liwen01 2024.07.21
前言
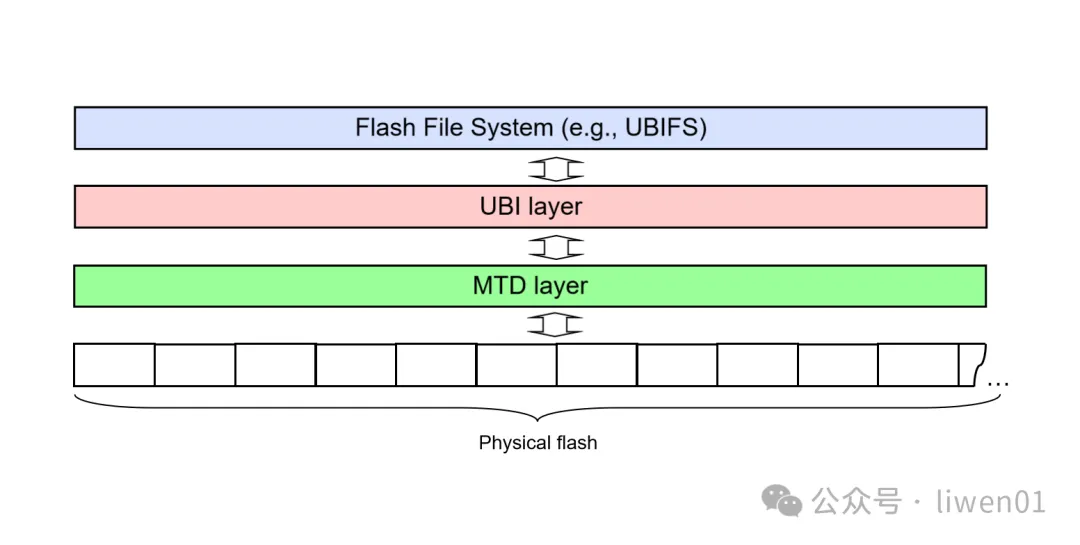
UBI (Unsorted Block Images)文件系统是一种用于裸 flash 的文件系统管理层。它是专为管理原始闪存设备而设计,特别适用于嵌入式系统。与 YAFFS2 和
JFFS2
不同的是,它可以提供整个 flash 空间的磨损平衡,并且有良好的扩展性,适用于大容量的
nand flash
。
(一)MTD、UBI 与 UBIFS
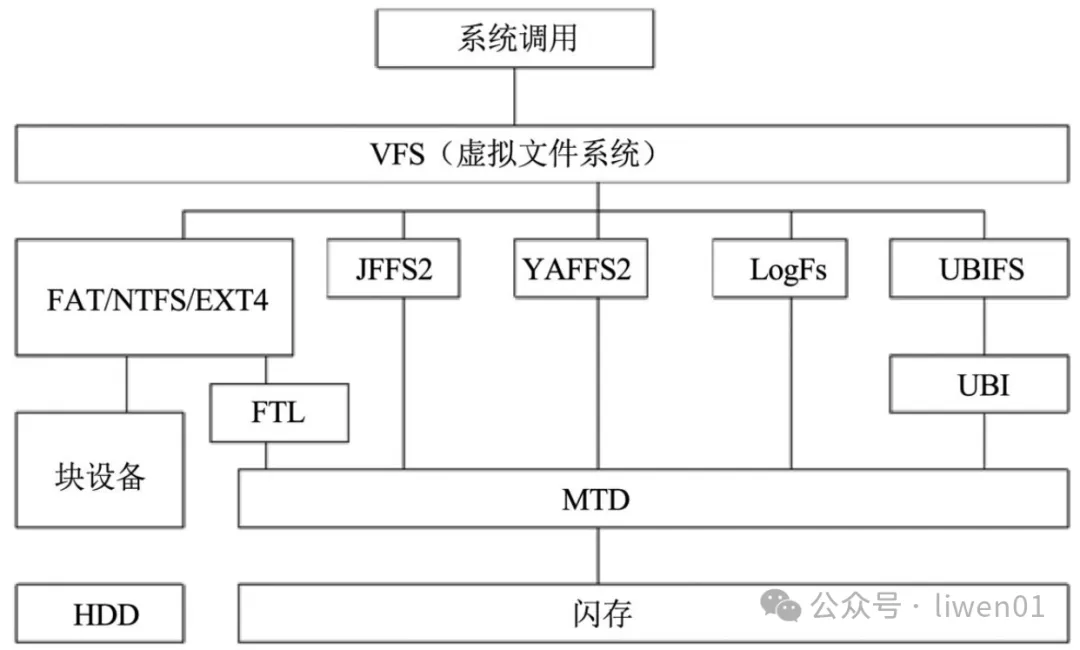
前面介绍的 JFFS2 和 YAFFS2 都是运行在 MTD 之上,而 UBIFS 只能运行在 UBI 之上,UBI 又只能运行于 MTD 之上,所以这里就涉及到 3 个子系统:MTD、UBI、UBIFS。
- MTD
提供了对底层闪存硬件的抽象和基本管理。
- UBI
在 MTD 之上增加了一层管理,处理闪存的复杂性并提供逻辑卷管理。
- UBIFS
是在 UBI 卷上运行的文件系统,充分利用 UBI 的特性,提供高效可靠的文件存储。
这里需要特别注意,
这里所说的闪存,是指裸 flash,而不是经过FTL转换后的 U 盘、SD、TF、SSD 等设备
。
在 Linux 中,经过 FTL 转换后的 U 盘、SD、TF、SSD 等设备,它们属于块设备,是模拟传统磁盘设计的一种数据结构,以扇区 sector 为读写单位。
而 MTD,它既不是字符设备,也不是块设备,它只是 MTD 设备
(1) MTD (Memory Technology Device)
MTD 是
Linux 内核
中的一个子系统,用于支持不同类型的闪存设备,如
NOR Flash
和 NAND Flash。MTD 提供了一个抽象层,使得文件系统和用户空间程序可以方便地访问底层的闪存硬件。
