MySQL 5.7 DDL 与 GH-OST 对比分析
作者:来自 vivo 互联网存储研发团队- Xia Qianyong
本文首先介绍MySQL 5.7 DDL以及GH-OST的原理,然后从效率、空间占用、锁阻塞、binlog日志产生量、主备延时等方面,对比GH-OST和MySQL5.7 DDL的差异。
一、背景介绍
在 MySQL 数据库中,DDL(数据定义语言)操作包括对表结构、索引、触发器等进行修改、创建和删除等操作。由于 MySQL 自带的 DDL 操作可能会阻塞 DML(数据操作语言)写语句的执行,大表变更容易产生主备延时,DDL 变更的速度也不能控制,因此在进行表结构变更时需要非常谨慎。
为了解决这个问题,可以使用 GitHub 开源的工具 GH-OST。GH-OST 是一个可靠的在线表结构变更工具,可以实现零宕机、低延迟、自动化、可撤销的表结构变更。相比于 MySQL 自带的 DDL 操作,GH-OST 可以在不影响正常业务运行的情况下进行表结构变更,避免了 DDL 操作可能带来的风险和影响。
通过使用 GH-OST工具,可以对 MySQL 数据库中的表进行在线结构变更,而不会对业务造成太大的影响。同时,GH-OST 工具还提供了多种高级特性,如安全性检测、自动化流程等,可以帮助用户更加高效地进行表结构变更。
二、MySQL5.7几种DDL介绍
2.1 copy
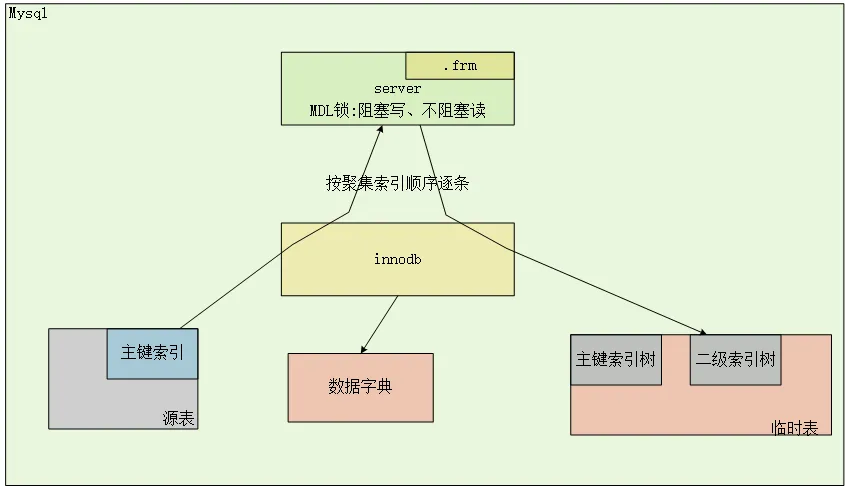
server层触发创建临时表
server层对源表加MDL锁,阻塞DML写、不阻塞DML读
server层从源表中逐行读取数据,写入到临时表
数据拷贝完成后,升级字典锁,禁止读写
删除源表,把临时表重命名为源表
MySQL copy方式的DDL变更,数据表的重建(主键、二级索引重建),server层作为中转把从innodb读取数据表,在把数据写到innodb层临时表。简单示意图如下:
2.2 inplace
(1)rebuild table
需要根据DDL语句创建新的表结构,根据源表的数据和变更期间增量日志,重建新表的主键索引和所有的二级索引。
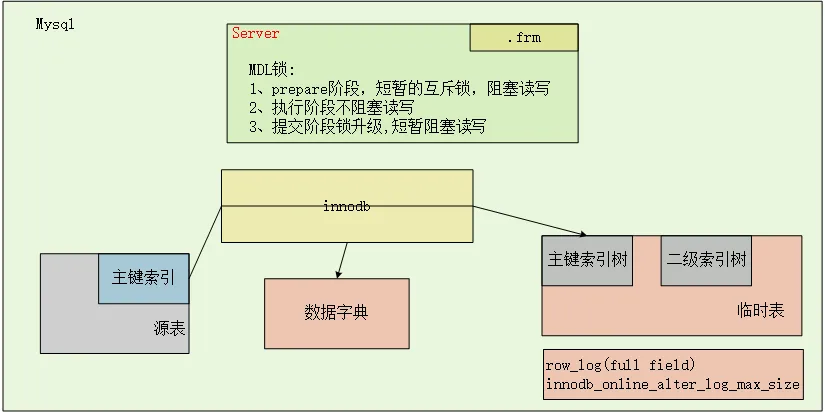
Prepare阶段
:
创建新的临时frm文件
持有EXCLUSIVE-MDL锁,禁止读写
根据alter类型,确定执行方式(copy,online-rebuild,online-norebuild)假如是Add Index,则选择online-norebuild
更新数据字典的内存对象
分配row_log对象记录增量
生成新的临时ibd文件
ddl执行阶段
:
降级EXCLUSIVE-MDL锁,允许读写
扫描old_table的聚集索引每一条记录rec
遍历新表的聚集索引和二级索引,逐一处理各个索引
根据rec构造对应的索引项
将构造索引项插入sort_buffer块排序
将sort_buffer块更新到新表的索引上
记录ddl执行过程中产生的增量(记录主键和索引字段)
重放row_log中的操作到新表索引商
