VMware Cloud Foundation 5.2 发布并引入了一个新的功能,借助 VCF Import Tool 工具可以将现有 vSphere 环境直接转换(Convert)为管理工作负载域或者导入(Import)为 VI 工作负载域。通过这种能力,客户无需购买新硬件和进行复杂的部署和迁移工作,即可将已有的环境快速转变为由 VMware Cloud Foundation 解决方案驱动的 SDDC 软件定义数据中心。使用这种方式,不会对现有的业务产生任何影响,即能够在不中断工作负载的情况下完成所有转换过程。
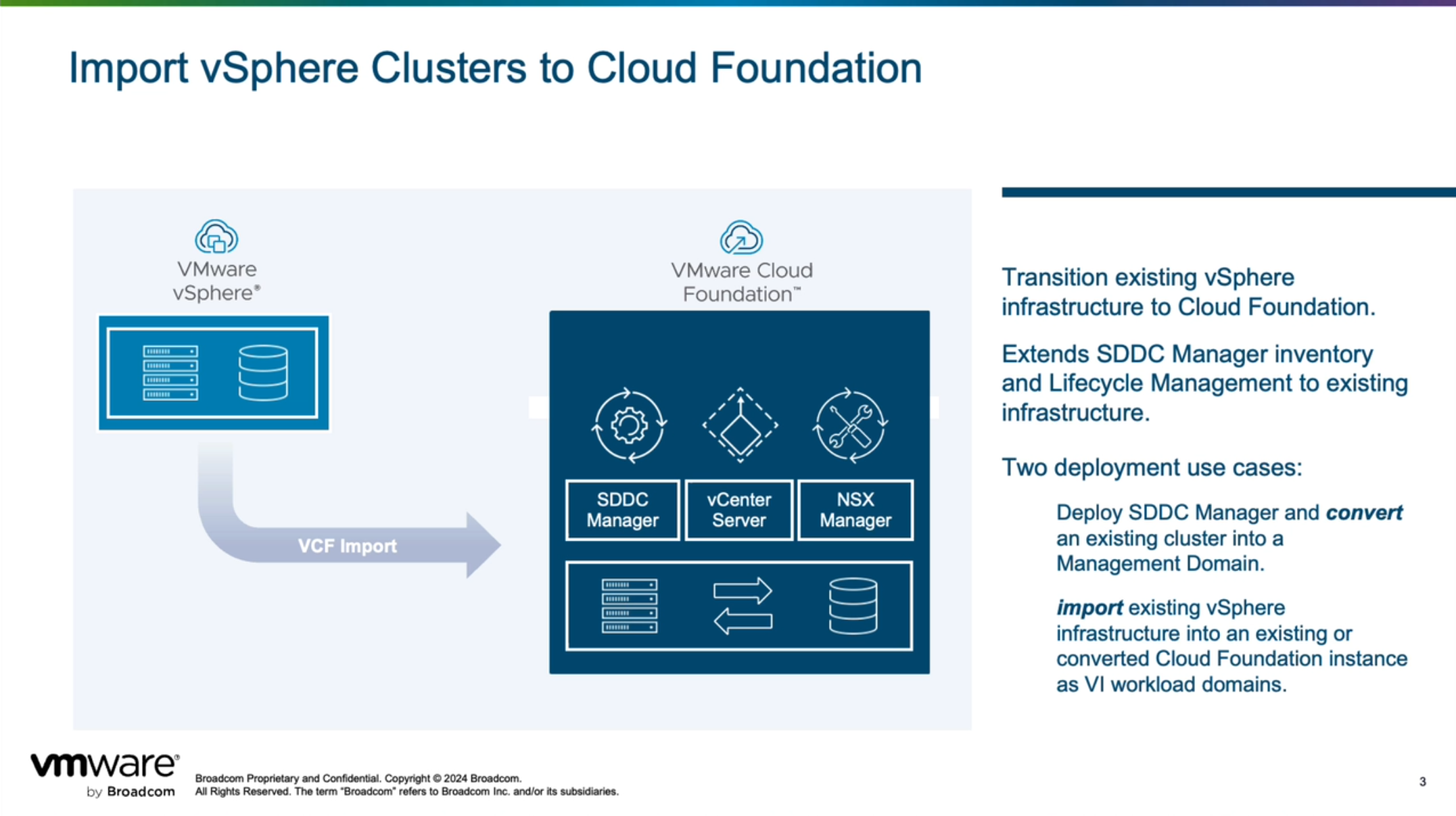
VCF Import Tool 提供两种方式来帮助客户将现有的 vSphere 环境转变为 VMware Cloud Foundation,分别是转换(Convert)和导入(Import)。如果客户之前从来没有用过 VMware Cloud Foundation 解决方案,也就是说现在可能是 vSphere 环境或者 vSphere+vSAN 环境,那可以使用 VCF Import Tool 提供的转换(Convert)功能直接将现有环境转换为管理工作负载域;如果客户环境中已经在用 VMware Cloud Foundation 解决方案,也就是说现在已经有了管理工作负载域,可以使用 VCF Import Tool 提供的导入(Import)功能直接将现有环境导入为 VI 工作负载域。总体来看,VMware Cloud Foundation 解决方案现在提供了三种方式来构建工作负载域,分别是部署(Deploy)、转换(Convert)和导入(Import),VMware Cloud Builder 方式用于 VCF 管理域初始部署(Deploy)。
注意,使用这两种方式所执行的工作流有所不同,如果是转换(Convert),那第一步需要在现有 vSphere 环境上部署 SDDC Manager,然后上传 VCF Import Tool 相关软件和工具并执行转换(Convert)过程;如果是导入(Import),那将 VCF Import Tool 相关软件和工具上传至 SDDC Manager 后即可执行导入(Import)过程。有关更多内容和细节请查看
《Converting or Importing Existing vSphere Environments into VMware Cloud Foundation》
产品文档。
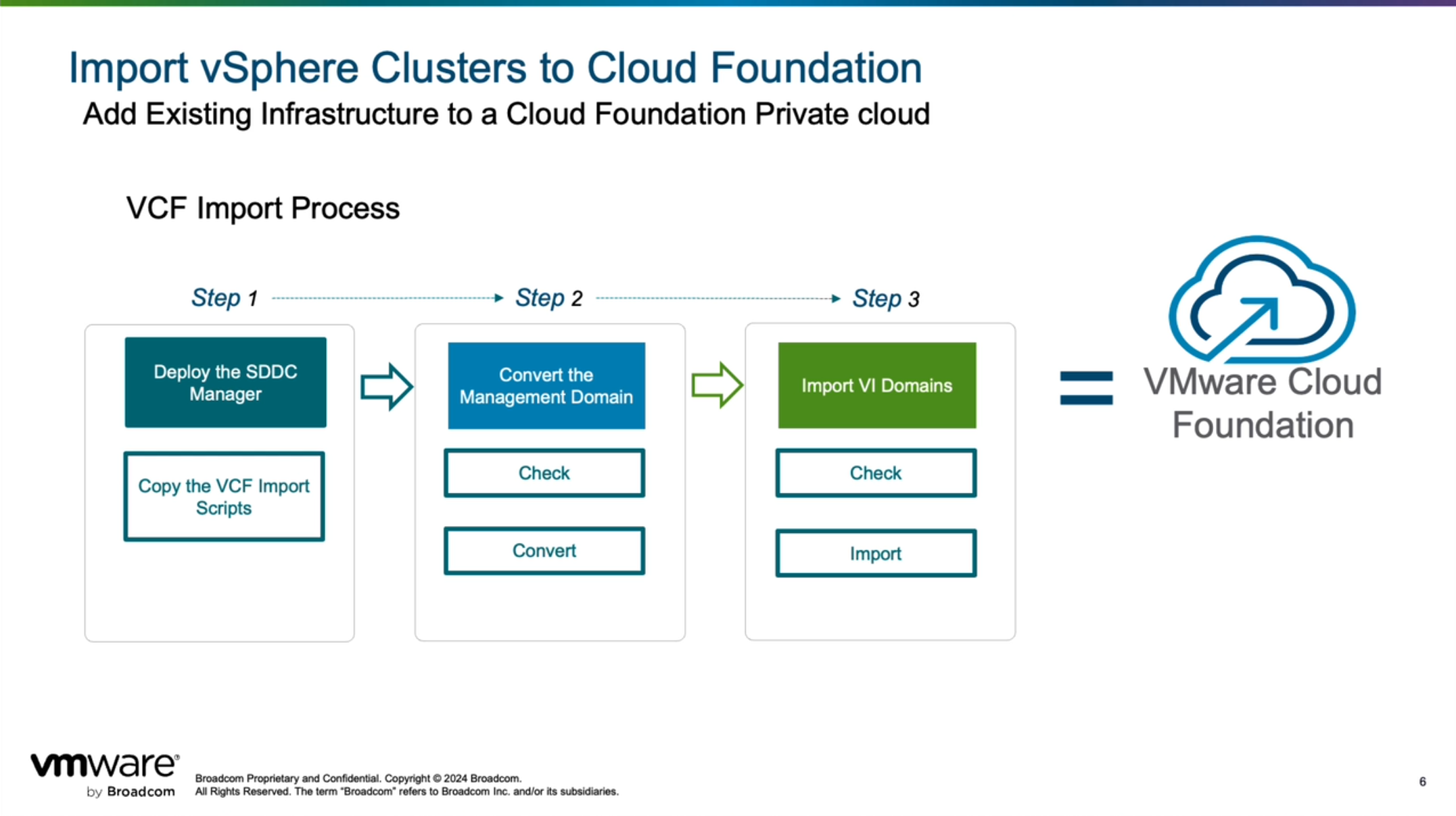
如果使用 VCF Import Tool 工具将现有 vShere 环境转换(Convert)为管理工作负载域或者导入(Import)为 VI 工作负载域,会具有许多
要求和限制
,需要先满足这些条件才能执行对应的操作。注,由于 VCF Import Tool 工具目前发布的还是初始版,随着后续工具的逐渐完善,肯定会支持越来越多的场景,比如目前版本还不支持具有 NSX 的环境,而在 VMware Explore 2024 大会上发布的
VMware Cloud Foundation 9
未来版本中将支持转换(Convert)或导入(Import)具有 NSX 解决方案的环境。
1)基本要求
转换为管理域:
- 现有 vSphere 环境必须运行 vSphere 8 U3 及更高版本(VCF 5.2 BOM),包括 vCenter 和 ESXi 主机。
- 现有 vSphere 环境中的 vCenter Server 虚拟机必须属于同一集群,也被称为“共存”。
导入为 VI 域:
- 现有 vSphere 环境必须运行 vSphere 7 U3 及更高版本(VCF 4.5 BOM),包括 vCenter 和 ESXi 主机。
