PCSR:已开源,三星提出像素级路由的超分辨率方法 | ECCV 2024
基于像素级分类器的单图像超分辨率方法(
PCSR
)是一种针对大图像高效超分辨率的新方法,在像素级别分配计算资源,处理不同的恢复难度,并通过更精细的粒度减少冗余计算。它还在推断过程中提供可调节性,平衡性能和计算成本而无需重新训练。此外,还提供了使用K均值聚类进行自动像素分配以及后处理技术来消除伪影。来源:晓飞的算法工程笔记 公众号
论文: Accelerating Image Super-Resolution Networks with Pixel-Level Classification

Introduction
单图像超分辨率(
SISR
)是一项专注于从低分辨率(
LR
)图像恢复高分辨率(
HR
)图像的任务。这一任务在数字摄影、医学成像、监控和安全等多个领域有广泛的实际应用。随着这些重要需求的增长,特别是在深度神经网络(
DNNs
)的推动下,
SISR
在过去几十年中取得了显著进展。
然而,随着新的
SISR
模型的推出,模型的容量和计算成本往往增加,这使得在具有有限资源的实际应用或设备中应用这些模型变得困难。因此,这导致了朝向设计更简单、高效的轻量级模型的转变,这些模型考虑了性能和计算成本之间的平衡。此外,还进行了大量研究,旨在减少现有模型的参数大小和/或浮点运算(
FLOPs
)数量,同时不影响其性能。
与此同时,对于高效的超分辨率(
SR
)技术的需求正在增加,尤其是随着为用户提供大规模图像的平台的兴起,例如先进的智能手机、高清电视或支持从
2K
到
8K
分辨率的专业显示器。然而,对大图像进行超分辨率处理是具有挑战性的;由于计算资源的限制,无法在单次处理中处理大图像(即每图像处理)。因此,处理大图像的常见方法是将给定的低分辨率(
LR
)图像分割成重叠的块,将超分辨率模型分别应用于每个块,然后合并输出以获得超分辨率图像。多项研究探讨了这种按块处理的方法,旨在提高现有模型的效率同时保持其性能。这些研究观察到,每个块的恢复难度各不相同,因此需要为每个块分配不同的计算资源。
尽管在块级别上自适应分配计算资源可以显著提高效率,但它存在两个限制可能阻碍其充分发挥更高效率的潜力:
- 由于超分辨率是一个低级视觉任务,即使是单个块也可能包含恢复难度不同的像素。当为包含简单像素的块分配大量计算资源时,可能会导致计算资源的浪费。相反,如果一个分配较少计算资源的块包含难处理的像素,会对性能产生负面影响。
- 这些所谓的块分配方法在较大块大小时效率降低,因为这些块更可能包含易处理和难处理像素的平衡混合。这引入了一个两难情境:我们可能希望使用较大的块,因为这不仅可以减少重叠区域中的冗余操作,还可以通过利用更多的上下文信息来增强性能。