- MTD 设备
:在 Linux 系统中,MTD 设备通常以 /dev/mtdX 和 /dev/mtdblockX 的形式出现,其中 X 是设备编号。
- MTD 子设备
:一个 MTD 设备可以被划分为多个子设备,每个子设备可以独立使用。
(2)UBI (Unsorted Block Images)
UBI 是一个在 MTD 设备之上的管理层,专门为 NAND Flash 设计。UBI 处理了 NAND Flash 固有的一些复杂性,如坏块管理和磨损均衡(wear leveling)。UBI将闪存划分为逻辑擦除块,并对它们进行管理。
- 坏块管理
:UBI 能够检测和管理坏块,确保数据写入时不会使用坏块。
- 磨损均衡
:UBI 通过均匀分布擦写操作,延长闪存的使用寿命。
- 逻辑卷
:UBI 支持在 MTD 设备上创建多个逻辑卷,每个卷可以独立使用。
(3)UBIFS (UBI File System)
UBIFS 是专门为 UBI 设计的文件系统,直接在 UBI 卷上运行。UBIFS 充分利用 UBI 的功能,提供了高效和可靠的文件存储解决方案。
- 动态特性
:UBIFS 支持动态调整文件系统大小,根据需要分配和回收空间。
- 日志结构
:UBIFS 使用日志结构文件系统,减少数据损坏的风险并提高写入性能。
- 压缩
:UBIFS 支持多种压缩算法,节省存储空间。
UBIFS 并不是唯一可以在UBI上运行的文件系统,理论上绝大部分文件系统都可以在 UBI 上运行。除了 UBIFS,其它文件系统在 UBI 上使用效率都不高。
(二)镜像文件制作
(1)UBIFS 镜像文件制作
(a)准备测试文件
新建4个测试目录,在目录中创建测试问价,文件使用 /dev/urandom 写入随机数
biao@ubuntu:~/test/ubifs/ubifs_urandom$ tree
.
