无缝融入,即刻智能[一]:Dify-LLM大模型平台,零编码集成嵌入第三方系统,42K+星标见证专属智能方案
1.Dify 简介
1.1 功能情况
Dify,一款引领未来的开源大语言模型(LLM)应用开发平台,革新性地融合了后端即服务(Backend as a Service,BaaS)与LLMOps的精髓,为开发者铺设了一条从创意原型到高效生产的快车道。其设计旨在打破技术壁垒,让非技术背景的用户也能轻松参与至AI应用的构思与数据运营之中,共同塑造智能未来。
Dify内嵌了构建LLM应用的全方位技术基石,覆盖了从模型库的海量选择(支持数百种模型)到高效直观的Prompt编排界面,再到卓越品质的检索增强生成(RAG)引擎与稳固可靠的Agent框架。这一集成的技术栈,不仅极大地简化了开发流程,还赋予了开发者前所未有的灵活性与创意空间。通过其灵活的流程编排功能及用户友好的界面与API接口,Dify帮助开发者有效规避了重复劳动,使他们能够将宝贵的时间和精力集中于创新思考与业务需求的深度挖掘上。
Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you)。
核心功能列表:
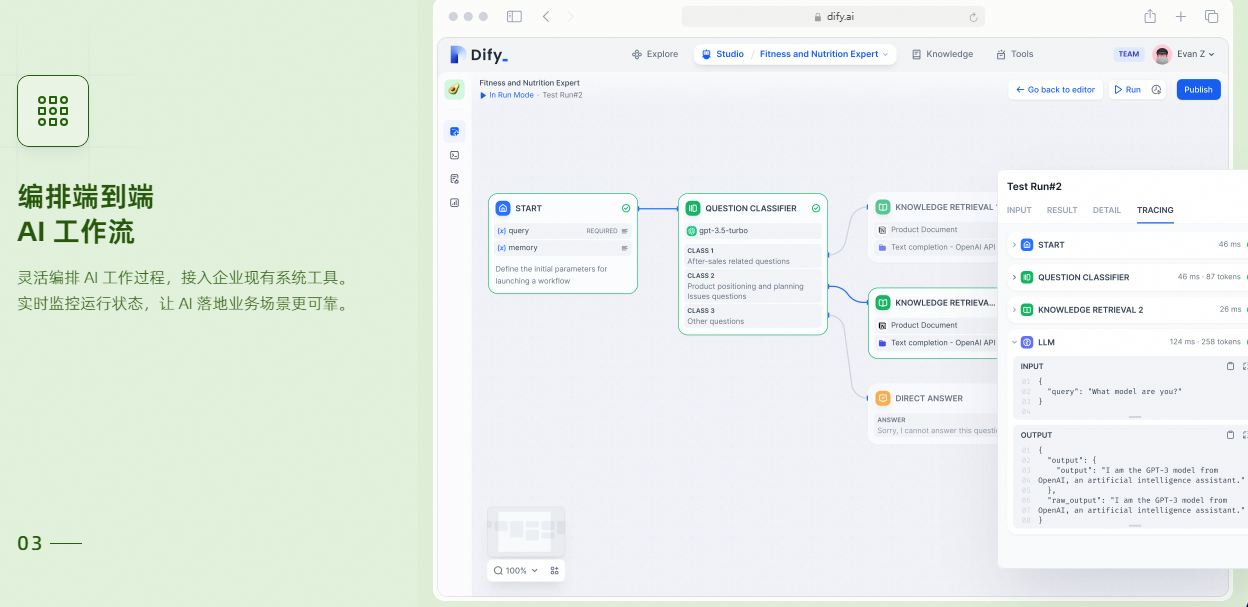
工作流
: 在画布上构建和测试功能强大的 AI 工作流程,利用以下所有功能以及更多功能。
全面的模型支持
: 与数百种专有/开源 LLMs 以及数十种推理提供商和自托管解决方案无缝集成,涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。
Prompt IDE
: 用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。
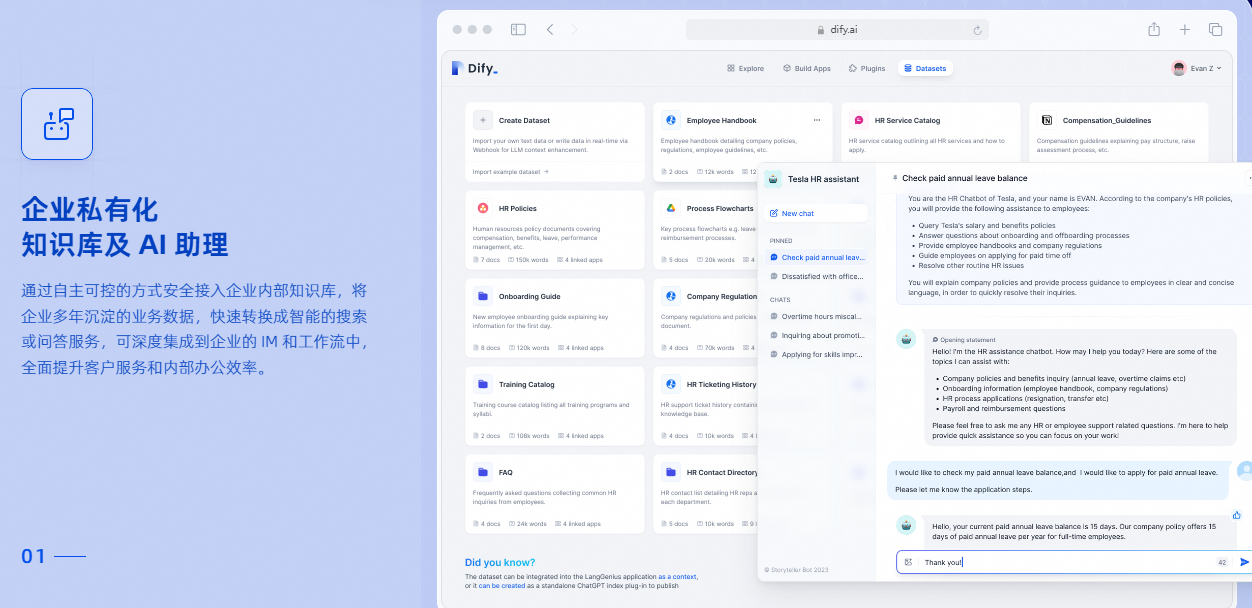
RAG Pipeline
: 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。
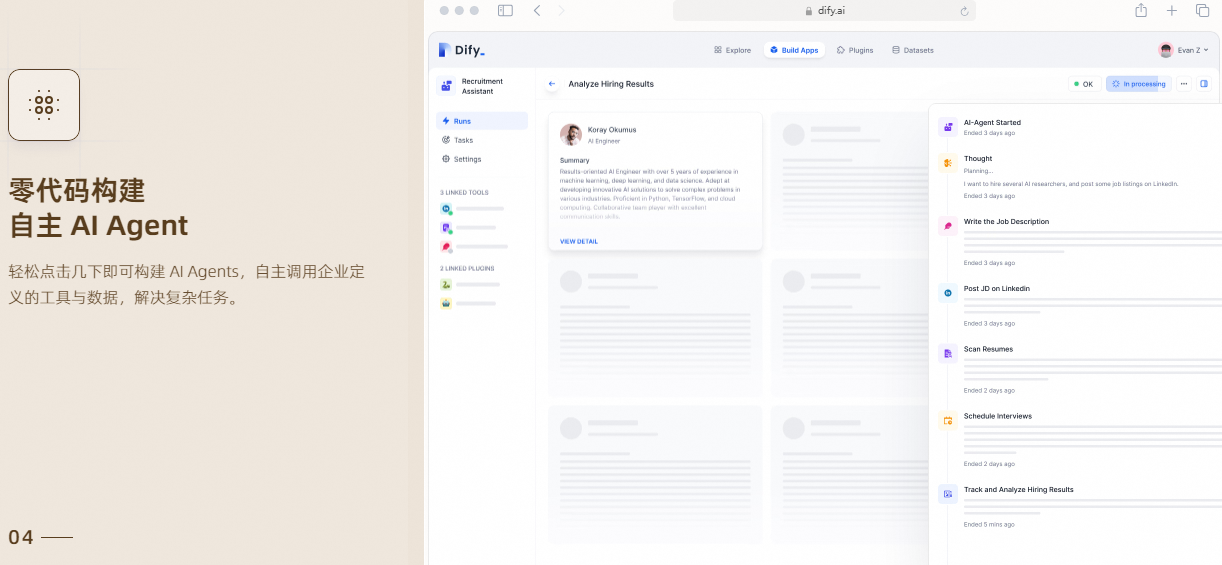
Agent 智能体
: 您可以基于 LLM 函数调用或 ReAct 定义 Agent,并为 Agent 添加预构建或自定义工具。Dify 为 AI Agent 提供了50多种内置工具,如谷歌搜索、DALL·E、Stable Diffusion 和 WolframAlpha 等。
