JVM学习-程序编译与优化
原文链接:
https://gaoyubo.cn/blogs/89d6d9be.html
一、前端编译与优化
Java技术下讨论“编译期”需要结合具体上下文语境,因为它可能存在很多种情况:
前端编译器(叫“编译器的前端”更准确一些)把
.java文件
转变成
.class文件
的过程JDK的Javac、Eclipse JDT中的增量式编译器(ECJ)
即时编译器(常称JIT编译器,Just In Time Compiler)运行期
把字节码转变成本地机器码
的过程HotSpot虚拟机的C1、C2编译器,Graal编译器
提前编译器(常称AOT编译器,Ahead Of Time Compiler)直接
把程序编译成与目标机器指令集相关的二进制代码
的过程JDK的Jaotc、GNU Compiler for the Java(GCJ)、Excelsior JET 。
本章标题中的“前端”指的是由
前端编译器
完成的编译行为,对于前端编译优化,有以下说法:
前端编译器对代码的运行效率几乎没有任何优化措施可言
Java虚拟机设计团队选择把对
性能的优化全部集中到运行期的即时编译器
中这样可以让那些不是由Javac产生的Class文件也同样能享受到编译器优化措施所带来的性能红利
相当多新生的Java语法特性,都是靠编译器的“语法糖”来实现,而不是依赖字节码或者Java虚拟机的底层改进来支持。
Java中即时编译器在运行期的优化过程,支撑了程序执行效率的不断提升;
前端编译器在编译期的优化过程,支撑着程序员的编码效率和语言使用者的幸福感的提高
1.1Javac编译器
从Javac源代码的总体结构来看,编译过程大致可以分为
1个准备过程和3个处理过程
,它们分别如下所示:
准备过程:初始化插入式注解处理器
解析与填充符号表过程,包括:
词法、语法分析:将源代码的字符流转变为标记集合,构造出抽象语法树
填充符号表:产生符号地址和符号信息
插入式注解处理器的注解处理过程:插入式注解处理器的执行阶段
分析与字节码生成过程,包括:
标注检查:对语法的静态信息进行检查。
数据流及控制流分析:对程序动态运行过程进行检查。
解语法糖:将简化代码编写的语法糖还原为原有的形式。
字节码生成:将前面各个步骤所生成的信息转化成字节码。
对于以上过程:执行插入式注解时又可能会产生新的符号,如果有新的符号产生,就必须转 回到之前的解析、填充符号表的过程中重新处理这些新符号
整个编译过程主要的处理由图中标注的8个方法来完成

解析和填充符号表
词法语法分析
1.词法分析
:词法分析是将源代码的字符流转变为标记(Token)集合的过程。
2.语法分析
:语法分析是根据标记序列构造抽象语法树的过程
抽象语法树:抽象语法树(Abstract Syntax Tree,AST)是一 种用来
描述程序代码语法结构的树形表示方式
,抽象语法树的每一个节点都代表着程序代码中的一个语法结构包、类型、修饰符、运算符、接口、返回值甚至连代码注释等都可以是一种特定的语法结构。
抽象语法树可通过Eclipse AST View插件查看,抽象语法树是以com.sun.tools.javac.tree.JCTree 类表示的
经过词法和语法分析生成语法树以后,编译器就不会再对源码字符流进行操作了,
后续的操作都建立在抽象语法树之上
填充符号表
符号表(Symbol Table)是由一组符号地址和符号信息构成的数据结构(可以理解成哈希表中的键值对的存储形式)
符号表中所登记的信息在编译的不同阶段都要被用到:
- 语义分析的过程中,符号表所登记的内容将用于语义检查 (如检查一个名字的使用和原先的声明是否一致)和产生中间代码
- 目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的直接依据。
注解处理器
可以把
插入式注解处理器
看作是一组编译器的插件,当这些插件工作时,允许读取、修改、添加抽象语法树中的任意元素。
譬如Java著名的编码效率工具Lombok,它可以通过注解来实现自动产生 getter/setter方法、进行空置检查、生成受查异常表、产生equals()和hashCode()方法,等等.
