DLA:动态层级注意力架构,实现特征图的持续动态刷新与交互 | IJCAI'24
论文深入探讨了层级注意力与一般注意力机制之间的区别,并指出现有的层级注意力方法是在静态特征图上实现层间交互的。这些静态层级注意力方法限制了层间上下文特征提取的能力。为了恢复注意力机制的动态上下文表示能力,提出了一种动态层级注意力(
DLA
)架构。
DLA
包括双路径,其中前向路径利用一种改进的递归神经网络块用于上下文特征提取,称为动态共享单元(
DSU
),反向路径使用这些共享的上下文表示更新特征。最后,注意力机制应用于这些动态刷新后的层间特征图。实验结果表明,所提议的
DLA
架构在图像识别和目标检测任务中优于其他最先进的方法。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Strengthening Layer Interaction via Dynamic Layer Attention

Introduction
众多研究强调了增强深度卷积神经网络(
DCNNs
)中层级间交互的重要性,这些网络在各种任务中取得了显著进展。例如,
ResNet
通过在两个连续层之间引入跳跃连接,提供了一种简单而高效的实现方式。
DenseNet
通过回收来自所有前置层的信息,进一步改善了层间交互。与此同时,注意力机制在
DCNNs
中的作用越来越重要。注意力机制在
DCNNs
中的演变经历了多个阶段,包括通道注意力、空间注意力、分支注意力以及时空注意力。
最近,注意力机制已成功应用于另一个方向(例如,
DIANet
、
RLANet
、
MRLA
),这表明通过注意力机制增强层间交互是可行的。与
ResNet
和
DenseNet
中简单的交互方式相比,引入注意力机制使得层间交互变得更加紧密和有效。
DIANet
在网络的深度上采用了一个参数共享的
LSTM
模块,以促进层间交互。
RLANet
提出了一个层聚合结构,用于重用前置层的特征,从而增强层间交互。
MRLA
首次引入了层级注意力的概念,将每个特征视为一个标记,通过注意力机制从其他特征中学习有用的信息。
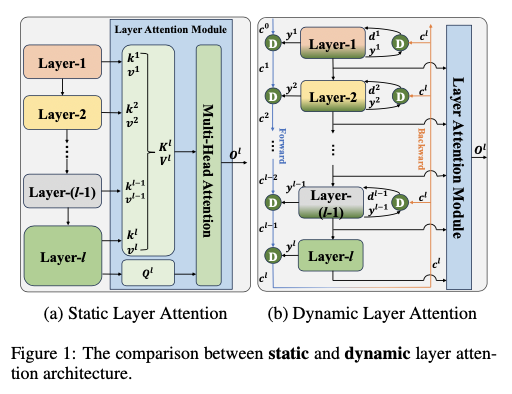
然而,论文发现现有的层级注意力机制存在一个共同的缺点:它们以静态方式应用,限制了层间信息交互。在通道和空间注意力中,对于输入
\(\boldsymbol{x} \in \mathbb{R}^{C \times H \times W}\)
,标记输入到注意力模块,所有这些标记都是从
\(\boldsymbol{x}\)
同时生成的。然而,在现有的层级注意力中,从不同时间生成的特征被视为标记并传入注意力模块,如图
1(a)
所示。由于早期生成的标记一旦产生就不会改变,因此输入的标记相对静态,这导致当前层与前置层之间的信息交互减少。
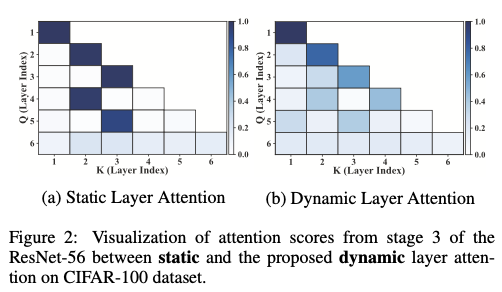
图
2(a)
可视化了在
CIFAR-100
上训练的
ResNet-56
的第
3
阶段的
MRLA
注意力分数。当前
5
层通过静态层级注意力重用来自前置层的信息时,只有一个特定层的关键值被激活,几乎没有其他层被分配注意力。这一观察验证了静态层级注意力削弱了层间信息交互的效率。
为了解决层级注意力的静态问题,论文提出了一种新颖的动态层级注意力(
DLA
)架构,以改善层间的信息流动,其中前置层的信息在特征交互过程中可以动态修改。如图
2(b)
所示,在重用前置层信息的过程中,当前特征的注意力从专注于某一特定层逐渐转变为融合来自不同层的信息。
DLA
促进了信息的更全面利用,提高了层间信息交互的效率。实验结果表明,所提的
DLA
架构在图像识别和目标检测任务中优于其他最先进的方法。
本文的贡献总结如下:
提出了一种新颖的
DLA
架构,该架构包含双路径,其中前向路径使用递归神经网络(
RNN
)提取层间的上下文特征,而后向路径则利用这些共享的上下文表示在每一层刷新原始特征。提出了一种新颖的
RNN
模块,称为动态共享单元(
DSU
),它被设计为
DLA
的适用组件。它有效地促进了
DLA
内部信息的动态修改,并且在逐层信息集成方面表现出色。
Dynamic Layer Attention
首先重新审视当前的层级注意力架构并阐明其静态特性,随后再介绍动态层级注意力(
DLA
),最后将呈现一个增强型
RNN
插件模块,称为动态共享单元(
DSU
),它集成在
DLA
架构中。
Rethinking Layer Attention
层级注意力由
MRLA
定义,并如图
1(a)
所示,其中注意力机制增强了层级间的交互。
MRLA
致力于降低层级注意力的计算成本,提出了递归层级注意力(
RLA
)架构。在
RLA
中,来自不同层的特征被视为标记并进行计算,最终产生注意力输出。
设第
\(l\)
层的特征输出为
\(\boldsymbol{x}^l \in \mathbb{R}^{C \times W \times H}\)
。向量
\(\boldsymbol{Q}^l\)
、
\(\boldsymbol{K}^l\)
和
\(\boldsymbol{V}^l\)
可以按如下方式计算:
\left\{
\begin{aligned}
\boldsymbol{Q}^l &= f^l_q(\boldsymbol{x}^l)\\
\boldsymbol{K}^l &= \text{Concat}\left[f^1_k(\boldsymbol{x}^1), \ldots, f^l_k(\boldsymbol{x}^l)\right] \\
\boldsymbol{V}^l &= \text{Concat}\left[f^1_v(\boldsymbol{x}^1), \ldots, f^l_v(\boldsymbol{x}^l)\right],
\end{aligned}
\right.
\end{equation}
\]
其中
\(f_q\)
是一个映射函数,用于从第
\(l\)
层提取信息,而
\(f_k\)
和
\(f_v\)
是相应的映射函数,分别用于从第
\(1\)
层到第
\(l\)
层提取信息。注意力输出
\(\boldsymbol{o}^l\)
的计算公式如下:
\begin{aligned}
\boldsymbol{o}^l &= \text{Softmax}\left(\frac{\boldsymbol{Q}^l (\boldsymbol{K}^l)^\text{T}}{\sqrt{D_k}}\right) \boldsymbol{V}^l \\
&=\sum^l_{i=1} \text{Softmax}\left(\frac{\boldsymbol{Q}^l \left[f_k^i(\boldsymbol{x}^i)\right]^\text{T}}{\sqrt{D_k}}\right) f_v^i(\boldsymbol{x}^i),
\end{aligned}
\end{equation}
\]
其中
\(D_k\)
作为缩放因子。
为了降低计算成本,轻量级版本的
RLA
通过递归方式更新注意力输出
\(\boldsymbol{o}^l\)
,具体方法如下:
\boldsymbol{o}^l = \boldsymbol{\lambda}_o^l \odot \boldsymbol{o}^{l-1} + \text{Softmax}\left(\frac{\boldsymbol{Q}^l \left[f_k^l(\boldsymbol{x}^l)\right]^\text{T}}{\sqrt{D_k}}\right) f_v^l(\boldsymbol{x}^l),
