MMCA:多模态动态权重更新,视觉定位新SOTA | ACM MM'24 Oral
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Visual Grounding with Multi-modal Conditional Adaptation

创新点
- 提出了多模态条件适应(
MMCA
)方法,该方法从一种新颖的权重更新视角改善了视觉引导模型中视觉编码器的特征提取过程。 - 将提出的
MMCA
应用于主流的视觉引导框架,并提出了灵活的多模态条件变换器和卷积模块,这些模块可以作为即插即用组件轻松应用于其他视觉引导模型。 - 进行广泛的实验以验证该方法的有效性,在四个具有代表性的数据集上的结果显示出显著的改善,且成本较小。
内容概述
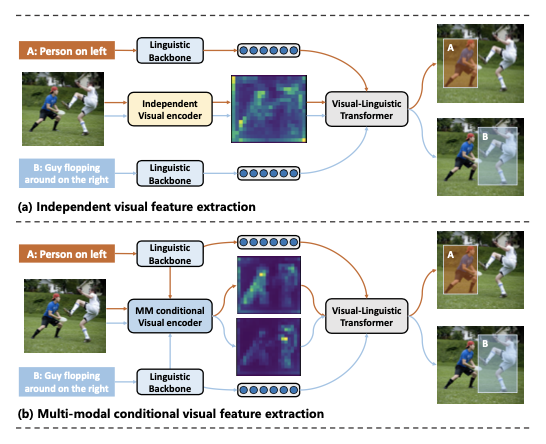
视觉定位旨在将传统的物体检测推广到定位与自由形式文本描述相对应的图像区域,已成为多模态推理中的核心问题。现有的方法通过扩展通用物体检测框架来应对这一任务,使用独立的视觉和文本编码器分别提取视觉和文本特征,然后在多模态解码器中融合这些特征以进行最终预测。
视觉定位通常涉及在同一图像中定位具有不同文本描述的物体,导致现有的方法在这一任务上表现不佳。因为独立的视觉编码器对于相同的图像生成相同的视觉特征,从而限制了检测性能。最近的方法提出了各种语言引导的视觉编码器来解决这个问题,但它们大多仅依赖文本信息,并且需要复杂的设计。
受
LoRA
在适应不同下游任务的高效性的启发,论文引入了多模态条件适配(
MMCA
),使视觉编码器能够自适应更新权重,专注于与文本相关的区域。具体而言,首先整合来自不同模态的信息以获得多模态嵌入,然后利用一组从多模态嵌入生成的权重系数,来重组权重更新矩阵并将其应用于视觉定位模型的视觉编码器。
MMCA
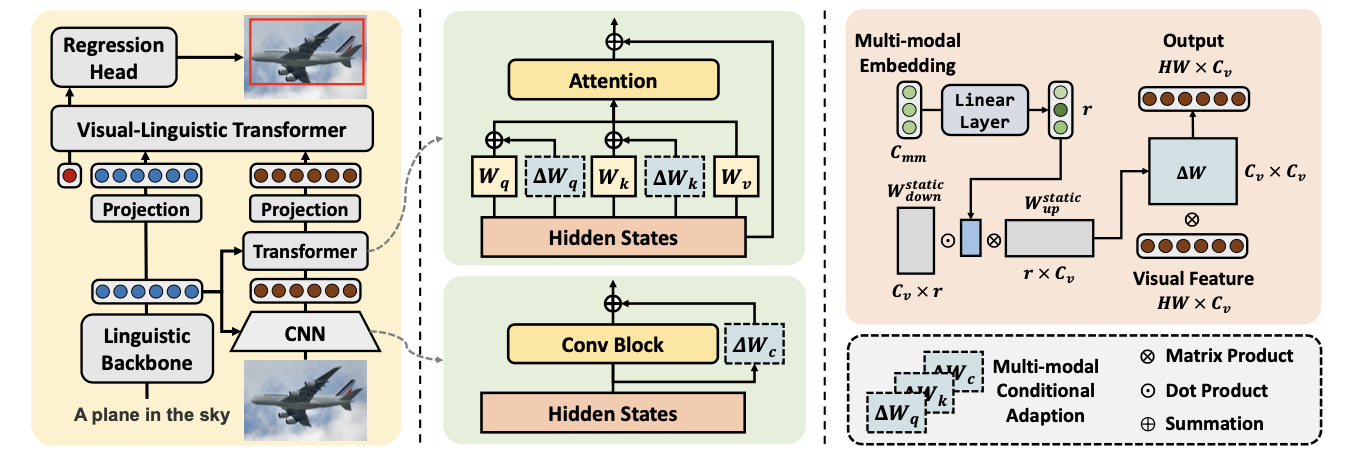
MMCA
遵循典型的端到端编码器-解码器范式:
- 给定一幅图像和一个语言表达作为输入将其输入到编码器部分,以生成相应的特征嵌入。
- 在语言分支中,语言主干将经过分词的语言表达作为输入,并提取文本特征
\(f_t\in \mathbb{R}^{N_t\times C_t}\)