├── test1
│ ├── file1
│ ├── file1_1
│ └── file1_2
├── test2
│ ├── file2
│ ├── file2_1
│ └── file2_2
├── test3
│ ├── file3
│ ├── file3_1
│ └── file3_2
└── test4
├── file4
├── file4_1
└── file4_2
4 directories, 12 files
biao@ubuntu:~/test/ubifs/ubifs_urandom$
文件大小信息如下:
biao@ubuntu:~/test/ubifs$ du ubifs_urandom
1904 ubifs_urandom/test3
168 ubifs_urandom/test2
1504 ubifs_urandom/test1
1476 ubifs_urandom/test4
5056 ubifs_urandom
biao@ubuntu:~/test/ubifs$
(b)制作 UBIFS 镜像文件
mkfs.ubifs -r ubifs_urandom -m 2048 -e 129024 -c 10000 -o ubifs_urandom.ubifs
各参数的作用:
-r, -d, --root=DIR build file system from directory DIR
-m, --min-io-size=SIZE minimum I/O unit size
-e, --leb-size=SIZE logical erase block size
-c, --max-leb-cnt=COUNT maximum logical erase block count
-o, --output=FILE output to FILE
上面命令的作用是:将 ubifs_urandom 目录里面的文件打包成一个页大小为 2048(2KB)、逻辑擦除块大小为 129024(126KB)、最大逻辑块为 10000 的 UBIFS 镜像文件 (ubifs_urandom.ubifs)。
这里有几点需要注意:
- -m 是页大小,不是子页大小
- -e 设置的逻辑擦除块大小要与UBI里的相同,不然挂载的时候会报错误
(2)UBI 镜像文件制作
在 UBIFS 的基础上,制作一个UBI镜像文件
(a)制作 UBI 镜像配置文件
创建配置文件 ubinize.cfg
[ubifs]
mode=ubi
image=ubifs_urandom.ubifs
vol_id=0
vol_size=256MiB
vol_type=dynamic
vol_name=ubifs_urandom
vol_flags=autoresize
- image 为我们上面制作的UBIFS文件系统镜像文件
- vol_id 指定卷 ID,这个是在有多个卷的时候使用
- vol_size 定义卷的大小
- vol_type 设置为动态卷,卷的大小可以变化
- vol_name 卷的名字
- vol_flags 自动调整大小
(b)制作 UBI 镜像文件
ubinize -o ubi.img -m 2048 -O 512 -p 128KiB ubinize.cfg
UBI 镜像文件和 UBIFS 的镜像文件,都需要根据实际 Flash 的参数进行设置
上面命令的作用是:将一个 ubifs 镜像文件制作成一个页大小为 2048(2KB)、子页大小为 (256Byte),物理擦除块大小为 128KB 的 UBI 镜像文件。
(三) 挂载 UBIFS 文件系统
为了方便调试,我们这里直接使用PC机上的虚拟 MTD 设备来仿真Flash。Linux 内核中有 3 种 MTD 设备模拟器可用:
- mtdram:在 RAM 中模拟 NOR 闪存;
- nandsim:在 RAM 中模拟 NAND 闪存;
- block2mtd:在块设备上模拟 NOR 闪存。
(1)加载 nandsim 模块
这里仿一个 1GiB, 2048 bytes page的 nand flash。
sudo modprobe nandsim first_id_byte=0xec second_id_byte=0xd3 third_id_byte=0x51 fourth_id_byte=0x95
可以通过 /proc/mtd 和 /dev/mtd0 查看模拟的 nandflsh 信息
biao@ubuntu:~/test/ubifs$ cat /proc/mtd
dev: size erasesize name
mtd0: 40000000 00020000 "NAND simulator partition 0"
biao@ubuntu:~/test/ubifs$ mtdinfo /dev/mtd0
mtd0
Name: NAND simulator partition 0
Type: nand
Eraseblock size: 131072 bytes, 128.0 KiB
Amount of eraseblocks: 8192 (1073741824 bytes, 1024.0 MiB)
Minimum input/output unit size: 2048 bytes
Sub-page size: 512 bytes
