DataLeap 数据资产实战:如何实现存储优化?
更多技术交流、求职机会,欢迎关注
字节跳动数据平台微信公众号,回复【1】进入官方交流群
背景
DataLeap 作为一站式数据中台套件,汇集了字节内部多年积累的数据集成、开发、运维、治理、资产、安全等全套数据中台建设的经验,助力企业客户提升数据研发治理效率、降低管理成本。
Data Catalog 是一种元数据管理的服务,会收集技术元数据,并在其基础上提供更丰富的业务上下文与语义,通常支持元数据编目、查找、详情浏览等功能。目前 Data Catalog 作为火山引擎大数据研发治理套件 DataLeap 产品的核心功能之一,经过多年打磨,服务于字节跳动内部几乎所有核心业务线,解决了数据生产者和消费者对于元数据和资产管理的各项核心需求。
Data Catalog 系统的存储层,依赖 Apache Atlas,传递依赖 JanusGraph。JanusGraph 的存储后端,通常是一个 Key-Column-Value 模型的系统,本文主要讲述了使用 MySQL 作为 JanusGraph 存储后端时,在设计上面的思考,以及在实际过程中遇到的一些问题。
起因
实际生产环境,我们使用的存储系统维护成本较高,有一定的运维压力,于是想要寻求替代方案。在这个过程中,我们试验了很多存储系统,其中 MySQL 是重点投入调研和开发的备选之一。
另一方面,除了字节内部外,在 ToB 场景,MySQL 的运维成本也会明显小于其他大数据组件,如果 MySQL 的方案跑通,我们可以在 ToB 场景多一种选择。
基于以上两点,我们投入了一定的人力调研和实现基于 MySQL 的存储后端。
方案评估
在设计上,JanusGraph 的存储后端是可插拔的,只要做对应的适配即可,并且官方已经支持了一批存储系统。结合字节的技术栈以及我们的诉求,做了以下的评估。
各类存储系统比较
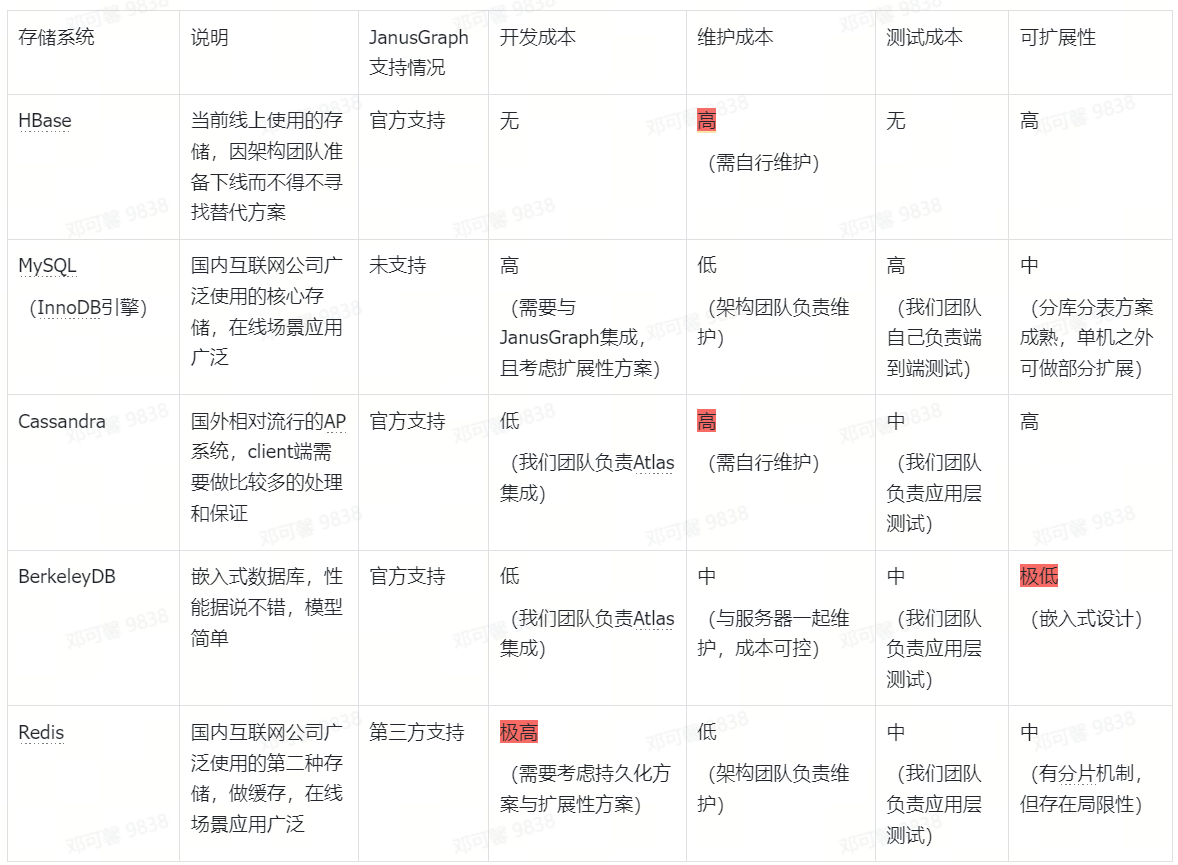
因投入成本过高,我们不接受自己运维有状态集群,排除了 HBase 和 Cassandra;
从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了 BerkeleyDB;
同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了 Redis。
最终我们挑选了 MySQL 来推进到下一步。
MySQL 的理论可行性
可以支持 Key-Value(后续简称 KV 模型)或者 Key-Column-Value(后续简称 KCV 模型)的存储模型,聚集索引 B+树排序访问,支持基于 Key 或者 Key-Column 的 Range Query,所有查询都走索引,且避免内存中重排序,效率初步判断可接受。
中台内的其他系统,最大的 MySQL 单表已经到达亿级别,且 MySQL 有成熟的分库分表解决方案,判断数据量可以支持。
在具体使用场景中,对于写入的效率要求不高,因为大量的数据都是离线任务完成,判断 MySQL 在写入上的效率不会成为瓶颈。
总体设计

维护一张 Meta 表做 lookup 用,Meta 表中存储租户与 DataSource(库)之间的映射关系,以及 Shards 等租户级别的配置信息。
