我用Awesome-Graphs看论文:解读PowerGraph
PowerGraph论文
:
《PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs》
上次通过文章
《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》
向大家介绍了论文图谱项目Awesome-Graphs,并从Google的
Pregel
开始解读图计算系统关键论文。这次向大家分享发表在OSDI 2012上的一篇经典图计算框架论文PowerGraph,旨在通过点切分解决图数据幂律分布导致的计算倾斜问题,并提出了区别于Pregel's VC(以点为中心)的GAS(以边为中心)计算框架。
对图计算技术感兴趣的同学可以多做了解,也非常欢迎大家关注和参与论文图谱的开源项目:
- Awesome-Graphs:
https://github.com/TuGraph-family/Awesome-Graphs - OSGraph:
https://github.com/TuGraph-family/OSGraph
提前感谢给项目点Star的小伙伴,接下来我们直接进入正文!
摘要
Pregel、GraphLab这样的分布式图计算系统在处理自然图时(点出度服从幂律分布),图计算性能和扩展性存在很大的限制,PowerGraph提出新的图切分方式来解决该问题。
1. 介绍
Pregel、GraphLab使用点程序(vertex-program)来描述图计算,这些点程序并行运行,并沿着边进行交互。这样的抽象要求点的邻居数较少以获取更大的并行度,也要求更高效的图分区以获取更少的通信量。但是在现实世界中,图的度数一般都是按照幂律分布的,也就是说存在一小部分点的度数非常高,这让传统的图分区变得比较困难。
PowerGraph提出了新的计算模型,在面向自然图的计算任务上,拥有更高的并行度、更少的通信存储成本和更高效的图分区策略。关键贡献有:
- 分析现有的图并行抽象在幂律图上计算的挑战和限制。
- 提出PowerGraph的图计算抽象。
- 提出增量缓存机制(Delta Caching)允许图状态的动态更新。
- 针对幂律图的高效切分方式。
- 针对网络和存储的理论建模。