语义分析与字节码生成
语义分析的主要任务则是对结构上正确的源 程序进行上下文相关性质的检查,譬如进行
类型检查、控制流检查、数据流检查
,等等
int a = 1;
boolean b = false;
char c = 2;
//后续可能出现的赋值运算:
int d = a + c;
int d = b + c; //错误,
char d = a + c; //错误
//C语言中,a、b、c的上下文定义不变,第二、三种写法都是可以被正确编译的
我们编码时经常能在IDE 中看到由红线标注的错误提示,其中绝大部分都是来源于语义分析阶段的检查结果。
1.标注检查
标注检查步骤要检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配,等等,刚才3个变量定义的例子就属于标注检查的处理范畴
在标注检查中,还会顺便进行 一个称为常量折叠(Constant Folding)的代码优化,这是Javac编译器会对源代码做的极少量优化措施 之一(代码优化几乎都在即时编译器中进行)。
int a = 2 + 1;

由于编译期间进行了常量折叠,所以在代码里面定 义“a=1+2”比起直接定义“a=3”来,并不会增加程序运行期哪怕仅仅一个处理器时钟周期的处理工作量。
2.数据及控制流分析
可以检查出诸如程序局部变量
在使用前是否有赋值
、方法的
每条路径是否都有返回值
、是否所有的受查异常都被正确处理了等问题。
3.解语法糖
在Javac的源码中,解语法糖的过程由desugar()方法触发。
Java中最常见的语法糖包括了前面提到过的泛型、变长参数、自动装箱拆箱,等等。
4.字节码生成
字节码生成是Javac编译过程的最后一个阶段,在Javac源码里面由com.sun.tools.javac.jvm.Gen类来完成。
字节码生成阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码指令写到磁盘中,编译器还进行了少量的代码添加和转换工作。
实例构造器()方法和类构造器()方法就是在这个阶段被添加到语 法树之中的
字符串的加操作替换为StringBuffer或StringBuilder(取决于目标代码的版本是否大于或等于JDK 5)的append()操 作,等等。
1.2语法糖的本质
泛型
泛型的本质是参数化类型或者参数化多态的应用,即可以将操作的数据类型指定为方法签名中的一种特殊参数。
Java选择的泛型实现方式叫作
类型擦除式泛型
:Java语言中的泛型只在程序源码中存在,在编译后的字节码文件中,全部泛型都被替换为原来的
裸类型
了,并且在相应的地方插入了强制转型代码。
类型擦除
裸类型”
(Raw Type)的概念:裸类型应被视为所有该类型泛型化实例的共同父类型(Super Type)
ArrayList<Integer> ilist = new ArrayList<Integer>();
ArrayList<String> slist = new ArrayList<String>();
ArrayList list; // 裸类型
list = ilist;
list = slist;
如何实现裸类型?
直接在编译时把ArrayList
泛型擦除前的例子
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("hello", "你好");
map.put("how are you?", "吃了没?");
System.out.println(map.get("hello"));
System.out.println(map.get("how are you?"));
}
把这段Java代码编译成Class文件,然后再用字节码反编译工具进行反编译后,将会发现泛型都不见了
public static void main(String[] args) {
Map map = new HashMap();//裸类型
map.put("hello", "你好");
map.put("how are you?", "吃了没?");
System.out.println((String) map.get("hello"));//强制类型转换
System.out.println((String) map.get("how are you?"));
}
当泛型遇到重载
public class GenericTypes {
public static void method(List<String> list) {
System.out.println("invoke method(List<String> list)");
}
public static void method(List<Integer> list) {
System.out.println("invoke method(List<Integer> list)");