,其中
\(N_t\)
是语言标记的数量。 - 在视觉分支中,
CNN
主干首先提取一个二维特征图,然后经过一系列变换器编码器层,生成一个展平的视觉特征序列
\(f_v\in \mathbb{R}^{N_v\times C_v}\)
。 - 多模态条件适应(
MMCA
)模块以层级方式应用于卷积层和变换器层的参数矩阵。该模块同时接受视觉和文本特征作为输入,并动态更新视觉编码器的权重,以实现基于语言的视觉特征提取。
- 在语言分支中,语言主干将经过分词的语言表达作为输入,并提取文本特征
- 将视觉和文本特征嵌入连接在一起,并在多模态解码器(视觉-语言变换器)的输入中添加一个可学习的标记 [
REG
],该解码器将来自不同模态的输入标记嵌入对齐的语义空间,并通过自注意力层执行模态内和模态间的推理。 - 回归头使用 [
REG
] 标记的输出状态来直接预测被指对象的四维坐标
\(\hat b = (\hat{x}, \hat{y}, \hat{w}, \hat{h})\)
。与真实框
\(b = (x, y, w, h)\)
的训练损失可以表述为:
\mathcal L=\mathcal L_{smooth-l1}(\hat b, b)+L_{giou}(\hat b, b)
\end{equation}
\]
条件适应
对于视觉引导任务,论文希望不同的指代表达能够控制视觉编码器的一组权重更新,从而引导编码器的注意力集中在与文本相关的区域。然而,直接生成这样的矩阵带来了两个缺点:(
1
)这需要一个大型参数生成器。(
2
)没有约束的生成器可能在训练中对表达式过拟合,而在测试期间却难以理解表达式。
受
LoRA
的启发,让网络学习一组权重更新的基矩阵并使用多模态信息重新组织更新矩阵。这使得参数生成器变得轻量,并确保网络的权重在同一空间内更新。
具体而言,先对权重更新矩阵进行分解,并将其重新表述为外积的和,通过
\(B_i, A_i\)
并使用加权和来控制适应的子空间:
\Delta Wx=BAx={\textstyle \sum_{i=1}^{r}} B_i\otimes A_i
\label{eq3}
\end{equation}
\]
h=W_0x+\Delta Wx=W_0x+{\textstyle \sum_{i=1}^{r}} w_iB_i\otimes A_i
\label{eq4}
\end{equation}
\]
为了简化并且不引入其他归纳偏差,使用线性回归来生成这一组权重:
[w_1, w_2, ..., w_r]^T
=W_gE_{mm}+
[b_1, b_2, ..., b_r]^T
\label{eq5}
\end{equation}
\]
其中
\(W_g\in \mathbb{R}^{r\times d}, [b_1, b_2, ..., b_r]^T\)
是参数矩阵,
\(E_{mm}\in \mathbb{R}^{d}\)
是特定层的多模态嵌入,它是由文本特征和从前一层输出的视觉特征生成的。
与迁移学习任务不同,这里并不打算微调一小部分参数以适应特定的下游任务,而是希望视觉编码器能够适应各种表达。因此,所有参数矩阵
\(W_0, B, A, W_g, [b_1, b_2, ..., b_r]^T\)
在训练阶段都是可学习的。
多模态嵌入
仅依赖文本信息来引导视觉编码器可能会在某些应用中限制灵活性,并且性能可能会受到文本信息质量的影响。为了缓解这些问题,采用门控机制来调节文本信息的输入。
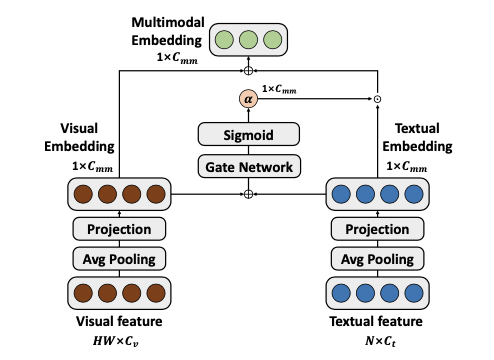
给定文本特征
\(F_t\in \mathbb{R}^{N_t\times C_t}\)
和展平的视觉特征
\(F_v\in \mathbb{R}^{HW\times C_v}\)
,使用简单门控机制来融合视觉和文本嵌入:
E_{t} = W_tF_t, E_{v}=W_vF_v
\end{equation}
\]
\alpha =\sigma[W^1_g\delta(W^2_g(E_{t}+E_{v}))]
\end{equation}
\]
E_{mm} = \alpha E_{t} + E_{v}
\end{equation}
\]
最后,融合嵌入
\(E_{mm}\)
被用来生成系数,从而指导视觉编码器的权重更新。
适配视觉定位
基于视觉编码器(卷积层和
Transformer
层),进一步提出了多模态条件
Transformer
和多模态条件卷积,用于将
MMCA
应用于视觉定位中。
多模态条件
