一、物理设备的命名规则
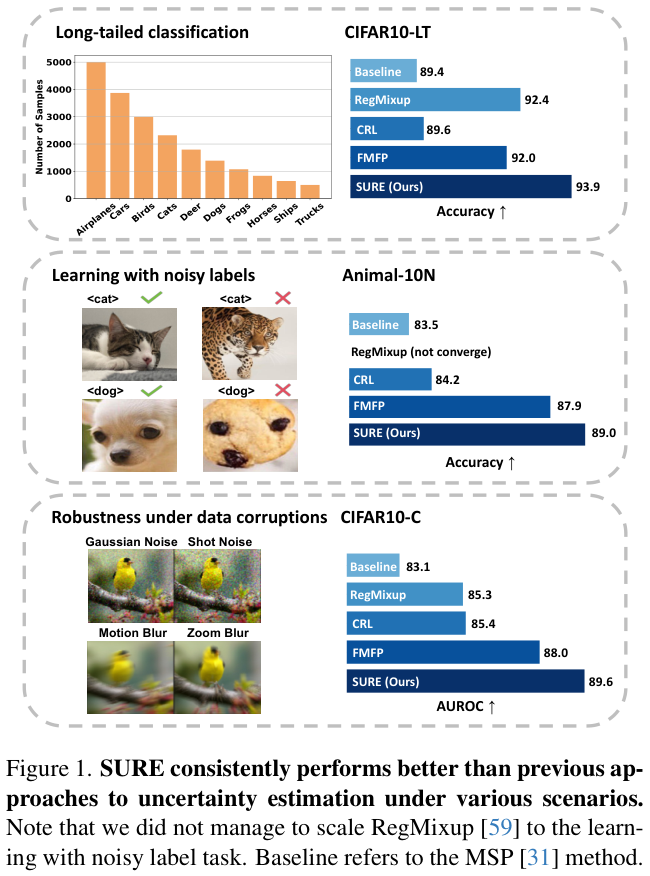
在 Linux 系统中一切都是文件,硬件设备也不例外。所有的硬件设备文件都在
/dev
文件夹中。
|
硬件
|
在Linux内的文件名
|
| SCSI/SATA/USB |
/dev/sd[a-p] |
| VirtI/O界面 |
/dev/vd[a-p] |
| 软盘 |
/dev/fd[0-1] |
| 打印机 |
/dev/lp[0-2] (25針印表機) /dev/usb/lp[0-15] (USB 介面) |
| 鼠标 |
/dev/input/mouse[0-15] (通用) /dev/psaux (PS/2界面) /dev/mouse (當前滑鼠) |
| CDROM/DVDROM |
/dev/scd[0-1] (通用) /dev/sr[0-1] (通用,CentOS 較常見) /dev/cdrom (當前 CDROM) |
| 磁带机 |
/dev/ht0 (IDE 界面) /dev/st0 (SATA/SCSI界面) /dev/tape (當前磁帶) |
| IDE设备 |
/dev/hd[a-d] (老系统才有) |
由于现在的 IDE 设备已经很少见了,所以一般的硬盘设备都是以“/dev/sd”开头。而一台主机上可以有多块硬盘,因此系统采用 a~z 来代表 26 块不同的硬盘(默认从 a 开始分配),而且硬盘的分区编号也很有讲究:
➢ 主分区或扩展分区的编号从 1 开始,到 4 结束;
➢ 逻辑分区从编号 5 开始。
有两点需要注意:
- 设备名称由内核识别顺序决定
:/dev 目录中 sda 设备之所以是 a,并不是由插槽决定的,而是由系统内核的识别顺序来决定的,而恰巧很多主板的插槽顺序就是系统内核的识别顺序,因此才会被命名为/dev/sda。
- 分区名称中的数字不代表分区数量
:比如sda3,它代表编号为3的分区,有可能不存在sda2,因为这个数字可以手动指定。
下图讲解了一个sata硬盘的名字所蕴含的信息

