图数据库基准测试 LDBC SNB 系列讲解:Schema 和数据生成的机制

LDBC(Linked Data Benchmark Council)Social Network Benchmark,简称 LDBC SNB,是一种针对社交网络场景的评估图数据库性能的基准测试。
LDBC 简介
除了 Social Network Benchmark,LDBC 旗下目前还有其他几种基准测试:Graphalytics Benchmark,Financial Benchmark 和 Semantic Publish Benchmark,分别针对图分析、金融和 RDF 的场景。Social Network Benchmark 是 LDBC 最早的提出的基准测试,已经成为国内外最主流的图数据库基准测试,在国内很多图数据库招标也会将 LDBC SNB 作为性能测试的一项。但需要说明的是,LDBC 本身作为一个非盈利组织,只提供官方审计。
不同图数据库可能受到运行环境以及基准测试的相关参数影响,因此测试结果的横向对比没有任何意义
。
LDBC SNB 主要包括三个主要部分:
- Data Generator
:这是一个数据生成工具,用于生成具有社交网络特性的大规模复杂数据。这些数据包括人、帖子、评论、地理位置、组织和其他一些社交网络的典型实体和关系。 - Interactive Workload
:主要针对 OLTP,模拟了用户在社交网络上的日常活动,例如发布帖子、添加好友、点赞等。读请求以查询以一到两跳为主,同时可能会伴随一些写请求。 - Business Intelligence Workload
:主要针对 OLAP,模拟了对社交网络数据进行深入分析,以全图查询为主。例如分析用户的社交行为、社区的形成和演变,以及其他一些需要复杂分析和大量数据处理的任务。