本文的主要目标是增强现有的单幅图像超分辨率(
SISR
)模型的效率,特别是针对较大的图像。为了克服前述的块分配方法所面临的限制,论文提出了一种名为像素级分类器单幅图像超分辨率(
PCSR
)的新方法,专门设计用于在像素级别自适应分配计算资源。模型包括三个主要部分:骨干网络、像素级分类器和一组容量不同的像素级上采样器。该模型的运作如下:1)骨干网络接受低分辨率输入并生成低分辨率特征图。2)对于
HR
空间中的每个像素,像素级分类器使用低分辨率特征图和像素的相对位置预测将其分配给特定的上采样器的概率。3)每个像素都根据需要自适应地分配给适当大小的像素级上采样器来预测其
RGB
值。4)通过聚合每个像素的
RGB
值获得超分辨率输出。

这是首个在大图像高效
SR
背景下应用像素级分配方法的方法。通过像素级别地减少冗余计算,可以进一步提升块分配方法的效率,如图
1
所示。在推断阶段,为用户提供调节性,可以在不需要重新训练的情况下权衡性能和计算成本。虽然该方法使用户能够管理这种权衡,但论文还提供了一个额外的功能,根据
K-means
聚类算法自动分配像素,从而简化用户体验。最后,论文引入了一种后处理技术,有效消除可能由像素级计算分配引起的伪影。实验证明,论文的方法在多个基准测试中(包括
Test2K
/
4K
/
8K
和
Urban100
)在各种
SISR
模型的
PSNR-FLOP
权衡方面优于现有的块分配方法。论文还与基于每幅图像处理的方法进行了比较,后者是将图像作为整体而不是分解为块来处理。
Method
Preliminary
单图像超分辨率(
SISR
)是一项任务,旨在从单个低分辨率(
LR
)输入图像生成高分辨率(
HR
)图像。在神经网络的框架内,
SISR
模型旨在发现一个映射函数
\(F\)
,将给定的
LR
图像
\(I^{LR}\)
转换为
HR
图像
\(I^{HR}\)
。可以用以下方程表示:
I^{HR} = F(I^{LR}; \theta),
\end{equation}
\]
其中
\(\theta\)
是模型参数集合。典型模型可以分解为两个主要组件:1)从
\(I^{LR}\)
提取特征的骨干网络
\(B\)
,和2)利用这些特征重构
\(I^{HR}\)
的上采样器
\(U\)
。因此,这个过程可以进一步表示为:
Z = B(I^{LR}; \theta_B), \quad
I^{HR} = U(Z; \theta_U).
\end{align}
\]
在这里,
\(\theta_B\)
和
\(\theta_U\)
分别是骨干网络和上采样器的参数,
\(Z\)
是提取的特征。在基于卷积神经网络(
CNN