重放row_log间产生dml操作append到row_log最后一个Block
commit阶段
:
当前Block为row_log最后一个时,禁止读写,升级到EXCLUSIVE-MDL锁
重做row_log中最后一部分增量
更新innodb的数据字典表
rename临时idb文件,frm文件
增量完成
MySQL rebuild table方式的DDL,数据不需要通过sever层中转,innodb层自己完成数据表的重建。简单示意图如下:
(2)build-index
需要根据DDL语句创建新的表结构,根据源表的数据和变更期间增量日志,创建新的索引。
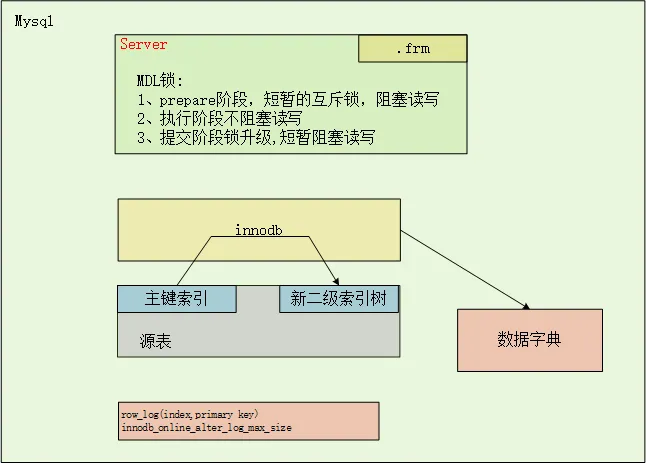
Prepare阶段
:
持有EXCLUSIVE-MDL锁,禁止读写
根据alter类型,确定执行方式(copy,online-rebuild,online-norebuild)
假如是Add Index,则选择online-norebuild
更新数据字典的内存对象
分配row_log对象记录增量
ddl执行阶段
:
降级EXCLUSIVE-MDL锁,允许读写
扫描old_table的聚集索引每一条记录rec
遍历新表的聚集索引,根据rec构造新的索引数据
将构造索引项插入sort_buffer块排序
将sort_buffer块更新到新表的索引上
记录ddl执行过程中产生的增量(仅记录主键和新索引字段)
重放row_log中的操作到新表索引上
重放row_log间产生dml操作append到row_log最后一个Block
commit阶段
:
当前Block为row_log最后一个时,禁止读写,升级到EXCLUSIVE-MDL锁
重做row_log中最后一部分增量
更新innodb的数据字典表
增量完成
MySQL rebuild index方式的DDL,数据不需要通过sever层中转,innodb层只需要完成变更二级索引的创建。简单示意图如下:
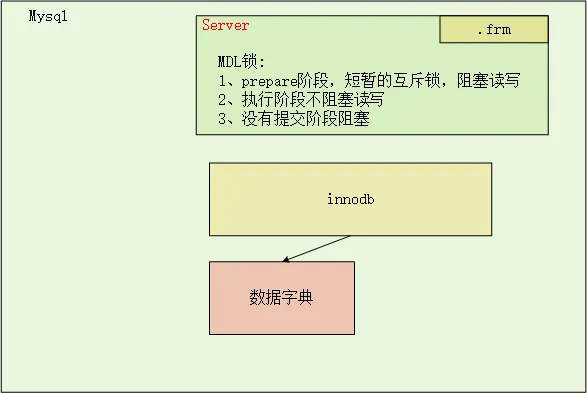
(3)only modify metadata
只修改元数据(.frm文件和数据字典),不需要拷贝表的数据。
三、GH-OST
在GH-OST端,根据DDL语句创建新的表结构,根据源表的数据和增量期间增量日志,重建新表的主键索引和所有的二级索引,最终完成DDL增量。
主要流程如下:
根据DDL语句和源表创建新的表结构
根据唯一索引(主键索引或者其它唯一索引)
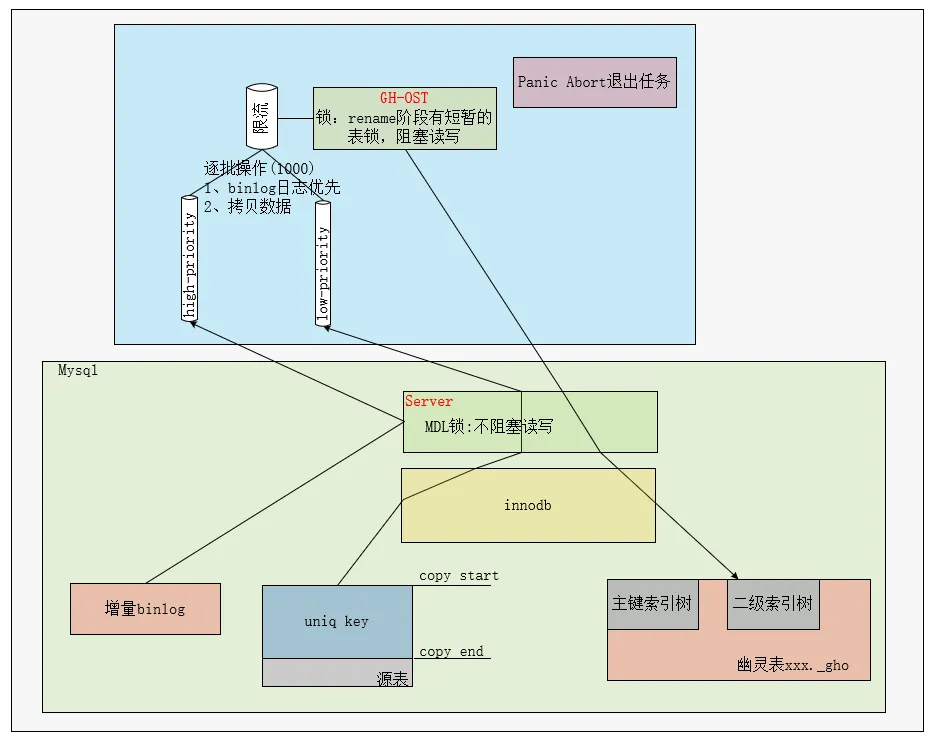
- 优先应用新增量的binlog到新的表中,需要经过GH-OST把binlog日志转换为sql,然后回放到影子表
- 其次拷贝源表中的数据到新的表中,表数据拷贝通过sql语句 insert ignore into (select .. from)直接在MySQL实例上执行,无需经过GH-OST中转
数据拷贝完成并应用完binlog后,通过lock table write 锁住源表