- 现有 vSphere 环境中的 vCenter Server 虚拟机必须属于同一集群或者在管理域中运行。
2)通用要求
- 现有 vSphere 集群中的所有主机都必须是同构的。即集群中的所有主机在容量、存储类型和配置(pNIC、VDS 等)方面都需要相同。
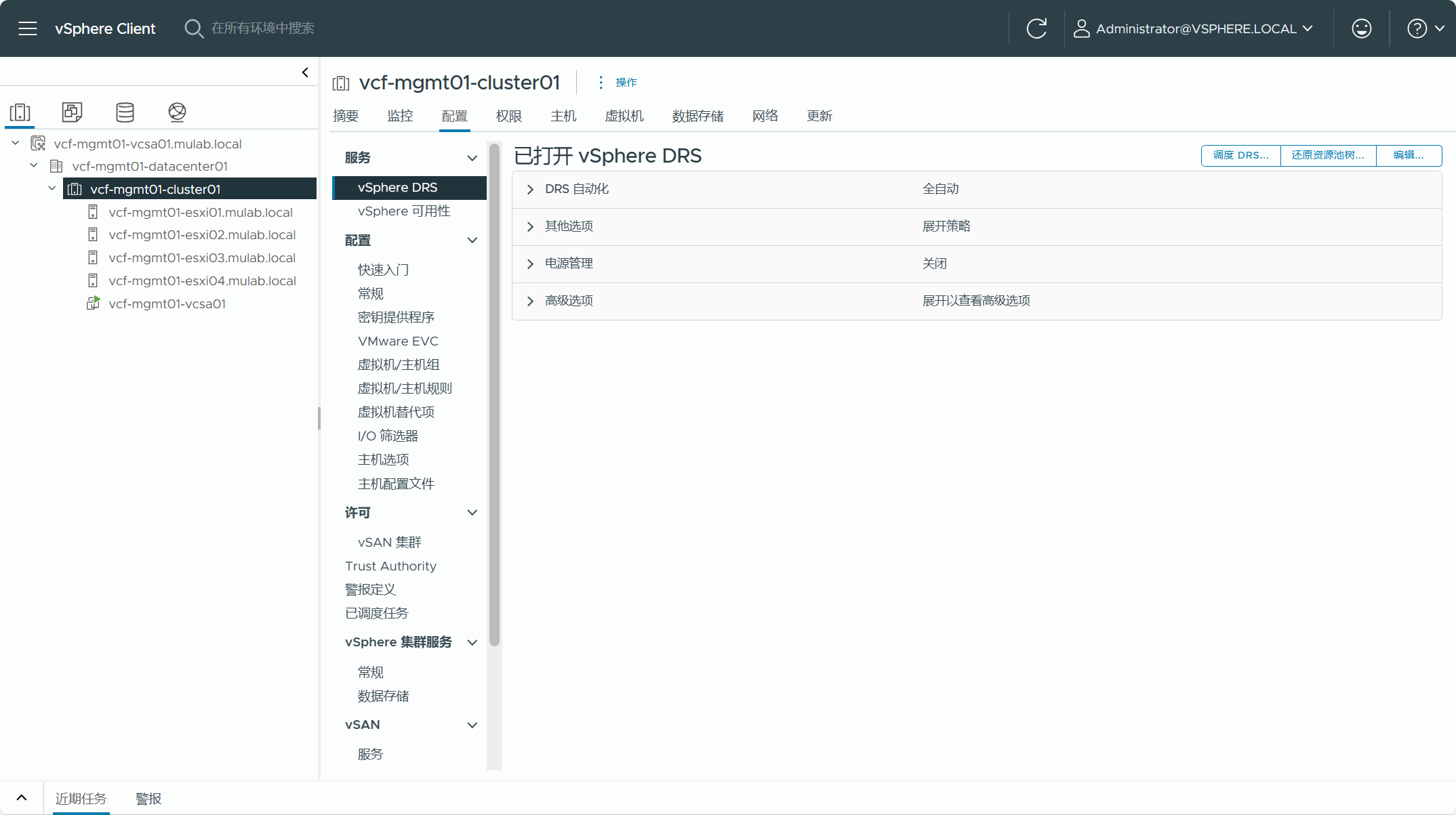
- 现有 vSphere 集群必须配置 DRS 为全自动模式。
- 现有 vSphere 集群只能使用三种受支持的存储类型之一:vSAN、NFS 或 FC SAN(VMFS)。
- 现有 vSphere 集群如果使用了 vSAN 存储,至少需要 4 台 ESXi 主机,使用其他类型的存储则至少需要 2 台 ESXi 主机,若要部署 NSX,则至少需要 3 台 ESXi 主机。
- 现有 vSphere 集群 vCenter Server 不能配置为增强型链接模式(EAM),使用转换或导入后,现有 vSphere 集群都只能属于自己的 SSO 域当中。
- 现有 vSphere 集群中的所有主机必须配置专用的 vMotion 网络,每台主机所配置的网卡流量有且只能有一个,并且网卡配置的 IP 地址必须是静态固定的。
- 现有 vSphere 环境中,vCenter Server 清单中的所有集群都必须配置了一个或多个专用 VDS 分布式交换机,VDS 交换机不能被多个集群共享,集群内不能存在 VSS 标准交换机。
- 现有 vSphere 环境中,vCenter Server 清单中不能有独立的主机,独立主机通常是指位于数据中心和主机文件夹而不属于任何集群的主机,若有则需要将主机移入到某个集群当中。
3)支持限制
- 不支持配置了 LACP 链路聚合的 vSphere 环境。
- 不支持配置了 VDS 交换机共享的 vSphere 环境。
- 不支持配置了 vSAN 延伸集群的 vSphere 环境。
- 不支持配置了 vSAN 集群“仅压缩”功能的 vSphere 环境。
- 不支持配置了 NSX 的 vSphere 环境。
- 不支持配置了 AVI Load Balancer 的 vSphere 环境。
- 不支持配置了 IaaS Control Plane 的 vSphere 环境。
- 不支持 VxRail 环境。
值得一提的是,使用 VCF Import Tool 方式将现有 vSphere 环境转换为管理工作负载域,可以绕过使用 Cloud Builder 部署 VCF 时只能使用 vSAN 的要求。有关使用要求和限制也可以查看这篇(
Introduction to the VMware Cloud Foundation (VCF) Import Tool
)文章。
使用 VCF Import Tool 工具有各种限制和注意事项,针对这些情况,下面让我们确认一下现有 vSphere 环境中的信息,以确保能满足转换要求。由于我这边是通过嵌套虚拟化搭建准备的环境,这跟实际环境肯定会有所区别,如果你也想搭建这样的测试环境,可以参考这篇(
一次性说清楚 vCenter Server 的 CLI 部署方式。
)文章中的方法,部署单节点 vSAN ESA 集群后再添加并配置其他 ESXi 主机。
首先,现有 vSphere 环境中的 vCenter Server 必须是 VCF 5.2 BOM 物料清单中的版本,如果实际环境中不是这个版本,需要将 vCenter Server 升级到该版本(或更高)。
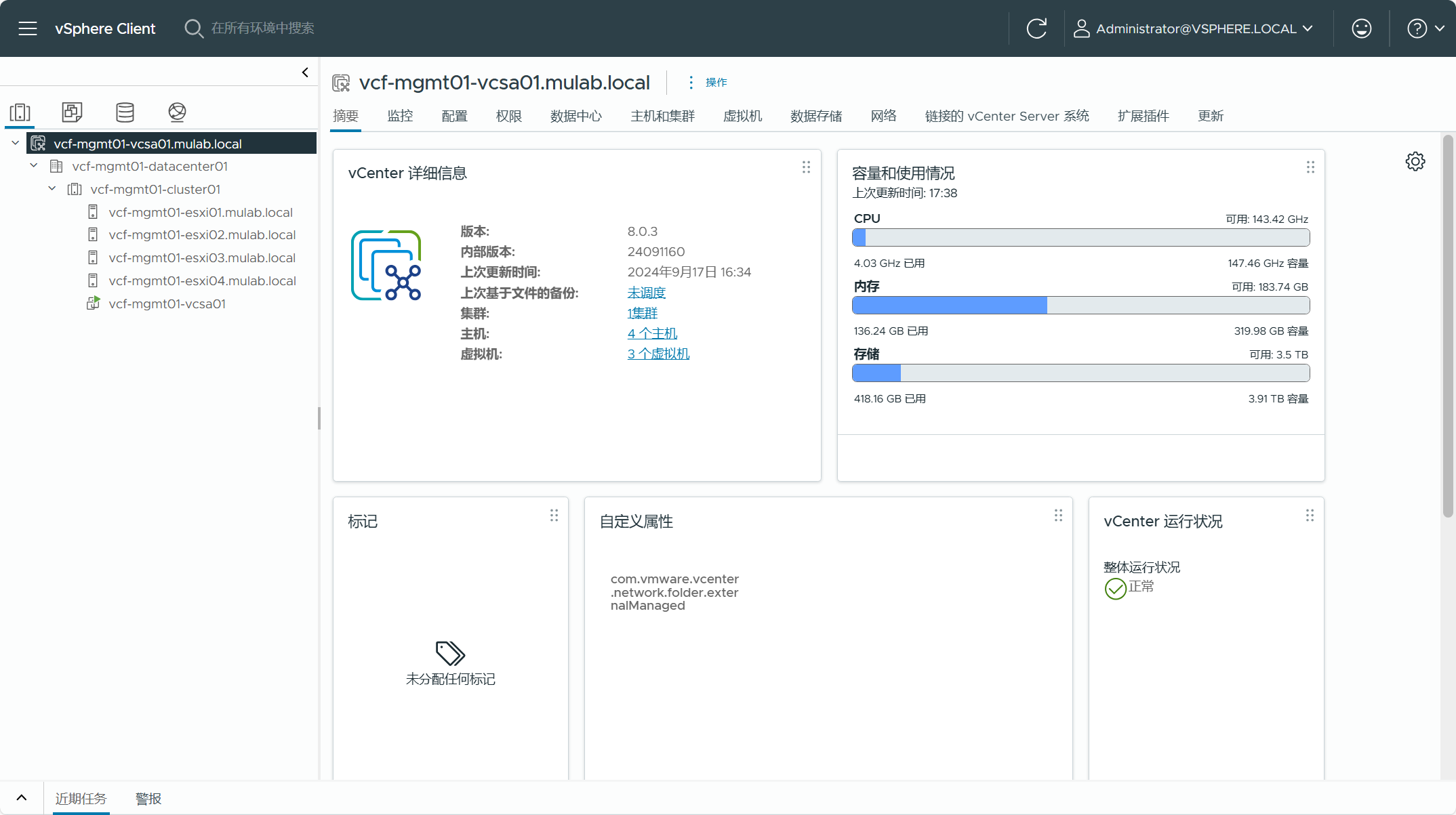
现有 vSphere 环境中用于转换为管理域集群内的主机必须是 VCF 5.2 BOM 物料清单中的版本,如果实际环境中不是这个版本,需要将 ESXi 主机升级到该版本(或更高)。由于集群使用了 vSAN 存储,所以集群内的主机要求至少具有 4 台。当前 vSphere 环境中不支持位于数据中心或主机文件夹的独立主机,如果有独立主机,则必须移至某个集群内。