OOB size: 64 bytes
Character device major/minor: 90:0
Bad blocks are allowed: true
Device is writable: true
biao@ubuntu:~/test/ubifs$
上面加载 nandsim 的时候,有定义4个ID值,具体值需要根据芯片手册的数据来设置。
第一字节为制造商代码、第二字节为设备代码、第三、四字节为Flash特定参数
下面是几个示例:
modprobe nandsim first_id_byte=0x20 second_id_byte=0x33 - 16MiB, 512 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0x35 - 32MiB, 512 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0x36 - 64MiB, 512 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0x78 - 128MiB, 512 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0x71 - 256MiB, 512 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0xa2 third_id_byte=0x00 fourth_id_byte=0x15 - 64MiB, 2048 bytes page;
modprobe nandsim first_id_byte=0xec second_id_byte=0xa1 third_id_byte=0x00 fourth_id_byte=0x15 - 128MiB, 2048 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0xaa third_id_byte=0x00 fourth_id_byte=0x15 - 256MiB, 2048 bytes page;
modprobe nandsim first_id_byte=0x20 second_id_byte=0xac third_id_byte=0x00 fourth_id_byte=0x15 - 512MiB, 2048 bytes page;
modprobe nandsim first_id_byte=0xec second_id_byte=0xd3 third_id_byte=0x51 fourth_id_byte=0x95 - 1GiB, 2048 bytes page;
(2)挂载 UBIFS 文件系统
(a) 加载 UBI 内核模块
sudo modprobe ubi mtd=0
这里将 ubi 加载到了 mtd 的设备 0 上
(b) 分离 MTD 上的设备 0
sudo ubidetach /dev/ubi_ctrl -m 0
(c)格式化 MTD 设备并写入 UBI 镜像文件
sudo sudo ubiformat /dev/mtd0 -s 512 -f ubi.img
(d)UBI设备附加回 MTD 设备 0 上
sudo ubiattach /dev/ubi_ctrl -m 0 -O 512
(e)挂载 UBIFS 到指定目录
sudo mount -t ubifs ubi0 /home/biao/test/ubifs/ubifs_simulator
(f)查看挂载状态
biao@ubuntu:~/test/ubifs$ df -h
Filesystem Size Used Avail Use% Mounted on
......
ubi0 927M 4.8M 923M 1% /home/biao/test/ubifs/ubifs_simulator
......
biao@ubuntu:~/test/ubifs$
biao@ubuntu:~/test/ubifs/ubifs_simulator$ ls
test1 test2 test3 test4
可以看到制作的 UBIFS 镜像文件已经被挂载到了 ubi0 卷上,挂载目录上的文件也就是我们的测试文件。
(四) UBIFS 镜像文件分析
上面我们制作了两个镜像文件 UBIFS 和 UBI,然后再将 UBI 镜像文件加载到 PC机上的 NAND Flash 模拟器 nandsim 上。要了解 UBIFS 的工作原理,我们有必要对它在 Flash 上的数据结构进行分析。
(1)UBIFS 数据结构
ubifs-media.h 中可以看到 UBIFS 所有数据结构定义,下面这个是通用数据结构,有
幻数
、crc校验、序列号、长度、节点类型、节点组类型这些信息,其中有效节点有11种。
通用头部结构体定义如下
/**
* struct ubifs_ch - common header node.
* @magic: UBIFS node magic number (%UBIFS_NODE_MAGIC)
* @crc: CRC-32 checksum of the node header
* @sqnum: sequence number
* @len: full node length
