ComfyUI 基础教程(二) —— Stable Diffusion 文生图基础工作流及常用节点介绍
上一篇文章讲解述首次启动 ComfyUI 会自动打开一个最基础的文生图工作流。实际上,后续我们可以通过菜单选项,或者快捷键
ctrl + D
来打开这个默认工作流。默认工作流如下: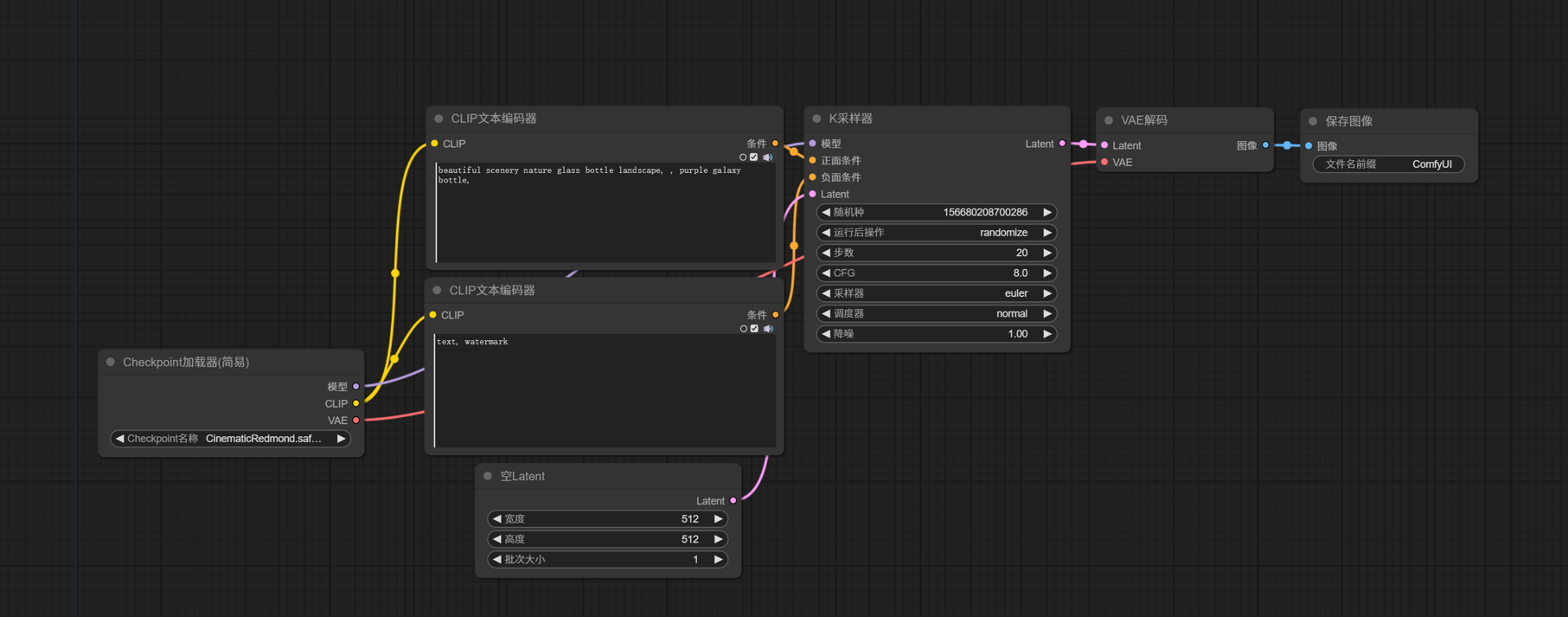
这是一个最基础的文生图工作流,本文通过对这个工作流的讲解,让大家对 ComfyUI 工作流有一个基本的认识。
一、文生图工作流核心节点
前面入坑铺垫这篇文章有推荐秋葉大佬的原理讲解视频,如果不了解也还没有看过的朋友,推荐去看看,传送门
B站秋葉大佬的视频
。
对原理有个大概了解的朋友应该知道,大模型是在潜空间处理图像的,人能识别的渲染出来的图片成为像素图。输入的条件信息,经过编码,传入潜空间,在潜空间里采样器去除噪波,最后在经过解码,输出像素图像。所以采样器是生成图片的最核心节点之一,下面就从采样器开始,依次介绍默认工作流中的节点。
1.1 【K采样器】
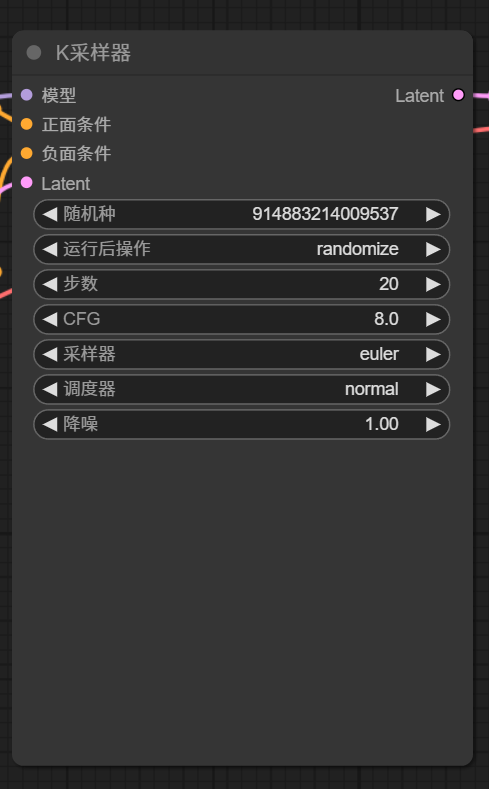
采样器节点有多种,默认工作流中d是最简单的
KSample
。下面说说 K采样器的参数:
- 随机种子:每生成一张图就会显示该图的数值,默认为 0;可选项有每次随机、固定、每次递增、每次递减。
- 步数:是指潜空间里的去除噪波迭代步数,一般设置为 25-40 左右。这个越大,所生成的图细节越多,但是生成图片需要的时间越长,并且一般超过 35 以后,则效果不是太明显,步数设置太小,则生成的图片一般质量越差。需要不断尝试,以确定每个大模型最适合的值。