\end{equation}
\]
其中
\(\boldsymbol{\lambda}^{l}_o\)
是一个可学习的向量,
\(\odot\)
表示逐元素相乘。通过多头结构设计,引入了多头递归层级注意力(
MRLA
)。
Motivation
MRLA
成功地将注意力机制整合进层间交互中,有效地解决了计算成本问题。然而,当
MRLA
应用于第
\(l\)
层时,前面
\(m\)
层 ( $ m<l $ ) 已经生成了特征输出
\(\boldsymbol{x}^m\)
,且没有后续变化。因此,
MRLA
处理的信息包括来自前几层的固定特征。相比之下,广泛使用的基于注意力的模型,如通道注意力、空间注意力和
Transformers
,都会将生成的标记同时传递到注意力模块中。将注意力模块应用于新生成的标记之间,可以确保每个标记始终学习到最新的特征。因此,论文将
MRLA
归类为静态层注意力机制,限制了当前层与较浅层之间的交互。
在一般的自注意力机制中,特征
\(\boldsymbol{x}^m\)
有两个作用:传递基本信息和表示上下文。当前层提取的基本信息使其与其他层区分开来。同时,上下文表示捕捉特征沿时间轴的变化和演变,这是决定特征新鲜度的关键方面。在一般的注意力机制中,每一层都会生成基本信息,而上下文表示会转移到下一层以计算注意力输出。相比之下,在层注意力中,一旦生成标记,就会用固定的上下文表示计算注意力,这降低了注意力机制的效率。因此,本文旨在建立一种新方法来恢复上下文表示,确保输入层注意力的信息始终保持动态。
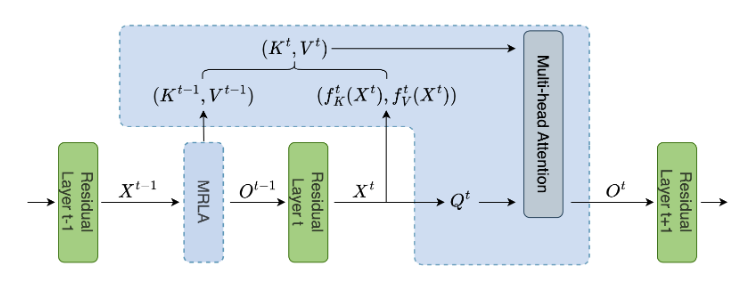
Dynamic Layer Attention Architecture
为了解决
MRLA
的静态问题,论文提出使用动态更新规则来提取上下文表示,并及时更新前面层的特征,从而形成了动态层注意力(
DLA
)架构。如图
1
(b) 所示,
DLA
包括两个路径:前向路径和后向路径。在前向路径中,采用递归神经网络(
RNN
)进行上下文特征提取。定义
RNN
块表示为
Dyn
,初始上下文表示为
\(\boldsymbol{c}^0\)
,其中
\(\boldsymbol{c}^0\)
被随机初始化。给定输入
\(\boldsymbol{x}^m \in \mathbb{R}^{ C\times W\times H}\)
,其中
\(m < l\)
,对
\(m\)
层应用全局平均池化(
GAP
)以提取全局特征,如下所示:
\boldsymbol{y}^m = \text{GAP}(\boldsymbol{x}^m),\ \boldsymbol{y}^m \in \mathbb{R}^{C}.
\end{equation}
\]
上下文表示的提取方式如下:
\boldsymbol{c}^m = \text{Dyn}(\boldsymbol{y}^m, \boldsymbol{c}^{m-1}; \theta^l).
\end{equation}
\]
其中,
\(\theta^l\)
表示
Dyn
的共享可训练参数。一旦计算出上下文
\(\boldsymbol{c}^l\)
,每一层的特征将在后向路径中同时更新,如下所示:
\left\{
\begin{aligned}
\boldsymbol{d}^m &= \text{Dyn}(\boldsymbol{y}^m, \boldsymbol{c}^l; \theta^l)\\
\boldsymbol{x}^m &\leftarrow \boldsymbol{x}^m \odot \boldsymbol{d}^m
\end{aligned}\right.