}
}
参数列表在
特征签名
中,因此参数列表不同时,可以进行重载,但是由于所有泛型都需要通过类型擦出转化为裸类型,导致参数都是
List list
,所以不能重载。会报错。

自动装箱、拆箱与遍历循环
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4);
int sum = 0;
for (int i : list) {
sum += i;
}
System.out.println(sum);
}
编译后:
public static void main(String[] args) {
List list = Arrays.asList( new Integer[] {
Integer.valueOf(1),
Integer.valueOf(2),
Integer.valueOf(3),
Integer.valueOf(4) });
int sum = 0;
for (Iterator localIterator = list.iterator(); localIterator.hasNext(); ) {
int i = ((Integer)localIterator.next()).intValue();
sum += i;
}
System.out.println(sum);
}
二、后端编译与优化
如果把字节码看作是程序语言的一种中间表示形式(Intermediate Representation,IR)的话, 那编译器无论在何时、在何种状态下把
Class文件转换成与本地基础设施(硬件指令集、操作系统)相关的二进制机器码
,都可以视为整个编译过程的后端
2.1即时编译器
由于
即时编译器编译本地代码需要占用程序运行时间
,通常要编译出优化程度越高的代码,所花 费的时间便会越长;
而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行阶段的速度也有所影响。
为了在程序启动响应速度与运行效率之间达到最佳平衡:
HotSpot虚拟机在编译子系统中加入了分层编译的功能,分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包 括:
- 第0层。程序纯解释执行,并且解释器不开启性能监控功能(Profiling)。
- 第1层。使用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开启 性能监控功能。
- 第2层。仍然使用客户端编译器执行,仅开启方法及回边次数统计等有限的性能监控功能。
- 第3层。仍然使用客户端编译器执行,开启全部性能监控,除了第2层的统计信息外,还会收集如分支跳转、虚方法调用版本等全部的统计信息。
- 第4层。使用服务端编译器将字节码编译为本地代码,相比起客户端编译器,服务端编译器会启 用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化。

编译对象与触发条件
会被即时编译器编译的目标是
热点代码
,这里所指的热点代码主要有两类:
- 被
多次
调用的方法。 - 被
多次
执行的循环体。
对于这两种情况,编译的目标对象都是整个方法体,而不会是单独的循环体。
这种编译方式因为 编译发生在方法执行的过程中,因此被很形象地称为
栈上替换
(On Stack Replacement,OSR),即方法的栈帧还在栈上,方法就被替换了。
多少次才算“多次”呢?
要知道某段代码是不是热点代码,是不是需要触发即时编译,这个行为称为“热点探测”(Hot Spot Code Detection),判定方式:
基于采样的热点探测(Sample Based Hot Spot Code Detection)
会周期性地检查各个线程的调用栈顶,如果发现
某个方法经常出现在栈顶,那这个方法就是
热点方法
。缺点:很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而 扰乱热点探测
基于计数器的热点探测(Counter Based Hot Spot Code Detection)
为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果
执行次数超过一定的阈值就认为它是
热点方法
。缺点:实现起来要麻烦一些,需要为每个方法建立并维护计数器,而且不能 直接获取到方法的调用关系
J9用过第一种采样热点探测,而在HotSpot 虚拟机中使用的是第二种基于计数器的热点探测方法,
HotSpot 中每个方法的 2 个计数器
- 方法调用计数器
- 统计方法被调用的次数,处理多次调用的方法的。
- 默认统计的不是方法调用的绝对次数,而是方法在一段时间内被调用的次数,如果超过这个时间限制还没有达到判为热点代码的阈值,则该方法的调用计数器值减半。
