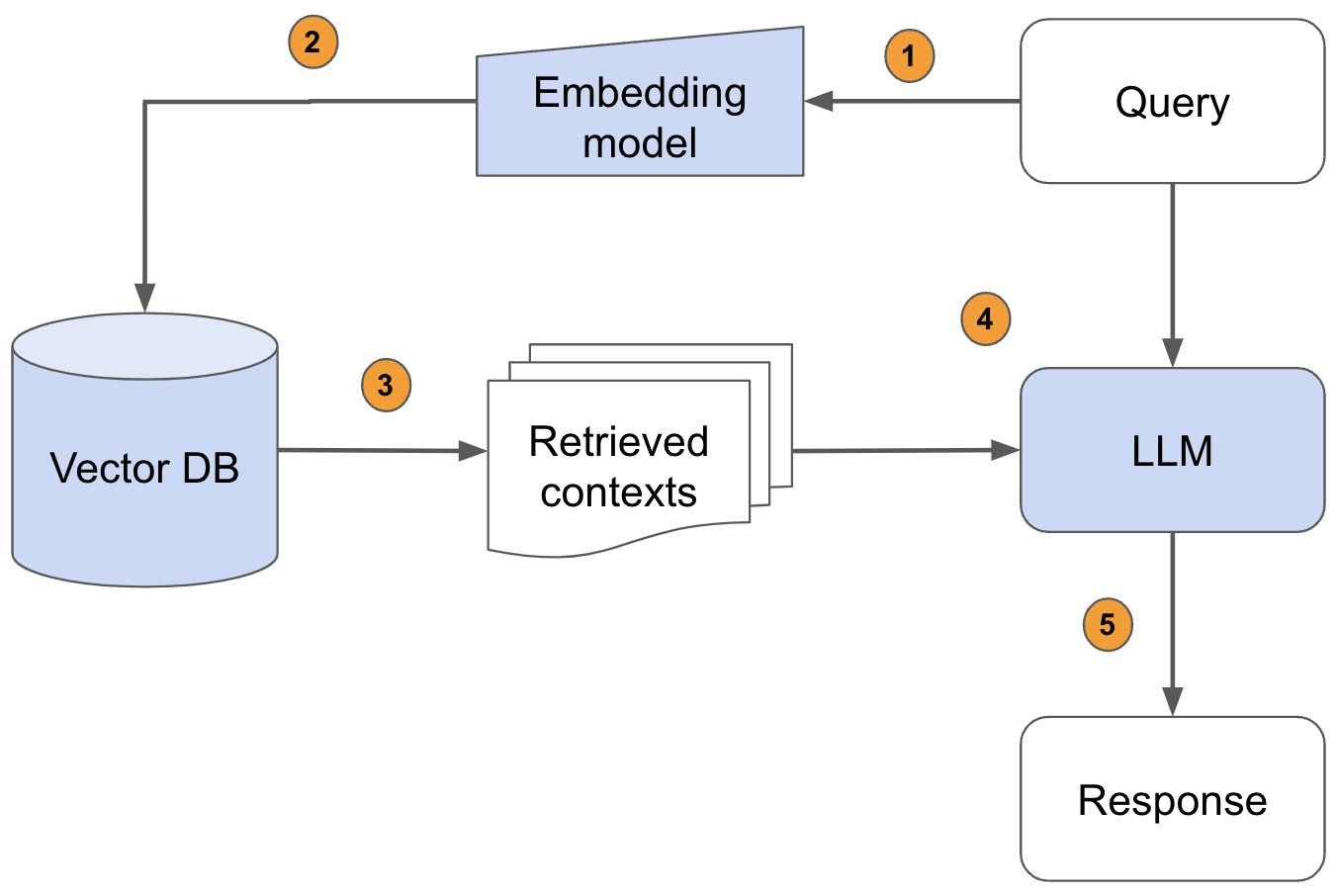
判断字符串是否唯一
算法1:用于判断一个字符串的字符是否都是唯一的,即没有重复的字符。
解决思路:首先将输入的字符串转换为字符数组,然后对字符数组进行排序。之后,使用一个while循环遍历排序后的字符数组,如果发现有任何两个相邻的字符相同,则返回false,表示字符串中有重复的字符。如果循环结束后都没有发现相邻的字符相同,则返回true,表示字符串中的字符都是唯一的。
代码示例:
public booleanisUnique(String astr) {char[] chars =astr.toCharArray();
Arrays.sort(chars);int i=0;while(i<chars.length-1){if(chars[i]==chars[i+1]){return false;
}
i++;
}return true;
}
上面潜在问题与风险:
字符编码问题:此方法假设所有字符都可以使用char类型处理,这对于大多数ASCII和Unicode字符是有效的。但是,如果处理包含如中文、希伯来文等复杂脚本的字符串时,单个字符可能需要多个char来表示(Java中的String和char基于UTF-16编码,对于代理对这种情况需要特殊处理)。这可能不是您想要的行为,尤其是在处理全球化的应用程序时。
性能效率问题:该方法对字符串进行排序,这在字符串非常长时可能非常耗时。对于判断字符串是否唯一的目的,排序并不是最高效的方法,因为它的时间复杂度是O(nlogn)。
空间复杂度问题:转换字符串为字符数组并进行排序将需要额外的O(n)空间复杂度,这在某些内存受限的场景下可能不是最佳选择。
异常处理:方法中没有对输入参数astr进行空值检查。虽然Java中对空字符串进行排序不会抛出异常,但如果业务逻辑不允许空字符串的存在,应当显式检查。
优化方向
使用HashSet:一个更高效的方法是使用HashSet。HashSet是一个无序、不重复元素的集合,它的添加操作的时间复杂度接近O(1)。可以通过遍历字符串的每个字符,尝试将它们添加到HashSet中来判断字符是否重复。如果字符重复,HashSet会拒绝添加,并立即返回false。这种方法的时间复杂度接近O(n),且不需要额外排序,更高效。
检查字符串长度:可以通过直接检查字符串的长度和字符集的大小来快速判断字符串是否包含重复字符。例如,如果字符串长度大于字符集的大小(考虑Unicode,这个字符集大小是固定的,即Character.MAX_VALUE),则一定存在重复字符,可以直接返回false。这种方法可以提前终止一些不必要的检查,尤其是在字符串很长时。
