ABAP READ内表新老语法对比
1、读取内表行新语法
740新语法中,对标READ,提出了新的语法,如下:
1.1、根据字段值查找
"-----------------------------@斌将军-----------------------------"老语法 READ TABLE lt_acd INTO ls_acd WITH KEY rbukrs = gs_acd-rbukrs.IF sy-subrc EQ 0.ENDIF."新语法 ls_acd = lt_acd[ rbukrs = gs_acd-rbukrs ]."-----------------------------@斌将军-----------------------------
1.2、按索引查找
"-----------------------------@斌将军-----------------------------"老语法 READ TABLE lt_acd INTO ls_acd INDEX 1.IF sy-subrc EQ 0.ENDIF."新语法 ls_acd = lt_acd[ 1]."-----------------------------@斌将军-----------------------------
1.3、判断记录是否存在
"-----------------------------@斌将军-----------------------------"老语法 READ TABLE lt_acd WITH KEY rbukrs = gs_acd-rbukrs TRANSPORTING NO FIELDS.IF sy-subrc EQ 0.ENDIF."新语法 IF LINE_EXISTS( lt_acd[ rbukrs = gs_acd-rbukrs ] ).ENDIF."-----------------------------@斌将军-----------------------------
1.4、获取行索引
"-----------------------------@斌将军-----------------------------"老语法 READ TABLE lt_acd WITH KEY rbukrs = gs_acd-rbukrs TRANSPORTING NO FIELDS.IF sy-subrc EQ 0.WRITE:SY-TABIX.ENDIF."新语法 LV_INDEX = LINE_INDEX( lt_acd[ rbukrs = gs_acd-rbukrs ] )."-----------------------------@斌将军-----------------------------
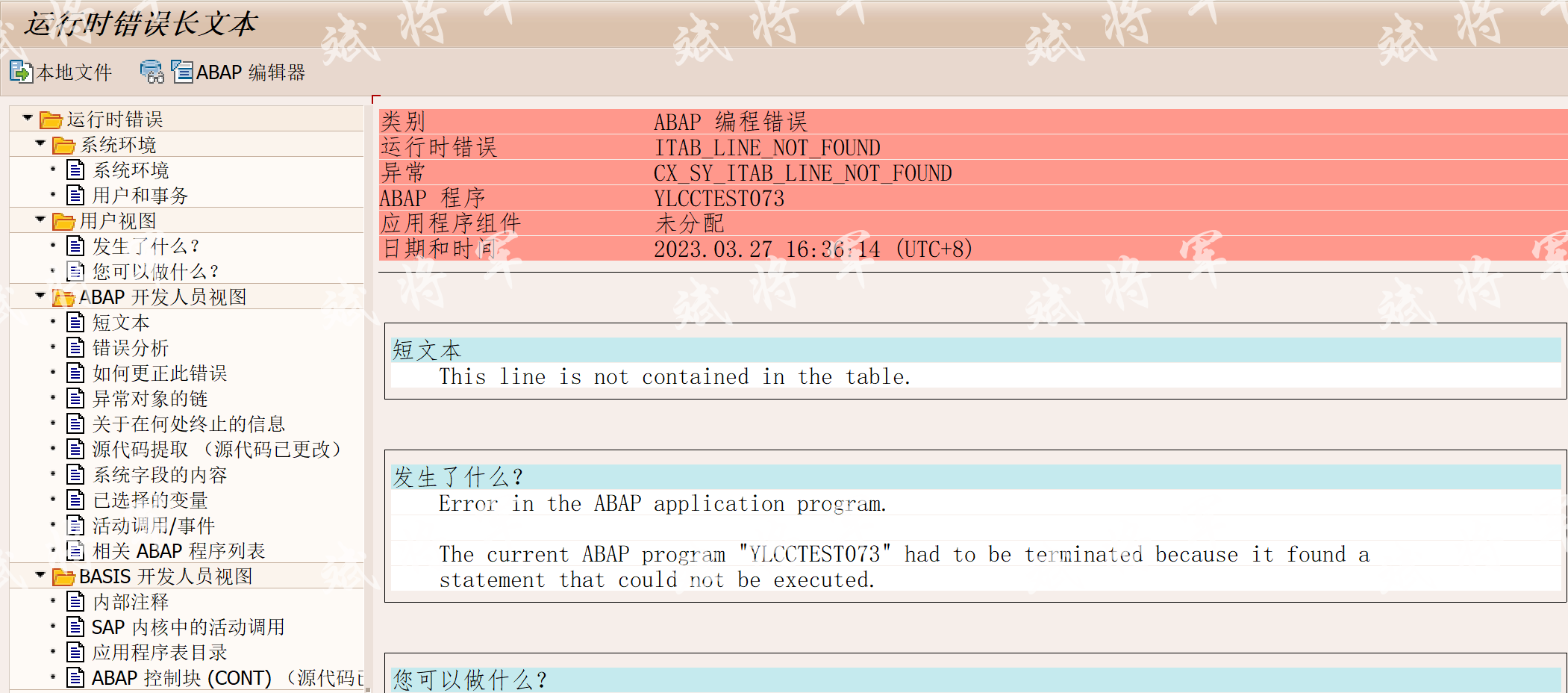
需要特别注意的是,新语法必须用TRY CATCH,或在查询前,用LINE_EXISTS()判断是否存在,否则将会导致DUMP
TRY.
ls_acd= lt_acd[ rbukrs = '333'].CATCHcx_sy_itab_line_not_found .MESSAGE '未找到数据' TYPE 'E'.ENDTRY."或 IF line_exists( lt_acd[ rbukrs = '333'] ).
ls_acd= lt_acd[ rbukrs = '333'].ELSE.MESSAGE '未找到数据' TYPE 'E'.ENDIF.
2.效率对比
由于老语法可以使用二分法查找,因此在效率上将会有差异。
现编写一个实例,循环2万条数据GT_ACD,并循环查询有14万条数据的LT_ACD中对应的值。下边测试各种情况下的查询速度
2.1、新语法
"-----------------------------@斌将军-----------------------------"1.测试新语法------------------------------------ GET TIME STAMP FIELDlv_current1.CLEAR:lv_index.LOOP AT gt_acd INTOgs_acd.
lv_index= lv_index + 1.TRY.
ls_acd= lt_acd[ rbukrs = gs_acd-rbukrs gjahr = gs_acd-gjahr belnr = gs_acd-belnr docln = gs_acd-docln ].CATCHcx_sy_itab_line_not_found .MESSAGE '未找到数据' TYPE 'E'.ENDTRY.ENDLOOP.GET TIME STAMP FIELDlv_current2."-----------------------------@斌将军-----------------------------
结果:

2.2、老语法READ
"-----------------------------@斌将军-----------------------------"2.测试老语法------------------------------------ GET TIME STAMP FIELDlv_current1.CLEAR:lv_index.LOOP AT gt_acd INTOgs_acd.
lv_index= lv_index + 1.READ TABLE lt_acd INTO ls_acd WITH KEY rbukrs = gs_acd-rbukrs
gjahr= gs_acd-gjahr
belnr= gs_acd-belnr
docln= gs_acd-docln.IF sy-subrc EQ 0.ENDIF.ENDLOOP.GET TIME STAMP FIELDlv_current2."-----------------------------@斌将军-----------------------------
结果:

2.3、老语法READ二分查找
"-----------------------------@斌将军----------------------------- GET TIME STAMP FIELDlv_current1.CLEAR:lv_index.SORT lt_acd BYrbukrs gjahr belnr docln.LOOP AT gt_acd INTOgs_acd.READ TABLE lt_acd INTO ls_acd WITH KEY rbukrs = gs_acd-rbukrs
gjahr= gs_acd-gjahr
belnr= gs_acd-belnr
docln= gs_acd-docln BINARY SEARCH.IF sy-subrc EQ 0.
lv_index= lv_index + 1.ENDIF.ENDLOOP.GET TIME STAMP FIELDlv_current2."-----------------------------@斌将军-----------------------------
结果:< 1S

2.4、新语法+排序表
"-----------------------------@斌将军-----------------------------"4.测试新语法+排序表------------------------------------ lt_acd_sort =lt_acd.GET TIME STAMP FIELDlv_current1.CLEAR:lv_index.LOOP AT gt_acd INTOgs_acd.
lv_index= lv_index + 1.TRY.
ls_acd= lt_acd_sort[ rbukrs = gs_acd-rbukrs gjahr = gs_acd-gjahr belnr = gs_acd-belnr docln = gs_acd-docln ].CATCHcx_sy_itab_line_not_found .MESSAGE '未找到数据' TYPE 'E'.ENDTRY.ENDLOOP.GET TIME STAMP FIELDlv_current2."-----------------------------@斌将军-----------------------------
结果:< 1S

综上所述:不使用二分查找,则新老语法都很慢。使用二分查找或新语法搭配排序表,则速度都有非常明显的提升