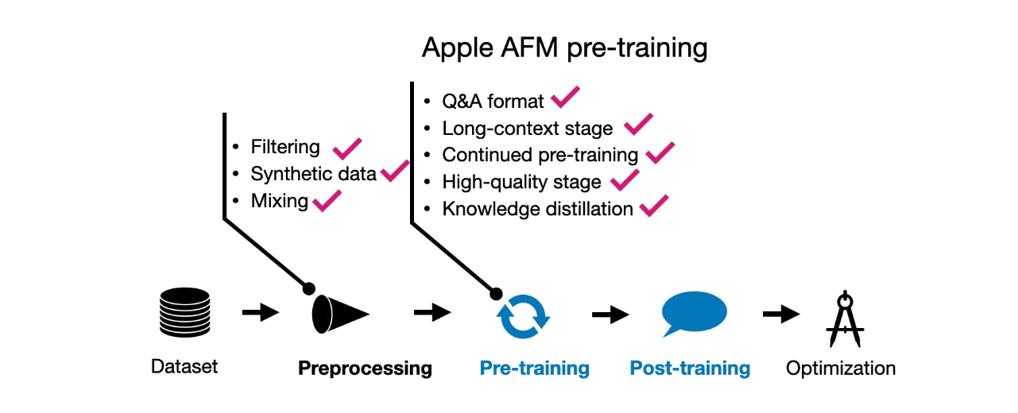
基本类型的响应式数据
在 Vue 3 中,
ref
是一个函数,用于创建响应式的数据。它主要用于处理基本类型(如数字、字符串、布尔值等)的数据响应式
当我们调用 ref 函数时,会返回一个包含一个 .value 属性的对象。这个对象会被转换成 Proxy 对象,通过拦截 getter 和 setter 操作,实现对 .value 属性的监听。当读取 .value 属性时,会触发 getter操作,将 .value 属性的值返回。当修改 .value 属性时,会触发 setter操作,将新的值赋给 .value 属性
<script setup lang="ts" name="UserInfo">
// 导入ref
import {ref} from "vue"
// 需要让哪个数据是响应式的,就给哪个数据使用ref
let age = ref(18)
let name = ref("vue3")
// 不需要响应式
let address:string = "Beijing"
// ref返回的是一个响应式对象,里面的value是具体的值
// 在template模版中使用 例如age,不需要age.value,模版会自动.value解析
// 但是在ts、js代码中使用,需要.value
function setAge(){
age.value = 20 // 将value改成20,响应式修改
}
</script>
<template>
{{ age }}
{{ name }}
{{address}}
<button @click="setAge">修改年龄</button>
</template>
ref也可以用于处理对象和数组,但对于复杂类型,
reactive
函数可能更加合适
<script setup lang="ts" name="UserInfo">
import {ref} from "vue"
// 响应式对象数据
// ref处理对象的原理-底层调用了reactive
let info = ref({name: "vue3", age: 18})
// 修改age
function setAge() {
info.value.age = 20
}
</script>
<template>
{{ info.age }}
{{ info.name }}
<button @click="setAge">修改年龄</button>
</template>
对象类型的响应式数据
reactive
是一个用于创建响应式对象的函数。它主要用于处理复杂的数据类型,如对象和数组,使得这些数据成为响应式数据,即当数据的内容发生变化时,与之绑定的组件模板会自动更新
当我们调用 reactive 函数时,会将传入的普通 JavaScript 对象转换为一个 Proxy 对象,通过拦截 getter 和 setter 操作,实现对整个对象的监听。当读取对象的属性时,会触发 getter操作,返回对应属性的值。当修改对象的属性时,会触发 setter操作,将新的值赋给对应的属性
<script setup lang="ts" name="UserInfo">
// 导入reactive
import {reactive} from "vue"
// 需要让哪个对象是响应式的,就给哪个对象使用ref
// 响应式对象
let info = reactive({name:"vue3",age:18})
// 非响应式对象
let ext = {address:"Beijing"}
// 修改age
function setAge(){
info.age = 20
}
</script>
<template>
{{ info.age }}
{{ info.name }}
{{ext.address}}
<button @click="setAge">修改年龄</button>
</template>
ref和reactive的区别
ref可以用来定义基本数据类型、对象数据类型
reactive只能用来定义对象数据类型
若需要一个基本类型的响应式数据,必须使用ref
若需要一个响应式对象,层级不深,ref、reactive都可以。
若需要一个响应式对象,且层级较深,推荐使用reactive
ref创建的变量必须使用.value
reactive重新分配一个新对象,会失去响应式,可以使用Object.assign整体替换
let info = reactive({name: "vue3", age: 18})
// info = {name:"vue2"},给info重新分配对象,会失去响应式
// info = reactive({name:"vue2"}) 不能使用该方式重新分配响应式对象,使用该方式后,不是原先的响应式info是一个新的响应式info,页面不更新
// 使用这种方式重新分配对象
Object.assign(info,{name:"vue2",age:20})
如果是使用ref创建的响应式对象,重新分配一个对象,可以直接分配
let info = ref({name: "vue3", age: 18})
// 直接赋值替换,也是响应式的,通过.value拿到替换,.value拿到的就是响应式的
info.value = {name:"3",age:20}