StoreManager 作为入口,在 openTransaction 的时候将租户信息注入到 StoreTransaction 中,并返回租户级别的 DataSource。
StoreManager 中以 name 为 Key,维护一组 Store,Store 与存储的数据类型有关,具有跨租户能力
常见的 Store 有
system_properies
,
tx_log
,
graphindex
,
edgestore
等对于 MySQL 最终的读写,都收敛在 Store,方法签名中传入 StoreTransaction,Store 从中取出租户信息和数据库连接,进行数据读写。
对于单租户来说,数据可以分表(shards),对于某个特定的 key 来说,存储和读取某个 shard,是根据 ShardManager 来决定
典型的 ShardManager 逻辑,是根据总 shard 数对 key 做 hash 决定,默认单分片。
对于每个 Store,表结构是 4 列(id, g_key, g_column, g_value),除自增 ID 外,对应 key-column-value model 的数据模型,key+column 是一个聚集索引。
Context 中的租户信息,需要在操作某个租户数据之前设置,并在操作之后清除掉。
细节设计与疑难问题
细节设计
存储模型
JanusGraph 要求 column-family 类型存储(如 Cassandra, HBase),也就是说,数据存储由一系列行组成,每行都由一个键(key)唯一标识,每行由多个列值(column-value)对组成,也会对列进行排序和过滤,如果是非 column-family 的类型存储,则需要另行适配,适配时数据模型有两种方式:Key-Column-Value 和 Key-Value。

KCV 模型:
会将 key\column\value 在存储中区分开来。
对应的接口为:
KeyColumnValueStoreManager
。
KV 模型:
在存储中仅有 key 和 value 两部分,此处的 key 相当于 KVC 模型中的 key+column;
如果要根据 column 进行过滤,需要额外的适配工作;
对应的接口为:
KeyValueStoreManager
,该接口有子类
OrderedKeyValueStoreManager
,提供了保证查询结果有序性的接口;同时提供了
OrderedKeyValueStoreManagerAdapter
接口,用于对 Key-Column-Value 模型进行适配,将其转化为 Key-Value 模型。
MySQL 的存储实现采用了 KCV 模型,每个表会有 4 列,一个自增的 ID 列,作为主键,同时还有 3 列分别对应模型中的 key\column\value,数据库中的一条记录相当于一个独立的 KCV 结构,多行数据库记录代表一个点或者边。
表中 key 和 column 这两列会组成联合索引,既保证了根据 key 进行查询时的效率,也支持了对 column 的排序以及条件过滤。
多租户
存储层面:默认情况下,JanusGraph 会需要存储
edgestore
,
graphindex
,
system_properties
,
txlog
等多种数据类型,每个类型在 MySQL 中都有各自对的表,且表名使用租户名作为前缀,如