- CFG: 提示词相关性。参数越大,图片效果越接近提示词。参数越小,AI 发挥空间越大,图片效果与提示词差异越大。一般设置在 10 左右就好,默认为 8。
- 采样器与调度器:采样器是与调度器结合一起使用的,采样器一般使用优化后/最新的采样器:euler_ancestral (简称 euler a)、dpmpp_2m 系列、dpmpp_3m 系列,调度器一般选择 normal 或 Karras
- 降噪:降噪:和步数有关系,1 就是我们 100% 的按照上方输入的步数去完成,0.1 就是 10%,一般不用懂,默认填 1 就行。
1.2 【主模型加载器】
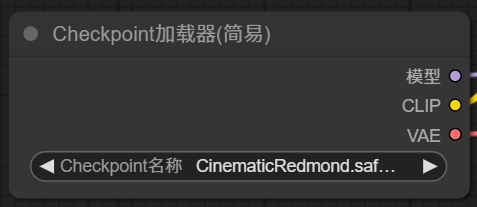
K采样器节点左边输入项,需要输入模型,所以需要添加一个主模型加载器,
Load Checkpoint
,。
主模型加载器只有一个参数,设置一个主模型。主模型的好坏决定了出图的整体质量,主要风格。
主模型加载器有三个输出项目,其中模型输出,就是 K 采样器的模型输入,需要把这两个点用线连接起来。
1.3 【Clip文本编码器】
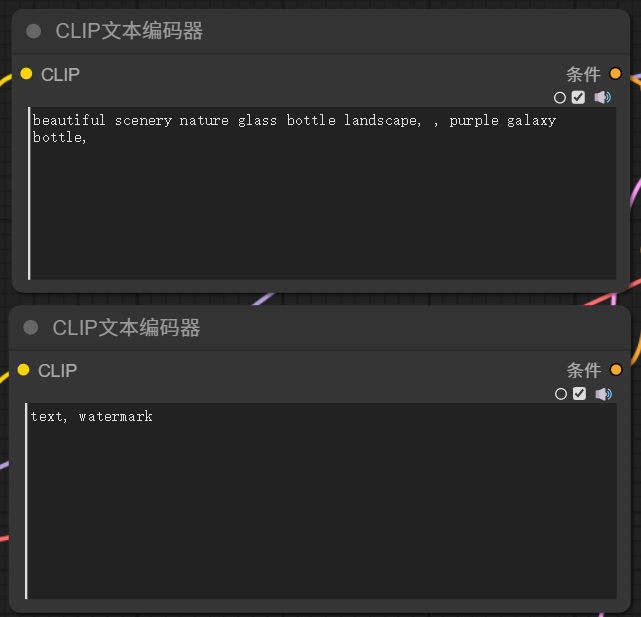
K采样器左边的输入项需要正面条件和负面条件,所谓的正面条件就是通过指令,告诉采样器,我要生成的图包含什么元素,负面条件就是通过指令告诉采样器,我要生成的图不包含什么样的元素。既然是文生图,当然是通过输入文字提示词发送指令,注意这里的提示词必须是英文,(英文水平不好的同学也不要着急,后面会讲解翻译节点)。但是,正常输入的文字,不能直接被采样器识别使用,需要经过编码,转换成采样器能识别的指令。这里就是通过
CLIP Text Encode (Prompt) conditioning
