SURE:增强不确定性估计的组合拳,快加入到你的训练指南吧 | CVPR 2024
论文重新审视了深度神经网络中的不确定性估计技术,并整合了一套技术以增强其可靠性。论文的研究表明,多种技术(包括模型正则化、分类器改造和优化策略)的综合应用显着提高了图像分类任务中不确定性预测的准确性
来源:晓飞的算法工程笔记 公众号
论文: SURE: SUrvey REcipes for building reliable and robust deep networks

Introduction
深度神经网络 (
DNNs
) 已成为结构化数据预测任务中强大且适应性高的工具,但准确评估其预测的可靠性仍然是一个巨大的挑战。在医疗诊断、机器人、自动驾驶和地球观测系统等关键安全领域,过度自信的预测的决策可能会导致严重的后果。因此,确保基于
DNN
的人工智能系统的鲁棒性至关重要。
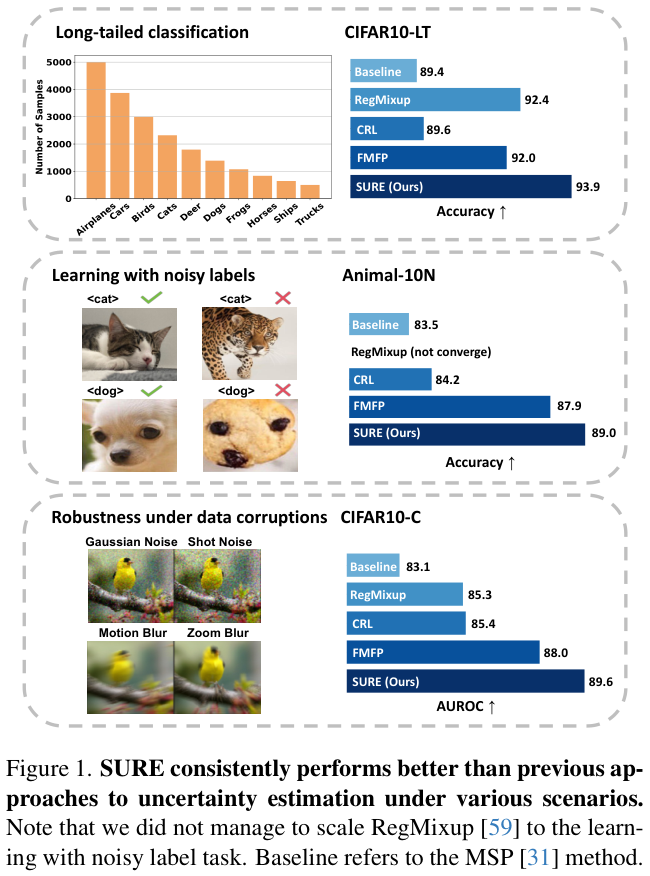
解决深度学习中的过度自信问题一直是重大研究工作的焦点,但目前很多方法的一个关键限制是测试场景有限,通常仅限于单个预定义任务(例如故障预测或分布外检测(
OOD
))的基准数据集。这些方法在涉及更复杂的现实情况时(如数据损坏、标签噪声或长尾类分布等),其有效性仍很大程度上尚未得到充分探索。而且通过实验表明,没有一种方法能够在不同的场景中表现一致。为此,论文提出了一个有效解决所有这些挑战的统一模型。
在论文追求增强不确定性估计的过程中,论文首先检查几种现有方法的综合影响,从而发现一种可以显着改进的综合方法。根据这些方法在模型训练过程中的功能对进行分类:
- 正则化和分类器:利用
RegMixup
正则化、正确性排名损失 (
CRL
) 和余弦相似性分类器 (
CSC
) 等技术,这有助于增加具有挑战性的样本的熵。 - 优化策略:按照
FMFP
的建议结合了锐度感知最小化 (
SAM
) 和随机权重平均 (
SWA
),确保模型能够收敛到更平坦的最小值。
这些不同技术的协同整合最终形成了论文的新颖方法
SURE
,该方法利用了每个单独组件的优势,产生了更加稳健和可靠的模型。
在评估
SURE
时,论文首先关注错误预测(
