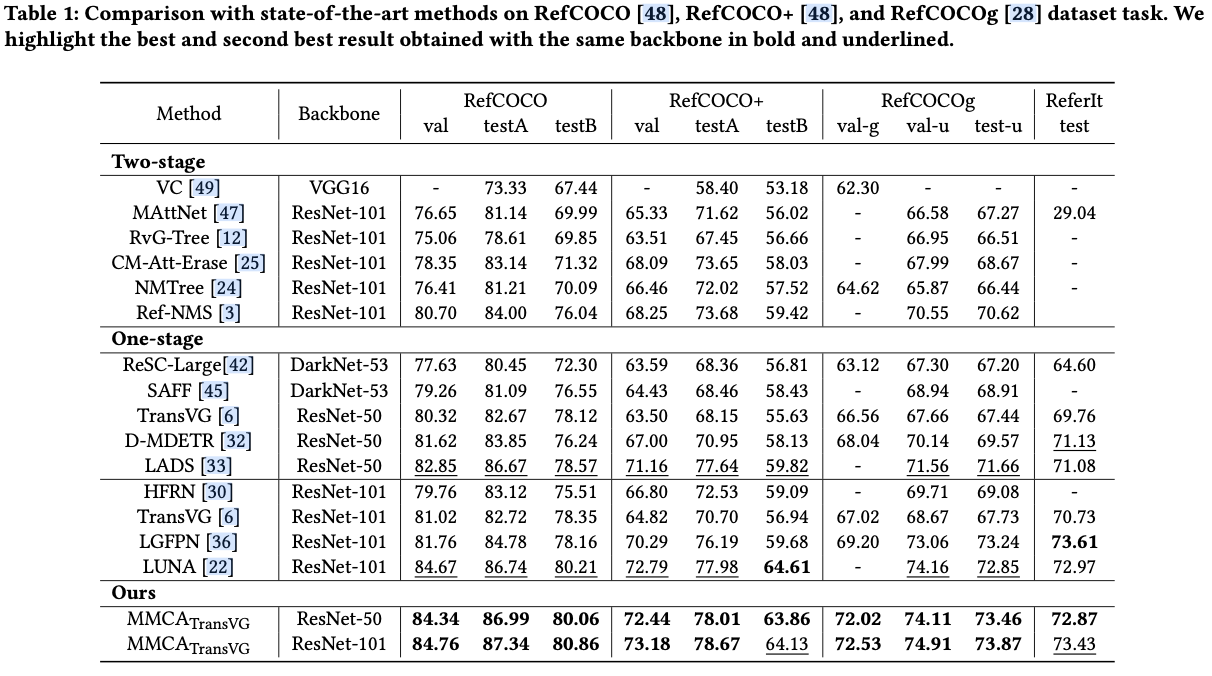
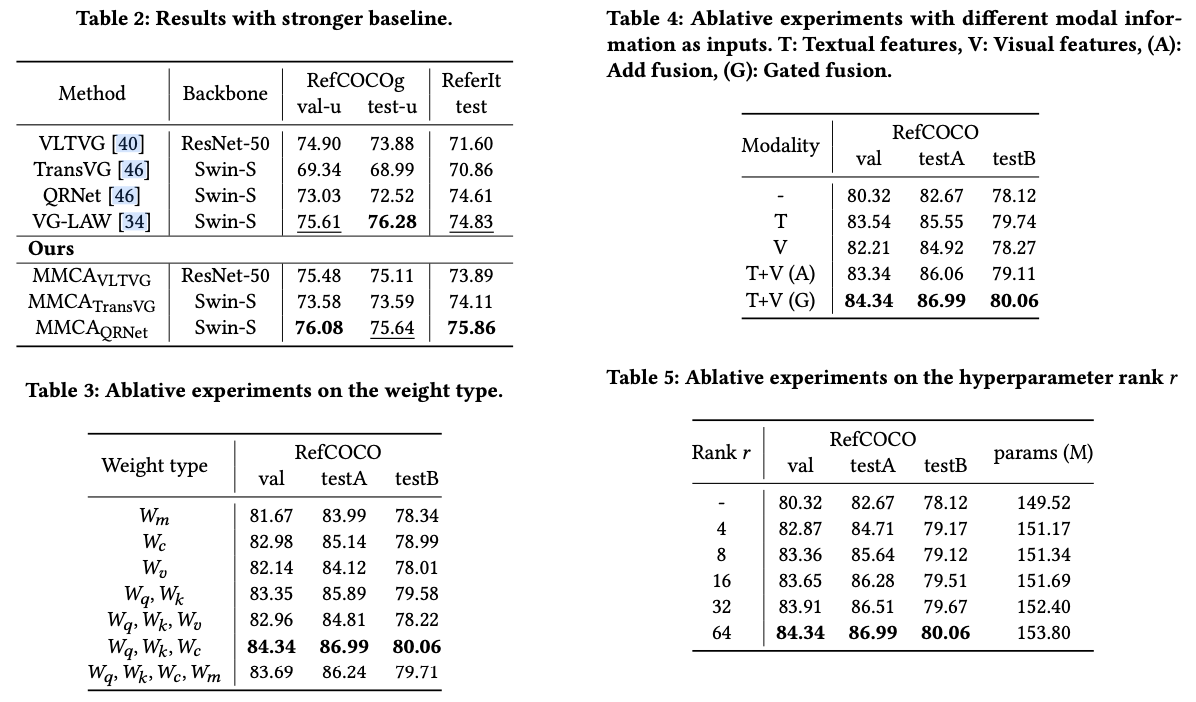
初探富文本之搜索替换算法
在我们的在线文档系统中,除了基础的富文本编辑能力外,搜索替换的算法同样也是重要的功能实现。纯文本搜索替换算法相对来说是比较容易实现的,而在富文本的场景中,由于存在图文混排、嵌入模块如
Mention
等,实现这一功能则相对要复杂得不少。那么本文则以
Quill
实现的富文本编辑器为基础,通过设计索引查找和图层渲染的方式来实现搜索替换。
描述
首先我们先来思考一下纯文本的搜索替换算法,对于纯文本而言我们可以直接通过一些方法来查找对应文本的索引值,然后无论是将其直接替换还是切割再联合的方式,都可以轻松地完成这个功能。而富文本本质上可以看作是携带着格式的纯文本,那么在这种情况下我们依然可以延续着对于纯文本的处理思路,只不过由于存在文本会被切割为多个片段的问题,就需要我们来兼容这个数据层面上的问题。
实际上在前边我们强调了当前的实现是以
Quill
为基础实现的方案,因为本质上搜索替换与数据结构的实现强相关,
quill-delta
是扁平的数据结构,相对来说比较方便我们来处理这个问题。而如果是嵌套的数据结构类型例如
Slate
的实现,我们仍然可以依照这个思路来实现,只不过在这里如果我们将其作为
DEMO
来实现并没有那么直观,嵌套的数据结构类型对于替换的处理上也会复杂很多。
那么在这里我们先来构造
Quill
的编辑器实例,在我们实现的实例中,我们只需要引用
quill.js
的资源,然后指定实例化的
DOM
节点即可初始化编辑器,我们在这里通过配置来注册了样式模块。文中的相关实现可以在
https://github.com/WindRunnerMax/QuillBlocks/blob/master/examples/find-replace.html
中查看。
<div class="editor-container">
<div id="$editor"></div>
</div>
<script src="https://cdn.quilljs.com/1.3.6/quill.js"></script>
<script>
const editor = new Quill($editor, {
modules: {
toolbar: [[{ header: [1, 2, false] }], ["bold", "italic", "underline"], ["code-block"]],
},
placeholder: "Enter Text...",
theme: "snow",
});
</script>
在
Quill
中是使用
quill-delta
来描述富文本内容的,
quill-delta
是一个扁平的数据结构,除了能描述富文本内容之外,还可以描述富文本内容的变更。在这里我们首先关注的是文档内容的描述,因此这里我们则是全部以
insert
的形式来描述,而之前我们也提到了富文本实际上就是纯文本携带属性,因此我们可以很轻松地使用下面的样式描述普通文本与加粗文本。
const delta = new Delta([
{ insert: "Hello " },
{ insert: "World", attributes: { bold: true } },
]);
我们的搜索替换方案本质上是在数据描述的基础上来查找目标内容,而从上边的数据结构来看,我们可以明显地看出在
attributes
上也可能存在需要查找的目标内容,例如我们需要实现
Mention
组件,是可以在
attributes
中存储
user
信息来展示