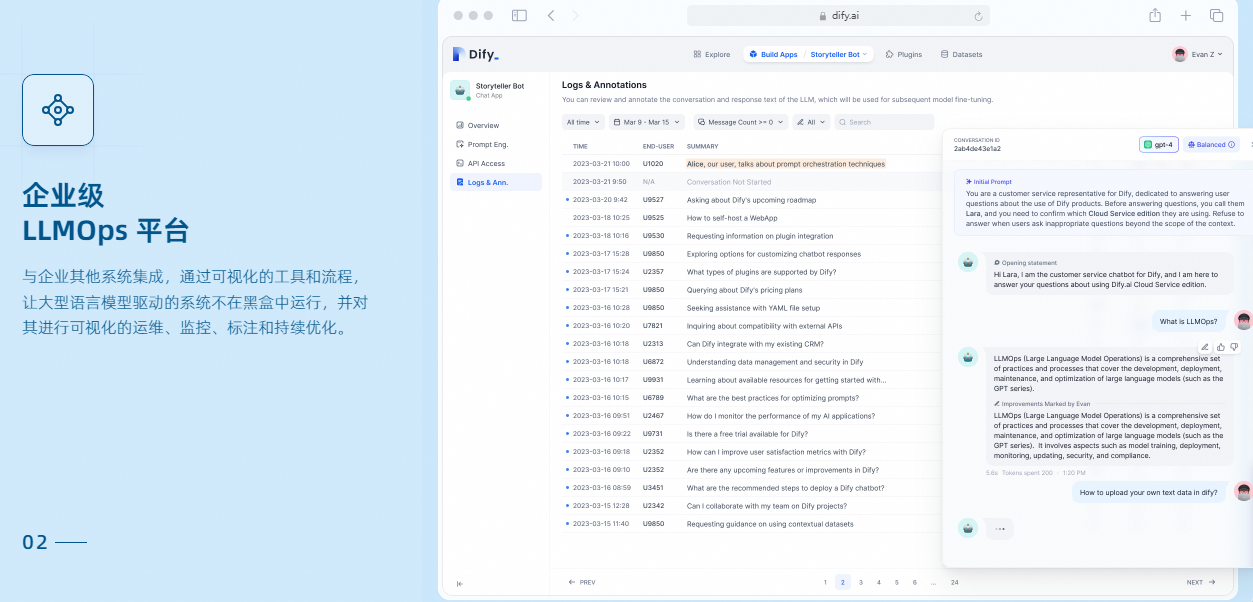
LLMOps
: 随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。
后端即服务
: 所有 Dify 的功能都带有相应的 API,因此您可以轻松地将 Dify 集成到自己的业务逻辑中。
功能对比
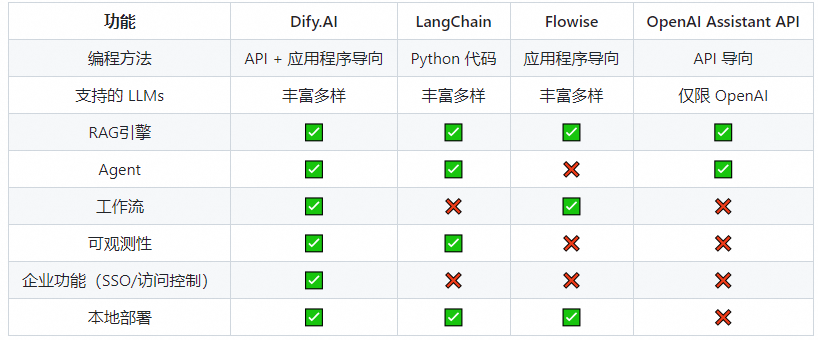
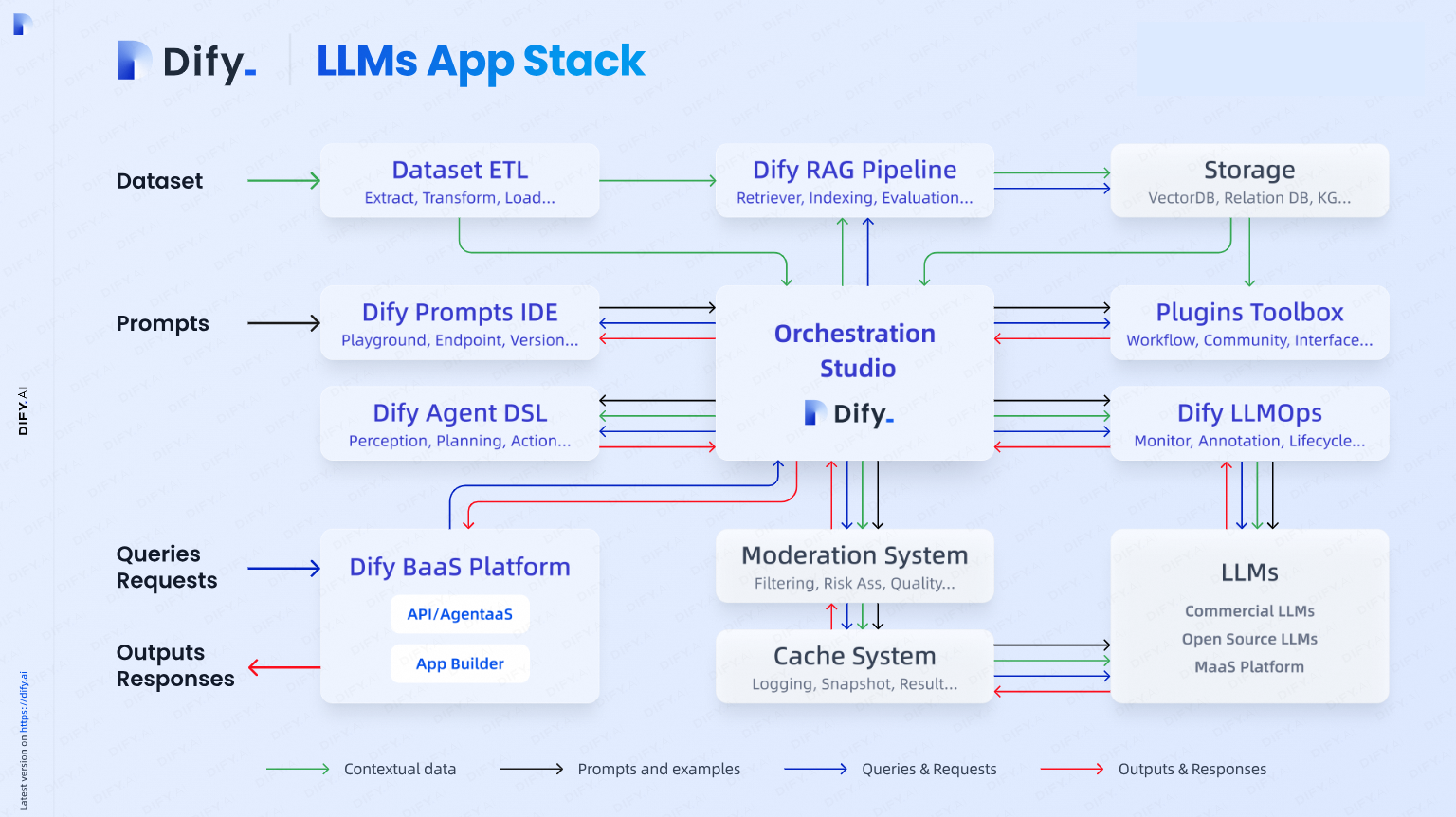
1.2 关键技术特性
本地模型推理 Runtime 支持
:Xinference(推荐),OpenLLM,LocalAI,ChatGLM,Ollama,NVIDIA TIS
Agentic Workflow 特性
:支持节点
- LLM
- 知识库检索
- 问题分类
- 条件分支
- 代码执行
- 模板转换
- HTTP 请求
- 工具
RAG特性:
- 索引方式
- 关键词
- 文本向量
- 由 LLM 辅助的问题-分段模式
- 检索方式
- 召回优化技术
向量数据库支持:Qdrant,Weaviate,Zilliz/Milvus,Pgvector,Pgvector-rs,Chroma,OpenSearch,TiDB,Tencent Vector,Oracle
1.3 云服务
Dify 为所有人提供了云服务,你无需自己部署即可使用 Dify 的完整功能。要使用 Dify 云服务,你需要有一个 GitHub 或 Google 账号。
1.4 更多LLM平台参考:
2. 社区版部署
2.1 Docker Compose 部署(推荐)

docker安装可参考下述文章:
克隆 Dify 代码仓库
git clone https://github.com/langgenius/dify.git
#进入 Dify 源代码的 docker 目录,执行一键启动命令:
cd dify/docker
cp .env.example .env
docker compose up -d
如果您的系统安装了 Docker Compose V2 而不是 V1,请使用 docker compose 而不是 docker-compose。通过$ docker compose version检查这是否为情况。在这里阅读更多信息。
遇到pulling失败问题,请添加镜像源,参考上述推荐文章有解决方案
- 部署结果展示:
最后检查是否所有容器都正常运行:
docker compose ps
包括 3 个业务服务 api / worker / web,以及 6 个基础组件 weaviate / db / redis / nginx / ssrf_proxy / sandbox 。

NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.6.16 "/bin/bash /entrypoi…" api 15 minutes ago Up 15 minutes 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db 15 minutes ago Up 15 minutes (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx 15 minutes ago Up 15 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis 15 minutes ago Up 15 minutes (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.1 "/main" sandbox 15 minutes ago Up 15 minutes
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy 15 minutes ago Up 15 minutes 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate 15 minutes ago Up 15 minutes
docker-web-1 langgenius/dify-web:0.6.16 "/bin/sh ./entrypoin…" web 15 minutes ago Up 15 minutes 3000/tcp
docker-worker-1 langgenius/dify-api:0.6.16 "/bin/bash /entrypoi…" worker 15 minutes ago Up 15 minutes 5001/tcp
进入 dify 源代码的 docker 目录,按顺序执行以下命令:
cd dify/docker
docker compose down
git pull origin main
docker compose pull
docker compose up -d
同步环境变量配置 (重要!)