failure prediction
),这是评估不确定性估计的关键任务。结果表明,
SURE
始终优于部署单独技术的模型。这种卓越的性能在
CIFAR10
、
CIFAR-100
、
Tiny-ImageNet
等各种数据集以及
ResNet
、
VGG
、
DenseNet
、
WideResNet
和
DeiT
等各种模型架构中都很明显。值得注意的是,
SURE
甚至超越了
OpenMix
,这是一种利用额外
OOD
数据的方法。通过将
SURE
直接应用到现实场景中,无需或只进行很少的特定于任务的调整,进一步见证了在为模型带来鲁棒性方面的有效性。具体来说,现实世界的挑战包括
CIFAR10-C
中的数据损坏、
Animal-10N
和
Food-101N
中的标签噪声以及
CIFARLT
中的类分布倾斜。在这些背景下,
SURE
取得的结果要么优于最新的方法,要么与最新的方法相当。
SURE
在
Food-101N
上达到了 88.0% 的令人印象深刻的准确率,显着超过了之前最先进的方法
Jigsaw-ViT
,该方法通过使用额外的预训练数据达到了 86.7% 的准确率,这证明了
SURE
在处理复杂的现实数据挑战方面的卓越能力。
本文的主要贡献总结如下:
- 实验证明现有方法在应对各种现实挑战时并不总能表现出色,需要更可靠、更稳健的方法来处理现实世界数据的复杂性。
- 提出用于鲁棒的不确定性估计的新颖方法
SURE
,结合模型正则化、分类器和优化策略等多种技术所实现的协同效应。在
SURE
方法下训练的模型在故障预测方面始终比在各种数据集和模型架构中部署单独技术的模型取得更好的性能。 - 直接应用于现实场景时,
SURE
始终表现出至少与最先进的方法相当的性能。
Methods
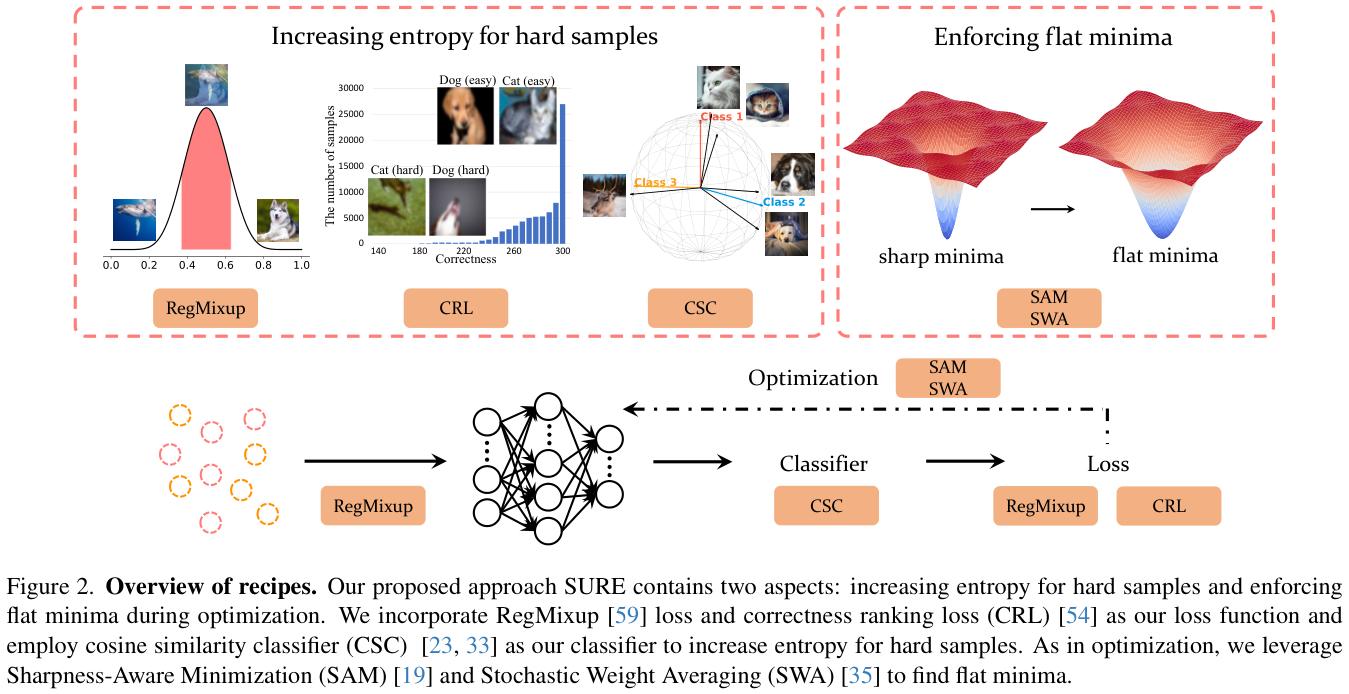
如图 2 所示,
SURE
旨在通过两个方面训练可靠且鲁棒的
DNN
:i)增加难样本的熵; ii) 在优化过程中强制寻找平坦极值(
flat minima
)。
定义
\(\{(\mathbf{x}_{i},\mathbf{y}_{i})\}_{i=1}^{N}\)
表示数据集,其中