Transformer
视觉主干中的
Transformer
编码器层主要由两种类型的子层组成,即
MHSA
和
FFN
。通过应用多模态条件适应,
MHSA
和
FFN
的计算变为:
\begin{split}
h'=softmax(\frac{(W'_q)XX^T(W'^T_k)} {\sqrt{d_k}})W_vX + X\\
W'_q = W_q + \Delta W_{q}, W'_k = W_k + \Delta W_{k}
\end{split}
\label{eq8}
\end{equation}
\]
X_{output}=LN(MLP(h')+\Delta W_{m}h'+h')
\label{eq9}
\end{equation}
\]
其中
\(\Delta W_{q}, \Delta W_{k}, \Delta W_{m}\)
是查询、关键和
MLP
块的线性投影的条件权重更新。
多模态条件卷积
为了便于应用多模态条件适应,将卷积权重更新展开为一个
2-D
矩阵并用两个矩阵
\(B\in \mathbb{R}^{c_{in}\times r}, A\in \mathbb{R}^{r\times c_{out}k^2}\)
进行近似,秩为
\(r\)
。于是,卷积块的多模态条件适应可以通过两个连续的卷积层
\(Conv_B\)
和
\(Conv_A\)
来近似:
X_{output}=Conv_{k \times k}(X)+Conv_A(W_{mm} \odot Conv_B(X))
\label{eq10}
\end{equation}
\]
其中
\(X\)
和
\(W_{mm}=[w_1, w_2, ..., w_r]^T\)
分别是来自前一卷积层的视觉特征和从多模态嵌入生成的权重系数。在通道维度上计算系数与
\(Conv_B\)
输出的点积,并将输出输入到
\(Conv_A\)
,这相当于重新组织权重更新。
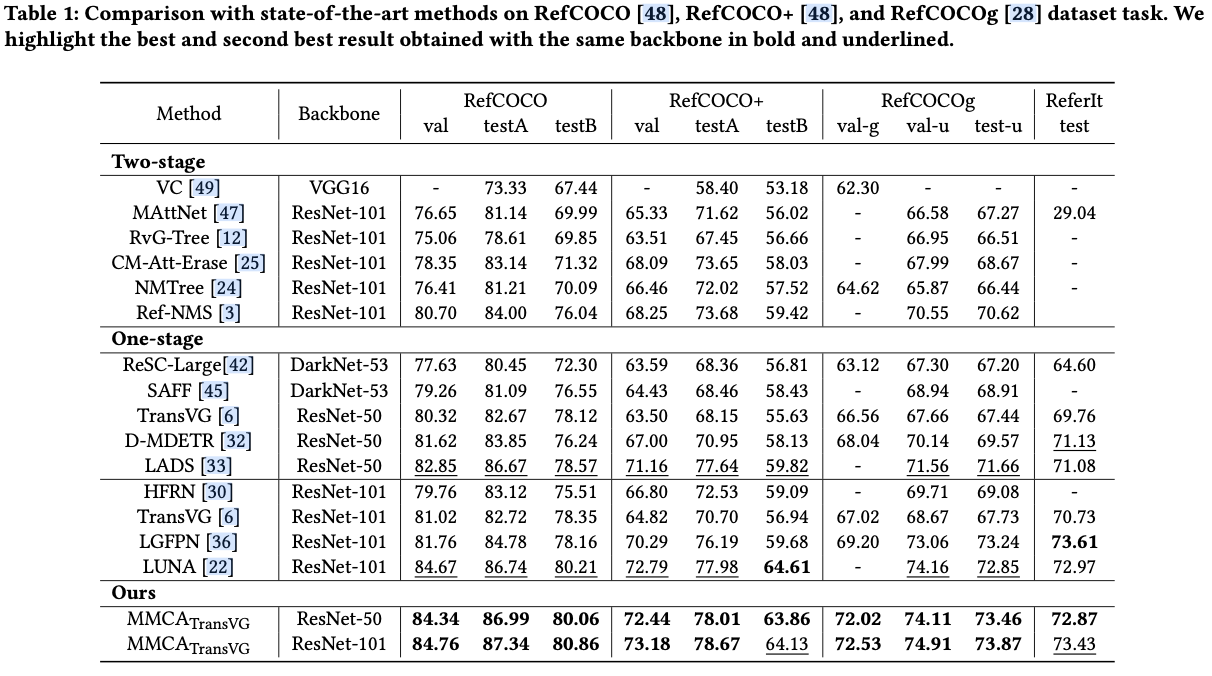
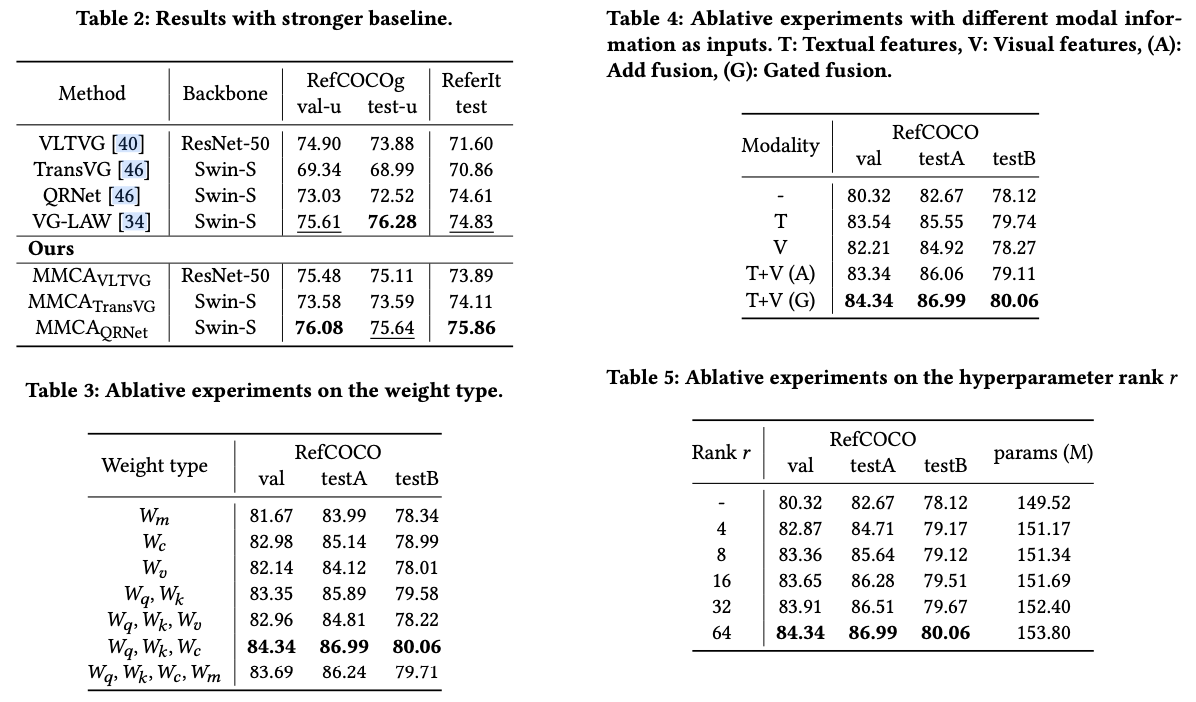
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