- PowerGraph的高性能开源实现。
- EC2上使用PowerGraph实现的三种MLDM算法的评估。
2. 图并行抽象
图并行抽象包含:
- 一个稀疏图:G={V, E}。
- 一个点程序:Q。
- Q可以在任意v ∈ V上并行执行,并可以和v的邻居u上的Q(u)进行交互,其中(u, v) ∈ E。
- GraphLab使用共享状态实现交互、Pregel使用消息传递实现交互。
2.1 Pregel
整体同步消息传递抽象。
BSP、消息传递、超步、barrier、终止条件、combiner
2.2 GraphLab
异步分布式共享内存抽象。
共享访问、分布式图存储、串行化避免邻居同时更新、消除消息传递、用户算法与数据移动解耦、点数据(与所有邻居共享)、边数据(与特定邻居共享)
2.3 PowerGraph
GAS计算模型:
- Gather阶段:收集邻点和邻边的值,并通过一个通用sum聚合:
\(\Sigma \leftarrow \bigoplus_{v \in \mathbf{Nbr}[u]} g(D_u, D_{(u,v)}, D_v)\)
。 - Apply阶段:将sum后的结果更新到中心点的值:
\(D_u^{new} \leftarrow a(D_u, \Sigma)\) - Scatter节点:将新的点值更新邻边值:
\(\forall v \in \mathbf{Nbr}[u]:(D_{(u,v)}) \leftarrow s(D_u^{new}, D_{(u,v)}, D_v)\)
Gather和Scatter对应点程序的输入和输出。比如PageRank,Gather只操作入边,Scatter只操作出边。但是很多MLDM算法Gather和Scatter会操作所有的邻边。
3. 自然图的挑战
自然图度数的幂律分布:
\(\mathbf{P}(d) \propto d^{-\alpha}\)
,
\(\alpha \approx 2\)
- α越大,说明图的密度越低(边数/点数),大多数点都是低度点。
- α越小,图的密度和高度节点数增多(图越倾斜)。
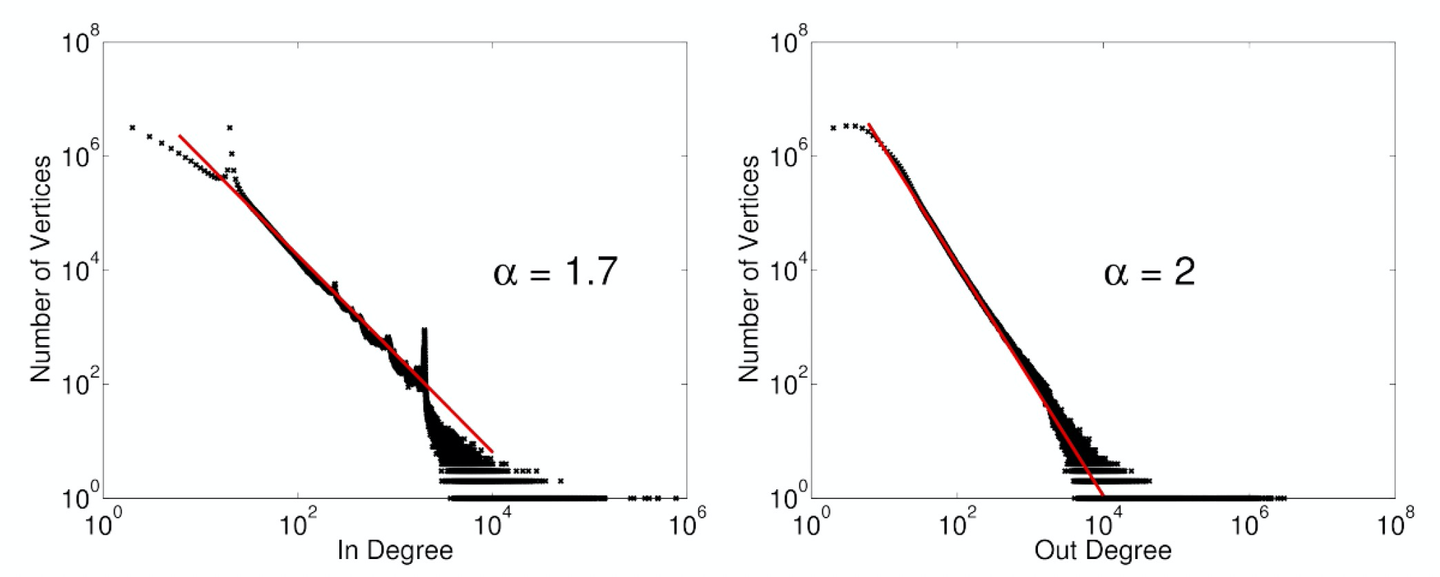
自然图热点带给已有图计算系统的挑战:
- Worker负载不均衡。
- 分区缺乏局部性。
