有时需要将MySQL数据库中的数据导出到外部存储文件中,MySQL数据库中的数据可以导出成sql文本文件、xml文件或者html文件。本节将介绍数据导出的常用方法。
11.4.1 使用SELECT…INTO OUTFILE导出文本文件
MySQL数据库导出数据时,允许使用包含导出定义的SELECT语句进行数据的导出操作。该文件被创建到服务器主机上,因此必须拥有文件写入权限(FILE权限)才能使用此语法。“SELECT...INTO OUTFILE 'filename'”形式的SELECT语句可以把被选择的行写入一个文件中,并且filename不能是一个已经存在的文件。SELECT...INTO OUTFILE语句的基本格式如下:
SELECT columnlist FROM table WHERE condition INTO OUTFILE 'filename' [OPTIONS]
可以看到SELECT columnlist FROM table WHERE condition为一个查询语句,查询结果返回满足指定条件的一条或多条记录;INTO OUTFILE语句的作用就是把前面SELECT语句查询出来的结果,导出到名称为“filename”的外部文件中;[OPTIONS]为可选参数选项,OPTIONS部分的语法包括FIELDS和LINES子句,其可能的取值如下:
FIELDS TERMINATED BY 'value':设置字段之间的分隔字符,可以为单个或多个字符,默认情况下为制表符(\t)。
FIELDS [OPTIONALLY] ENCLOSED BY 'value':设置字段的包围字符,只能为单个字符,若使用了OPTIONALLY关键字,则只有CHAR和VERCHAR等字符数据字段被包围。
FIELDS ESCAPED BY 'value':设置如何写入或读取特殊字符,只能为单个字符,即设置转义字符,默认值为“\”。
LINES STARTING BY 'value':设置每行数据开头的字符,可以为单个或多个字符,默认情况下不使用任何字符。
LINES TERMINATED BY 'value':设置每行数据结尾的字符,可以为单个或多个字符,默认值为“\n”。
FIELDS和LINES两个子句都是自选的,但是如果两个都被指定了,则FIELDS必须位于LINES的前面。
使用SELECT...INTO OUTFILE语句,可以非常快速地把一张表转储到服务器上。如果想要在服务器主机之外的部分客户主机上创建结果文件,不能使用SELECT...INTO OUTFILE,应该使用“MySQL –e "SELECT ..." > file_name”这类的命令来生成文件。
SELECT...INTO OUTFILE是LOAD DATA INFILE的补语,用于语句的OPTIONS部分的语法包括部分FIELDS和LINES子句,这些子句与LOAD DATA INFILE语句同时使用。
【例11.10】使用SELECT...INTO OUTFILE将test_db数据库中的person表中的记录导出到文本文件,SQL语句如下:
mysql> SELECT * FROM test_db.person INTO OUTFILE 'D:/person0.txt';
语句执行后报错信息如下:
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
这是因为MySQL默认对导出的目录有权限限制,也就是说使用命令行进行导出的时候,需要指定目录。那么指定的目录是什么呢?
查询指定目录的命令如下:
show global variables like '%secure%';
执行结果如下:
+-------------------------+-----------------------------------------------+
| Variable_name | Value |
+-------------------------+-----------------------------------------------+
|require_secure_transport | OFF |
|secure_file_priv | D:\ProgramData\MySQL\MySQL Server 9.0\Uploads\|
+-------------------------+-----------------------------------------------+
因为secure_file_priv配置的关系,所以必须导出到D:\ProgramData\MySQL\MySQL Server 9.0\Uploads\目录下,该目录就是指定目录。如果想自定义导出路径,需要修改my.ini配置文件。打开路径D:\ProgramData\MySQL\MySQL Server 9.0,用记事本打开my.ini文件,然后搜索以下代码:
secure-file-priv="D:/ProgramData/MySQL/MySQL Server 9.0/Uploads"
在上述代码前添加#注释掉,然后添加以下内容:
结果如图11.1所示。
图11.1 设置数据表的导出路径
重启MySQL服务器后,再次使用SELECT...INTO OUTFILE将test_db数据库中的person表中的记录导出到文本文件,SQL语句如下:
mysql>SELECT * FROM test_db.person INTO OUTFILE 'D:/person0.txt';
Query OK,1 row affected (0.01 sec)
由于指定了INTO OUTFILE子句,因此SELECT会将查询出来的3个字段值保存到C:\person0.txt文件中。打开该文件,内容如下:
1 Green 21Lawyer2 Suse 22dancer3 Mary 24Musician4 Willam 20sports man5 Laura 25\N6 Evans 27secretary7 Dale 22cook8 Edison 28singer9 Harry 21magician10 Harriet 19 pianist
默认情况下,MySQL使用制表符(\t)分隔不同的字段,字段没有被其他字符包围。另外,第5行中有一个字段值为“\N”,表示该字段的值为NULL。默认情况下,当遇到NULL时,会返回“\N”,代表空值,其中的反斜线(\)表示转义字符;如果使用ESCAPED BY选项,则N前面为指定的转义字符。
【例11.11】使用SELECT...INTO OUTFILE语句,将test_db数据库person表中的记录导出到文本文件,使用FIELDS选项和LINES选项,要求字段之间使用逗号分隔,所有字段值用双引号引起来,定义转义字符为单引号“\'”,SQL语句如下:
SELECT * FROM test_db.person INTO OUTFILE "D:/person1.txt"FIELDS
TERMINATED BY','ENCLOSED BY'\"'ESCAPED BY'\''LINES
TERMINATED BY'\r\n';
该语句将把person表中所有记录导入D盘目录下的person1.txt文本文件中。
“FIELDS TERMINATED BY ','”表示字段之间用逗号分隔;“ENCLOSED BY '\"'”表示每个字段用双引号引起来;“ESCAPED BY '\'”表示将系统默认的转义字符替换为单引号;“LINES TERMINATED BY '\r\n'”表示每行以回车换行符结尾,保证每一条记录占一行。
执行成功后,在D盘下生成一个person1.txt文件。打开文件,内容如下:
"1","Green","21","Lawyer"
"2","Suse","22","dancer"
"3","Mary","24","Musician"
"4","Willam","20","sports man"
"5","Laura","25",'N'
"6","Evans","27","secretary"
"7","Dale","22","cook"
"8","Edison","28","singer"
"9","Harry","21","magician"
"10","Harriet","19","pianist"
可以看到,所有的字段值都被双引号引起来;第5条记录中空值的表示形式为“N”,即使用单引号替换了反斜线转义字符。
【例11.12】使用SELECT...INTO OUTFILE语句,将test_db数据库person表中的记录导出到文本文件,使用LINES选项,要求每行记录以字符串“>”开始、以字符串“<end>”结尾,SQL语句如下:
SELECT * FROM test_db.person INTO OUTFILE "D:/person2.txt"LINES
STARTING BY'>'TERMINATED BY'<end>';
语句执行成功后,在D盘下生成一个person2.txt文件。打开该文件,内容如下:
> 1 Green 21 Lawyer <end>> 2 Suse 22 dancer <end>> 3 Mary 24 Musician <end>> 4 Willam 20 sports man <end>> 5 Laura 25 \N <end>> 6 Evans 27 secretary <end>> 7 Dale 22 cook <end>> 8 Edison 28 singer <end>> 9 Harry 21 magician <end>> 10 Harriet 19 pianist <end>
可以看到,虽然将所有的字段值导出到文本文件中,但是所有的记录没有分行,出现这种情况是因为TERMINATED BY选项替换了系统默认的换行符。如果希望换行显示,则需要修改导出语句:
SELECT * FROM test_db.person INTO OUTFILE "D:/person3.txt"LINES
STARTING BY'>'TERMINATED BY'<end>\r\n';
执行完语句之后,换行显示每条记录,结果如下:
> 1 Green 21 Lawyer <end>
> 2 Suse 22 dancer <end>
> 3 Mary 24 Musician <end>
> 4 Willam 20 sports man <end>
> 5 Laura 25 \N <end>
> 6 Evans 27 secretary <end>
> 7 Dale 22 cook <end>
> 8 Edison 28 singer <end>
> 9 Harry 21 magician <end>
> 10 Harriet 19 pianist <end>
11.4.2 使用mysqldump命令导出文本文件
除了使用SELECT… INTO OUTFILE语句导出文本文件之外,还可以使用mysqldump命令。11.1节开始介绍了使用mysqldump备份数据库,该工具不仅可以将数据导出为包含CREATE、INSERT的sql文件,也可以导出为纯文本文件。
mysqldump创建一个包含创建表的CREATE TABLE语句的tablename.sql文件和一个包含其数据的tablename.txt文件。mysqldump导出文本文件的基本语法格式如下:
mysqldump -T path-u root -p dbname [tables] [OPTIONS]
只有指定了-T参数才可以导出纯文本文件;path表示导出数据的目录;tables为指定要导出的表名称,如果不指定,将导出数据库dbname中所有的表;[OPTIONS]为可选参数选项,这些选项需要结合-T选项使用。OPTIONS常见的取值有:
--fields-terminated-by=value:设置字段之间的分隔字符,可以为单个或多个字符,默认情况下为制表符(\t)。
--fields-enclosed-by=value:设置字段的包围字符。
--fields-optionally-enclosed-by=value:设置字段的包围字符,只能为单个字符,只能包括CHAR和VERCHAR等字符数据字段。
--fields-escaped-by=value:控制如何写入或读取特殊字符,只能为单个字符,即设置转义字符,默认值为\。
--lines-terminated-by=value:设置每行数据结尾的字符,可以为单个或多个字符,默认值为“\n”。
这里的OPTIONS的设置与SELECT…INTO OUTFILE语句中的OPTIONS不同,各个取值中等号后面的value值不要用引号括起来。
【例11.13】使用mysqldump将test_db数据库person表中的记录导出到文本文件,SQL语句如下:
mysqldump -T D:\ test_db person -u root -p
语句执行成功,系统D盘目录下面将会有两个文件,分别为person.sql和person.txt。person.sql包含创建person表的CREATE语句,其内容如下:
-- MySQL dump 10.13 Distrib 9.0.1, forWin64 (x86_64)--
--Host: localhost Database: test_db-- ------------------------------------------------------
-- Server version 9.0.1
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT*/;/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS*/;/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION*/;
SET NAMES utf8mb4 ;/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE*/;/*!40103 SET TIME_ZONE='+00:00'*/;/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE=''*/;/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0*/;--
-- Table structure fortable `person`--DROP TABLE IF EXISTS `person`;/*!40101 SET @saved_cs_client = @@character_set_client*/;/*!40101 SET character_set_client = utf8*/;
CREATE TABLE `person` (
`id`int(10) unsigned NOT NULL AUTO_INCREMENT,
`name`char(40) NOT NULL DEFAULT '',
`age`int(11) NOT NULL DEFAULT '0',
`info`char(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;/*!40101 SET character_set_client = @saved_cs_client*/;/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE*/;/*!40101 SET SQL_MODE=@OLD_SQL_MODE*/;/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT*/;/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS*/;/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION*/;/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES*/;-- Dump completed on 2024-07-25 16:40:55
备份文件中的信息已在11.1.1节中介绍了。
person.txt包含数据包中的数据,其内容如下:
1 Green 21Lawyer2 Suse 22dancer3 Mary 24Musician4 Willam 20sports man5 Laura 25\N6 Evans 27secretary7 Dale 22cook8 Edison 28singer9 Harry 21magician10 Harriet 19 pianist
【例11.14】使用mysqldump命令将test_db数据库中的person表中的记录导出到文本文件,使用FIELDS选项,要求字段之间使用逗号“,”间隔,所有字符类型字段值用双引号引起来,定义转义字符为“?”,每行记录以“\r\n”结尾,SQL语句如下:
mysqldump -T D:\ test_db person -u root -p --fields-terminated-by=, --fields-optionally-enclosed-by=\"--fields-escaped-by=? --lines-terminated-by=\r\n
Enter password:******