二、MBR和GPT分区格式
MBR和GPT是两种磁盘分区方式,当我们使用磁盘分区助手格式化硬盘的时候,它会提示你让你选择一种分区格式

1、 MBR分区
MBR分区方式出现的比较早,在Win7及Win7以前的系统都使用MBR分区方式,所以在磁盘管理界面,就能看到有主分区、逻辑分区等字眼

那MBR是什么呢?
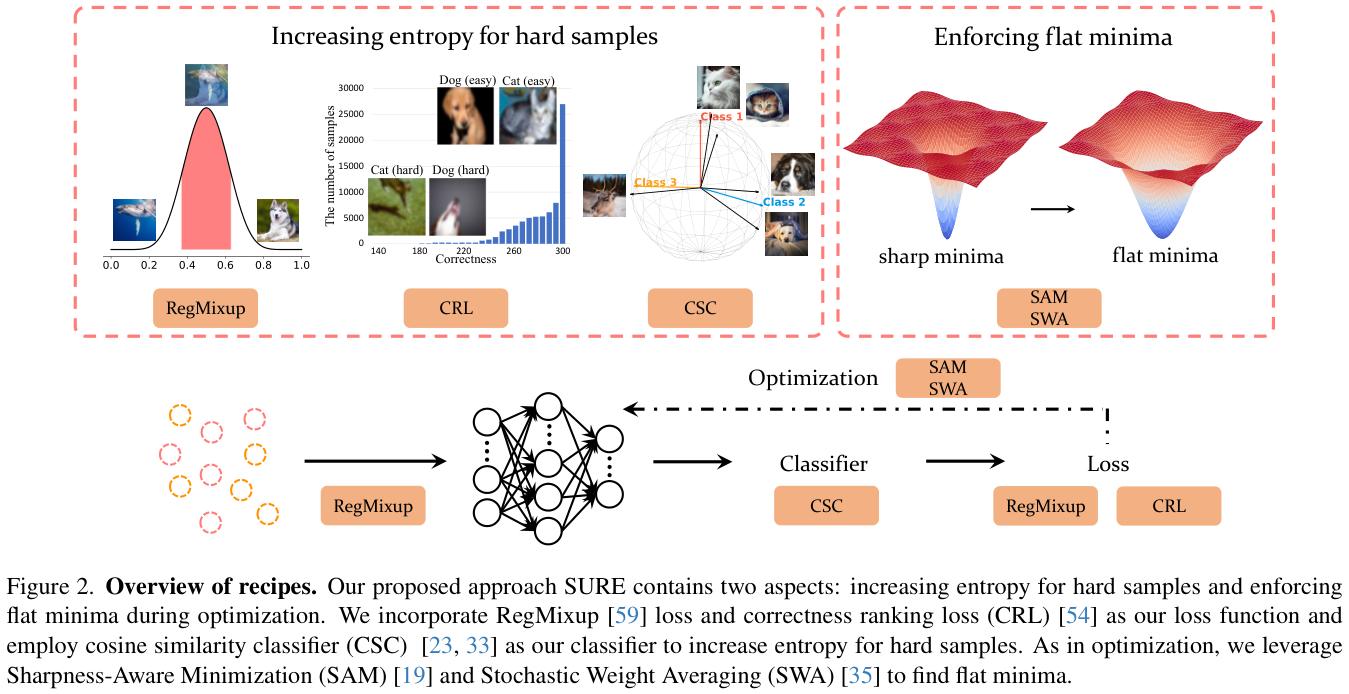
MBR,全称Master Boot Record, 主引导记录的意思,开机之后读取的第一个硬盘内容,帮助系统找到开机程序并正常开机。
硬盘由许多个扇区组成,MBR硬盘每个扇区的大小是512字节,最重要的第一个扇区格式如下所示