LDBC SNB
的论文里还提到了一个 SNB Algorithms,顾名思义主要是跑图算法的,如 PageRank、社区发现、广度搜索等。但论文是 2015 年发表的,当时描述这个场景还在起草中,目前已经将这部分移到了 Graphalytics Benchmark。
此外,想要运行 LDBC SNB 测试,还需要一个官方提供的 Driver。不同的数据库需要基于 Driver 的接口实现相应的 Connector,用来连接 Driver 和数据库。之后 Driver 会根据 Benchmark 的相关参数生成 Workload(这里可以理解为一系列的查询语句),并驱动待测数据库执行这些查询语句,最终得到性能测试结果。
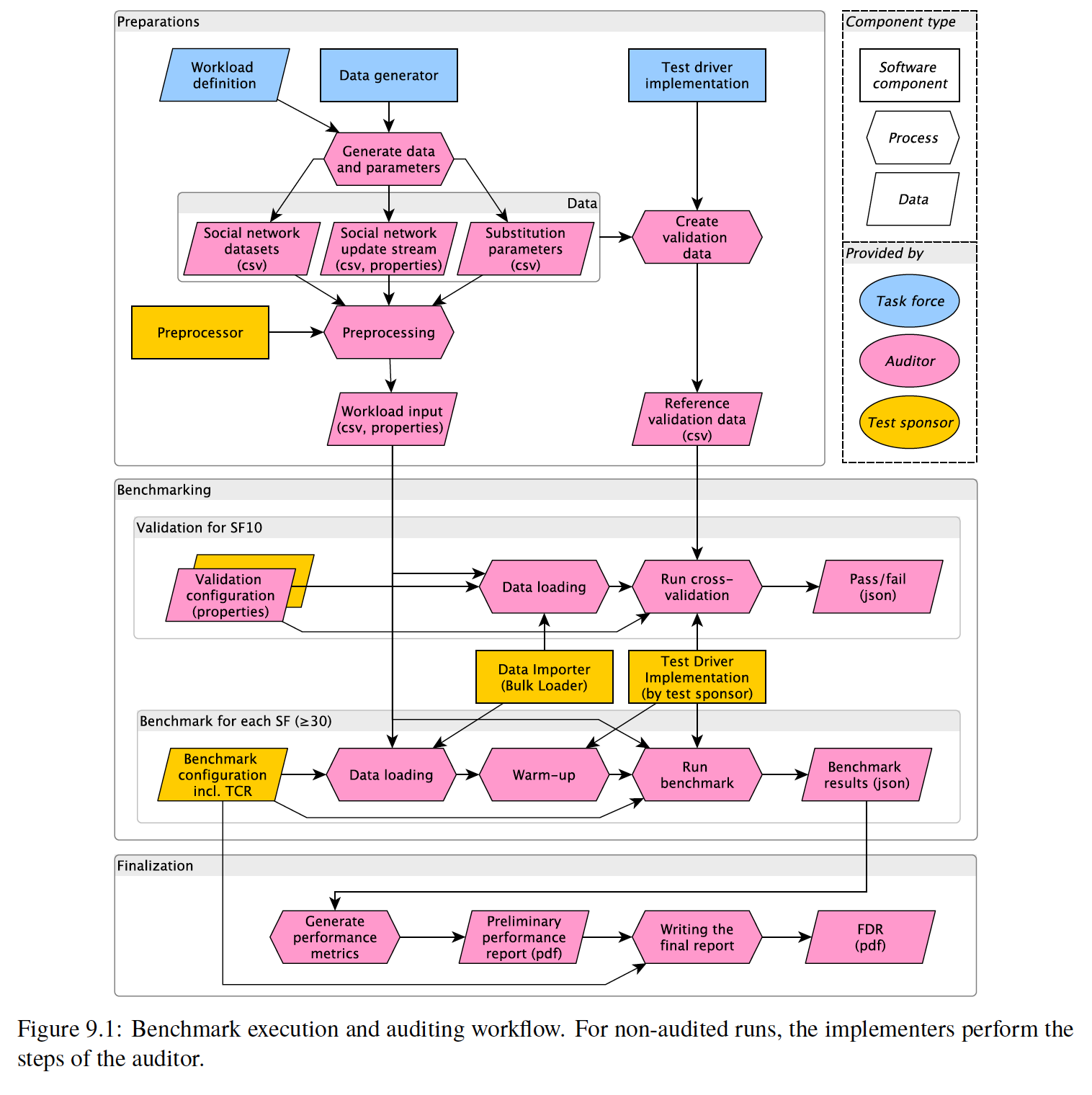
整个 LDBC SNB 基准测试的流程如下,主要分成
准备阶段
、
基准测试
、
结果输出
这三个阶段。
准备阶段主要执行数据生成,包括初次导入的全量数据,以及后续实时更新的数据。此外在官方审计中,还需要在 SF10 Dataset 上进行 Validation,因此这一阶段也会生成用于校验的数据。
基准测试阶段会先在 SF10 Dataset(在本文文末介绍了何为 SF)上进行 Validation,之后会在 SF30 或者 SF100 Dataset 进行性能测试。Validation 的过程就是在数据导入之后,由 Driver 根据之前准备阶段的一系列 query 和期望结果,对数据库的查询结果进行校验,以确保数据库的查询结果正确。Validation 的这个过程没有时间要求。而之后的性能测试分为导入、预热、性能测试,数据库可以有 30 分钟的预热时间,而在性能测试至少要持续两个小时,最终将测试结果汇总并输出。