- 关闭热度衰减:
-XX: -UseCounterDecay
(此时方法计数器统计的是方法被调用的绝对次数); - 设置半衰期时间:
-XX: CounterHalfLifeTime
(单位是秒); - 热度衰减过程是在 GC 时顺便进行。
- 默认阈值在客户端模式下是1500次,在服务端模式下是10000次,
- 关闭热度衰减:
- 回边计数器
- 统计一个方法中 “回边” 的次数,处理多次执行的循环体的。
- 回边:在字节码中遇到控制流向后跳转的指令(不是所有循环体都是回边,空循环体是自己跳向自己,没有向后跳,不算回边)。
- 调整回边计数器阈值:
-XX: OnStackReplacePercentage
(OSR比率)
- Client 模式:
回边计数器的阈值 = 方法调用计数器阈值 * OSR比率 / 100
; - Server 模式:
回边计数器的阈值 = 方法调用计数器阈值 * ( OSR比率 - 解释器监控比率 ) / 100
;
- Client 模式:
- 统计一个方法中 “回边” 的次数,处理多次执行的循环体的。

编译过程
虚拟机在代码编译未完成时会按照解释方式继续执行,
编译动作在后台的编译线程执行。
禁止后台编译:
-XX: -BackgroundCompilation
,打开后这个开关参数后,交编译请求的线程会等待编译完成,然后执行编译器输出的本地代码。
在后台编译过程中,客户端编译器与服务端编译器是有区别的。
客户端编译器
是一个相对简单快速的三段式编译器,主要的
关注点在于局部性的优化
,而放弃了许多耗时较长的全局优化手段。
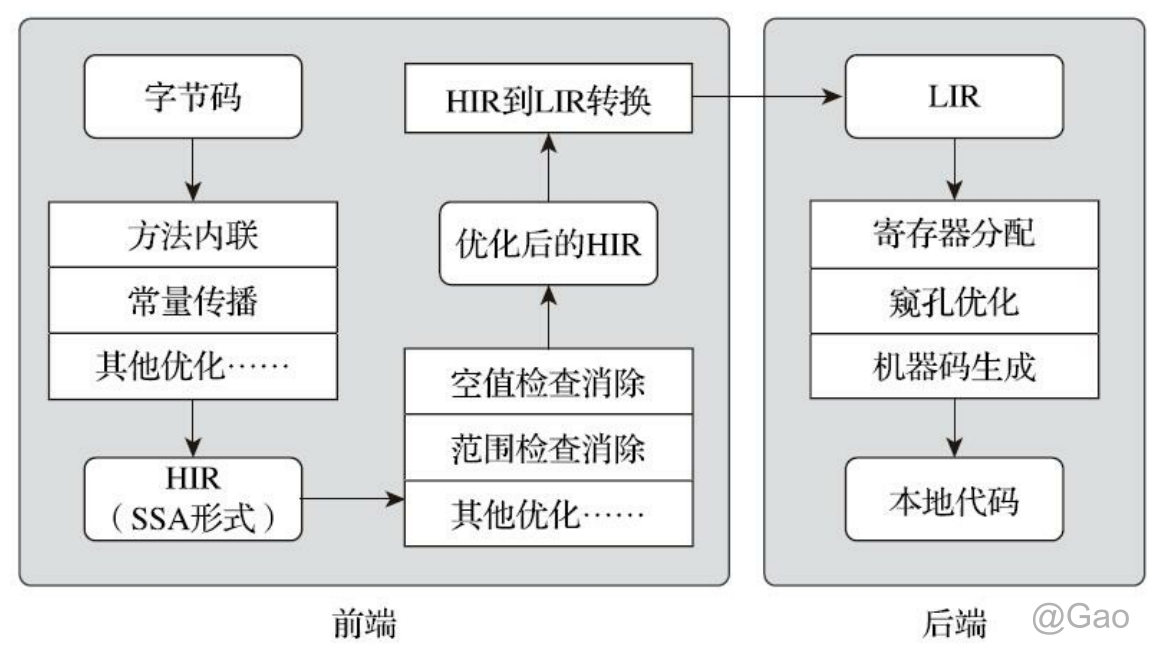
第一个阶段,一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representation,HIR,即与目标机器指令集无关的中间表示)。HIR使用静态单分配 (Static Single Assignment,SSA)的形式来代表代码值,这可以使得一些在HIR的构造过程之中和之后进行的优化动作更容易实现。在此之前编译器已经会在字节码上完成一部分基础优化,
如方法内联、 常量传播等优化将会在字节码被构造成HIR之前完成。第二个阶段,一个平台相关的后端从HIR中产生低级中间代码表示(Low-Level Intermediate Representation,LIR,即与目标机器指令集相关的中间表示),而在此之前会在HIR上完成另外一些优化,如空值检查消除、范围检查消除等,以便让HIR达到更高效的代码表示形式。
最后的阶段是在平台相关的后端使用线性扫描算法(Linear Scan Register Allocation)在LIR上分配寄存器,并在LIR上做窥孔(Peephole)优化,然后产生机器代码。客户端编译器大致的执行过程如图
服务端编译器
是专门面向服务端的典型应用场景,执行大部分经典的优化动作,如:无用代码消除(Dead Code Elimination)、循环展开 (Loop Unrolling)、循环表达式外提(Loop Expression Hoisting)、消除公共子表达式(Common Subexpression Elimination)、常量传播(Constant Propagation)、基本块重排序(Basic Block Reordering)等,还会实施一些与Java语言特性密切相关的优化技术,如范围检查消除(Range Check Elimination)、空值检查消除(Null Check Elimination,不过并非所有的空值检查消除都是依赖编译器优化的,有一些是代码运行过程中自动优化了)等。
另外,还可能根据解释器或客户端编译器提供的 性能监控信息,进行一些不稳定的预测性激进优化,如守护内联(Guarded Inlining)、分支频率预测 (Branch Frequency Prediction)等
服务端编译采用的寄存器分配器是一个全局图着色分配器,它可以充分利用某些处理器架构(如 RISC)上的大寄存器集合。
2.2提前编译器
现在提前编译产品和对其的研究有着两条明显的分支:
与传统C、C++编译器类似的,在
程序运行之前把程序代码编译成机器码的静态翻译工作把原本
即时编译器在运行时要做的编译工作提前做好并保存下来
,下次运行到这些代码(譬如公共库代码在被同一台机器其他Java进程使用)时直接把它加载进来使用。(本质是给即时编译器做缓存加速,去改善Java程序的启动时间)
在目前的Java技术体系里,这种提前编译已经完全被主流的商用JDK支持
困难:这种提前编译方式不仅要和目标机器相关,甚至还必须与HotSpot虚拟机的运行时参数绑定(如生成内存屏障代码)才能正确工作,要做提前编译的话,自然也要把这些配合的工作平移过去。
2.3即时编译器的优势
提前编译的代码输出质量,一定会比即时编译更高吗?