* @node_type: node type
* @group_type: node group type
* @padding: reserved for future, zeroes
*
* Every UBIFS node starts with this common part. If the node has a key, the
* key always goes next.
*/
struct ubifs_ch {
__le32 magic;
__le32 crc;
__le64 sqnum;
__le32 len;
__u8 node_type;
__u8 group_type;
__u8 padding[2];
} __packed;
节点类型定义:
enum {
UBIFS_INO_NODE,
UBIFS_DATA_NODE,
UBIFS_DENT_NODE,
UBIFS_XENT_NODE,
UBIFS_TRUN_NODE,
UBIFS_PAD_NODE,
UBIFS_SB_NODE,
UBIFS_MST_NODE,
UBIFS_REF_NODE,
UBIFS_IDX_NODE,
UBIFS_CS_NODE,
UBIFS_ORPH_NODE,
UBIFS_NODE_TYPES_CNT,
};
(2)UBIFS 节点布局
我们前面通过 mkfs.ubifs 制作生成的 UBIFS 镜像文件,它包含 5 种节点类型,在镜像文件中的布局如下图。
最开始是超级快、后面是两个Master、 最后面是Index Node,它们各自的功能如下:
Superblock Node
: 存储文件系统的基本信息,如大小、状态、版本等。
Master Node
: 保存文件系统的当前状态,包括对日志头和根索引节点的指针。
Commit Start Node
:标记一个提交操作的开始。它用于在文件系统崩溃时确定哪些数据是已提交的。
Data Node
: 存储文件的数据。每个数据节点都与一个文件的特定部分对应。
Index Node
:用于构建UBIFS的索引结构,类似于传统文件系统中的索引节点(inode)。
(3)UBIFS 节点工作原理
挂载文件系统
:
- 读取superblock和master node以恢复文件系统的基本状态和重要元数据指针。
- 初始化其他必要的数据结构和缓存。
文件操作
:
- 创建文件:在索引树中添加新的索引节点,并分配相应的数据节点来存储文件内容。
- 读写文件:通过索引节点找到相应的数据节点,然后执行读写操作。
- 修改文件:修改的数据会写入新的数据节点,并更新相应的索引节点。
提交
:
- 写入 commit start node 以标记提交的开始。
- 将所有修改的数据节点和索引节点写入闪存。
- 更新 master node 以反映最新的文件系统状态。
崩溃恢复:
- 检查 commit start node 以确定哪些提交操作已完成。
- 通过 master node 恢复文件系统的最新一致状态。
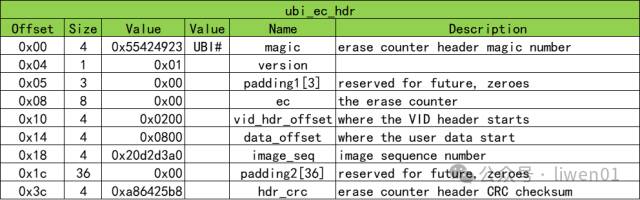
(4)UBIFS 节点分析
这里我们只分析superblock节点,其它node也类似
使用 hexdum 查看 一个 ubifs 镜像文件,最开始的位置就是superblock
00000000 31 18 10 06 e6 e4 54 b6 d9 05 00 00 00 00 00 00 |1.....T.........|
00000010 00 10 00 00 06 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 08 00 00 00 00 02 00 35 00 00 00 64 00 00 00 |........5...d...|
00000030 00 00 16 00 00 00 00 00 04 00 00 00 02 00 00 00 |................|
00000040 01 00 00 00 01 00 00 00 08 00 00 00 00 01 00 00 |................|
00000050 04 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 |................|
00000060 00 00 00 00 00 00 00 00 00 ca 9a 3b 1c fe ed 83 |...........;....|
00000070 7a ef 48 f7 83 2c 10 74 b9 36 09 9b 00 00 00 00 |z.H..,.t.6......|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
.........
对上面数据镜像解析,可以看到如下信息:
(五) UBI 镜像文件分析
(1) UBI 数据布局
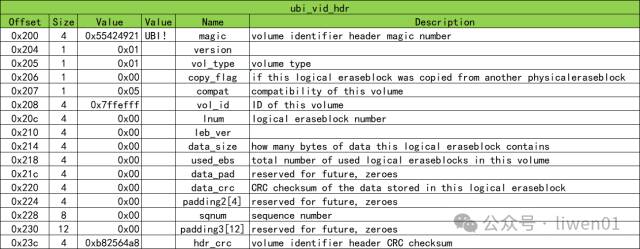
UBI 主要的数据结构是 ubi_ec_hdr 和 ubi_vid_hdr :
ubi_ec_hdr
: (Erase Counter Header) 包含擦除计数信息头部结构,主要作用是记录和管理物理擦除块的擦除次数。