// 响应式基本数据类型不能直接这样修改,需要通过.value
// 使用该方式相当于创建了一个新的响应式,而不是原先的响应式,页面是跟原先的响应式关联
let count = ref(10)
count = ref(20)
toRefs和toRef
- 作用:将一个响应式对象中的每一个属性,转换为
ref
对象。
- 备注:
toRefs
与
toRef
功能一致,但
toRefs
可以批量转换
let info = reactive({name: "vue3", age: 18})
// 解构赋值
let {name, age} = info
function setInfo() {
//页面没有响应式变化
// 变化的数据是解构出来的age,而不是info.age
age += 1
}
// 解构赋值
// 底层实现是将每一个属性 使用ref进行转换,都是ref对象
// toRefs可以批量转换
let {name, age} = toRefs(info)
function setInfo() {
// 页面数据可以响应式变化
age.value += 1
}
// toRef只能转换单个
let age = toRef(info,age)
计算属性
根据已有数据计算出新数据(和
Vue2
中的
computed
作用一致)
计算属性是有缓存的,多个场景使用一个计算属性,计算数据不发生变化,则只计算一次
- 只读计算属性
// 导入computed计算属性,是一个函数
import {computed, ref} from "vue"
let name = ref("vue")
let age = ref(20)
// 计算属性
// 只读取的计算属性,不能通过info=xxx这种方式修改info
let info = computed(() => name.value + "-" + age.value)
- 可读可修改计算属性
// 导入computed计算属性,是一个函数
import {computed, ref} from "vue"
let name = ref("vue")
let age = ref(20)
// 计算属性
let info = computed({
get() {
return name + "-" + age
},
set(value) {
// value需要是 xx-xxx的数据格式
// 将数据用-切割
const [str1,str2] = value.split("-")
// 将数据赋值给name和age 触发重新计算 然后生成新的info
name.value = str1
age.value = Number(str2)
}
})
监视属性
- 作用:监视数据的变化(和
Vue2
中的
watch
作用一致)
- 特点:
Vue3
中的
watch
只能监视以下四种数据:
ref
定义的数据。
reactive
定义的数据。- 函数返回一个值(
getter
函数)
- 一个包含上述内容的数组
ref基本数据类型
直接写数据名监视,监视的是该数据value值的改变
// 导入watch
import {watch, ref} from "vue"
let name = ref("vue")
let age = ref(20)
// 监视
// 要监视的属性不需要写.value,回调函数(该属性新值,该属性旧值)
const wa = watch(name, (newValue, oldValue) => {
console.log("新数据",newValue,"旧数据",oldValue)
// 如果新数据 的长度大于等于10的时候,停止监视
if (newValue.length >=10){
// 原理:watch函数会返回一个函数。这个返回的函数实际上是一个用于清理或停止监视操作的句柄
wa()
}
})
ref对象类型数据
监视的是对象的【地址值】,若想监视对象内部的数据,要手动开启深度监视
// 导入watch
import {watch, ref} from "vue"
let info = ref({name: "vue", category: "js"})
// 监视的是对象的内存地址的值
// info.value = {}的时候会触发,修改里面某个属性不好触发
watch(info, (newValue, oldValue) => {
// 如果修改整个对象,newValue是新对象,oldValue是旧对象
console.log(newValue, oldValue)
})
watch的第三个参数是一个配置对象,deep、immediate等等
watch(info, (newValue, oldValue) => {
// 如果修改某个属性,newValue, oldValue两个都是新值,因为他们是同一个对象
// 如果修改整个对象才会是两个对象
console.log(newValue, oldValue)
// deep开启深度监视,修改里面的某个属性 、修改整个对象 都会触发
// immediate在watch函数创建的时候立即执行一次回调函数
},{deep:true,immediate:true})
reactive对象数据类型
监视reactive对象,默认开启了深度监视
import {watch, ref, reactive} from "vue"