由于篇幅限制,我们这一系列重点介绍 SNB Interactive Workload 相关内容。这一篇,我们主要会结合论文,介绍 SNB 的 Schema 以及数据生成,也就是准备阶段。
LDBC SNB Schema 生成
为了和 SNB 中的数据命名统一,本文相关名称我会用英文,所以读起来可能会有些怪怪的。为了降低理解成本,每个英文单词首次出现后面会跟随对应的中文注释讲解。
SNB 的数据主要是模拟了一个类似 Facebook 的社交网络。其中数据都是围绕
Person
(人)构建而来,
Person
之间会构成
Friendship
(情谊)网络。每个
Person
可能会有若干
Forum
(特定讨论区),
Person
可以在
Forum
中下面发送若干
Post
(帖子),其他
Person
可能会
likes
(点赞)其中一些
Message
(消息)。
以上这些元素的数据量主要会受
Person
和时间的影响:
- 有更多朋友的人会发送更多的评论或点赞
- 时间越长,会结交更多的朋友,评论或点赞数量也会上升
还有一部分数据不会随
Person
数量而变化,主要包括一些
Organization
(组织,这里主要是学校)以及
Place
(地方,这里主要是居住城市、国家等地理信息)。这部分数据会在数据生成时起一些作用,比如在同一时期在同一个学校上学的人更有可能称为朋友。
SNB 的完整 Schema 如下图所示:
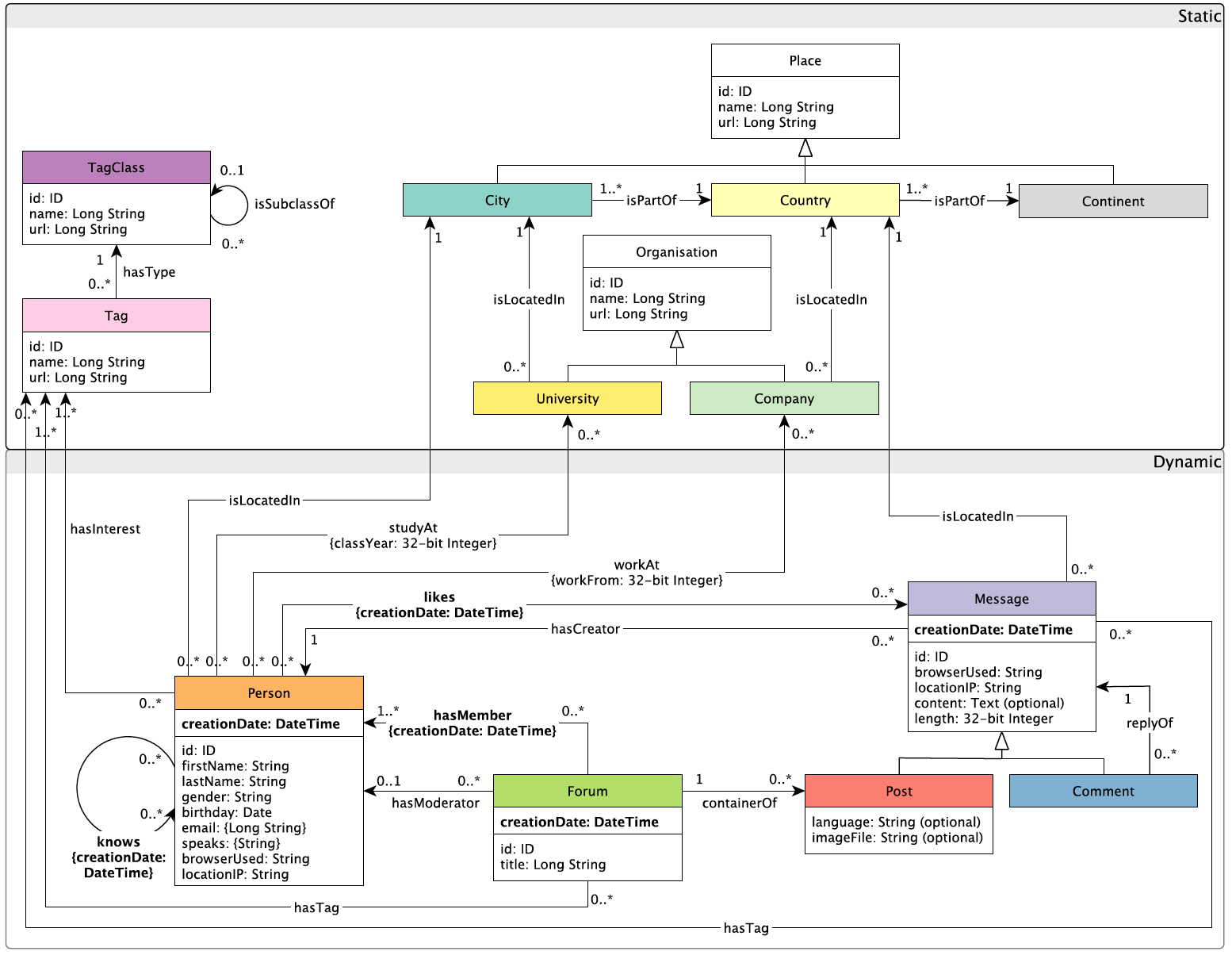
大多数图数据库在进行测试时候,会将实体建模为点,而不同关系会建模为边。但这只是一个惯例,
SNB 的数据建模和实际数据库中的 Schema 可以不同,只要数据库能够完成相应 Workload 的查询即可
。
LDBC SNB 数据生成