以下为即时编译器相较于提前编译器的优势:
性能分析制导优化(Profile-Guided Optimization,PGO)
抽象类通常会是什么实际类型、条件判断通常会走哪条分支、方法调用通常会选择哪个版本、循环通常会进行多少次等
,这些数据一般在静态分析时是无法得到的,或者不可能存在确定且唯一的解, 最多只能依照一些启发性的条件去进行猜测。但
在动态运行时却能看出它们具有非常明显的偏好性。
就可以把热的代码集中放到 一起,集中优化和分配更好的资源(分支预测、寄存器、缓存等)给它。激进预测性优化(Aggressive Speculative Optimization)
静态优化无论如何都必须保证优化后所有的程序外部可见影响(不仅仅是执行结果) 与优化前是等效的
然而,即时编译的策略就可以不必这样保守,
可以大胆地按照高概率的假设进行优化
,万一真的走到罕见分支上,大不了退回到低级编译器甚至解释器上去执行,并不会出现无法挽救的后果。
如果Java虚拟机真的遇到虚方法就去查虚表而不做内 联的话,Java技术可能就已经因性能问题而被淘汰很多年了。
实际上虚拟机会通过类继承关系分析等 一系列激进的猜测去做去虚拟化(Devitalization),以保证绝大部分有内联价值的虚方法都可以顺利内联。
链接时优化(Link-Time Optimization,LTO)
如C、C++的程序要调用某个动态链接库的某个方法,就会出现很明显的边界隔阂,还难以优化。
这是因为主程序与动态链接库的代码在它们编译时是完全独立的,两者各自编译、优化自己的代码。然而,
Java语言天生就是动态链接的
,一个个 Class文件在运行期被加载到虚拟机内存当中。
三、编译器优化技术
| 类型 | 优化技术 |
|---|---|
| 编译器策略 (Compiler Tactics) | |
| 延迟编译 (Delayed Compilation) | |
| 分层编译 (Tiered Compilation) | |
| 栈上替换 (On-Stack Replacement) | |
| 延迟优化 (Delayed Reoptimization) | |
| 静态单赋值表示 (Static Single Assignment Representation) | |
| 基于性能监控的优化技术 (Profile-Based Techniques) | |
| 乐观空值断言 (Optimistic Nullness Assertions) | |
| 乐观类型断言 (Optimistic Type Assertions) | |
| 乐观类型增强 (Optimistic Type Strengthening) | |
| 乐观数组长度增强 (Optimistic Array Length Strengthening) | |
| 裁剪未被选择的分支 (Untaken Branch Pruning) | |
| 乐观的多态内联 (Optimistic N-morphic Inlining) | |
| 分支频率预测 (Branch Frequency Prediction) | |
| 调用频率预测 (Call Frequency Prediction) | |
| 基于证据的优化技术 (Proof-Based Techniques) | |
| 精确类型推断 (Exact Type Inference) | |
| 内存值推断 (Memory Value Inference) | |
| 内存值跟踪 (Memory Value Tracking) | |
| 常量折叠 (Constant Folding) | |
| 重组 (Reassociation) | |
| 操作符退化 (Operator Strength Reduction) | |
| 空值检查消除 (Null Check Elimination) | |
| 类型检测退化 (Type Test Strength Reduction) | |
| 类型检测消除 (Type Test Elimination) | |
| 代数简化 (Algebraic Simplification) | |
| 公共子表达式消除 (Common Subexpression Elimination) | |
| 数据流敏感重写 (Flow-Sensitive Rewrites) | |
| 条件常量传播 (Conditional Constant Propagation) | |
| 基于流承载的类型缩减转换 (Flow-Carried Type Narrowing) | |
| 无用代码消除 (Dead Code Elimination) | |
| 语言相关的优化技术 (Language-Specific Techniques) | |