可以看到在第一个扇区中,MBR占据446个字节,结束符占2个字节,剩余64个字节用于存放分区表,每个分区表条目占用16字节,分区表中一共四条记录,代表着四个主分区。这也说明了为什么早期Windows7系统为什么在分区的时候会提示“该磁盘已包含最大分区数”不允许添加,因为早期Windows使用的MBR硬盘,它的设计只允许有4个主分区。
当然不可能只让创建四个分区,这不合理,所以可以让第四个分区变成扩展分区,在扩展分区内创建多个逻辑分区。
做个总结,在MBR硬盘中:
- 主分区最多只能有四个(硬盘的限制)
- 扩展分区最多只能有一个(操作系统的限制)
- 逻辑分区是扩展分区中持续切割出来的分割槽。
- 只有主分区和逻辑分区能被格式化,扩展分区无法被格式化。
- 逻辑分区的数量在不同的操作系统上上限不一样,Linux系统中SATA硬盘已经能够划分出63个以上的逻辑分区。
- 逻辑分区的编号从5开始,就算只有一个主分区一个扩展分区,那逻辑分区的编号也从5开始。
另外,磁盘分区表只有64字节大小,每条记录只有16字节大小,所以它能录的数据是很有限的,这导致它无法正确获取2.2TB以上硬盘的实际容量。
早期的 Linux 系统为了兼容于Windows 的磁盘,因此使用的是支持 Windows 的 MBR的方式来处理开机引导程序和分区表。
现在Linux系统安装的时候根据磁盘大小,如果安装磁盘小于2TB,则默认使用MBR初始化硬盘;大于2TB,则会使用GPT初始化硬盘。
当然,也可以在安装系统的时候强制使用GPT进行磁盘分区。
查看磁盘类型的命令:
fdisk -l

disk label type 如果是dos,就是mbr硬盘;如果是gpt,则为gpt硬盘。
2、 GPT分区
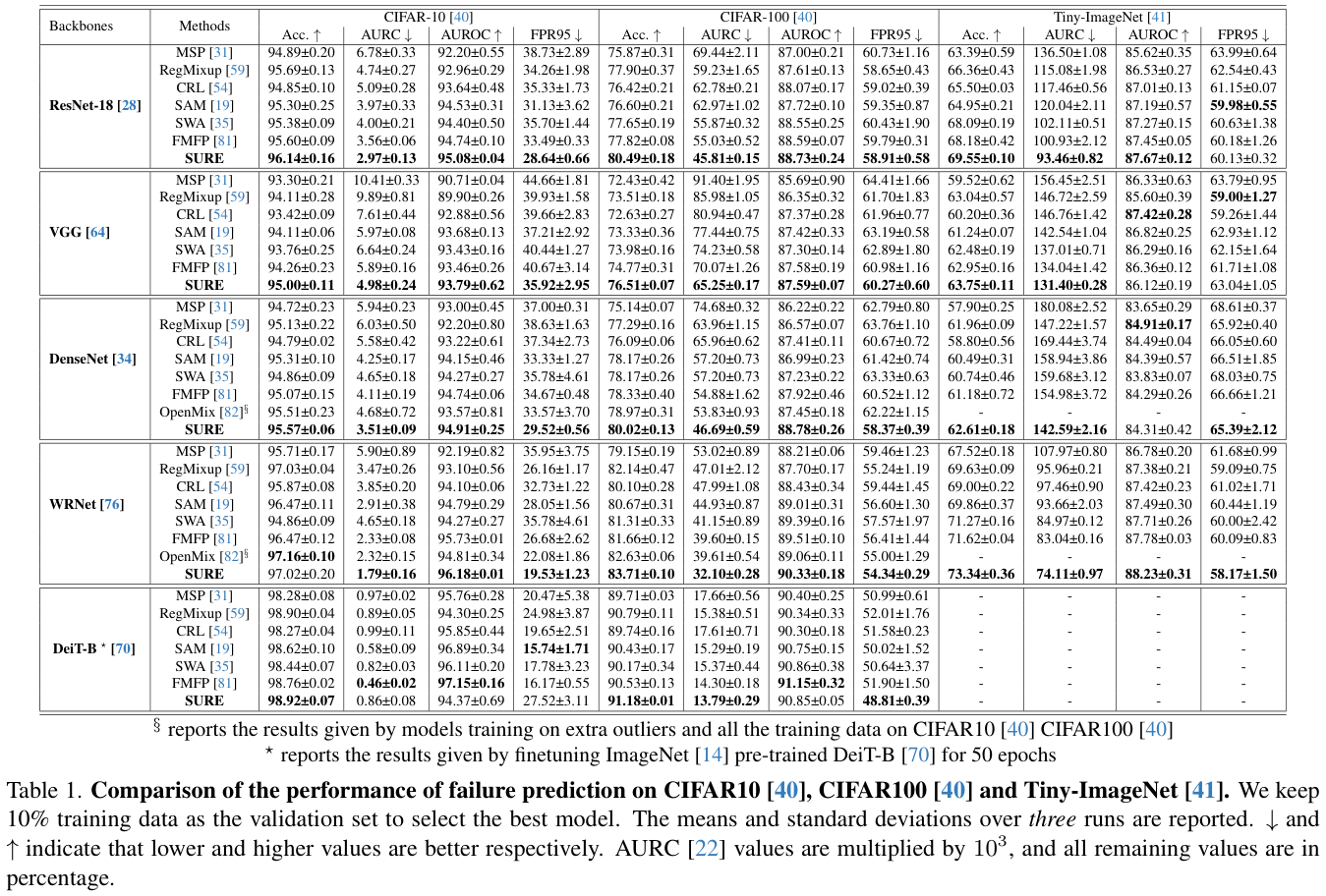
GPT分区(
GUID partition table
)模式使用GUID分区表,是源自EFI标准的一种较新的磁盘分区表结构的标准。与普遍使用的主引导记录(MBR)分区方案相比,GPT提供了更加灵活的磁盘分区机制。
GPT磁盘分区格式如下所示

