# npm设置代理
npm config set proxy http://127.0.0.1:8080
npm config set https-proxy http://127.0.0.1:8080
# yarn设置代理
yarn config set proxy http://127.0.0.1:8080
yarn config set https-proxy http://127.0.0.1:8080
删除了代理后,继续执行
react-native run-android
命令进行验证,依然报上面的certificate has expired错误。看起来有点到了山群水尽的地步,
最后,索性一不做二不休,直接跳过SSL证书验证,执行下面的命令。
# 跳过npm SSL证书验证
npm set strict-ssl false
# 跳过yarn SSL证书验证
yarn config set "strict-ssl" false -g
再次执行
react-native run-android
命令,这次certificate has expired错误消失了。
至少把问题往前推进了一步。
不过也别高兴得太早,又碰到了新的问题。且继续看下面的填坑记录。
Invalid regular expression引发的困扰
这次报告的错误消息为:
error Invalid regular expression:
/(.*\\__fixtures__\\.*|node_modules[\\\]react[\\\]dist[\\\].*|website\\node_modules\\.
*|heapCapture\\bundle\.js|.*\\__tests__\\.*)$/:
Unterminated character class. Run CLI with --verbose flag for more details.
def REACT_NATIVE_VERSION = new File(['node', '--print',"JSON.parse(require('fs').readFileSync(require.resolve('react-native/package.json'), 'utf-8')).version"].execute(null, rootDir).text.trim())
allprojects {
configurations.all {
resolutionStrategy {
// Remove this override in 0.65+, as a proper fix is included in react-native itself.
force "com.facebook.react:react-native:" + REACT_NATIVE_VERSION
}
}
我的react-native版本是0.59.9,低于0.63,那就直接用上面的方法。
再次运行
react-native run-android
进行验证,这次总算打包成功了!!!
不过也不要高兴得太早,预知后事如何,请继续...
DeviceException: No connected devices
执行后出现如下的异常:
PS E:\project\exphone\exphoneapp2> react-native run-android
(node:18976) Warning: Accessing non-existent property 'padLevels' of module exports inside circular dependency
(Use `node --trace-warnings ...` to show where the warning was created)
info Starting JS server...
info Building and installing the app on the device (cd android && gradlew.bat app:installDebug)...
> Task :app:installDebug FAILED
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:installDebug'.
> com.android.builder.testing.api.DeviceException: No connected devices!
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
这个异常的核心是com.android.builder.testing.api.DeviceException: No connected devices!
也就是没有连接到模拟器。
我用的模拟器是
BlueStacks蓝叠
,这个模拟器要比Google的模拟器快。
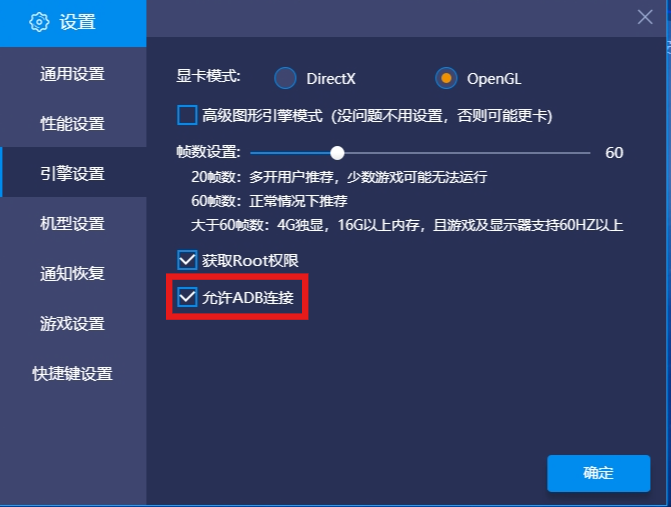
需要设置的地方是勾选其中允许ADB连接:
明明我的模拟器启动起来了,为何不能连接上呢?
