为什么在使用onnxruntime-gpu下却没有成功调用GPU?
20240105,记。
最近在使用GPU对onnx模型进行加速过程中(仅针对N卡,毕竟也没有别的显卡了。。),遇到了点问题:就是明明在安装了合适版本的显卡驱动和CUDA后,onnx还是不能够成功调用GPU,并且还出现了先导入torch,再导入onnxruntime就可以成功调用的奇怪现象。
测试机器:Windows10,RTX 3070,onnxruntime-gpu==1.16.1,显卡驱动:522,CUDA11.8
问题展示:
onnxruntime.InferenceSession(ckpt, providers=['CUDAExecutionProvider'])
2024-01-05 10:44:22.7798928 [W:onnxruntime:Default, onnxruntime_pybind_state.cc:743 onnxruntime::python::CreateExecutionProviderInstance] Failed to create CUDAExecutionProvider. Please reference https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements to ensure all dependencies are met.
在onnxruntime版本与CUDA等版本均对应,但却出现上面的警告信息,且没有查看到GPU调用。
下意识的会考虑是不是onnxruntime压根没找到GPU,所以尝试了下面的代码:
import onnxruntime
onnxruntime.get_device() # 得到的输出结果是GPU,所以按理说是找到了GPU的
解决之路:
自然是找issue是找官方仓库的issue是最靠谱的了,参考链接:
https://github.com/microsoft/onnxruntime/issues/11092
看完后真的给了我一种顿悟感,而且竟然还与torch莫名地产生了联系,一开始有大佬给出的解决方法是先
import torch
再
import onnxruntime
,但这个方法就很奇怪,我使用了onnx,自然是不想再引入torch这个包,而且torch还很大,没有解决根本问题。
之后有一个佬给出的回答才让我明白过来:
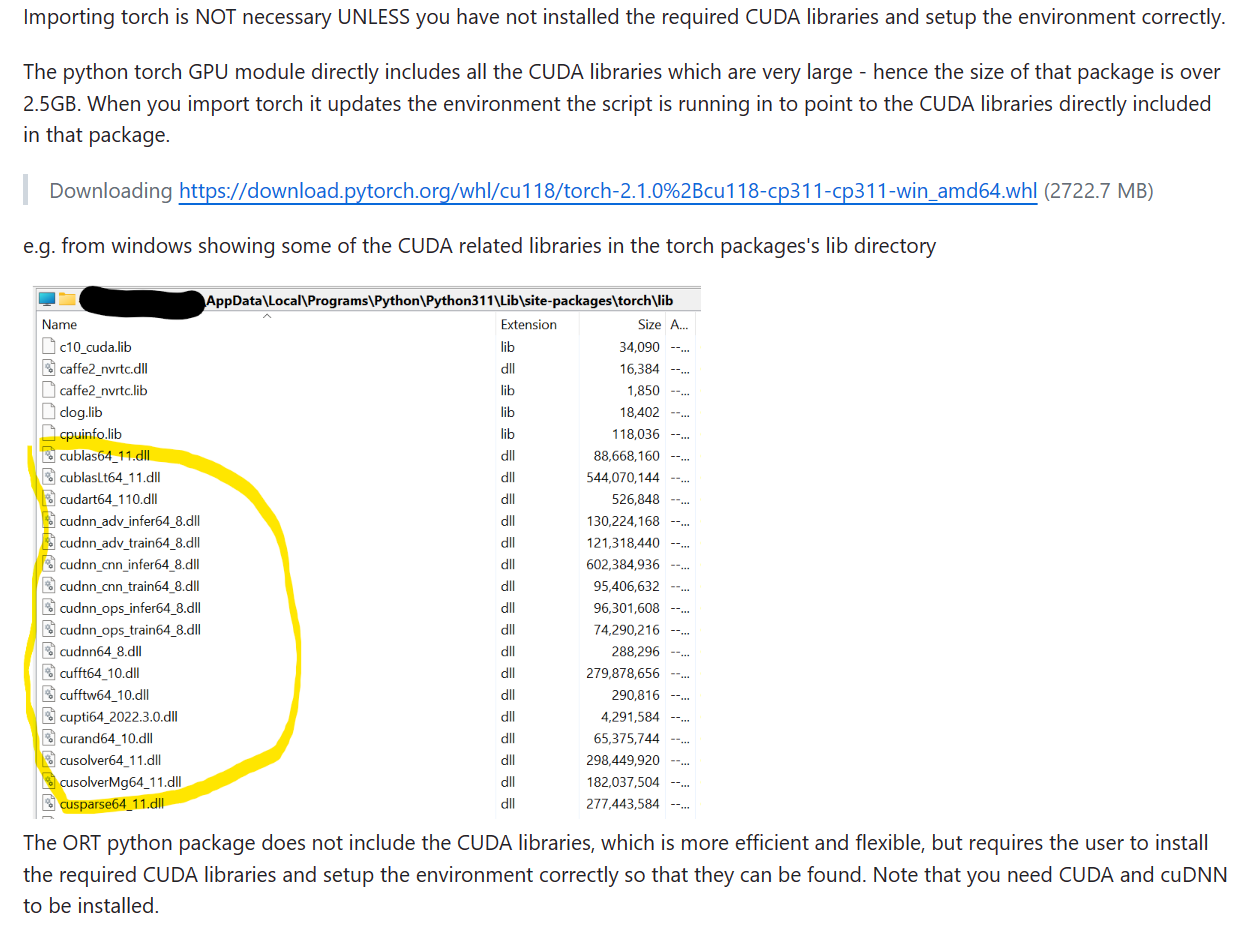
我去查看了自己的torch的lib目录,发现下面确实有cudnn相关的动态链接库,但是去cuda的目录下(
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
),却并没有发现相关的库,也就是说,平常我们安装好cuda就可以用torch了,是因为torch自带了cudnn,即使我们没有安装cudnn,也能够去使用(cuda属于是框架,cudnn是属于软件层面的加速库)。
但onnxruntime不一样,它并没有自带cudnn,所以是需要自己去加cudnn添加进cuda的对应目录下的,具体可参考
cudnn的安装教程
,还有官方教程写的也是比较清晰的:
Installation Guide - NVIDIA Docs

主要是解压下载的压缩包,复制cudnn的文件到cuda目录,以及添加环境变量,不过之前安装CUDA的时候应该已经默认添加过环境变量了。
完成这一步后,重新尝试了执行onnx推理,但却碰到了另一个问题:
Could not locate zlibwapi.dll. Please make sure it is in your library path!
重新查找后,根据
解决Could not locate zlibwapi.dll. Please make sure it is in your library path! - 知乎 (zhihu.com)
给出的回答,
NVIDIA官网已不再提供
zlibwapi.dll
的下载
,重新去
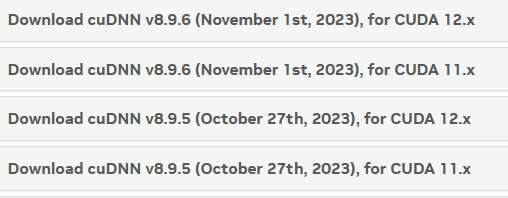
换了最新版本的cuDNN
,目前每个版本又分为与cuda对应的11.x和12.x的版本。版本对应可参考:
Support Matrix - NVIDIA Docs
至此就解决了我碰到的onnxruntime无法在GPU推理的问题,关键点还是在于
按照以往torch使用的思路,以为安装了驱动和CUDA就可以了(或者说下意识以为cuDNN就已经一起安装好了,但其实并没有),但还需要添加cuDNN库,因为torch自带了,而onnxruntime没有自带