算法(第4版)练习题1.1.27的三种解法
本文列举了对于
算法 : 第4版 / (美) 塞奇威客 (Sedgewick, R.) , (美) 韦恩 (Wayne, K.) 著 ; 谢路云译. -- 北京 : 人民邮电出版社, 2012.10 (2021.5重印)
(以下简称原书或书)中的练习题 1.1.27 的三种解法(C++ 实现),并对包含原书题中的递归方法在内的四种解法的执行时间进行了统计和对比。
◆ 要求
原书中的练习题 1.1.27 要求对如下二项分布递归过程中的值保存在数组中,
b(n,k,p) = 1.0 ( n == 0 && k == 0 )
b(n,k,p) = 0.0 ( n < 0 || k < 0 )
b(n,k,p) = (1.0-p) * b(n-1,k,p) + p * b(n-1,k-1,p)
◆ 解一
依然采用递归的方式,但使用二维数组保存中间结果。
如下代码所示,
static long double binomial1(int N, int K, long double p) // #1
{
long double x;
long double** b = new long double*[N+1]; // #2
long double* data = new long double[(N+1)*(K+1)];
...
x = binomial1_impl(b, N, K, p); // #3
...
return x;
}
static long double binomial1_impl(long double** b, int N, int K, long double p)
{
if (N == 0 && K == 0) return 1.0L;
if (N < 0 || K < 0) return 0.0L;
if (b[N][K] == -1) {
... // #4
b[N][K] = (1.0L-p) * binomial1_impl(b, N-1, K, p) + p * binomial1_impl(b, N-1, K-1, p);
}
return b[N][K];
}
保持对外的接口不变(#1),创建一个二维数组 b[0..N][0..K] 保存中间计算结果(#2),并将其传给算法实现(#3)。算法虽然还是用递归调用(#4),但由于中间结果保存在全局的二维数组中,不用频繁地压栈和弹栈去获取中间数据。此解法网络上也见于
[github] reneargento/algorithms-sedgewick-wayne
和
[github] aistrate/AlgorithmsSedgewick
。
◆ 解二
使用二维数组保持中间结果,但同时将递归改进为递推。若以横向为 x 轴,纵向为 y 轴,左上角为坐标原点,则坐标轴上的 (x,y) 点则代表二维数组的 b[y][x] 单元。
以 N = K = 4 为例,
0 1 2 3 4
0 * * * * * <-- * 代表待计算的单元
1 * * * * *
2 * * * * *
3 * * * * *
4 * * * * ? <-- 最终计算结果的单元 (4,4)
仔细考察递归关系式的特点,b(-1,*,p) = 0.0, b(*,-1,p) = 0.0。由
b(0,1,p) = (1.0-p) * b(-1,1,p) + p * b(-1,0,p)
= (1.0-p) * 0.0 + p * 0.0
= 0.0
b(0,2,p) = (1.0-p) * b(-1,1,p) + p * b(-1,1,p)
= (1.0-p) * 0.0 + p * 0.0
= 0.0
...
可推论出,二维数组中的第 0 行中的所有单元(不含b[0][0])均为 0.0;由
b(1,0,p) = (1.0-p) * b(0,0,p) + p * b(0,-1,p)
= (1.0-p) * 1.0 + p * 0.0
= 1.0-p
b(2,0,p) = (1.0-p) * b(1,0,p) + p * b(1,-1,p)
= (1.0-p) * (1.0-p) + p * 0.0
= (1.0-p)^2
...
可推论出,二维数组中的第 0 列的单元为 (1.0-p)^y。
因为每个单元 b[n][k] 结果(n 代表行号,k 代表列号),依赖于 b[n-1][k-1] 和 b[n-1][k] 的结果。为了减少计算量,递推过程可仅用到二维数组的部分单元。笔者设置一个 G 点,将待计算单元的区域划分为 '#' 和 '*' 两部分,G 点在 '#' 区域中。分为以下三种情况,
第一种情况,N < K:(如 N = 4, K = 6)
0 1 2 3 4 5 6
0 - - G # # # # <-- G 点所在单元为 0.0
1 - - - * * * * <-- '-' 代表不用计算的单元
2 - - - - * * *
3 - - - - - * *
4 - - - - - - ? <-- 最终结果的存储单元
G 点为 b(0,K-N)。按照递推关系式容易推导出,'#' 和 '*' 区域均为 0.0,所以最终结果即 0.0。
第二种情况,N = k:(如 N = 6, K = 6)
0 1 2 3 4 5 6
0 G # # # # # # <-- G 点所在单元为 1.0
1 - * * * * * *
2 - - * * * * *
3 - - - * * * *
4 - - - - * * *
5 - - - - - * *
6 - - - - - - ?