SNB 的一个重要部分是 Data Generator(下文称为 DataGen),用来生成满足上面 Schema 的数据。Generator 生成的数据由以下三个参数决定:
Person
的个数- 模拟多少年的数据
- 从哪一年开始模拟
根据官方文档,DataGen 生成的数据有以下性质:
- 现实性
:生成数据模拟了一个真实的社交网络。一方面,生成数据中的属性、基数、数据相关性和分布经过精心设置,从而能够模拟 Facebook 等真实社交网络。另一方面,其原始数据来自于
DBpedia
,保证数据中的属性值真实且相关。 - 可扩展性
:针对不同规模和预算的系统,DataGen 能够生成不同大小的数据集(GB 到 TB 级),此外 DataGen 可以在单机,或者是一个集群中完成数据生成。 - 确定性
:无论用来生成数据的机器数量多少、机器配置是高还是低,DataGen 生成的数据都是确定且相同的。这一重要功能确保了任意一个数据系统都能使用相同的数据集,保证不同系统环境之间的测评比较公平且基准测试结果可重复。 - 易用性
:DataGen 被设计得尽可能易于使用。
整个数据生成的流程图如下所示,我们会分解为几部分介绍:
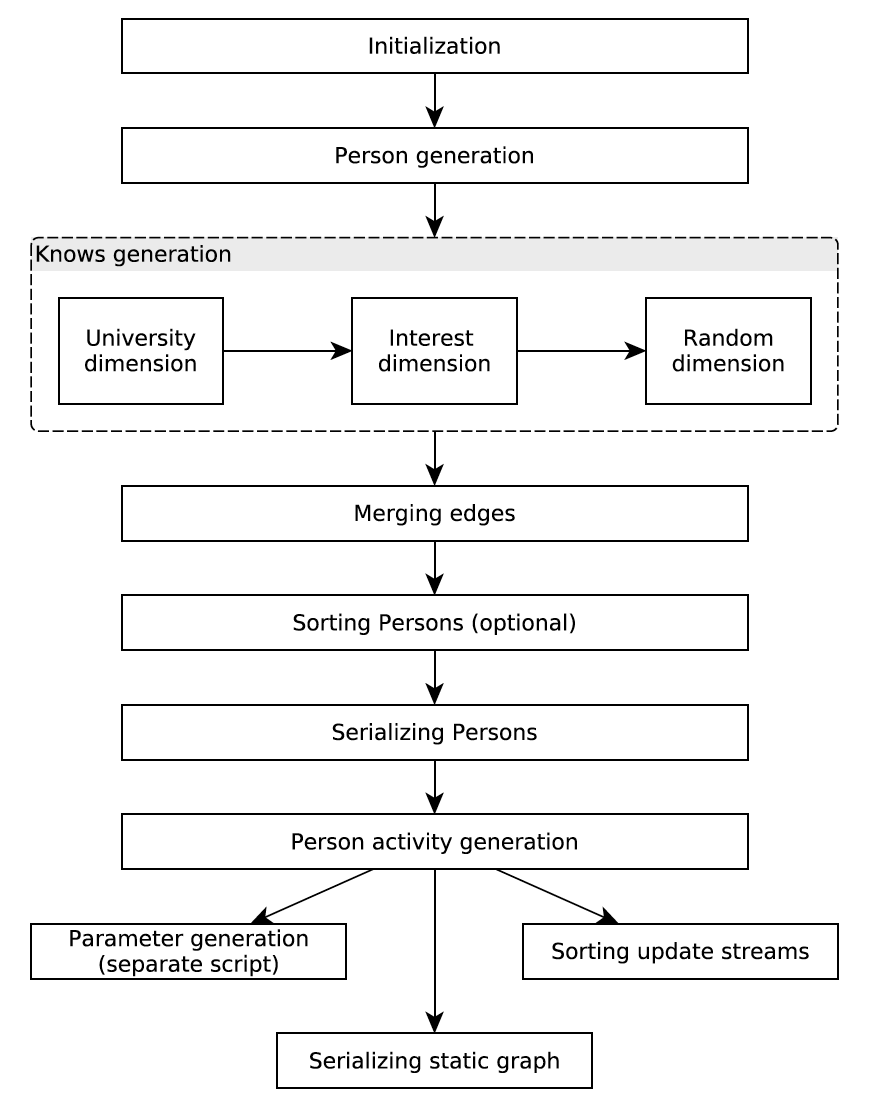
生成属性分布
第一步是初始化。DataGen 使用的原始数据来自于 DBpedia,针对每一个属性,DataGen 会根据以下方面决定属性的分布:
- 有多少种可能的属性值
- 每一种属性值出现的概率
最终将属性的分布情况作为资源文件以及 DataGen 的参数保存下来。
生成 Person 和 Friendship
前面也提到过,SNB 的 Schema 的核心是
Person
,这也体现在数据生成过程中。接下来 DataGen 就会生成所有
Person
,以及
Person
