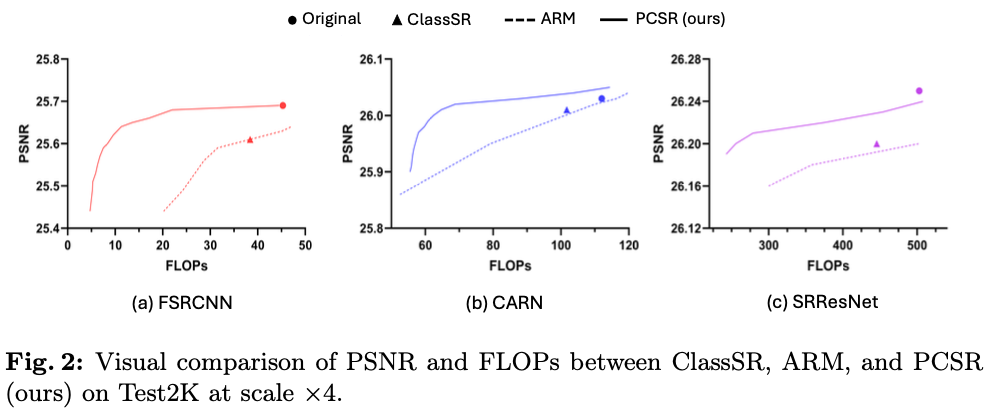
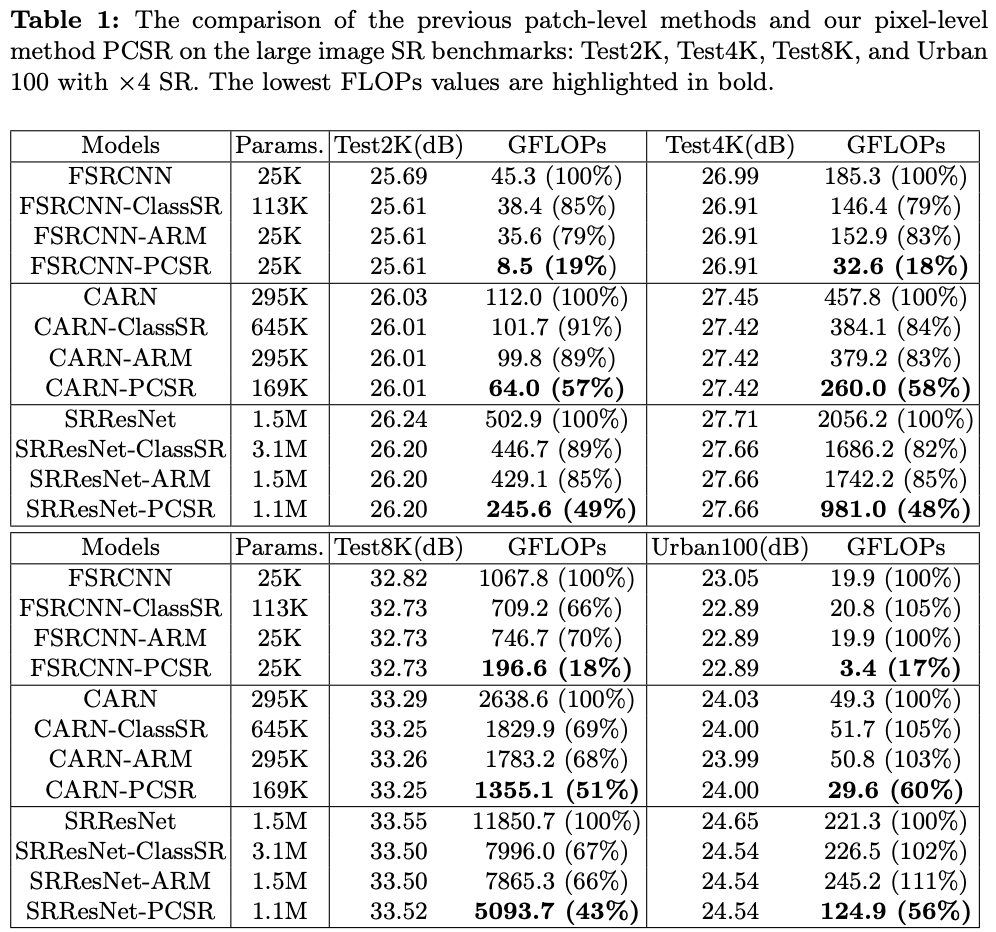
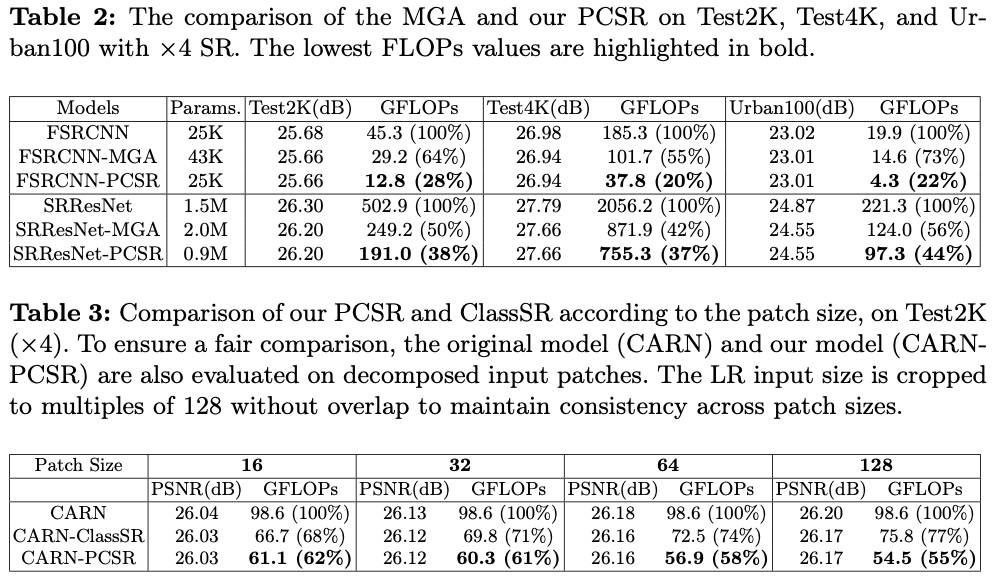
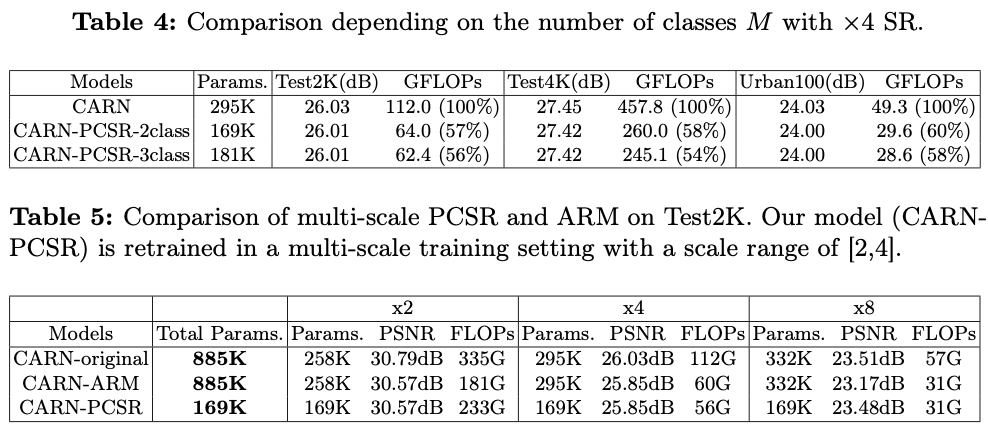
Linux | Ubuntu 16.04.4 通过docker安装单机FastDFS
Ubuntu 16.04.4 通过docker安装单机fastdfs
前言
很久没有写技术播客了,这是一件很不应该的事情,做完了事情应该有沉淀的。
我先说一点前情提要,公司的fastdfs突然就挂了,做过的操作就是日志文件太大了,所以把日志文件给删了,理论上这个动作应该不影响程序运行才对。
然后tracker怎么都启动不起来了。会报下面这个错误。
file: tracker_service.c, line: 2079, client ip: 47.xxx.xxx.52, group_name: group1, new ip address 172.xxx.xxx.217 != client ip address 47.xxx.xxx.52
我的tracker和storage都部署在同一台服务器上,其中47开头的是同一台服务器的公网IP,172开头的是这台服务器的内网IP。
然后tracker、storage和client的配置文件,我都改过一遍,都改成内网、都改成公网、一个是公网、一个是内网。反正就是不行。
不过我后来在搜索后续答案的过程中有受到一点启发,就是直接改一下host文件,给ip随便分配一个域名,这样后期的配置都用域名,有可能可以解决这个问题。
因为存储的数据都是从其他地方拉取过来的,只是过一个临时的中转,所以,里面的数据丢了也无所谓,于是,我就想,我索性重新再装一个fastdfs好了。
但是fastdfs并不能通过一个命令直接卸载,所以,我直接删除了它相关的各种文件。
但是有可能我删的不是很干净,在我装最新版本fastdfs的时候,编译
libserverframe
的时候,报下面这个错。
Makefile:59: recipe for target 'fdfs_monitor' failed
搜索了一圈,提到这个问题的人并不多,然后我试了直接从git上clone代码的方式,去git上下载压缩包再解压的方式,都编译不过去。
初步判断是依赖库的版本冲突了,或者有缺失。
这里再提一个题外话,我们在使用
make intall
命令的时候,应该习惯性加上
--prefix
参数,配置文件的安装路径,如下:
make install --prefix=/opt/application
如果不配的话,安装后可执行文件默认放在
/usr/local/bin
,库文件默认放在
/usr/local/lib
,配置文件默认放在
/usr/local/etc
,其它的资源文件放在
/usr/local/share
