JAVAAPI实现血缘关系Rest推送到DataHub V0.12.1版本
DataHub 更青睐于PythonAPI对血缘与元数据操作
虽然开源源码都有Java示例和Python示例:但是这个API示例数量简直是1:100的差距!!不知为何,项目使用Java编写,示例推送偏爱Python的官方;;;搞不懂也许就是开源官方团队写脚本的是Python一哥吧!
显然DataHub 更青睐于Python API对血缘与元数据操作
Java示例:屈指可数
Python示例 就是海量丰富了
目前Java示例就两个好用:
DatasetAdd.java 和 DataJobLineageAdd.java
(一)DatasetAdd.java 是设置元数据到Datahub
private static void extractedTable() {
String token = "";
try (RestEmitter emitter =
RestEmitter.create(b -> b.server("http://10.130.1.49:8080").token(token))) {
MetadataChangeProposal dataJobIOPatch =
new DataJobInputOutputPatchBuilder()
.urn(
UrnUtils.getUrn(
"urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_456)")) //这个是使用的JOB输入表级:中转处理任务
.addInputDatasetEdge(
DatasetUrn.createFromString(
"urn:li:dataset:(urn:li:dataPlatform:mysql,JDK-Name,PROD)")) //这个是使用的JOB输入表级:入口节点
.addOutputDatasetEdge(
DatasetUrn.createFromString(
"urn:li:dataset:(urn:li:dataPlatform:hive,JDK-Name,PROD)")) //这个是使用的JOB输入表级:出口节点
.addInputDatajobEdge(
DataJobUrn.createFromString(
"urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)")) // 这里定义字段列级别的血缘关系:中转处理任务
.addInputDatasetField(
UrnUtils.getUrn(
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:hive,JDK-Name,PROD),userName)")) // 列字段的入口节点
.addOutputDatasetField(
UrnUtils.getUrn(
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:mysql,JDK-Name,PROD),userName)")) // 列字段的出口节点
.build();
Future<MetadataWriteResponse> response = emitter.emit(dataJobIOPatch);
System.out.println(response.get().getResponseContent());
} catch (Exception e) {
e.printStackTrace();
System.out.println("Failed to emit metadata to DataHub"+ e.getMessage());
throw new RuntimeException(e);
}
}
(二)DataJobLineageAdd.java 是设置元数据带JOB任务的血缘到Datahub
public static void main(String[] args)
throws IOException, ExecutionException, InterruptedException {
// Create a DatasetUrn object from a string
DatasetUrn datasetUrn = UrnUtils.toDatasetUrn("hive", "JDK-Mysql", "PROD");
// Create a CorpuserUrn object from a string
CorpuserUrn userUrn = new CorpuserUrn("ingestion");
// Create an AuditStamp object with the current time and the userUrn
AuditStamp lastModified = new AuditStamp().setTime(1640692800000L).setActor(userUrn);
// Create a SchemaMetadata object with the necessary parameters
SchemaMetadata schemaMetadata =
new SchemaMetadata()
.setSchemaName("customer")
.setPlatform(new DataPlatformUrn("hive"))
.setVersion(0L)
.setHash("")
.setPlatformSchema(
SchemaMetadata.PlatformSchema.create(
new OtherSchema().setRawSchema("__RawSchemaJDK__")))
.setLastModified(lastModified);
// Create a SchemaFieldArray object
SchemaFieldArray fields = new SchemaFieldArray();
// Create a SchemaField object with the necessary parameters
SchemaField field1 =
new SchemaField()
.setFieldPath("mysqlId")
.setType(
new SchemaFieldDataType()
.setType(SchemaFieldDataType.Type.create(new StringType())))
.setNativeDataType("VARCHAR(50)")
.setDescription(
"Java用户mysqlId名称VARCHAR")
.setLastModified(lastModified);
fields.add(field1);
SchemaField field2 =
new SchemaField()
.setFieldPath("PassWord")
.setType(
new SchemaFieldDataType()
.setType(SchemaFieldDataType.Type.create(new StringType())))
.setNativeDataType("VARCHAR(100)")
.setDescription("Java用户密码VARCHAR")
.setLastModified(lastModified);
fields.add(field2);
SchemaField field3 =
new SchemaField()
.setFieldPath("CreateTime")
.setType(