中一部分后续操作所需要的信息,比如每个
Person
有多少
Friendship
(这个值非常重要,其分布满足 Power law(幂定律)),
Person
所就读的大学,
Person
所就职的公司等。
接下来,DataGen 会创建每个
Person
的
Friendship
关系(即流程图中的
knows
)。和真实社交网络一样,有相同兴趣或者行为的人,很有可能会连接在一起。为了模拟这样的社交网络,SNB 在生成
Friendship
时会考虑以下三个维度:
Person
所就读的大学,就读时间,以及大学所在城市Person
的兴趣- 每个
Person
会生成一个随机值,随机值越相近代表其越类似(这是为了模拟不是所有朋友都是通过大学和兴趣结交的)
三个维度分别占每个
Person
的
Friendship
关系权重的 45%,45% 和 10%,也就将
Person
之间建边的过程分成了三个子步骤。
DataGen 会依次根据三个维度将所有
Person
进行排序(每次只按一个维度进行排序),然后将排序过后的
Person
切分为不相交的多个部分,分发给不同 Worker 进程。即便是切分之后,每个 Worker 线程负责的
Person
可能也可能超过内存大小。因此,Worker 线程会维护一个滑动窗口,滑动窗口内的
Person
之间建立
Friendship
关系的概率满足几何分布。
如下图所示:
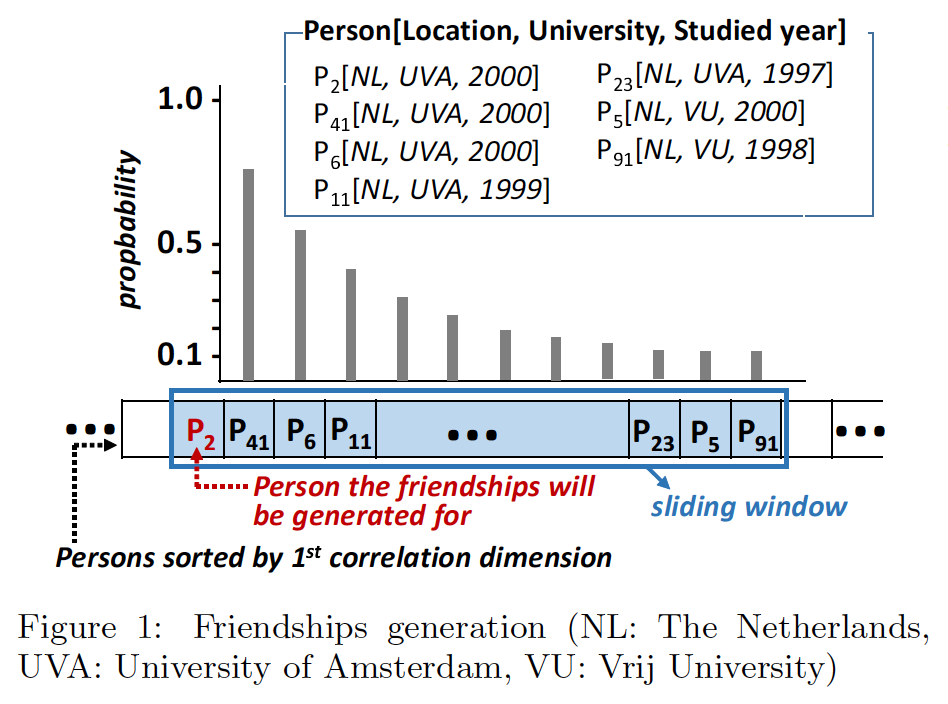
假设现在根据就读大学这个维度进行了排序,得到了一个
Person
有序序列。之后 Worker 就会维护一个滑动窗口,每次为滑动窗口最左侧的人生成
Friendship
关系(上图当前是 P2),滑动窗口内的其他人和窗口第一个人建立
Friendship