在MBR分区中,一个扇区是512字节,在GPT分区中,用LBA(Logical Block Address)来表示“一个扇区”,默认大小也是512字节。整个GPT硬盘就是由N多个LBA组成。
GPT分区比较复杂,更多信息不在此讨论,只需要知道
- 分区表有32条记录,每条记录可以记录四个分区,所以它最多能有4*32=128个分区,所以它必要像MBR一样区分主分区、逻辑分区,在GPT中所有分区都是主分区。
- 最高支持18EiB的单硬盘容量,1EiB = 1048576 TiB。
GPT分区很明显比MBR分区要功能更强大;但是GPT分区在linux中不能使用fdisk命令进行管理,只能使用parted工具管理。
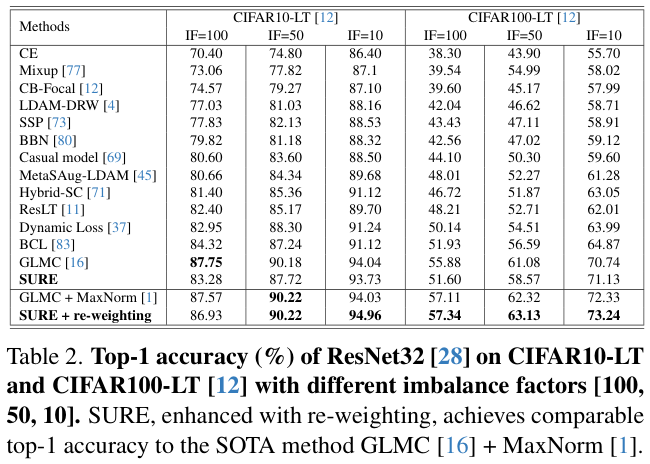
3、MBR和GPT分区的区别
|
磁盘分区形式
|
支持最大磁盘容量
|
支持分区数量
|
Linux分区工具
|
| 主启动记录分区(MBR) |
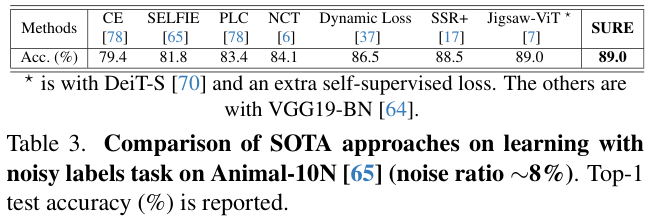
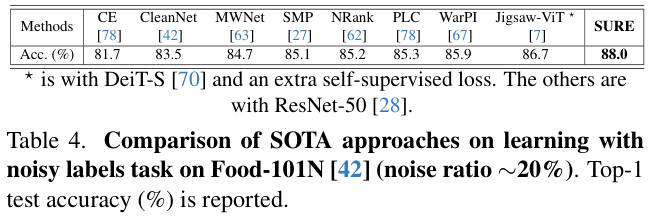
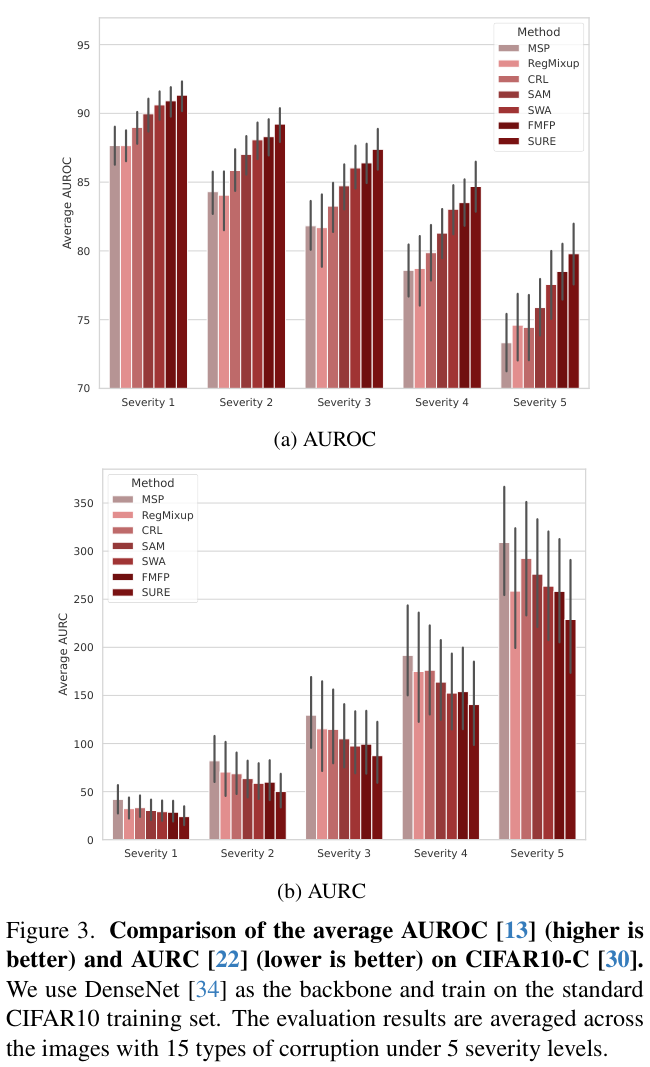