进行编码。这里的两个 Clip 文本编码器作用是一样的,文本编码器,需要针对模型配合使用的,所以这里它的输入端,应该连接到主模型输出项的 Clip 点。Clip 文本编码器输出的条件,分别连接到 K 采样器输入端的正面条件和负面条件。
1.4 【空 Latent】
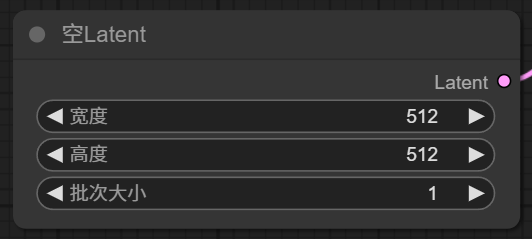
现在 K 采样器输入项还差一个 Latent, 这里有一个空 Latent 作为输入项。
Empty Latent Image
节点有三个参数,宽度、高度指定了潜空间生成图像的宽高,注意这里是单位是像素。批次大小,意思是一次生成多少张图片。
1.5 【VAE 解码】
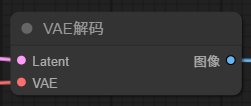
K 采样器的左边输入项和参数都填完了,那 K 采样器生成图片之后需要输出结果,前面提到,潜空间里的图像是数字信号的形式,需要经过解码,转换成像素图像,这里就需要用到
VAE Decode
。
VAE 解码器有两个输入项, Latent 输入点连接到 K 采样器的输出点。
另一个 AVE 用到的模型,一般主模型都嵌入了VAE模型,连接到主模型即可,默认工作流中,就是直接连接到主模型加载器输出项的VAE。当然也可以自己主动加载额外的 VAE 模型。
1.6 【保存图像】
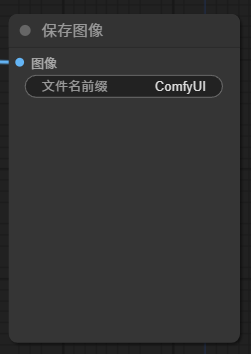
经过 VAE 解码后的图像,最后输出到
Save Image
节点可以预览,并保存。默认保存路径,在 ComfyUI 安装目录下的
output
文件夹,
该节点有一个参数,设置保存文件名的前缀。
二、ComfyUI 模型知识