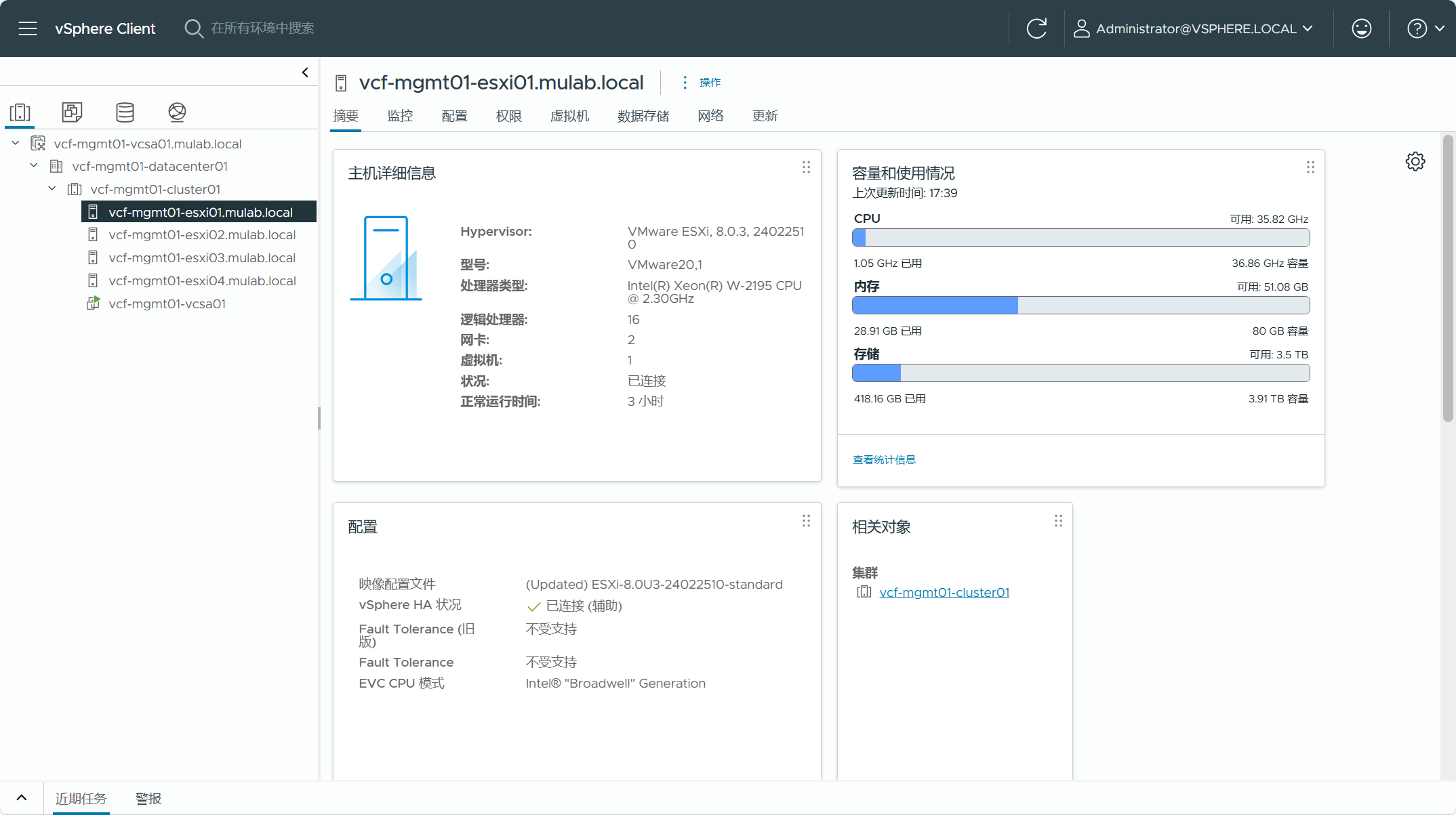
集群内每个 ESXi 主机的 VMkernel 网卡所启用的服务流量类型必须只有一个,也就是说每种流量类型的服务只能有一个 VMkernel 网卡,vmk0 不能既启用了管理流量,同时又启用了 vMotion 流量,必须分开。这些 VMkernel 网卡所分配的 IP 地址不能是 DHCP 获取的,必须是静态配置并且固定的。
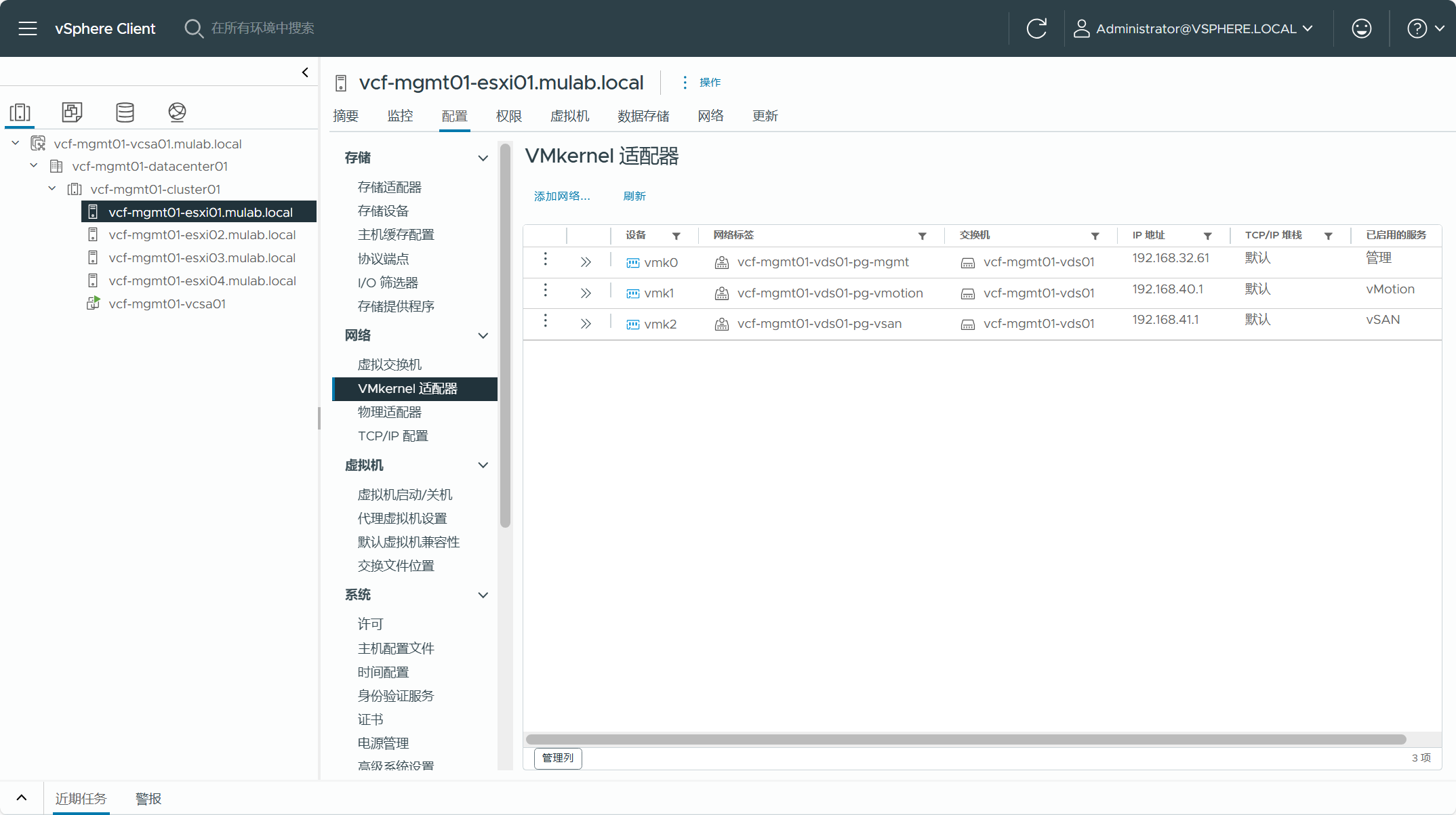
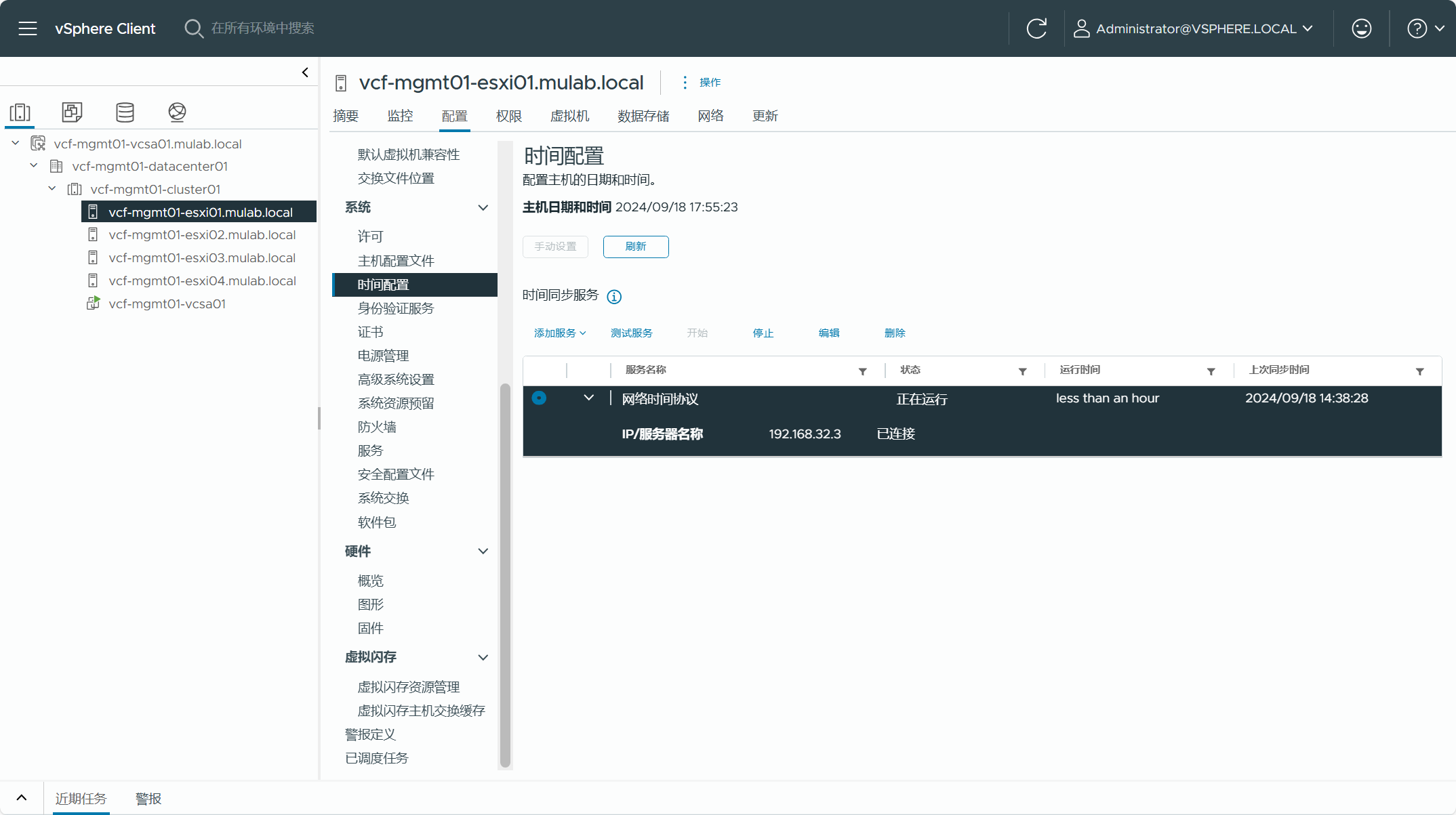
集群内每个 ESXi 主机都应该配置了 NTP 时钟同步。同样,vCenter Server 也应该配置。
现有 vSphere 环境中的集群 DRS 配置必须是全自动的。
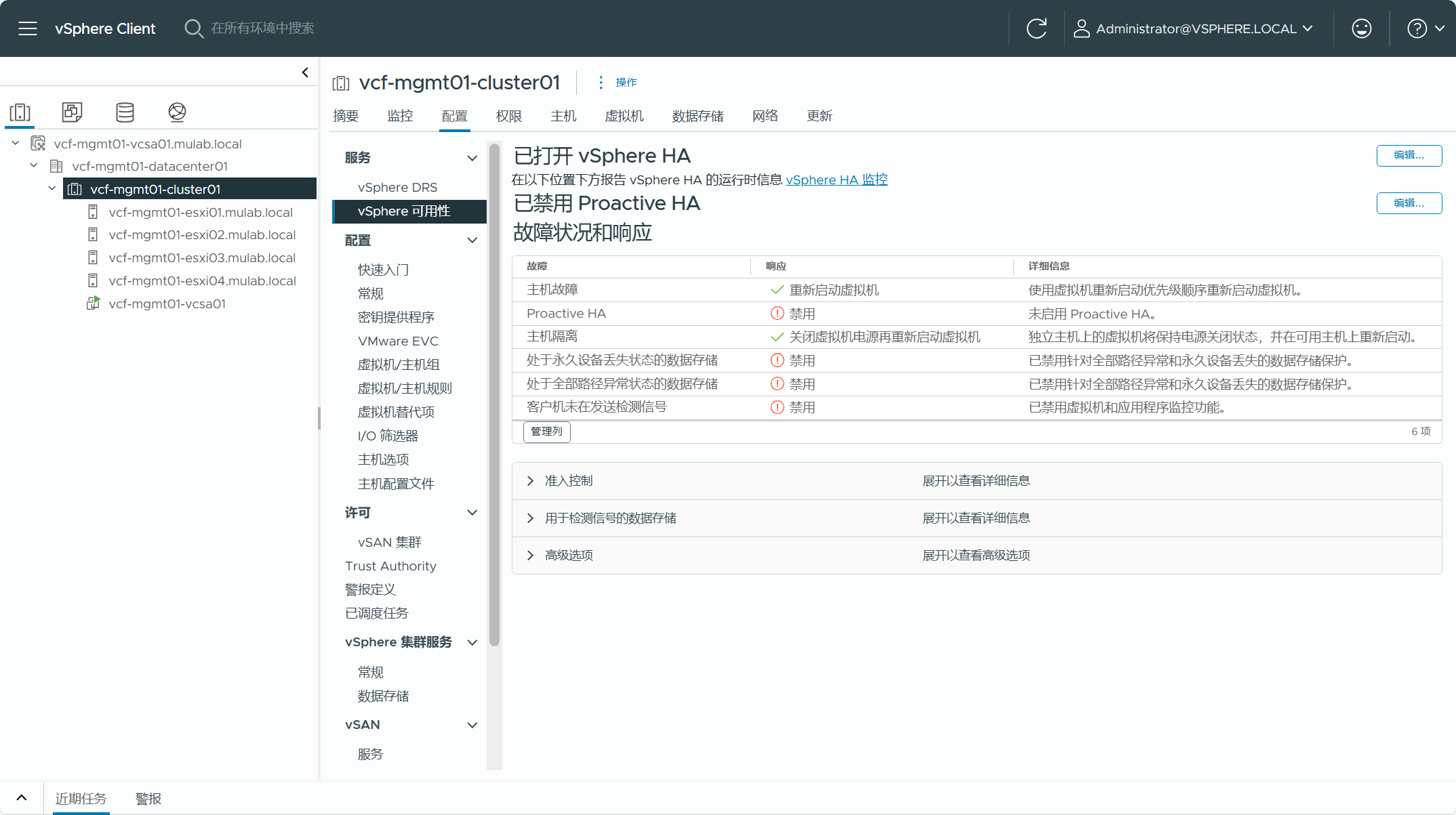
现有 vSphere 集群如果为 vSAN 集群,只能是 vSAN HCI 标准/单站点集群,目前还不支持 vSAN HCI 延伸集群。如果使用了 OSA 架构的 vSAN 集群,不支持仅开了压缩功能,重删和压缩需要都开启。
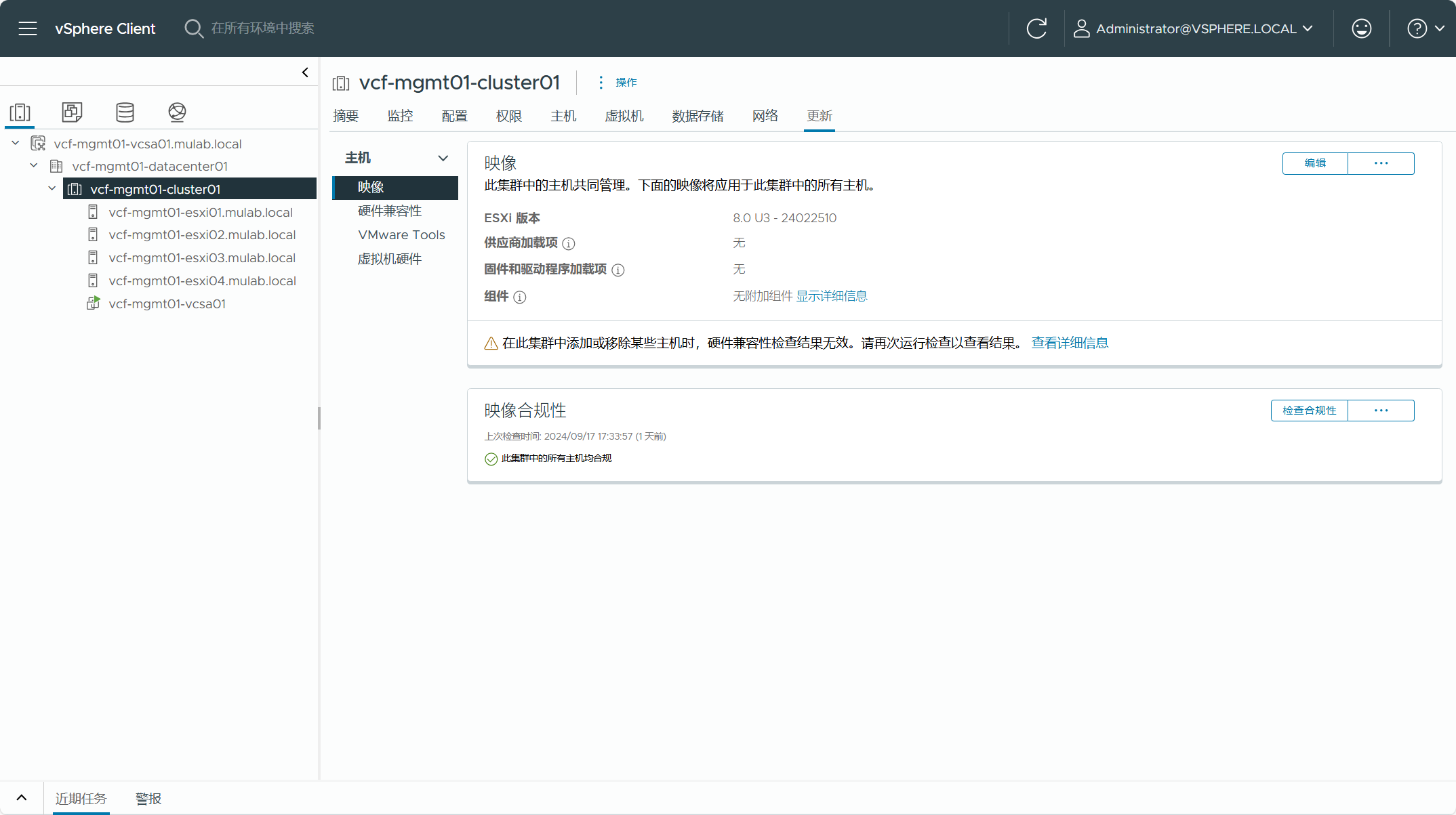
现有 vSphere 集群使用了基于 vLCM 的生命周期管理方式。
现有 vSphere 集群中当前有 vCenter Server 虚拟机和 vCLS 集群服务虚拟机,如果转换为管理域,则 vCenter Server 虚拟机必须存在于于这个集群之中,不能位于其他位置,如果有多个集群并且用于转换的集群中没有 vCenter Server 虚拟机,则需要先将虚拟机迁移到管理域集群。
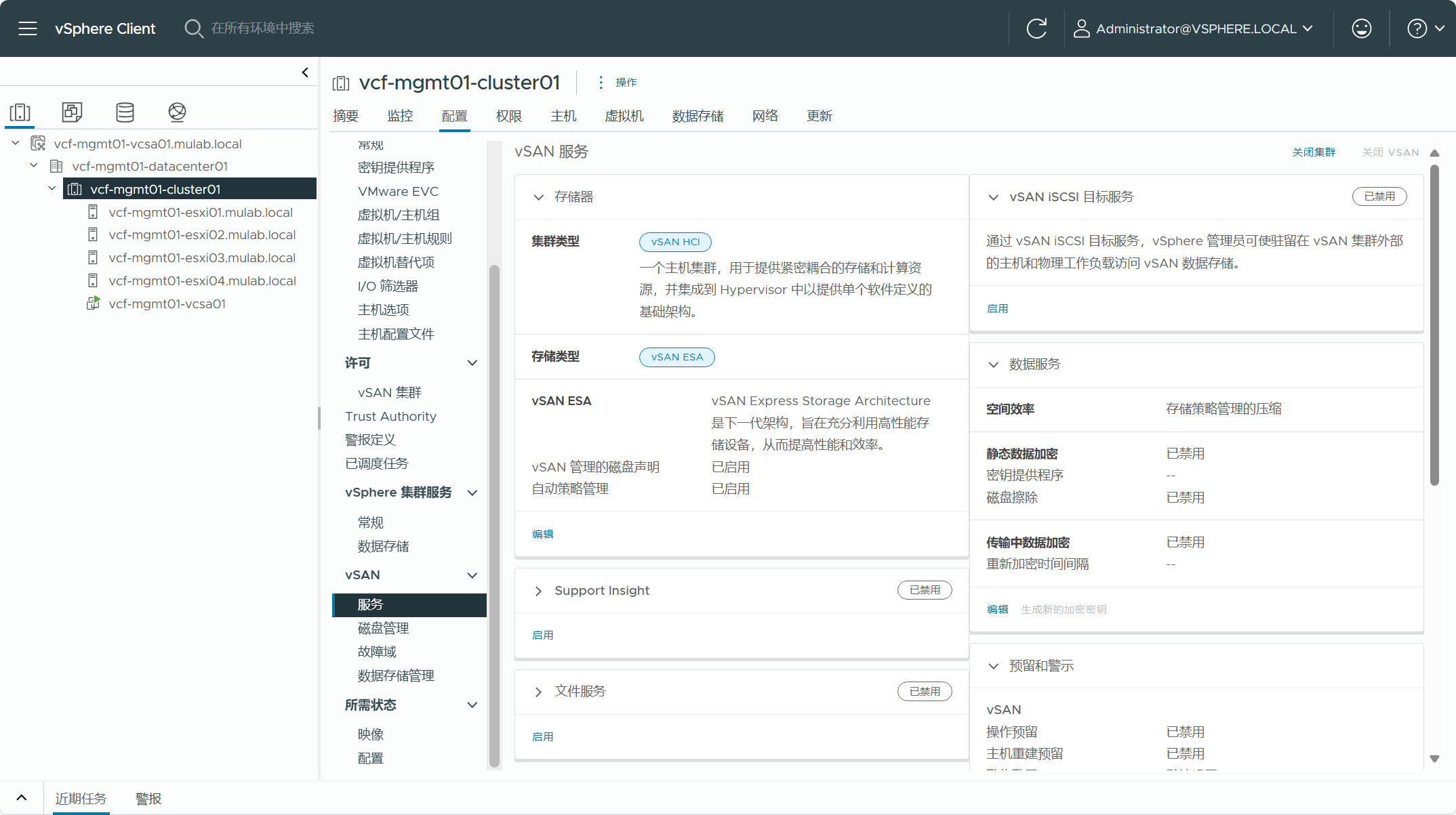
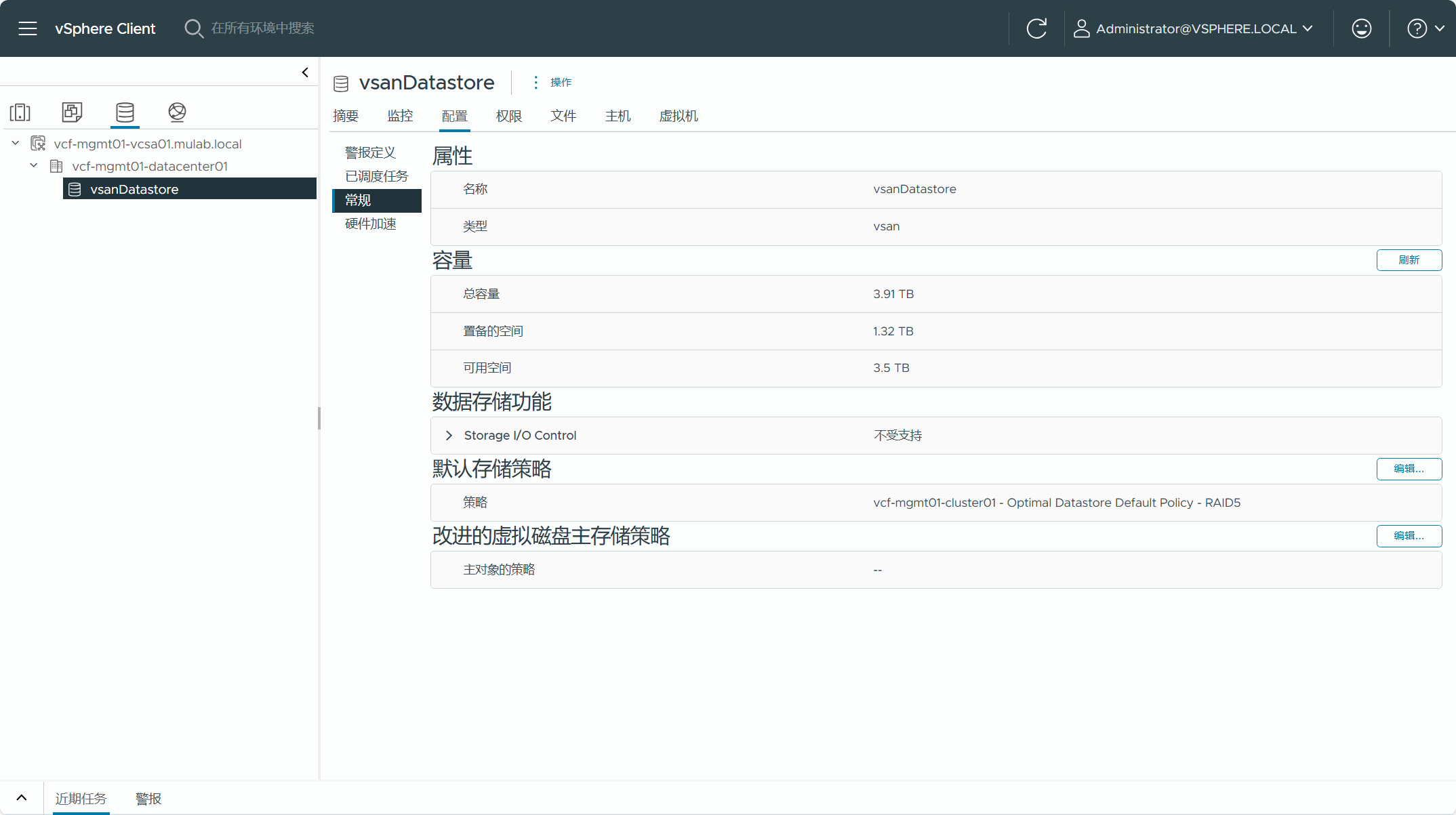
现有 vSphere 集群所使用的 vSAN 存储。
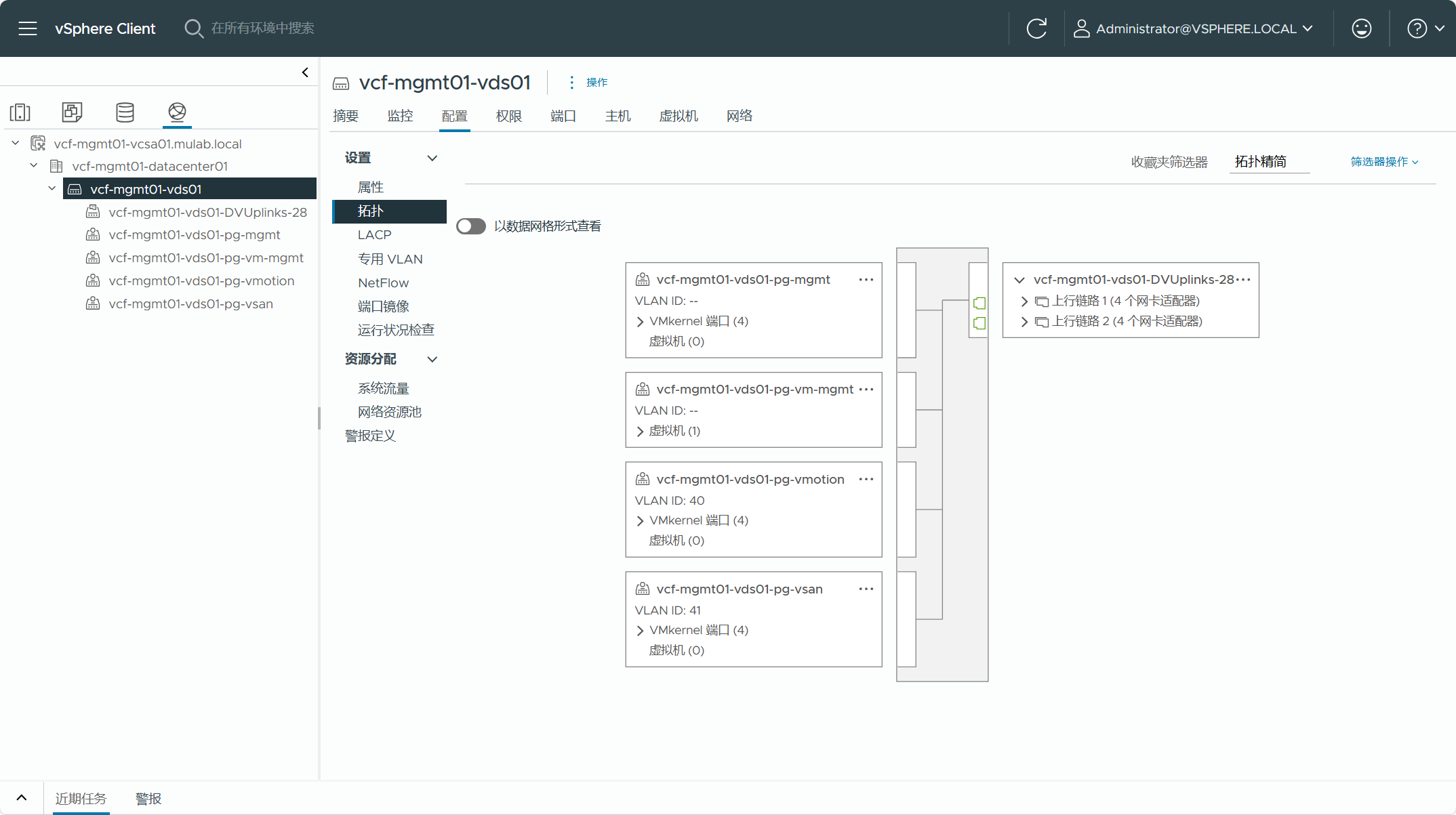
现有 vSphere 集群所使用的 VDS 分布式交换机,转换为管理域的集群不能存在 VSS 标准交换机,如果有标准交换机,则需要将虚拟机迁移至分布式交换机并将标准交换机删除。这个 VDS 交换机不能启用 LACP 链路聚合功能,同时集群内的 ESXi 主机至少有两张网卡(10G)连接到这个 VDS 交换机的上行链路当中。这个 VDS 交换机只能专用于这个集群,不能有多个集群共享同一个 VDS 交换机。
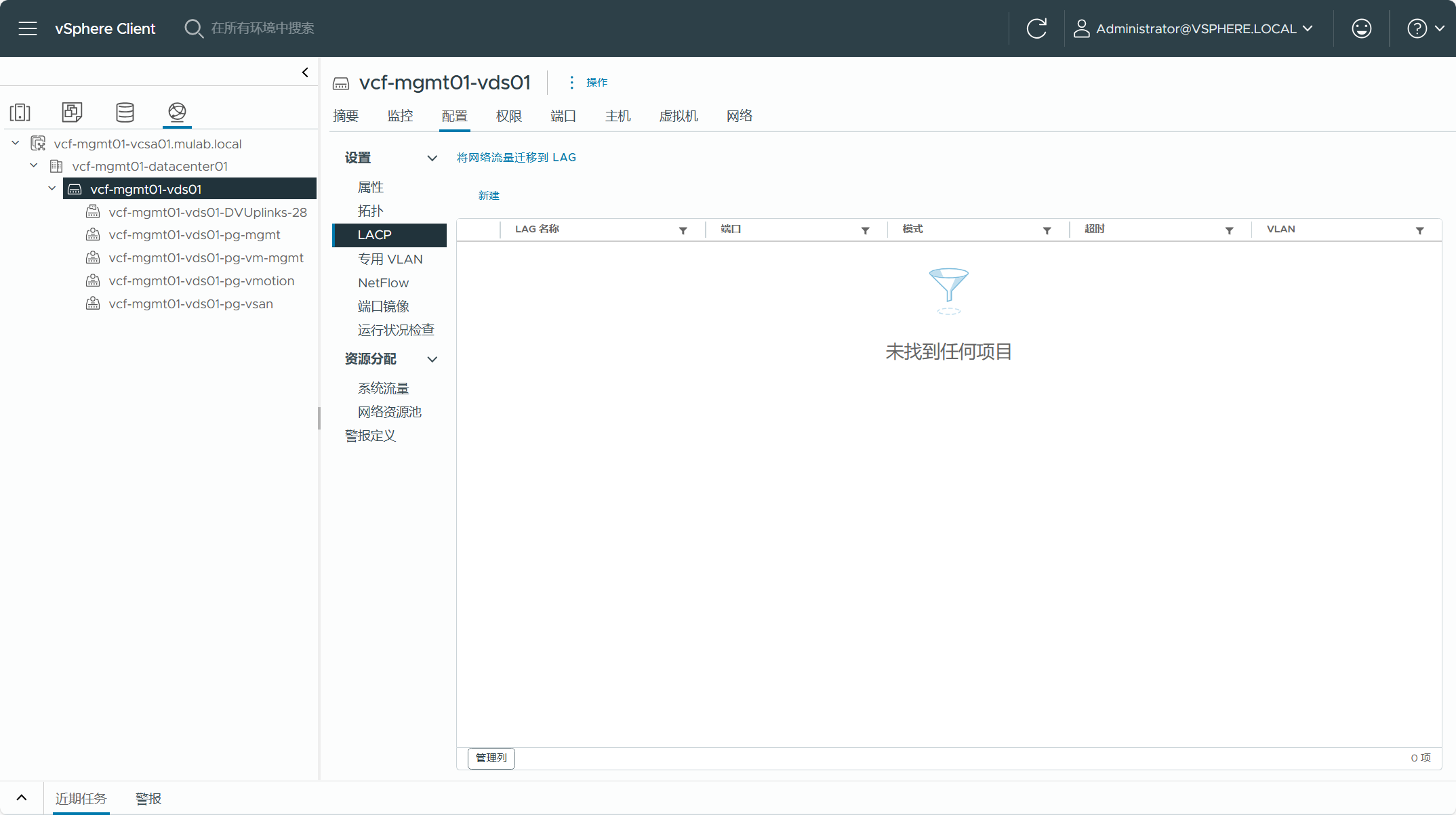
现有 vSphere 集群的 vCenter Server 不能配置增强型链接模式(ELM),否则当前 VCF Import Tool 版本不支持。
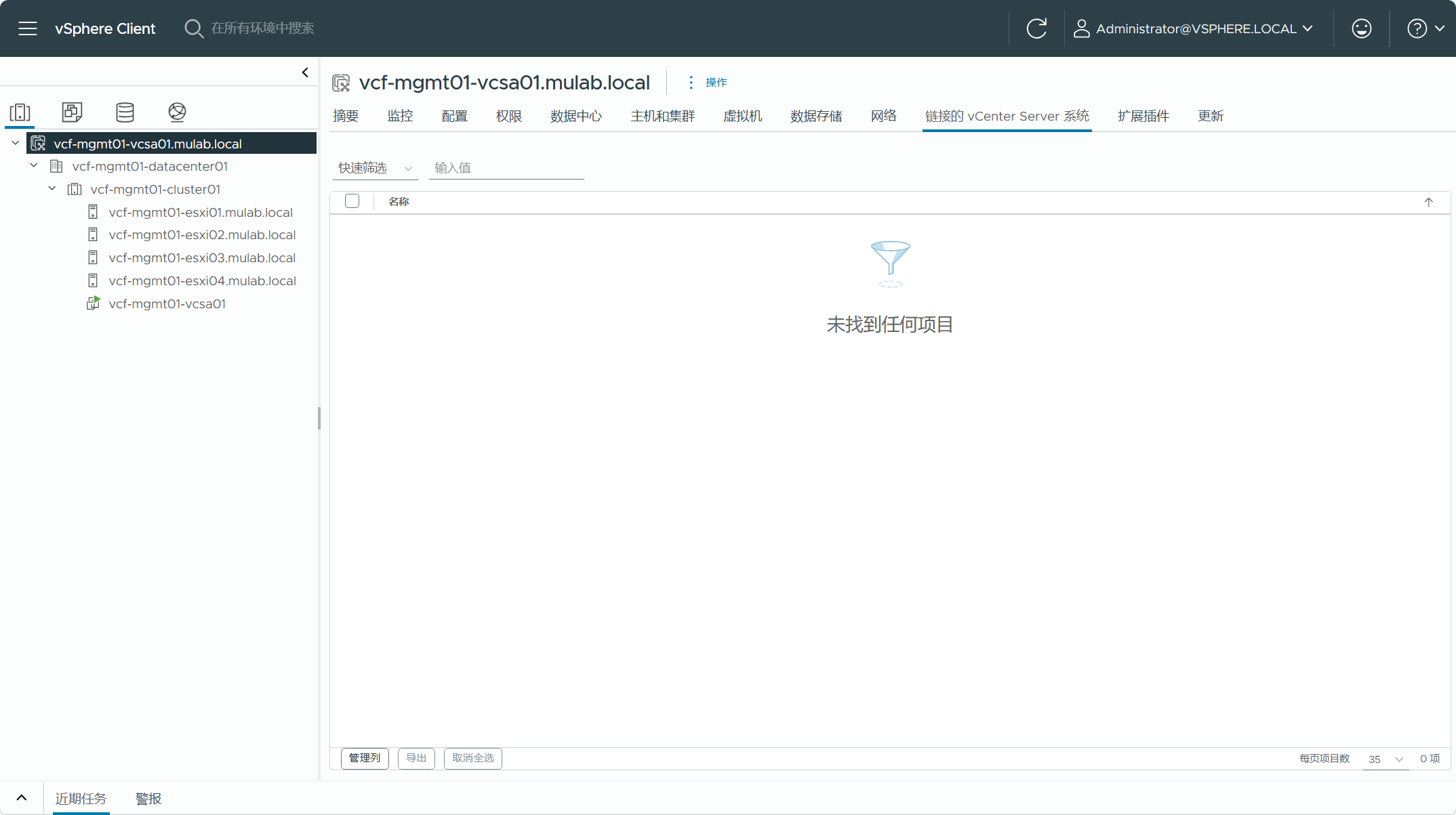
现有 vSphere 集群的 vCenter Server 不能注册到任何 NSX 解决方案当中,当前还不支持转换具有 NSX 注册的 vCenter Server。
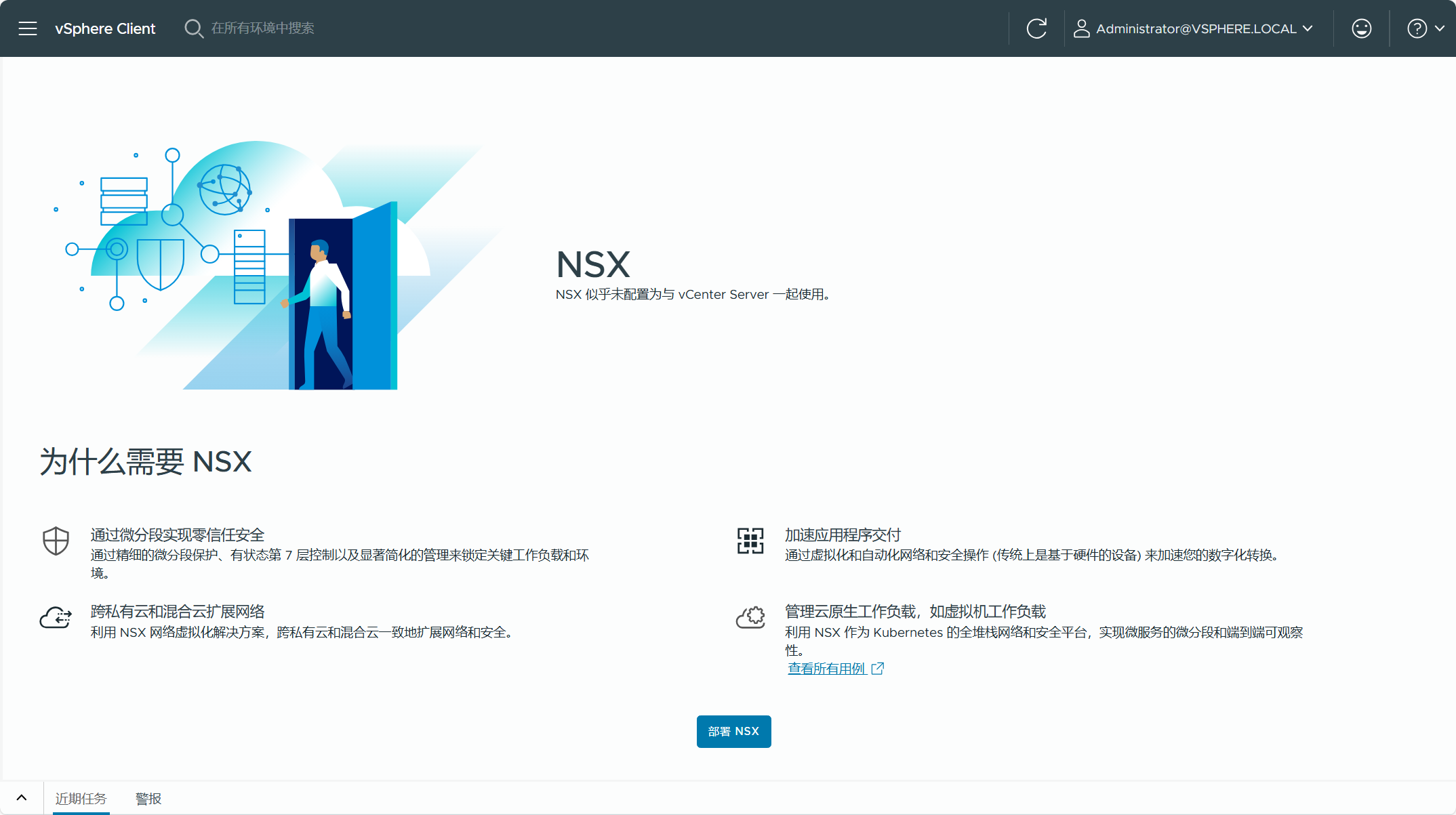
现有 vSphere 集群没有启用工作负载管理(IaaS Control Plane,以前叫 vSphere with Tanzu)。其他的,还有就是现有 vSphere 环境不能是 VxRail 环境,不能部署了 AVI Load Balancer 等其他解决方案。