tenantA_edgestore
,这样即使不同租户的数据在同一个数据库,在存储层面租户之间的数据也进行了隔离,减少了相互影响,方便日常运维。(理论上每个租户可以单独分配一个数据库)
具体实现:每个租户都会有各自的 MySQL 连接配置,启动之后会为各个租户分别初始化数据库连接,所有和 JanusGraph 的请求都会通过 Context 传递租户信息,以便在操作数据库时选择该租户对应的连接。
具体代码:
MysqlKcvTx:实现了
AbstractStoreTransaction
,对具体的 MySQL 连接进行了封装,负责和数据库的交互,它的
commit
和
rollback
方法由封装的 MySQL 连接真正完成。MysqlKcvStore:实现了
KeyColumnValueStore
,是具体执行读写操作的入口,每一个类型的 Store 对应一个
MysqlKcvStore
实例,
MysqlKcvStore
处理读写逻辑时,根据租户信息完全自主组装 SQL 语句,SQL 语句会由
MysqlKcvTx
真正执行。MysqlKcvStoreManager:实现了
KeyColumnValueStoreManager
,作为管理所有 MySQL 连接和租户的入口,也维护了所有 Store 和
MysqlKcvStore
对象的映射关系。在处理不同租户对不同 Store 的读写请求时,根据租户信息,创建
MysqlKcvTx
对象,并将其分配给对应的
MysqlKcvStore
去执行。
事务
几乎所有与 JanusGraph 的交互都会开启事务,而且事务对于多个线程并发使用是安全的,但是 JanusGraph 的事务并不都支持 ACID,是否支持会取决于底层存储组件,对于某些存储组件来说,提供可序列化隔离机制或者多行原子写入代价会比较大。
JanusGraph 中的每个图形操作都发生在事务的上下文中,根据 TinkerPop 的事务规范,每个线程执行图形上的第一个操作时便会打开针对图形数据库的事务,所有图形元素都与检索或者创建它们的事务范围相关联,在使用
commit
或者
rollback
方法显式的关闭事务之后,与该事务关联的图形元素都将过时且不可用。
JanusGraph 提供了
AbstractStoreTransaction
接口,该接口包含
commit
和
rollback
的操作入口,在 MySQL 存储的实现中,
MysqlKcvTx
实现了
AbstractStoreTransaction
,对具体的 MySQL 连接进行了封装,在其
commit
和
rollback
方法中调用 SQL 连接的
commit
和
rollback
方法,以此实现对于 JanusGraph 事务的支持。
public classMysqlKcvTx extends AbstractStoreTransaction {private static final Logger log = LoggerFactory.getLogger(MysqlKcvTx.class);privatefinal Connection connection;
@Getterprivatefinal String tenant;publicMysqlKcvTx(BaseTransactionConfig config, String tenant, Connection connection) {