docker 部署运行完成后,输入指令sudo docker ps即可看到运行的容器,其中在运行的容器列表可以看到有个 nginx 的容器,且对外访问的是 80 端口,这个就是外部访问的端口,下面我们进行本地访问测试
在浏览器中输入
http://localhost
访问 Dify。访问
http://127.0.0.1:80
即可使用本地部署的 Dify。
10.80.2.195:80

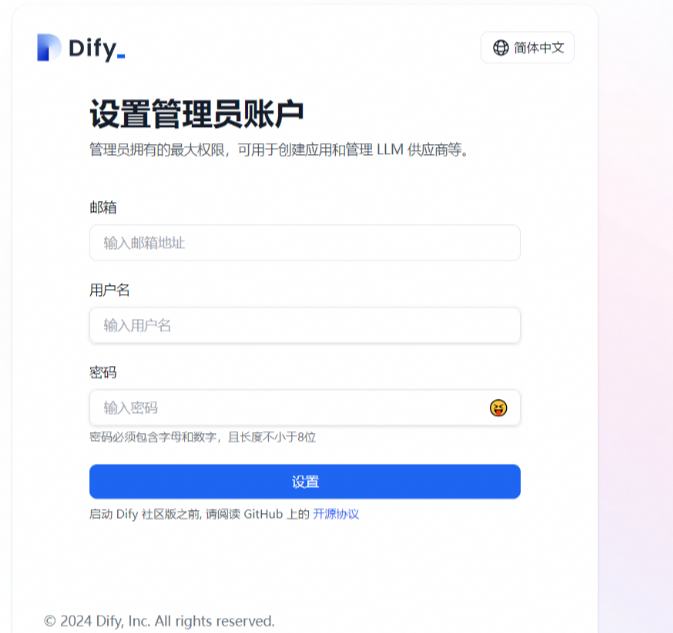
随便填写,进入界面
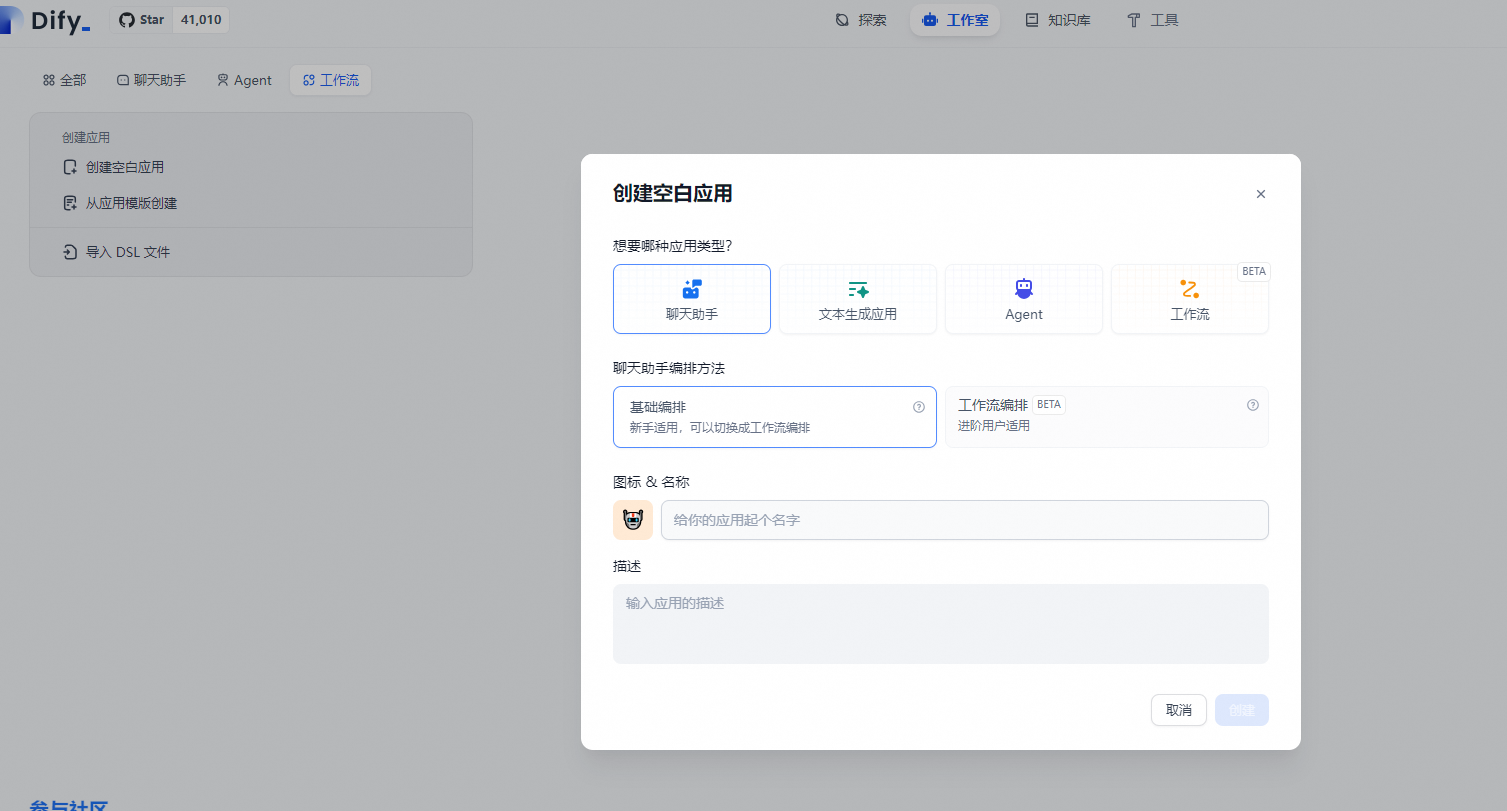
编辑 .env 文件中的环境变量值。然后,重新启动 Dify:
docker compose down
docker compose up -d
完整的环境变量集合可以在 docker/.env.example 中找到。
2.2 本地码源部署

Clone Dify 代码:
git clone https://github.com/langgenius/dify.git
在启用业务服务之前,需要先部署 PostgresSQL / Redis / Weaviate(如果本地没有的话),可以通过以下命令启动:
cd docker
cp middleware.env.example middleware.env
docker compose -f docker-compose.middleware.yaml up -d
- 进入 api 目录
cd api
- 复制环境变量配置文件.
cp .env.example .env
- 生成随机密钥,并替换 .env 中 SECRET_KEY 的值
openssl rand -base64 42
sed -i 's/SECRET_KEY=.*/SECRET_KEY=<your_value>/' .env
- 安装依赖包
Dify API 服务使用 Poetry 来管理依赖。您可以执行 poetry shell 来激活环境。
poetry env use 3.10
poetry install
- 执行数据库迁移,将数据库结构迁移至最新版本。
poetry shell
flask db upgrade
- 启动 API 服务
flask run --host 0.0.0.0 --port=5001 --debug
正确输出:
* Debug mode: on
INFO:werkzeug:WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5001
INFO:werkzeug:Press CTRL+C to quit
INFO:werkzeug: * Restarting with stat
WARNING:werkzeug: * Debugger is active!