上面语句要在一行中输入,语句执行成功后,系统D盘目录下面将会有两个文件,分别为person.sql和person.txt。person.sql包含创建person表的CREATE语句,其内容与【例11.13】中的相同;person.txt文件的内容与【例11.13】中的不同,显示如下:
1,"Green",21,"Lawyer"
2,"Suse",22,"dancer"
3,"Mary",24,"Musician"
4,"Willam",20,"sports man"
5,"Laura",25,?N6,"Evans",27,"secretary"
7,"Dale",22,"cook"
8,"Edison",28,"singer"
9,"Harry",21,"magician"
10,"Harriet",19,"pianist"
可以看到,只有字符类型的值被双引号引起来了,而数值类型的值没有;第5行记录中的NULL表示为“?N”,使用“?”替代了系统默认的“\”。
11.4.3 使用mysql命令导出文本文件
mysql是一个功能丰富的工具命令,使用它们还可以在命令行模式下执行SQL指令,将查询结果导入文本文件中。相比mysqldump,mysql工具导出的结果具有更强的可读性。
如果MySQL服务器是单独的机器,用户是在一个客户端上进行操作,要把数据结果导入客户端上。
使用mysql导出数据文本文件的基本语法格式如下:
mysql -u root -p --execute= "SELECT语句" dbname > filename.txt
该命令使用--execute选项,表示执行该选项后面的语句并退出,后面的语句必须用双引号引起来;dbname为要导出的数据库名称;导出的文件中不同列之间使用制表符分隔,第1行包含了各个字段的名称。
【例11.15】使用mysql命令,将test_db数据库中的person表中的记录导出到文本文件,SQL语句如下:
mysql -u root -p --execute="SELECT * FROM person;" test_db > D:\person3.txt
语句执行完毕之后,系统D盘目录下面将会有名称为“person3.txt”的文本文件,其内容如下:
id name age info1 Green 21Lawyer2 Suse 22dancer3 Mary 24Musician4 Willam 20sports man5 Laura 25NULL6 Evans 27secretary7 Dale 22cook8 Edison 28singer9 Harry 21magician10 Harriet 19 pianist
可以看到,person3.txt文件中包含了每个字段的名称和各条记录,该显示格式与MySQL命令行下SELECT查询结果的显示格式相同。
使用mysql命令还可以指定查询结果的显示格式,如果某条记录的字段很多,可能一行不能完全显示,可以使用--vartical参数将每条记录分为多行显示。
【例11.16】使用mysql命令将test_db数据库中的person表中的记录导出到文本文件,使用--vertical参数显示结果,SQL语句如下:
mysql -u root -p --vertical --execute="SELECT * FROM person;" test_db > D:\person4.txt
语句执行之后,D:\person4.txt文件中的内容如下:
*** 1. row ***id:1name: Green
age:21info: Lawyer*** 2. row ***id:2name: Suse
age:22info: dancer*** 3. row ***id:3name: Mary
age:24info: Musician*** 4. row ***id:4name: Willam
age:20info: sports man*** 5. row ***id:5name: Laura
age:25info: NULL*** 6. row ***id:6name: Evans
age:27info: secretary*** 7. row ***id:7name: Dale
age:22info: cook*** 8. row ***id:8name: Edison
age:28info: singer*** 9. row ***id:9name: Harry
age:21info: magician*** 10. row ***id:10name: Harriet
age:19info: pianist
可以看到,SELECT的查询结果导出到文本文件之后,显示格式发生了变化,如果person表中的记录内容很长,这样显示会让人更加容易阅读。
mysql还可以将查询结果导出到html文件中,使用--html选项即可。
【例11.17】使用MySQL命令将test_db数据库中的person表中的记录导出到html文件,SQL语句如下:
mysql -u root -p --html --execute="SELECT * FROM person;" test_db > D:\person5.html
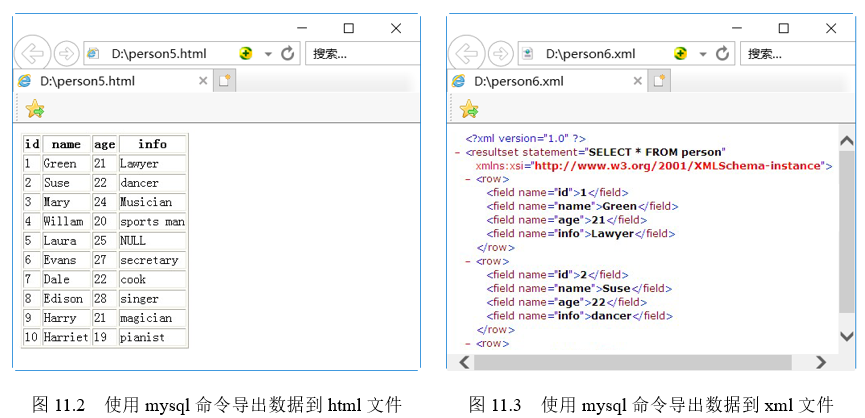
语句执行成功,将在D盘创建文件person5.html,该文件在浏览器中的显示效果如图11.2所示。
如果要将表数据导出到xml文件中,可使用--xml选项。
【例11.18】使用mysql命令将test_db数据库中的person表中的记录导出到xml文件,SQL语句如下:
mysql -u root -p --xml --execute="SELECT * FROM person;" test_db >D:\person6.xml
语句执行成功,将在D盘创建文件person6.xml,该文件在浏览器中的显示效果如图11.3所示。