super(config);this.tenant =tenant;this.connection =connection;
}
@Overridepublic synchronized voidcommit() {try{if(Objects.nonNull(connection)) {
connection.commit();
connection.close();
}if(log.isDebugEnabled()) {
log.debug("tx has been committed");
}
}catch(SQLException e) {
log.error("failed to commit transaction", e);
}
}
@Overridepublic synchronized voidrollback() {try{if(Objects.nonNull(connection)) {
connection.rollback();
connection.close();
}if(log.isDebugEnabled()) {
log.debug("tx has been rollback");
}
}catch(SQLException e) {
log.error("failed to rollback transaction", e);
}
}publicConnection getConnection() {returnconnection;
}
}
数据库连接池
Hikari 是 SpringBoot 内置的数据库连接池,快速、简单,做了很多优化,如使用 FastList 替换 ArrayList,自行研发无所集合类 ConcurrentBag,字节码精简等,在性能测试中表现的也比其他竞品要好。
Druid 是另一个也非常优秀的数据库连接池,为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防 SQL 注入,内置 Loging 能诊断 Hack 应用行为。
关于两者的对比很多,此处不再赘述,虽然 Hikari 的性能号称要优于 Druid,但是考虑到 Hikari 监控功能比较弱,最终在实现的时候还是选择了 Druid。
疑难问题
连接超时
现象:在进行数据导入测试时,服务报错" The last packet successfully received from the server was X milliseconds ago",导致数据写入失败。
原因:存在超大 table(有 8000 甚至 10000 列),这些 table 的元数据处理非常耗时(10000 列的可能需要 30 分钟),而且在处理过程中有很长一段时间和数据库并没有交互,数据库连接一直空闲。
解决办法:
调整 mysql server 端的 wait_timeout 参数,已调整到 3600s。
调整 client 端数据库配置中连接的最小空闲时间,已调整到 2400s。
分析过程:
怀疑是 mysql client 端没有增加空闲清理或者保活机制,conneciton 在线程池中长时间没有使用,mysql 服务端已经关闭该链接导致。尝试修改客户端 connection 空闲时间,增加 validationQuery 等常见措施,无果;
