Ffmpeg分布式视频转码问题总结
本文主要聊一聊云原生时代分布式转码系统实施过程中碰到的一些问题。
聊问题之前简单介绍一下我们的分布式转码方案。
云原生分布式转码
在计算资源招之即来的云计算时代,正在重构着软件架构的方方面面。
对软件架构师或者运维管理者影响比较大的一个点便是不需要在做容量规划,不需要提前评估为了应对某个活动应该准备多少台机器,这个特点也深刻影响软件架构的设计。
分布式转码方案
在之前的文章中有说到视频转码主要分为3个步骤:
- 切片:将输入的视频进行切片,切分成一个个较小的视频片段
- 转码:将一个个小的视频片段下发到不同的机器上进行转码,并行执行,充分利用多个实例的计算能力
- 合并:将转码后的小视频片段合并成一个视频
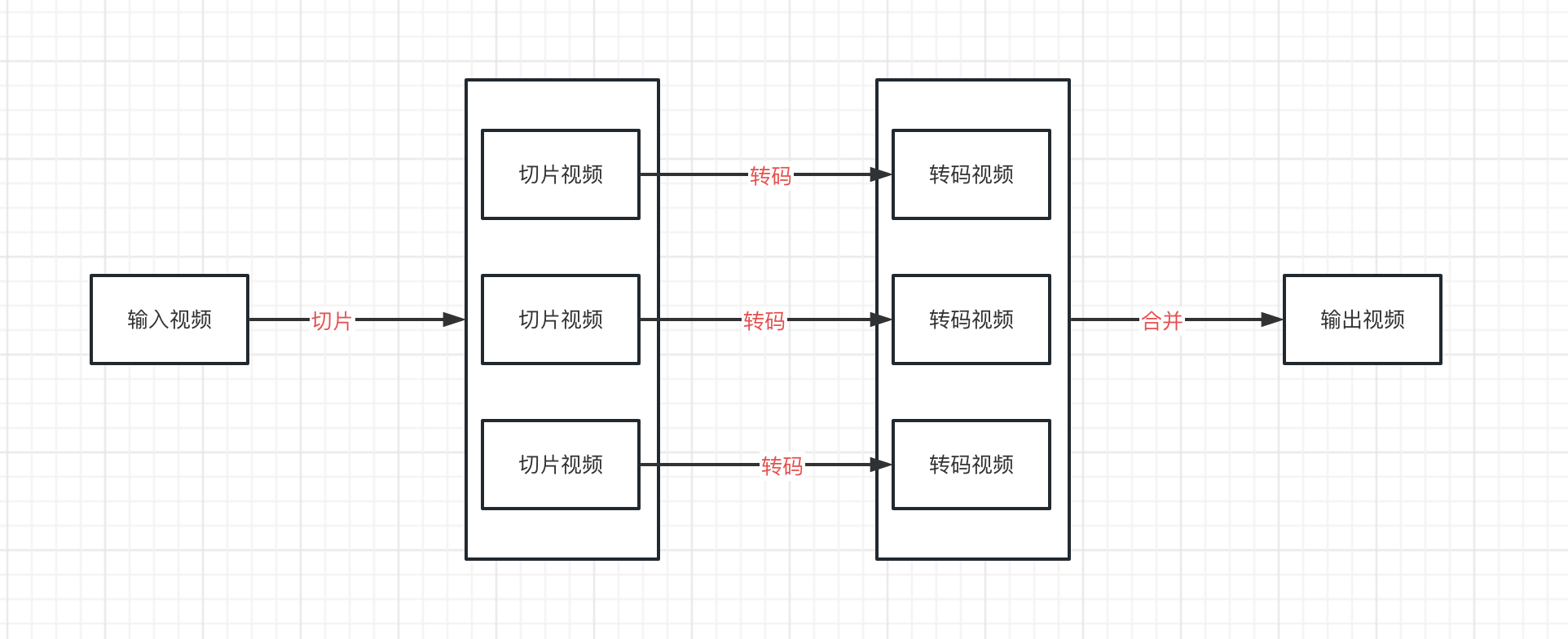
切片 转码 合并
输入视频 ------> (n个)转码任务 ------> (n个)转码结果 -----> 输出视频
为什么要切片?