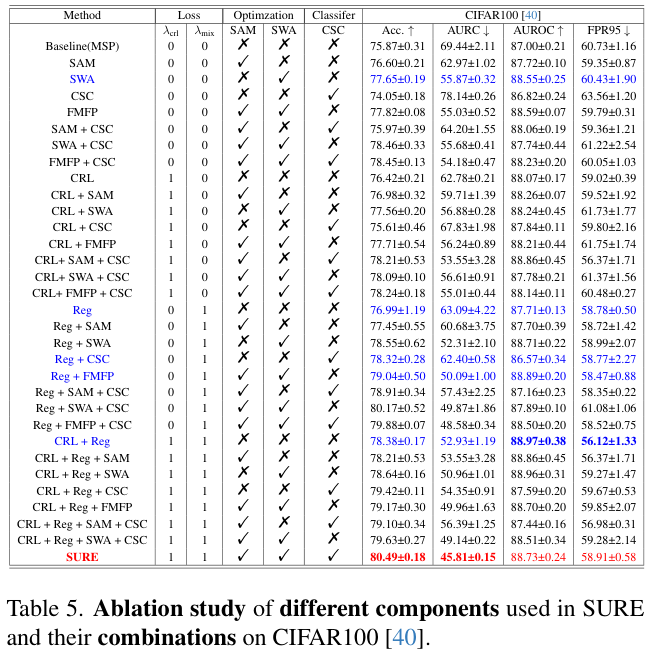
2 TiB |
● 4个主分区
● 3个主分区和1个扩展分区
MBR分区包含主分区和扩展分区,其中扩展分区里面可以包含若干个逻辑分区。扩展分区不可以直接使用,需要划分成若干个逻辑分区才可以使用。以创建6个分区为例,以下两种分区情况供参考:
● 3个主分区,1个扩展分区,其中扩展分区中包含3个逻辑分区。
● 1个主分区,1个扩展分区,其中扩展分区中包含5个逻辑分区。 |
以下两种工具均可以使用:fdisk工具parted工具 |
| 全局分区表(GPT, Guid Partition Table) |
18 EiB1 EiB = 1048576 TiB |
不限制分区数量
GPT格式下没有主分区、扩展分区以及逻辑分区之分。 |
parted工具 |
三、普通分区挂载
当我们有了一块新硬盘,从插入电脑开始,一共需要做分区、格式化、挂载三个步骤,下面就依次详细说说这个流程中的细节。
以下流程是基于Vmware Workstation环境做的实验。
1、新增硬盘
原来我已经有两块硬盘了,现在新增加一块12G的硬盘,只需要修改下设置,新增一块硬盘即可