根据打点发现单条消息处理耗时过高,疑似线程卡死;
新增打点发现线程没卡死,只是在执行一些非常耗时的逻辑,这时候已经获取到了数据库连接,但是在执行那些耗时逻辑的过程中和数据库没有任何交互,长时间没有使用数据库连接,最终导致连接被回收;
调高了 MySQL server 端的 wait_timeout,以及 client 端的最小空闲时间,问题解决。
并行写入死锁
现象:线程 thread-p-3-a-0 和线程 thread-p-7-a-0 在执行过程中都出现 Deadlock。
具体日志如下:
原因:
结合日志分析,两个线程并发执行,需要对同样的多个记录加锁,但是顺序不一致,进而导致了死锁。
55A0
这个 column 对应的 property 是"__modificationTimestamp",该属性是 atlas 的系统属性,当对图库中的点或者边有更新时,对应点或者边的"__modificationTimestamp"属性会被更新。在并发导入数据的时候,加剧了资源竞争,所以会偶发死锁问题。
解决办法:
业务中并没有用到"__modificationTimestamp"这个属性,通过修改 Atlas 代码,仅在创建点和边的时候为该属性赋值,后续更新时不再更新该属性,问题得到解决。
性能测试
环境搭建
在字节内部 JanusGraph 主要用作 Data Catalog 服务的存储层,关于 MySQL 作为存储的性能测试并没有在 JanusGraph 层面进行,而是模拟 Data Catalog 服务的业务使用场景和数据,使用业务接口进行测试,主要会关注接口的响应时间。
接口逻辑有所裁剪,在不影响核心读写流程的情况下,屏蔽掉对其他服务的依赖。
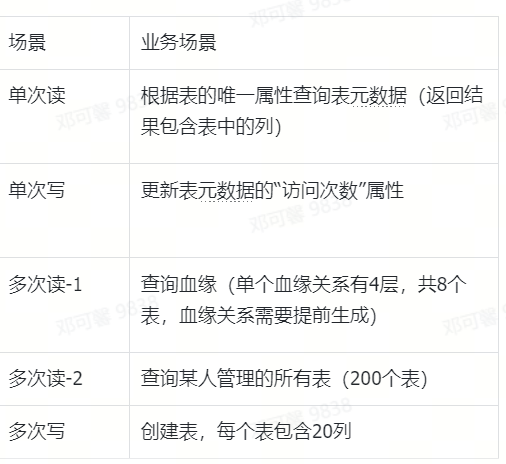
模拟
单租户表单分片情况下,库表元数据创建、更新、查询,表之间血缘关系的创建、查询,以此反映在图库单次读写和多次读写情况下 MySQL 的表现。
整个测试环境搭建在火山引擎上,总共使用 6 台 8C32G 的机器,硬件条件如下:

测试场景如下:
测试结论
总计 10 万个表(库数量为个位数,可忽略)
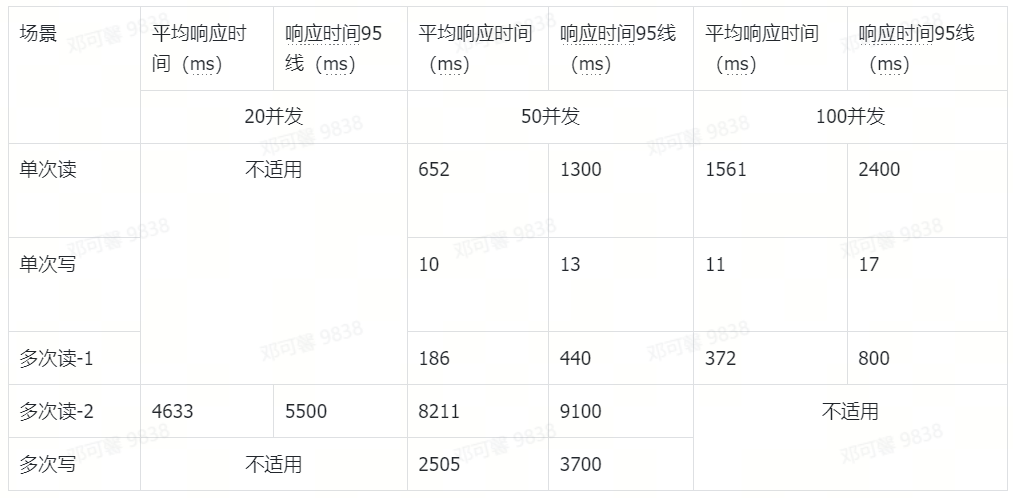
在 10 万个表且模拟了表之间血缘关系的情况下,
graphindex
表的数据量已有 7000 万,
edgestore
表的数据量已有 1 亿 3000 万,业务接口的响应时间基本在预期范围内,可满足中小规模 Data Catalog 服务的存储要求。
总结
MySQL 作为 JanusGraph 的存储,有部署简单,方便运维等优势,也能保持良好的扩展性,在中小规模的 Data Catalog 存储服务中也能保持较好的性能水准,可以作为一个存储选择。
市面上也有比较成熟的 MySQL 分库分表方案,未来可以考虑将其引入,以满足更大规模的存储需求。
火山引擎 Data Catalog 产品是基于字节跳动内部平台,经过多年业务场景和产品能力打磨,在公有云进行部署和发布,期望帮助更多外部客户创造数据价值。目前公有云产品已包含内部成熟的产品功能同时扩展若干 ToB 核心功能,正在逐步对齐业界领先 Data Catalog 云产品各项能力。
点击跳转
大数据研发治理DataLeap
了解更多