2.1 模型后缀名的区别
模型的后缀名有很多。常见的有
.ckpt
、
.pt
、
.pth
、
.pkl
、
.safetensors
等。
CheckPoint 是一个概念,在模型训练过程中,不能保证一次就训练成功,中途可能会有各种因素导致失败,并且训练成功是一个伪概念,某些算法模型训练步数也不是越多越好,过多的训练会出现过拟合的情况。所以我们能做的是每训练一定的步数,保存一次训练结果,类似于存档。一方面使用某次训练的结果,觉得效果符合预期了,就可以停止训练了,最后将这个模型用于发布即可。另一方面,中途训练失败了,可以从某个 CheckPoint 继续开始训练。
.ckpt 是 checkpoint 的单词简写,仅仅是单词简写,不要认为 .ckpt 后缀的模型就是主模型,它俩没有关系。.ckpt 是 TensorFlow 中用于保存模型参数的格式。TensorFlow 是 Google 发布的深度学习框架。
.pt 是 PyTorch 保存模型参数的格式。PyTorch 是 Meta(facebook) 发布的深度学习框架。PyTorch 保存模型的格式,除了 .pt 之外还有.pth 和 .pkl。.pt 和 .pth 之间没有本质区别。而 .pkl 仅仅是多了一步使用 python 进行了序列化。
.safetensors 从名字可以看出,该格式更加安全。前面提到,可以从某个 CheckPoint 恢复训练,则需要在该 .ckpt 模型中保存了一些训练信息,比如模型的权重,优化器的状态,Python 代码等等,这就容易造成信息泄露,同时容易被植入恶意代码。所以 .ckpt 模型存在不安全因素,同时体积会比较大。.safetensors 是 huggingface 推出的新的模型存储格式,专门为 StableDiffusion 设计的,它只包含模型权重信息,模型体积更小,更加安全,加载速度也更快,通常用于模型的最终版本。而 .ckpt 模型适合用于对模型的微调、再训练。