然后开机启动,查看下dev文件夹,可以发现多出一个sdc文件,它就是第三块磁盘。

2、分区命令:fdisk
fdisk命令(format disk)用于新建、修改及删除磁盘的分区表信息,语法格式为
fdsk 磁盘名称
,它和大多数普通linux命令不同的是,它是一个交互式的命令,键入命令
fdisk /dev/sdc
,进入交互界面

进入交互界面之前,有两段英文提示
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x2394a4f6.
翻译成中文,包含以下几点
- 所有的改变都只是暂存在内存中,直到最后收到写入命令才依次执行内存中的操作。
- 当前设备不包含任何可识别的分区表,这意味着这是一块新设备,还没有分区过。
- 你要知道你正在做什么事情:进入此交互界面意味着你正在对当前磁盘进行分区操作,分区类型为dos,也就是MBR。
这段提示信息量还是有的,如果已经分区过的磁盘,则会提示如下信息

可以看到少了一些提示信息。
接下来看看该命令的怎么使用,它有提示,就是m命令。
m
m命令是首次提示的命令,它用于展示所有可用的命令以及每个命令的作用,键入m命令

翻译过来如下所示
a
:切换引导标志(toggle a bootable flag)。允许您在分区上切换引导标志,以指示该分区是否可引导。
b
:编辑BSD磁盘标签(edit bsd disklabel)。用于编辑BSD磁盘标签的命令。
c
:切换DOS兼容性标志(toggle the dos compatibility flag)。允许您在分区上切换DOS兼容性标志,以指示该分区是否与DOS兼容。
d
:删除一个分区(delete a partition)。用于删除选择的分区。
g
:创建一个新的空GPT分区表(create a new empty GPT partition table)。用于创建一个新的空GUID分区表(GPT)。
G
:创建一个IRIX(SGI)分区表(create an IRIX (SGI) partition table)。用于创建一个IRIX(SGI)分区表。
l
:列出已知的分区类型(list known partition types)。显示已知的分区类型列表。
m
:打印此菜单(print this menu)。打印
fdisk
命令的菜单,显示可用的操作选项。
n
:添加一个新分区(add a new partition)。用于添加新的分区。
o
:创建一个新的空DOS分区表(create a new empty DOS partition table)。用于创建一个新的空DOS分区表。
p
:打印分区表(print the partition table)。显示磁盘上的分区表。
q
:退出而不保存更改(quit without saving changes)。退出
fdisk
命令,不保存对分区表的更改。
s
:创建一个新的空Sun磁盘标签(create a new empty Sun disklabel)。用于创建一个新的空Sun磁盘标签。
t
:更改分区的系统ID(change a partition's system ID)。允许您更改选择的分区的系统ID。
u
:更改显示/输入单位(change display/entry units)。用于更改
fdisk
命令中显示和输入的单位。
v
:验证分区表(verify the partition table)。验证磁盘上的分区表以确保其有效性。
w
:将表写入磁盘并退出(write table to disk and exit)。将对分区表的更改写入磁盘并退出
fdisk
命令。
x
:额外功能(仅供专家使用)(extra functionality (experts only))。提供额外的高级功能,仅供有经验的用户使用。
p
p命令用于查看硬盘设备内已有的分区信息,其中包括了硬盘的容量大小、扇区个数等信息。