为了加快转码速度。
视频转码是一个非常耗时的操作,让不同的机器并行转码不同的视频片段,可以充分利用大规模计算资源来加快最耗时的转码流程。
举一个例子,假设1台4核8G的机器能够提供2倍速的转码速度,
- 转码1个小时的视频则需要30分钟;
- 如果将1个小时视频分成2个片段(每段30分钟),就能够并行在2台机器上执行,那么每个片段分别只需要15分钟就能够转码完成;
- 如果将1个小时视频分成4个片段(每段15分钟),就能够并在在4台机器上执行,那么每个片段分别只需要7.5分钟就转码完成;
理论上对视频进行合理的切片加上充足的计算资源,能够极大的提高转码的速度。
虽然这种分布式切片转码方案优势这么明显,但是在实践过程中也发现了不少问题。
想借此文跟大家探讨一下我们碰到的部分问题以及解决方案,看看大家有没有更好的方案。
要是能够给大家带来一些帮助、少踩两个坑,目的就达到了。
碰到的问题
- 不聊工程上的问题,工程上的问题都比较好解决
- 主要聊ffmpeg切片、转码、合并过程中所遇到的问题
- 知识储备的原因,有些ffmpeg底层的原理可能会一笔带过。。
m3u8转码后有杂音
对于m3u8转码,我们在切片环节直接用ts文件作为切片,转码后再合并为最终的视频文件。
这么做的好处是大大缩短了切片的时间,如果用ffmpeg 进行切片需要将文件读取到内存再切成一个个小视频;
而直接用ts文件作为切片的好处是大大缩短了切片这个环节的耗时,相当于纯文本处理,把m3u8文件中的ts文件地址解析出来就行。
问题现象
m3u8转码后生成的视频有轻微的杂音,而原m3u8文件中
问题解释