new SchemaFieldDataType().setType(SchemaFieldDataType.Type.create(new DateType())))
.setNativeDataType("Date")
.setDescription("Java用户创建时间Date")
.setLastModified(lastModified);
fields.add(field3);
// Set the fields of the SchemaMetadata object to the SchemaFieldArray
schemaMetadata.setFields(fields);
// Create a MetadataChangeProposalWrapper object with the necessary parameters
MetadataChangeProposalWrapper mcpw =
MetadataChangeProposalWrapper.builder()
.entityType("dataset")
.entityUrn(datasetUrn)
.upsert()
.aspect(schemaMetadata)
.build();
// Create a token
String token = "";
// Create a RestEmitter object with the necessary parameters
RestEmitter emitter = RestEmitter.create(b -> b.server("http://10.130.1.49:8080").token(token));
// Emit the MetadataChangeProposalWrapper object
Future<MetadataWriteResponse> response = emitter.emit(mcpw, null);
// Print the response content
System.out.println(response.get().getResponseContent());
emitter.close();
}
我们大多数时候不是需要带JOb的血缘关系
例如: 直接是表与表之间有关系
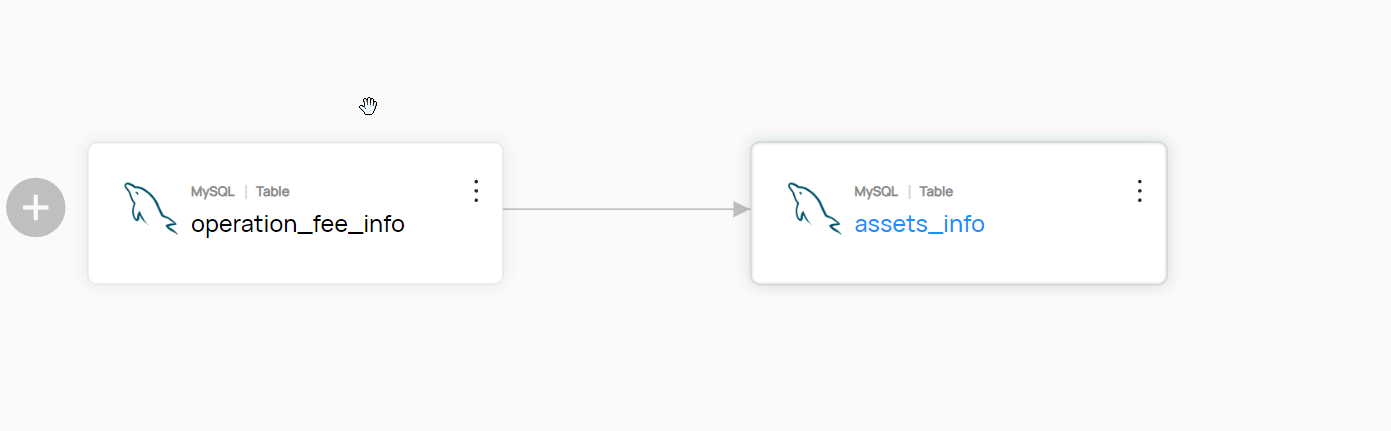
python脚本这里不赘述:太多示例了。重点是Java这边怎么实现这个东西
参考DataJobLineageAdd示例:他这里核心分析
(1.1) 就是把血缘关系提交到Datahub
代码====>
Future<MetadataWriteResponse> response = emitter.emit(dataJobIOPatch);
System.out.println(response.get().getResponseContent());
分析====>
emitter.emit(?) 这个方法就是提交血缘关系;
里面填充好的就是血缘关系数据吧:示例是dataJobIOPatch 就是携带JOB的血缘关系数据;
因为他初始化变量的时候就是DataJobInputOutputPatchBuilder构建的,见名知意就是JOb相关的
MetadataChangeProposal dataJobIOPatch =
new DataJobInputOutputPatchBuilder()......
所以我们是否是MetadataChangeProposal的实现替换为别的方式:找找源码
类比思想:看看同样的builder实现的地方有别的实现没有

挑出了看着很像的实现:猜一下肯定是和JOB没关系了,而且是直接操作元数据的关系的
DatasetPropertiesPatchBuilder
EditableSchemaMetadataPatchBuilder
UpstreamLineagePatchBuilder
SO 简单改造一下 取名为:DataSetLineageAdd
@Slf4j
class DataSetLineageAdd {
private DataSetLineageAdd() {}
/**
* Adds lineage to an existing DataJob without affecting any lineage
*
* @param args
* @throws IOException
* @throws ExecutionException
* @throws InterruptedException
*/
public static void main(String[] args)
throws IOException, ExecutionException, InterruptedException {
extractedTable();
}
private static void extractedRow() {
// 没有java版本。。。。
}
private static void extractedTable() {
String token = "";
try (RestEmitter emitter =
RestEmitter.create(b -> b.server("http://10.130.1.49:8080").token(token))) {
MetadataChangeProposal mcp =
new UpstreamLineagePatchBuilder().
urn(UrnUtils.getUrn("urn:li:dataset:(urn:li:dataPlatform:mysql,ctmop.assets_info,PROD)"))
.addUpstream(DatasetUrn.createFromString(
"urn:li:dataset:(urn:li:dataPlatform:mysql,ctmop.operation_fee_info,PROD)"), DatasetLineageType.TRANSFORMED)
.build();
Future<MetadataWriteResponse> response = emitter.emit(mcp);
System.out.println(response.get().getResponseContent());
} catch (Exception e) {
e.printStackTrace();
System.out.println("Failed to emit metadata to DataHub"+ e.getMessage());
throw new RuntimeException(e);
}
}
}
表级血缘用JAVA代码就实现了;这是一个简单的Demo;更深入的拓展需要自行挖掘!!!

有人说表级血缘太low了,能不能做到JAVA的字段级血缘关系呢。。。。当然没问题
看我示例用的这个:UpstreamLineagePatchBuilder 他意思没有指定表级还是字段级;API 方法 addUpstream 和 urn都是泛用型,理论上都OK
分析:
表级的元数据: urn:li:dataset:(urn:li:dataPlatform:mysql,ctmop.assets_info,PROD) 这个样子
列级的元数据: urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:mysql,JDK-Name,PROD),userName) 这个样子
发现规律了:表级外面包一层urn:li:schemaField:XXXX,字段名 那不就是列字段了,。。。。。浅谈捯饬结束!!!
有问题还望大家指正:!!!