INFO:werkzeug: * Debugger PIN: 695-801-919
- 启动 Worker 服务
用于消费异步队列任务,如数据集文件导入、更新数据集文档等异步操作。 Linux / MacOS 启动:
celery -A app.celery worker -P gevent -c 1 -Q dataset,generation,mail,ops_trace --loglevel INFO
如果使用 Windows 系统启动,请替换为该命令:
celery -A app.celery worker -P solo --without-gossip --without-mingle -Q dataset,generation,mail,ops_trace --loglevel INFO
-------------- celery@TAKATOST.lan v5.2.7 (dawn-chorus)
--- ***** -----
-- ******* ---- macOS-10.16-x86_64-i386-64bit 2023-07-31 12:58:08
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: app:0x7fb568572a10
- ** ---------- .> transport: redis://:**@localhost:6379/1
- ** ---------- .> results: postgresql://postgres:**@localhost:5432/dify
- *** --- * --- .> concurrency: 1 (gevent)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> dataset exchange=dataset(direct) key=dataset
.> generation exchange=generation(direct) key=generation
.> mail exchange=mail(direct) key=mail
[tasks]
. tasks.add_document_to_index_task.add_document_to_index_task
. tasks.clean_dataset_task.clean_dataset_task
. tasks.clean_document_task.clean_document_task
. tasks.clean_notion_document_task.clean_notion_document_task
. tasks.create_segment_to_index_task.create_segment_to_index_task
. tasks.deal_dataset_vector_index_task.deal_dataset_vector_index_task
. tasks.document_indexing_sync_task.document_indexing_sync_task
. tasks.document_indexing_task.document_indexing_task
. tasks.document_indexing_update_task.document_indexing_update_task
. tasks.enable_segment_to_index_task.enable_segment_to_index_task
. tasks.generate_conversation_summary_task.generate_conversation_summary_task
. tasks.mail_invite_member_task.send_invite_member_mail_task
. tasks.remove_document_from_index_task.remove_document_from_index_task
. tasks.remove_segment_from_index_task.remove_segment_from_index_task
. tasks.update_segment_index_task.update_segment_index_task
. tasks.update_segment_keyword_index_task.update_segment_keyword_index_task
[2024-07-31 13:58:08,831: INFO/MainProcess] Connected to redis://:**@localhost:6379/1
[2024-07-31 13:58:08,840: INFO/MainProcess] mingle: searching for neighbors
[2024-07-31 13:58:09,873: INFO/MainProcess] mingle: all alone
[2024-07-31 13:58:09,886: INFO/MainProcess] pidbox: Connected to redis://:**@localhost:6379/1.
[2024-07-31 13:58:09,890: INFO/MainProcess] celery@TAKATOST.lan ready.
前端页面部署
安装基础环境
Web 前端服务启动需要用到
Node.js v18.x (LTS)
、
NPM 版本 8.x.x
或
Yarn
。
安装 NodeJS + NPM
进入
https://nodejs.org/en/download,选择对应操作系统的
v18.x 以上的安装包下载并安装,建议 stable 版本,已自带 NPM。
- 进入 web 目录,安装依赖包
cd web
npm install
- 配置环境变量。在当前目录下创建文件 .env.local,并复制.env.example中的内容。根据需求修改这些环境变量的值:
#For production release, change this to PRODUCTION
NEXT_PUBLIC_DEPLOY_ENV=DEVELOPMENT
#The deployment edition, SELF_HOSTED
NEXT_PUBLIC_EDITION=SELF_HOSTED