2.2 模型的分类
ComfyUI 中用到的模型种类非常之多,为了方便理解和学习,我们可以对模型进行分类,大致可以分为以下几类:
1. checkpoint
主模型、大模型、底模、基础模型等。通过特定训练最终形成的一个保持该领域特征的一种综合算法合集,可以精准的匹配你的需求。比如摄影写实模型、3D模型、二次元模型、室内设计模型等等。Checkpoint 的训练难度大,需要的数据集大,生成的体积也较大,动则占用几个G的磁盘空间。
2. Lora
Lora 模型作为大模型的一种补充,能对生成的图片进行单一特征的微调,比如生成的人物图片具有相同的人脸特征、穿着特定服装、具备特定画风等等。Lora 模型体积较小,一般几十几百兆, 个人主机就可训练自己需要的 Lora 模型。
3. VAE
VAE 模型可以当作滤镜,目前针对 Stable Diffusion 主流的 VAE 模型有两个,二次元使用
kl-f8-anime2VAE
, 写实风格使用
vae-ft-mse-840000-ema-pruned
。
4. EMBEDDING
文本嵌入模型,应用于提示词中,是一类经过训练的提示词合集,主要用来提升画质,规避一些糟糕的画面。比如:
badhandv4
、
Bad_picture
、
bad_prompt
、
NG_Deep Negative
、
EasyNegative
,这些是经常用到的反向提示词嵌入模型,可以单独使用或者组合使用。
5. 其它