不使用额外空间:如果空间复杂度是一个重要考虑因素,可以通过遍历字符串,使用一个长度为Character.MAX_VALUE的boolean数组来标记字符是否出现过。这样可以将空间复杂度降低到O(1),但会稍微牺牲一些时间复杂度,因为需要额外的逻辑来处理Unicode代理对。
代码可读性:当前方法的实现逻辑较为间接(通过排序来寻找重复),对于未深入了解的读者可能不够直观。使用HashSet或其他直接算法可以提高代码的可读性和可维护性。
安全性和边界条件
安全性:此方法不涉及网络、文件访问或其他外部资源,因此从传统意义上讲是安全的。但是,它依赖于Java String和字符数组的实现,应确保使用的Java环境没有相关安全漏洞。
边界条件:应当检查输入参数是否为null,避免潜在的NullPointerException。同时,空字符串("")应当被认为是不包含重复字符的,这一点当前实现处理得当。
以下是相应的代码优化。请注意,由于涉及的修改较为复杂,一些细节可能需要进一步调整。
根据上述建议,可以使用HashSet来优化原代码,不仅提高性能,同时增强代码的可读性和可维护性。以下是使用HashSet重构后的代码:
1 public classStringUniqueChecker {2 /** 3 * 用于判断一个字符串的字符是否都是唯一的,即没有重复的字符。4 * 使用HashSet来检查字符是否重复,HashSet的add方法会自动拒绝重复的元素。5 *@paramastr 输入的字符串6 *@return如果字符串中的字符都是唯一的,则返回true;否则,返回false。7 */ 8 public booleanisUnique(String astr) {9 //检查输入是否为null或空字符串 10 if (astr == null ||astr.isEmpty()) {11 return true;12 }13 14 HashSet<Character> set = new HashSet<>();15 for (int i = 0; i < astr.length(); i++) {16 char c =astr.charAt(i);17 //如果set中已经包含了当前字符,则说明有重复字符 18 if(set.contains(c)) {19 return false;20 }21 set.add(c);22 }23 return true;24 }25 }