#The base URL of console application, refers to the Console base URL of WEB service if console domain is
#different from api or web app domain.
#example: http://cloud.dify.ai/console/api
NEXT_PUBLIC_API_PREFIX=http://localhost:5001/console/api
#The URL for Web APP, refers to the Web App base URL of WEB service if web app domain is different from
#console or api domain.
#example: http://udify.app/api
NEXT_PUBLIC_PUBLIC_API_PREFIX=http://localhost:5001/api
#SENTRY
NEXT_PUBLIC_SENTRY_DSN=
NEXT_PUBLIC_SENTRY_ORG=
NEXT_PUBLIC_SENTRY_PROJECT=
- 构建代码,启动 web 服务
npm run build
npm run start
#or
yarn start
#or
pnpm start
ready - started server on 0.0.0.0:3000, url: http://localhost:3000
warn - You have enabled experimental feature (appDir) in next.config.js.
warn - Experimental features are not covered by semver, and may cause unexpected or broken application behavior. Use at your own risk.
info - Thank you for testing `appDir` please leave your feedback at https://nextjs.link/app-feedback
访问 Dify
在浏览器中输入
http://localhost
访问 Dify。访问
http://127.0.0.1:3000
即可使用本地部署的 Dify。
2.3 单独启动前端 Docker 容器
当单独开发后端时,可能只需要源码启动后端服务,而不需要本地构建前端代码并启动,因此可以直接通过拉取 docker 镜像并启动容器的方式来启动前端服务,以下为具体步骤:
docker run -it -p 3000:3000 -e CONSOLE_API_URL=http://127.0.0.1:5001 -e APP_API_URL=http://127.0.0.1:5001 langgenius/dify-web:latest
3. Ollama 部署的本地模型
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。,这是 Ollama 的官网地址:
https://ollama.com/
以下是其主要特点和功能概述:
- 简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。
- 轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
- API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
- 预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源
3.1 一键安装
curl: (77) error setting certificate verify locations:CAfile: /data/usr/local/anaconda/ssl/cacert.pemCApath: none
报错原因: cacert.pem 的寻址路径 CAfile 不对,也就是在该路径下找不到文件。
- 找到你的 cacert.pem 文件所在位置 /path/to/cacert.pem。如果你没有该证书,可以先在
https://curl.se/ca/cacert.pem
下载,保存在某个目录中。
- 设置环境变量
export CURL_CA_BUNDLE=/path/to/cacert.pem
#将"/path/to/cacert.pem"替换为你的证书文件的实际路径。
export CURL_CA_BUNDLE=/www/anaconda3/anaconda3/ssl/cacert.pem
curl -fsSL https://ollama.com/install.sh | sh
3.2 手动安装
ollama中文网:
https://ollama.fan/getting-started/linux/
- 下载 ollama 二进制文件:Ollama 以自包含的二进制文件形式分发。将其下载到您的 PATH 中的目录:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
- 将 Ollama 添加为启动服务(推荐):为 Ollama 创建一个用户:
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
3.在 /etc/systemd/system/ollama.service 中创建一个服务文件:
#vim ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
- 然后启动服务:
sudo systemctl enable ollama
- 启动 Ollama¶
使用 systemd 启动 Ollama:
sudo systemctl start ollama
- 更新,查看日志
#再次运行
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
#要查看作为启动服务运行的 Ollama 的日志,请运行:
journalctl -u ollama
- 步骤7:关闭 Ollama 服务
#关闭ollama服务
service ollama stop