@user
的信息,而
insert
置入的内容则是空占位,那么在这里我们就实现一下
Quill
的
Mention
插件。
const Embed = Quill.import("blots/embed");
class Mention extends Embed {
static blotName = "mention";
static className = "ql-mention";
static tagName = "SPAN";
static create(value) {
const node = super.create(value);
node.innerHTML = `@${value}`;
node.setAttribute("data-value", value);
return node;
}
static value(domNode) {
return domNode.getAttribute("data-value");
}
}
Quill.register(Mention);
则此时我们的预置的数据结构内容则如下所示,我们可能注意到数据结构中
Mention
的
insert
是对象并且实际内容是并不是在
attributes
而是在
insert
中。这是因为在
Quill
中描述
parchment
的
blots/embed
中
value
是由
insert
存储的
blotName
对象来完成的,因此在示例中我们查找的目标还是在
insert
对象中,但是并不实际影响我们需要对其进行额外的查找实现。
editor.setContents([
{ "insert": "查找替换" },
{ "attributes": { "header": 1 }, "insert": "\n" },
{ "insert": "查找替换的富文本基本能力,除了基本的" },
{ "attributes": { "bold": true }, "insert": "文本查找" },
{ "insert": "之外,还有内嵌结构例如" },
{ "attributes": { "italic": true }, "insert": "Mention" },
{ "insert": "的" },
{ "insert": { mention: "查找能力" } },
{ "insert": "。\n" },
]);
搜索算法
首先我们先来设计一下内容的搜索算法,既然前边我们已经提到了富文本实际上就是带属性的纯文本,那么我们就先来设想对于纯文本的搜索实现。文本搜索算法实现本质上就是字符串文本的匹配,那么我们很容易想到的就是
KMP
算法,而实际上
KMP
算法并不是最高效的实现算法,在各种文本编辑器中实现的查找功能更多的是使用的
Boyer-Moore
算法。
在这里我们先不考虑高效的算法实现,我们实现的目标则是在长文本中查找目标文本的索引值,因此可以直接使用
String
对象的
indexOf
来实现查找。而我们实际上是需要获取目标文本的所有索引值,因此需要借助这个方法的第二个参数
position
来实现查找的起始位置。而如果我们使用正则来实现索引则容易出现输入的字符串被处理为正则保留字的问题,例如搜索
(text)
字符串时,则在不特殊处理的情况下会被认为搜索
text
文本。
const origin = "123123000123";
const target = "123";
const indices = [];
let startIndex = 0;
while ((startIndex = origin.indexOf(target, startIndex)) > -1) {