| 类型继承关系分析 (Class Hierarchy Analysis) | |
| 去虚拟化 (Devirtualization) | |
| 符号常量传播 (Symbolic Constant Propagation) | |
| 自动装箱消除 (Autobox Elimination) | |
| 逃逸分析 (Escape Analysis) | |
| 锁消除 (Lock Elision) | |
| 锁膨胀 (Lock Coarsening) | |
| 消除反射 (De-reflection) | |
| 内存及代码位置变换 (Memory and Placement Transformation) | |
| 表达式提升 (Expression Hoisting) | |
| 表达式下沉 (Expression Sinking) | |
| 冗余存储消除 (Redundant Store Elimination) | |
| 相邻存储合并 (Adjacent Store Fusion) | |
| 交汇点分离 (Merge-Point Splitting) | |
| 循环变换 (Loop Transformations) | |
| 循环展开 (Loop Unrolling) | |
| 循环剥离 (Loop Peeling) | |
| 安全点消除 (Safepoint Elimination) | |
| 迭代范围分离 (Iteration Range Splitting) | |
| 范围检查消除 (Range Check Elimination) | |
| 循环向量化 (Loop Vectorization) | |
| 全局代码调整 (Global Code Shaping) | |
| 内联 (Inlining) | |
| 全局代码外提 (Global Code Motion) | |
| 基于热度的代码布局 (Heat-Based Code Layout) | |
| Switch调整 (Switch Balancing) | |
| 控制流图变换 (Control Flow Graph Transformation) | |
| 本地代码编排 (Local Code Scheduling) | |
| 本地代码封包 (Local Code Bundling) | |
| 延迟槽填充 (Delay Slot Filling) | |
| 着色图寄存器分配 (Graph-Coloring Register Allocation) | |
| 线性扫描寄存器分配 (Linear Scan Register Allocation) | |
| 复写聚合 (Copy Coalescing) | |
| 常量分裂 (Constant Splitting) | |
| 复写移除 (Copy Removal) | |
| 地址模式匹配 (Address Mode Matching) | |
| 指令窥空优化 (Instruction Peepholing) | |
| 基于确定有限状态机的代码生成 (DFA-Based Code Generator) |
3.1一个优化的例子
原始代码:
static class B {
int value;
final int get() {
return value;
}
}
public void foo() {
y = b.get();
// ...do stuff...
z = b.get();
sum = y + z;
}
第一步优化:
方法内联(一般放在优化序列最前端,因为对其他优化有帮助)
目的:
- 去除方法调用的成本(如建立栈帧等)
- 为其他优化建立良好的基础
public void foo() {
y = b.value;
// ...do stuff...
z = b.value;
sum = y + z;
}
第二步优化:
公共子表达式消除
public void foo() {
y = b.value;
// ...do stuff... // 因为这部分并没有改变 b.value 的值
// 如果把 b.value 看成一个表达式,就是公共表达式消除
z = y; // 把这一步的 b.value 替换成 y
sum = y + z;
}
第三步优化:
复写传播
public void foo() {
y = b.value;
// ...do stuff...
y = y; // z 变量与以相同,完全没有必要使用一个新的额外变量
// 所以将 z 替换为 y
sum = y + z;
}
第四步优化:
无用代码消除
无用代码:
- 永远不会执行的代码
- 完全没有意义的代码
public void foo() {
y = b.value;
// ...do stuff...