- 通信的非对称性导致的性能瓶颈。
- 存储量与度数成正比,超过单机内存容量。
- 计算无法并行化,扩展性受限。
4. PowerGraph抽象
PowerGraph结合了Pregel和GraphLab的设计优点。从GraphLab借鉴了“数据图”和“共享状态”的思想降低用户设计信息转移的成本,从Pregel的借鉴了可交换、可结合的sum的概念(不依赖于分区的实现)。
4.1 GAS点程序
GAS的stateless接口设计:
GAS的计算流程:
Gather阶段的gather和sum函数使用map+reduce方式收集邻居信息。gather函数在u的邻边上(扇入,gather_nbrs可以是none、in、out、all)并行执行,gather_nbrs可以是none、in、out、all。sum函数是可交换可结合的,sum的结果放到点u对应的累加值
\(a_u\)
,这个值是缓存形式。
Apply阶段的apply函数根据点缓存计算新的点值
\(D_u\)
并自动写回到图状态。
\(a_u\)
的大小和apply函数的复杂度决定了网络和存储的效率,因此它们应该和节点度数亚线性/常数相关。
Scatter阶段的scatter函数在u的邻边上(扇出,scatter_nbrs可以是none、in、out、all)并行执行,并生成新的边值
\(D_{(u,v)}\)
自动写回到图状态。scatter函数有个可选返回值
\(\Delta a\)
,如果
\(\Delta a\)
不空,且邻点的累加值缓存
\(a_v\)
也存在,则使用sum函数更新
\(a_v\)
。否则清空
\(a_v\)
缓存值。
算法举例:
- PageRank
- #outNbrs(v)表示v的出度,这里应该理解为一个可事先聚合的图特征。
- apply的0.15并未除以全图点数N,非严格的PageRank算法。
\(\mathbf{Rank}(u) = \frac{1-q}{|V|} + q \sum_{v \in \mathbf{Nbr}[u]}\frac{\mathbf{Rank}(v)}{\mathbf{\#outNbrs}(v)}, q=0.85\) - Du.delta的本来语义是Du.rank的变化,这里除以#outNbrs(u)导致收敛语义变化:点rank不再更新 -> 点传递给出度邻居的rank不再更新。虽不影响算法收敛,但是受