\end{equation}
\]
参考公式
5
,前向上下文特征提取是一个逐步过程,其计算复杂度为
\(\mathcal{O}(n)\)
。与此同时,公式
6
中的特征更新可以并行进行,计算复杂度为
\(\mathcal{O}(1)\)
。在更新
\(\boldsymbol{x}^m\)
后,
DLA
的基础版本使用公式
2
来计算层注意力,简称
DLA-B
。对于
DLA
的轻量级版本,简单地更新
\(\boldsymbol{o}^{l-1}\)
,然后使用公式
3
来获得
DLA-L
。
Computation Efficiency
DLA
在结构设计上具有几个优点:
- 全局信息被压缩以计算上下文信息,这一功能已经在
Dianet
中得到验证。 DLA
在
RNN
模块内使用了共享参数。- 上下文
\(\boldsymbol{c}^l\)
在每一层中以并行的方式单独输入到特征图中,前向和后向路径在整个网络中共享相同的参数并引入了一个高效的
RNN
模块用于计算上下文表示。
通过这些高效设计的结构规则,计算成本和网络容量得到了保障。
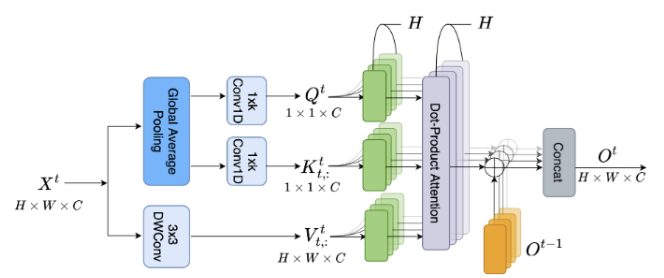
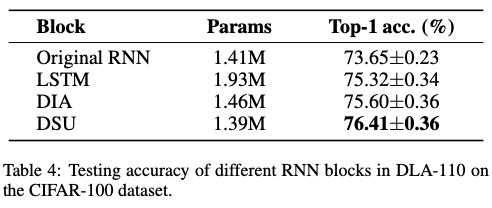
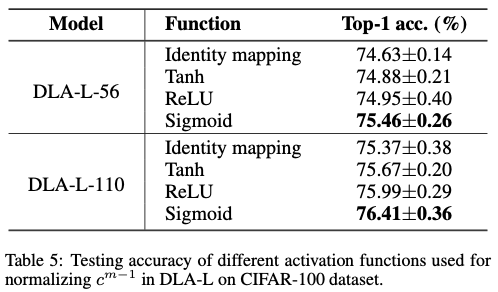
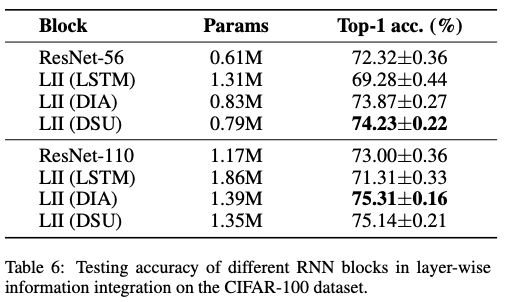
Dynamic Sharing Unit
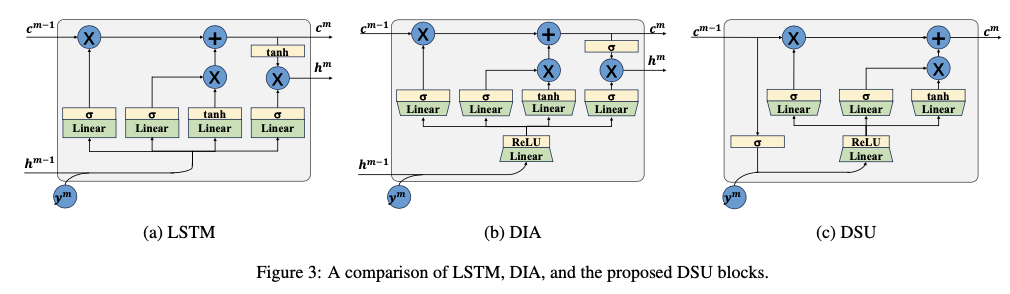
LSTM
,如图
3(a)
所示,设计用于处理序列数据和学习时间特征,使其能够捕捉和存储长序列中的信息。然而,在将
LSTM
嵌入
DLA
作为递归块时,
LSTM
中的全连接线性变换显著增加了网络容量。为了缓解这种容量增加,