)的上采样器中,除了卷积层之外,还会使用多种操作来增加正在处理的图像的分辨率。这些操作范围从简单的插值到更复杂的方法,如反卷积或子像素卷积。与使用基于
CNN
的上采样器不同,可以采用基于多层感知器(
MLP
)的上采样器以像素级方式操作。
Network Architecture
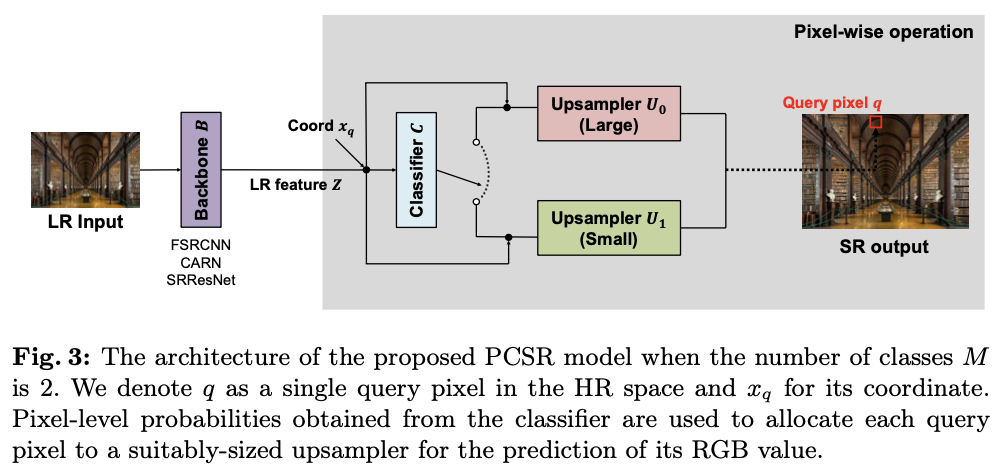
PCSR
的概述如图
3
所示,一个模型由一个骨干网络和一组上采样器组成。此外,使用一个分类器来衡量在高分辨率空间中恢复目标像素(即查询像素)的难度。低分辨率输入图像被送入骨干网络,并生成相应的低分辨率特征。然后,分类器确定每个查询像素的恢复难度,通过相应的上采样器计算其输出的
RGB
值。
Backbone
论文提出了一种像素级计算分布方法,用于高效的大图像超分辨率。可以使用任何现有的深度超分辨率网络作为骨干网络,以适应所需的模型大小。例如,可以采用小尺寸的
FSRCNN
,中等尺寸的
CARN
,大尺寸的
SRResNet
,以及其他模型。
Classifier
引入了一个基于
MLP
网络的轻量级分类器,以像素级方式获取属于每个上采样器(或类别)的概率。对于给定的查询像素坐标
\(x_q\)
,分类器根据分类概率将其分配给相应的上采样器,以预测其
RGB
值。通过将简单的像素适当地分配给轻量级上采样器而不是重型上采样器,可以在最小性能损失的情况下节省计算资源。
定义一个低分辨率输入为
\(X \in \mathbb{R}^{h \times w \times 3}\)
,其对应的高分辨率图像为
\(Y \in \mathbb{R}^{H \times W \times 3}\)
。设
\(\{y_i\}_{i=1...HW}\)
是高分辨率图像
\(Y\)
中每个像素的坐标,
\(\{Y(y_i)\}_{i=1...HW}\)
是相应的
RGB
值。首先,通过骨干网络从低分辨率输入计算出一个低分辨率特征
\(Z \in \mathbb{R}^{h \times w \times D}\)
。然后,给定类别数
\(M\)
,分类器
\(C\)
给出分类概率
\(p_i \in \mathbb{R}^M\)
:
p_i = \sigma(C(Z, y_i; \theta_C)),
\end{equation}
\]
其中,
\(\sigma\)
是
softmax
函数。基于
MLP
的分类器操作方式类似于一个上采样器,主要区别在于其输出维度为
\(M\)
Upsampler
采用
LIIF
作为上采样器,适用于像素级处理。首先,将先前定义的
\(y_i\)
从高分辨率空间归一化,将其映射到低分辨率空间中的坐标