使用 VCF Import Tool 工具对现有 vSphere 环境进行转换(Convert)或导入(Import),需要提前准备相关软件和工具,如下图所示。主要有三个文件,首先第一个是 VCF Import Tool,用于执行转换(Convert)或导入(Import)的命令行工具;第二个是 VCF-SDDC-Manager-Appliance,这是 VCF 中 SDDC Manager 组件的独立部署设备,执行转换(Convert)或导入(Import)过程需要在 SDDC Manager 虚拟机中运行;第三个是 VMware Software Install Bundle - NSX_T_MANAGER 4.2.0.0,这是 NSX 解决方案的 NSX Manager 安装包,在执行转换(Convert)或导入(Import)的过程中或者 Day 2,用于部署 NSX 解决方案。
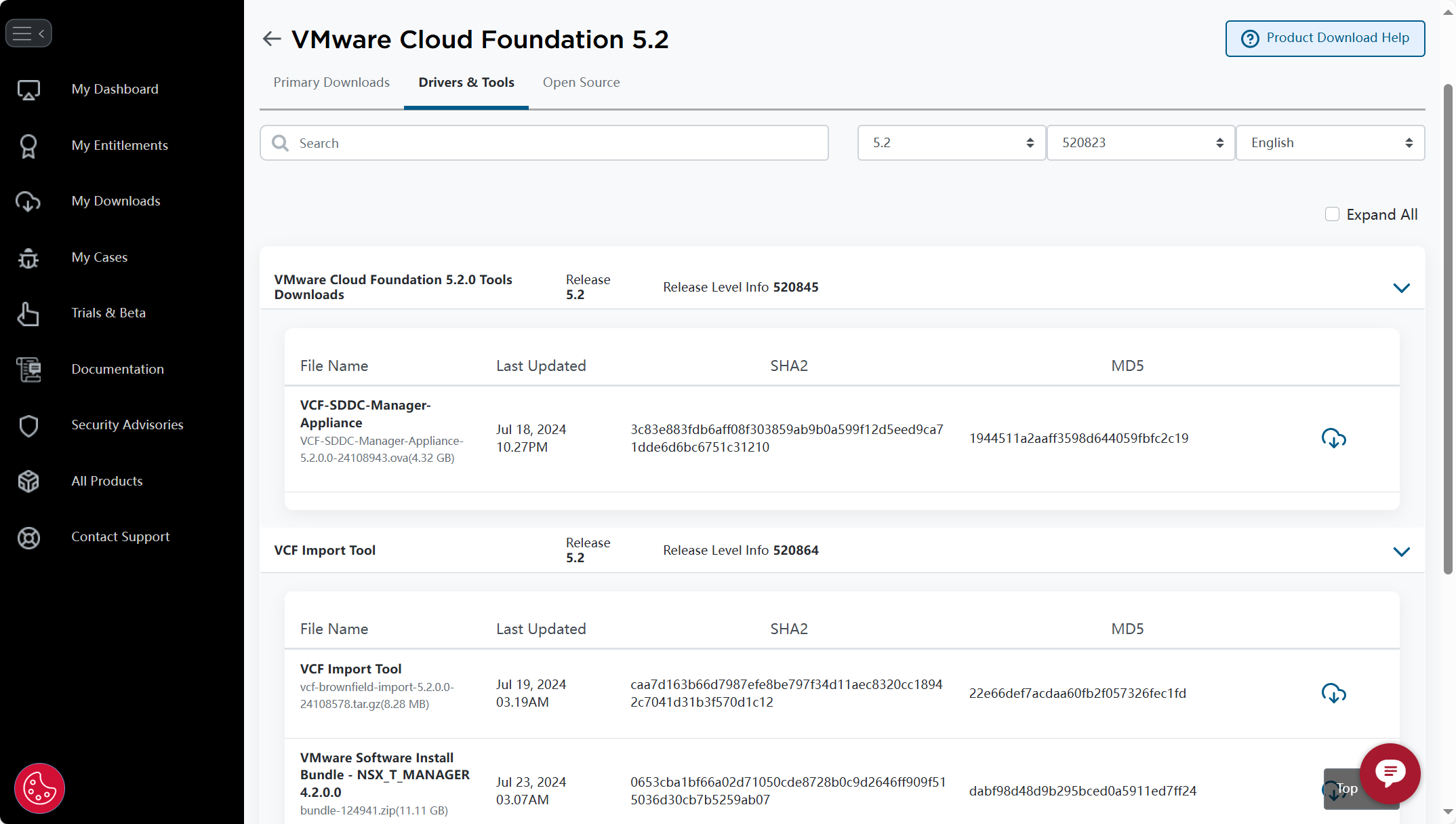
如果你有账号,可以登录
Broadcom 支持门户
(BSP)并在上图中的地方进行下载,如果你嫌麻烦,下面的百度网盘链接也可以保存。
| 文件名称 |
MD5 |
百度网盘 |
| VCF-SDDC-Manager-Appliance-5.2.0.0-24108943.ova |
1944511a2aaff3598d644059fbfc2c19 |
https://pan.baidu.com/s/1lUbrN0zjLUUC1oB8L7ZRAg?pwd=lvx9 |
| vcf-brownfield-import-5.2.0.0-24108578.tar.gz |
22e66def7acdaa60fb2f057326fec1fd |
| bundle-124941.zip |
dabf98d48d9b295bced0a5911ed7ff24 |
准备了相关软件和工具后,可以使用 VCF Import Tool 工具先对当前的 vSphere 环境进行验证一下,看看现有 vSphere 环境是否有那些地方不符合 VCF Import Tool 转换(Convert)或导入(Import)的要求。通过 SSH 以 root 用户连接到 vCenter Server 并进入 Shell 命令行,运行 chsh 命令将 vCenter Server 的默认终端命令行从 API 改成 Shell,然后创建一个临时目录(vcfimport),将 VCF Import Tool 工具上传到这个目录。
chsh
/bin/bash
mkdir /tmp/vcfimport
ls /tmp/vcfimport
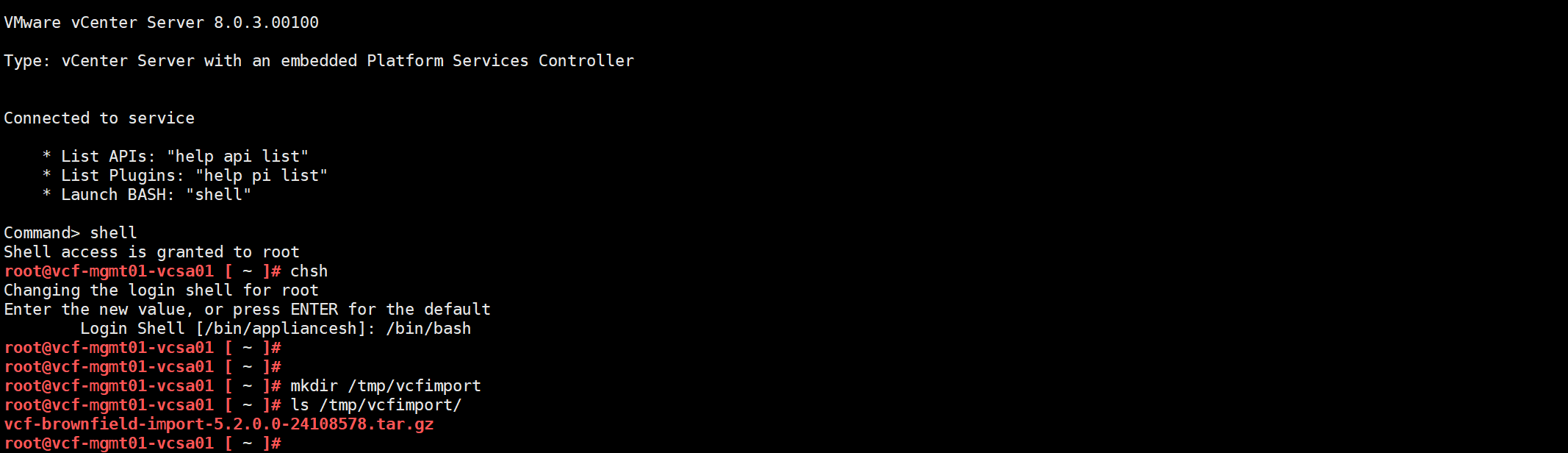
进入到工具上传的目录,使用 tar 命令解压文件,再进入到 vcf-brownfield-toolset 目录。
cd /tmp/vcfimport/
tar -xf /tmp/vcfimport/vcf-brownfield-import-5.2.0.0-24108578.tar.gz
cd vcf-brownfield-import-5.2.0.0-24108578/vcf-brownfield-toolset/

需要使用工具包内的
vcf_brownfield.py
脚本来执行现有 vSphere 环境的检查,命令如下所示。
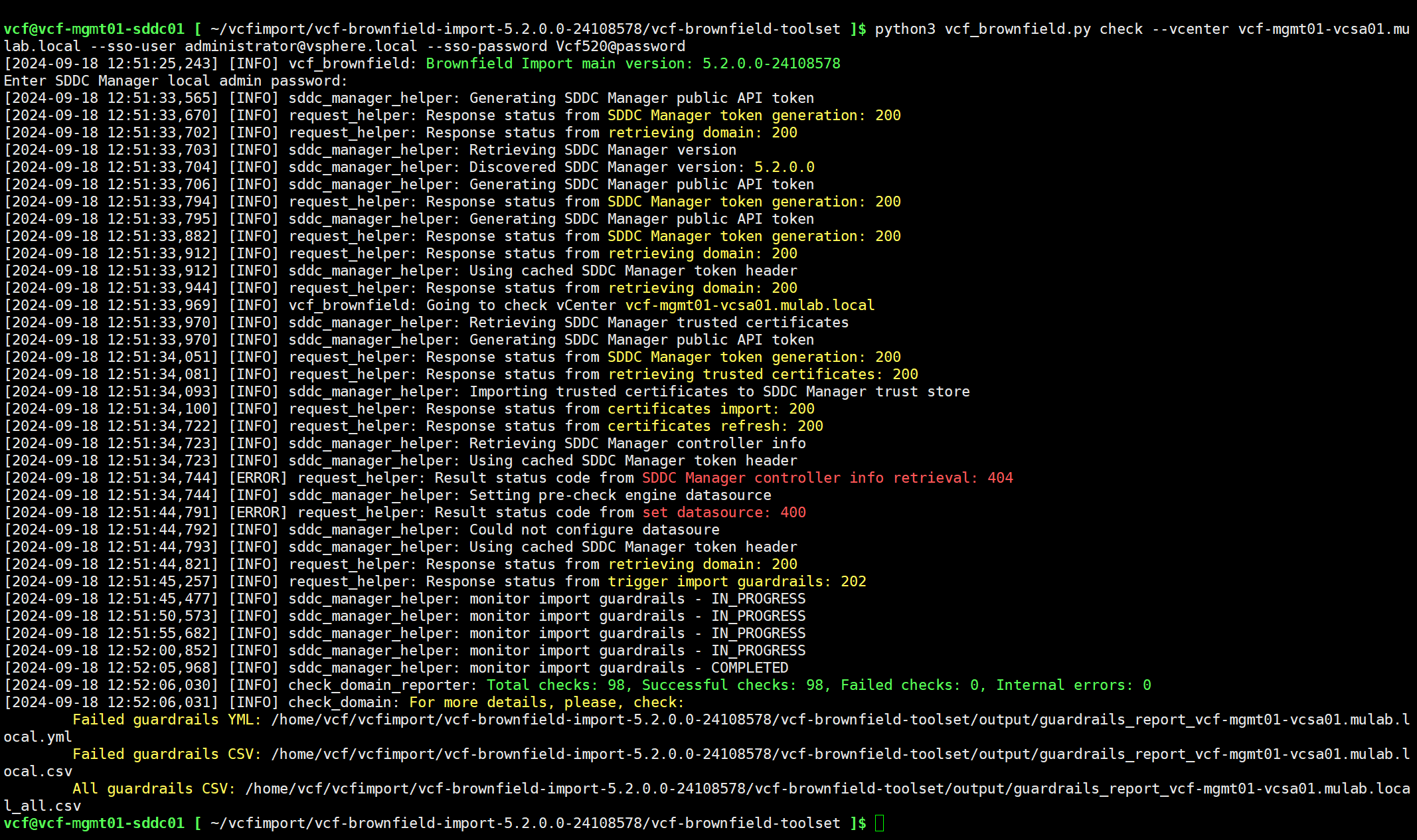
python3 vcf_brownfield.py precheck --vcenter vcf-mgmt01-vcsa01.mulab.local --sso-user administrator@vsphere.local --sso-password Vcf520@password
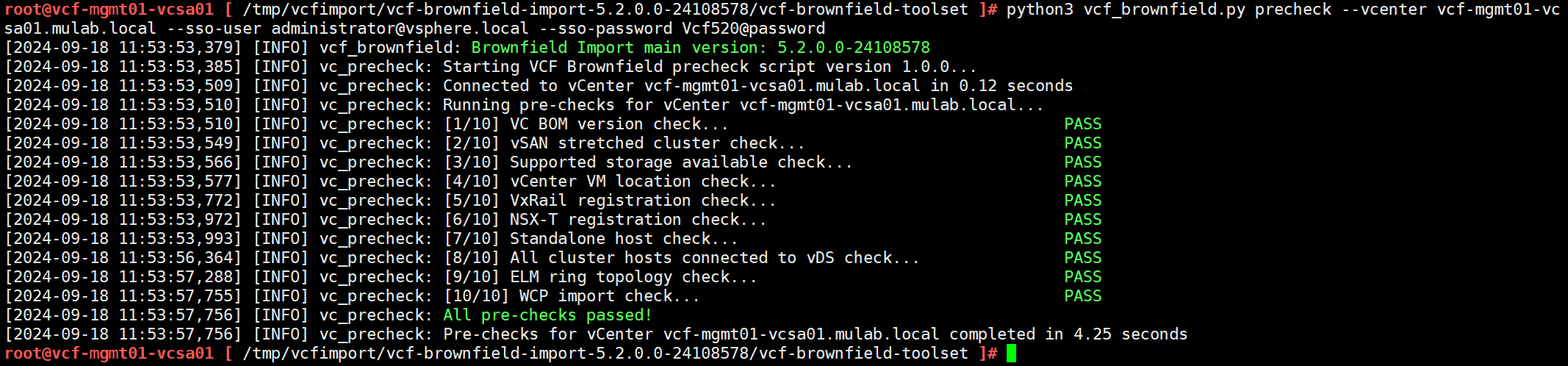
检查结果通过,将 VCF Import Tool 工具包从 vCenter Server 中删除。
cd ~