indices.push(startIndex);
startIndex += target.length;
}
console.log(indices); // [0, 3, 9]
const origin = "123123000123";
const target = "123";
const indices = [];
const regex = new RegExp(target, "g");
let match;
while ((match = regex.exec(origin)) !== null) {
indices.push(match.index);
}
console.log(indices); // [0, 3, 9]
在我们上述的测试中,可以将其放置于
https://perf.link/
测试一下执行性能,将其分别实现防止于
Test Cases
中测试,可以发现实际上
indexOf
的性能还会更高一些,因此在这里我们就直接使用
indexOf
来实现我们的搜索算法。在浏览器中测试万字文本的
indexOf
搜索,结果稳定在
1ms
以内,性能表现是完全可以接受的,当然这个搜索结果和电脑本身的性能也是强相关的。
indexOf // 141,400 ops/s
RegExp // 126,030 ops/s
那么此时我们就来处理关于
Delta
的索引建立,那么由于富文本的表达存在样式信息,反映在数据结构上则是存在文本的片段,因此我们的搜索首先需要直接将所有文本拼接为长字符串,然后使用
indexOf
进行查找。此外在前边我们已经看到数据结构中存在
insert
,在这里我们需要将其作为不可搜索的文本占位,以避免在搜索时将其作为目标文本的一部分。
const delta = editor.getContents();
const str = delta.ops
.map(op => (typeof op.insert === "string" ? op.insert : String.fromCharCode(0)))
.join("");
let index = str.indexOf(text, 0);
const ranges = [];
while (index >= 0) {
ranges.push({ index, length: text.length });
index = str.indexOf(text, index + text.length);
}
而对于类似于
Mention
模块的
Void/Embed
结构处理则需要我们特殊处理,在这里不像是先前对于纯文本的内容搜索,我们不能将这部分的相关描述直接放置于
insert
中,因此此时我们将难以将其还原到原本的数据结构中,如果不能还原则无法将其显示为搜索的结果样式。那么我们就需要对
delta.ops
再次进行迭代,然后
case by case
地将需要处理的属性进行处理。
const rects = [];
let iterated = 0;
delta.ops.forEach(op => {
if (typeof op.insert === "string") {
iterated = iterated + op.insert.length;
return void 0;
}
iterated = iterated + 1;
if (op.insert.mention) {
const value = op.insert.mention;
const mentionIndex = value.indexOf(text, 0);
if (mentionIndex === -1) return void 0;
// 绘制节点位置 ...