\(\mathbf{x}_{i}\)
是输入图像,
\(\mathbf{y}_{i}\)
是其标签,
\(N\)
是样本数。
SURE
中增加难样本熵的方法由三个部分组成:
- 增加
RegMixup
正则化
\(\mathcal{L}_{mix}\)
,通过数据增强添加难样本。 - 增加正确性排名损失
\(\mathcal{L}_{crl}\)
,通过将实例的置信度与正确预测次数比例进行排序对齐来正则化类概率。 - 在分类的交叉熵损失
\({\mathcal{L}}_{ce}\)
使用余弦相似度分类器(
CSC
)的结果作为输入,可以更好地表达难样本。
此外,为了平坦极值,在优化过程中使用锐度感知最小化 (
SAM
) 和随机权重平均 (
SWA
)。
Increasing entropy for hard samples
Total loss
如上所述,
SURE
的目标函数由三部分组成,表示为:
\[\mathcal{L}_{total}=\mathcal{L}_{ce}+\lambda_{mix}\mathcal{L}_{mix}+\lambda_{crl}\mathcal{L}_{crl}
\quad\quad (1)
\]
RegMixup regularization
Mixup
是一种广泛用于图像分类的数据增强方法。
给定两个输入目标对
\((\mathbf{x}_{i},\mathbf{y}_{i})\)
和
\((\mathbf{x}_{j},\mathbf{y}_{j})\)
,通过线性插值来获得增强样本
\((\tilde{\mathbf{x}}_{i}, {\tilde{\mathbf{y}}}_{i})\)
:
\[\tilde{{\bf x}}_{i}=m{\bf x}_{i}+(1-m){\bf x}_{j},\quad\tilde{{\bf y}}_{i}=m{\bf y}_{i}+(1-m){\bf y}_{j}
\quad\quad (2)
\]
其中
\(m\)
表示混合系数,遵循
Beta
分布:
\[m\sim\mathrm{Beta}(\beta,\beta),~~~\beta\in(0,\infty)
\quad\quad (3)