rm -rf /tmp/vcfimport/

SDDC Manager 是 VCF 解决方案的关键核心组件,如果通过 Cloud Builder 工具构建管理域则将自动部署 SDDC Manager 虚拟机,如果使用 VCF Import Tool 方式进行转换(Convert)则需要手动将 SDDC Manager 设备部署到现有 vSphere 环境当中。
导航到 vCenter Server(vSphere Client)->数据中心->集群,右击选择“部署 OVF 模板”。
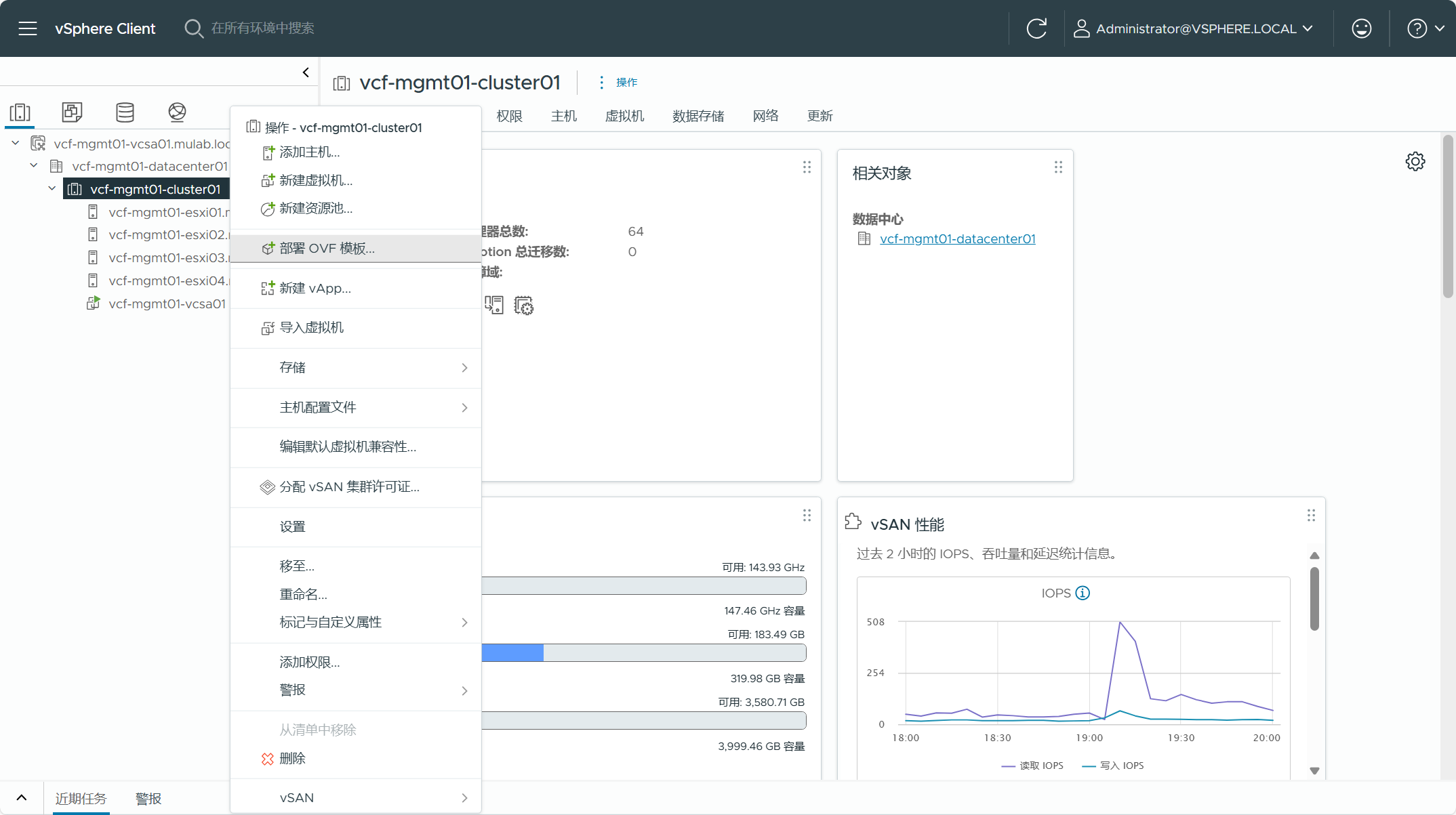
选择从本地文件上载 SDDC Manager OVA 设备,点击下一页。
配置 SDDC Manager 虚拟机的名称并选择存放的位置,点击下一页。
选择 SDDC Manager 虚拟机所使用的计算资源,点击下一页。
检查 SDDC Manager OVA 设备的摘要信息,点击下一页。
接受 SDDC Manager 安装许可协议,点击下一页。
选择 SDDC Manager 虚拟机所使用的存储,点击下一页。
选择 SDDC Manager 虚拟机所使用的网络端口组,点击下一页。
配置 SDDC Manager 虚拟机各类用户的密码以及地址等信息,点击下一页。
检查所有配置,点击完成并开始部署。
部署成功后,可以对 SDDC Manager 虚拟机创建一个快照。
右击 SDDC Manager 虚拟机,点击打开电源。
此时,如果访问 SDDC Manager UI,可以看到正在初始化中,现在不用管它,只需要能通过 SSH 访问 SDDC Manager 的 Shell 即可。

后续我们需要通过 SDDC Manager 执行现有 vSphere 环境的转换过程,但是在正式执行转换前,还需要在 SDDC Manager 上再执行一次预检查,确定当前 vSphere 环境是否满足转换为管理域的要求。通过 SSH 以 vcf 用户连接到 SDDC Manager 的命令行,使用以下命令创建一个新的目录(vcfimport),然后将 VCF Import Tool 文件上传到 SDDC Manager 的这个目录,再将文件解压后并进入到 vcf-brownfield-toolset 目录。
mkdir /home/vcf/vcfimport
ls /home/vcf/vcfimport
cd /home/vcf/vcfimport
tar -xf vcf-brownfield-import-5.2.0.0-24108578.tar.gz
cd vcf-brownfield-import-5.2.0.0-24108578/vcf-brownfield-toolset/

进入 VCF Import Tool 目录后,使用以下命令在 SDDC Manager 上执行环境检查。总共有 98 个内容,成功检查 97 个,失败 1 个。
python3 vcf_brownfield.py check --vcenter vcf-mgmt01-vcsa01.mulab.local --sso-user administrator@vsphere.local --sso-password Vcf520@password
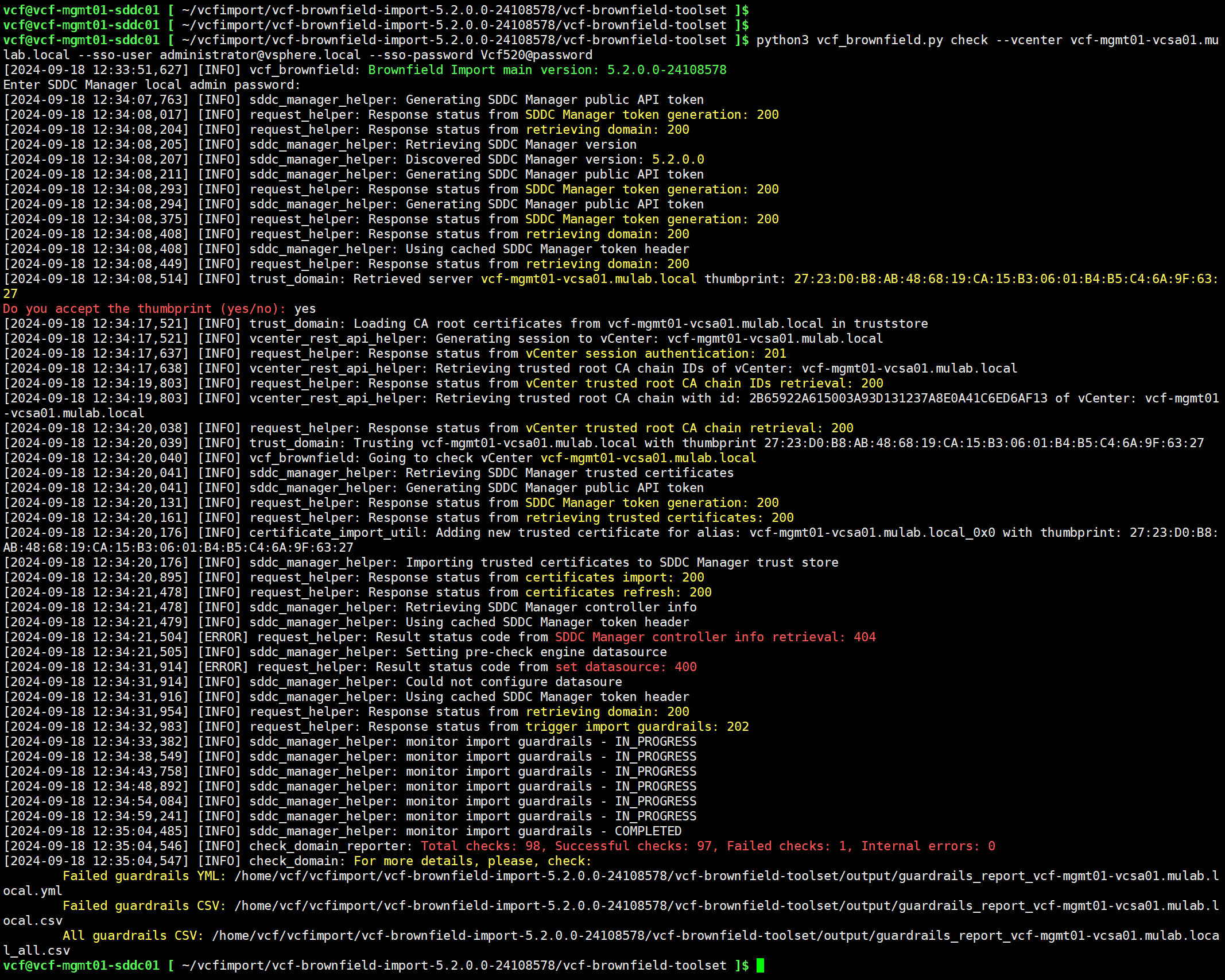
可以通过输出的结果(JSON 文件和 CSV 表格文件),查看具体失败的内容,还可以通过 All guardrails CSV 文件查看所有检查的内容。

根据上面所查看的 JSON 文件,有一个检查失败的原因是由于当前 vSphere 环境的 vLCM 配置有一项与 SDDC Manager 中的默认 vLCM 配置不一致导致的。其实,我们可以通过
ESX Upgrade Policy Guardrail Failure