比如 controlnet模型、ipadapter模型、faceswap 模型、放大模型等等
对于 Stable Diffusion 的模型,现在也有了众多版本。常见版本有 SD1.5、SD2.0/2.1、 SDXL,其中 SDXL 模型生成的图片质量最高,相应地对硬件要求也相对高一点,而 SD1.5 生态最完善,这两个版本使用的最多。
需要强调的一点是:使用时,不同类型模型的版本需要对应上,比如主模型选择的是 SDXL 版本,Lora 使用 SD1.5 模型是无法正常运行的。
2.3 模型的存放路径
ComfyUI 的安装目录中有专门存放模型的文件夹。只需要将下载下来的模型放到对应的文件夹下。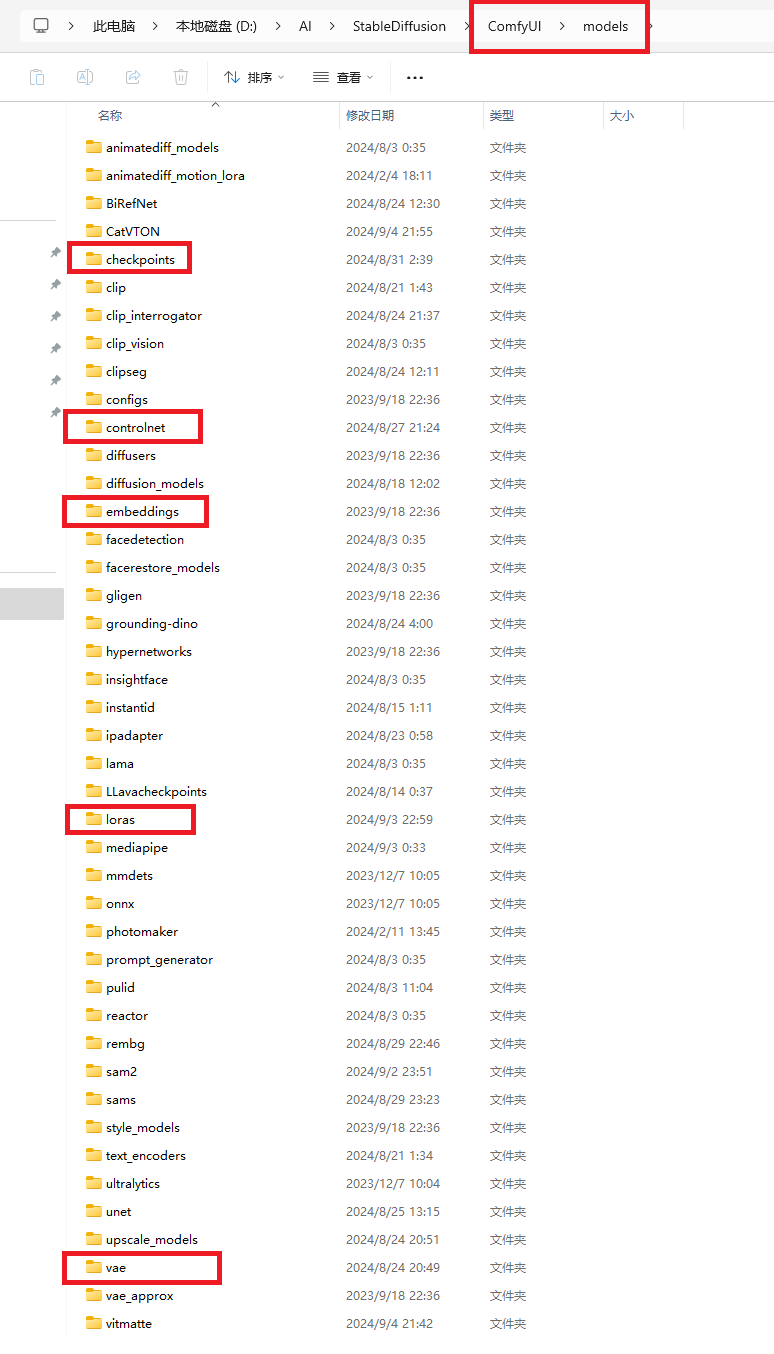
2.4 模型的下载地址
推荐两个主流的模型下载地址:
C 站:
https://civitai.com/
抱脸:
https://huggingface.co/
这两个网站中能下载到任何你想要的模型。
C 站查找模型可以过滤分类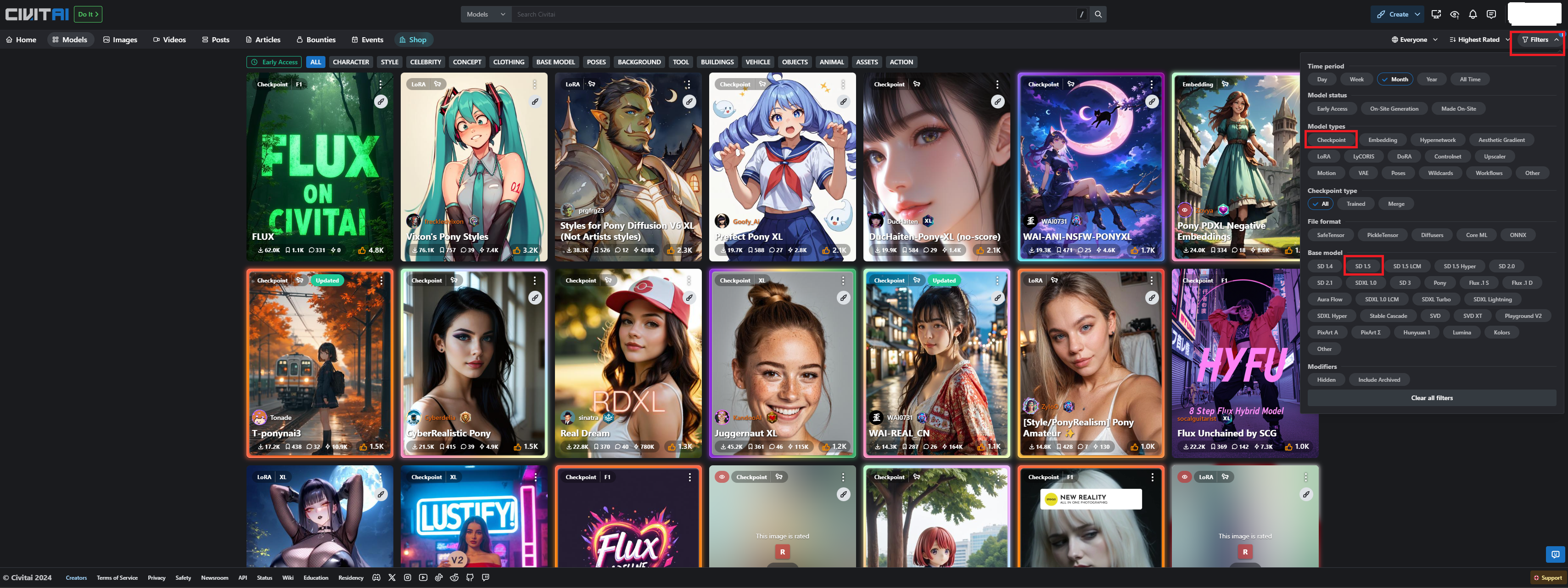
2.5 模型的架构
常见的的模型的架构分类:
Latent Diffusion 模型架构分类
| 文本编码 | 去噪扩散 | 编码解码 | 变体 | |
|---|---|---|---|---|
| SD1.5 | CLIP | UNET | VAE | |
| SDXL | ClipL/ClipG | UNET | VAE | Kolors/Pony/Playground |
| SD3 | ClipL/ClipG/T5 | Dit | VAE | DIT混元/AuraFlow/Flux |
SD 快速模型