\]
RegMixup
正则化
\(\mathcal{L}_{mix}\)
计算增强样本的损失值:
\[\mathcal{L}_{mix}(\tilde{\bf x}_{i},\tilde{\bf y}_{i})=\mathcal{L}_{ce}(\tilde{\bf x}_{i},\tilde{\bf y}_{i})
\quad\quad (4)
\]
设置
\(\beta=10\)
,确保两个样本高度混合。
与
RegMixup
类似,将
\(\mathcal{L}_{mix}\)
作为附加正则化器,与
\((\mathbf{x}_{i},\mathbf{y}_{i})\)
上的原始交叉熵损失
\(\mathcal{L}_{ce}\)
一起使用。 较高的
\(\beta\)
值会导致样本严重混合,促使模型在大量的插值样本上表现出高熵,增加训练的挑战性。
Correctness ranking loss
正确性排名损失鼓励
DNN
将模型的置信度与训练期间收集的正确预测比例信息保持一致(即经常预测正确的图像,其置信度也应该高于不经常预测正确的图像)。
对于两个输入图像
\(\mathbf{x}_{i}\)
和
\(\mathbf{x}_{j}\)
,
\(\mathcal{L}_{crl}\)
的定义为:
\[{\mathcal{L}}_{crl}(\mathbf{x}_{i},\mathbf{x}_{j})=\operatorname*{max}(0,|c_{i}-c_{j}|-\operatorname{sign}(c_{i}-c_{j})(\mathbf{s}_{i}-\mathbf{s}_{j}))
\quad\quad (5)
\]
其中
\(c_{i}\)
和
\(c_{j}\)
表示训练期间
\(\mathbf{x}_{i}\)
和
\(\mathbf{x}_{j}\)
被正确预测的比例,
\(\mathbf{s}_{i}\)
和
\(\mathbf{s}_{j}\)
表示
\(\mathbf{x}_{i}\)
和
\(\mathbf{x}_{j}\)
的置信度得分,即
softmax
得分,
sign
表示符号函数。