输入命令查看当前模拟器设备:
# adb devices列出模拟器设备
PS E:\project\exphone\exphoneapp2> adb devices
List of devices attached
发现确实没有显示出连接上的模拟器。
那我们就手动连接一个:
# 使用adb connect进行连接
PS E:\project\exphone\exphoneapp2> adb connect 127.0.0.1:6666665
connected to 127.0.0.1:6666665
PS E:\project\exphone\exphoneapp2> adb devices
List of devices attached
127.0.0.1:6666665 device
Server Software:
Server Hostname:192.168.100.100Server Port:51997Document Path:/api/hello
Document Length:24bytes
Concurrency Level:1Time takenfor tests: 4.361seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:1190000bytes
HTML transferred:240000bytes
Requests per second:2293.29 [#/sec] (mean)
Time per request:0.436[ms] (mean)
Time per request:0.436[ms] (mean, across all concurrent requests)
Transfer rate:266.51 [Kbytes/sec] received
ab -n 100000 -c 4 http://192.168.100.102:51996/api/hello
测试结果:qps = 6277 【对比:.NET Core 8 对应的 qps = 5765】
Document Path: /api/hello
Document Length:24bytes
Concurrency Level:8Time takenfor tests: 1.593seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:1190000bytes
HTML transferred:240000bytes
Requests per second:6277.48 [#/sec] (mean)
Time per request:1.274[ms] (mean)
Time per request:0.159[ms] (mean, across all concurrent requests)
Transfer rate:729.51 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect:000.301Processing:010.413Waiting:010.413Total:110.414Percentage of the requests served within a certain time (ms)50% 166% 175% 180% 290% 295% 298% 299% 2100% 4 (longest request)
ab 在.NET8 中只能在2个并发中测试出5765的成绩,而在.NET4 中能在8个并发中测试出6277的成绩。
我怀疑是不是我调整了程序引发的,于是重新对.NET8进行测试:
测试结果显示,数据一样,这~~~~
C、使用 CYQ.Data 读数据库,输出 Json,来看看压测结果(读数据库接口)
测试代码:
public void HelloDb(string msg)
{
string conn = "server=.;database=MSLog;uid=sa;pwd=123456";
using (MProc proc = new MProc("select top 1 * from SysLogs", conn))
{
Write(proc.ExeJson());
}
}
运行结果:返回一条数据:
下面直接进行压测
ab -n 10000 -c 8 http://192.168.100.100:51997/api/hellodb
Concurrency Level: 8Time takenfor tests: 1.658seconds
Complete requests:10000Failed requests:0Write errors:0Total transferred:10550000bytes
HTML transferred:9590000bytes
Requests per second:6031.36 [#/sec] (mean)
Time per request:1.326[ms] (mean)
Time per request:0.166[ms] (mean, across all concurrent requests)
Transfer rate:6213.95 [Kbytes/sec] received
目前看来,在ab的测试结果中,倒是 .NET 程序在 Windows 部署中更优。
下面用 wrk 进行极限压测再看看结果:
2、测试 Window 11 下,虚拟机wrk工具压测:(读数据库输出Json)
虚拟机环境:
CPU :Intel(R) Core(TM) i5-9400 CPU @ 2.90GHz
内核: 2
逻辑处理器: 2
内存:4G
Concurrency Level:1Time takenfor tests: 22.728seconds
Complete requests:100000Failed requests:0Write errors:0Total transferred:11900000bytes
HTML transferred:2400000bytes
Requests per second:4399.90 [#/sec] (mean)
Time per request:0.227[ms] (mean)
Time per request:0.227[ms] (mean, across all concurrent requests)
Transfer rate:511.32 [Kbytes/sec] received
B、我们调整一下参数,看看ab在单机下能压出多少来(简单接口返回):
ab -n 100000 -c 48 http://192.168.100.102/api/hello
Concurrency Level:48Time takenfor tests: 5.253seconds
Complete requests:100000Failed requests:0Write errors:0Total transferred:11900000bytes
HTML transferred:2400000bytes
Requests per second:19037.81 [#/sec] (mean)
Time per request:2.521[ms] (mean)
Time per request:0.053[ms] (mean, across all concurrent requests)
Transfer rate:2212.40 [Kbytes/sec] received