因为采样率的原因,ts文件中的音视频流并不是完全对其的。如:

直接播放m3u8文件时,会将所有的ts文件都看成一个整体,即将每个ts片段中的视频流和音频流都连接起来的,所以播放时没有杂音。
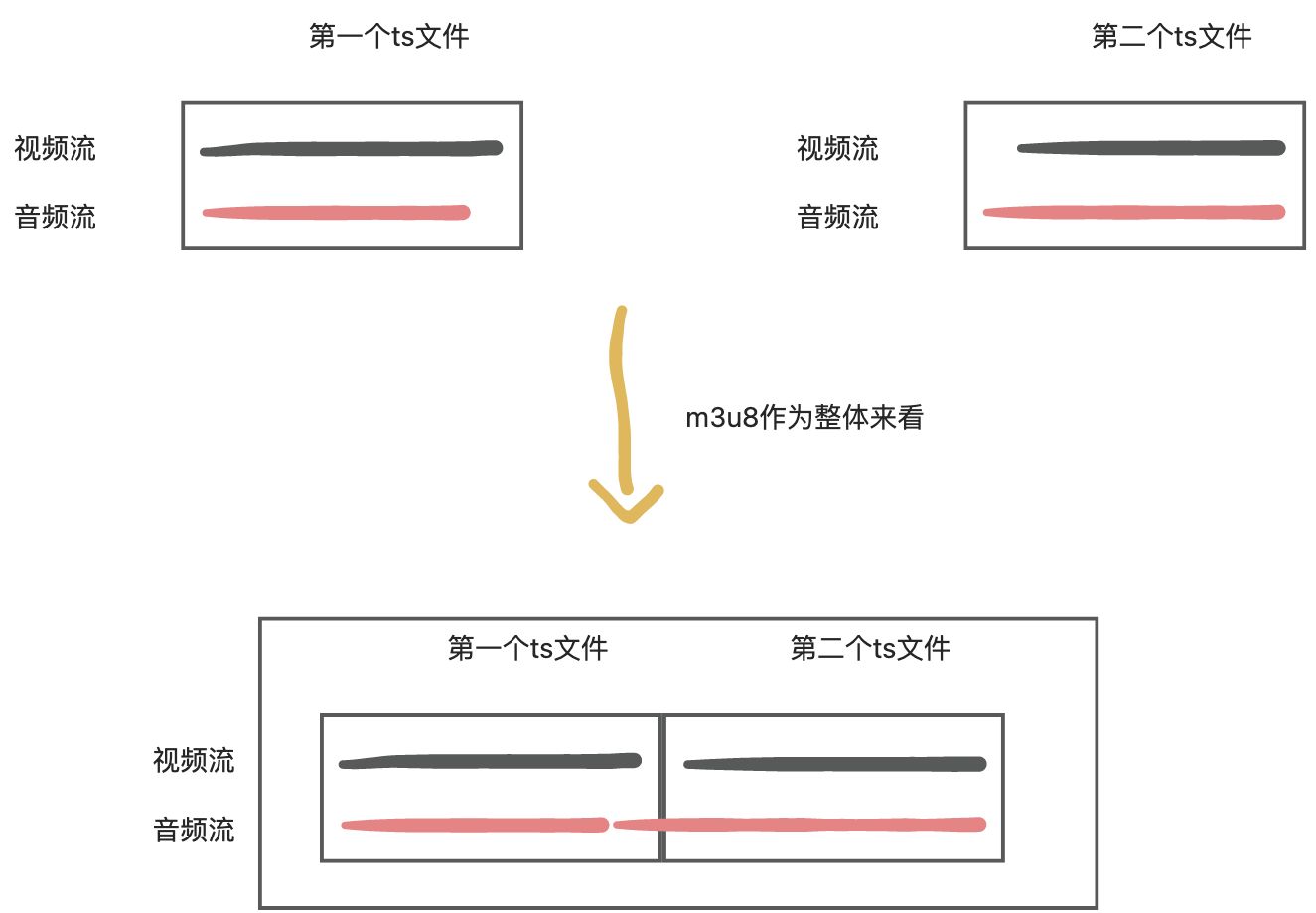
以上图第一个ts为例,将ts文件转码为mp4后,缺失的音频流将默认会补齐,这就造成了杂音的出现。
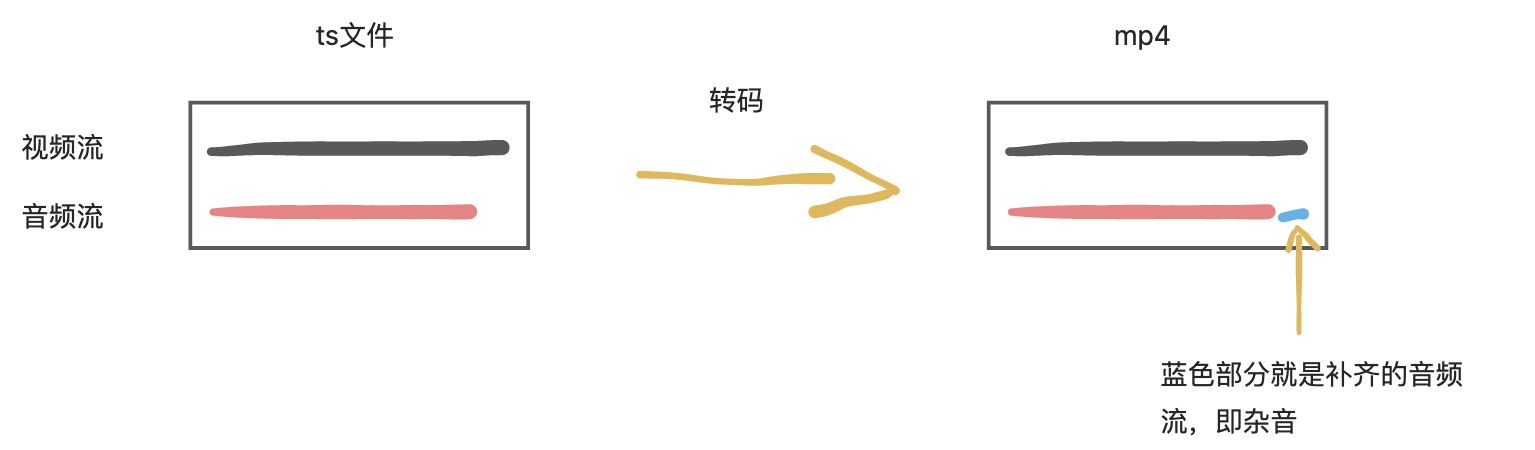
解决方案
将音视频流分离,单独进行转码。
- 对于视频流,仍然采用切成小视频片段的方式进行转码
- 对于音频流,转码不耗资源,就不再进行切片,而是对整个音频流进行转码
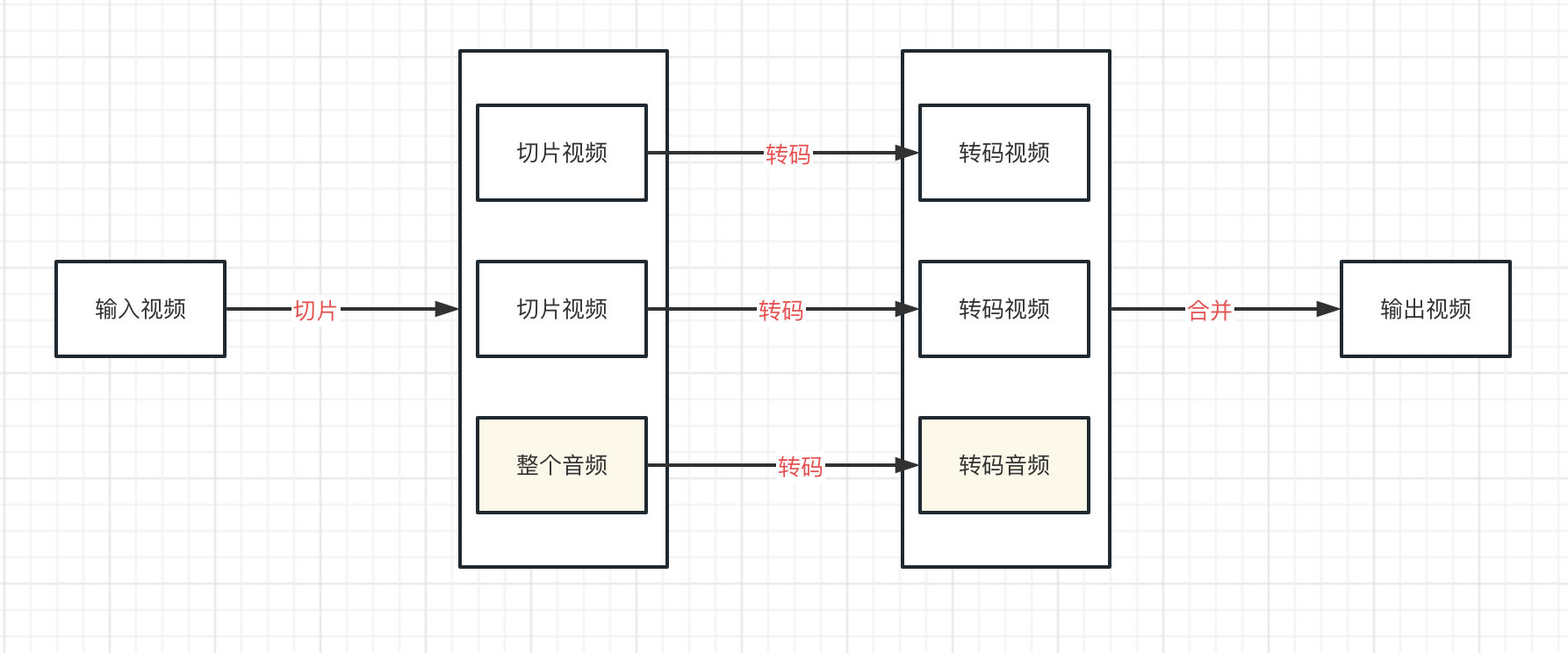
这样m3u8转码出来就不会有杂音了。
附对应的切片跟合并命令
# 切片命令
ffmpeg -i input.mp4 -map 0:v -f segment -segment_time 15 -reset_timestamps 1 -c copy segment%d.mp4 -map 0:a -c:v vframes 1 -c:a copy audio.mp4 -y
# 合并视频命令
ffmpeg -f concat -safe 0 -i concat.txt -c copy concat.mp4
# 合并视频与音频命令
ffmpeg -i concat.mp4 -i audio.mp4 -map 0:v -map 1:a -c:v copy -c:a copy output.mp4 -y
转码后视频变长&音画不同步
问题现象