3.3 Linux内网离线安装Ollama
- 查看服务器CPU的型号
##查看Linux系统CPU型号命令,我的服务器cpu型号是x86_64
lscpu
- 步骤2:根据CPU型号下载Ollama安装包,并保存到目录
下载地址:
https://github.com/ollama/ollama/releases/
#x86_64 CPU选择下载ollama-linux-amd64
#aarch64|arm64 CPU选择下载ollama-linux-arm64
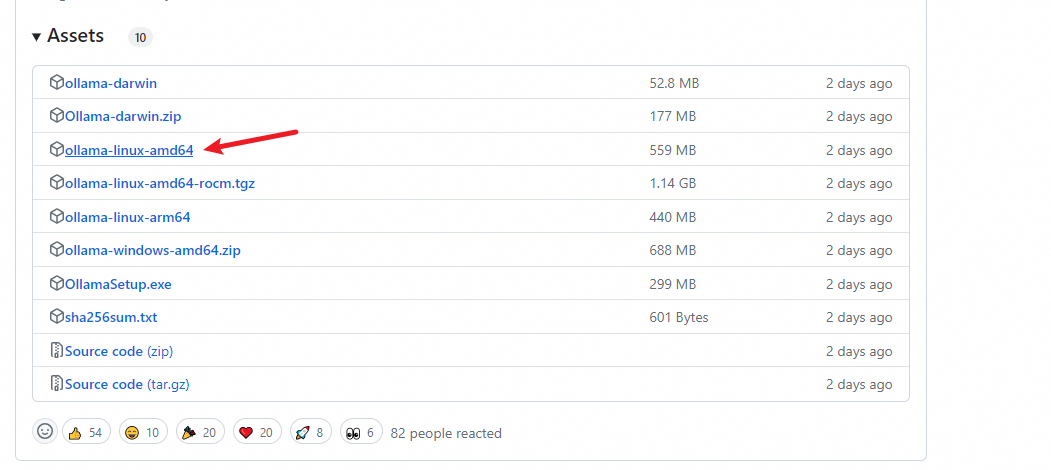
#有网机器下载过来也一样
wget https://ollama.com/download/ollama-linux-amd64
下载到离线服务器上:/usr/bin/ollama ollama就是你下载的ollama-linux-amd64 改名了(mv),其他步骤一致
3.4 修改存储路径
Ollama模型默认存储在:
- macOS: ~/.ollama/models
- Linux: /usr/share/ollama/.ollama/models
- Windows: C:\Users<username>.ollama\models
如果 Ollama 作为 systemd 服务运行,则应使用以下命令设置环境变量systemctl:
通过调用 来编辑 systemd 服务systemctl edit ollama.service。这将打开一个编辑器。
Environment对于每个环境变量,在部分下添加一行[Service]:
直接在“/etc/systemd/system/ollama.service”增了2行:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:7861"
Environment="OLLAMA_MODELS=/www/algorithm/LLM_model/models"
保存并退出。
重新加载systemd并重新启动 Ollama:
systemctl restart ollama
参考链接:
https://github.com/ollama/ollama/blob/main/docs/faq.md
- 使用 systemd 启动 Ollama:
sudo systemctl start ollama
- 终止
终止(ollama加载的大模型将会停止占用显存,此时ollama属于失联状态,部署和运行操作失效,会报错:
Error: could not connect to ollama app, is it running?需要启动后,才可以进行部署和运行操作
systemctl stop ollama.service
- 终止后启动(启动后,可以接着使用ollama 部署和运行大模型)
systemctl start ollama.service
3.5 启动LLM
ollama pull llama3.1
ollama pull qwen2
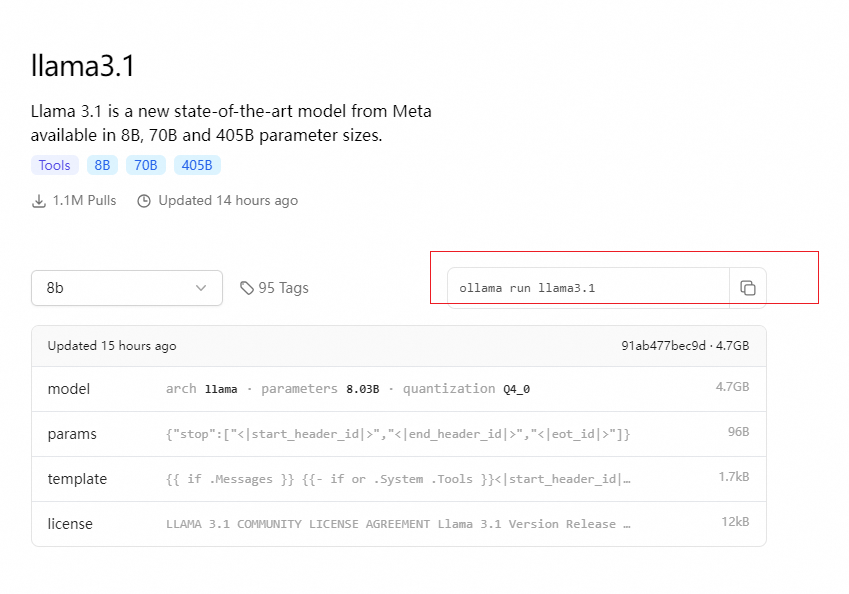
ollama run llama3.1
ollama run qwen2

- 查看是否识别到大模型:
ollama list
, 如果成功, 则会看到大模型
ollama list
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 3 hours ago
- 使用该
ollama ps
命令查看当前已加载到内存中的模型。
NAME ID SIZE PROCESSOR UNTIL
qwen2:latest e0d4e1163c58 5.7 GB 100% GPU 3 minutes from now
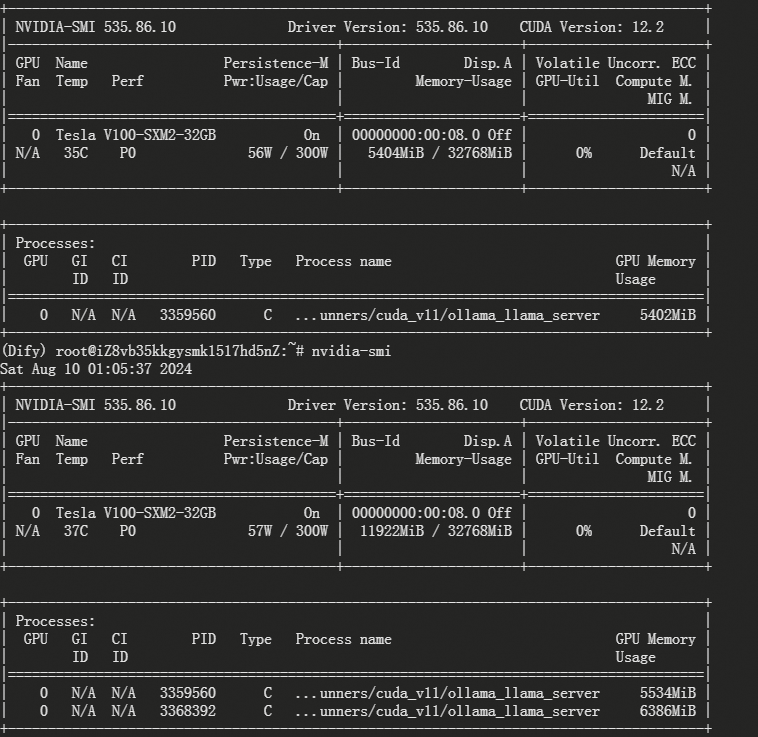
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.86.10 Driver Version: 535.86.10 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla V100-SXM2-32GB On | 00000000:00:08.0 Off | 0 |
| N/A 35C P0 56W / 300W | 5404MiB / 32768MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 3062036 C ...unners/cuda_v11/ollama_llama_server 5402MiB |
+---------------------------------------------------------------------------------------+
curl http://10.80.2.195:7861/api/chat -d '{
"model": "llama3.1",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
3.6 更多其他配置
Ollama 可以设置的环境变量
:
OLLAMA_HOST
:这个变量定义了Ollama监听的网络接口。通过设置OLLAMA_HOST=0.0.0.0,我们可以让Ollama监听所有可用的网络接口,从而允许外部网络访问。
OLLAMA_MODELS
:这个变量指定了模型镜像的存储路径。通过设置OLLAMA_MODELS=F:\OllamaCache,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。
OLLAMA_KEEP_ALIVE
:这个变量控制模型在内存中的存活时间。设置OLLAMA_KEEP_ALIVE=24h可以让模型在内存中保持24小时,提高访问速度。
OLLAMA_PORT
:这个变量允许我们更改Ollama的默认端口。例如,设置OLLAMA_PORT=8080可以将服务端口从默认的11434更改为8080。
OLLAMA_NUM_PARALLEL
:这个变量决定了Ollama可以同时处理的用户请求数量。设置OLLAMA_NUM_PARALLEL=4可以让Ollama同时处理两个并发请求。
OLLAMA_MAX_LOADED_MODELS
:这个变量限制了Ollama可以同时加载的模型数量。设置OLLAMA_MAX_LOADED_MODELS=4可以确保系统资源得到合理分配。
