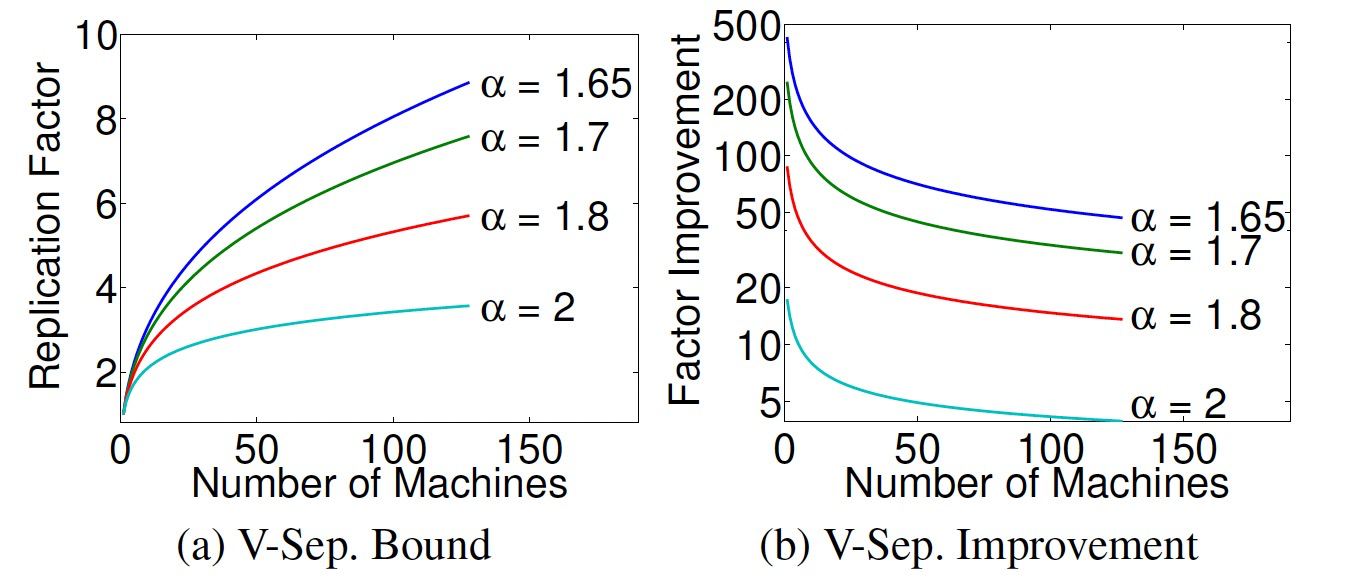
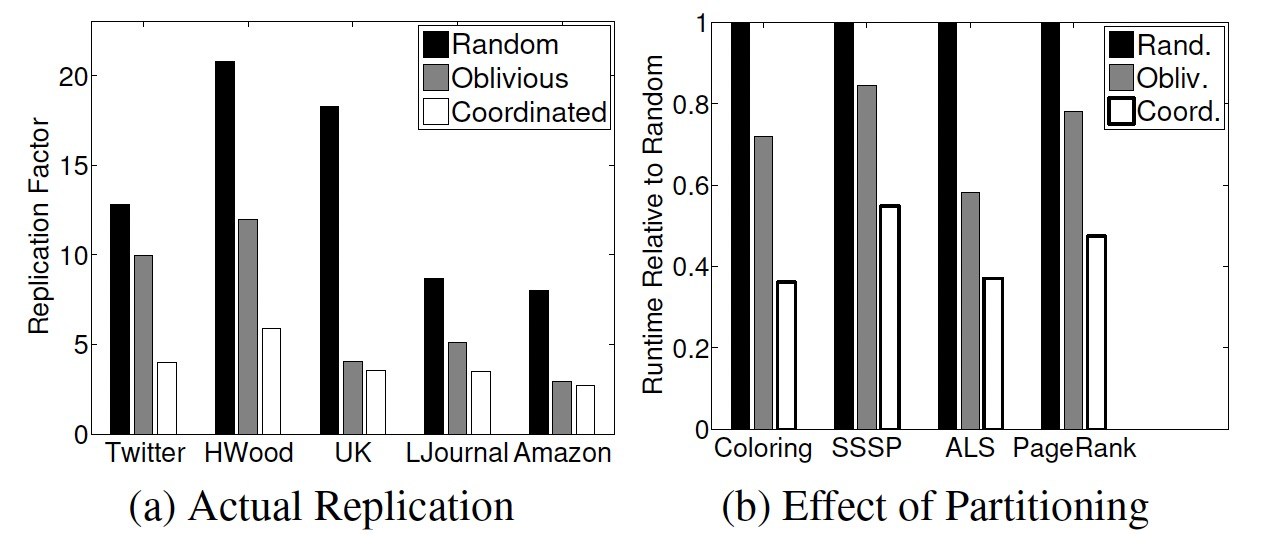
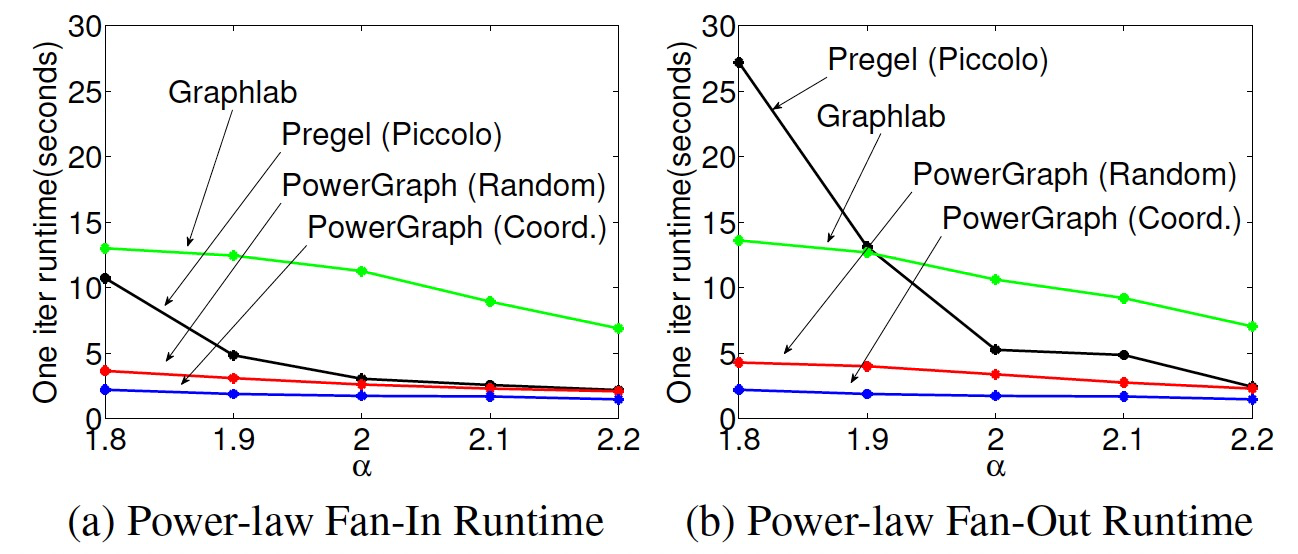
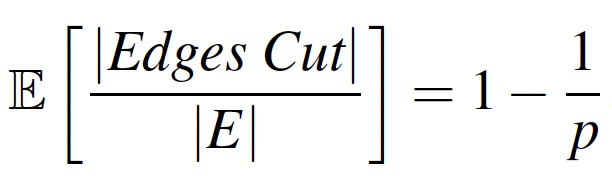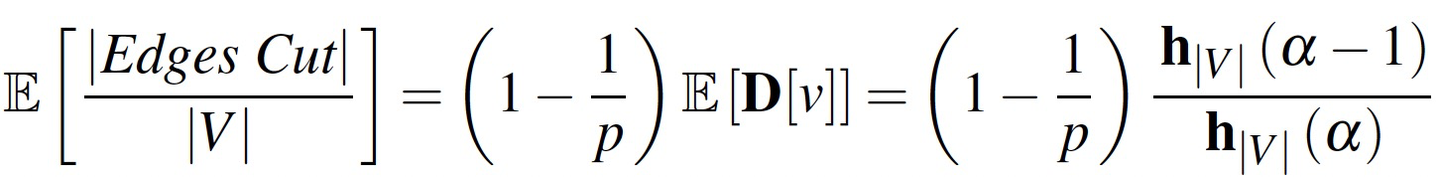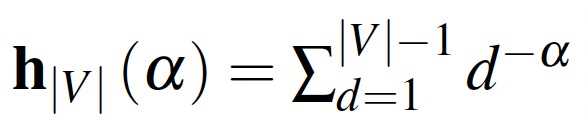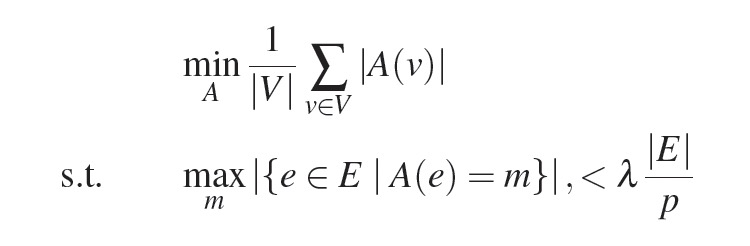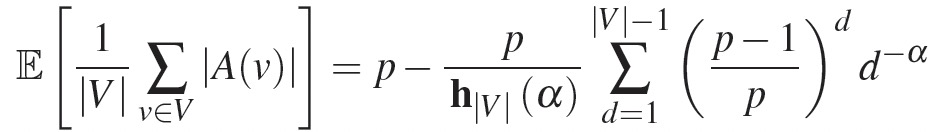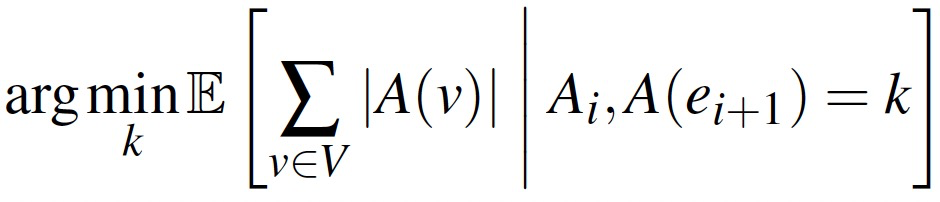1 PDU 概述
在电信领域,
协议数据单元(PDU)
[1]
是指在计算机网络的对等实体之间传输的单个信息单元。它由协议特定的
控制信息
和
用户数据
组成。在通信协议栈的分层架构中,每一层都实现针对特定类型或数据交换模式定制的协议。
例如,传输控制协议(TCP)实现了面向连接的传输模式,该协议的 PDU 被称为段,而用户数据协议(UDP)则使用数据包作为 PDU 进行无连接通信。在互联网协议族的较底层,即互联网层,PDU 被称为数据包,而不考虑其有效载荷类型。
本文将以一些列的例子来了解 GNU Radio 的 PDU 相关操作。为我们使用数字调制传输文件、音频、视频等数据打好基础。
2 Demo 详解
2.1 Random PDU Generator
该块在启动时发送一次随机 PDU,然后每次收到消息时发送,第一个 demo 如下
pdu_simple_demo1_random.grc
:
[2]