\(\epsilon\)
精度影响。 - scatter返回值是delta,这里应该是Du.delta,即传播给出度邻居的delta增量值,可直接sum到
\(a_v\)
。
- 贪心图着色
- apply的min c应该理解为,除了邻居的颜色集合S之外的,在所有备选颜色中选择id最小的颜色c。
- scatter函数直接返回空,以为图着色的状态不能增量更新,而是覆盖更新。
- SSSP
- scatter的changed(Du):Dunew != Duold。
- scatter的increased(Du):Dunew > Duold。
- 只有Du变小了才需要Active(v),也才需要返回Du+D(u,v),这里不够严谨。

4.2 增量缓存
GAS点程序一般会被少量的邻居更新触发,但是每次都会gather所有邻居的数据,造成计算资源浪费,因此通过维护点的sum值缓存
\(a_u\)
,以实现跳过下次迭代的gather阶段。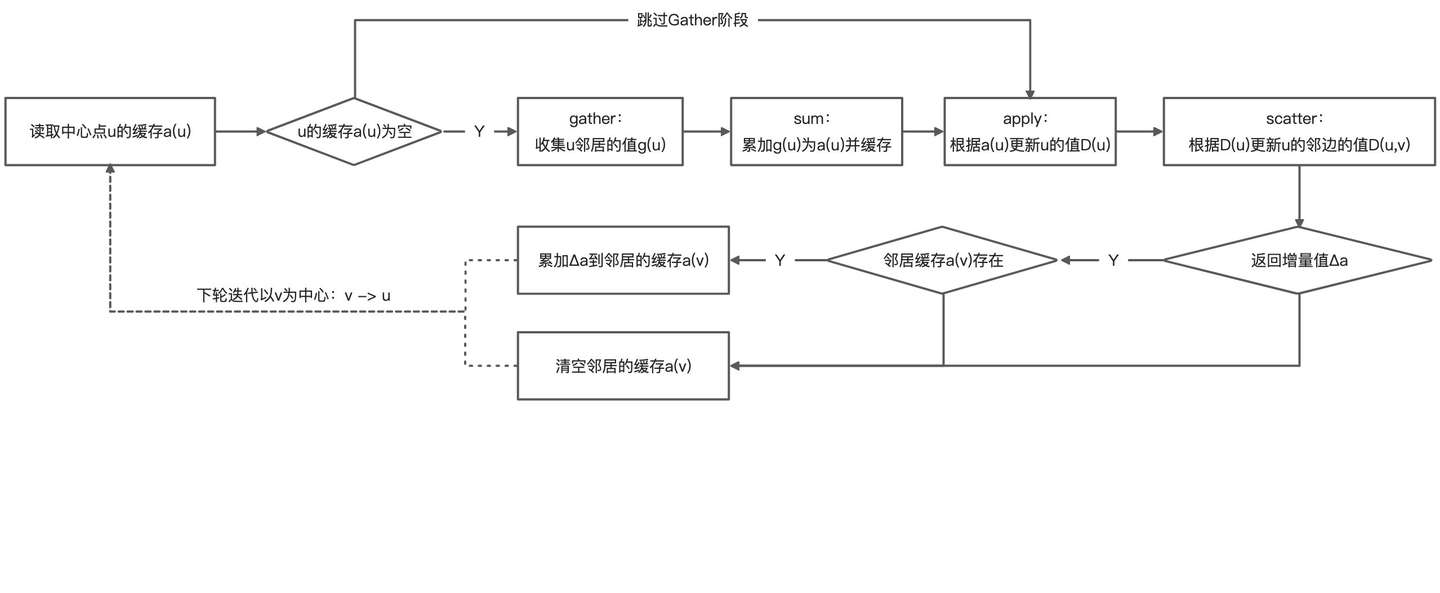
增量值
\(\Delta a\)
相当于基于上轮gather的结果进行的修正,一般要求Gather阶段的累积操作类型构成一个阿贝尔群(拥有可交换、可结合的加法操作,以及加法逆元(求负)操作),那么:
\(\Delta a = g(D_u, D_{(u, v)}^{new}, D_v^{new}) - g(D_u, D_{(u, v)}, D_v)\)
4.3 激活下次计算
通过调用Active(v)或Active_all()触发点上的计算,但仅限于激活当前点自身或邻点,这种限制保证激活事件可以被高效地处理,并为同步和异步处理提供了灵活性。
4.3.1. 同步执行
特点:
- gather、apply、scatter按序执行,每个阶段称为minor-step。
- GAS的所有minor-step构成super-step。
- 上一minor-step对点边的修改提交后,后续的minor-step才可见。
- 在上一super-step激活的点,在下一super-step会被执行。
- 类Pregel的方式,保证了执行的确定性。
- 执行低效,算法收敛速度满。
4.3.2 异步执行