| LCM | Turbo | Lightning |
|---|---|---|
| Latent Consistency Models 潜在一致性模型,清华大学研发的一款新一代生成模型,图像生成速度提升 5-10 倍,LCM-SD1.5、LCM-SDXL、LCM-Lora、Animatediff LCM、 SVD LCM | 官方在 SDXL1.0基础上采用了新的蒸馏方案,1-4 步就可以生成高质量图像,网络架构与 SDXL 一致。只适用于 SDXL, SD1.5无该类型模型 | 字节跳动在 SD1.0 基础上结合渐进式对抗蒸馏提炼出来的扩散蒸馏方法,本质上也是 SDXL 模型 |
关于模型架构的知识比较复杂,我也只是浅浅的了解。不懂这部分,对使用 ComfyUI 绘图影响不大,但是了解这些架构信息,对模型的兼容性方面会有一定的认识,有助于解决后面在使用过程中因模型版本、兼容性导致的问题。
三、其它常用节点简单介绍
插件的安装方法上一篇文章已经介绍过,不清楚的可以先去看看。
3.1 汉化插件 AIGODLIKE-COMFYUI-TRANSLATION
使用秋叶整合包,默认是安装了汉化节点的。作用是将菜单、设置等界面元素汉化。安装完汉化节点后,重启 ComfyUI ,然后再在设置中找到语言栏,切换为中文即可。
3.2 提示词翻译插件 ComfyUI_Custom_Nodes_AlekPet
前面提到,Clip 文本编码器需要输入英文提示词。如果英文不好,则可以安装提示词翻译插件。
使用方式:
鼠标放在 Clip 文本编码器节点上,右键 -> 转换为输入 -> Convert text to input。
将参数转换成输入节点。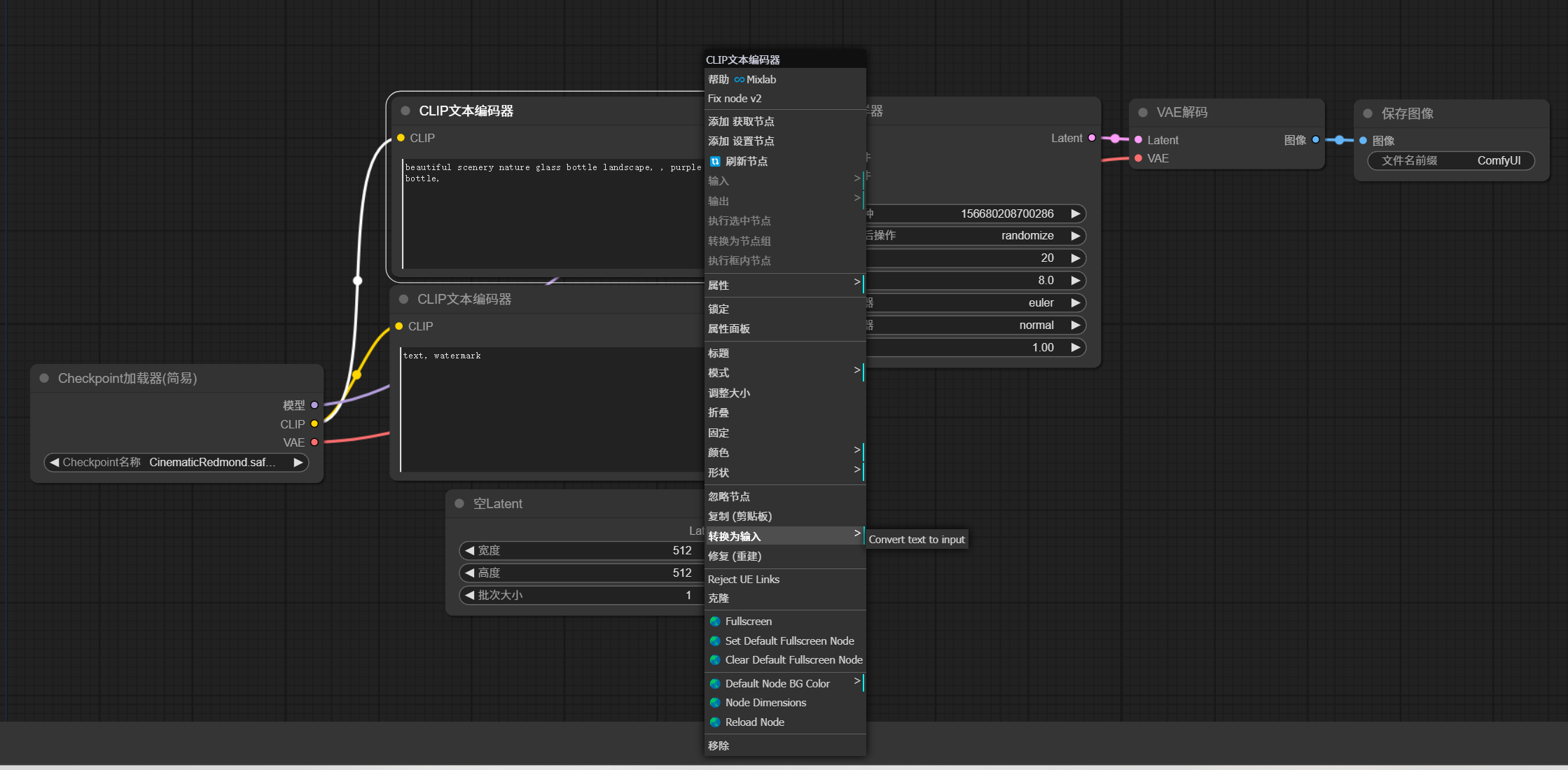