运行后,每隔 2S 产生一个 PDU:
message_debug :info: The `print_pdu` port is deprecated and will be removed; forwarding to `print`.
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 110 bytes
pdu vector contents =
0000: 69 e4 6c f5 94 8c 28 23 c3 26 3a 41 cf d7 fd 41
0010: 55 d0 4c 3e 03 ed 37 59 e8 32 d9 40 f4 9d c7 79
0020: fc 5a 11 d4 cb 95 98 8c bb ea b1 49 ae c1 64 c0
0030: 8f 61 35 91 87 13 67 0d 5a 87 97 c7 5b ef f7 21
0040: 27 91 65 78 63 03 ba 56 63 29 ed cb 6f 4f dc 87
0050: 9e 2a 1e 9a 78 43 57 a7 87 b0 b7 bf fd 73 b8 15
0060: e9 3a 81 e9 8e 27 80 d3 76 89 8b ff 72 14
************************************
其四个参数分别影响:PDU 长度范围最少为 15,最大为 150 字节,mask 与 pdu 每一字节做 AND 操作,总长度必须是
Length Modulo
的倍数。
2.2 Async CRC32
在 3.10 版本该块已经被
CRC_Append
和
CRC_Check
替换。
[4]
该块用于处理异步消息的字节流,可以选择 create 模式和 check 模式:
- create:在 pdu 数据后面多加 4 字节,即输入数据的 CRC32
- check:计算输入数据的 LEN(PDU)-4 的 CRC32 和 PDU 最后 4 字节是否相等,相等输出去除 CRC32 的数据,不相等没有输出。
例子如下
tx_stage1.grc
:

输出 LOG:
Press Enter to quit: ***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 44 bytes
pdu vector contents =
0000: 22 e7 d5 20 f8 e9 38 a1 4e 18 8c 47 30 8c fe f5
0010: ff f7 f7 28 b9 f8 fb f5 1c 7c cc cc 4c 24 01 6b
0020: 1c ea a3 ca e0 f5 80 a7 cc 09 5c d9
************************************
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 48 bytes
pdu vector contents =
0000: 22 e7 d5 20 f8 e9 38 a1 4e 18 8c 47 30 8c fe f5
0010: ff f7 f7 28 b9 f8 fb f5 1c 7c cc cc 4c 24 01 6b
0020: 1c ea a3 ca e0 f5 80 a7 cc 09 5c d9 db 73 02 76
************************************
一个数据帧一般由
帧头 + 内容 + 校验(帧尾)
构成,这个例子介绍如何添加帧头
tx_stage3.grc
:

1)Default Header Format Obj
Default Header Format Obj
[14]
用于 PDU 格式化的默认标头格式化程序。用于处理默认的数据包头。默认标头由访问代码和数据包长度组成。长度被编码为重复两次的 16 位值:
| access code | hdr | payload |
当 access code <= 64 bits 时 hdr 为:
| 0 -- 15 | 16 -- 31 |
| pkt len | pkt len |
访问代码和标头按照网络字节顺序进行格式化。
该标头生成器不会计算 CRC 或将 CRC 附加到数据包中。在添加标头之前,请使用 CRC32 异步块。
因此:
流程图中的设置意义如下:
- Access Code:'10101010111101010101',最长为 64 bits,用于其他块去查找包的起始位置(
测试发现,最终输出的 Aceesss Code 总是 8bits 倍数,从右向左数 8 倍数个 bits
)
- Threshold:(临界点)访问代码中有多少位可能是错误的,但仍然算作正确
- Payload Bits per Symbol:有效负载调制器中使用的每个符号的位数
2)Protocol Formatter (Async)
Protocol Formatter (Async)
[15]
块可以将一个 a header format object 附加到 PDU 上。然后标头的长度将测量有效负载加上 CRC 长度(CRC32 为 4 个字节)。
该块接收 PDU 并创建 header,通常用于 MAC 级处理。每个收到的 PDU 被认为是它自己的 frame,因此任何 fragmentation 要在上游或之前的流程图中处理完毕。
该块的 'header' message port 会输出在该块中创建的 header。标头完全基于对象,该对象是从 header_format_base 类派生的对象。所有这些 packet header format objects 都是相同的:他们接收 payload 数据以及有关 PDU 可能的 metadata 信息。
对于不同的数据包头格式化需求,我们可以定义继承自 header_format_base 块并重载 header_format_base::format 函数的新类。
因此,运行后输出结果为:
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 6 bytes
pdu vector contents =
0000: af 55 00 30 00 30
************************************
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 48 bytes
pdu vector contents =
0000: 22 e7 d5 20 f8 e9 38 a1 4e 18 8c 47 30 8c fe f5
0010: ff f7 f7 28 b9 f8 fb f5 1c 7c cc cc 4c 24 01 6b
0020: 1c ea a3 ca e0 f5 80 a7 cc 09 5c d9 db 73 02 76
************************************
上面三个例子终于合成了一个完整数据帧,接下来我们尝试将其 header 和 payload 部分合并输出:
tx_stage4.grc