特点:
- 只要处理器和网络资源充足,被激活的点会立即执行。
- apply/scatter对点边做的修改被立即更新到图上,并对后续计算的邻点可见。
- 充分利用资源并加速算法收敛。
- 执行的不确定性,导致算法结果不稳定,甚至出现分歧。
为了解决异步执行结果不确定的问题,GraphLab使用了串形化机制。通过细粒度锁协议禁止邻点程序的并发执行,这要求邻点需要顺序地获取锁,对高度点不够公平。为此,PowerGraph提出了并行锁协议来解决该问题。
4.4 对比GraphLab/Pregel
- 模拟GraphLab点程序:通过gather和sum连接邻点和邻边上的数据,并使用apply运行GraphLab的程序。
- 模拟Pregel点程序:通过gather和sum收集输入消息,并合并用于计算输出消息的邻居列表,然后通过apply生成新的消息集合发送给scatter。
5. 分布式图切分
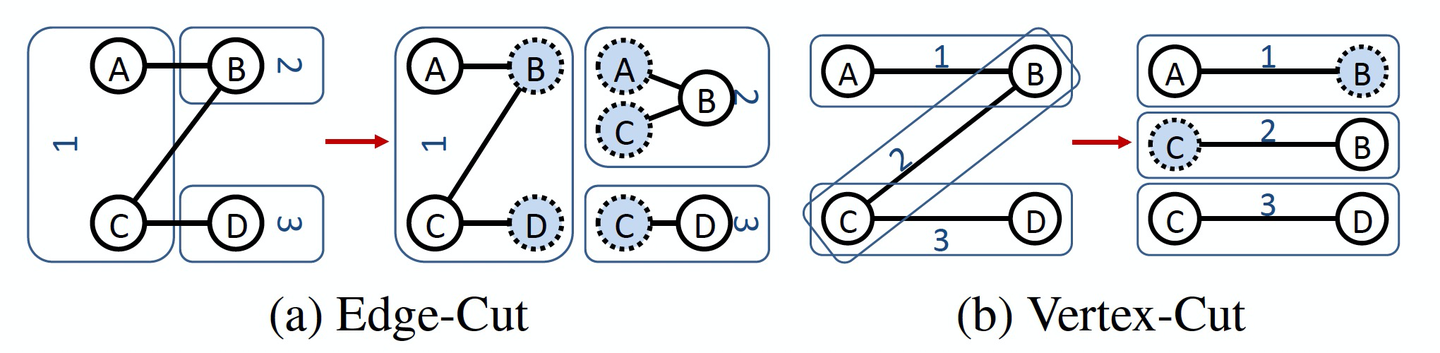
边切分导致更多的存储和网络开销,因为要多维护一份邻居信息(边+ghost点)。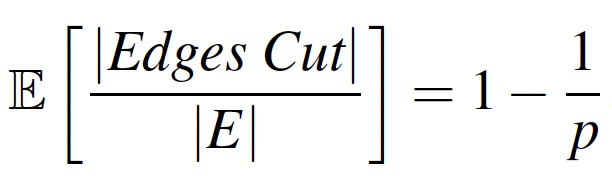
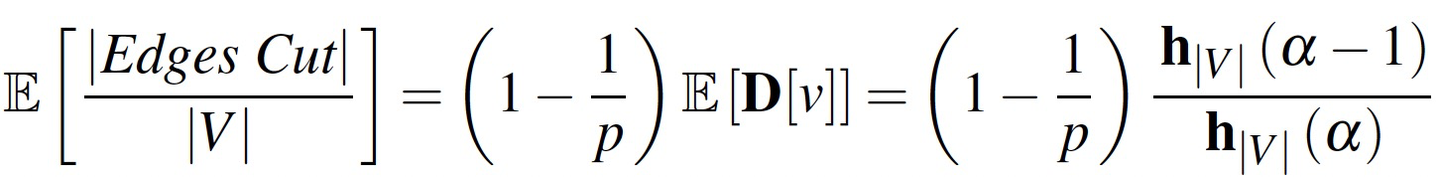
幂律Zipf分布的归一化常数:
5.1 平衡的p路点切分算法
平衡的p路点切分被描述为以下最优化问题: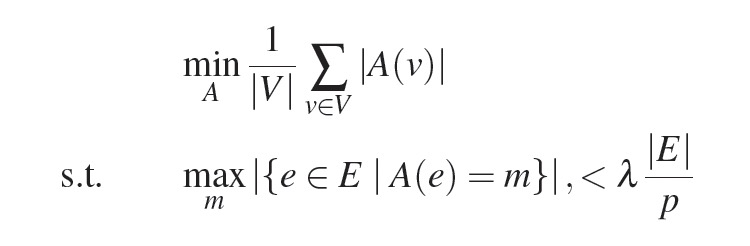
- p:机器数
- A(v):点v分配到的机器分区集合,{1, p}的子集。
- A(e):边e分配到的机器分区,取值[1, p]。
- λ:非平衡因子,不小于1的一个小常数。
- min优化目标:尽可能减少点切分到的机器分区总数,降低存储/网络开销。
- max优化目标:平衡约束,保证边尽可能平均分配到各个机器分区。
在幂律分布图上,复制因子仅和α相关。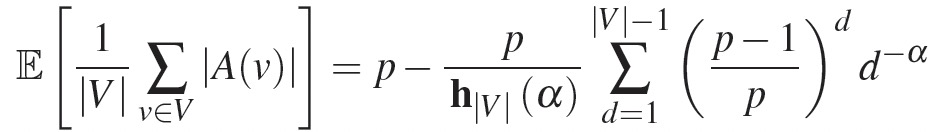
- α越小,机器数越多,复制因子越高。
- α越小,机器数越少,点切分的优势越明显。
给定边切分,如果产生了g个ghost点,那么对于同样分区边界的点切分,mirror点的个数严格小于g。
5.2 贪心点切分算法