查看 SDDC Manager 中 vLCM 的默认配置,检查当前 vSphere 环境的 vLCM 配置,然后将这些配置调整为 SDDC Manager 中 vLCM 的默认配置即可。当然,如果你不处理,这个失败的检查应该不会影响现有 vSphere 环境转换为管理域。根据错误的信息,将当前 vSphere 环境的 vLCM 配置修改为 SDDC Manager 中 vLCM 的默认配置,如下图所示。
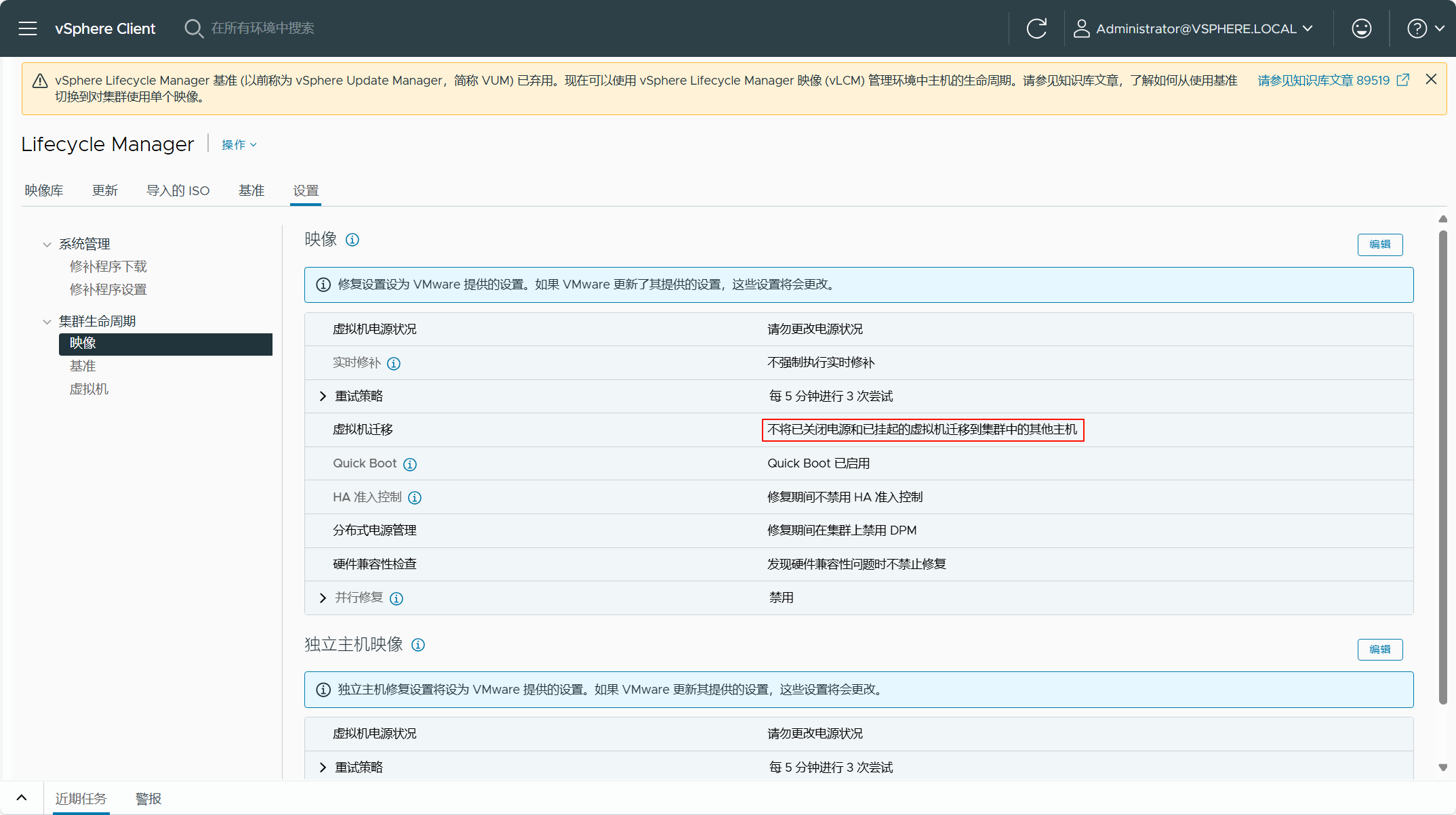
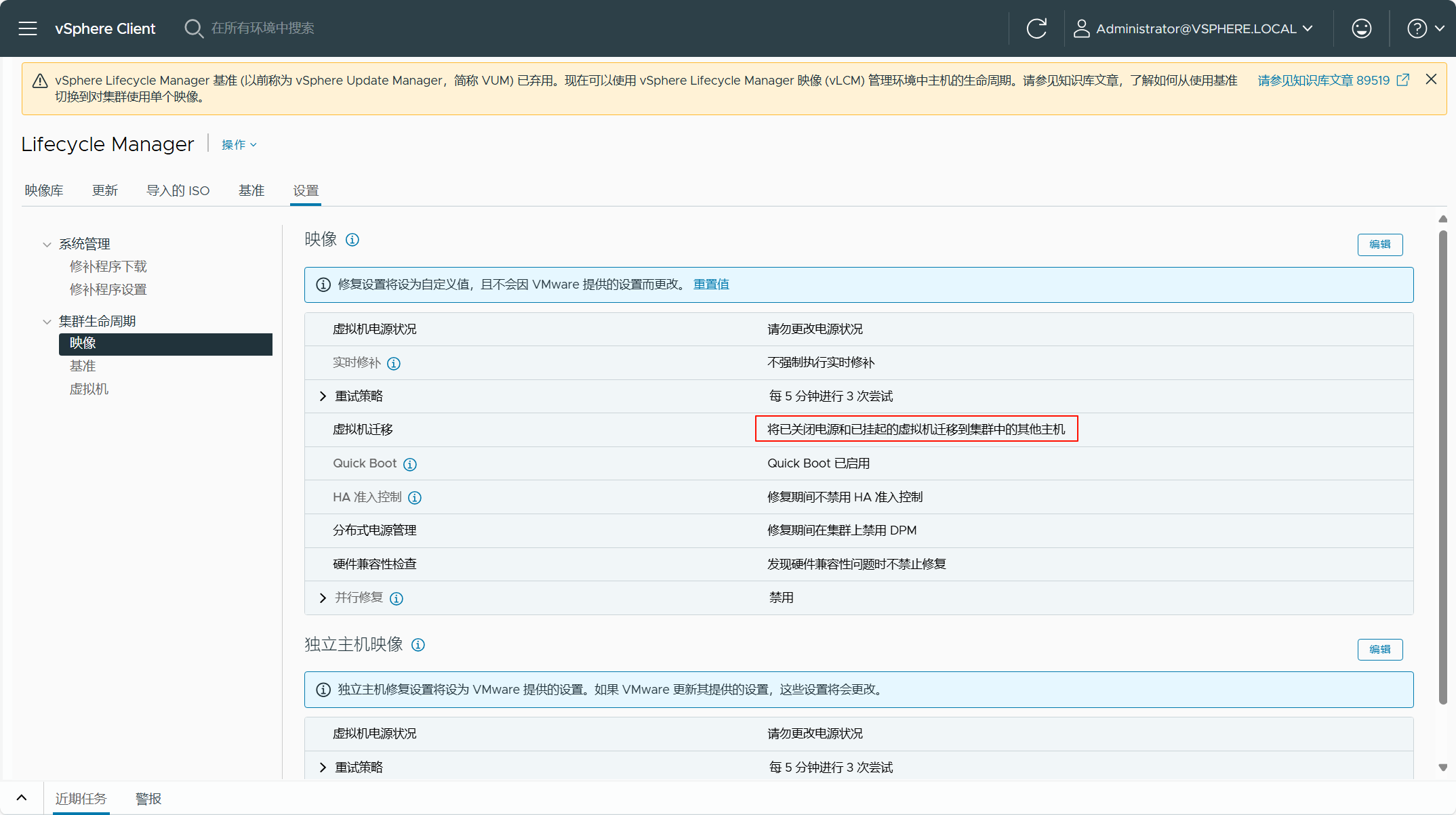
修改 vLCM 配置后,重新执行一遍检查,现在所有检查都已成功。
在将现有 vSphere 环境转换为管理域时,我们可以同时执行 NSX 的部署,由于当前还不支持将现有 NSX 的环境转换为管理域,所以这一步算是对这一解决方案的补充。不过,如果在执行转换过程部署 NSX 解决方案,这只会为 ESXi 主机配置只有安全功能的 NSX,如果想实现完整的 NSX Overlay 网络功能,比如支持微分段、T0/T1 网关等,需要在 NSX 部署完以后,单独去配置 TEP 网络和其他设置。这一步骤是可选操作,你可以在执行转换过程同时执行 NSX 的部署,也可以在执行转换结束之后,在其他时间再执行 NSX 的部署。
使用 VCF Import Tool 执行现有 vSphere 环境的转换并同时执行 NSX 的部署需要准备一个
JSON 配置文件
,如下所示。这个配置文件中定义了 NSX Manager 的部署大小,NSX 集群的 VIP 地址以及三个 NSX Manager 设备的地址信息,请一定提前配置好这些地址的正反向域名解析,还有一个重点要注意的是,NSX 所部署的安装包路径,这个保持默认即可。
{
"license_key": "AAAAA-BBBBB-CCCCC-DDDDD-EEEEE",
"form_factor": "medium",
"admin_password": "Vcf520@password",
"install_bundle_path": "/nfs/vmware/vcf/nfs-mount/bundle/bundle-124941.zip",
"cluster_ip": "192.168.32.66",
"cluster_fqdn": "vcf-mgmt01-nsx01.mulab.local",
"manager_specs": [{
"fqdn": "vcf-mgmt01-nsx01a.mulab.local",
"name": "vcf-mgmt01-nsx01a",
"ip_address": "192.168.32.67",
"gateway": "192.168.32.254",
"subnet_mask": "255.255.255.0"
},
{
"fqdn": "vcf-mgmt01-nsx01b.mulab.local",
"name": "vcf-mgmt01-nsx01b",
"ip_address": "192.168.32.68",
"gateway": "192.168.32.254",
"subnet_mask": "255.255.255.0"
},
{
"fqdn": "vcf-mgmt01-nsx01c.mulab.local",
"name": "vcf-mgmt01-nsx01c",
"ip_address": "192.168.32.69",
"gateway": "192.168.32.254",
"subnet_mask": "255.255.255.0"
}]
}
将 NSX 部署的 JSON 配置文件以及 NSX 的安装包上传到 SDDC Manager 中,需要记住这个配置文件上传的路径,后面需要用到。
ls /home/vcf/vcfimport/
ls /nfs/vmware/vcf/nfs-mount/bundle/

通过 vcf 用户登录到 SDDC Manager 命令行,进入到 vcf-brownfield-toolset 目录后,使用以下命令执行 vSphere 环境转换过程。运行命令后,输入 SDDC Manager 的 admin 和 backup 用户的密码以及 vCenter Server 的 root 密码进行验证。
cd /home/vcf/vcfimport/vcf-brownfield-import-5.2.0.0-24108578/vcf-brownfield-toolset/
python3 vcf_brownfield.py convert --vcenter vcf-mgmt01-vcsa01.mulab.local --sso-user administrator@vsphere.local --sso-password Vcf520@password --nsx-deployment-spec-path /home/vcf/vcfimport/vcf520-import-nsx.json
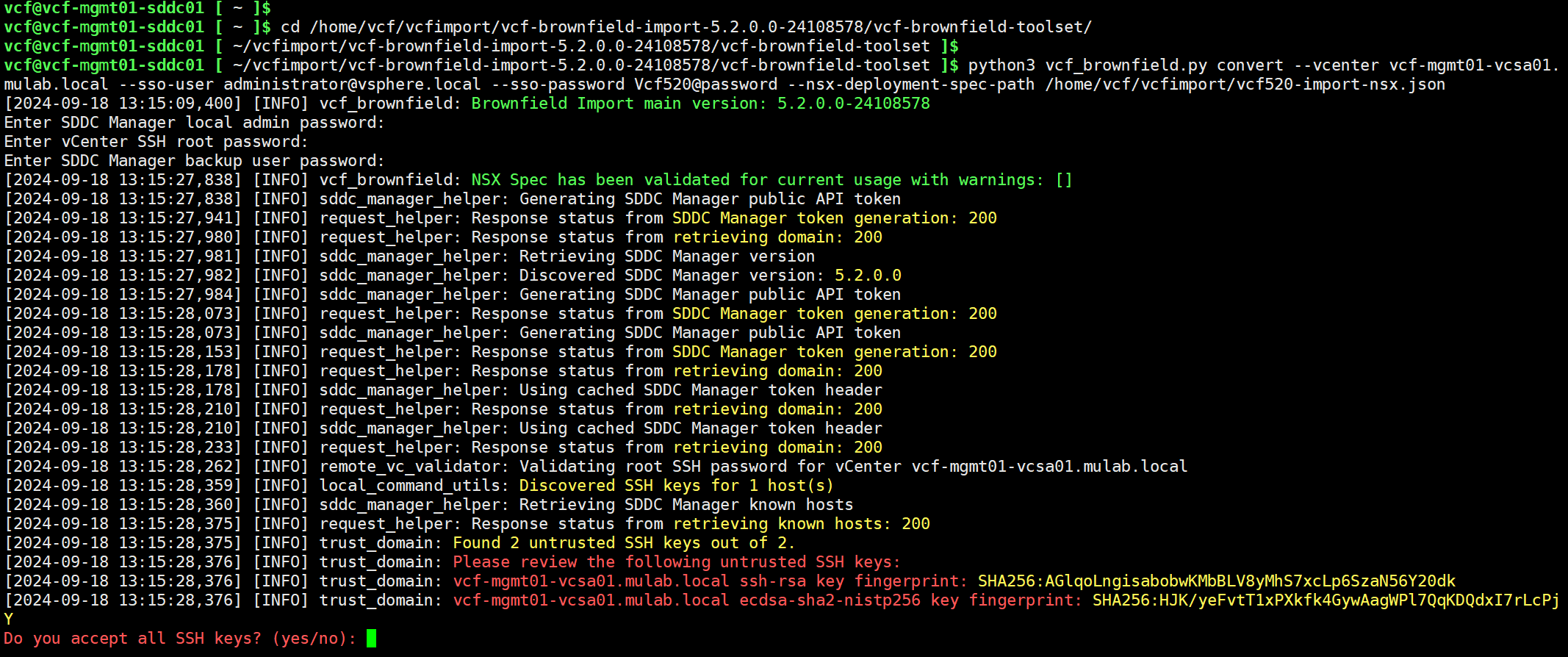
此时,可以登录 SDDC Manager UI 查看任务执行的状态。
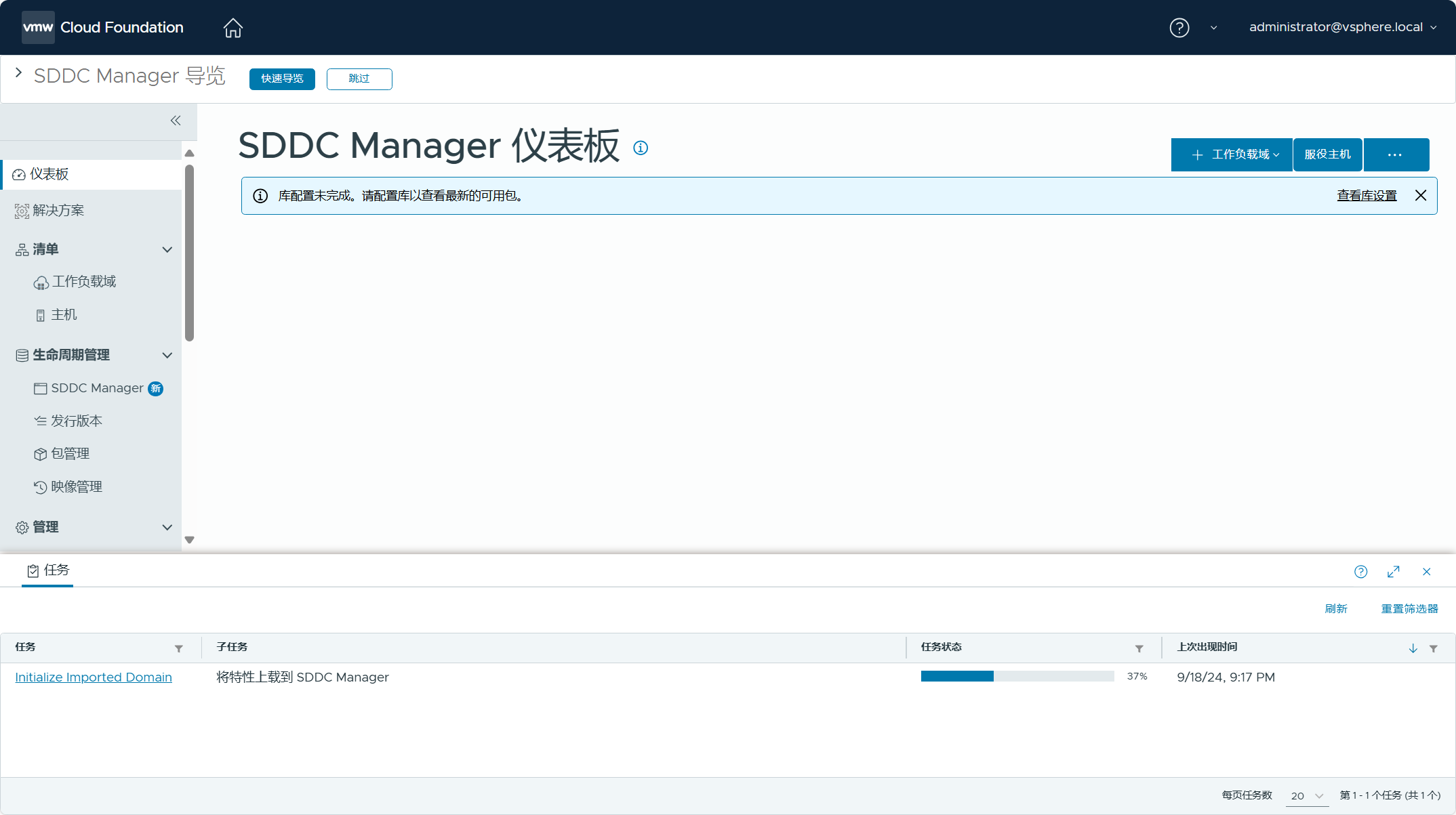
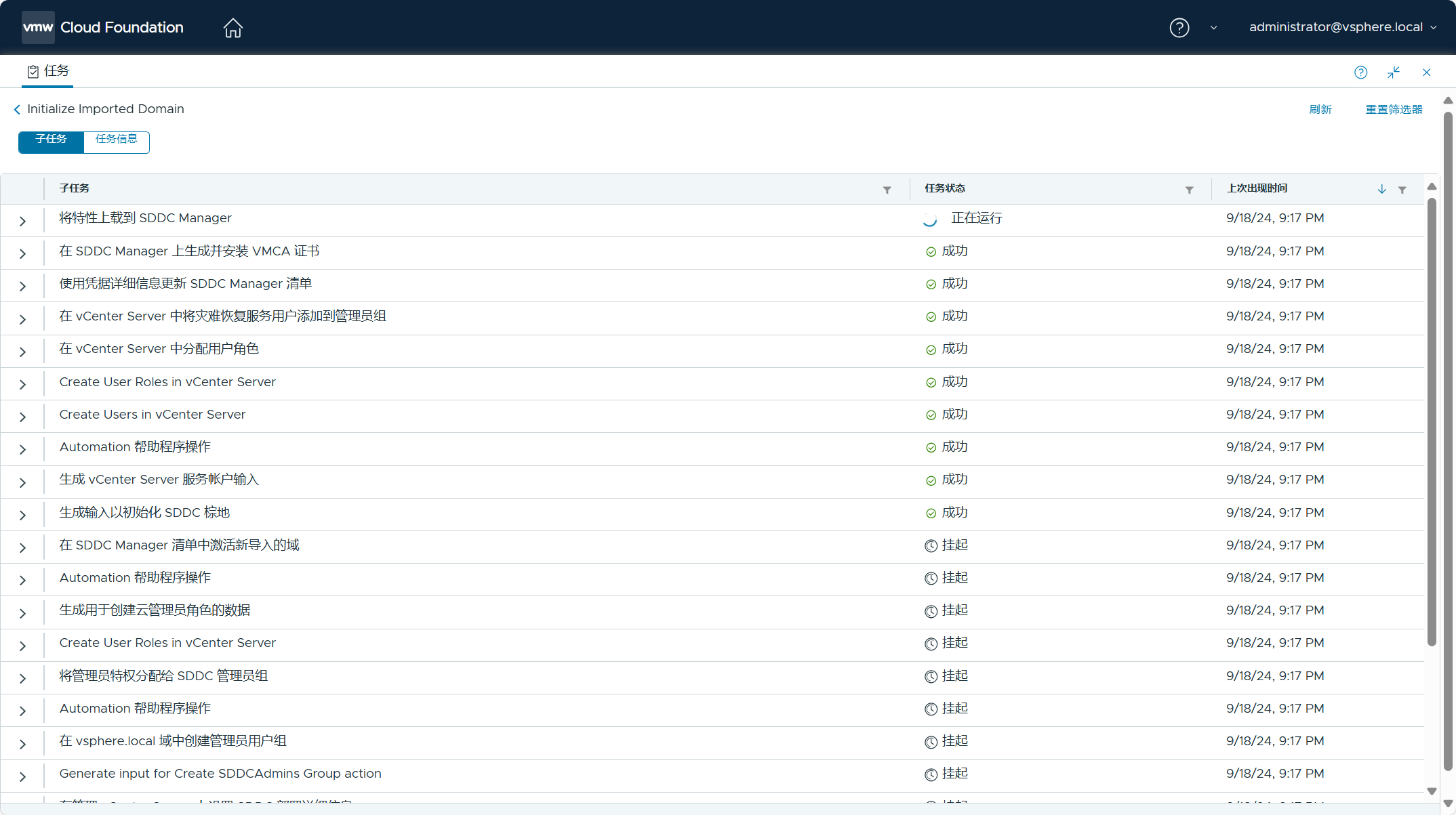
转换任务执行一段时间后,居然失败了!
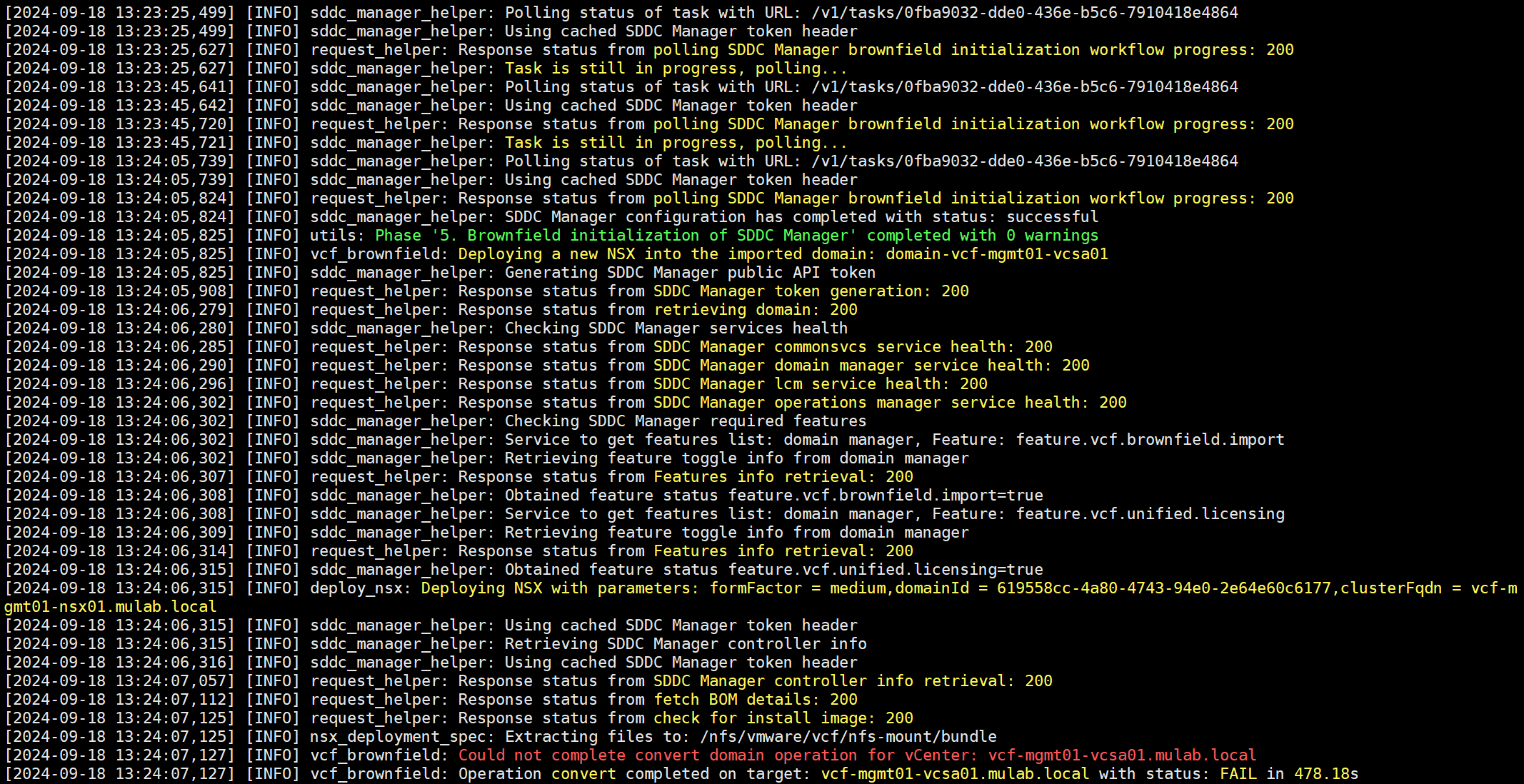
但是,通过 SDDC Manager UI 查看,任务已经成功了。
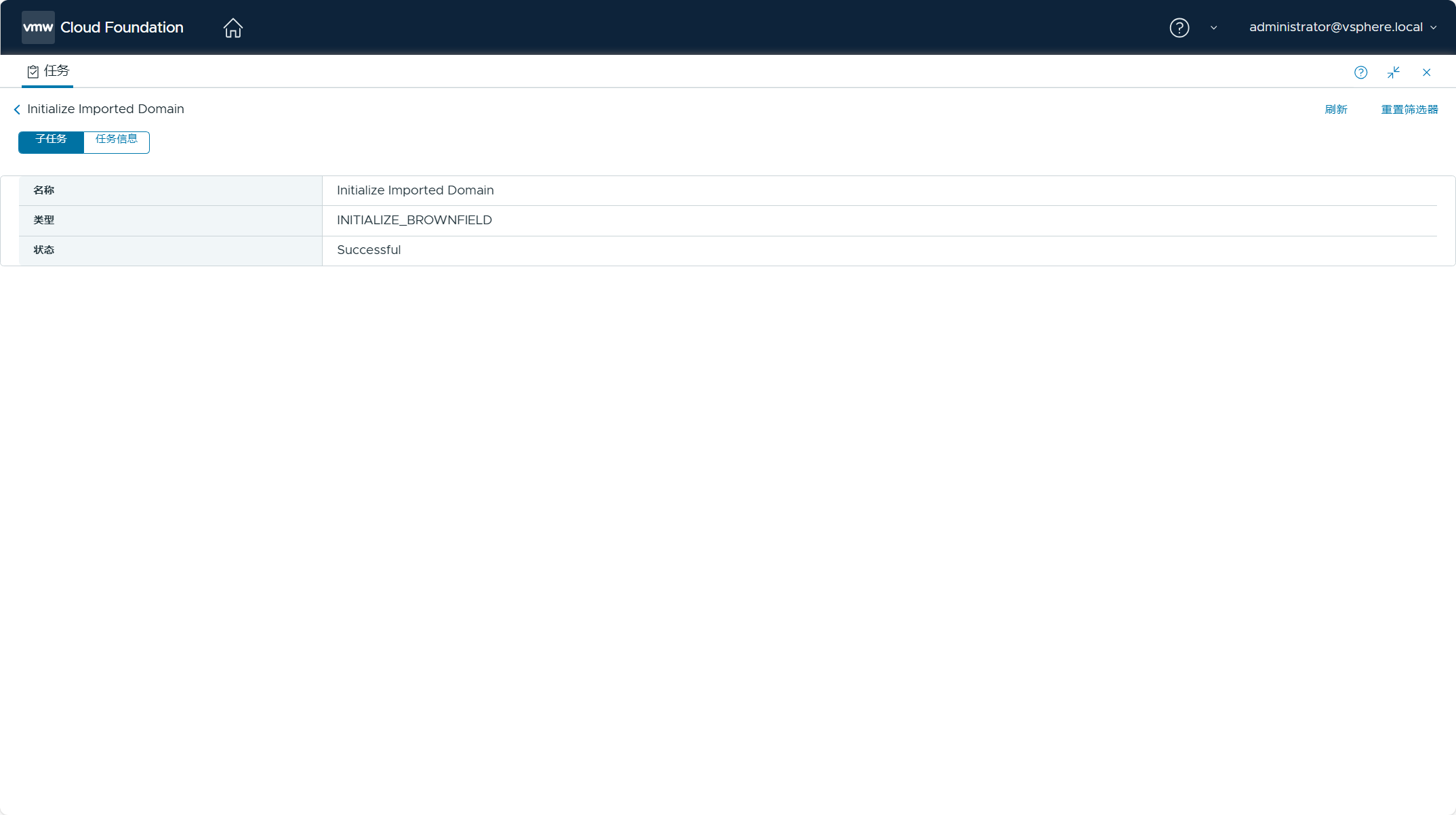
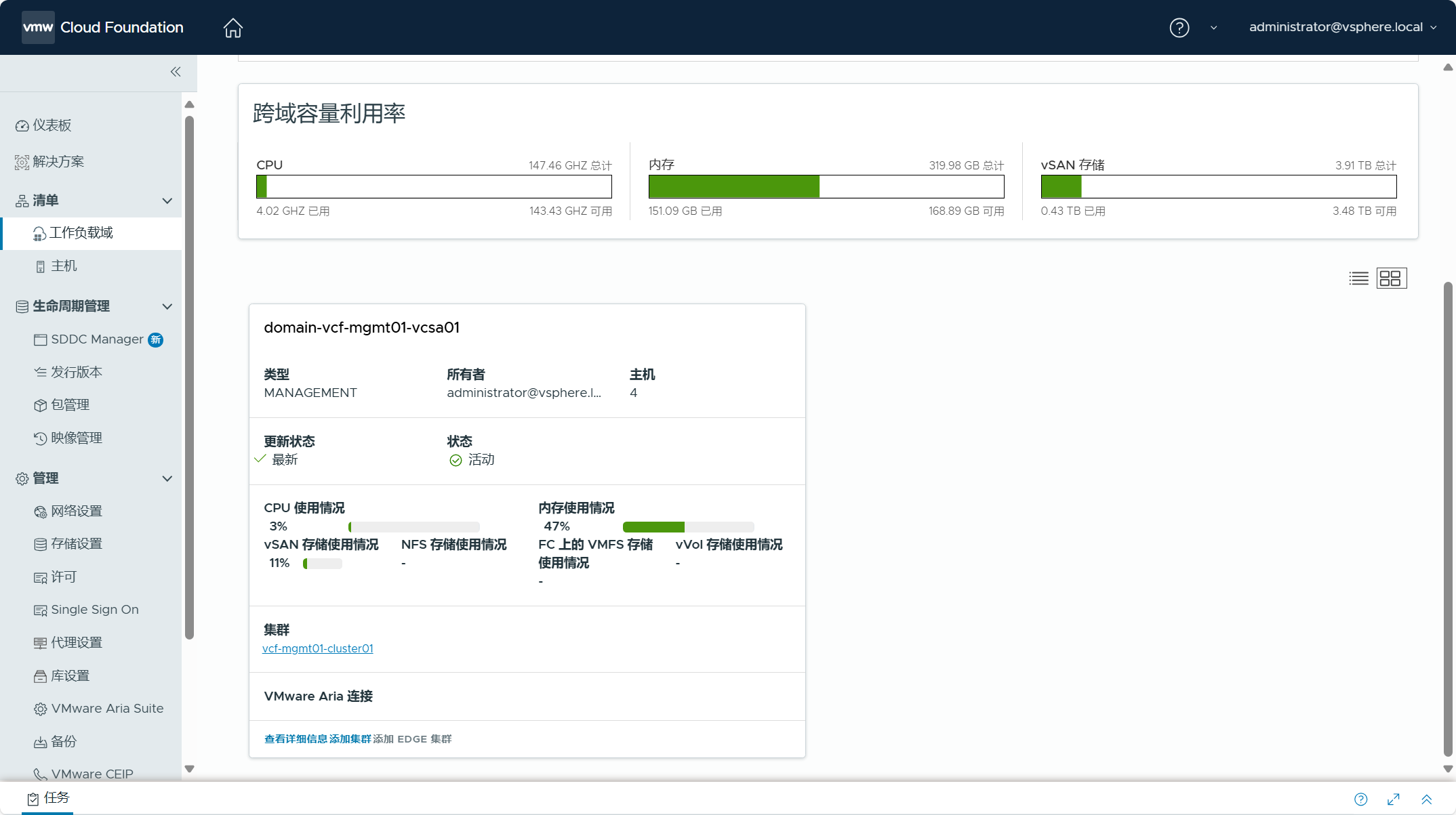
也能看到 vSphere 环境已经转换成管理域。
使用下面命令查看了一下输出结果,原因是部署 NSX 任务失败了,意思是说上传的 NSX 安装包不是一个有效的 ZIP 文件。
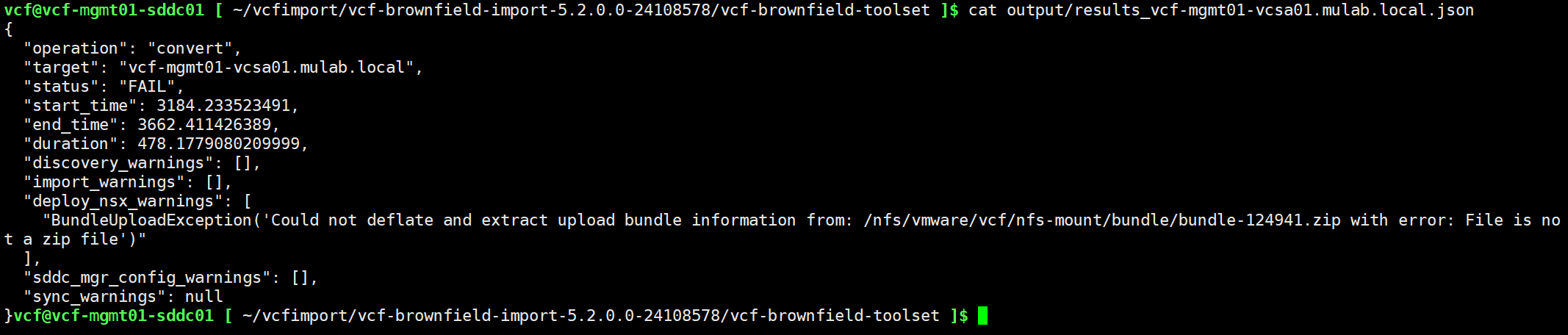
再次查看了一下上传的 NSX 安装包文件,发现确实是上传的包有问题,大小只有 3 个多 G,额确实是自己疏忽了。将文件删除后,重新使用 FTP 工具将 NSX 安装包上传上去,查看大小为 12 G,这次没问题了。正常情况下,你应该不会遇到上面这个问题。

由于已经完成 vSphere 环境的转换,现在不能再重新使用上面的 Convert 命令了,就是等于在转换的时候没有执行 NSX 的部署,所以这就当作是在 Day 2 执行这个步骤,我们需要使用另外一个命令来
单独执行 NSX 的部署
工作流,如下所示。
python3 vcf_brownfield.py deploy-nsx --vcenter vcf-mgmt01-vcsa01.mulab.local --nsx-deployment-spec-path /home/vcf/vcfimport/vcf520-import-nsx.json
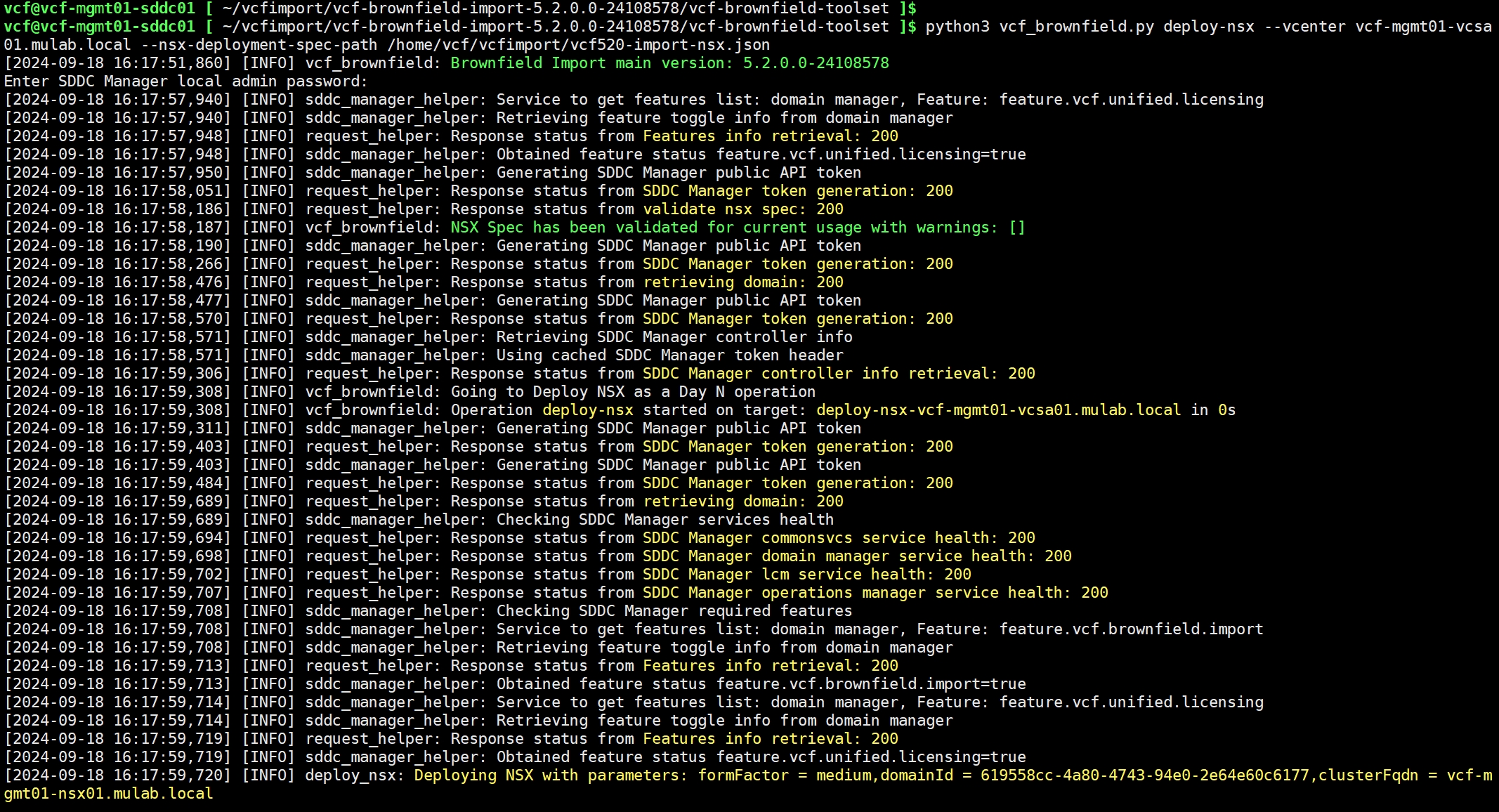
现在可以看到,NSX 设备压缩包已经可以正常解压了,输入 yes 开始 NSX Manager 的部署。
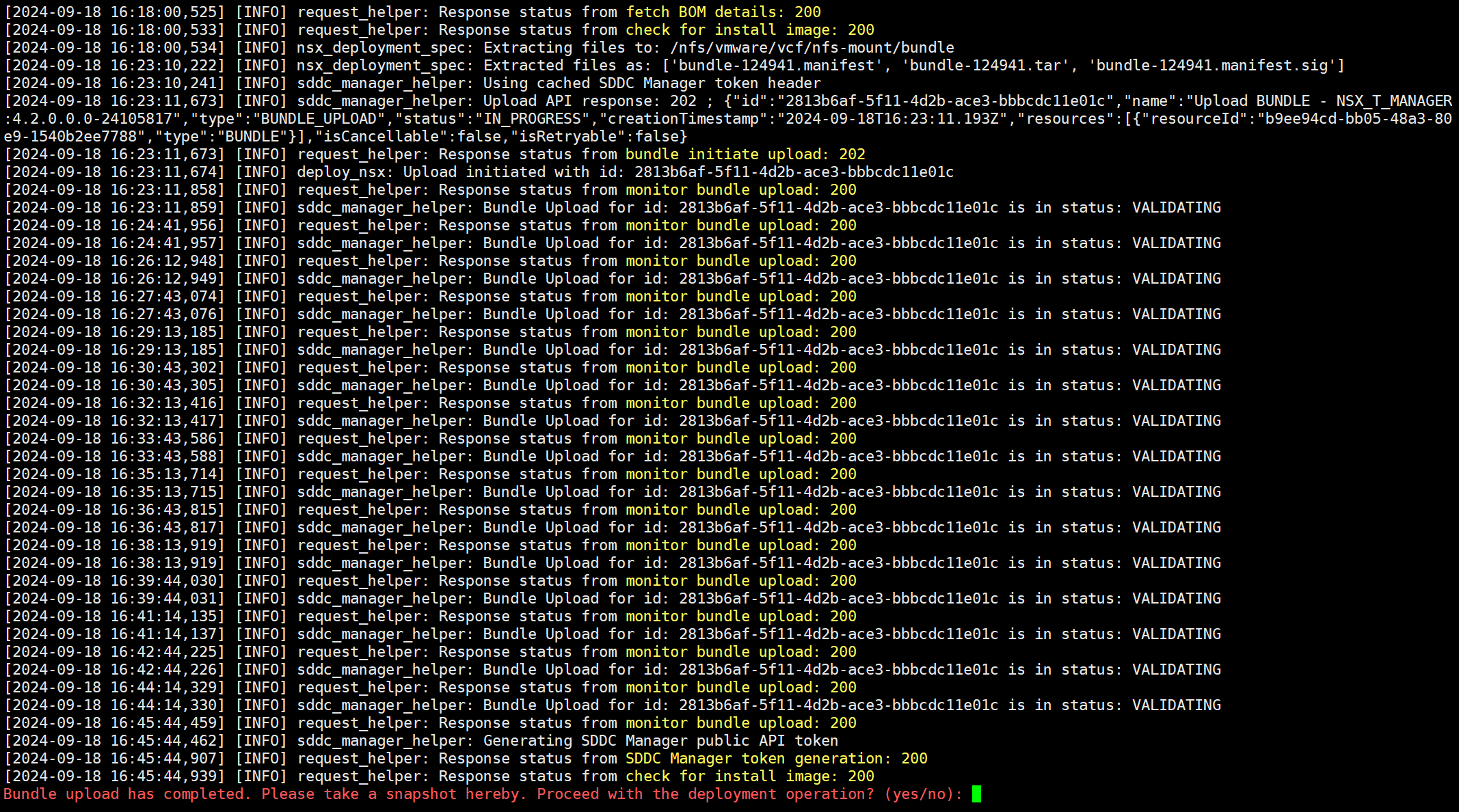
NSX 部署成功。
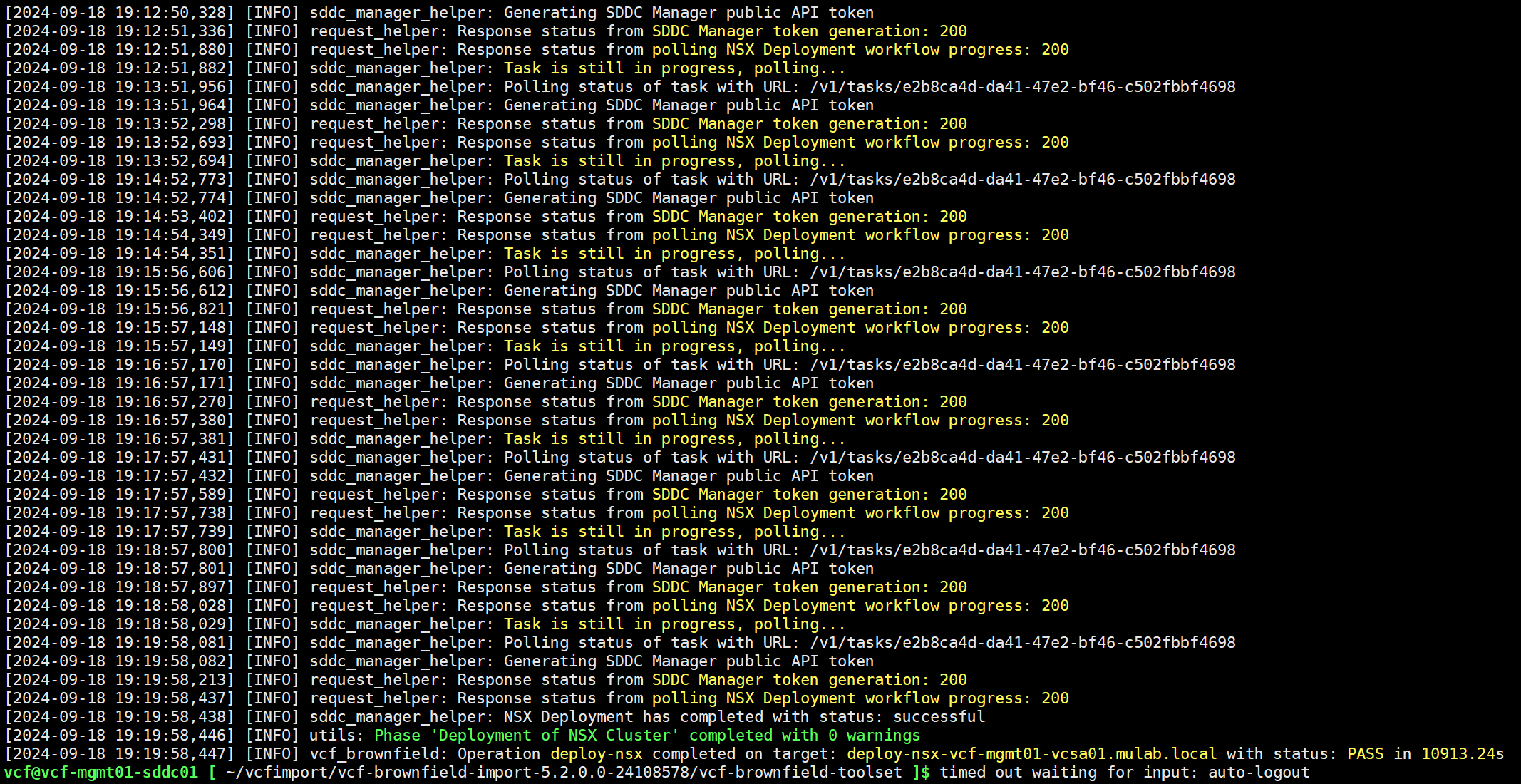
通过 SDDC Manager UI 查看任务状态,结果也是成功。
部署成功后,切换到 root 用户,重新启动 SDDC Manager 的所有服务,并等待 UI 重新初始化。