上面例子基于 2.3 中的合成信息,分别对 header 和 payload PDU 转换为 Stream,然后每 1 bit 输出 1bytes 数据(其实就是 bit 0 -> byte 0; bit 1 -> byte 1),接着 Map 其实就是执行 output[i] = map[input[i]],然后借助 Chunks to Symbols
[21]
[22]
将 bytes 转变为复数(采用星座图转换),最后使用 Tagged Steam Mux 将两股输入合并输出。运行后看 time sink 图能看出 header (0xaf 0x55 ... -> 10101111 01010101 ...) 对应:1 -1 1 -1 1 1 1 1 -1 1 ....
备注:
该流程图中涉及星座图的知识,可以参考
[16]
[17]
[18]
[19]
[20]
[21]
[22]
2.5 对 PDU 实施突发填充和渐变
burst shaper block 用于应用突发填充和斜坡的突发整形器块,通过在每个脉冲的前后添加一些补偿,使得脉冲更加稳定和清晰。它有两种补偿方式:
- 一种是在脉冲的前后添加一些零值,也就是没有信号的空白,这样可以避免脉冲之间的干扰,也可以调节脉冲的间隔。
- 另一种是在脉冲的前后添加一些相位符号,也就是交替的+1/-1的信号,这样可以使得脉冲的上升和下降更加平滑,也可以调节脉冲的形状。
如果使用定相符号,则在每个突发之前和之后将插入长度为ceil(N/2)的+1/-1个符号的交替模式,其中 N 是抽头矢量的长度。斜上/斜下形状将应用于这些相位符号。
如果不使用相位符号,则渐变将直接应用于每个突发的头部和尾部。
burst shaper block 的参数有以下几个:
窗口系数(Window Taps):这是一组用来控制脉冲的上升和下降的系数,它可以用来改变脉冲的波形,例如将方波变为正弦波,或将模拟信号变为数字信号
[23]
[24]
。
前补偿长度(Pre-padding Length):这是在每个脉冲前面添加的零值的个数,它可以用来调节脉冲的间隔,也可以用来避免脉冲之间的干扰。
后补偿长度(Post-padding Length):这是在每个脉冲后面添加的零值的个数,它可以用来调节脉冲的间隔,也可以用来避免脉冲之间的干扰。
插入相位符号(Insert Phasing Symbols):这是一个布尔值,表示是否在每个脉冲的前后添加相位符号,如果为真,那么会在每个脉冲的前后添加交替的+1/-1的信号(ceil(N/2) 用于上翼侧,ceil(N/2) 用于下翼侧,如果 taps.size 为奇数,中间的 tag 将用作上翼侧的最后一个,和下翼侧的第一个),如果为假,那么不会添加相位符号,而是直接对脉冲的头尾进行补偿。
长度标签名称(Length Tag Name):这是用来标记每个脉冲的长度的标签的名称,它可以用来控制脉冲的发送和接收,也可以用来分析脉冲的性能。
burst shaper block 的输出是一个经过整形和补偿的脉冲序列,它的长度标签会更新为包含补偿的长度,而且会放在输出的开头。其他的标签会根据它们的位置,放在相应的输出上,以保持与脉冲的关联。
备注:窗函数(英语:window function)在信号处理中是指一种除在给定区间之外取值均为0的实函数。譬如:在给定区间内为常数而在区间外为0的窗函数被形象地称为矩形窗。任何函数与窗函数之积仍为窗函数,所以相乘的结果就像透过窗口“看”其他函数一样。窗函数在频谱分析、滤波器设计、波束形成、以及音频数据压缩(如在Ogg Vorbis音频格式中)等方面有广泛的应用。
[23]
[24]
一个简单的例子如下:
burst_tagger.grc

运行后效果如下:

其中 Vector Source 是 8 个 1,8 个 -1,在 Stream to Tagged Stream 中将 160 个采样打包加长度标签(即 10 组向量),然后将数据送到两个配置不同的 Burst shaper 块中(一个使能定向符号,一个不使能,两个都使用海宁窗,N=50):
因此第一个输出的数据为:上翼 25 个1,-1交替信号(作用海宁窗),然后 160 个采样数据,然后 25 个下翼 1,-1交替信号,最后 padding 20 个 0 信号。因此最终数据总长度为:25+160+25+20 = 230
因此第二个输出的数据为:海宁窗直接作用 160 个采样数据的前 25 个形成上翼,作用后 25 个形成下翼,中间 110 个不实施作用,最后 padding 20 个 0 信号。因此最终数据总长度为:160+20=180
进一步,我们可以在 2.4 的完整数据帧基础上,加入 burst shaper(前后各填充 10 个 0,采用海宁窗,使能定向符号)->
tx_stage5.grc
:

2.6 RRC 滤波与多相任意重采样
2.6.1 FIR 滤波器例子
首先来看几个常见的滤波器的效果
filter_taps.grc
:

效果如下:

其中:
1)低通滤波器:截止频率为 14K,带宽为 1K,看图就能直接 get 到
2)高通滤波器:截止频率为 2K,带宽为 1K,看图也能 get
3)带通滤波器:设置 6K 到 10K,也是能看图 get
4)带阻滤波器:设置 6K 到 10K,也是能看图 get
5)RRC 根(平方根)升余弦滤波器需要单独介绍下
2.6.2 滤波器基础及 RRC 知识
要想理解 RRC 需要补充几个基础知识点
:
1)什么时候用 RRC?
数字通信系统中,基带信号进入调制器前,波形是矩形脉冲,突变的上升沿和下降沿包含高频成分丰富,信号的频谱一般比较宽,通过带限信道时,单个符号的脉冲将延伸到相邻符号的码元内,产生码间串扰。因此在信道带宽有限的情况下,要降低误码率,需在信号传递前,通过发送滤波器(脉冲成型滤波器)对其进行脉冲成型处理,改善其频谱特性,产生合适信道传输的波形。数字系统中常用的波形成形滤波器有升余玄脉冲滤波器、平方根升余玄滤波器、高斯滤波器等
[32]
。
2)什么是 RRC?
升余弦滤波器:
升余弦滤波器(Raised-cosine filter)是一种经常作脉冲成型滤波器,它能够最大限度地减少码间干扰(ISI)。之所以会如此命名是因为,该滤波器的最简形式频谱 (
\(\beta = 1\)
) 的非零部分为余弦函数且被抬升至水平轴的上方
[33]
[34]
。
数学描述为:
升余弦滤波器是低通奈奎斯特滤波器的一种实现,即具有对称性的滤波器。这意味着它的频谱在
f=± 1/(2T)
表现出奇对称性(Ts 是符号速率),如下:

引出根升余玄滤波:
当用于过滤符元流时,奈奎斯特滤波器具有消除 ISI 的特性,因为除了
\(n = 0\)
的情形之外,所有
\(nT\)
(n 是整数)的脉冲响应都是零。
因此,如果传输的波形在接收端被正确采样,原本的符元值就可以完全恢复。
然而,在许多实际的通讯系统,由于受白噪声之影响,会在接收器中使用匹配滤波器。对于零 ISI,发射和接收滤波器的净响应必须等于
\(H(f)\)
:
\[{\displaystyle H_{R}(f)\cdot H_{T}(f)=H(f)}
\]
因此:
\[{\displaystyle |H_{R}(f)|=|H_{T}(f)|={\sqrt {|H(f)|}}}
\]
这些滤波器称为根升余弦滤波器
[33]
[34]
。
集中重要参数:
滚降系数
:滚降系数
\(\beta\)
是对滤波器带宽过量(excess bandwidth)的度量,即所占带宽超过奈奎斯特带宽
\(\frac {1}{2T}\)
的部分,有些作者会使用
\({\displaystyle \alpha }\)
表示.
若我们将多余的带宽表示为
\({\displaystyle \Delta f}\)
,则:
\[{\displaystyle \beta ={\frac {\Delta f}{\left({\frac {1}{2T}}\right)}}={\frac {\Delta f}{R_{S}/2}}=2T\,\Delta f}
\]
\({\displaystyle R_{S}={\frac {1}{T}}}\)
是符元率。
上面的图显示为
\({\displaystyle \beta }\)
在 0 和 1 之间变化的振幅响应,以及对脉冲响应的相应作用。可以看出,时域的涟波准位会随着
\({\displaystyle \beta }\)
减少而增加,这可以减少滤波器的频寛过量,但只能以伸长脉冲响应为代价。
宽带
:升余弦滤波器的带宽通常定义为其频谱的非零正频率部分的宽度,即:
\[{\displaystyle BW={\frac {R_{S}}{2}}(\beta +1),\quad (0<\beta <1)}
\]
3)高斯滤波和升余玄滤波的区别
问:为什么GMSK要加高斯滤波器,而QPSK加升余弦滤波器?这么加这两种滤波器的主要区别是什么?有什么好处
[30]
?
答:GMSK 加高斯滤波器主要是为了减少带外辐射,让信号带宽更窄,从而增加信道容量,加入高斯后,反而会增加 ISI。而 QPSK 加升余弦滤波器主要是为了减少 ISI,对信号带宽有一定的减小,但减小程度没有高斯厉害。
4)滤波基础知识
为了更好地理解 RRC,我们需要再补充些滤波器的基础知识:
数字滤波器的作用通常可以概括为两方面
:
- 信号恢复(signal restoration)
: 信号恢复指滤波器能对失真信号进行恢复
- 信号分离(signal separation)
:信号分离 则指滤波器可以从冲突、干扰、或噪声中分离目标信号
数字滤波的两方面作用恰好对应了信号携带信息的两种不同模式
:
- 时域调制
: 时域调制 指使用信号的振幅、相位等波形特征表示要携带的信息内容,在这种情况下时域的采样结果可直接用于信息内容的提取;
- 频域调制
:频域调制是利用周期信号的频率特征区别和表示不同的信息;
滤波器分类
:

时域参数
:
通常使用
阶跃响应(Step Response)
描述滤波器的时域特征
[40]
。阶跃响应指输入信号为单位准阶跃信号时,滤波器的响应输出(阶跃信号的形式如下图所示)。由于阶跃信号本质上是单位脉冲信号在时间上的积分,所以对于线性系统而言,阶跃响应就是单位脉冲响应在时间上的积分。
给定一个滤波器阶跃响应,阶跃响应的哪些参数可以用于描述该滤波器的性能?
- 过渡速度(transition speed):规定阶跃响应中输出振幅从10%变化到90%振幅所经历的样本数为过渡速度。
- 过冲幅度(overshoot):过冲指信号通过滤波器后其时域振幅发生波动的现象,这是时域中包含的信息的基本失真。
- 线性相位(linear phase):希望阶跃响应的上半部分与下半部分对称。这种对称是为了使上升边与下降边看起来相同。这种对称性被称为线性相位,因为当阶跃响应上下对称时,频率响应的相位是一条直线。
注
:本节基本上复制于《物联网前沿实践》,详细细请参考
[40]
。
频域参数
:
从频域上看,滤波器的作用是允许某些频率的信号无失真地通过,而完全阻塞另一些频率的信号。有:低通、高通、带通、带阻。
上述四种滤波器的共同特征是能够在频域分离不同频率的信号分量,在设计和选择滤波器时,我们需要考虑以下三个重要参数:
- 滚降速度:为了分离间隔很近的频率,滤波器必须具有快速滚降
- 通带波纹:为了使通带频率不改变地通过滤波器,必须尽可能抑制通带纹波
- 阻带衰减:为了充分阻挡阻带频率,必须具有良好的阻带衰减