\(\mathcal{L}_{crl}\)
旨在将置信度得分与正确性统计数据对齐,难样本在训练过程中不太可能被正确预测,因此鼓励其具有较低的置信度,从而具有较高的熵来进行反向更新。
Cosine Similarity Classifier (CSC)
CSC
通过简单地用余弦分类器替换最后一个线性层,在少样本分类中有不错效果。简单而言就是每个类学习一个原型向量,将其与图像的特征网络输出进行余弦相似计算,将结果作为预测分数。
对于图像
\(\mathbf{x}_{i}\)
,分类向量中对应
\(k\)
类的单元表示为
\(\mathbf{s}_{i}^{k}\)
,其定义如下:
\[\mathrm{s}_{i}^{k}=\tau\cdot\mathrm{cos}(f_{\theta}(\mathbf{x}_{i}),w^{k})=\tau\cdot\frac{f_{\theta}(\mathbf{x}_{i})}{||f_{\theta}(\mathbf{x}_{i})||_{2}}\cdot\frac{w^{k}}{||w^{k}||_{2}},
\quad\quad (6)
\]
其中
\(\tau\)
是温度超参数,
\(f_{\theta}\)
是
\(\theta\)
参数化的
DNN
网络,用于提取输入图像的特征,
\(w^{k}\)
代表第
\(k\)
类的原型向量。
CSC
鼓励分类器关注从输入图像提取的特征向量与类原型向量之间的方向对齐,这使得它在概念上不同于传统的线性分类器。传统的线性分类器中关注点积得出的幅值(用于进行
softmax
),而
CSC
仅关注其方向是否一致。
CSC
的一个主要好处是能够更好地处理难样品,将难样本视为与多个类原型向量在余弦角度相等,从而比使用点积的传统线性分类器提供更有效的可解释性和潜在更高的熵。
Flat minima-enforced optimization
论文联合采用锐度感知最小化(
SAM
)和随机权重平均(
SWA
)来增强平面最小值。
Sharpness-Aware Minimization (SAM)
由于参数量巨大,深度模型存在较多的局部极值,而优化过程就是在寻找其中一个极值。一般认为,平坦的极值比尖锐的极值的泛化能力更强。为此,