Environment="OLLAMA_PORT=9380" 没有用
vim /etc/systemd/system/ollama.service
[Service]
Environment="CUDA_VISIBLE_DEVICES=0,1"
3.7 Ollama常见命令
- 重启 ollama
systemctl daemon-reload
systemctl restart ollama
- 重启 ollama 服务
ubuntu/debian
sudo apt update
sudo apt install lsof
stop ollama
lsof -i :11434
kill <PID>
ollama serve
sudo apt update
sudo apt install lsof
stop ollama
lsof -i :11434
kill <PID>
ollama serve
- 确认服务端口状态:
netstat -tulpn | grep 11434
- 配置服务
为使外网环境能够访问到服务,需要对 HOST 进行配置。
打开配置文件:
vim /etc/systemd/system/ollama.service
根据情况修改变量 Environment:
服务器环境下:
Environment="OLLAMA_HOST=0.0.0.0:11434"
虚拟机环境下:
Environment="OLLAMA_HOST=服务器内网IP地址:11434"
3.8 卸载Ollama
如果决定不再使用Ollama,可以通过以下步骤将其完全从系统中移除:
(1)停止并禁用服务:
sudo systemctl stop ollama
sudo systemctl disable ollama
(2)删除服务文件和Ollama二进制文件:
sudo rm /etc/systemd/system/ollama.service
sudo rm $(which ollama)
(3)清理Ollama用户和组:
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
通过以上步骤,不仅能够在Linux平台上成功安装和配置Ollama,还能够灵活地进行更新和卸载。
4.配置LLM+Dify
netstat -tulnp | grep ollama
#netstat -tulpn | grep 11434
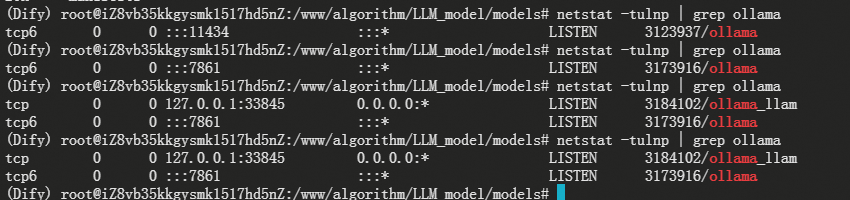
- 报错: "Error: could not connect to ollama app, is it running?"
参考链接:
https://stackoverflow.com/questions/78437376/run-ollama-run-llama3-in-colab-raise-err-error-could-not-connect-to-ollama
/etc/systemd/system/ollama.service文件是:
[Service]
ExecStart=/usr/local/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0:7861"
Environment="OLLAMA_KEEP_ALIVE=-1"
export OLLAMA_HOST=0.0.0.0:7861
ollama list
ollama run llama3.1
#直接添加到环境变量也可以
vim ~/.bashrc
source ~/.bashrc
在 设置 > 模型供应商 > Ollama 中填入:
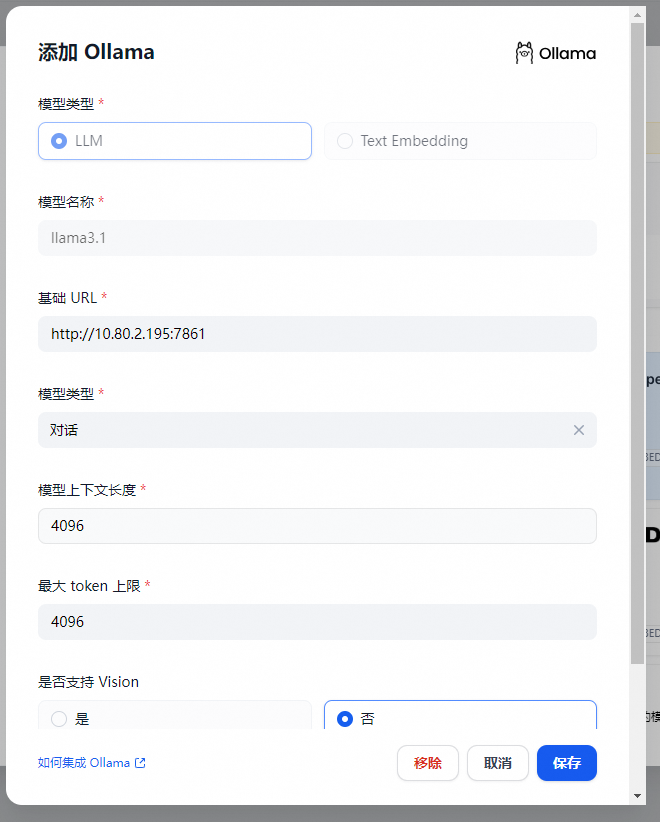
模型名称:llama3.1
基础 URL:
http://<your-ollama-endpoint-domain>:11434
- 此处需填写可访问到的 Ollama 服务地址。
- 若 Dify 为 docker 部署,建议填写局域网 IP 地址,如:
http://10.80.2.195:11434
或 docker 宿主机 IP 地址,如:
http://172.17.0.1:11434
。
- 若为本地源码部署,可填写
http://localhost:11434
。
模型类型:对话
模型上下文长度:4096
- 模型的最大上下文长度,若不清楚可填写默认值 4096。
最大 token 上限:4096
- 模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。
是否支持 Vision:是
- 当模型支持图片理解(多模态)勾选此项,如 llava。
点击 "保存" 校验无误后即可在应用中使用该模型。
Embedding 模型接入方式与 LLM 类似,只需将模型类型改为 Text Embedding 即可。
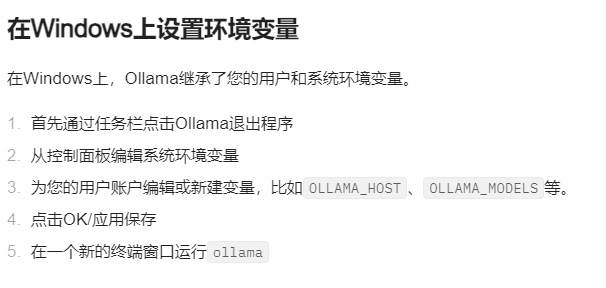
- 如果您使用Docker部署Dify和Ollama,您可能会遇到以下错误:
httpconnectionpool(host=127.0.0.1, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
httpconnectionpool(host=localhost, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
这个错误是因为 Docker 容器无法访问 Ollama 服务。localhost 通常指的是容器本身,而不是主机或其他容器。要解决此问题,您需要将 Ollama 服务暴露给网络。

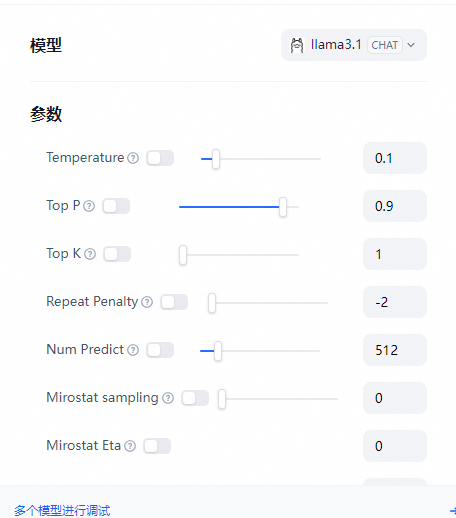
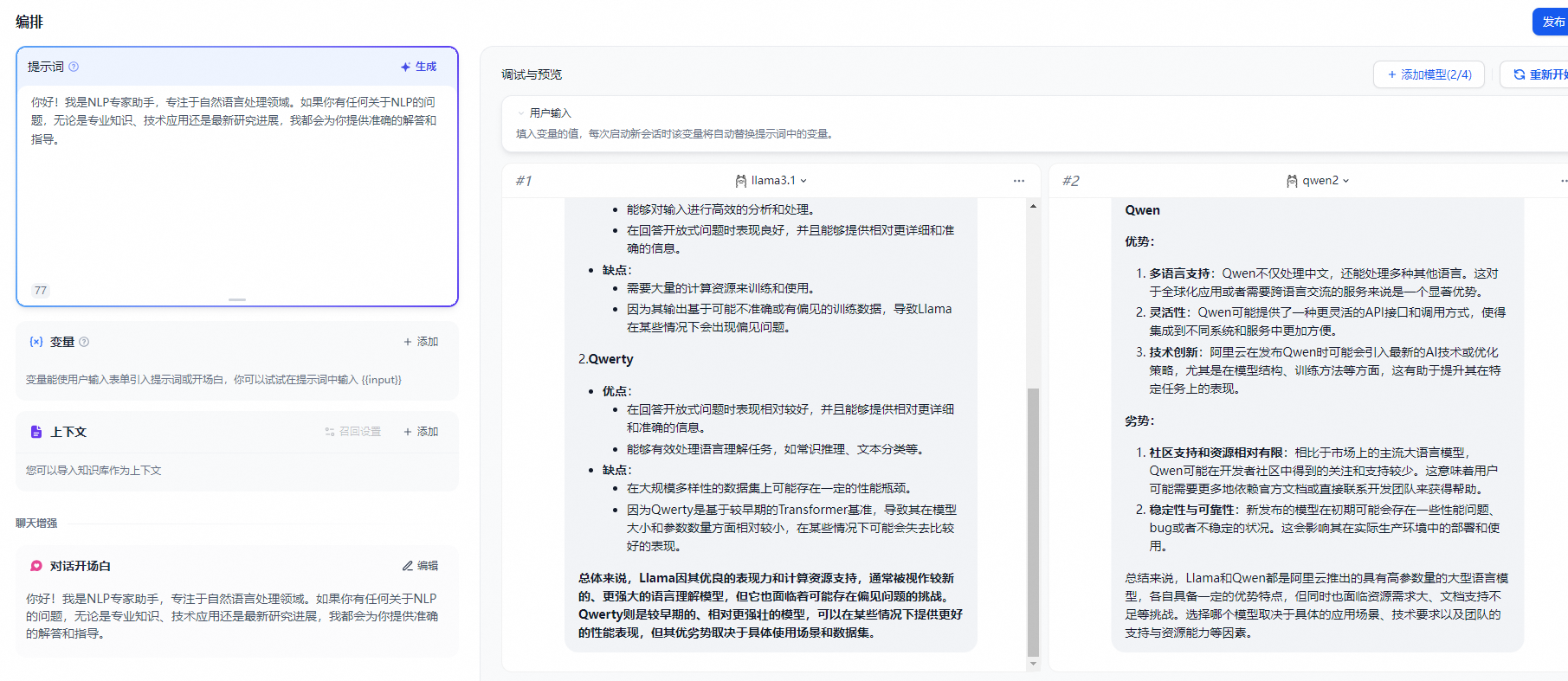
4.1.多模型对比
参考单个模型部署一样,进行再一次配置添加即可
- 需要注意的是添加完新的模型配置后,需要刷新dify网页,直接网页端刷新就好,新添加的模型就会加载进来

更多推荐
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
更多优质内容请关注CSDN:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。