基于百度智能云的OCR接口进行图文识别
由于一些客户的内部系统需要提取一些记录信息,如果手工录入会变得比较麻烦,因此考虑使用百度云的OCR进行图片文字的提取处理,综合比较了一下开源免费的Tesseract 类库进行处理,不过识别效果不太理想,因此转为了百度的OCR云接口处理方式,测试的效果比较理想,基本上较少出现错别字。本篇随笔介绍如何利用百度OCR进行图片文字的提取处理,以便从别的系统中批量化获得响应的系统数据,然后进行相应的格式化处理。
1、百度OCR服务申请
百度的OCR接口调用是收费的接口,不过一般是在超过一定量的情况后进行收费,我们可以申请获得每月免费的额度。
百度智能云地址:
https://login.bce.baidu.com/
首先我们去到百度智能云里,在左边菜单栏的产品服务中搜索"文字识别",点击【领取免费资源】,将所有的免费资源领取,领取之后要半个小时之后才能生效。

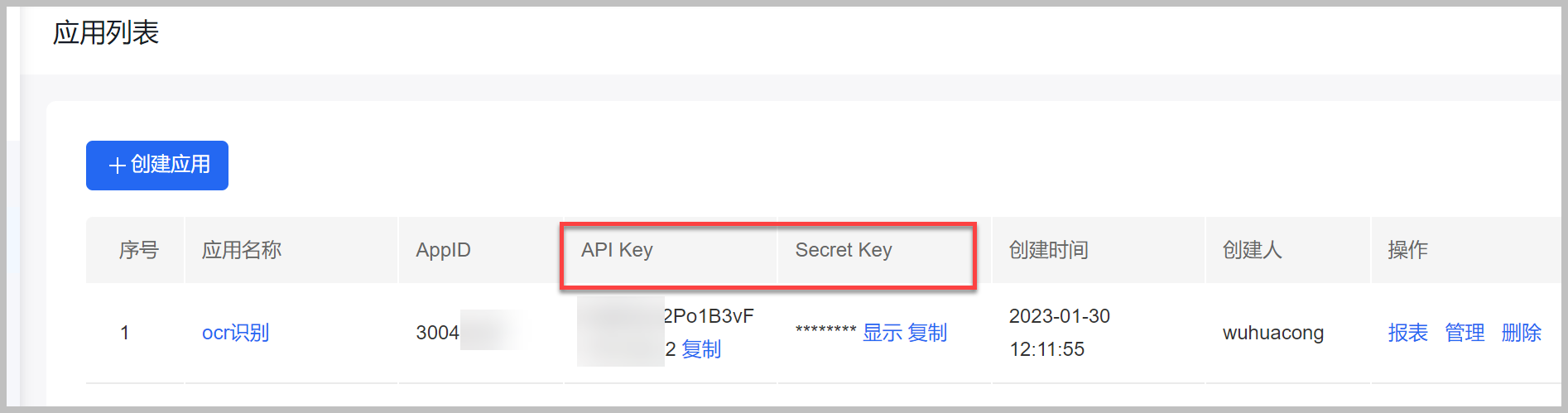
回到主面板,我们要进行创建应用,填写相关的信息即可创建成功,应用创建好之后会生成AppID、API Key和Secret Key,使用百度AI的SDK,使用API Key和Secret Key参数接口调用处理!
2、项目测试/接口调用
创建一个Winform的测试项目及性能接口的调用测试,在Nuget上添加对应的Baidu.AI的SDK包,以及Json.NET的类库,如下所示。
设计一个界面,对图片文件的内容进行识别处理。
具体测试的代码如下所示。
private void btnLoadImage_Click(objectsender, EventArgs e)
{var imageFile = FileDialogHelper.OpenImage(false, "");if(imageFile != null)
{var str =BaiduOcr(imageFile);//var str = TesseractOcr(imageFile); this.txtResuilt.Text =str;