// y = y; 这句没有意义的,去除
sum = y + y;
}
3.2方法内联
它是
编译器最重要的优化手段
,甚至都可以不加 上“之一”。
除了消除方法调用的成本之外,它更重要的意义是为其他优化手段建立良好的基础
目的是:去除方法调用的成本(如建立栈帧等),并为其他优化建立良好的基础,所以一般将方法内联放在优化序列最前端,因为它对其他优化有帮助。
为了解决虚方法的内联问题:引入
类型继承关系分析(Class Hierarchy Analysis,CHA)用于确定在目前已加载的类中,某个接口是否有多于一种的实现,某个类是否存在子类、子类是否为抽象类等。
- 对于非虚方法:
- 直接进行内联,其调用方法的版本在编译时已经确定,是根据变量的静态类型决定的。
- 对于虚方法:
(激进优化,要预留“逃生门”)
- 向 CHA 查询此方法在当前程序下是否有多个目标可选择;
- 只有一个目标版本:
- 先对这唯一的目标进行内联;
- 如果之后的执行中,虚拟机没有加载到会令这个方法接收者的继承关系发生改变的新类,则该内联代码可以一直使用;
- 如果加载到导致继承关系发生变化的新类,就抛弃已编译的代码,退回到解释状态进行执行,或者重新进行编译。
- 有多个目标版本:
- 使用内联缓存,未发生方法调用前,内联缓存为空;
- 第一次调用发生后,记录调用方法的对象的版本信息;
- 之后的每次调用都要先与内联缓存中的对象版本信息进行比较;
- 版本信息一样,继续使用内联代码,是一种
单态内联缓存
(Monomorphic Inline Cache) - 版本信息不一样,说明程序使用了虚方法的多态特性,退化成
超多态内联缓存
(Megamorphic Inline Cache),查找虚方法进行方法分派。
- 版本信息一样,继续使用内联代码,是一种
- 只有一个目标版本:
- 向 CHA 查询此方法在当前程序下是否有多个目标可选择;
3.3逃逸分析【最前沿】
基本行为
分析对象的作用域,看它有没有能在当前作用域之外使用:
- 方法逃逸:对象在方法中定义之后,能被外部方法引用,如作为参数传递到了其他方法中。
- 线程逃逸:赋值给 static 变量,或可以在其他线程中访问的实例变量。
对于不会逃逸到方法或线程外的对象能进行优化
- 栈上分配:
对于不会逃逸到方法外的对象,可以在栈上分配内存,这样这个对象所占用的空间可以随栈帧出栈而销毁,减小 GC 的压力。 - 标量替换(重要):
- 标量:基本数据类型和 reference。
- 不创建对象,而是将对象拆分成一个一个标量,然后直接在栈上分配,是栈上分配的一种实现方式。
- HotSpot 使用的是标量替换而不是栈上分配,因为实现栈上分配需要更改大量假设了 “对象只能在堆中分配” 的代码。
- 同步消除
- 如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,对这个变量实施的同步措施也就可以安全地消除掉。
虚拟机参数
- 开启逃逸分析:
-XX: +DoEscapeAnalysis - 开启标量替换:
-XX: +EliminateAnalysis - 开启锁消除:
-XX: +EliminateLocks - 查看分析结果:
-XX: PrintEscapeAnalysis - 查看标量替换情况:
-XX: PrintEliminateAllocations
例子
Point类的代码,这就是一个包含x和y坐标的POJO类型
// 完全未优化的代码
public int test(int x) {
int xx = x + 2;
Point p = new Point(xx, 42);
return p.getX();
}
步骤1:构造函数内联
public int test(int x) {
int xx = x + 2;
Point p = point_memory_alloc(); // 在堆中分配P对象的示意方法
p.x = xx; // Point构造函数被内联后的样子
p.y = 42;
return p.x; // Point::getX()被内联后的样子
}
步骤2:标量替换
经过逃逸分析,发现在整个test()方法的范围内Point对象实例不会发生任何程度的逃逸, 这样可以对它进行标量替换优化,把其内部的x和y直接置换出来,分解为test()方法内的局部变量,从 而避免Point对象实例被实际创建
public int test(int x) {
int xx = x + 2;
int px = xx;
int py = 42;
return px;
}
步骤3:无效代码消除
通过数据流分析,发现py的值其实对方法不会造成任何影响,那就可以放心地去做无效代码消除得到最终优化结果,
public int test(int x) {
return x + 2;
}