注
:本节基本上复制于《物联网前沿实践》,详细细请参考
[40]
。
2.6.3 回来理解 RRC

RRC Filter Taps 有以下参数
[41]
:
- Gain
: Overall gain of filter (default 1.0)
- Sample Rate
: Sample rate in samples per second.
- Symbol Rate
: Symbol rate, must be a factor of sample rate. Typically ((samples/second) / (samples/symbol)).
- Excess BW
: Excess bandwidth factor, also known as alpha. (default: 0.35)
- Num Taps
: Number of taps (default: 11*samp_rate). Note that the number of generated filter coefficients will be num_taps + 1.
由于 2.2 介绍升余弦滤波器的带宽通常定义为其频谱的非零正频率部分的宽度,即:
\[{\displaystyle BW={\frac {R_{S}}{2}}(\beta +1),\quad (0<\beta <1)}
\]
因此流程图中的 RRC 滤波器相当于低通滤波器,滤波的带宽为 16K/2(1+0.35) = 10.8
2.6.4 理解重采样
对于数字调制:

采样率变换,是软件无线电中的一个重要概念。一般来说,接收端射频器件以较高的采样率进行采样,可以使被采样带宽增加,而且有利于降低量化噪声,但高采样率会使采样后的数据速率很高,例如,接收卫星信号的采样率可达500MSPS,每秒采500M个样点,数据规模庞大,容易导致后续信号处理的负担加重,因此,非常有必要在ADC后进行降速处理,自然也就涉及到采样率的变换问题。
采样率的变换,通常分为内插(也称上采样)和抽取(也称下采样)。内插是指提高采样率以增加数据样点的过程;抽取是指降低采样率以去除多余数据样点的过程。

这里直接上结论,插值后信号的频谱为原始信号频谱经过I倍“压缩”得到,抽取后的信号频谱以原始信号频谱的D倍进行“展宽”。
——
复制自知乎-楚友马-gnuradio 入门开发
GNU Radio 提供以下几种重采样块:Fractional Resampler、Rational Resampler Base、Rational Resampler、Polyphase Arbitrary Resampler。我们这个例子中使用了 Polyphase Arbitrary Resampler,因此只对其进行简单介绍(其他的后面出一期专门介绍):
多相任意重采样器是一种用于对信号流进行任意比例的重采样的技术,它可以根据不同的需求,调节信号的采样率和波形。它的原理是,将一个长的滤波器分解为多个短的滤波器,形成一个多相滤波器组,然后对输入信号进行多相分解,使得每个分支的信号只需要经过一个短的滤波器,从而降低运算量和延迟。接着,根据目标的重采样比例,从多相滤波器组中循环地取出一定数量的输出信号,并在相邻的输出信号之间进行插值,得到一个近似的重采样结果
[26]
[28]
。
多相任意重采样器的优点是,它可以实现任意的重采样比例,无论是有理数还是无理数,而不需要进行复杂的内插或抽取操作。它也可以有效地减少滤波器的长度和运算量,提高重采样的效率和精度。它的缺点是,它需要对滤波器和信号进行多相分解,这会增加一些存储和计算的开销。它也会引入一些量化误差,因为它是通过插值来实现任意比例的重采样,而不是精确的重采样。因此,它需要根据具体的应用场景和性能要求,来选择合适的滤波器个数和插值方法
[27]
[29]
。
3 发送相关的小 DEMO
3.1 前向纠错编码
编码需要用到
FEC Async Encoder
块
[5]
:
将在 message port 上接收到的帧(作为 async messages 或 PDU)进行编码。该 encoder 将完整消息作为一个帧或块进行编码。消息的长度会被用于帧的长度,特别的该块的
MTU
参数用于设置最大传输单元的大小,这意味传输帧长度不能大于这个值。
此部署处理的消息是 messages full of unpacked bits 或 PDU messages,这意味着协议的更高层需要完成帧头、帧尾、CRC 校验等组装。为了处理 PDU,需要将
packed
选项设置为 True,然后该块将使用 FEC API 来正确地对 PDU 中的 bits 进行解包,再通过 encoder,并将它们重新打包输出新的 PDU 用于下一阶段。
该块还提供对解包和打包顺序设置:LSB 和 MSB。默认
rev_unpack
和
rev_pack
设置为 True,也就是说拆包 bits 反转、打包 bits 反转。