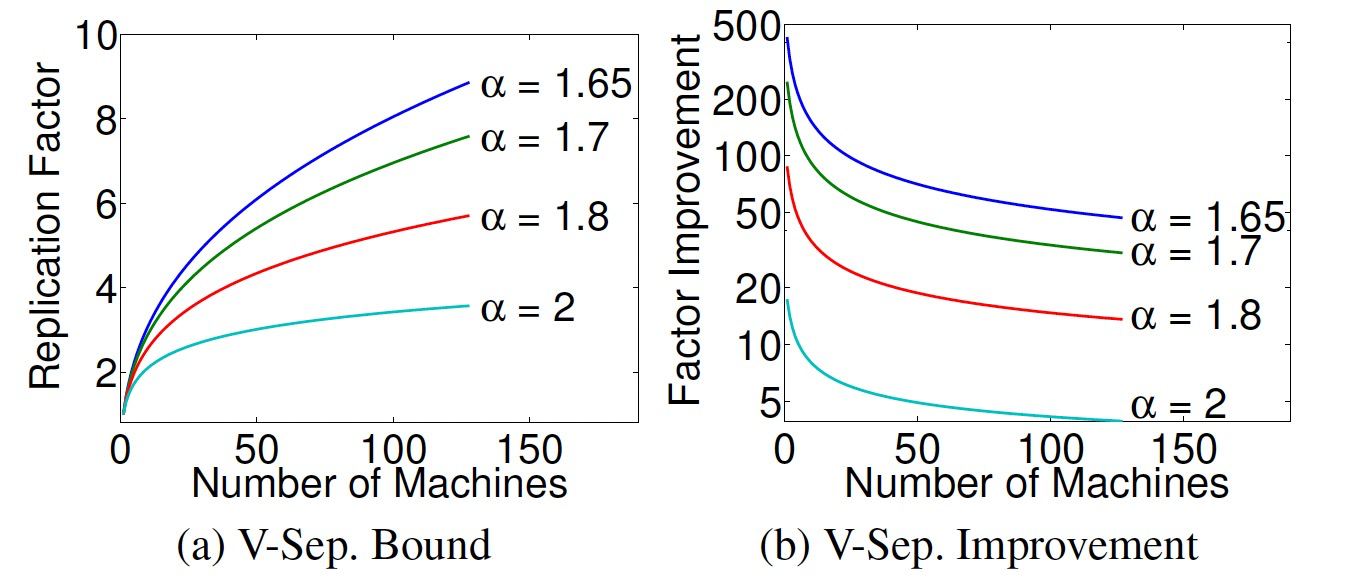
贪心点切分被描述为以下最优化问题:当放入新的边时,尽可能减少复制因子的增加。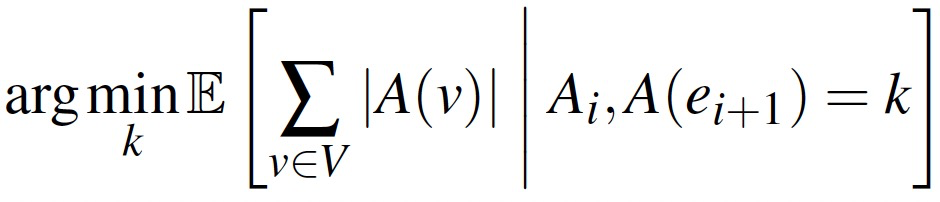
- Ai:已经分配的第i条边所在的机器分区。
- A(ei+1):第i+1条边要分配的机器分区。
- k:求最优的k值,让复制因子(|V|是恒定的)最小。
基于此,推导出边放置策略:对于边e(u, v),
- case 1:A(u)、A(v)在一个机器,那么e(u, v)就分配到这个机器。
- case 2:A(u)、A(v)不在一个机器,那么e(u, v)就分配边最少的机器。
- case 3:A(u)、A(v)只有一个分配,那么e(u, v)就分配到已分配的机器。
- case 3:A(u)、A(v)没有分配,那么e(u, v)就分配到负载最小的机器。
贪婪启发式算法是去随机化的,因此需要在各个机器间进行协调,为此有两种分布式实现:
- Coordinated:维护分布式的表格,记录Ai(v)的值。所有机器定期更新这个分布式表,维护自身缓存。
- Oblivious:每个机器独立运行贪婪启发算法,维护各自的Ai(v)值,不共享数据。
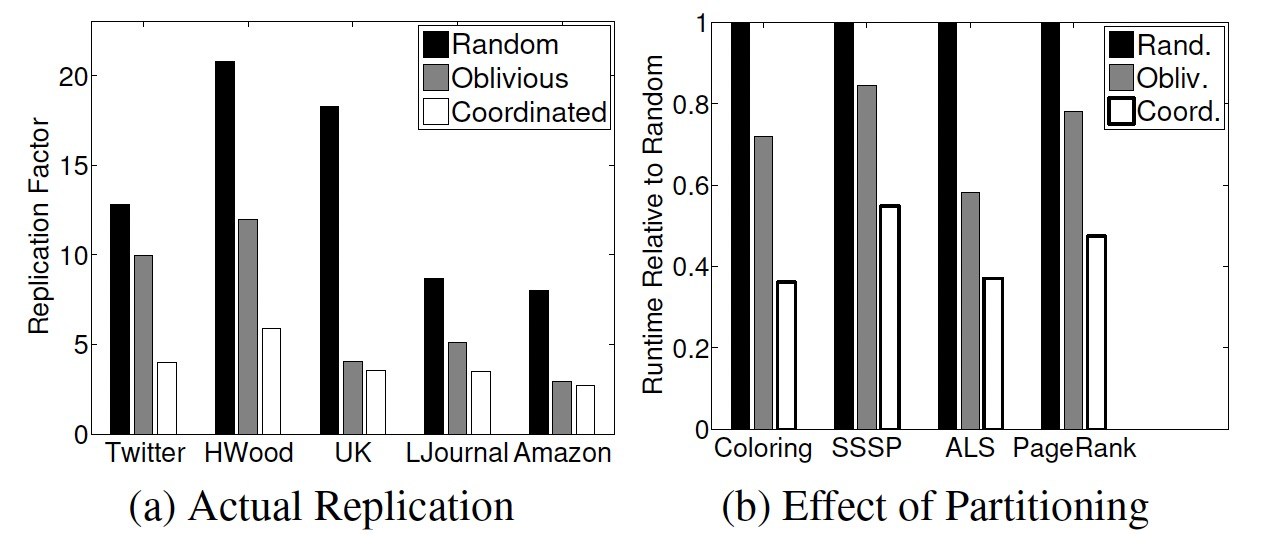
- 在不同的数据集上,Coordinated复制因子最低,其次Oblivious,最后Random。
- 在不同图算法上,Coordinated运行时间最少,其次Oblivious,最后Random。
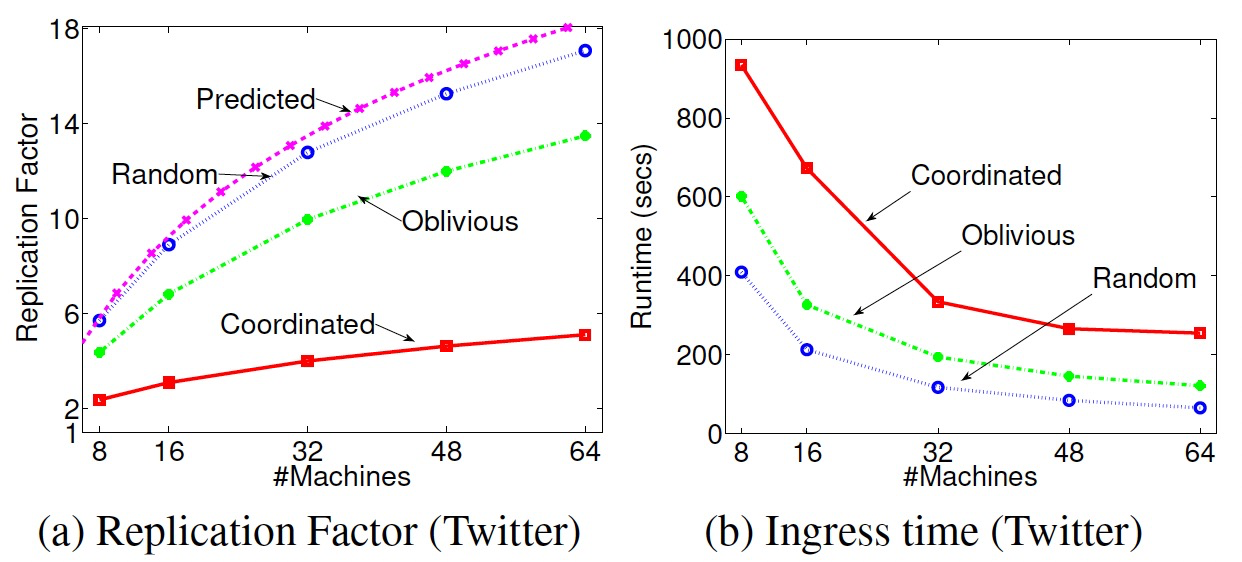
- Twitter数据集上,随着机器增多复制因子也会增加,Coordinated增长最慢,其次Oblivious,最后Random。论文提出的复制因子模型和Random算法非常接近。
- Twitter数据集上,构图时间上,Coordinated最慢,其次Oblivious,最后Random。随着机器增多构图时间会减少。
6. 抽象对比
测试准备:
- 使用5个合成的幂律分布图,α从1.8~2.2。
- 通过Zipf采样构建扇出图,然后反转图获得扇出图。
- 执行PageRank算法。