应用数据完成-获取到锁期间产生的增量binlog
delete源表,rename影子表为源表,完成数据增量
GH-OST 进行DDL变更,GH-OST服务通知server层,server层作为中转把从innodb读取数据表,在把数据写到innodb层影子表。并且GH-OST作为中转读取DDL变更期间增量binlog解析成SQL写语句回放到影子表。简单示意图如下:
四、对比分析
DDL变更执行时长、对磁盘的额外占用(临时数据表+binlog)、锁阻塞时长、主备延时都是执行DDL变更人员比较关心的问题,本章将从从执行效率、占用表空间、锁阻塞、产生binlog日志量、主备延时等方面对MySQL原生的DDL和GH-OST进行对比分析。
4.1 执行效率
(1)only modify metadata(正常小于1S)
(2)build-index: 数据条目越多、新索引字段越大耗时越多
增量日志超过innodb_online_alter_log_max_size造成DDL失败
(3)rebuild table: 数据条目越多、所有索引字段之和越大耗时越多
增量日志超过innodb_online_alter_log_max_size造成DDL失败
(4)copy:数据条目越多,所有索引字段之和越大耗时越多,相对于rebuild table,数据需要从server层中转,所以比rebuild table耗时多
(5)GH-OST :数据条目越多,所有索引字段之和越大耗时越多,
相对于copy,增量日志数据需要从GH-OST中转,所以比copy耗时多
有各种限流,(主备延时,threads超限延时…),增加耗时
增量期间应用binlog速度如果跟不上业务产生binlog日志的速度,将无法完成增量
critical 参数还会导致主动退出,例如thread_running
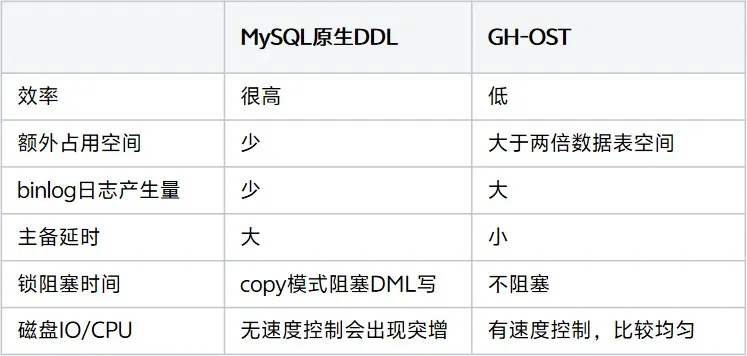
耗时:only modify metadata < build-index < build < copy < GH-OST
4.2 占用表空间
【only modify metadata】:忽略
【build-index】:额外需要,新增索引字段占用的空间
【rebuild-table】:额外需要约两倍的表空间
【copy】:额外需要约两倍的表空间
【GH-OST】 :临时表占用约两倍的表空间,另外生成影子表会产生大量的binlog日志会占用表空间
占用表空间: only modify metadata < build-index < build = copy < GH-OST
4.3 锁阻塞
(1)only modify metadata
DDL prepare阶段短暂的MDL排他锁,阻塞读写
(2)build-index table
DDL prepare阶段短暂的MDL排他锁,阻塞读写
执行阶段(主要耗时阶段),MDL SHARED_UPGRADABLE锁,不阻塞读写
执行阶段的最后会回放增量日志row_log,两个block间隙和最后block,持有源表索引的数据结构锁,会阻塞写