}
}private static string BaiduOcr(stringimageFile)
{var APIKey = "**********";var SecretKey = "********";var ocr = newBaidu.Aip.Ocr.Ocr(APIKey, SecretKey);var currentImage =FileUtil.FileToBytes(imageFile);var result =ocr.Accurate(currentImage);string str = string.Empty;var txts = (from obj in (JArray)result.Root["words_result"]select (string)obj["words"]).ToList();string startString = "手术助手";int startIndex = 0;for (int i = 0; i < txts.Count(); i++)
{if (txts[i] ==startString)
{
startIndex= i; //记录二维表的开始位置 }
}var newList = txts.Skip(startIndex + 1).ToList();
str= string.Join("\r\n", newList);returnstr;
}
如系统界面的图片如下所示。
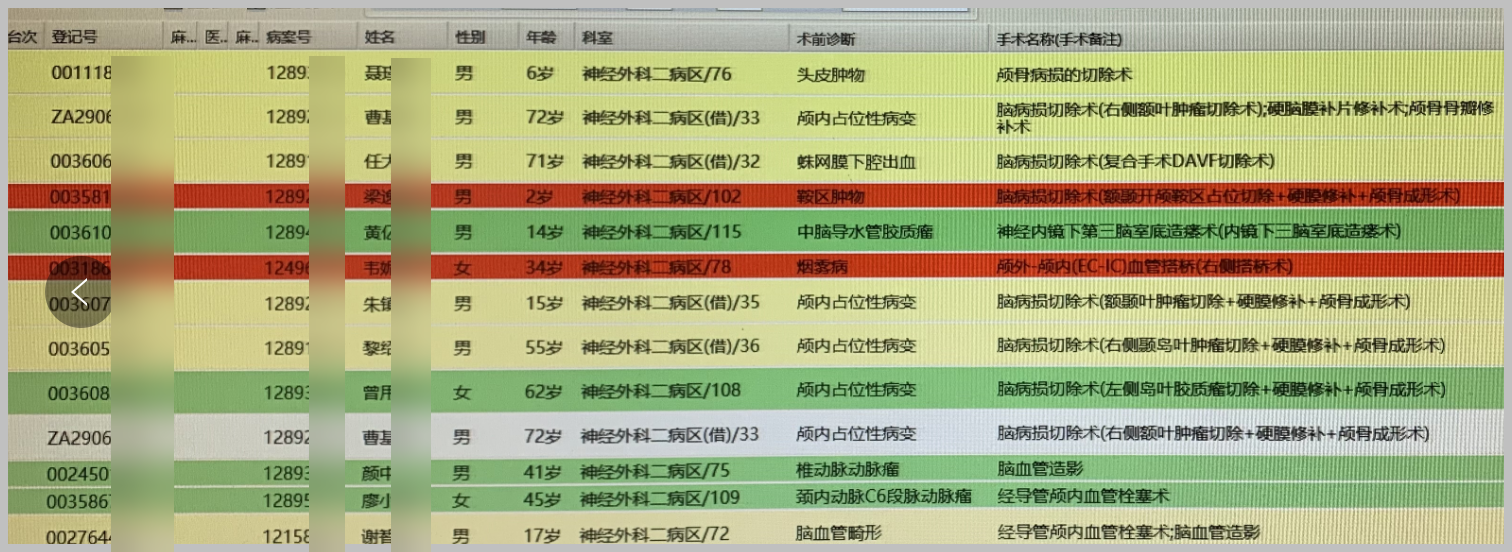
使用百度OCR接口进行测试,可以看到具体的测试结果即可,然后根据结果进行格式化的转换就可以输出对应Excel格式或者其他格式了
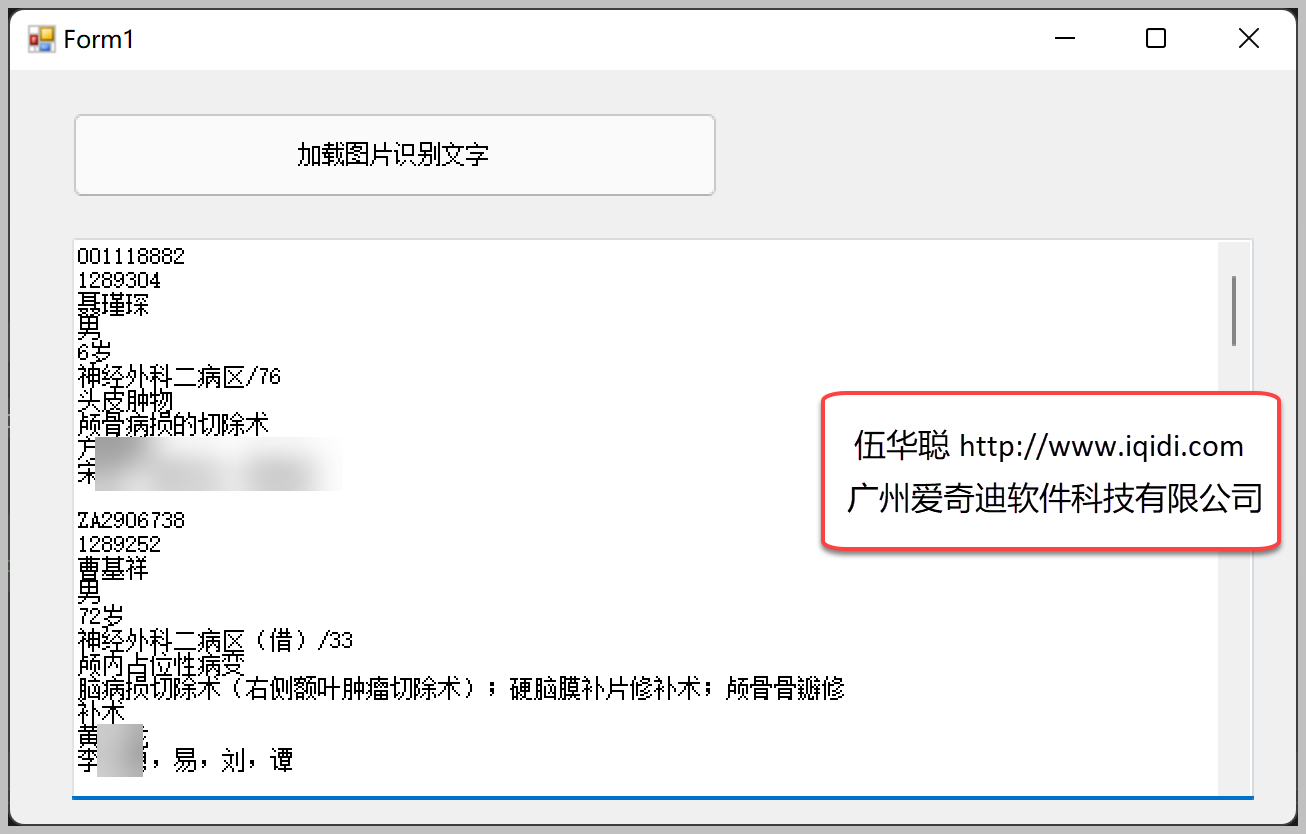
能够获取列表的记录,进行相应的处理即可,这样可以减少数据提取或者录入的时间,通过OCR的自动化处理,可以极大的提高数据的处理效率。