WPS或xls 数据分列 清洗
一 、一般分离
时间:2017年11月27日14:55:12 数据如下:
501陈**:田莨铺58
502陈**:田莨铺58
503陈**。六麻杨冲58元
504陈**。石脚哗。200元
505陈**。中垌。58元
506陈**。中垌。58元
509陈**。河浪。108元
要分成 序号可以排序,屋名可以排序,金额可以排序。所以要分成四列,后面并且有元字。
分列前进行清洗整理数据:
1、陈字之前 替换多一个空格,
2、先去掉元字
3、地址前后添加多一个空格,【可以用替换的方式】
分列:
把数据放在A列,ctrl+shift +向下箭头 全选一列。使用xls中的 :数据--分列
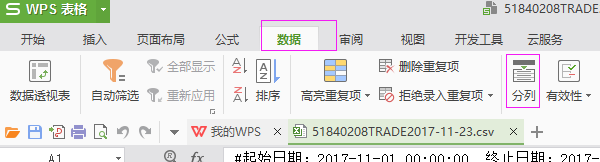
选择好分隔符号

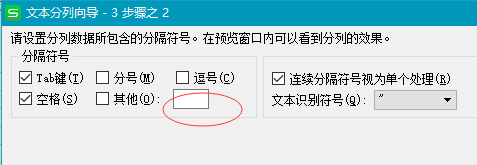
排序:选择全部数据,自定义排序。选择第一个排序 再选择第二个排序--->完成!
二、只是统计一篇文本中的金额总数
,有其他数字干扰===2017年12月8日14:38:32

某一天需要帮忙核对数据的总数,而不需要进行太花哨的整理:
采用快速去除其他文字,留下数字的方法:(提取数据)
陈字 前面加上& 用陈替换成 &陈,
采用xls 数字-分列 分隔符 &
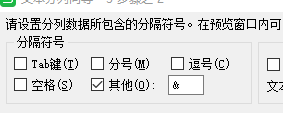
去除序号,这样就去除了干扰数字。把右边部分的放到新的xls,利用公式提取所有数字和小数点出来。注意是否还有其他干扰的数字,如果有要想办法去掉。
=LOOKUP(9E+307,--MID(
A1
,MIN(FIND({0;1;2;3;4;5;6;7;8;9},
A1
&1234567890)),ROW($1:$1022))) 数据放在A列,此公式放在B1单元格,
注意公式里面的A1(相对A1取值)
,下拉。即得到所有数据。

全选B列 即可得到总数,谢谢各位看官
===2017年12月13日10:01:23 用 nodepad++工具 中用正则替换掉中文
准备工作:先安装nodepad++ 工具,和到下方网站看看,获取你需要的正则表达式

在线正则表达式测试
http://tool.oschina.net/regex#
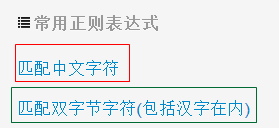
本人用第一个正则表达式 [\u4e00-\u9fa5] 替换有问题;选择第二个的正则表达式是:[^\x00-\xff]
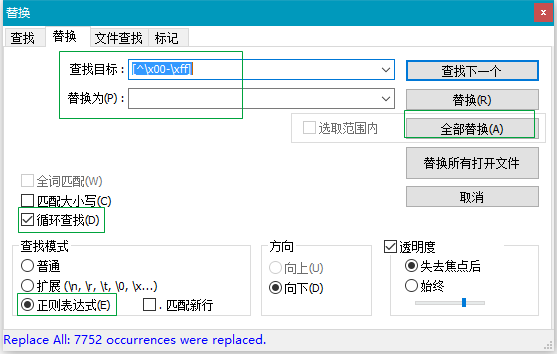
实际操作:还是要先吧序号去掉,上面截图的设置,全部替换后:
替换后还会有英文的 :号存在,因为英文下的“:”不是双字节,也再次把:替换为空。
此时有很多空格存在, 编辑--空白操作--移除行首和行尾空格。把整列复制到xls统计。
有时候会反过来操作,要去掉数字保留文字 ,可以正则 \d 替换问空字符即可。
==待续》。。
拓展:需要配合正则快速剔除 文本 或数字技能,各种替换
整列复制 ctrl +左键+十字光标(放上去边界变成十字是左键拖动)
整列移动 shift +左键+十字光标(放上去边界变成十字是左键拖动)
====筛选出某一批序号在一个表格里面的位置(整批找出)
如果需要用到 用到countif 函数
WPS 表格筛选两列相同数据-完美-2017年11月1日更新 - 海蓝steven - 博客园
http://www.cnblogs.com/rogge7/p/5227890.html