SAM
通过寻找邻域平坦的参数来增强模型泛化能力,从而使
DNN
具有一致的小损失,避免陷入尖锐的局部极值。
对于论文的目标函数
\({\mathcal{L}}_{total}\)
和
DNN
参数
\({\boldsymbol{\theta}}\)
,
SAM
优化器寻求满足以下公式的
\(\theta\)
:
\[\underset{\theta}{\mathrm{min}}\underset{||\epsilon||_2\leq\rho}{\mathrm{max}} \mathcal{L}_{total}(\theta+\epsilon)
\quad\quad(7)
\]
其中
\(\epsilon\)
是扰动向量,
\(\rho\)
是论文寻求最小化损失锐度的邻域大小。
SAM
算法在
\(\ell_2\)
范数小于
\(\rho\)
的范围内寻找使损失最大化的扰动向量
\(\epsilon\)
(此过程需要基于
\(\theta\)
产生的梯度进行计算),然后基于
\(\theta + \epsilon\)
产生的新梯度反向更新模型参数
\(\theta\)
,交替进行上面两个步骤来最小化扰动损失。
Stochastic Weight Averaging (SWA)
SWA
通过在训练过程中平均模型权重来提高
DNN
的泛化能力。
从标准训练阶段开始,
SWA
开始对后续每个周期的权重进行平均,权重更新为:
\[\theta_{\mathrm{SWA}}=\frac{1}{T}\sum_{t=1}^{T}\theta_{t}
\quad\quad(8)
\]
其中
\(\theta_{t}\)
表示
\(t\)
周期时的模型权重,
\(T\)
是应用
SWA
的周期总数。
Implementation details
使用以随机梯度下降(
SGD
)作为基础优化器的
SAM
进行训练,动量为 0.9,初始学习率为 0.1,权重衰减为 5e-4,采用余弦退火学习率策略,数据批次大小为128。总共训练 200 个周期,
SWA
起始周期设置为 120,将
SWA
的学习率设置为 0.05,以增强训练的有效性和模型鲁棒性。设置公式 (3) 中的