提交阶段,MDL锁升级为排他锁
回放剩余的row_log(执行完成致MDL锁升级期间新增的row_log,持有源表索引的数据结构锁,阻塞读写)
(3)rebuild-table: 和build-index table一致
(4)copy
DDL prepare阶段短暂的MDL排他锁,阻塞读写
执行阶段(主要耗时阶段),阻塞写,不阻塞读
(5)GH-OST
等待锁的时间也会阻塞业务
进入rename到拿表写锁的间隙有少量的新增binlog,后续需要持锁回放这部分日志
rename表本身的耗时通常1s以内左右
锁阻塞时间:
only modify metadata=GH-OST < build-index table = rebuild-table < copy(整个DDL期间都会阻塞业务的写)
锁阻塞分析:
MySQL DDL在获取MDL排它锁和GH-OST获取表的的写锁,在获取锁的等待期间都会阻塞业务的读写
MySQL等待锁的超时时间为MySQL参数innodb_lock_wait_timeout。等待超时则失败
GH-OST等待锁的时间,等待超时时间可配(默认6秒),等待超时次数可配
4.4 产生binlog日志量
【MySQL5.7 DDL】: 在DDL执行结束时仅向binlog中写入一条DDL语句,日志量较小。
【GH-OST】: 影子表在全量数据拷贝和增量数据应用过程中产生大量的binlog日志(row模式),对于大表日志量非常大。
产生binlog日志量:MySQL5.7 DDL < GH-OST
4.5 主备延时分析
(1)MySQL5.7 DDL:MySQL集群主备环境
Master上DDL执行完成,binlog提交后,slave才开始进行DDL。
slave串行复制、group复制模式,需要等前面的DDL回放完成后才会进行后续binlog回放,主备延时至少是DDL回放的时间。

(2)GH-OST:主备复制延时基本可以忽略
GH-OST在master上创建一个影子表,在执行数据拷贝和binlog应用阶段,GHO表的binlog会实时同步到备。
影子表(_GHO表)应用完成后,通过rename实现新表切换,这个rename动作也会通过binlog传到salve执行完成DDL。

延时时间:GH-OST < MySQL DDL
备库执行DDL期间主库异常,主备切换。备库升级为主过程中,要回放完relaylog中的DDL和dml,才能对外服务,否则会出现数据丢失,这将造成业务较长时间的阻塞。
4.6 总结
GH-OST 工具和 MySQL 原生 DDL 工具的适用场景不同,具体使用哪种工具需要根据实际需求进行选择。
变更人员无法判断本次DDL是否会造成DML阻塞、锁阻塞等,建议使用GH-OST工具。
如果需要进行在线表结构变更,并且需要减少锁阻塞时间、减少主备延时等问题,建议使用 GH-OST 工具。
变更只涉及到元数据的修改,建议使用mysql原生DDL。
如果表结构变更较小,对锁阻塞时间和主备延时要求不高,建议使用 MySQL 原生 DDL 工具。
参考资料:





