(赠书)国产开源视觉语言模型CogVLM2在线体验:竟能识别黑悟空
CogVLM2是一款视觉语言模型(Visual Language Model),由智谱AI和清华KEG潜心打磨。这款模型是CogVLM的升级版本,支持高达 1344 * 1344 的图像分辨率,提供支持 中英文双语 的开源模型版本。
这类模型可以做很多跨领域的活儿,比如给图片配上描述文字、回答关于图片的问题(这叫VQA,就是视觉问答)、或者根据描述去找对应的图片等等。为了更好地完成这些任务,CogVLM2用了更高级的设计和技术,比如用更大的数据量来训练、更深的神经网络结构,还有更聪明的训练方法。
CogVLM 的进步主要归功于一个核心理念:“视觉优先”。以前的多模态模型常常把图像特征简单地放到和文本特征一样的层面上处理,而且用来处理图像的那部分通常比较简单,这样一来,图像就像是文本的“配角”,所以效果也就一般。而CogVLM则让视觉信息占据了更重要的位置。
环境准备
本地部署
CogVLM在Github上发布了开源的程序代码,可以做图片推理、视频推理,甚至进行模型的微调(不过GPU资源需求很大),Github地址:
https://github.com/THUDM/CogVLM2
建议使用Linux系统,搭配 NVIDIA GPU,显存最少需16G以上。
具体的安装使用方法,大家可以看官方的这篇介绍:
https://github.com/THUDM/CogVLM2/blob/main/basic_demo/README_zh.md
使用云环境
如果你本地没有足够的GPU资源,对编程也是一窍不通,或者只是想先看看效果,可以使用我打包的云平台镜像,一键启动,直接运行,不浪费时间。
云平台对新用户有一定的赠送额度,足够体验这个应用,平台注册地址:
仅体验图片推理,无需任何技术操作,请打开这个网址:
https://www.haoee.com/applicationMarket/applicationDetails?appId=39&IC=XLZLpI7Q

应用创建成功后,即可在“控制台”->“我的应用”中打开这个应用。

因为平台限制,如果还想使用API或者做视频推理,请打开这个网址:https://bbs.haoee.com/postDetail/656
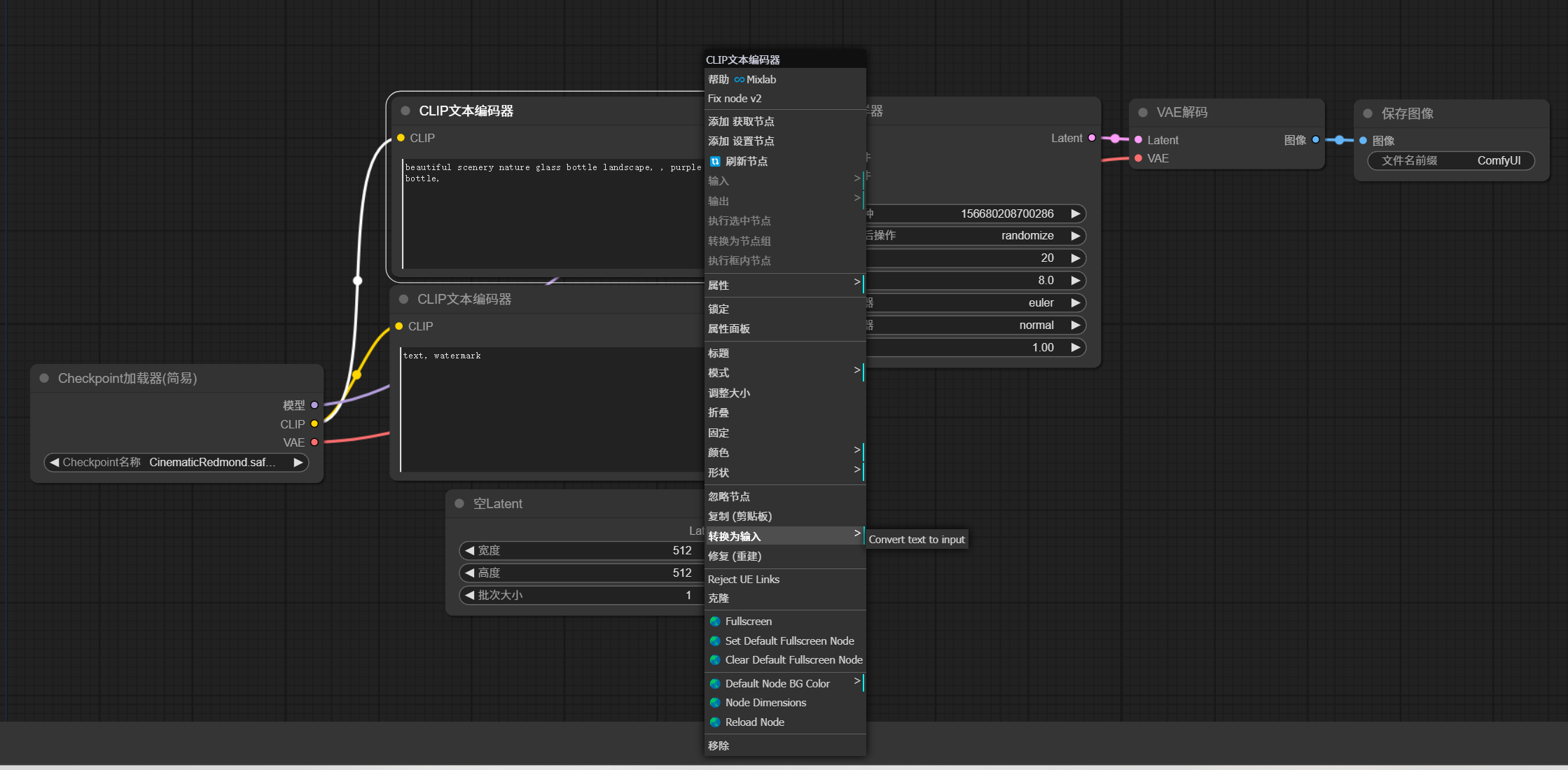
点击页面右下方的“创建实例”:

注意如果你要做视频推理,因为需要的资源比较多,这里需要选择2张卡才能跑的起来:

实例启动成功后,我们可以在“控制台”->“容器实例”中打开对应实例的 JupyterLab 交互工具。

在 JupyterLab 中可以在左边选择要使用的功能,右边启动应用,查看运行日志。

然后回到容器实例页面,点击“公网访问”获取对应程序的外网访问地址。
图片推理WebUI使用说明
1、容器实例启动成功后,在实例列表页面找到对应的实例,点击操作中的“JupyterLab”。

2、在打开的页面中点击“基础页面启动器”,然后继续点击页面中的重启按钮,启动对应的程序,如下图所示:

3、待程序启动成功后,回到实例列表页面,点击“公网访问”:

复制其中的第一个链接,然后在浏览器中打开。

4、在浏览器打开应用后,页面下方:
(1)首先上传一张图片;
(2)然后针对这张图片提出你的问题。
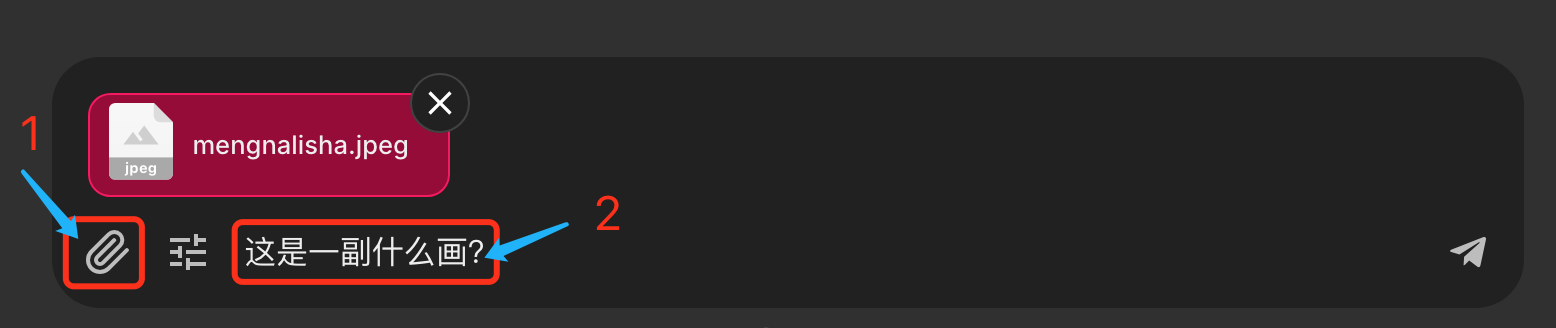
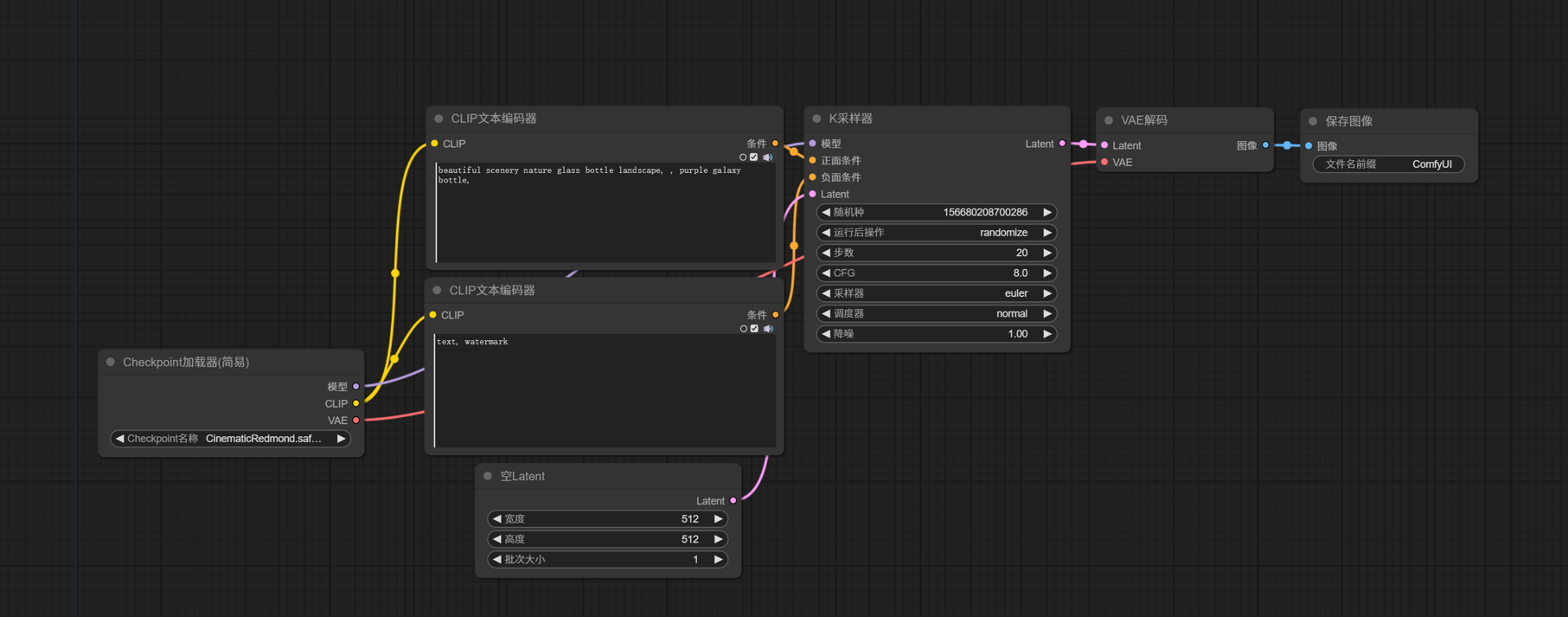
这里用黑悟空的一张照片来演示,效果如下:

如果要开启新的会话,请点击页面右上角的这个按钮:

图片推理API使用说明
1、容器实例启动成功后,在实例列表页面找到对应的实例,点击操作中的“JupyterLab”。

2、在打开的页面中点击“基础API启动器”,然后继续点击页面中的重启按钮,启动对应的程序,如下图所示:

3、待程序启动成功后,回到实例列表页面,点击“公网访问”:

其中的第2个链接就是API的访问地址。

访问API的代码请参考:
https://github.com/THUDM/CogVLM2/blob/main/basic_demo/openai_api_request.py
注意:图片推理API是单独的程序,使用单显卡时会关闭页面推理程序。如需同时启动,需要双显卡,并修改 CogVLM2/startup/start_basic_api.sh 中的 CUDA_VISIBLE_DEVICES=1。
视频推理使用说明
1、视频推理需要的显存比较多,在好易平台上需要2个4090D的显卡,所以创建实例的时候需要选择2卡,如下图所示:

2、容器实例启动成功后,在实例列表页面找到对应的实例,点击操作中的“JupyterLab”。

3、在打开的页面中点击“视频识别启动器”,然后继续点击页面中的重启按钮,启动对应的程序,如下图所示:

4、待程序启动成功后,回到实例列表页面,点击“公网访问”:

其中的两个连接分别提供了网页和API的访问地址。

5、在浏览器打开网页后,页面中:
(1)首先上传一个视频(1分钟以内的);
(2)然后针对这个视频提出你的问题。

6、使用视频推理API
参考代码如下,请注意替换其中的API地址和本地视频文件路径。
import requests
url = 'http://127.0.0.1:7861/video_qa'
video_file = "../resources/videos/lion.mp4"
question = "Describe this video in detail."
temperature=0.2
files = {'video': open(video_file, 'rb')}
data = {'question': question,'temperature': temperature}
response = requests.post(url, files=files, data=data)
print(response.json()["answer"])参加赠书活动
为了回馈各位读者,萤火君和机械工业出版社搞了一个赠书活动,就是下边这本机器学习四大名著之一的『机器学习实战』全新升级第3版!中文版豆瓣评分9.6!读者公认对入门和实践极其友好的机器学习书籍之一!

- 读者公认对入门和实践极其友好的机器学习书籍之一!
- 具体的示例+简单的理论+可用于生产环境的Python框架
- 帮助你直观地理解并掌握构建智能系统所需要的概念和工具
- 配备大量代码示例,帮助你学以致用!
想要领书的同学,请给公/众/号 “萤火遛AI” 发消息 “机器学习实战”,即可参与抽奖,9月9日上午10点开奖!