let info = reactive({name: "vue", category: "js"})
watch(info, (newValue, oldValue) => {
// newValue, oldValue不管是修改整个对象还是某个属性,都是新值
// 因为修改某个属性值 or Object.assign修改,地址值都没变,都是从同一个对象拿数据,都是新值
console.log(newValue, oldValue)
// 默认开启了深度监视
})
ref或reactive对象数据的某个属性
监视响应式对象中的某个属性,且该属性是基本类型的,要写成函数式(可监视的第三种数据,能返回一个值的函数)
// reactive 和ref创建都可
let info = reactive({
name: "vue", category: "js", address: {
phone: 110,
email: "123213"
}
})
// 监视info对象的name属性,函数式
watch(() => info.name, (newValue, oldValue) => {
// new是新值,old是旧值
console.log(newValue, oldValue)
})
监视响应式对象中的某个属性,且该属性是对象类型的,可以直接写也可以写函数式,推荐函数式
// reactive 和ref创建都可
let info = reactive({
name: "vue", category: "js", address: {
phone: 110,
email: "123213"
}
})
// 直接编写
// address中的某个属性发生变化,可以监视,但是整个对象替换,不会触发监视,即便开启深度监视
watch(info.address, (newValue, oldValue) => {
console.log(newValue,oldValue)
})
// 函数式
// address中的某个属性发生变化,可以监视,整个对象替换,也可以触发监视
// 若是对象监视的是地址值,需要关注对象内部,需要手动开启深度监视
watch(() => info.address, (newValue, oldValue) => {
console.log(newValue, oldValue)
},{deep:true})
监视多个数据
// 监视多个数据,可以放在一个数组里面
watch([() => info.address,()=>info.name], (newValue, oldValue) => {
// newValue和oldValue 是前后的整个info对象
console.log(newValue, oldValue)
},{deep:true})
watchEffect
立即运行一个函数,同时响应式地追踪其依赖,并在依赖更改时重新执行该函数
watch
对比
watchEffect
都能监听响应式数据的变化,不同的是监听数据变化的方式不同
watch
:要明确指出监视的数据
watchEffect
:不用明确指出监视的数据(函数中用到哪些属性,那就监视哪些属性)
// 引入watchEffect
import {watchEffect, ref, reactive} from "vue"
let info = reactive({
name: "vue", category: "js", address: {
phone: 110,
email: "123213"
}
})
let count = ref(0)
// 初始化的时候会首先执行一次,相当于watch的immediate:true
const wa = watchEffect(()=>{
// 函数中用到哪些属性,vue会分析监视哪些属性
if (info.name.length >10){
alert("长度大于10")
// 停止监视
wa()
}
if (count.value === 10){
alert("count")
wa()
}
})
标签中的ref属性
用于注册模版引用
<template>
<!-- 与vue2一样-->
<!-- 用在普通DOM标签上,获取的是DOM节点 -->
<h1 ref="t">title</h1>
<!-- 用在组件标签上,获取的是组件实例对象-->
<UserInfo ref="user"></UserInfo>
<button @click="cli">按钮</button>
</template>
<script setup lang="ts">
import {ref} from "vue";
let t = ref() // ref=t的DOM节点对象,可以直接操作该DOM
let user = ref() // ref=user的组件实例对象
</script>
通过ref获取的组件实例对象,有一个保护措施,在父组件要访问子组件的哪些数据,需要通过defineExpose显示的指定
// 在子组件引入defineExpose
import {ref,defineExpose} from "vue"
// 在子组件显示指定的数据,在父组件通过ref拿到的组件实例对象才可以fang'w
defineExpose([name,age])
props
和vue2的props原理一样,主要是语法上的区别