转码后的视频长度较输入视频长度变长了。
如输入视频是3600s,输出视频可能是3601s,多了1s;而且输入视频时长越长,误差越大。
问题解释
与上一个问题「m3u8转码后有杂音」的原因类似:
- 因为采样率的原因,切出来的视频片段中的音视频流时长不完全一致
- 对视频片段进行转码时取最长的流时长作为输出后的视频片段的时长
- 在合并环节直接将所有转码后的视频片段拼接在一起,所以输出的视频时长变长了
解决方案
与上一个问题「m3u8转码后有杂音」的解决方案类似:将音视频流分别抽离进行转码,最后在合并环节将音视频流合在一起。
这样避免了在切片环节音视频流时长互相影响。
m3u8文件切片起止时间不准
问题现象
举一个例子,从a.m3u8的第10s开始切5s视频出来,命令如下:
ffmpeg -ss 10 -t 5 -i a.m3u8 -c copy out.mp4
实际输出的out.mp4不一定从a.m3u8第10s开始的。
问题解释
在切片环节已经不准确了,合并出来的视频肯定也是不准的,所以我们要在切片环节把这个问题解决掉。
这里我引入最近大火的ChatGPT的回答:
m3u8格式的视频不支持随机访问,而且由于ts文件的长度不固定,ffmpeg很难精确定位到seek目标所在位置。

解决方案
我们是怎么解决的呢,可以参考ChatGPT给出来的4种解决方案的第4个方案:
- 将包含切片起止时间的最小ts文件集合筛选出来
- 将最小ts文件集合转封装为mp4
- 重新计算出在mp4上实际的起止时间,进行切片
想必大家肯定有很多疑问,我们一步一步来解释一下。
如何将包含切片起止时间的最小ts片段集合筛选出来?