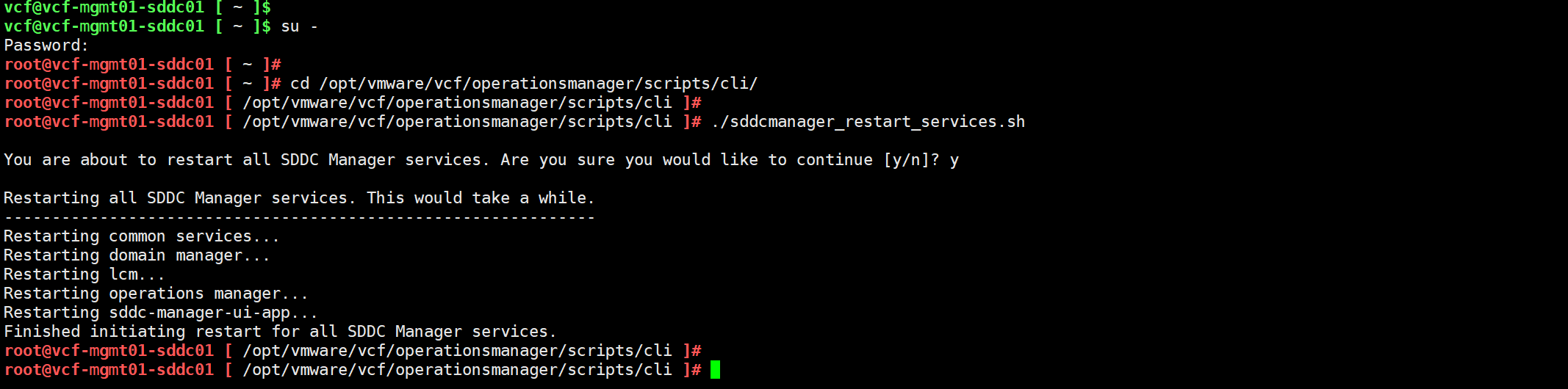
导航到 SDDC Manager UI->清单->工作负载域,可以看到现有 vSphere 环境已经被转换成管理域,管理域的名称为 domain-vcf-mgmt01-vcsa01。
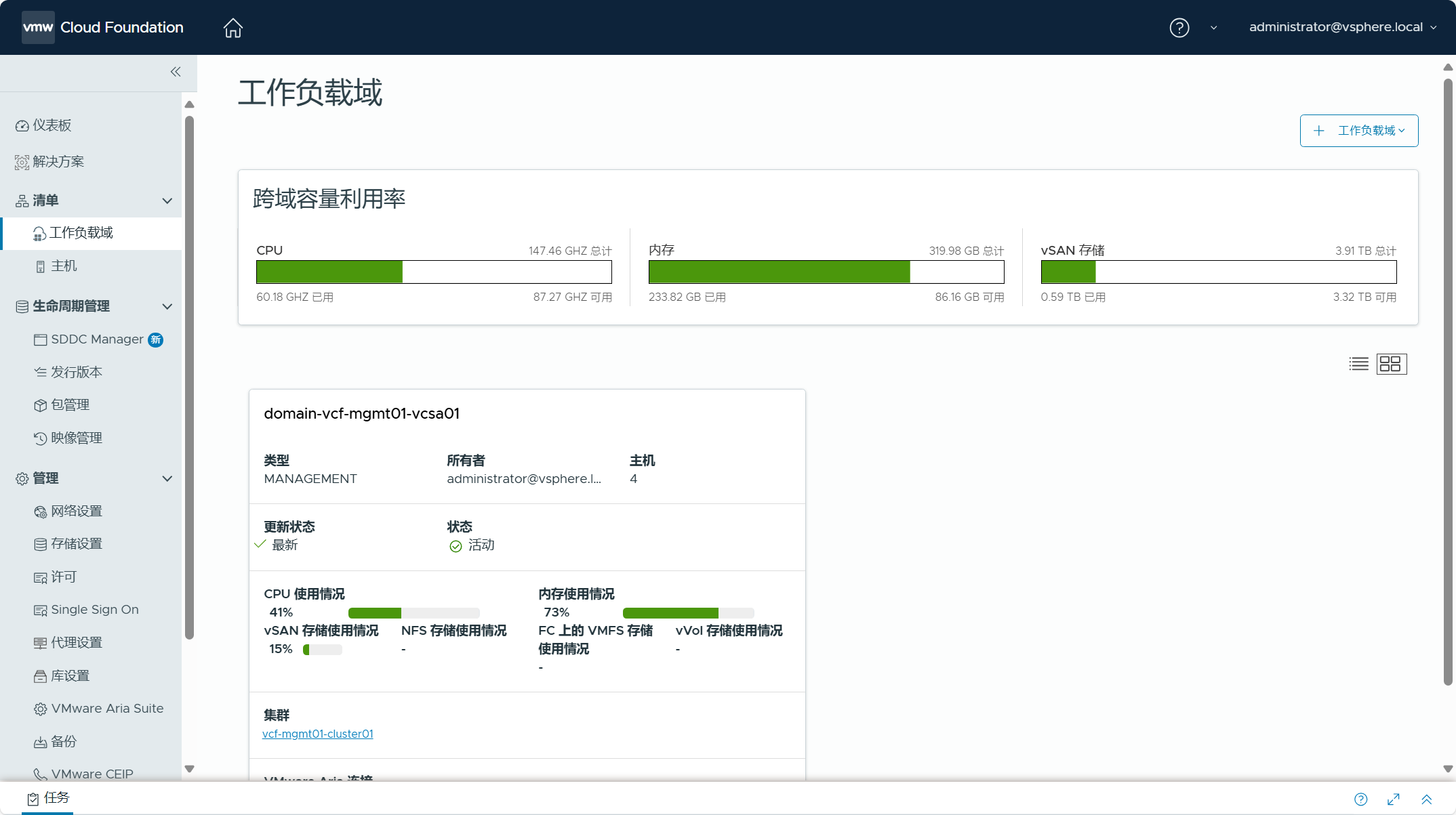
点击进入管理域,查看该工作负载域的摘要信息,提示当前管理域中的产品缺少许可证,需要点击“添加许可证”为该域中的产品分配许可证密钥。
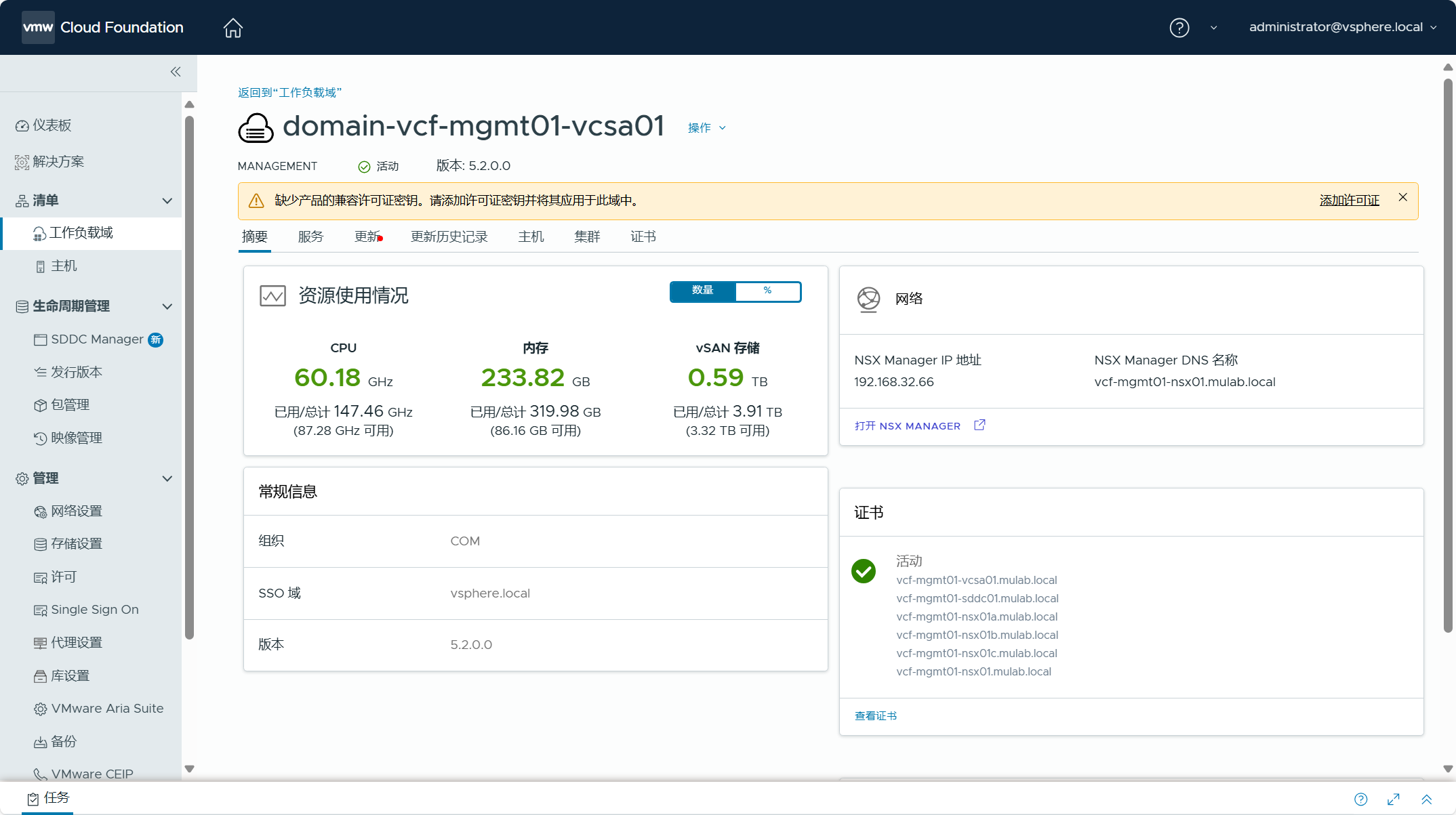
在主机和集群选项卡中,可以看到属于 vSphere 环境中的 ESXi 主机和集群配置信息。
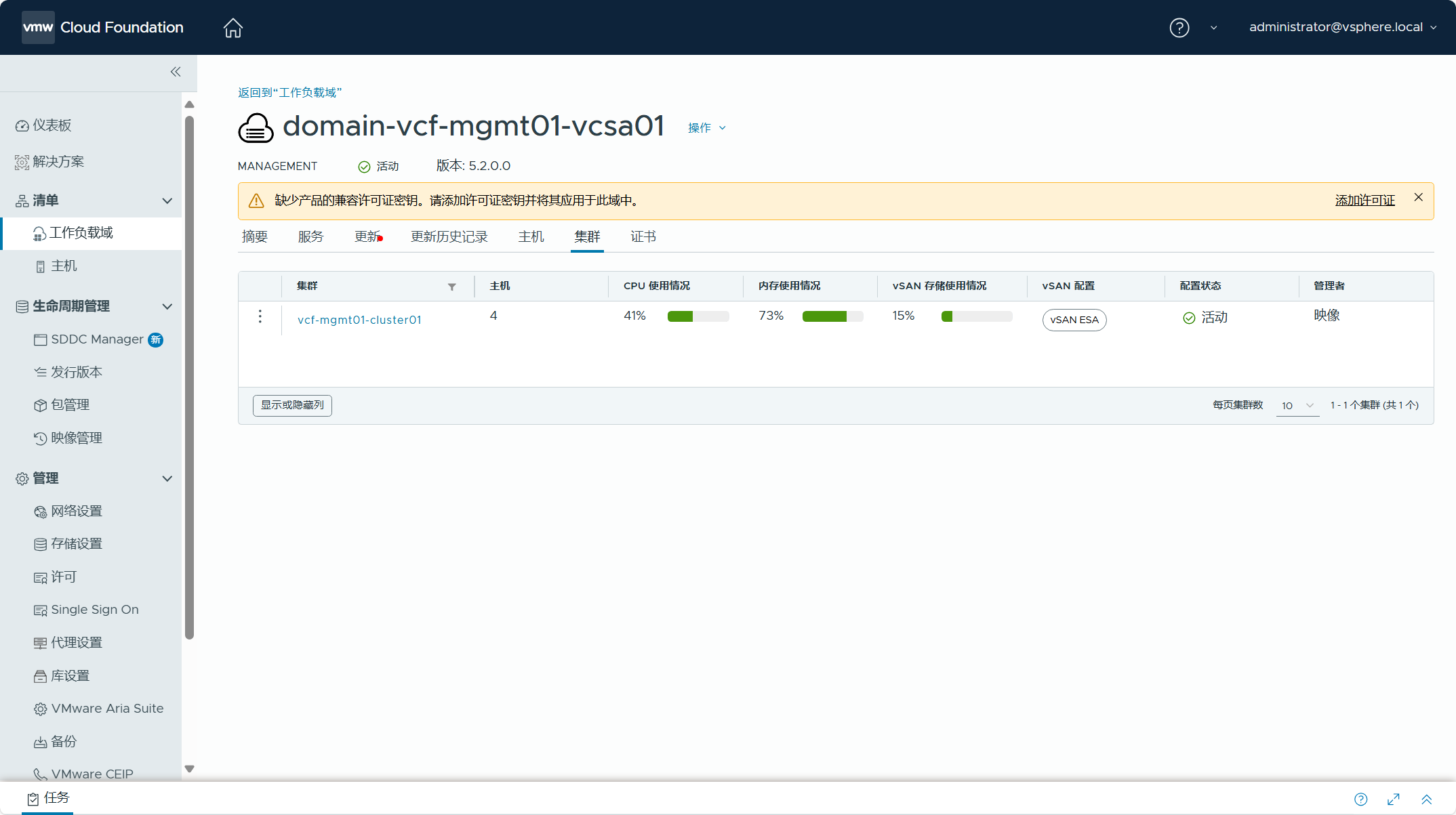
导航到 SDDC Manager UI->管理->网络设置,可以看到 vSphere 环境中 ESXi 主机的 VMkernel 网卡,用于 vMotion 服务和 vSAN 服务的静态 IP 地址已经被创建为网络池。
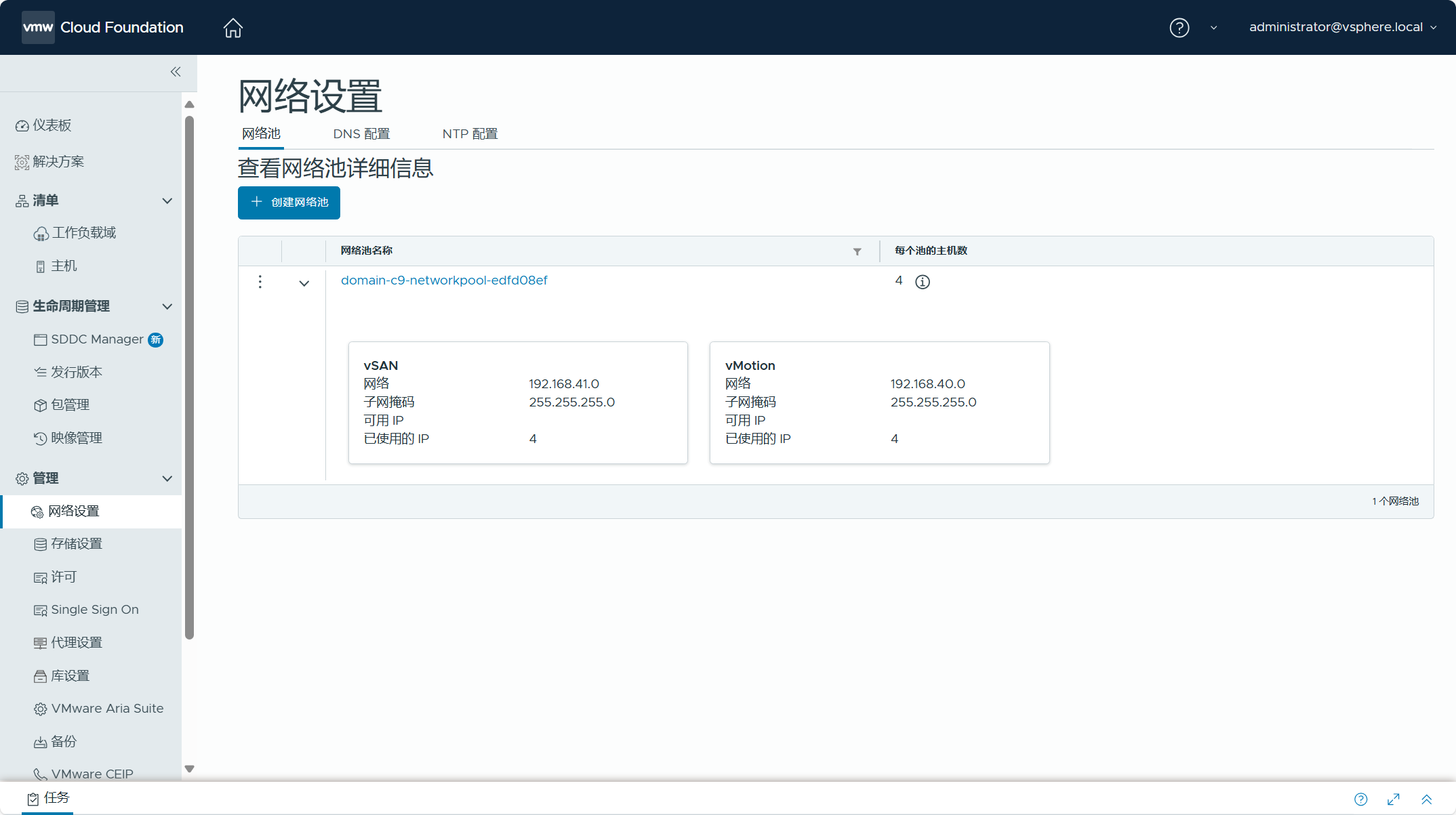
导航到 SDDC Manager UI->管理->许可,由于当前管理域中产品缺少许可证,可以点击“许可证密钥”为该域中的产品分配许可证密钥。
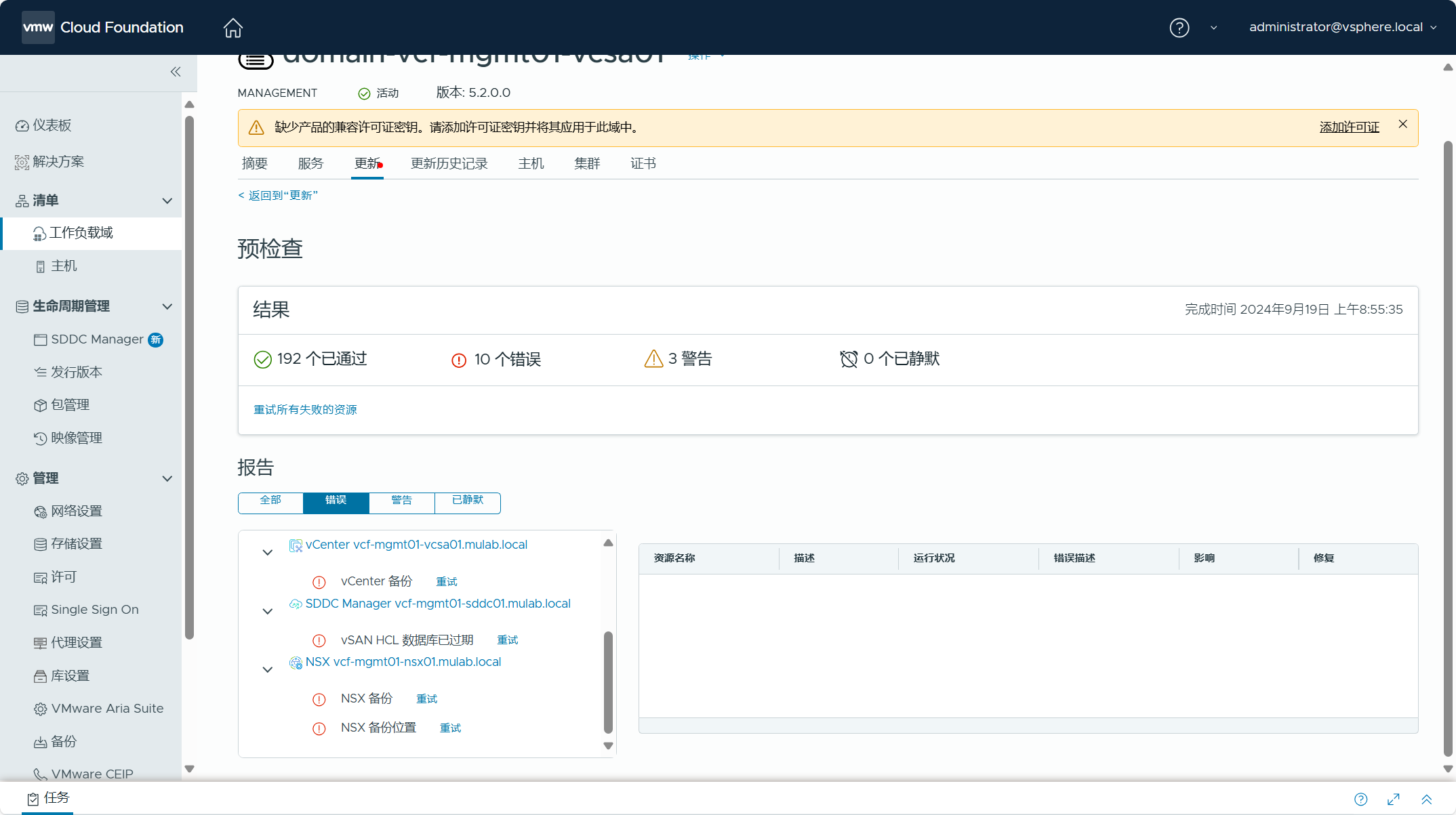
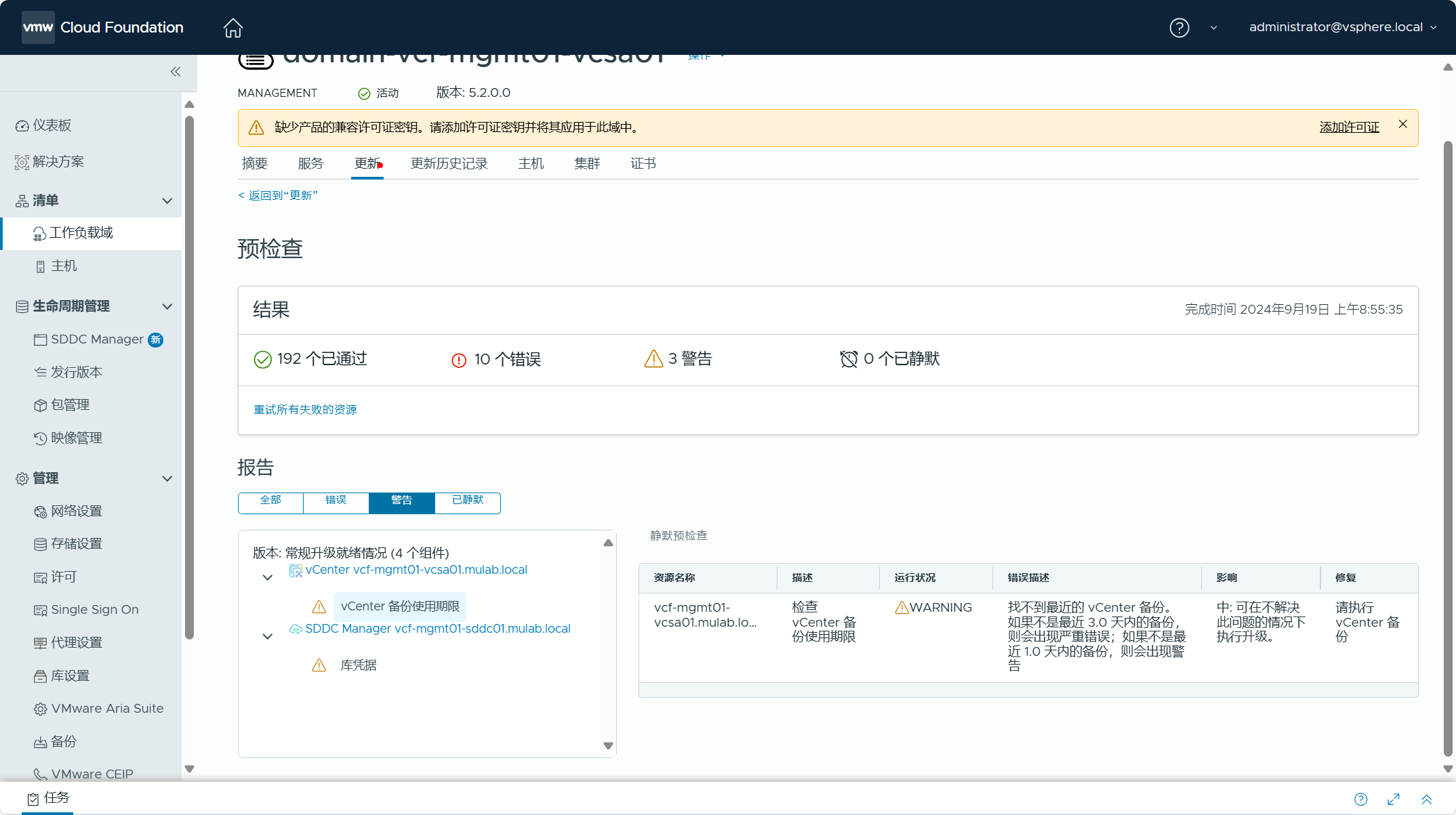
可以对管理域执行一下预检查,检查各个组件和配置是否正常。
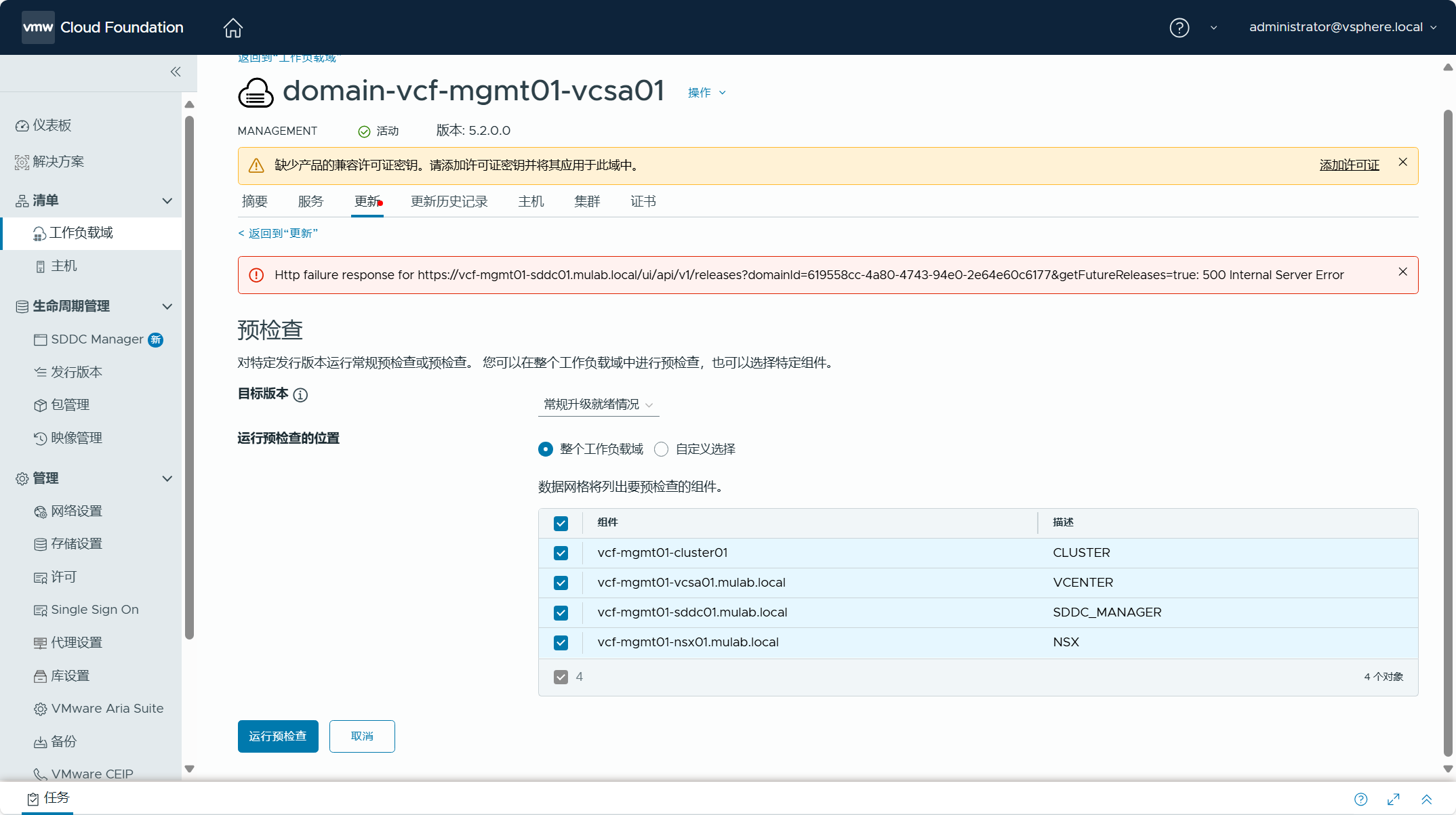
查看检查结果,可以看到有些错误和警告,这些都可以忽略,因为当前环境中确实还没有进行配置。
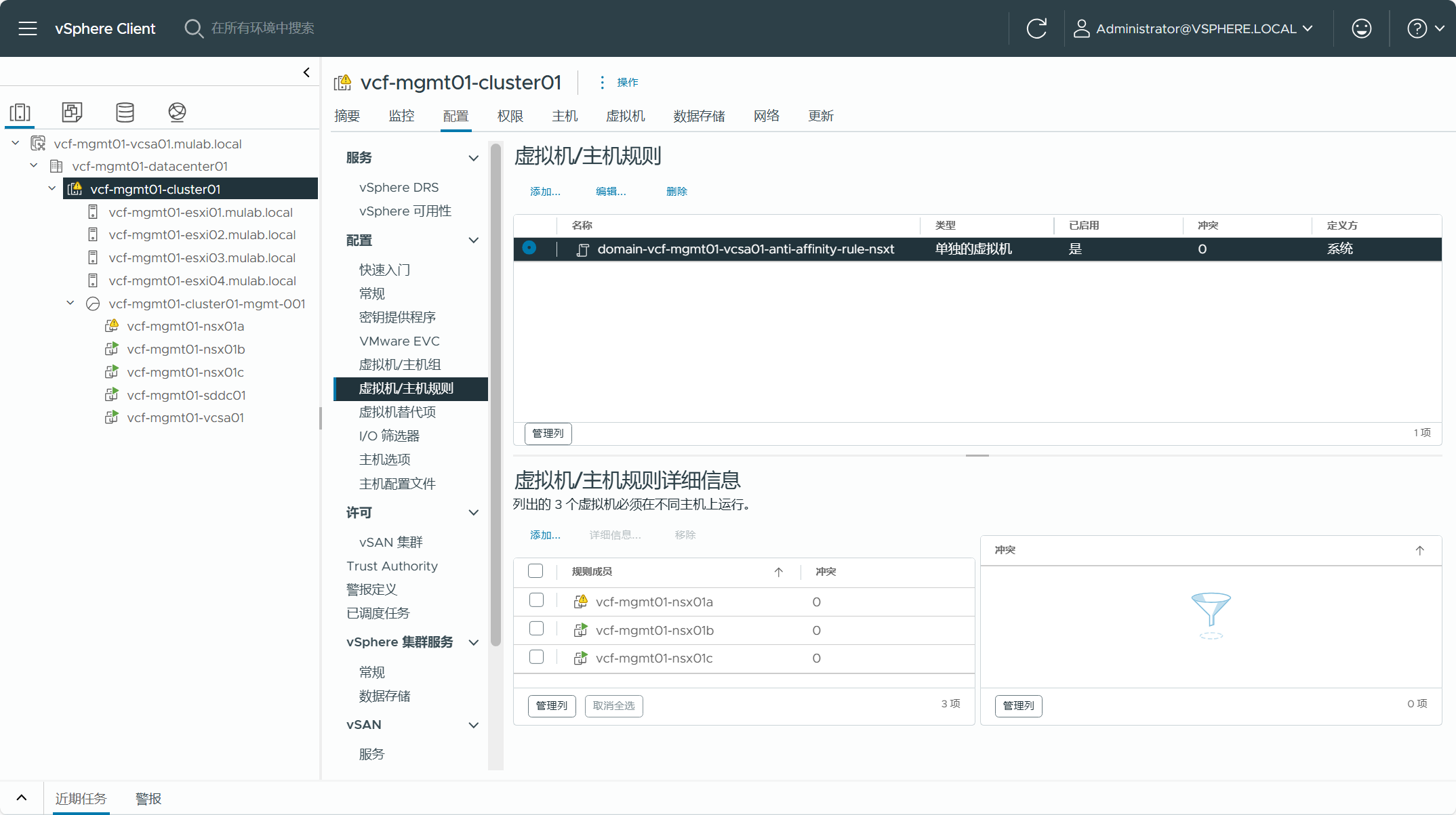
登录 vCenter Server(vSphere Client),可以看到三个 NSX Manager 设备已被部署到管理域集群当中,并且创建了虚拟机/主机关联性规则,三个虚拟机必须在不同的主机上运行,这就是为什么如果使用转换(Convert)将现有 vSphere 环境转换为管理域,如果没有使用 vSAN 解决方案,使用了 NFS 或者 FC SAN,如果要部署 NSX 的话就需要三台主机,如果不部署 NSX 的话可以只需要两台主机。
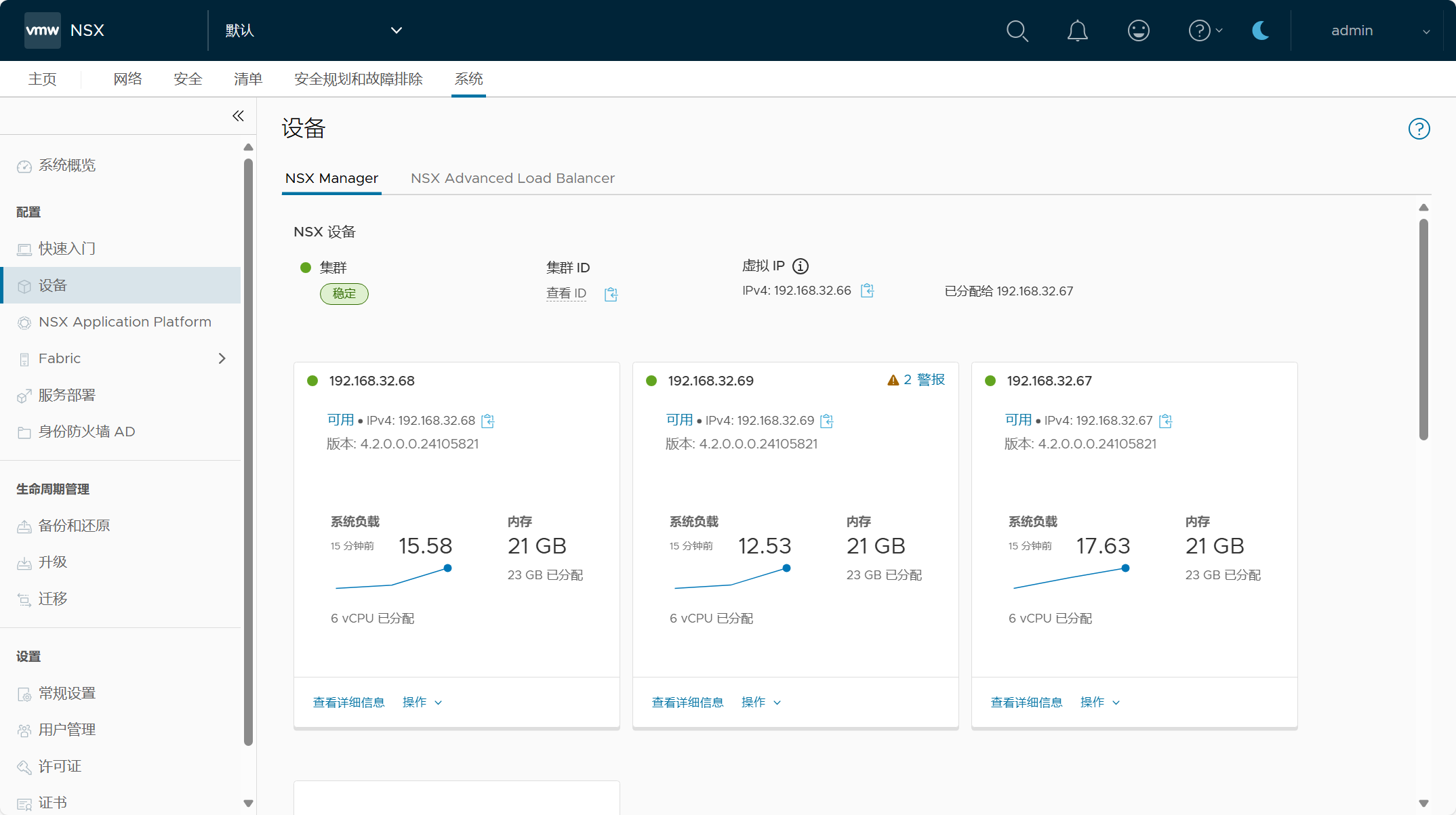
登录 NSX Manager UI(VIP),查看 NSX 系统配置概览。
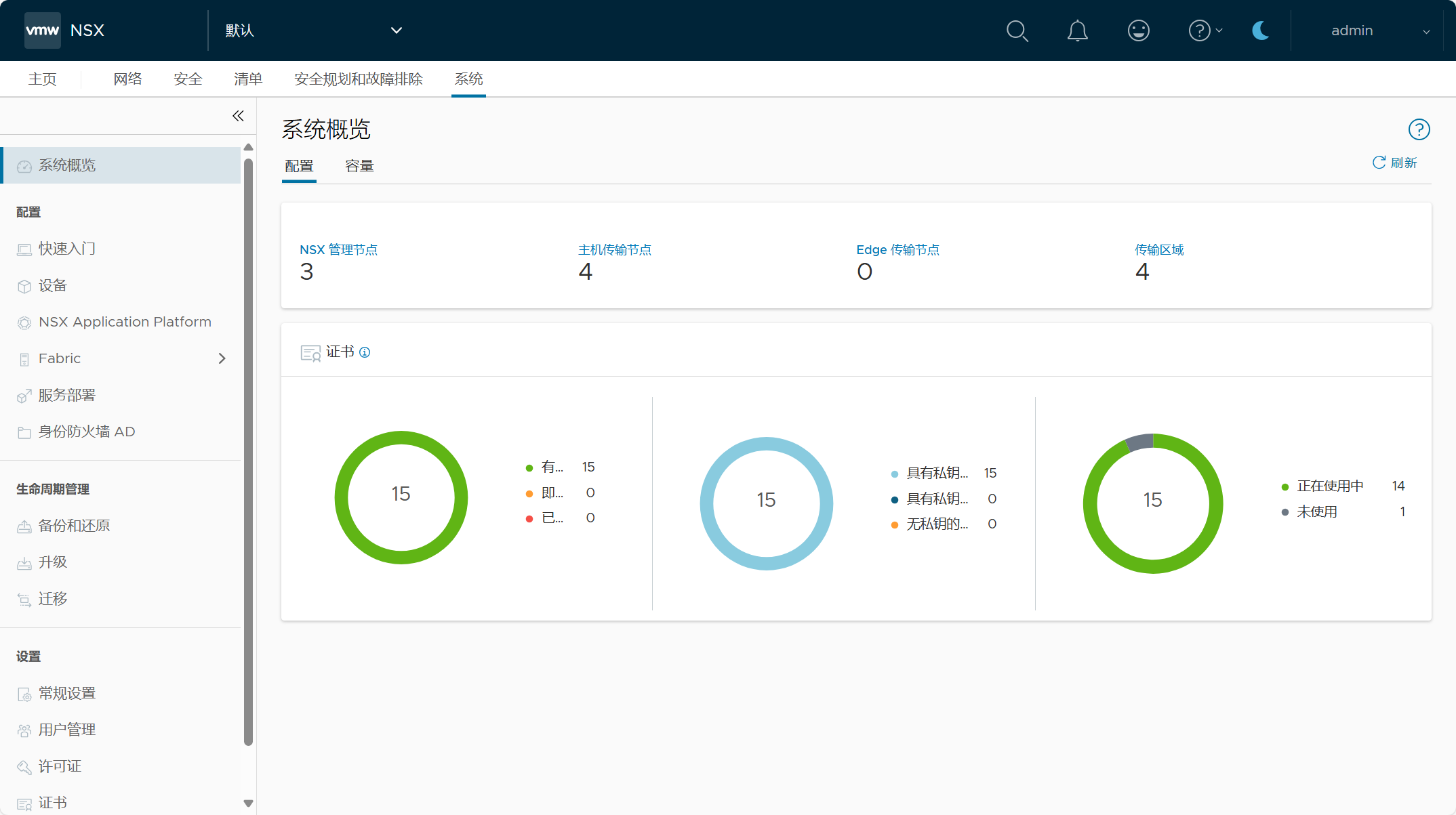
NSX 集群配置,一个由三节点 NSX Manager 所组成的 NSX 管理集群。
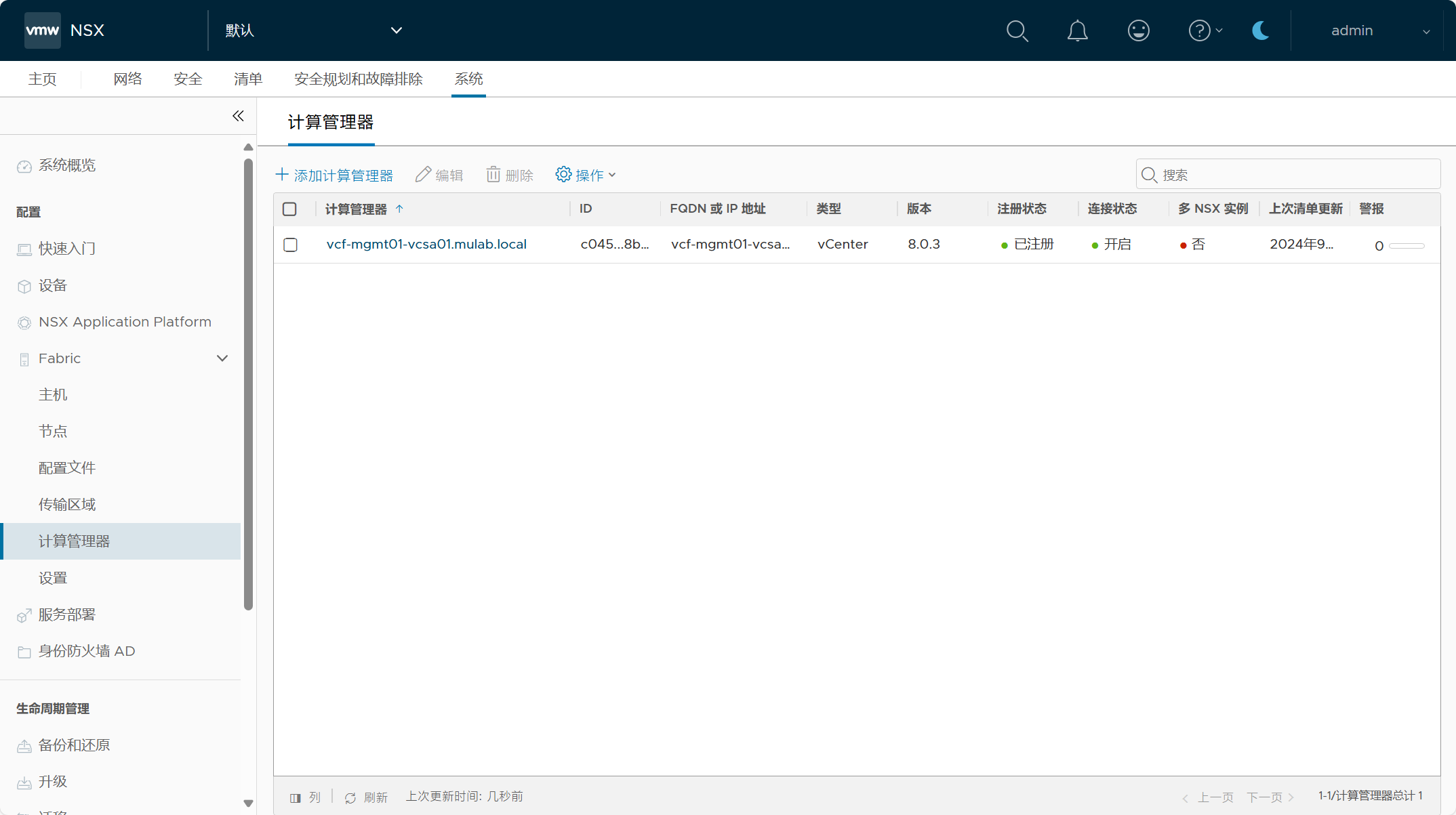
管理域 vCenter Server 已作为计算管理器被添加到 NSX 当中。
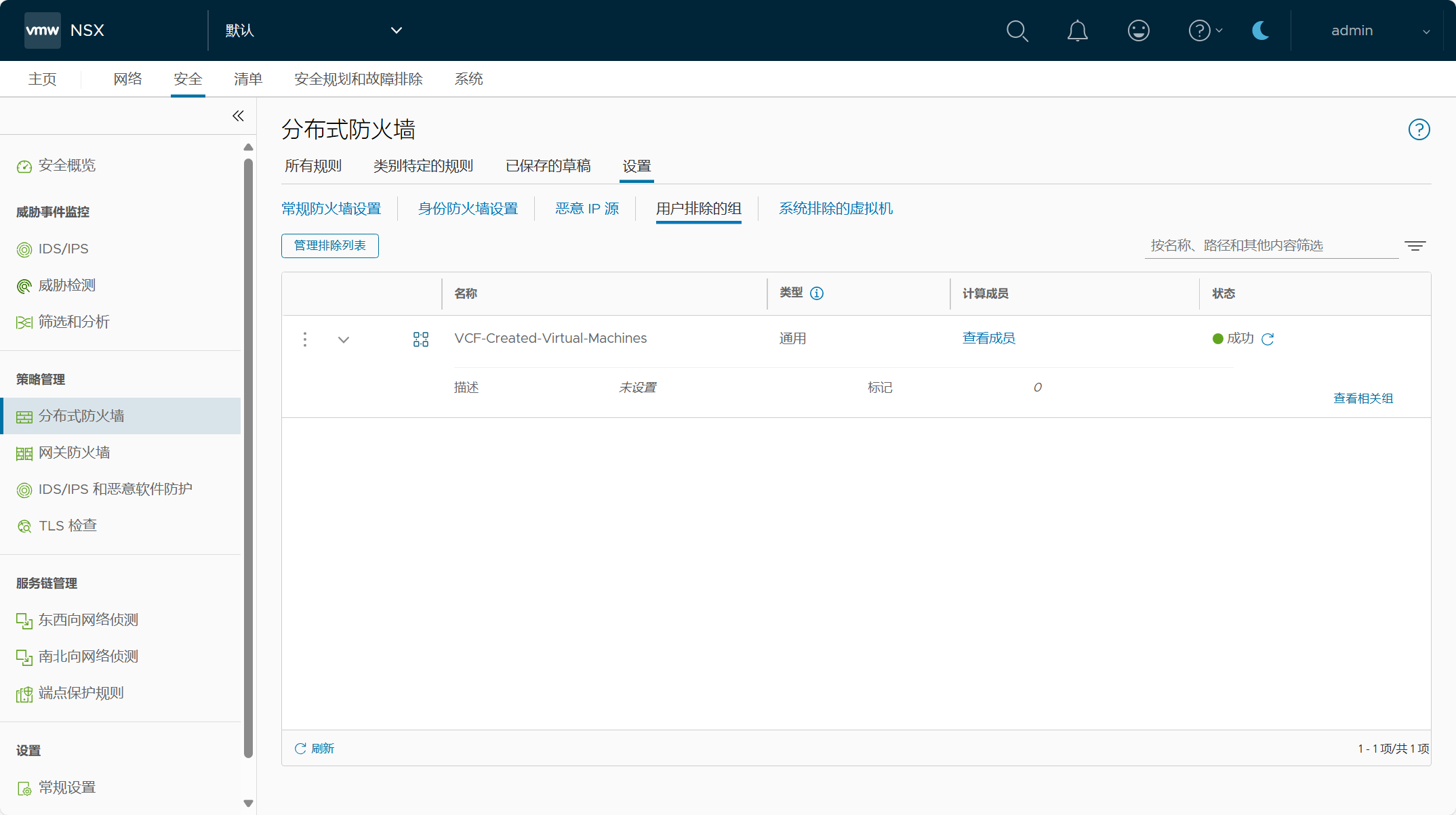
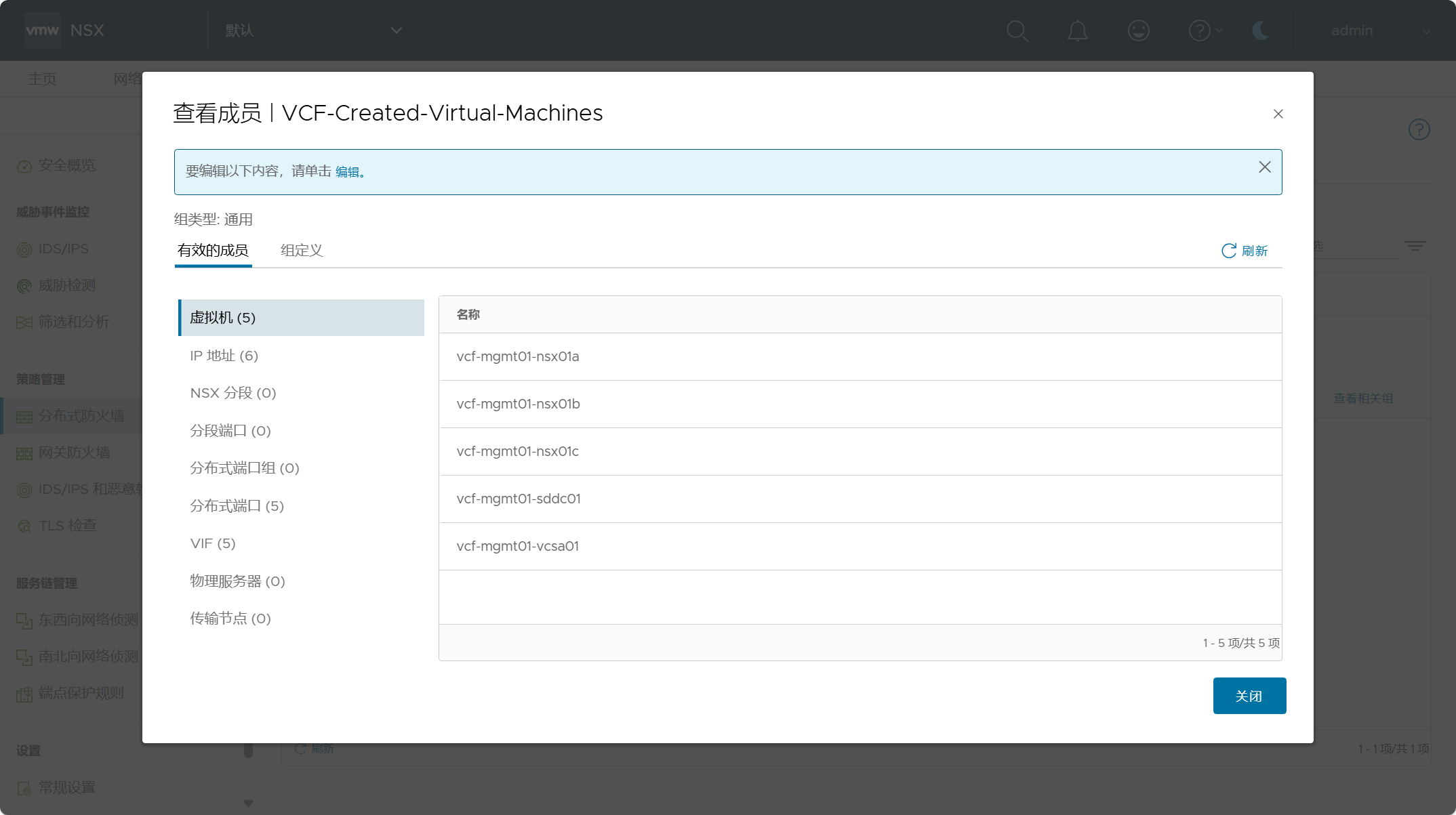
管理域集群中的主机已配置了分布式虚拟端口组(DVPG)的NSX,也就是 NSX-Security only 仅安全功能,也就是说可以将 NSX 的安全功能应用于管理域 vCenter Server 上连接至虚拟端口组的管理组件虚拟机。
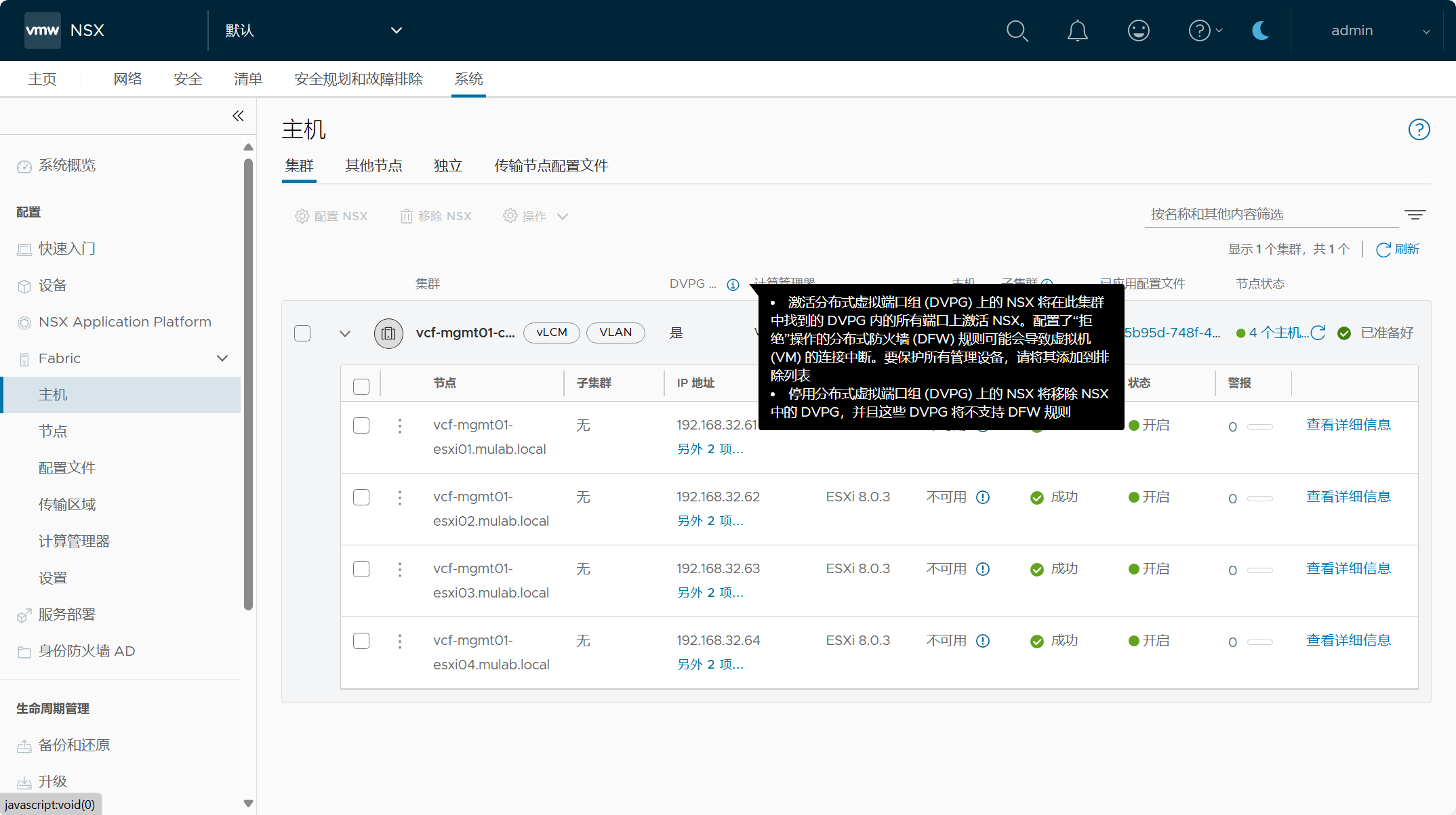
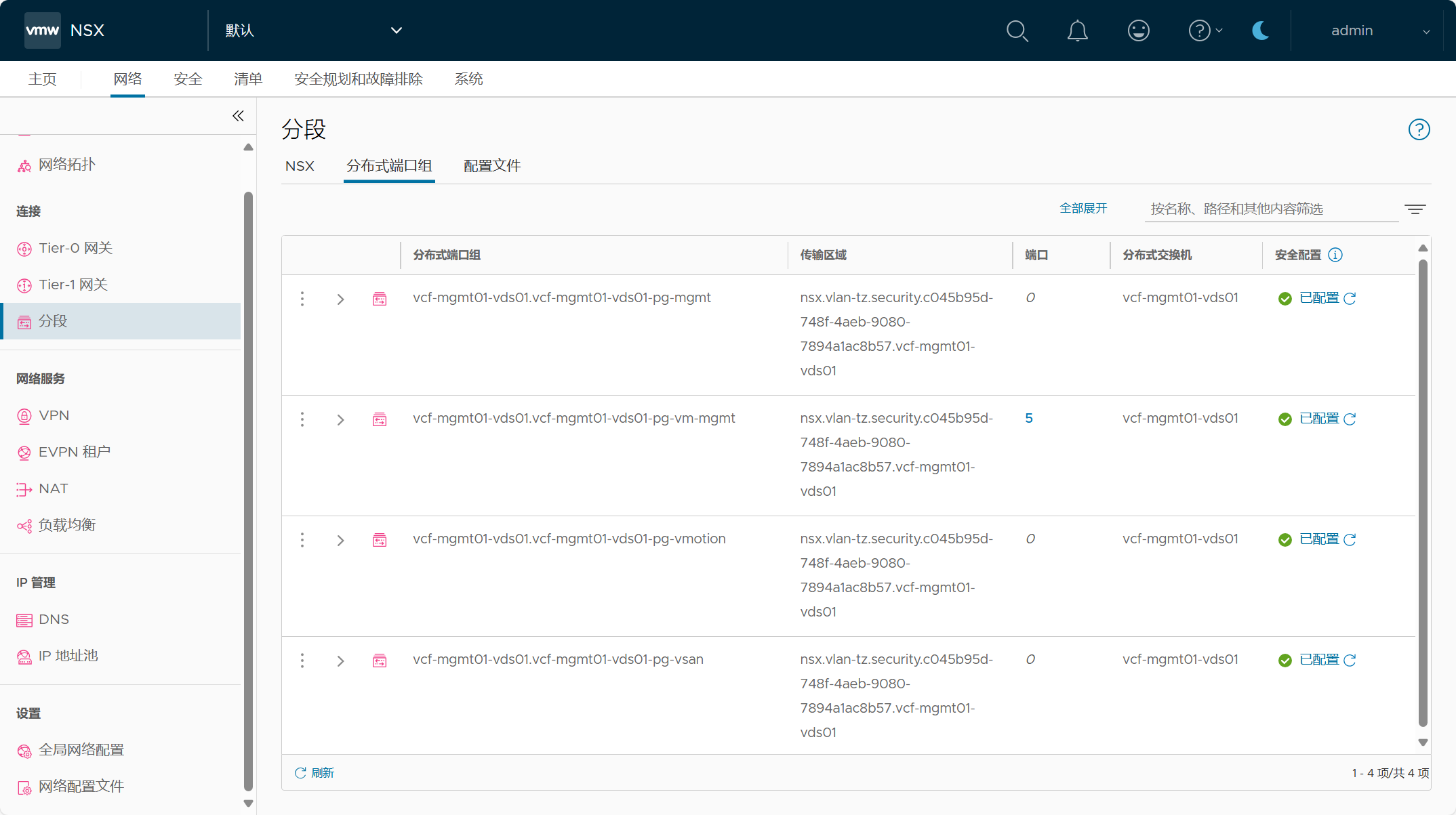
注意,在制定 NSX 安全策略之前,请确保将关键管理虚拟机列入白名单或进行排除,以避免出现锁定情况,你也可以为不是管理组件的虚拟机单独创建 DFW 排除列表。