\(\hat{y}_i \in \mathbb{R}^2\)
。给定低分辨率特征
\(Z\)
,将最接近
\(\hat{y}_i\)
(通过欧氏距离)的特征表示为
\(z_i^* \in \mathbb{R}^D\)
,并将其对应的坐标表示为
\(v_i^* \in \mathbb{R}^2\)
。然后,上采样过程总结如下:
\label{eq:liif1}
I^{SR}(y_i) = U(Z, y_i ; \theta_U) = U([z_i^*, \hat{y}_i-v_i^*]; \theta_U),
\end{align}
\]
其中,
\(I^{SR}(y_i) \in \mathbb{R}^3\)
是在
\(y_i\)
处的
RGB
值,[
\(\cdot\)
] 表示连接操作。通过查询每个
\(\{y_i\}_{i=1...HW}\)
处的
RGB
值并组合它们,可以得到最终的输出
\(I^{SR}\)
。在论文提出的方法中,可以利用
\(M\)
个并行的上采样器
\(\{U_0, U_1, ..., U_{M-1}\}\)
来处理各种恢复难度(即从重到轻的容量)。
Training
在训练阶段,将一个查询像素通过所有
\(M\)
个上采样器进行前向传播,并将输出聚合,以有效地反向传播梯度,具体操作如下:
\label{eq:pcsr2}
\hat{Y}(y_i) = \sum_{j=0}^{M-1} p_{i,j} \times U_j(Z,y_i;\theta_{U_j}),
\end{equation}
\]
其中,
\(\hat{Y}(y_i) \in \mathbb{R}^3\)
是在
\(y_i\)
处的
RGB
输出,
\(p_{i,j}\)
是该查询像素位于上采样器
\(U_j\)
中的概率。
然后,利用两种类型的损失函数:重构损失
\(L_{recon}\)
以及类似于
ClassSR
中使用的平均损失
\(L_{avg}\)
。重构损失定义为预测输出的
RGB
值与目标之间的
L1
损失,目标视为
GT
高分辨率(
HR
)块与双线性上采样的低分辨率(
LR
)输入块之间的差异。这是希望分类器能够通过强调高频特征来很好地执行分类任务,即使容量非常小。因此,损失可以表达为:
L_{recon} = \sum_{i=1}^{HW} \lvert (Y(y_{i}) - upX(y_{i})) - \hat{Y}(y_{i}) \rvert,
\end{equation}
\]
其中,
\(upX(y_i)\)
是双线性上采样的低分辨率(
LR
)输入块在位置
\(y_i\)
处的
RGB
值。对于平均损失,通过以下方式定义损失,以鼓励每个类别内像素的均匀分配:
\label{eq:loss2}
L_{avg} = \sum_{j=1}^{M} \lvert \sum_{n=1}^{N} \sum_{i=1}^{HW} p_{n,i,j} - \frac{NHW}{M} \rvert,
\end{equation}
\]
其中,
\(p_{n,i,j}\)
是第
\(n\)
张高分辨率图像(即批处理维度,批量大小为
\(N\)
)中第
\(i\)
个像素属于第
\(j\)
类的概率。在这里,将每个类别的概率视为分配给该类别的像素数量的有效数量。设置目标为
\(\frac{NHW}{M}\)
,希望在总共
\(NHW\)
个像素中,将相同数量的像素分配给每个类别(或者上采样器)。
最后,总损失
\(L\)
定义为:
L = w_{recon} \times L_{recon} + w_{avg} \times L_{avg}.
\end{equation}
\]
由于从头开始联合训练所有模块(即主干
\(B\)
,分类器
\(C\)
,以及上采样器
\(U_{j \in [0,M)}\)
)可能导致训练不稳定,所以采用多阶段训练策略。假设上采样器的容量从
\(U_0\)
逐渐减少到
\(U_{M-1}\)
,模型性能的上限由主干
\(B\)
和最重的上采样器
\(U_0\)
决定。因此,最初仅使用重构损失训练
\(\{B,U_0\}\)
。然后,从
\(j=1\)
到
\(j=M-1\)
,重复以下过程:先冻结已经训练好的
\(\{B, U_0, ..., U_{j-1}\}\)
,将
\(U_j\)
连接到主干(对于
\(j=1\)
还要新连接
\(C\)
),最后联合使用总损失训练
\(\{U_j, C\}\)
。
Inference
在
PCSR
的推断阶段,整体过程与训练类似,但查询像素根据预测的分类概率被分配给唯一的上采样器分支。虽然可以将像素分配给具有最高概率的分支,但论文为用户提供了在不重新训练的情况下控制计算性能平衡的能力。为此,论文考虑了
FLOP
(浮点运算数)计数在决策过程中的影响,定义并预先计算了每个上采样器
\(U_{j \in [0,M)}\)
的
FLOP
影响,如下:
cost(U_j) = \sigma(flops(B; (h_0, w_0)) + flops(U_j; (h_0, w_0))),
\end{equation}
\]
其中,
\(\sigma\)
是
softmax
函数,
\(flops(\cdot)\)
是给定固定分辨率
\((h_0, w_0)\)
的模块的
FLOPs
。像素
\(y_i\)
的分支分配如下确定:
argmax_j \frac{p_{i,j}}{[cost(U_j)]^k},