ubi_vid_hdr
: (Volume Identifier Header) 包含卷标识信息头部结构,主要作用是管理和识别物理卷块中的数据。
一个UBI卷被分成多个块,每个块都有这两个头部。ubi_ec_hdr 记录每个块被擦除的次数,帮助管理块的寿命和可靠性。而 ubi_vid_hdr 则确保每个块在卷中的正确位置和数据完整性。
它们在镜像文件或是 flash 中的数据布局如下:
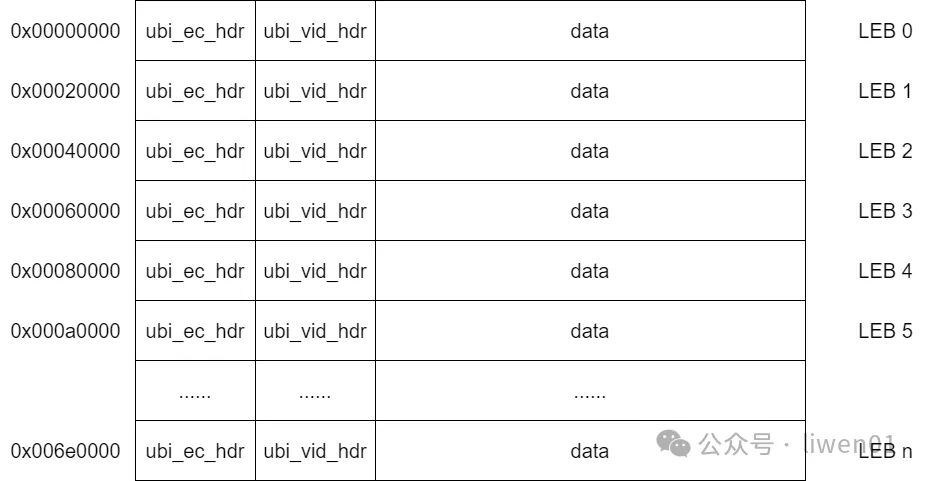
(2) 数据分析
查看 ubi.img 镜像文件的前4KB 数据,这里需要特别注意的是,
UBI的数据是按大端模式存储的,与之前分析的镜像文件有所不同
biao@ubuntu:~/test/ubifs$ hexdump -s 0 -n 4096 -C ubi.img
00000000 55 42 49 23 01 00 00 00 00 00 00 00 00 00 00 00 |UBI#............|
00000010 00 00 02 00 00 00 08 00 20 d2 d3 a0 00 00 00 00 |........ .......|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 92 3a 9d cd |.............:..|
00000040 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00000200 55 42 49 21 01 01 00 05 7f ff ef ff 00 00 00 00 |UBI!............|
00000210 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000230 00 00 00 00 00 00 00 00 00 00 00 00 b8 25 64 a8 |.............%d.|
00000240 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00000800 00 00 08 21 00 00 00 01 00 00 00 00 01 00 00 0d |...!............|
00000810 75 62 69 66 73 5f 75 72 61 6e 64 6f 6d 00 00 00 |ubifs_urandom...|
00000820 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000890 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000008a0 00 00 00 00 00 00 00 00 8c 7e c0 aa 00 00 00 00 |.........~......|
000008b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
......
ubi_ec_hdr 的数据解析如下
ubi_vid_hdr 的数据解析如下
(3) UBI工作原理
UBI 的工作原理可以通过下面官方的演示视频来介绍:
坏快管理实现原理可以查看下面视频:
(六)优缺点
(1)优点
(a)耐用性和可靠性
:
磨损均衡
:UBI能够有效地管理闪存的擦除次数,确保所有的擦除块均匀地使用,从而延长闪存的寿命。
坏块管理
:UBI能够检测并处理坏块,确保数据不被写入这些损坏的区域,提高文件系统的可靠性。
崩溃恢复
:UBI在系统崩溃或掉电后具有良好的恢复能力,能够尽量减少数据损失。
(b)动态大小管理
:
动态分区调整
:UBI允许动态调整分区的大小,这对于存储需求变化较大的应用非常有用。
灵活的空间管理
:UBI可以灵活地管理闪存空间,支持动态的文件系统分配和调整。
(c)支持大容量闪存
:UBI支持大容量的闪存设备,适合用于需要大量存储空间的嵌入式系统中。
(2)缺点
(a)复杂性增加
:
设计复杂
:UBI的实现较为复杂,需要在内核中增加额外的层次来管理闪存,这增加了系统设计和维护的复杂性。
调试困难
:由于其复杂的机制,UBI的问题排查和调试比传统文件系统更加困难。
(b)资源消耗
:
内存占用
:UBI需要额外的内存来维护其数据结构,对于内存资源有限的嵌入式系统可能会带来一定的压力。
CPU消耗
:UBI的运行需要额外的CPU资源来执行磨损均衡和垃圾回收等任务,可能会影响系统的整体性能。
(c)不适合所有应用
:
专用性强
:UBI主要针对原始闪存设备进行优化,对于使用其他存储介质(如eMMC、SD卡等)的系统,其优势可能不明显。
特定领域应用
:UBI的设计主要面向嵌入式系统,对于桌面或服务器系统,其他文件系统(如EXT4、XFS等)可能更为适合。
结尾
总的来说,UBI文件系统在需要高可靠性、高耐用性和灵活空间管理的嵌入式系统中表现出色,但其复杂性和资源消耗也需要在具体应用中进行权衡。
----------------End----------------
如需获取更多内容
请关注
liwen01
公众号