G 点为 b(0,0)。按照递推关系式容易推导出,数组中 n = k 的单元为 p^n。所以最终结果即 p^N。
第三种情况,N > K:(如 N = 6, K = 4)
0 1 2 3 4
0 # # # # #
1 # # # # #
2 G # # # # <-- G 点所在单元为 (1.0-p)^2
3 - * * * *
4 - - * * *
5 - - - * *
6 - - - - ?
G 点为 b(N-K,0)。可先计算 '#' 区域中的单元,再计算 '*' 区域中的单元,得出最终结果。处理'#'区域时,为避免大量的数组下标越界判断,可以考虑先计算 0 行和 0 列的所有单元。
如下代码所示,
static long double binomial2(int N, int K, long double p)
{
long double x;
if (N < K) { // #1
x = 0.0L;
} else if (N == K) { // #2
x = powl(p, N);
} else { // #3
...
b[0][0] = 1.0L;
// process '#' area // #4
// calcuate [1..N-K][0]
for (i = 1; i <= N-K; ++i)
b[i][0] = powl(1.0L-p, i);
// calcuate [0][1..K]
for (j = 1; j <= K; ++j)
b[0][j] = 0.0L;
// calcuate [1..N-K][1..K]
for (i = 1; i <= N-K; ++i)
for (j = 1; j <= K; ++j)
b[i][j] = (1.0L-p) * b[i-1][j] + p * b[i-1][j-1];
// process '*' area // #5
for (i = N-K+1; i <= N; ++i)
for (j = i-(N-K); j <= K; ++j)
b[i][j] = (1.0L-p) * b[i-1][j] + p * b[i-1][j-1];
x = b[N][K]; // #6
...
}
return x;
}
三条分支(#1、#2、#3)分别对应前述三种情况。在第三种情况下,再先处理 '#' 区域(#4),然后采用递推求值的方式处理 '*' 区域(#5),最后得到结果(#6)。
◆ 解三
此方法是从递推解法中引申出来了。进一步探究这个此二项分布的递归式,以 N = 4 且 K = 4 为例,
0 1 2 3 4
0 1.0
1 1.0-p p
2 (1.0-p)^2 2*(1.0-p)*p p^2
3 (1.0-p)^3 3*[(1.0-p)^2]*p 3*(1-p)*(p^2) p^3
4 (1.0-p)^4 4*[(1.0-p)^3]*p 6*[(1.0-p)^2]*(p^2) 4*(1.0-p)*(p^3) p^4
可以发现,从第 0 行到第 N 行的非零单元即“杨辉三角形”,第 n 行中的非零单元之和构成 [(1.0-p) + p]^k 的展开式。因此,解二中的第三种情况,可结合利用通项公式 C(N,K)*[(1.0-p)^(N-K)]*(p^K) 来解决。
如下代码所示,
static long double binomial3(int N, int K, long double p)
{
long double x;
if ...
} else {
x = combination(N, K) * powl(1.0L-p, N-K) * powl(p, K);
}
return x;
}
◆ 测试
编译并执行程序,
$ g++ -std=c++11 -o 27.out 27.cpp
$ ./27.out 10 5 0.25
为易于显示两者之间的差异,笔者选择了硬件配置偏低的测试环境。
- 硬件配置:Raspberry Pi 3 Model B
- Quad Core 1.2GHz 64bit
- 1G RAM
- 16G MicroSD
- 100 Base Ethernet
- 软件配置:Raspbian Stretch
- g++ (Raspbian 6.3.0-18+rpi1+deb9u1) 6.3.0 20170516
测试并记录了 (N, K, p) 为 (10, 5, 0.25), (20, 10, 0.25), (40, 20, 0.25), (80, 40, 0.25), (100, 50, 0.25) 的情况下,原递归、解一、解二、解三执行时所消耗的时间。
结果如下图所示,
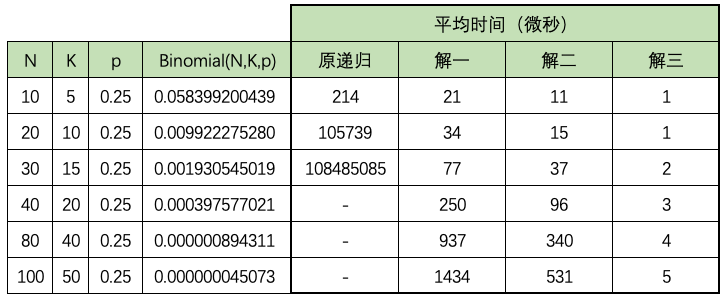
对比可以看出,不同的解法在执行时间上的差异随着计算量的增加而逐步扩大。
◆ 最后
完整示例代码和测试结果,请参考
[gitee] cnblogs/17328989
。
写作过程中,笔者参考了
[github] reneargento/algorithms-sedgewick-wayne
和
[github] aistrate/AlgorithmsSedgewick
的实现方式。致 reneargento 和 aistrate 两位。