可以看到是空的,当前磁盘还没有分区过。
n
n命令用于创建分区,键入n命令

它会提示创建的是主分区还是扩展分区(因为是MBR分区格式,所以才会有主分区或者扩展分区),默认是主分区,那就键入回车就行

接下来提示分区编号,还是默认就行

回车后提示输入开始的扇区位置,默认值2048,这个地方敲回车即可,因为系统会自动计算出最靠前的空闲扇区的位置。

系统提示输入结束的扇区位置,这里输入
+2G
,表示要2G的分区大小,系统会自动计算出结束的扇区位置。
然后分区就创建成功了。输入p命令,可以看到多了一个分区,分区名为sdc1

w
w命令用于将分区表写入磁盘,这样就完成了对磁盘的分区。

有时候该命令执行完成之后,并不会将分区信息同步给内核,导致操作失败。可以使用
partprobe
命令手动同步分区信息到内核,多执行几次,如果还不行,就
重启
linux,重启之后肯定就好了。
3、格式化命令:mkfs
mkfs是linux的格式化操作的命令,mkfs双按tab键,可以看到它有多个衍生命令

现在linux都是xfs文件系统格式了,所以这里按照
mkfs.xfs
命令执行格式化操作,执行格式为:
mkfs.xfs /dev/sdc1

这样就完成了格式化操作,接下来进行系统挂载。
4、挂载命令:mount
mount命令是挂载命令,将分区挂载到某个目录,这样对目录中文件的CRUD操作就作用到了对应的分区上。
mount命令的格式是:
mount 分区名 文件夹
或者
mount UUID=分区UUID 文件夹
首先先建立个文件夹:
mkdir /dir3
,然后将
/dev/sdc1
挂载到
/dir3
,挂载命令为:
mount /dev/sdc1 /dir3
这样就完成了挂载。
UUID挂载方式需要知道分区的UUID,获取方式是使用
blkid
命令
5、获取分区UUID:blkid
blkid的英文全称是:block id,该命令用于获取每个分区的UUID信息;有时候该命令会受到缓存的影响设设备列表可能不会更新,使用
blkid -g
命令可以清除缓存。

然后使用命令
mount UUID="74cbf319-cb9f-417e-9027-5328689477c1" /dir3
完成挂载。
需要注意的是mount命令只能一次挂载,重启系统之后挂载就会失效,需要将挂载写入
/etc/fstab
文件,这样才能完成分区的永久性挂载。
5、永久挂载:/etc/fstab文件
/etc/fstab文件存放着需要永久挂载的数据,系统启动之后会自动读取该文件,并完成文件中的所有挂载。写入格式如下
设备文件 挂载目录 格式类型 权限选项 是否备份 是否自检

为了将/dev/sdc1永远挂载到/dir3目录,需要将以下信息追加到/etc/fstab文件
/dev/sdc1 /dir3 xfs defaults 0 0
写入该文件并不会自动生效,需要使用命令
mount -a
或者重启系统生效。
已经实现了/dev/sdc1挂载到/dir3目录,接下来使用
df
命令查看挂载状态和硬盘使用量信息。
6、磁盘使用情况统计:df
df命令(disk free)用于显示目前在Linux系统上的文件系统磁盘使用情况,其使用格式为
df [选项]... [FILE]...
-a, --all
:显示所有文件系统,包括虚拟文件系统。
-B, --block-size=SIZE
:指定块大小,以特定单位显示磁盘空间信息(如 MB、GB)。
-h, --human-readable
:以人类可读的格式显示输出结果。
-H, --si
:以 1000 作为基数,以 SI 单位显示输出结果(例如,MB、GB)。
-i, --inodes
:显示 inode 使用情况而不是块使用情况。
-k, --kilobytes
:以 KB 作为单位显示磁盘空间信息。
-l, --local
:仅显示本地文件系统。
-m, --portability
:使用 POSIX 输出格式。
-n, --no-sync
:不执行文件系统同步操作。
-P, --portability
:使用 POSIX 输出格式。
-t, --type=TYPE
:仅显示指定类型的文件系统。
-T, --print-type
:显示文件系统的类型。
-x, --exclude-type=TYPE
:排除指定类型的文件系统。
--sync
:在显示文件系统信息之前执行文件系统同步操作。
--total
:在输出的最后一行显示总计。
-v, --verbose
:详细显示文件系统信息。
-l, --local
:仅显示本地文件系统。
--help
:显示帮助信息并退出。
--version
:显示版本信息并退出。
最常用的命令就是
df -h
了,接下来使用该命令查看磁盘使用量情况

