入 无穷循环,读取客户端的请求,发送响应,最后 客户端断开连接时退出循环(由
read()
返回 一个空字符串)。
我们使用键入的异常来处理客户端断开连接并通知用户 错误处理命令。例如,如果用户做错了 对服务器的格式化请求,我们将提出一个
CommandError
, 哪个是 序列化为错误响应并发送给客户端。
在继续之前,让我们讨论客户端和服务器将如何通信。
线程
我面临的第一个挑战是如何处理通过 线。我在网上找到的大多数示例都是毫无意义的回声服务器,它们进行了转换 套接字到类似文件的对象,并且刚刚调用
readline()
。如果我想 用新线存储一些腌制的数据或字符串,我需要一些 一种序列化格式。
在浪费时间尝试发明合适的东西之后,我决定阅读 有关文档
Redis协议
, 其中 事实证明实施起来非常简单,并且具有 支持几种不同的数据类型。
Redis协议使用请求/响应通信模式与 客户。来自服务器的响应将使用第一个字节来指示 数据类型,然后是数据,以回车/线路进给终止。

让我们填写协议处理程序的类,使其实现Redis 协议。
class ProtocolHandler(object):
def __init__(self):
self.handlers = {
'+': self.handle_simple_string,
'-': self.handle_error,
':': self.handle_integer,
'$': self.handle_string,
'*': self.handle_array,
'%': self.handle_dict}
def handle_request(self, socket_file):
first_byte = socket_file.read(1)
if not first_byte:
raise Disconnect()
try:
# Delegate to the appropriate handler based on the first byte.
return self.handlers[first_byte](socket_file)
except KeyError:
raise CommandError('bad request')
def handle_simple_string(self, socket_file):
return socket_file.readline().rstrip('\r\n')
def handle_error(self, socket_file):
return Error(socket_file.readline().rstrip('\r\n'))
def handle_integer(self, socket_file):
return int(socket_file.readline().rstrip('\r\n'))
def handle_string(self, socket_file):
# First read the length ($<length>\r\n).
length = int(socket_file.readline().rstrip('\r\n'))
if length == -1:
return None # Special-case for NULLs.
length += 2 # Include the trailing \r\n in count.
return socket_file.read(length)[:-2]
def handle_array(self, socket_file):
num_elements = int(socket_file.readline().rstrip('\r\n'))
return [self.handle_request(socket_file) for _ in range(num_elements)]
def handle_dict(self, socket_file):
num_items = int(socket_file.readline().rstrip('\r\n'))
elements = [self.handle_request(socket_file)
for _ in range(num_items * 2)]
return dict(zip(elements[::2], elements[1::2]))
对于协议的序列化方面,我们将执行与上述相反的操作: 将Python对象转换为序列化的对象!
class ProtocolHandler(object):
# ... above methods omitted ...
def write_response(self, socket_file, data):
buf = BytesIO()
self._write(buf, data)
buf.seek(0)
socket_file.write(buf.getvalue())
socket_file.flush()
def _write(self, buf, data):
if isinstance(data, str):
data = data.encode('utf-8')
if isinstance(data, bytes):
buf.write('$%s\r\n%s\r\n' % (len(data), data))
elif isinstance(data, int):
buf.write(':%s\r\n' % data)
elif isinstance(data, Error):
buf.write('-%s\r\n' % error.message)
elif isinstance(data, (list, tuple)):
buf.write('*%s\r\n' % len(data))
for item in data:
self._write(buf, item)
elif isinstance(data, dict):
buf.write('%%%s\r\n' % len(data))
for key in data:
self._write(buf, key)
self._write(buf, data[key])
elif data is None:
buf.write('$-1\r\n')
else:
raise CommandError('unrecognized type: %s' % type(data))
将协议处理保持在其自己的类中的另一个好处是 我们可以重复使用
handle_request
和
write_response
建立方法 客户端库。
执行命令
类
Server
我们模拟的课程现在需要
get_response()
方法 已实施。命令将假定由客户端以简单方式发送 字符串或命令参数数组,因此
data
传递给
get_response()
将是字节或列表。为了简化处理,如果
data
这是一个简单的字符串,我们将通过拆分将其转换为列表 空格。
第一个参数将是命令名称,并带有任何其他参数 属于指定命令。就像我们对第一个的映射一样 字节给处理者
ProtocolHandler
, 让我们创建一个的映射 命令回调
Server
:
class Server(object):
def __init__(self, host='127.0.0.1', port=31337, max_clients=64):
self._pool = Pool(max_clients)
self._server = StreamServer(
(host, port),
self.connection_handler,
spawn=self._pool)
self._protocol = ProtocolHandler()
self._kv = {}
self._commands = self.get_commands()
def get_commands(self):
return {
'GET': self.get,
'SET': self.set,
'DELETE': self.delete,
'FLUSH': self.flush,
'MGET': self.mget,
'MSET': self.mset}
def get_response(self, data):
if not isinstance(data, list):
try:
data = data.split()
except:
raise CommandError('Request must be list or simple string.')