。
安装一时爽,卸载火葬场。
因为可能原因是版本冲突,然后我现在也卸载不干净了,于是我就想到了docker,docker是另外开辟出来的一个独立的环境,不受当前主环境影响,而且服务器上还有其他正在跑的服务,我也不可能重置服务器。不得不说docker真是一个好东西啊,是哪个小天才发明的。
fastdfs镜像选择
fastdfs并没有提供官方的镜像,所以只能用网友们自主创建的。
https://hub.docker.com/search?q=fastdfs
收藏最多的是一个season的镜像,不过,我看它的版本很老了,好像才1.2版,更新时间也是9年前了。所以我没有用这个,我看到好几篇文章里都用的是delron的镜像,所以我也用的这一个。当然这个也挺老了,6年前更新的。
但我急于解决问题,也没有心思去好好研究和挑选了,总之,亲测它单机好使,使用起来也比较方便,集成了nginx,可以直接通过浏览器访问资源。
镜像的拉取
如果你的这台机器,之前没有用过docker的话,还是一个老生常谈的问题,你很有可能连接超时,然后拉取失败,所以要配置镜像。
如果你还没有安装过docker,也可以先安装一下:
apt install docker.io
修改镜像配置文件 :
vim /etc/docker/daemon.json
把各种镜像的地址加上(没有缩进的那几个就是):
下面是从网上搜到的镜像:
DaoCloud https://docker.m.daocloud.io
阿里云 https://<your_code>.mirror.aliyuncs.com(阿里云提供了镜像源:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors 登录后你会获得一个专属的地址)
Docker镜像代理 https://dockerproxy.com
百度云 https://mirror.baidubce.com
南京大学 https://docker.nju.edu.cn
中科院 https://mirror.iscas.ac.cn
"https://yxzrazem.mirror.aliyuncs.com",
"http://hub-mirror.c.163.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
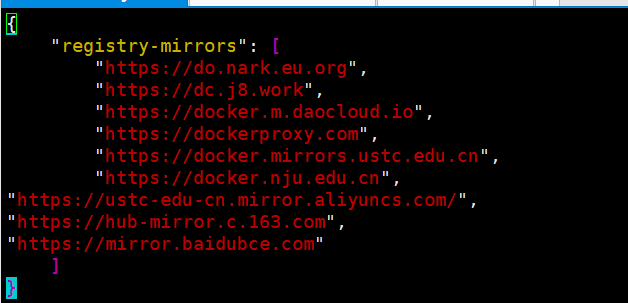
来一份示例方便粘贴
{
"registry-mirrors": [
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn",
"https://ustc-edu-cn.mirror.aliyuncs.com/",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com"
]
}
重新加载配置,并重启docker:
systemctl daemon-reload
systemctl restart docker
运行docker的tracker服务:
# 先创建文件夹,文件夹随便定义,我这里是为了方便,直接延用了别人播客的定义(其中-p是可以直接创建多级目录)
mkdir -p /mydata/fastdfs/tracker
cd /mydata/fastdfs/tracker
# 执行docker命令
docker run -d --name tracker --network=host -v /mydata/fastdfs/tracker:/var/fdfs delron/fastdfs tracker
# 注意:tracker服务默认的端口为22122
运行docker的storage服务:
# 创建文件夹
mkdir -p /mydata/fastdfs/storage
cd /mydata/fastdfs/storage
# 执行命令
docker run -d --name storage --network=host -e TRACKER_SERVER=x.x.x.x:22122 -v /mydata/fastdfs/storage:/var/fdfs -e GROUP_NAME=group1 delron/fastdfs storage
# 注意:其中TRACKER_SERVER中的ip要修改为你的Tracker服务所在的服务IP地址
# storage默认端口为23000
storage服务中默认安装了nginx,端口为8888
服务测试
1.在/mydata/fastdfs/storage下上传一张图片,1.png
2.进入storage容器,上传图片
# 进入storage容器
docker exec -it storage bash
# 进入容器内文件夹
cd /var/fdfs/
#执行上传命令
/usr/bin/fdfs_upload_file /etc/fdfs/client.conf 1.png
得到文件路径:
group1/M00/00/00/rBA12WbOG4OAW8SKAAM9zD7woDQ406.png
3.浏览器访问图片:
http://47.xxx.xxx.52:8888/group1/M00/00/00/rBA12WbOG4OAW8SKAAM9zD7woDQ406.png
能访问,说明上传下载一切正常。
参考(未必全)
https://rqsir.github.io/2019/04/13/linux-make-install的安装与卸载/
https://blog.csdn.net/weixin_50160384/article/details/139861337
https://www.cnblogs.com/likecoke/p/17495358.html
https://www.cnblogs.com/hequanbao/p/17035045.html