- GraphLab(v1)、Pregel(Piccolo,Giraph内存不足)、PowerGraph。
- 8 * 8C32G Intel Xeon E5620、1G带宽。
- GraphLab、Piccolo使用随机边切分,PowerGraph使用随机点切分。
6.1 计算不平衡
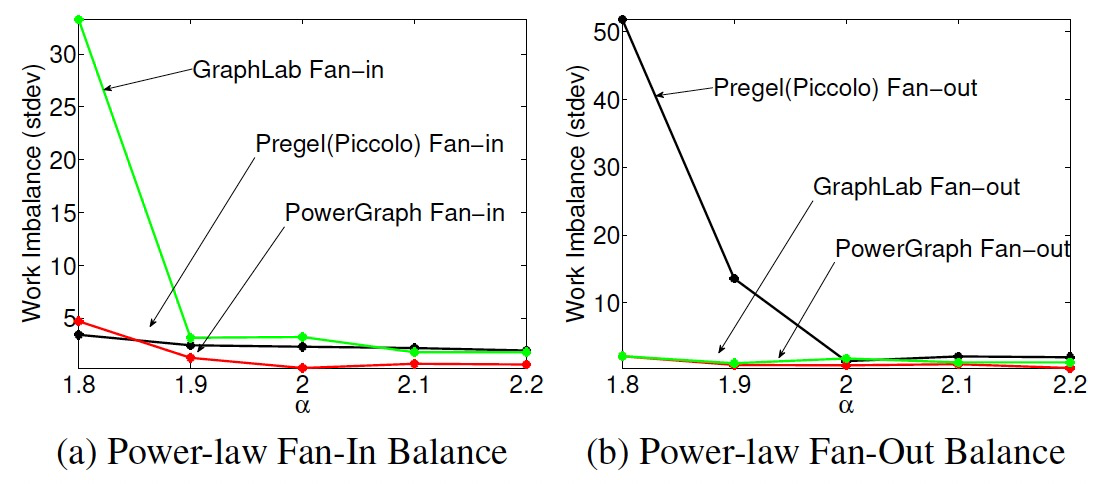
- 通过迭代时间的标准差来衡量计算的不平衡性。
- GraphLab在扇入边较多时,迭代标准差变大(GraphLab加载更多的邻居)。
- Pregel在扇出边较多时,迭代标准差变大(Pregel要发送更多的消息)。
- 均匀的边分布,让PowerGraph受影响较少。
6.2 通信不平衡
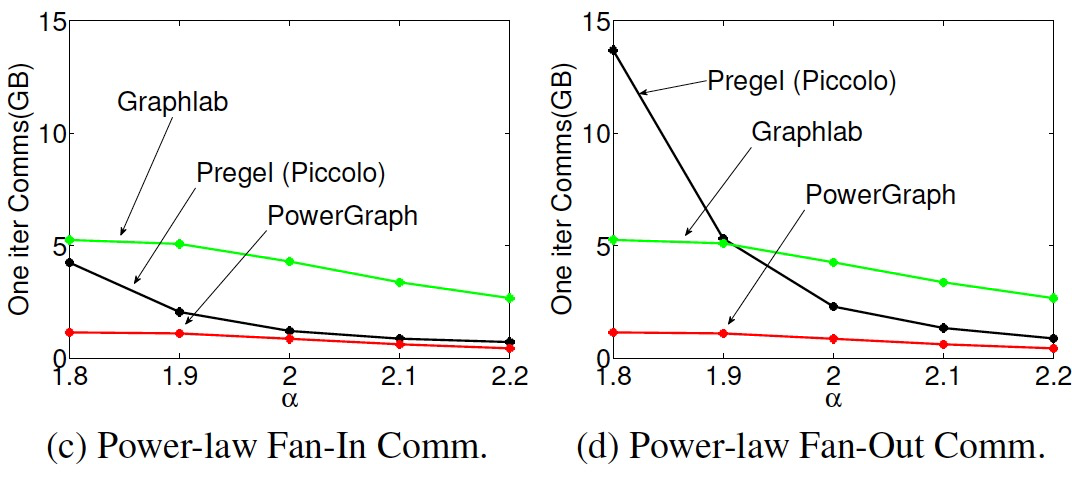
- 边切分通信量与ghost数相关,点切分通信量与mirror数相关。
- Pregel需要往出边发消息,因此在扇出图上通信量很高。
- GraphLab和PowerGraph在数据同步时不考虑边方向,因此通讯量基本不变。
- PowerGraph的通信量最少得益于高效的点切分。
6.3 运行时间对比
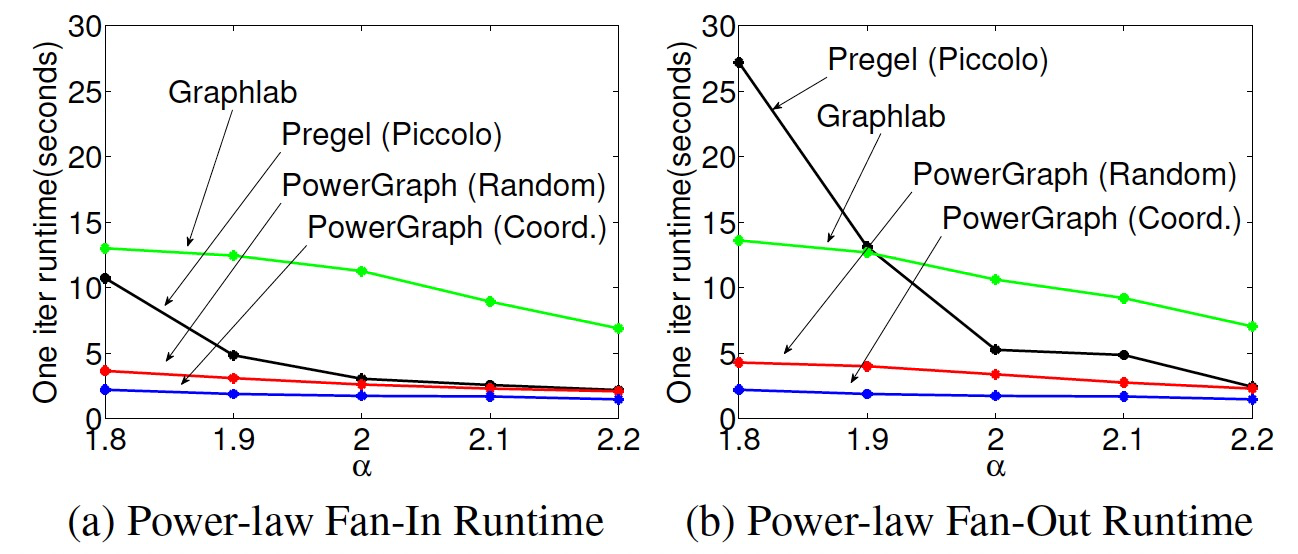
- 迭代整体运行时间和通信量很匹配,与计算关联较少,是因为PageRank计算比较轻量。
- 使用贪心分区策略,可以将性能再提升25%-50%。
7. 实现与评估
使用三种PowerGraph的实现进行分析:
- Bulk Synchronous (Sync):同步实现。
- Asynchronous (Async):异步实现。
- Asynchronous Serializable (Async+S):异步+串行化实现。
7.1 图的加载与分区
实验从HDFS上分布式加载数据文件,默认采用Oblivious算法进行图分区。贪婪启发式的分区策略对所有的算法的执行时间和内存消耗都有明显降低。运行时时间和复制因子正相关。
7.2 同步引擎
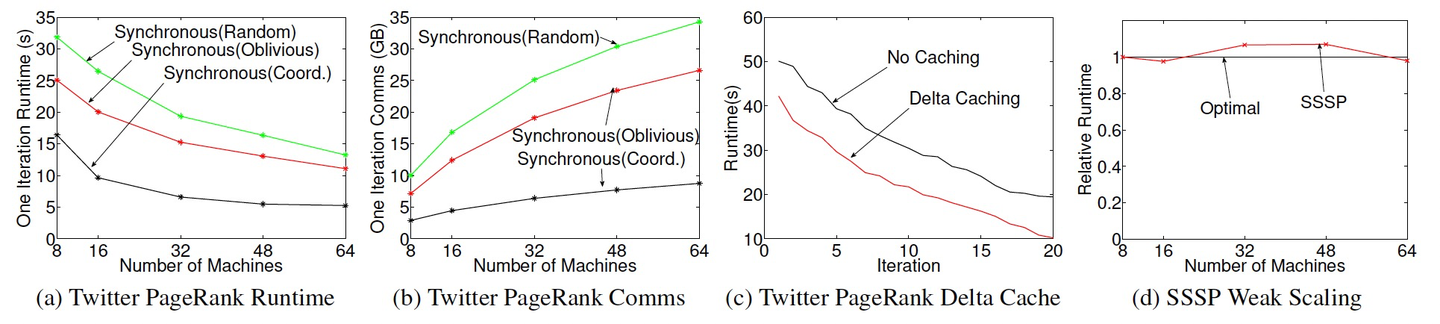
- PowerGraph是Spark的性能的3-8x。
- 尽管贪心启发式分区算法有加载成本,但依然带给任务更大的性能提升和通信量下降。
- Delta Caching:通过避免不必要的gather,运行耗时降低45%。
- Weak Scaling(Gustafson定律):保持单个处理器上的问题规模不变,效果接近理想值(65s处理6.4B的边图,衡量水平扩展能力,理想值是根据定律推导)。
7.3 异步引擎
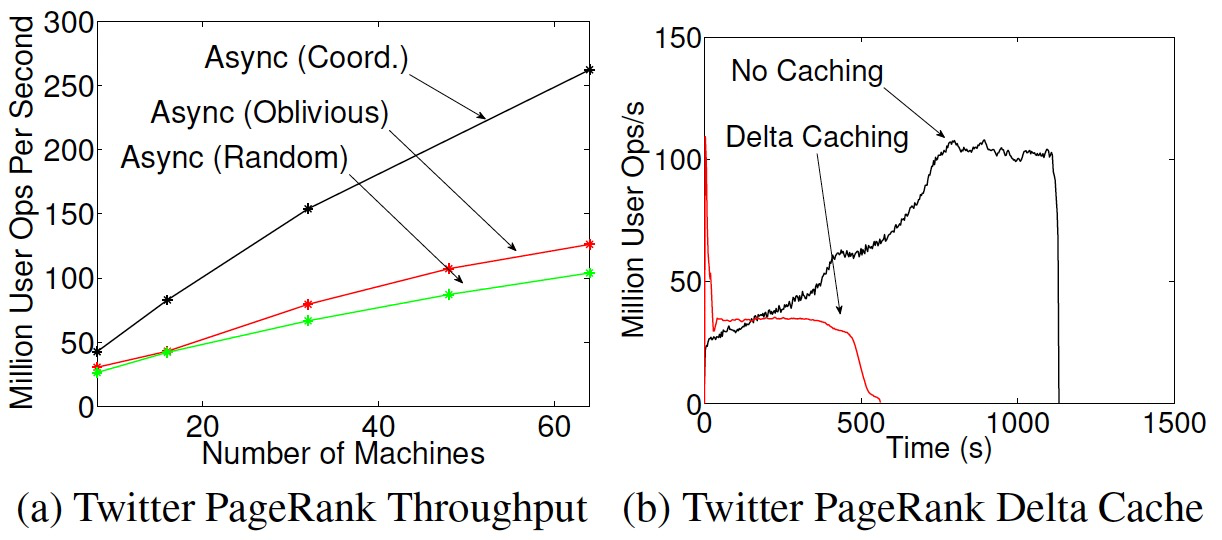
- PowerGraph使用状态机管理点状态:INACTIVE、GATHER、APPLY、SCATTER。
- 随着分区数的增加,任务的吞吐(点程序操作数/秒)稳定的增加。
- 使用Delta Caching可以让算法快速收敛,关闭Delta Caching吞吐会持续上升(计算聚焦到高度点时增加了计算通信比)。
- 使用同步方式跑图着色算法会导致算法无法收敛。(每次迭代都是更新同样的颜色 min c)
7.4 异步串行化引擎
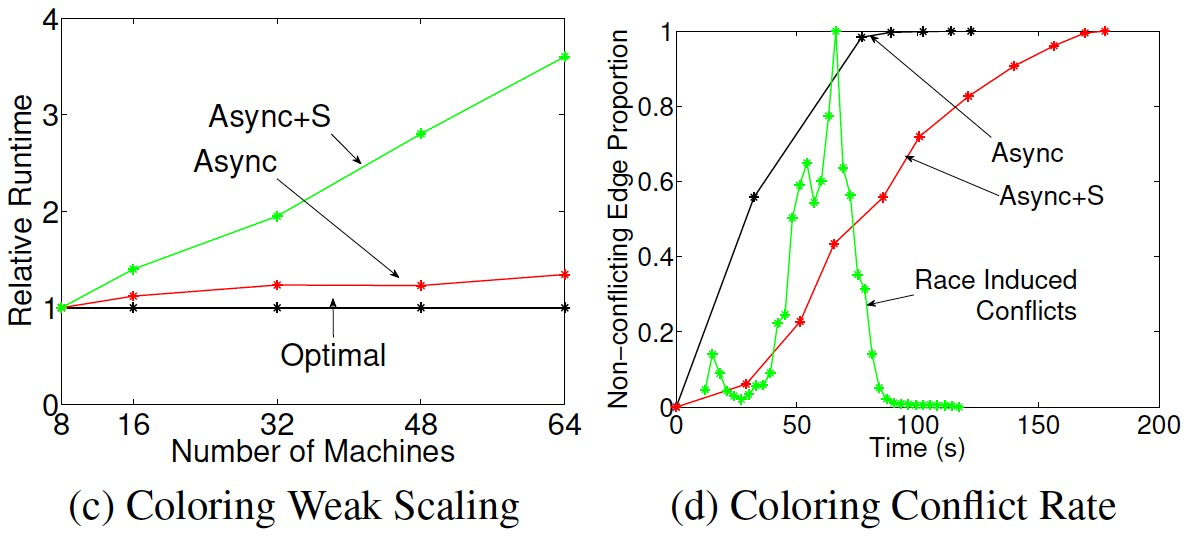
- 通过禁止邻点程序同时执行,实现串行化。
- 确保图并行计算的串行化等价于解决哲学家进餐问题:点=哲学家;边=叉子。(GraphLab采用Dijkstra的方案,PowerGraph采用Chandy-Misra的方案)
- 串行的并行度不随着点数线性增长,因为是幂律图,点密度是超线性增长的。
- 图着色问题,异步引擎可以快速的满足着色条件,但最后1%的边占用了34%的时间(长尾,高度点竞争),异步串行化相对更均匀。另外,异步引擎的多执行了2倍的操作。
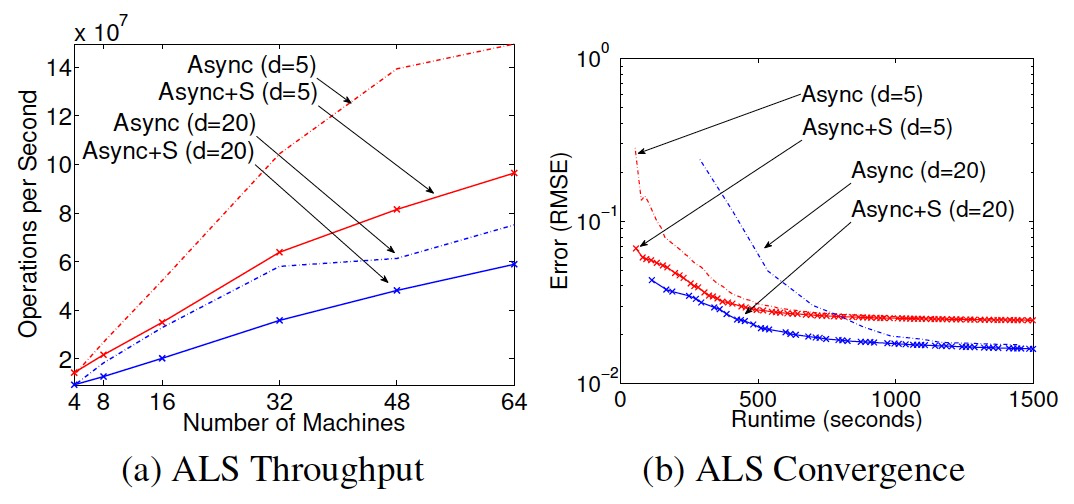
- ALS算法(交差最小二乘),异步引擎的吞吐更高,异步串行化的收敛更快。
7.5 错误容忍
- 同步引擎在超步间保存快照。
- 异步引擎先把任务挂起,再使用GraphLab的快照算法保存。
7.6 MLDM应用
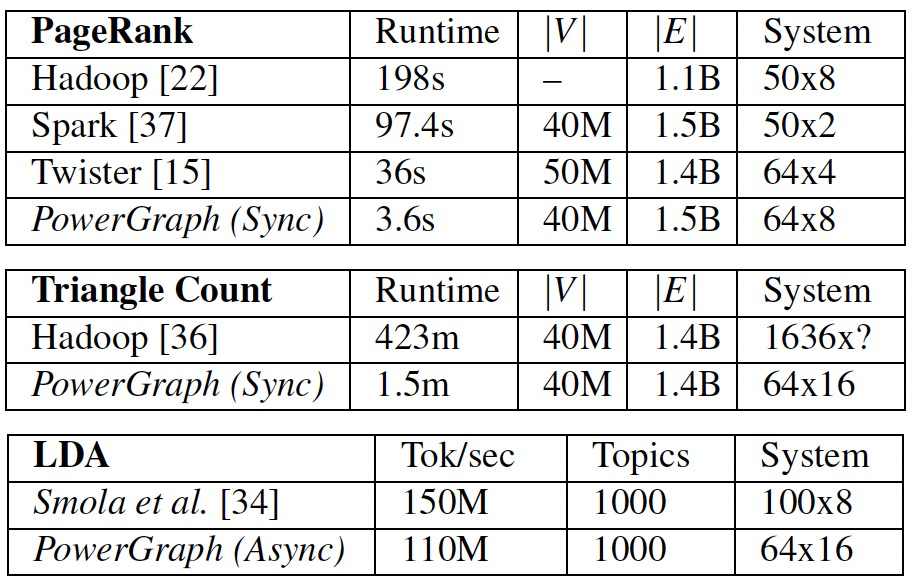
结论
- 超图:点切分问题可以被转换为超图的切分问题,通过将边转换为超图的点,将点转化为超图的边。但是超图切分属于时间密集型,而我们倾向于降低通信量这个目标。
- 流式点切分、流式边切分。
- GraphChi:可以借鉴补充外存的计算思路。
- 动态图计算:探索基于时间的图结构。