的比例满足几何分布。
直到滑动窗口的第一个人建立了足够多的
Friendship
之后,滑动窗口的起点会移到下一个人。
这里没有深究滑动窗口的大小、几何分布的参数甚至是随机生成器的参数,不知道在出现滑动窗口内无法生成足够多 Friendship 关系时,DataGen 如何处理。
将三个维度都经过排序、分发、按滑动窗口建边之后,DataGen 就进入了下一阶段。
生成社交活动
生成完
Person
和
Friendship
之后,DataGen 就开始生成每个
Person
的社交活动,包括
Forum
,
Post
和
Comment
。这部分数据也有一些相关性存在:
- 有越多
Friendship
的
Person
在社交网络上会越活跃 - 每个
Person
更可能在自己感兴趣或者就读大学相关的
Forum
进行
Post
或者
Comment - 社交活动和时间是有相关性的,比如接近世界杯,足球相关的讨论就会激增
最终输出
经过以上步骤之后,DataGen 完成了数据生成,模拟的社交网络图会分成两部分进行输出:
- Dataset:90% 的数据用于初始导入
- Update Streams:10% 的数据用于后续实时更新
除此之外,还会生成后续 Workload 中请求的参数(主要是起点)。关于参数生成我们会在下一篇详细解释,这里简单描述一下 SNB 的读请求 Workload。Interactive Workload 主要的查询希望在一秒以内得到查询结果,所有读 query 都是从图中的一个点出发,获取很小一部分的子图信息。另外,因不同起点的出入度不同,基本上也就决定了这次读请求会访问的数据量。
为了测试不同系统和场景,SNB 定义了比例因子(Scale Factor,即所谓的 SF)用来控制最终生成的数据量大小。比如,SF1 原始数据大小为 1 GB,同理 SF0.1 和 SF300 的大小为 100 MB 和 300 GB。不同比例因子的各个类型的点边数据量如下表所示:
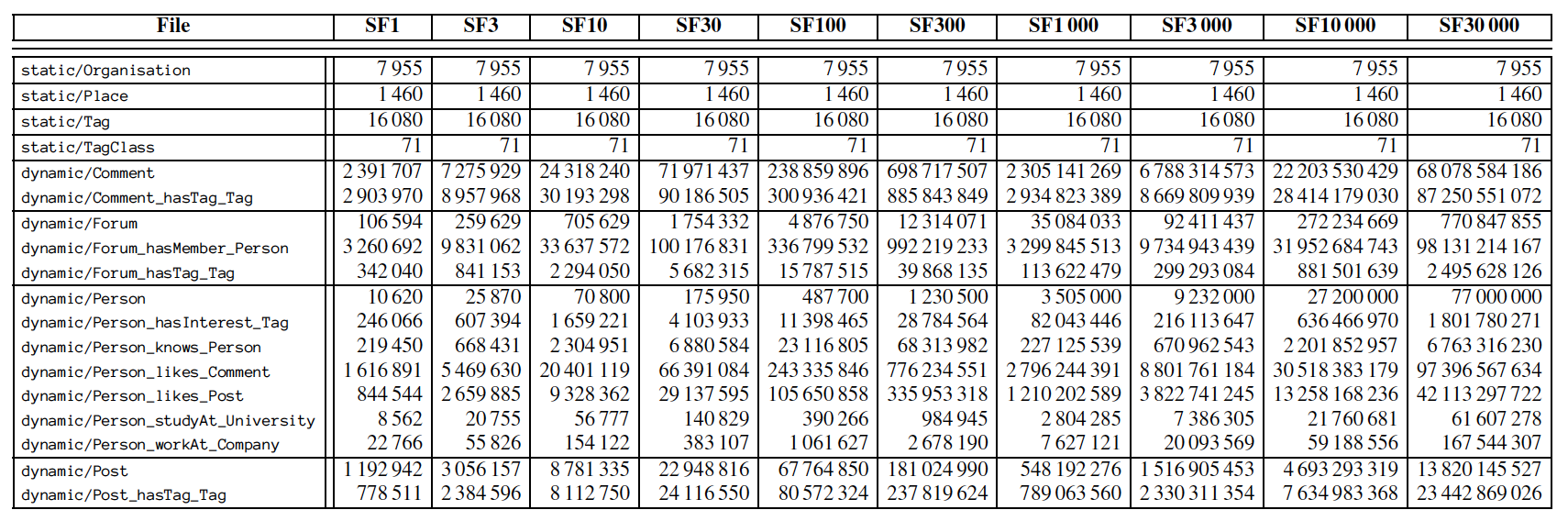
最终生成的 Dataset 分为两大类:Static 和 Dynamic,格式都是 CSV。根据 DataGen 配置的线程数量大小,最终生成的数据也会分为多个分片。Static 包含
Organization
、
Place
、
Tag
等,都是基于 DBpedia 生成的静态数据,其数量不会随着比例因子变化而变化。换而言之,这部分数据与
Person
的个数无关。而 Dynamic 部分主要包括
Person
、
knows
(即前面数据生成部分描述的
Friendship
)、
Forum
、
Post
和
Comment
等。
而 Update Streams 中包含了所有更新的操作,主要就是模拟实时注册新用户、评论、点赞、加好友等等行为。
Reference
到这里准备阶段大概就介绍完了,在准备阶段最终生成的请求参数部分我们会在下一篇讲述Workload时再展开。
- ldbc-snb-interactive-sigmod-2015.pdf (ldbcouncil.org)
- The LDBC Social Network Benchmark Specification
关于 NebulaGraph
NebulaGraph 是一款开源的分布式图数据库,自 2019 年开源以来,先后被美团、京东、360 数科、快手、众安金融等多家企业采用,应用在智能推荐、金融风控、数据治理、知识图谱等等应用场景。GitHub 地址:
https://github.com/vesoft-inc/nebula
作者:
critical27