m3u8文件中的每一个ts文件都标明了该ts文件的时长,我们可以借助这个将最小的ts文件集合筛选出来
为什么要转封装为mp4?
因为mp4支持随机访问
m3u8转封装为mp4会不会出现m3u8中的音视频编码不支持mp4的情况?
不会。可以参考维基百科:
https://en.wikipedia.org/wiki/Comparison_of_video_container_formats如何重新计算出在mp4上的实际起止时间?
参考问题1的回答,可以通过每个ts文件的时间,计算出最终在mp4上实际的起止时间
PS:ChatGPT真的太强大了,要是ChatGPT早点出来会少走很多弯路。
输入视频的音视频编码不规范
问题现象
在切片环节切片失败
问题解释
用户输入的视频文件编码不规范:
- 视频编码正常,音频编码不规范。如将pcm编码的音频流封装到了mp4格式中
- 视频编码与音频编码均不规范。大概率是原视频被强行改了后缀,如将a.mp4改成a.mxf
因为切片环节设计到重新封装的操作,将1个mp4切成多个mp4就需要重新封装。
在重新封装时就会报错,不同的容器格式支持不同的音视频编码,可以参考维基百科:
https://en.wikipedia.org/wiki/Comparison_of_video_container_formats
有意思的是用户意识不到他们的视频文件有问题,因为音视频流都能够正常解码(即能够正常播放)。
解决方案
第2个问题在目前的分布式转码方案中还没有好的解决方案,再加上出现概率非常小(用户手动更改文件后缀),这里不做讨论。
主要讨论一下第1个问题的解决方案:在切片环节就将音频文件转码了。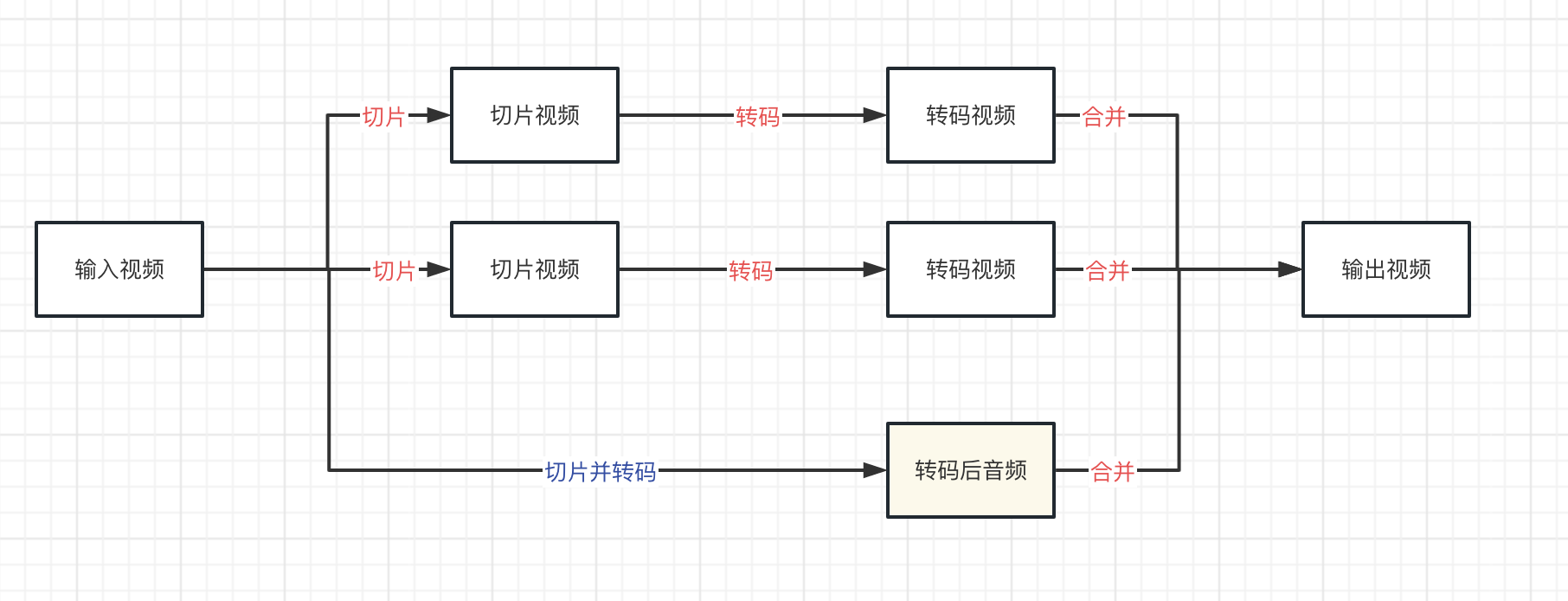
为什么能够在切片环节对音频转码?因为音频转码不耗CPU,不会明显影响到切片环节的速度。
mxf不支持抽离音频流
问题现象
mxf格式的视频经过切片命令抽离出来的音频文件时长只有1帧(0.04s)。
因为我们切片命令里只给了1帧图片到音频文件中。
问题解释
mxf以视频流的长度作为整个视频的长度,意味着音频切片只有一帧图像的话,整个视频时长只有1帧的时长。
所以问题准确的描述应该为mxf不支持以这种方式抽离音频流。
解决方案
既然mxf不支持以这种方式抽离音频流,那么方案有2个:
- 将所有的视频流不转码,都copy到音频文件中,还是只对音频流进行转码。
- 看看有没有完全包含mxf支持的音视频编码格式并且支持这种方式抽离音频流的封装格式。