因此,流程图(
tx_stage2.grc
)中的 Encoder 模块的 MTU 设置为 1.5K,packed 设置为 True,FEC 打包对象可选三个:
|
EFC 对象块
|
参数
|
功能介绍
|
Repetition Encoder Definition
[6]
|
- 维度:?
- Frame Bits:帧最大 bits
- 重复:每 1 bit 重复多少次
|
按 bits 重复多少个 |
| Dummy Encoder Definitio |
- 维度:?
- Frame Bits |
透传 |
CC Encoder Definition
[7]
|
- 维度:?
- Frame Bits
- Constraint Length (K):[2, 31]
- Rate Inverse(1/R)
- Polynomials(多项式)
- Start State:移位寄存器初始值
[0, 2^(K-1)-1]
,大多数文献和书籍都使用从左向右移位的移位寄存器,而这里是从右向左,这意味着该值必须反转。
- Streaming behavior:指定卷积编码器的行为方式
- Byte Padding(字节填充):编码的帧是否应该填充到最近的字节 |
对恒定长的帧实施卷积编码,允许指定约束长度(K)、编码率、多项式。编码对象维护一个移位寄存器,该移位寄存器从输入流中取每个 bit,然后与与移位寄存器做 AND 运算,
Voyager 多项式常见二进制表示为 1011011和1111001,八进制为 133 和 171。对于这个块二进制需要颠倒:1101101和1001111;八进制这是155和117;十进制是109和79。一些标准(例如CCSDS 131.0-B-3)要求对某些输出进行反转。这是通过提供多项式的负值来支持的,例如-109。
NASA 的 Voyager code 使用 K=7, Rate=1/2:
1 + x^2 + x^3 + x^5 + x^6
1 + x + x^2 + x^3 + x^6
卷积编码行为有:
- Streaming:这种模式期望不间断的样本流进入编码器,并且输出流被连续编码。
- Terminated:为基于分组的系统设计的模式。此模式刷入 K-1 bits 进入编码器,将 rate*(K-1) bits 添加到输出,这提高了对块的最后比特的保护,并有助于解码器。
- Tailbiting(咬尾):另一种基于分组的方法。此模式将用数据包的最后(k-1)位预初始化编码器的状态,而不是在数据包的末尾添加位(如“CC_TERMINATED”)。
- Truncated(截断的):总是在帧之间将寄存器重置为起始状态。 |
CCSDS Encoder Definition
[13]
|
参数和 CC Encoder Definition 类似 |
是一种特殊的卷积码:CCSDS Encoding class for convolutional encoding with rate 1/2, K=7, and polynomials [109, 79]. |
采用 3 重复编码输出 log :
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 48 bytes
pdu vector contents =
0000: 22 e7 d5 20 f8 e9 38 a1 4e 18 8c 47 30 8c fe f5
0010: ff f7 f7 28 b9 f8 fb f5 1c 7c cc cc 4c 24 01 6b
0020: 1c ea a3 ca e0 f5 80 a7 cc 09 5c d9 db 73 02 76
************************************
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 144 bytes
pdu vector contents =
0000: 03 80 38 ff 81 ff fc 71 c7 03 80 00 ff fe 00 ff
0010: 8e 07 03 fe 00 e3 80 07 1c 0f f8 00 7e 00 e0 0f
0020: c0 1c 01 ff 03 f0 00 e0 0f c0 ff ff f8 ff f1 c7
0030: ff ff ff ff f1 ff ff f1 ff 03 8e 00 e3 fe 07 ff
0040: fe 00 ff fe 3f ff f1 c7 00 7f c0 1f ff c0 fc 0f
0050: c0 fc 0f c0 1c 0f c0 03 81 c0 00 00 07 1f 8e 3f
0060: 00 7f c0 ff 8e 38 e3 80 3f fc 0e 38 ff 80 00 ff
0070: f1 c7 e0 00 00 e3 81 ff fc 0f c0 00 0e 07 1c 7f
0080: c0 fc 7e 07 fc 7e 3f 1f f0 3f 00 00 38 1f f1 f8
************************************
运算过程:
22 e7 -> 0010 0010 1110 0111 -> [000 000 111 000] [000 000 111 000] [111 111 111 000] [000 111 111 111]
-> 0000 0011 1000 0000 0011 1000 1111 1111 1000 0001 1111 1111
-> 0 3 8 0 3 8 f f 8 1 f f
-> 03 80 38 ff 81 ff
采用 CC Encoder 编码:K=7, Rate=1/2(rate = 1/Rate = 2),多项式使用 [109,79]
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 48 bytes
pdu vector contents =
0000: 22 e7 d5 20 f8 e9 38 a1 4e 18 8c 47 30 8c fe f5
0010: ff f7 f7 28 b9 f8 fb f5 1c 7c cc cc 4c 24 01 6b
0020: 1c ea a3 ca e0 f5 80 a7 cc 09 5c d9 db 73 02 76
************************************
***** VERBOSE PDU DEBUG PRINT ******
()
pdu length = 97 bytes
pdu vector contents =
0000: 0d ff d7 ec 6e df 0a 42 26 b6 b9 c9 9e e1 8e dd
0010: 8b 9e 16 63 43 c4 d0 f2 4b fe af c4 01 8c 83 9d
0020: 21 3f ff 20 d3 20 38 5d 3d 7e c6 06 ba b8 34 2d
0030: c4 24 6e ad 7f 0f 0f 0f d0 23 ea c5 0b 03 46 58
0040: 61 e4 b2 c7 cc 10 a6 45 3b d5 26 5d 18 9c d2 e7
0050: 6d 7f e7 dc 64 ef bc 47 0b fa 2b 3b fe 7d cb bf
0060: 49
************************************
运算过程
[8]
[9]
[10]
[11]
[12]
:
22 e7 d5 20 -> 0010 0010 1110 0111 1101 0101 0010 0000 -> [001000] [101110] [011111] [010101] [001000] 00
001000 001000
1011011 1111001
------- -------
001000 001000
000000 001000 -> 0 0 1 0 1 1 -> 000011011111 -> 0D F
001000 001000 -> 0 0 1 1 1 1
001000 001000
000000 000000
001000 000000
001000 001000
------ ------
001011 001111
更标准与生动的计算过程:

- 将多项式转为寄存器流程图
2)初始每个寄存器为 0,然后将 00100010 按照从左到右顺序一个字节一个字节送入这个寄存器图
3)每送入 1 个 bit 出来 2 个 bits
4)最后将每次输出的 bit 对按顺序连接
3.2 Chat App
这个例子比较简单,就是个输入框内输入啥,Message Debug 输出啥
pdu_simple_demo2_chat.grc
:

3.3 PDU 操作集合演示
这个例子展示了关于 PDU 操作的各种块
pdu_simple_demo3_pdu_tools.grc
:

其中几个新块的功能如下:
- PDU Set:此块将向 PDU 元数据字典添加一个 key-value 数据对。
- Add System Time:此块将把系统时间作为双精度浮点值添加到 PDU 元数据中。时间键可以由用户设置。
- Note:通常,一些 PDU 处理将在这里进行,以便应用时间基准。
- Time Delta:此块计算从添加时间键到现在所经过的毫秒数,并当流程图停止时打印统计信息。
- PDU Split:PDU 将会被拆分成数据字典 metadata dictionary 和 统一向量 uniform vector , 然后分别作为 dict/uvec PMT 消息发出。
因此整个流程图每隔 400ms 输出一个大 PDU,然后增加一个 KEY1 键值对,再增加一个 SYS_TIME 键值对,然后做一个小处理(主要是演示耗费时间统计),然后增加一个 time_delta_ms 键值对,最后将信息分拆为字典和向量。
字典的打印结果为:
time_delta :debug: time_delta_ms PDU received at 1706628911.598694 with time delta 0.045776 milliseconds
******* MESSAGE DEBUG PRINT ********
((time_delta_ms . 0.0457764) (SYS_TIME . 1.70663e+09) (KEY1 . 123.4))
************************************
参考链接
[1].维基百科 —— PDU
[2].GNU Radio —— Random PDU Generator
[3].GNU Radio —— PDU Set
[4].GNU Radio —— Async CRC32
[5].GNU Radio —— FEC Async Encoder
[6].GNU Radio —— Repetition Encoder Definition
[7].GNU Radio —— CC Encoder Definition
[8].周武旸 —— 中国科学技术大学 个人通信与扩频实验室《编码论第四章》(超详细介绍卷积编码)
[9].知乎 —— 卷积码(有些错误,对于理解 8 有帮助)
[10].国外问答论坛 —— 旅行者号上面如何实现卷积码的提问
[11].美国国防信息安全中心
[12].维基百科 —— 卷积码
[13].GNU Radio —— CCSDS Encoder Definition
[14].GNU Radio —— Default Header Format Obj
[15].GNU Radio —— Protocol Formatter (Async)
[16].清华大学学报 —— OFDM星座旋转调制自适应交织器设计
[17].知乎 —— 星座图通信原理(相比 18 更多例子和图)
[18].CSDN —— 详解IQ调制以及星座图原理(相比 20 更详细)
[19].中国科技核心期刊 —— 基于星座图的数字信号调制方法综述
[20].CSDN —— 星座图的原理和应用(简单介绍 IQ 调制和星座图)
[21].GNU Radio —— Chunks to Symbols
[22].GNU Radio —— Constellation Object
[23].CSDN —— 一文读懂FFT,海宁窗(hann)和汉明窗(hamming)的区别,如何选择窗函数
[24].维基百科 —— 窗函数 Window function
[25].GNU Radio —— Burst Shaper
[26].知乎 —— 楚友马-gnuradio 入门开发
[27].北理工学报 —— 基于抽取滤波器多相分解的多速率采样模块设计
[28].CSDN —— 多相抽取器实现及matlab示例
[29].Matlab —— 对非均匀采样信号进行重采样
[30].通信技术互动问答 —— 为什么GMSK要加高斯滤波器,而QPSK加升余弦滤波器?
[31].CSDN —— 滤波器之升余弦(很简单形象介绍了清楚)
[32].清华大学出版社 —— MATLAB/System View 通信原理实验与系统仿真,3.3.1 升余弦滤波器
[33].CSDN —— 升余弦和根升余弦滤波器(SRRC,RRC)的单位脉冲响应(详细)
[34].维基百科 —— 升余弦滤波器
[35].维基百科 —— 冲激响应
[36].维基百科 —— 滤波器
[37].维基百科 —— 低通滤波器
[38].IC 先生 —— 升余玄滤波器工作原理_滚降系数_冲激响应表达式
[39].知乎 —— 信号发送端用根升余弦滤波器进行成形滤波,那么接收端用什么滤波器来匹配呢?
[40].清华大学 —— 《物联网前沿实践》第 5 章信号滤波(超好)
[41].GNU Radio —— Root Raised Cosine Filter
[42].NASA —— Root Raised Cosine (RRC) Filters and Pulse Shaping in Communication Systems
[43].Matlab —— raised-cosine-filtering
[44].文献 —— The care and feeding of digital,pulse-shaping filters
[45].华强电子 —— 什么是FIR滤波器?FIR滤波器工作原理、组成、优缺点及应用详解
[46].Stack Exchange —— RRC 滤波器的正确增益是多少?
[47]. NI —— RFmx 波形创建器用户手册
[48]. 博客 —— C 中的根升余弦滤波器
[49]. 欧洲航天局 —— 平方根升余弦信号
[50]. BOOK —— Intuitive guide to topics in communications and digital signal processing(很直观看信号与系统)
教程列表
基础教程:
综合教程:
SDR 小工具教程:
基础块教程:
视频和博客


:
如果觉得不错,帮忙点个支持哈~