可以看到sdc1已经挂载到了/dir3目录还剩余2G存储可用。这样看起来似乎不是非常直观,总觉得有点乱,使用
lsblk
命令则能够更直观的看到每个磁盘以及它们的分区情况和分区大小。
7、树状展示硬盘分区:lsblk
lsblk命令的英文全称是:list block,实际上它就是以树状结构展示磁盘分区情况,这样会更直观

8、查看文件占用大小:du
du(disk usage)命令用于查看分区或者目录所占用的磁盘大小,常用的命令:
du -sh 目录名
,比如
du -sh /*
,这样就能查询到根目录的所有文件和文件夹占用磁盘的大小
s: 仅显示指定目录或文件的总大小,而不显示其子目录的大小。
h:--human-readable 以K,M,G为单位,提高信息的可读性。

s参数比较重要,没有它的话,默认du命令会递归查询所有文件夹及子文件夹、子文件,疯狂打印到屏幕上,显得非常乱,所以如果没有特殊需要,一般是要加-s参数的。
四、交换分区挂载
1、新建分区
交换(SWAP)分区是一种通过在硬盘中预先划分一定的空间,然后把内存中暂时不常用的数据临时存放到硬盘中,以便腾出物理内存空间让更活跃的程序服务来使用的技术,其设计目的是为了解决真实物理内存不足的问题。通俗来讲就是让硬盘帮内存分担压力。但由于交换分区毕竟是通过硬盘设备读写数据的,速度肯定要比物理内存慢,所以只有当真实的物理内存耗尽后才会调用交换分区的资源。
在生产环境中,交换分区的大小一般为真实物理内存的 1.5~2 倍。
接下来切出一个大小为5G的分区用于扩容交换分区。

这样就得到了一个5G的新分区sdc2。接下来修改该分区类型,将其改为
swap
类型

最后,敲击w完成分区表编辑。
接下来键入lsblk命令,可以看到sdc2分区已经存在了

2、格式化交换分区:mkswap
交换分区使用前也要格式化,只是它的格式化命令不是mkfs,而是mkswap,英文全称是"make swap",语法格式是"mkswap 设备名称"

这样就完成了交换分区格式化。
3、激活交换分区:swapon
swapon命令用于激活新的交换分区设别,英文全称为“swap on”,语法格式为:
swapon 设备名称
接下来执行命令:swapon /dev/sdc2
为了验证是否扩容成功,可以使用命令
free -m
查看内存和交换分区的大小
4、查看内存和交换空间大小:free
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。共享内存将被忽略。
命令参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。

可以看到扩容之后交换空间扩大了5G。
5、修改fstab永久挂载
之前的一次分区普通挂载的配置是这样的
/dev/sdc1 /dir3 xfs defaults 0 0
swap分区的挂载则是这样的
/dev/sdc2 swap swap defaults 0 0
也就是挂载目标变成了swap,而非一个目录;文件系统类型也是swap,而非普通分区的xfs格式。
之后运行命令
mount -a
或者重启系统即可生效。
五、卸载分区
1、卸载普通分区
其实就是逆向操作,首先,删除fstab中的记录

然后
umount
命令卸除挂载
umount /dev/sdc1
然后删除分区

之后,再用
lsblk
命令查看下分区,发现sdc1已经没了,sdc硬盘下只剩下了sdc2分区。

2、卸载交换分区
还是老规矩,先从fstab文件中删除交换分区的挂载信息

然后运行命令
swapoff
关闭指定的交换分区
swapoff /dev/sdc2
最后,删除分区,删除分区的方法和卸载普通分区一样。
删除完毕之后,再看sdc磁盘分区,就发现该磁盘已经没有分区了

这时候就可以安全移除磁盘了。
如果没有争取的卸载磁盘,有可能会导致开机失败的情况,这点需要注意。
最后,欢迎关注我的博客:
https://blog.kdyzm.cn