\(\beta\)
= 10 以进行混合数据增强,所有超参数(包括
\(\lambda_{mix}\)
、
\(\lambda_{crl}\)
和
\(\tau\)
)均根据验证集表现上进行调整。
在对
ImageNet
预训练模型
DeiT-Base
进行微调时,设置学习率为 0.01,在 50 个周期内权重衰减为 5e-5,
SWA
开始周期为 1,学习率为 0.004。
Experiments
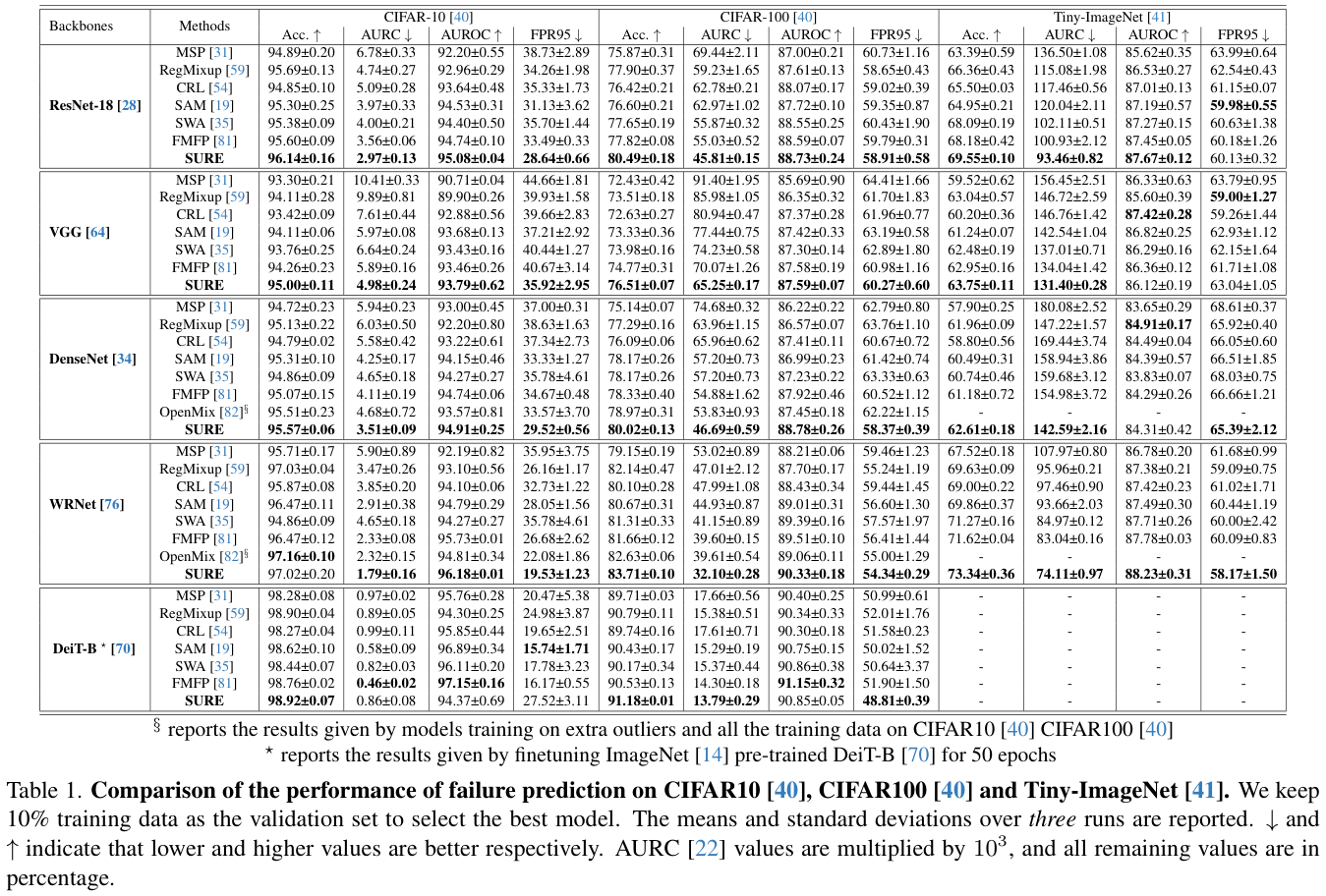
表 1 中展示了
CIFAR10
、
CIFAR100
和
Tiny-ImageNet
上的故障预测结果。
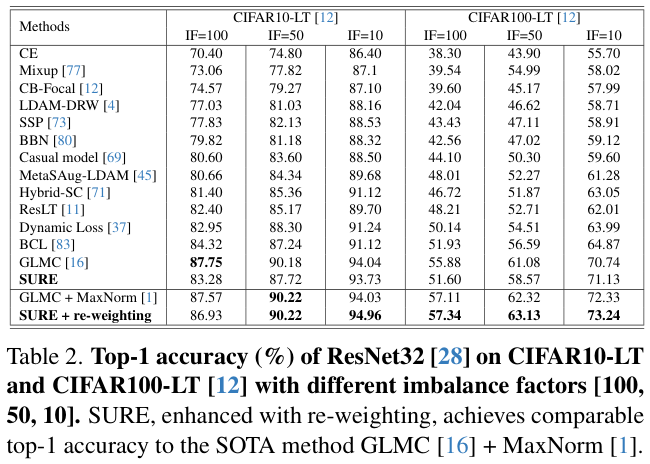
表 2 展示了在长尾数据集
CIFAR10-LT
和
CIFAR100-LT
与最先进方法比较。
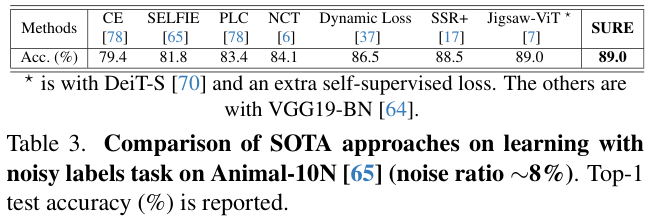
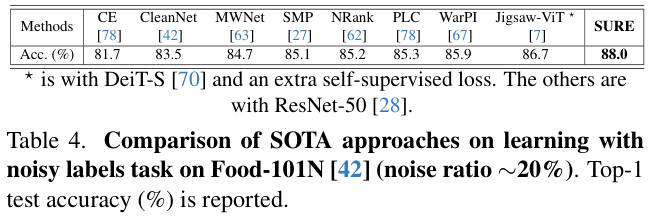
表 3 和表 4 展示了在含噪声标签的
Animal-10N
和
Food-101N
上的 top-1 准确率。
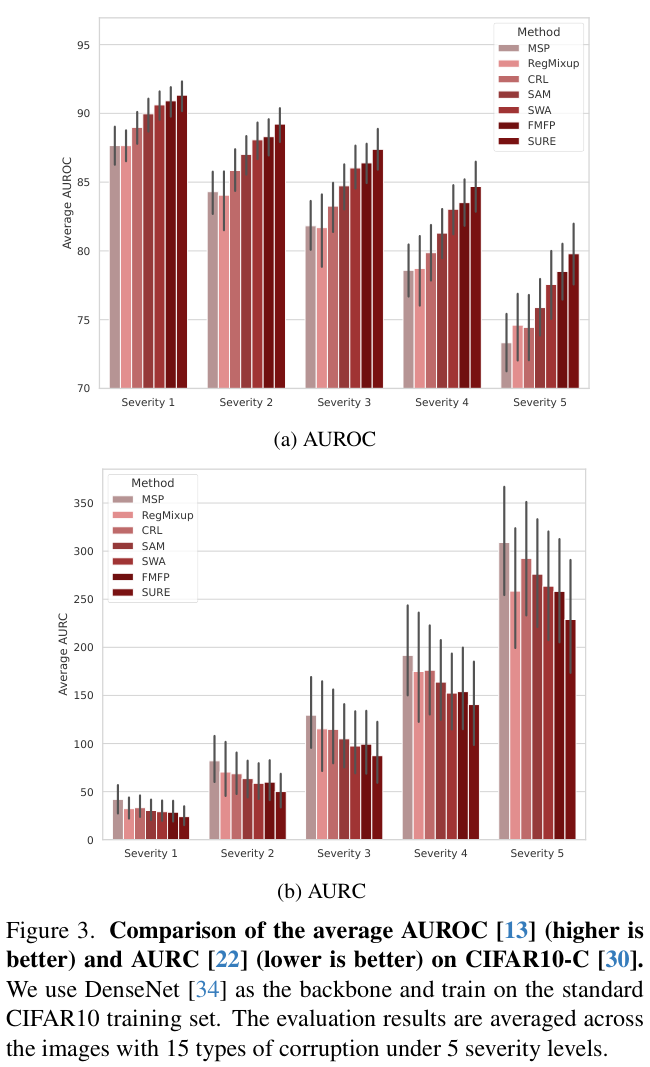
在实际应用中,环境条件容易频繁变化,例如天气从晴朗到多云,再到下雨。对于模型来说,在这种分布或领域偏移下保持可靠的决策能力至关重要。图 3 展示了在偏移数据集
CIFAR10-C
上评估使用
CIFAR10
的干净训练集训练的模型的性能比较。
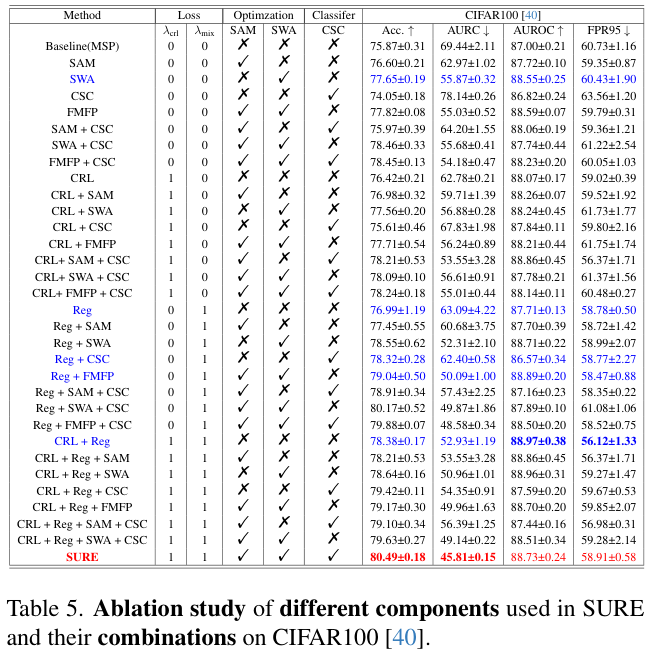
论文在表 5 中分析了每个组件对
SURE
在
CIFAR100
上的性能贡献。
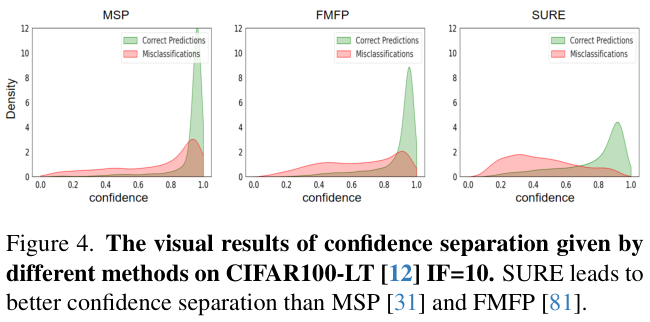
图 4 中可视化了
CIFAR100-LT IF=10
上的置信度分布,
SURE
明显比
MSP
和
FMFP
带来更好的置信度分离。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