方案1相当于音频文件对输入视频进行了一次拷贝,如果输入视频特别大,那么音频文件也将会特别大。
我们最终采用的方案2。
有没有这种格式呢?即支持所有mxf 音视频编码格式,又支持这种方式抽离音频。
还真有。通过维基百科:
https://en.wikipedia.org/wiki/Comparison_of_video_container_formats
,可以发现avi格式能够支持所有mxf支持的音视频编码格式;而且经过测试,也支持这种方式将音频抽离出来。
所以对于mxf格式的视频,在切片环节切出来的音频文件设置为avi格式。
ffmpeg对图片支持不够友好
问题现象
对于头信息比较大的图片再加上不能准确读取后缀的话(如加签访问的场景),很大概率会解析失败,获取到错误的meta信息。
如将图片识别出2帧。
问题解释
ffmpeg确实对图片支持不太友好
解决方案
将图片下载到本地,再进行识别。
这种方案有一个缺点是耗时会非常长,如果业务方同步调用获取信息接口有可能会超时。
阿里云的转码方案
决定自研转码之前,我们是使用阿里云的转码服务的。
上面碰到的很多问题在阿里云转码服务中都不存在,这里面固然有阿里云在音视频转码领域的积累,但是我想也跟他们的转码方案有很大的关系。
经过长时间的观察,我猜阿里云没有使用
切片-转码-合并
这种方案,而是
使用高性能服务器,不切片直接对视频进行转码
。
为什么呢?因为上述问题中,基本上都是在切片环节出现的问题。尤其是「输入视频的音视频编码不规范」这个问题,只要使用
切片-转码-合并
这种方案,那么百分之百会碰到跟我们的问题。而阿里云不能使用我们这种非常规手段去解决。
因为视频封装格式、音视频编码格式非常多,出于稳定性考虑,不可能碰到问题了再case by case的去解决。
但是
使用高性能服务器,不切片直接对视频进行转码
这种方案固然能够避免很多切片环节的问题,但是也很容易造成转码任务阻塞。举一个例子:
在机器资源池不大的情况下,A用户输入了很多优先级低转码非常耗时的视频,把资源池都占满了;而随后B用户输入了1个优先级很搞的视频,虽然优先级很高,但是也得等待A用户正在转码的视频转完,让出1台机器才能执行。
这种情况对B用户体验就非常不好,在A用户转码完成之前对B用户来说服务是不可用的。
最后
好了,本篇将我们实施分布式转码过程中所碰到的比较难解的问题以及解决方案都聊了一遍。
当然,以后还会碰新的问题,我会将其放在一个系列文章里面讨论,希望能够给大家带来一些帮助或者少踩一些坑。