\end{equation}
\]
其中,
\(k\)
是一个超参数,
\(p_{i,j}\)
是之前提到的查询像素被分配到
\(U_j\)
的概率。根据定义,设置较低的
\(k\)
值会导致更多像素被分配给更重的上采样器,从而最小化性能下降但增加计算负载。相反,较高的
\(k\)
值会将更多像素分配给较轻的上采样器,以降低计算需求为代价接受性能下降。
Adaptive Decision Making (ADM)
尽管论文的方法允许用户管理计算性能平衡,论文还提供了一种额外功能,根据整个图像统计信息的概率值自动分配像素。其步骤如下:对于单个输入图像,给定
\(\forall p_{i,j}\)
并将
\(U_{j \in [0, \lfloor(M+1)/2\rfloor)}\)
视为重型上采样器,计算
\(sum_{0 \leq j<\lfloor(M+1)/2\rfloor} p_{i,j}\)
表示该像素的恢复难度,从而得到总数为
\(i\)
的值。然后使用聚类算法将这些值分组成
\(M\)
个簇。最后,根据每个簇的中心值将每个组分配给从最重的
\(U_0\)
到最轻的
\(U_{M-1}\)
的上采样器。可以采用
K-means
聚类算法来最小化计算负载,由于均匀初始化中心值,该过程具有确定性。
Pixel-wise Refinement
由于每个像素的
RGB
值是由独立的上采样器预测的,当相邻像素分配给具有不同容量的上采样器时可能会产生伪影。为了解决这个问题,论文提出了一个简单的解决方案:按容量将下半部分的上采样器视为轻型上采样器,上半部分视为重型上采样器,当相邻像素分配给不同类型的上采样器时则进行细化。具体而言,对于分配给
\(U_{j}\)
的像素,其中
\(\lfloor(M+1)/2\rfloor \leq j < M\)
(即轻型上采样器),如果至少有一个相邻像素被分配给
\(U_{j}\)
,其中
\(0 \leq j<\lfloor(M+1)/2\rfloor\)
(即重型上采样器),则将其
RGB
值替换为
SR
输出中相邻像素(包括自身)的平均值。像素级细化算法无需额外的前向处理,仅通过少量的额外计算有效减少伪影,并对整体性能影响最小。
Experiments
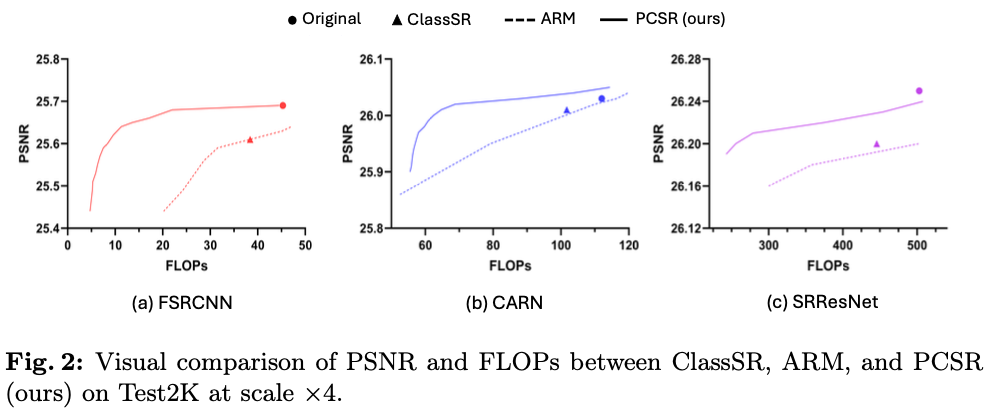
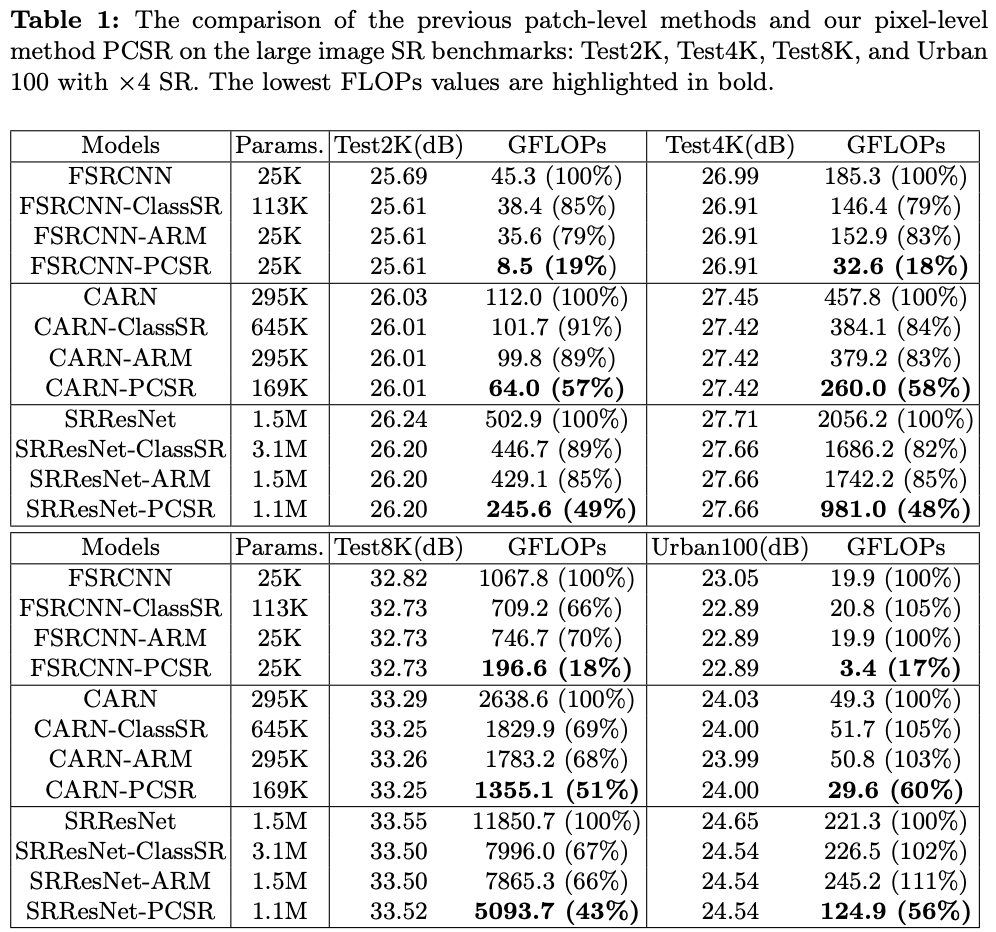
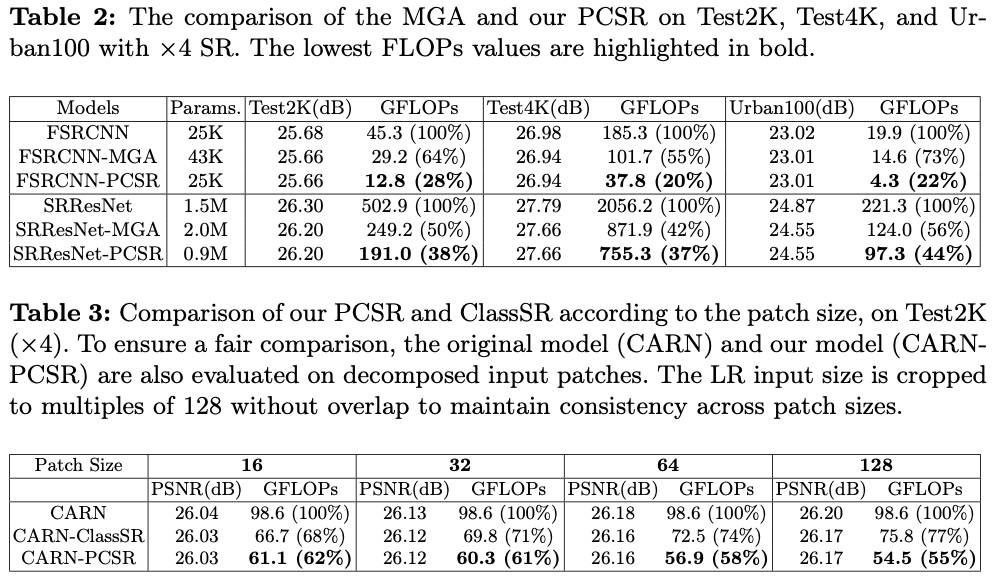


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