新建一个提示词翻译节点。
在空白处,右键 -> 新建节点 -> Alek 节点 -> 文本 -> 翻译文本(高级)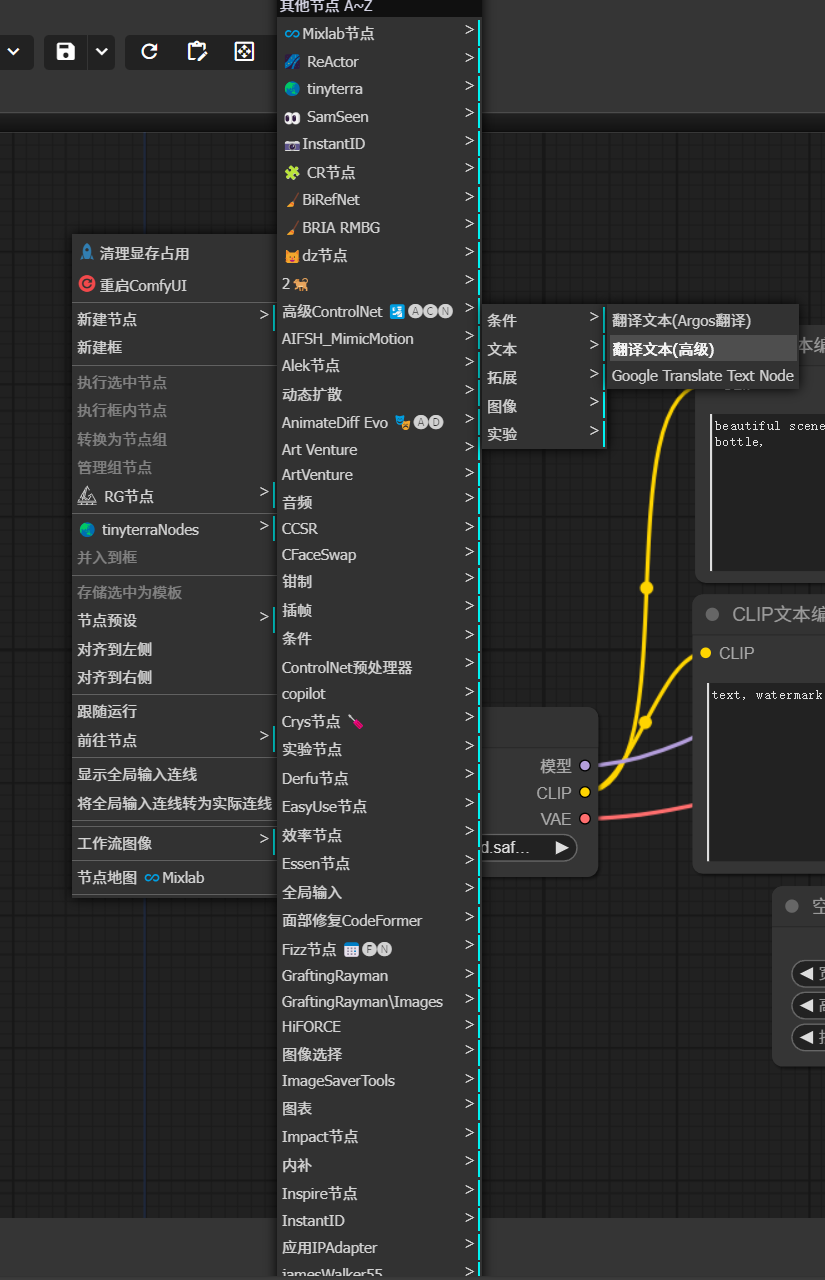
或者,在空白处双击左键,输入
tanslate
会自动匹配出节点,选择正确的节点。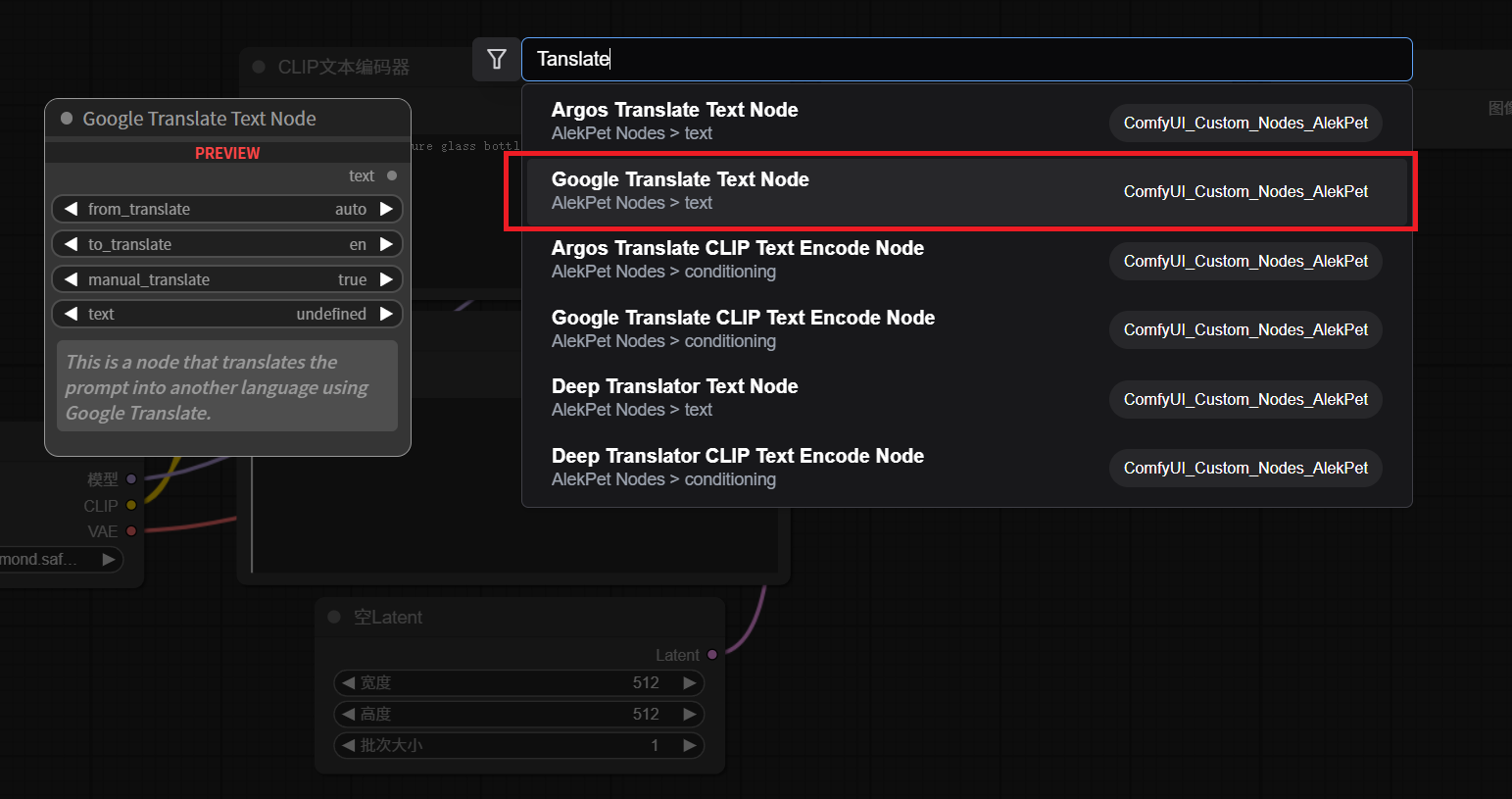
将提示词翻译节点与 Clip 文本编码器连接起来

这样我们就可以在在提示词翻译节点中填入中文提示词。需要注意的是,该提示词翻译插件使用的是 Google 翻译,需要外网环境。
使用技巧:
- 节点是可以复制粘贴的。比如需要对负面提示词添加同样的节点,直接复制一个就可以了。
3.3 元节点 primitive
图中分别表示小数、文本、布尔值、整数、多行文本。
元节点,简单来说就是把原始输入数据原封不动输出。那这样有什么作用呢,最典型的就是复用。
重要说明:一个节点的输入点只能有一个,但是输出点可以有多个。
使用技巧:
所有节点的参数和正向节点组件输入都是可以相互转化的。很多时候可以把相同的参数,转换为输入节点,然后用共同的元组件输入。
3.4 预览图像节点 Preview Image
前面说到保存图像节点,会自动保存到 output 文件夹下面,有时候我们只是想看看图片是什么样,并不想保存。比如中间过程的图片,或者不确定图片是否使我们想要的。这时候可以使用预览图像节点。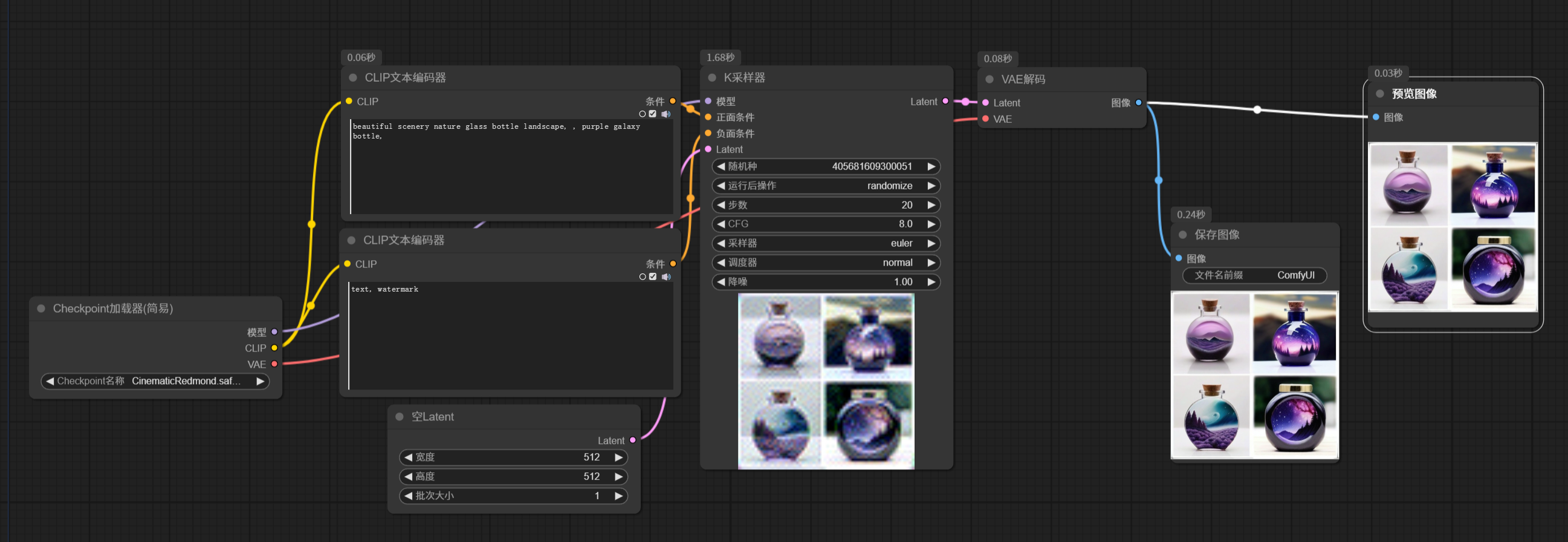
后记
本文从默认文生图工作流入手,介绍了其中的核心节点。同时介绍了 Stable Diffusion 中的模型分类。更多节点使用,将在后续文章中介绍,敬请关注。