Dianet
提出了一种变体
LSTM
块,称为
DIA
单元,如图
3(b)
所示。在将数据输入网络之前,
DIA
首先利用线性变换和
ReLU
激活函数来降低输入维度。此外,
DIA
在输出层将
Tanh
函数替换为
Sigmoid
函数。
LSTM
和
DIA
生成两个输出,包括一个隐藏向量
\(\boldsymbol{h}^m\)
和一个
cell
状态向量
\(\boldsymbol{c}^m\)
。通常,
\(\boldsymbol{h}^m\)
用作输出向量,而
\(\boldsymbol{c}^m\)
作为记忆向量。
DLA
专注于从不同层中提取上下文特征,其中
RNN
模块不需要将其内部状态特征传递到外部。因此,论文舍弃了输出门,并通过省略
\(\boldsymbol{h}^m\)
来合并记忆向量和隐藏向量。
论文提出的简化
RNN
模块被称为动态共享单元(
Dynamic Sharing Unit
,
DSU
),工作流程如图
3(c)
所示。具体而言,在添加
\(\boldsymbol{c}^{m-1}\)
和
\(\boldsymbol{y}^m\)
之前,首先使用激活函数
\(\sigma(\cdot)\)
对
\(\boldsymbol{c}^{m-1}\)
进行归一化。在这里,选择
Sigmoid
函数 (
\(\sigma(z) = 1 /(1 + e^{-z})\)
)。因此,
DSU
的输入被压缩如下:
\boldsymbol{s}^m = \text{ReLU}\left(\boldsymbol{W}_1\left[ \sigma(\boldsymbol{c}^{m-1}), \boldsymbol{y}^m \right] \right).
\end{equation}
\]
隐藏变换、输入门和遗忘门可以通过以下公式表示:
\left\{
\begin{aligned}