}
});
当我们将所有的数据收集到起来后,就需要构建虚拟图层来展示搜索的结果。首先我们需要处理最初处理的
insert
纯文本的搜索结果,由于我们在输入的时候通常都是使用
input
来输入搜索的文本目标,因此我们是不需要处理
\n
的情况,这里的图层处理是比较方便的。而具体的虚拟图层实现在先前的
diff
算法文章中已经描述得比较清晰,这里我们只实现相关的调用。
const rangeDOM = document.createElement("div");
rangeDOM.className = "ql-range virtual-layer";
$editor.appendChild(rangeDOM);
const COLOR = "rgba(0, 180, 42, 0.3)";
const renderVirtualLayer = (startRect, endRect) => {
// ...
};
const buildRangeLayer = ranges => {
rangeDOM.innerText = "";
ranges.forEach(range => {
const startRect = editor.getBounds(range.index, 0);
const endRect = editor.getBounds(range.index + range.length, 0);
rangeDOM.appendChild(renderVirtualLayer(startRect, endRect));
});
};
而在这里我们更需要关注的是
Mention
的处理,因为在这里我们不能够使用
editor.getBounds
来获取其相关的
BoundingClientRect
,因此这里我们需要自行计算其位置。因此我们此时需要取得
mentionIndex
所在的节点,然后通过
createRange
构建
Range
对象,然后基于该
Range
获取
ClientRect
,这样就取得了我们需要的
startRect
和
endRect
,但是需要注意的是,此时我们取得是绝对位置,还需要将其换算为编辑器实例的相对位置才可以。
const [leaf, offset] = editor.getLeaf(iterated);
if (
leaf &&
leaf.domNode &&
leaf.domNode.childNodes[1] &&
leaf.domNode.childNodes[1].firstChild
) {
const textNode = leaf.domNode.childNodes[1].firstChild;
const startRange = document.createRange();
startRange.setStart(textNode, mentionIndex + 1);
startRange.setEnd(textNode, mentionIndex + 1);
const startRect = startRange.getBoundingClientRect();
const endRange = document.createRange();
endRange.setStart(textNode, mentionIndex + 1 + text.length);
endRange.setEnd(textNode, mentionIndex + 1 + text.length);
const endRect = endRange.getBoundingClientRect();
rects.push({ startRect, endRect });
}
rects.forEach(it => {
const editorRect = editor.container.getBoundingClientRect();
const startRect = {
bottom: it.startRect.bottom - editorRect.top,
height: it.startRect.height,
left: it.startRect.left - editorRect.left,
right: it.startRect.right - editorRect.left,
top: it.startRect.top - editorRect.top,
width: it.startRect.width,
};
const endRect = {
bottom: it.endRect.bottom - editorRect.top,
height: it.endRect.height,
left: it.endRect.left - editorRect.left,
right: it.endRect.right - editorRect.left,
top: it.endRect.top - editorRect.top,
width: it.endRect.width,
};
const block = renderVirtualLayer(startRect, endRect);
rangeDOM.appendChild(block);
});
批量替换
替换的实现在
Delta
的结构上会比较简单,在先前我们也提到了
Delta
不仅能够通过
insert
描述文档,还可以借助
retain
、
delete
、
insert
方法来描述文档的变更,那么我们需要做的就是在上述构造的
ranges
的基础上,构造目标的变更描述。而由于我们先前构造的
Mention
是不允许进行实质性的替换操作的,所以我们只需要关注原本的
insert
文本内容即可。
这里的实现重点是实现了批量的
changes
构造,首先需要定义
Delta
实例,紧接着的
preIndex
是用来记录上一次执行过后的索引位置,在我们的
ranges
循环中,
retain
是用来移动指针到当前即将处理的原文本内容,然后调用
delete
将其删除,之后的
insert
是替换的目标文本,注意此时的指针位置是在目标文本之后,因此需要将
preIndex
更新为当前处理的索引位置,最后将其应用到编辑器即可。
const batchReplace = () => {
const text = $input1.value;
const replace = $input2.value;
if (!text) return void 0;
const changes = new Delta();
let preIndex = 0;
ranges.forEach(range => {
changes.retain(range.index - preIndex);
changes.delete(range.length);
changes.insert(replace);
preIndex = range.index + range.length;
});
editor.updateContents(changes);
onFind();
};
每日一题
https://github.com/WindrunnerMax/EveryDay
参考
https://quilljs.com/docs/delta
https://www.npmjs.com/package/parchment
https://www.npmjs.com/package/quill-delta/v/4.2.2
https://developer.mozilla.org/zh-CN/docs/Web/API/Document/createRange
https://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
https://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html