父组件
<script setup lang="ts" name="App">
import UserInfo from './components/UserInfo.vue'
// 引入自定义类型约束 前面要+ type
import { type UserList} from "@/types";
import { reactive} from "vue";
let users = reactive<UserList>([
{id: "001", name: "1", age: 1},
{id: "002", name: "2", age: 2},
{id: "003", name: "3", age: 3},
]
)
</script>
<template>
<!-- 传递users-->
<UserInfo :list="users"></UserInfo>
</template>
子组件-不约束类型
<script setup lang="ts" name="UserInfo">
import { type UserList} from "@/types";
// import {defineProps} from "vue"
// 看视频教程defineProps需要导入,但是导入后使用有报错,然后看资料不需要导入,不确定是不是和版本有关系
// 不约束类型
defineProps(["list"])
// 如果使用变量接收defineProps,返回值是{传递的key:传递的value}
</script>
<template>
<ul>
<li v-for="user of list" :key="user.id">{{ user.name }}</li>
</ul>
</template>
子组件-约束类型
// 接收list参数,类型是UserList
defineProps<{ list: UserList }>()
子组件-可选以及设置默认值
// 使用withDefaults设置默认值
withDefaults(
// 第一个参数defineProps接收参数,?可行参数是ts语法
defineProps<{ list?: UserList }>(),
// 第二个参数是一个对象,给可选参数设置默认值
{
list: () => [{id: "001", name: "1", age: 1}]
}
)
vue3的生命周期钩子
<script setup lang="ts" name="UserInfo">
// setup函数是创建阶段,在setup语法糖里相当于进入了创建阶段
import {onBeforeMount, onBeforeUnmount, onBeforeUpdate, onMounted, onUnmounted, onUpdated} from "vue";
// 挂载前
onBeforeMount(() => {
console.log("挂载前")
})
// 挂载完毕
onMounted(() => {
console.log("挂载完毕")
})
// 更新前
onBeforeUpdate(() => {
console.log("更新前")
})
// 更新完毕
onUpdated(() => {
console.log("更新完毕")
})
// 卸载前,等同于vue2的销毁
onBeforeUnmount(() => {
console.log("卸载前")
})
// 卸载后
onUnmounted(() => {
console.log("卸载后")
})
</script>
自定义hooks
本质是一个函数,把
setup
函数中使用的
Composition API
进行了封装,类似于
vue2.x
中的
mixin
。
自定义
hook
的优势:复用代码, 让
setup
中的逻辑更清楚易懂
使用use作为hooks文件名的前缀(非强制,社区惯例)
编写hooks文件
import {ref, onMounted, computed} from "vue";
// 整体hooks逻辑写在一个函数里
export default function () {
// 定义响应式数据
let info = ref<number>(1)
// 获取数据
function getDetail() {
return info
}
// 修改数据
function setDetail(value: number) {
info.value = value
}
// 可以写钩子方法
onMounted(() => {
console.log("挂载完毕")
})
// 可以写计算属性
let doubleInfo = computed<number>(() => {
return info.value * 2
})
// 其他的监视属性等等vue方法属性都可以在这里编写
// 将这些方法组合成一个hooks,然后提供给组件使用
// 向外部提供东西
return {getDetail, setDetail,doubleInfo}
}
使用hooks
import useDetail from "@/hooks/useDetail";
const {getDetail,setDetail,doubleInfo} = useDetail()
getDetail()
setDetail(6)