if not data:
raise CommandError('Missing command')
command = data[0].upper()
if command not in self._commands:
raise CommandError('Unrecognized command: %s' % command)
return self._commands[command](*data[1:])
我们的服务器快完成了! 我们只需要执行六个命令 在
get_commands()
方法:
class Server(object):
def get(self, key):
return self._kv.get(key)
def set(self, key, value):
self._kv[key] = value
return 1
def delete(self, key):
if key in self._kv:
del self._kv[key]
return 1
return 0
def flush(self):
kvlen = len(self._kv)
self._kv.clear()
return kvlen
def mget(self, *keys):
return [self._kv.get(key) for key in keys]
def mset(self, *items):
data = zip(items[::2], items[1::2])
for key, value in data:
self._kv[key] = value
return len(data)
而已! 我们的服务器现在可以开始处理请求了。在下一个 本节,我们将实现一个客户端与服务器进行交互。
客户端
要与服务器交互,让我们重新使用
ProtocolHandler
类到 实现一个简单的客户端。客户端将连接到服务器并发送 命令编码为列表。我们将同时使用
write_response()
和
handle_request()
编码请求和处理服务器响应的逻辑 分别。
class Client(object):
def __init__(self, host='127.0.0.1', port=31337):
self._protocol = ProtocolHandler()
self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self._socket.connect((host, port))
self._fh = self._socket.makefile('rwb')
def execute(self, *args):
self._protocol.write_response(self._fh, args)
resp = self._protocol.handle_request(self._fh)
if isinstance(resp, Error):
raise CommandError(resp.message)
return resp
与
execute()
方法上,我们可以传递任意参数列表,这些参数将被编码为数组并发送到服务器。来自服务器的响应被解析并作为Python对象返回。为了方便起见,我们可以为各个命令编写客户端方法:
class Client(object):
# ...
def get(self, key):
return self.execute('GET', key)
def set(self, key, value):
return self.execute('SET', key, value)
def delete(self, key):
return self.execute('DELETE', key)
def flush(self):
return self.execute('FLUSH')
def mget(self, *keys):
return self.execute('MGET', *keys)
def mset(self, *items):
return self.execute('MSET', *items)
为了测试我们的客户端,让我们配置Python脚本以启动服务器 直接从命令行执行时:
测试服务器
要测试服务器,只需从命令行执行服务器的Python模块即可。在另一个终端中,打开Python解释器并导入
Client
来自服务器模块的类。安装客户端将打开连接,您可以开始运行命令!
>>> from server_ex import Client
>>> client = Client()
>>> client.mset('k1', 'v1', 'k2', ['v2-0', 1, 'v2-2'], 'k3', 'v3')
3
>>> client.get('k2')
['v2-0', 1, 'v2-2']
>>> client.mget('k3', 'k1')
['v3', 'v1']
>>> client.delete('k1')
1
>>> client.get('k1')
>>> client.delete('k1')
0
>>> client.set('kx', {'vx': {'vy': 0, 'vz': [1, 2, 3]}})
1
>>> client.get('kx')
{'vx': {'vy': 0, 'vz': [1, 2, 3]}}
>>> client.flush()
2
完整代码
from gevent import socket
from gevent.pool import Pool
from gevent.server import StreamServer
from collections import namedtuple
from io import BytesIO
from socket import error as socket_error
import logging
logger = logging.getLogger(__name__)
class CommandError(Exception): pass
class Disconnect(Exception): pass
Error = namedtuple('Error', ('message',))
class ProtocolHandler(object):
def __init__(self):
self.handlers = {
'+': self.handle_simple_string,
'-': self.handle_error,
':': self.handle_integer,
'$': self.handle_string,
'*': self.handle_array,
'%': self.handle_dict}
def handle_request(self, socket_file):
first_byte = socket_file.read(1)
if not first_byte:
raise Disconnect()
try:
# Delegate to the appropriate handler based on the first byte.
return self.handlers[first_byte](socket_file)
except KeyError:
raise CommandError('bad request')
def handle_simple_string(self, socket_file):
return socket_file.readline().rstrip('\r\n')
def handle_error(self, socket_file):
return Error(socket_file.readline().rstrip('\r\n'))
def handle_integer(self, socket_file):
return int(socket_file.readline().rstrip('\r\n'))
def handle_string(self, socket_file):
# First read the length ($<length>\r\n).
length = int(socket_file.readline().rstrip('\r\n'))
if length == -1:
return None # Special-case for NULLs.