\boldsymbol{\tilde{c}}^m &= \text{Tanh}(\boldsymbol{W}_2^c \cdot \boldsymbol{s}^m + b^c) \\
\boldsymbol{i}^m &= \sigma(\boldsymbol{W}_2^i \cdot \boldsymbol{s}^m + b^i ) \\
\boldsymbol{f}^m &= \sigma(\boldsymbol{W}_2^f \cdot \boldsymbol{s}^m + b^f )
\end{aligned}
\right.
\end{equation}
\]
随后,得到
\boldsymbol{c}^m = \boldsymbol{f}^m \odot \boldsymbol{c}^{m-1} + \boldsymbol{i}^m \odot \boldsymbol{\tilde{c}}^m
\end{equation}
\]
为了减少网络参数,令
\(\boldsymbol{W}_1\in \mathbb{R}^{\frac{C}{r}\times 2C}\)
和
\(\boldsymbol{W}_2\in \mathbb{R}^{C\times \frac{C}{r}}\)
,其中
\(r\)
是缩减比率。
DSU
将参数减少到
\(5C^2/r\)
,比
LSTM
的
\(8C^2\)
和
DIA
的
\(10C^2/r\)
更少。
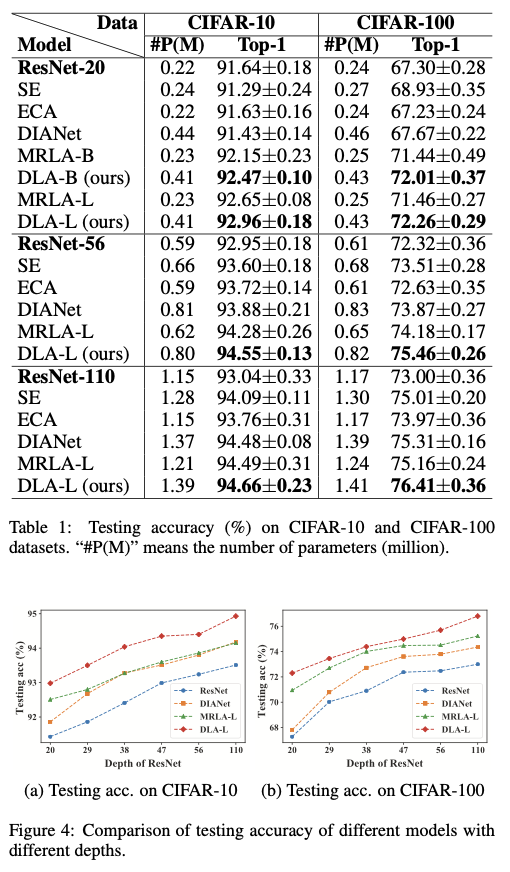
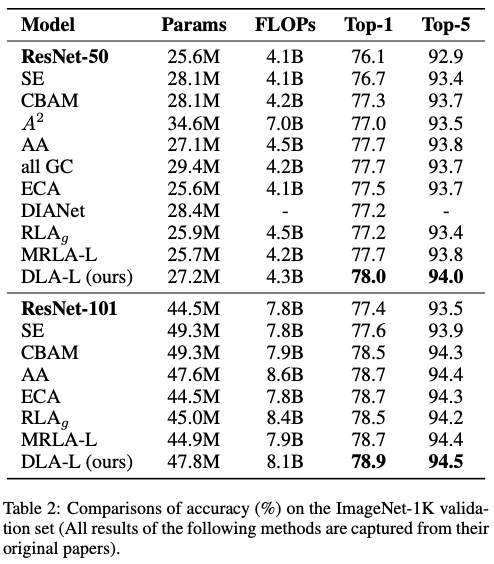
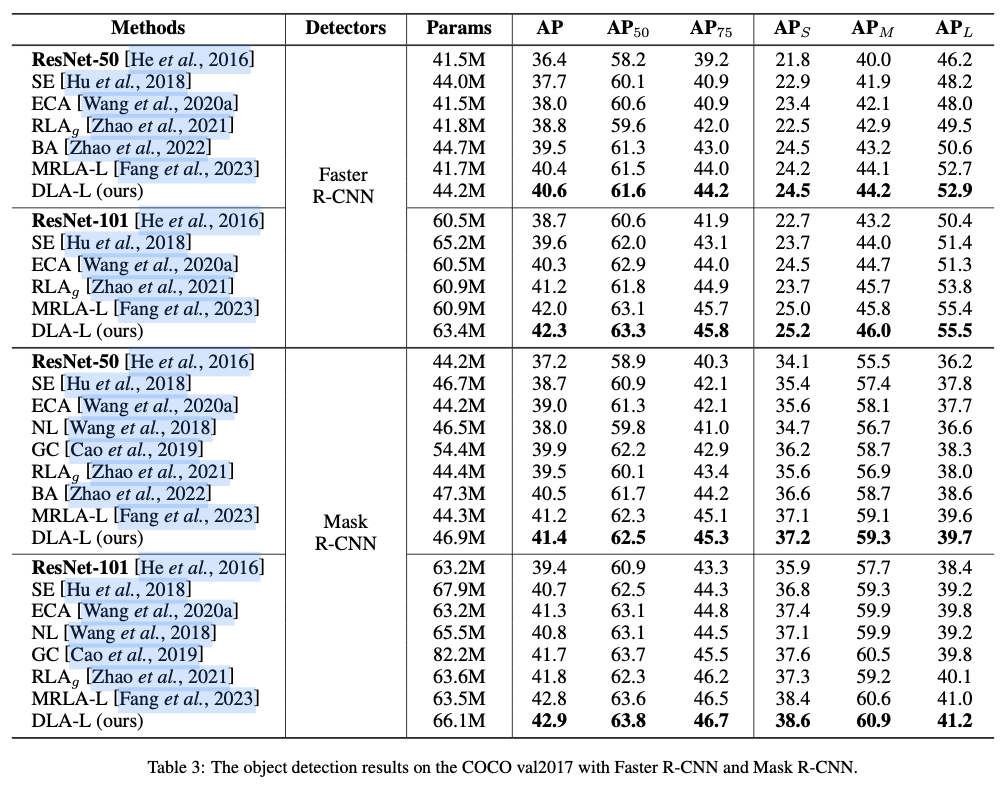
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