length += 2 # Include the trailing \r\n in count.
return socket_file.read(length)[:-2]
def handle_array(self, socket_file):
num_elements = int(socket_file.readline().rstrip('\r\n'))
return [self.handle_request(socket_file) for _ in range(num_elements)]
def handle_dict(self, socket_file):
num_items = int(socket_file.readline().rstrip('\r\n'))
elements = [self.handle_request(socket_file)
for _ in range(num_items * 2)]
return dict(zip(elements[::2], elements[1::2]))
def write_response(self, socket_file, data):
buf = BytesIO()
self._write(buf, data)
buf.seek(0)
socket_file.write(buf.getvalue())
socket_file.flush()
def _write(self, buf, data):
if isinstance(data, str):
data = data.encode('utf-8')
if isinstance(data, bytes):
buf.write('$%s\r\n%s\r\n' % (len(data), data))
elif isinstance(data, int):
buf.write(':%s\r\n' % data)
elif isinstance(data, Error):
buf.write('-%s\r\n' % error.message)
elif isinstance(data, (list, tuple)):
buf.write('*%s\r\n' % len(data))
for item in data:
self._write(buf, item)
elif isinstance(data, dict):
buf.write('%%%s\r\n' % len(data))
for key in data:
self._write(buf, key)
self._write(buf, data[key])
elif data is None:
buf.write('$-1\r\n')
else:
raise CommandError('unrecognized type: %s' % type(data))
class Server(object):
def __init__(self, host='127.0.0.1', port=31337, max_clients=64):
self._pool = Pool(max_clients)
self._server = StreamServer(
(host, port),
self.connection_handler,
spawn=self._pool)
self._protocol = ProtocolHandler()
self._kv = {}
self._commands = self.get_commands()
def get_commands(self):
return {
'GET': self.get,
'SET': self.set,
'DELETE': self.delete,
'FLUSH': self.flush,
'MGET': self.mget,
'MSET': self.mset}
def connection_handler(self, conn, address):
logger.info('Connection received: %s:%s' % address)
# Convert "conn" (a socket object) into a file-like object.
socket_file = conn.makefile('rwb')
# Process client requests until client disconnects.
while True:
try:
data = self._protocol.handle_request(socket_file)
except Disconnect:
logger.info('Client went away: %s:%s' % address)
break
try:
resp = self.get_response(data)
except CommandError as exc:
logger.exception('Command error')
resp = Error(exc.args[0])
self._protocol.write_response(socket_file, resp)
def run(self):
self._server.serve_forever()
def get_response(self, data):
if not isinstance(data, list):
try:
data = data.split()
except:
raise CommandError('Request must be list or simple string.')
if not data:
raise CommandError('Missing command')
command = data[0].upper()
if command not in self._commands:
raise CommandError('Unrecognized command: %s' % command)
else:
logger.debug('Received %s', command)
return self._commands[command](*data[1:])
def get(self, key):
return self._kv.get(key)
def set(self, key, value):
self._kv[key] = value
return 1
def delete(self, key):
if key in self._kv:
del self._kv[key]
return 1
return 0
def flush(self):
kvlen = len(self._kv)
self._kv.clear()
return kvlen
def mget(self, *keys):
return [self._kv.get(key) for key in keys]
def mset(self, *items):
data = zip(items[::2], items[1::2])
for key, value in data:
self._kv[key] = value
return len(data)
class Client(object):
def __init__(self, host='127.0.0.1', port=31337):
self._protocol = ProtocolHandler()
self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self._socket.connect((host, port))
self._fh = self._socket.makefile('rwb')
def execute(self, *args):
self._protocol.write_response(self._fh, args)
resp = self._protocol.handle_request(self._fh)
if isinstance(resp, Error):
raise CommandError(resp.message)
return resp
def get(self, key):
return self.execute('GET', key)
def set(self, key, value):
return self.execute('SET', key, value)
def delete(self, key):
return self.execute('DELETE', key)
def flush(self):
return self.execute('FLUSH')
def mget(self, *keys):
return self.execute('MGET', *keys)
def mset(self, *items):
return self.execute('MSET', *items)
if __name__ == '__main__':
from gevent import monkey; monkey.patch_all()
logger.addHandler(logging.StreamHandler())
logger.setLevel(logging.DEBUG)
Server().run()
各位看官,如对你有帮助欢迎点赞,收藏,转发,关注公众号【Python魔法师】获取更多Python魔法知识~